-
TabularDataを使ったSwiftでのデータの分析と操作
TabularDataフレームワークを使って、Swiftで非構造化データの読み込み、分析、操作を行う方法を確認します。この方法は、機械学習タスクのためにデータを事前に処理する必要がある場合や、Appでデータをオンザフライで処理する必要がある場合に利用できます。大規模なデータセットを扱う場合、複数のデータテーブルを統合する場合、データをプログラムでフィルタリングする場合に、TabularDataフレームワークがどのように役立つかを説明します。また、DataFrameを活用して、Appのデータ処理を中心とした機能を実行する方法についても紹介します。
リソース
関連ビデオ
WWDC22
-
このビデオを検索
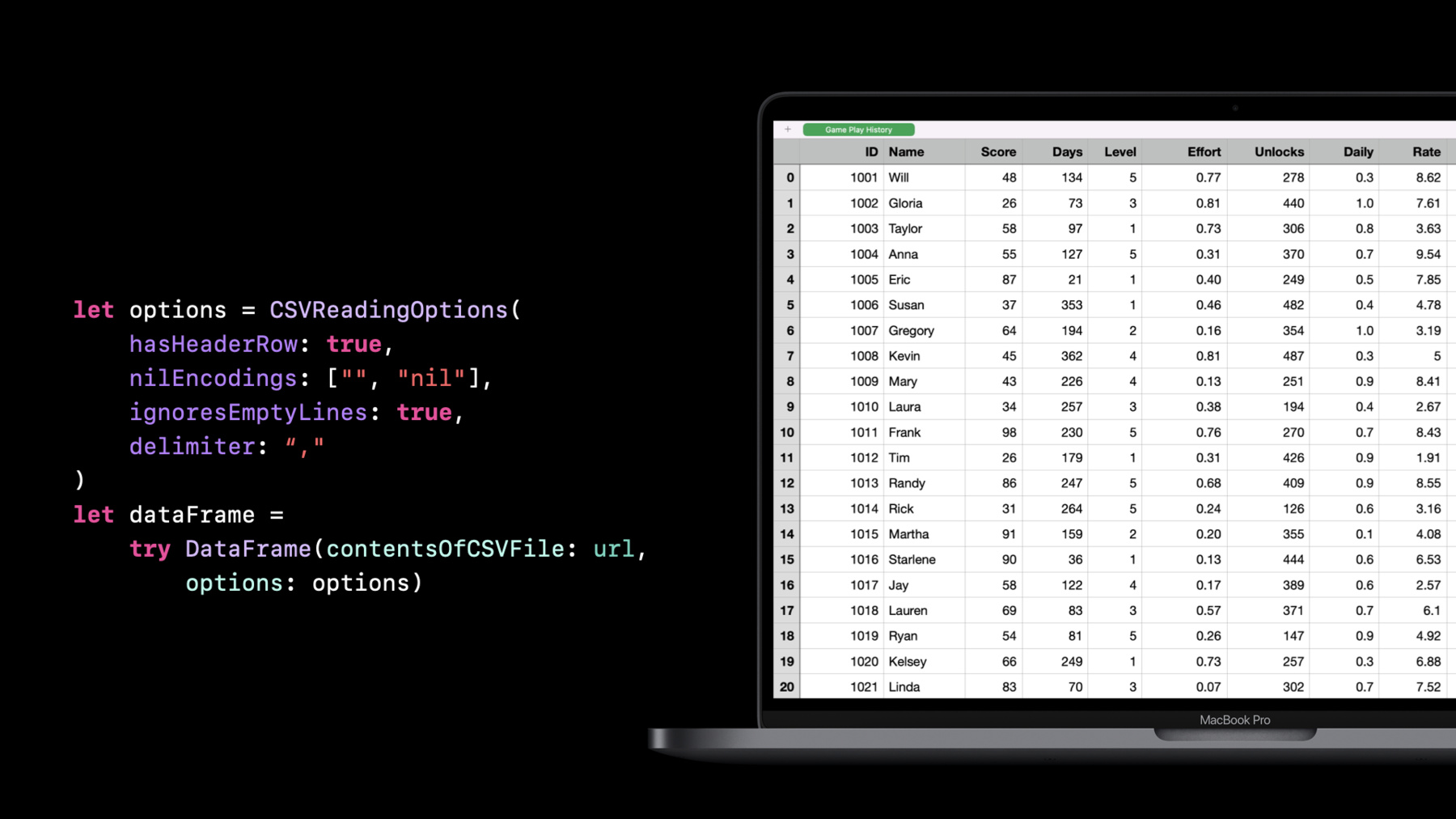
こんにちは Alejandroです 今日はDavidと私で データの操作と分析のための 新しいフレームワークである TabularDataを紹介します 概要を紹介した後で データ分析 データ変換 ベストプラクティスについて説明し 最後にまとめを行います では 始めましょう まず 表形式のデータとは 何かについて説明します 表形式のデータとは 簡単に言うと スプレッドシートのように 行と列で構成された データのことです しかし 何百もの列や 何百万もの行が あったらどうでしょうか そこで使うのが TabularData フレームワークです それは何でしょうか? これは Appleが取り組んできた まったく新しいフレームワークです macOS iOS tvOS watchOSに すでに搭載されていて 非構造化データの分析と 操作に役立ちます 「非構造化データ」とは あらかじめ決められた方法で 整理されていない データのことです 例えば 気象データや 人口統計など 技術仕様が決まっていない データセットを ダウンロードする場合のことを 思い浮かべてください そして 新しいデータセットを 取り扱うときに 最初にすることが 「分析」です これは そこにどのような情報が あるのかを調べることです 例えば どのような値があるか? データの型は?データの表現方法は? 欠損値はあるか?といったことです データセットの内容を 正しく把握し 次のステップである 「操作」に移るためには こうした質問の答えを まず知る必要があります 「操作」とは 解決したい課題に 最も適した形式になるよう データセットを変換することです 例えば 日付を文字列ではなく date型で表現したいとか xとyの座標を組み合わせて point型にしたいといった 状況が考えられます TabularDataフレームワークは 大規模なデータセットを 扱うのに最適です 一般的なユースケースを挙げると まず ある基準に基づいてデータを グループ化するために使います 例えば 人々を 年齢別にグループ化したり 共通の値があるデータセットを 結合するといったケースです 例えば トランザクション の表に 購入者情報を 結合するといったことが 考えられます 次に データを分割して 段階的に処理したり データセット全体のサブセットに フィルタリングするためにも使います また 機械学習の特徴量 エンジニアリングを行う場合など データパイプラインの構築にも 活用できます フレームワークに関する文脈では 表のことをDataFrameと呼びます DataFrameは スプレッドシートのように 行と列で構成されています しかし スプレッドシートとは違い 列にはすべて 特定の型の 値しか入れることができません これは同時に 列には 独自のカスタム型を含め どのような型でも 入れられることを意味します 例えば 辞書 GPS座標 RAWオーディオサンプルなどです DataFrameやDataFrameの スライスを表す表を 表示する際は 必ず左側に インデックス列を作ります これは データインデックスで 行にアクセスする必要がある場合に 重要になります フィルタリングのように データが 変更されない操作もあれば ソートのように 結果としてできる データフレームのインデックスが 変わる操作もあります では 列について 詳しく考えてみましょう 先ほど述べたように 列はそれぞれ 特定の要素の型を持っています この場合はIntです また列は データフレーム内で 一意の名前を持つ必要があります 列は 配列と同様 コレクションである Column型で 表現されます 列は名前で参照する こともできますが ほとんどの場合 型も必要となります 列名と型を有する ColumnIDという構造体があり 特定の列を参照するために 使用することができます 可能な限り 列の参照には 文字列リテラルではなく 定義済みのColumnIDを 使うことをお勧めします また DataFrameの すべての列は 要素の数が 同じである必要があることにも 注意してください しかし 要素に欠損がある 可能性が常にあり それはnil値として表されます Column型と同様に Row型も存在します 行の各要素には 列名またはインデックスで アクセスできます Row型は プロキシであると 考えることができます 実際には行の要素は 含まれていませんが 代わりにDataFrame内の行を指す 参照として機能します では DataFrameは どのように作成するのでしょうか? 今からお見せします DataFrameは 辞書リテラルから 作成することも 一度に1列ずつ 作成することもできます これは 辞書リテラルから 作成した例です 辞書リテラルを使う際は 文字列 数値 ブール値 日付といった Swiftの 基本的な型を 使わなければならないことに 注意してください また すべての列の要素の数が 同じである必要もあります DataFrameを構築する より一般的な方法は 一度に1つずつ列を構築し それからDataFrameに 列を追加することです 例を挙げてみましょう まず 空のDataFrameを作成します それから 列を作成します そして その列を DataFrameに追加します すべての列にこのプロセスを 繰り返すことができますが 先ほど説明した通り すべての列が同じ数の 要素を有していることを確認し 列に一意の名前を 付けるようにしてください DataFrameとは何かが わかったところで データの分析をしてみましょう まず データセットの 読み込みを行います TabularDataはカンマ区切り値 CSV JSONファイルの 読み込みに対応しています ファイルのURLを指定して イニシャライザを呼び出すだけで すべてのデフォルトオプションを 使って読み込みが行われます ここでは CSVを読み込む際に利用できる オプションを紹介します CSVを使ったことがある方は ご存知かもしれませんが 常にカンマが使われているとは限りません 区切り文字が タブやセミコロンの場合もあります または 列名を記した ヘッダー行がある場合と ない場合があります また 文字列で特殊文字を エスケープする方法や 欠損値の表現方法にも バリエーションがあります TabularDataはすべての バリエーションを処理できます この例では ヘッダー行がないことを指定し カスタムのnilエンコーディングを使い 空の行を無視し セミコロンを区切り文字として使っています デフォルトだけでなく すべてのオプションを確認するには ドキュメントを参照してください ファイルのサイズが大きい場合は 一度に行のサブセットだけを 読み込むこともできます これには rowsのオプションを使います 例えば この例では 最初の100行だけが読み込まれます 同様に 列のサブセットを 選択することもできます これには columnsの引数を使います この方法を使えば 列を再編成することもできます
CSVファイルを読み込む際の 型推論の仕組みについて 簡単に説明します CSVファイルはすべて テキストベースですが すべての列をString型にするのは あまり便利ではありません そのため CSVファイルを読み込む際に TabularDataはまず値を数値 ブール値 日付に変換しようとし その後残りを文字列にします 値を特定の型に 強制的に変換したい場合や 読み込みを少しでも速くしたい場合は 列の型を明示的に指定することができます これを行うには typesの引数を使います この例では idという列にInteger型を そしてnameという列に String型を指定しています これにより 読み込み処理が 速くなるだけでなく 指定された型に変換できない値が あった場合には エラーがスローされるようになります こうすると 問題を早期に発見して 適切に対処することができ 想定外の型の列ができてしまって Appがクラッシュするのを 防ぐことができます 最後に 日付の解析について 触れておきます TabularDataは デフォルトで ISO8601形式の日付を 検出して解析します CSVファイルに別の形式の日付が 含まれている場合は カスタムの日付解析方法を 指定する必要があります これについては デモのときに Davidから説明と 例の紹介をしてもらいます では次に データの書き出しについて説明します 最も簡単な1つ目の方法は Swiftのprint関数です これを使うと ターミナルに 見やすい表が出力されます 出力された表には 行のインデックス 列名 列の型 データの最初の数行 そして行数と列数が含まれています また 画面にすべての行やすべての列が 収まらない場合 そのことも示されます この場合 非表示の列が さらに10個あります printは 分析やデバッグには最適ですが データの格納には 明らかに適していません DataFrameをCSVファイルとして 保存したい場合は writeCSVメソッドを使います 注意すべき点は writeCSVはすべての値を デフォルトで文字列に 変換するということです 列にカスタムの型を使用する場合は 生成されるCSVが 読み返せないものになる 可能性があるので注意が必要です CSVでは 列の一部を変換する 必要がある場合があるため 一般的なルールとして CSVに書き込む際は 列にSwiftの基本的な型のみを 使用してください writeCSVには 読み込みの場合と 同様のオプションがあり CSVデータの書き方を カスタマイズできます ここでは カスタムのnilエンコーディングと カスタムの区切り文字を使って ヘッダを無効にする例を紹介します 特定の行へのアクセスは 行の添え字を使うだけで実行できます これにより その行の特定の列に アクセスできます しかし 可能な場合は常に まず列にアクセスし それから行にアクセスしてください これが列へのアクセス方法です 名前で列にアクセスする場合は 添え字から列のラベルを 省略することができます また 行のサブセットに アクセスすることもできます その場合 DataFrameの スライスが得られます DataFrameのスライスは DataFrameとよく似ていて 基本的に元のDataFrameへの参照です ほとんどの状況では それが完全なDataFrameなのか スライスなのかを知る必要はありません そして最後に 列のサブセットを 選択することもできます これにより 選択された列のみを含む 新しいDataFrameが返されます また filterメソッドを使って 行のサブセットを 選択することもできます フィルタ操作の結果は 行の範囲の選択と同じように DataFrameのスライスになります しかし 行の範囲とは異なり フィルタは不連続な行を 返す可能性があります DataFrameのスライスの インデックスを扱う際は 注意が必要です 配列のスライスと同様に スライスのインデックスは 元の行のインデックスを反映します 具体的には 最初のインデックスが ゼロでなかったり 次のインデックスが 現在のインデックスに1を 加えたものでない場合があります 文字列のインデックスと同様 0ではなくstartIndexを countではなく endIndexを 1を加えるのではなく index(after:)を使います さて 基本的なことを 理解できたところで 実際にAppを構築して 実践してみましょう サンフランシスコで駐車場を 探すのは大変です Davidと私は 街中で 近くにある駐車場を 確認できるiPhone Appを 作りたいと考えています 市が公開している データを利用して 近くにある 現在駐車可能な パーキングメーターを 特定したいと思っています データセットがあることはわかっていますが どのようなデータが入っているかを 正確には知りません そのため 最初のステップは そのデータセットを分析して 内容を把握することになります では Davidと交代します David Findlay: ありがとう Alejandro こんにちは フレームワークエンジニアの Davidです このデモでは TabularDataを使って データセットを分析する方法の 例を紹介します まずは パーキングポリシーの CSVファイルを分析します 最初のステップは データの読み込みですが これはDataFrameのイニシャライザに ファイルのURLを渡すだけでかまいません このイニシャライザはスロー可能なので 解析エラーが起こった場合の 処理に便利です 次に 簡単なprintで 最初の数行と数列を調べます
読み込みに数秒かかりましたが これはDataFrameが 100万行以上 15列以上の データをメモリに読み込んだためです データセットを初めて分析するときは通常 データセットの全体は必要ないので 読み込むときに行の範囲を指定して 分析のスピードを 上げると良いでしょう
次に 列を見てみましょう 画面に収まりきらないため 2つの列が右に 隠れていることに 注目してください FormattingOptionsで これを修正する方法を紹介します
FormattingOptionsでは データの表示方法を 設定できます ここでは 出力結果の スクロールを防ぐために maximumLineWidthを250にし 列幅を15に 行数を5に減らします それから descriptionメソッドで print文に formattingOptionsを 追加します
できました これですべての列が確認できたので 役立つものだけいくつか選んで 残すことにします ここで 列を自分の好きな順番に並べて 整理してみるのも良いでしょう HourlyRate DayOfWeek 開始と終了の時間 StartDate PostIDを残します あとは DataFrameを読み込む際に これらの列をパラメータとして 追加するだけです
はい これでずっと楽に 分析できるようになりました StartDate列を見てみましょう これはString型です 自動的に検出されるのは ISO8601の 日付だけだからです それで 別の日付形式を 明示的に指定する必要があります これは 先ほどAlejandroが説明した CSVReadingOptions を使って解決できます Foundation Date Parsing APIを使って 日付の解析方法を追加してみます 形式は年 月 日 ロケールは米国英語 タイムゾーンはPST (太平洋標準時)にします そして DataFrameを 読み込むときに CSVReadingOptions を渡します
これで StartDate列が 適切な型になったので DataFrameを簡単に フィルタリングして 有効なパーキングポリシーのみを 取得することができます 現在の日付を表す変数から始め filterメソッドを使って DataFrameをフィルタリングします filterメソッドは 列名 (ここではStartDate)と 型(Date)を受け取ります クロージャでは オプショナルの dateをアンラップし 日付の値がnilの場合は falseを返すことで フィルタの結果に表示されないようにします そして最後に 現在の日付以前の 開始日を保持します では printを変更して フィルタリングした結果を お見せします
ここからはStartDate列は 必要ないので 先に削除しておきます しかし DataFrameの スライスから列を削除することは できないので 注意が必要です まずDataFrameに変換して filteredPoliciesを varにする必要があります 列の削除はmutating メソッドだからです これで removeColumnメソッドで 列を削除し StartDate列を削除の対象として 指定できました 以上で パーキングポリシーの データセットで必要な 分析が完了しました 次のセクションでは Alejandroが 表形式のデータを補強する 方法について説明します Alejandroに戻します Alejandro:ありがとう David ここまでで データセットの内容を よく理解することができました 次のステップは ニーズに 合わせてデータを変換したり 補強したりすることです 最も単純な種類の変換は 列内の値を 変更することです これは 各値を新しい値に おそらく別の型の値にマッピングする map操作の形で 行うことができます TabularDataでは mapのIn-place版である 便利なtransformColumn が利用できます この例では DayOfWeek列を 文字列から曜日を表す整数へと 変換しています このようなコードになります 要素ごとに Stringを Intに変換します
transformColumnと同様に decodeメソッドは データのデコードを行います CSVファイルを扱うとき CSVの中に配列や辞書が JSONの値として 埋め込まれている場合があります TabularDataには このための decodeメソッドがあります この例では 左のDataFrameに JSONデータのBLOBが 埋め込まれています decodeでは JSONDecoderを使って 列を独自の型に変換します この例では Preferencesです そして コードはこのようになります Preferences型は Decodableプロトコルに 準拠している必要があり 列にはJSONDecoderが 入力として想定する Data型の要素が 含まれている必要があることに 注意してください 別の便利な操作として filledメソッドがあります このメソッドでは 列のすべての 欠損値をデフォルトの値に 置き換えることができます そして 列操作の最後に summaryについて 触れたいと思います summaryでは 列の内容を簡単に 概観することができます summaryメソッドは カテゴリ別の概要を返します 説明文の中で someCountとして 要素の数が表示され noneCountとして 欠損している要素の数が 表示されています さらに 一意な要素の数と modeと呼ばれる 最頻値も示されています また 数値を含む列でのみ 利用可能な numericSummaryという メソッドもあります カウントだけでなく 平均値や標準偏差などの 統計情報も確認できます これは summaryを 出力した場合の結果ですが summaryの構造体を 直接使って統計情報に アクセスすることもできます 例えば スコアを 75パーセンタイルのものに フィルタリングしたい 場合などです さて 列の変換の話を たくさんしましたが 列の変換はそれほど 興味深い処理ではありません 本当に面白いのは DataFrameの変換です 列の変換とは異なり DataFrameの変換では 複数の列を一度に操作します 簡単な例として sortがあります ソートの仕組みはよく知られていますが わかりやすくなるように 説明したいと思います この表をスコアで ソートしてみましょう これはすべての列に影響します また ソートをすると 行のインデックスが変わります DataFrameの 別の興味深い変換方法は combineColumnsです combineColumnsメソッドでは 複数の列を1つに まとめることができます 例えば 緯度と経度の列が 別々にあり それらをCLLocation型に まとめたいとします これはそれを行う方法の一例です まず 結合したい列を指定します そして 新しい列に名前をつけます それから 入力元の列と 新しい列の型を 指定します その際 すべてをオプショナルにする 必要があることに注意してください そして 欠損値の処理と 新しい値の構築を行います 列と同様 DataFrameにも summaryメソッドがあります これは すべての列の 統計の概要を返すものです DataFrameが大きい場合 この方法は負荷が高くなるため 調べたい列のみを対象にして 概要を取得したほうが 良い場合があります 別の面白いメソッドは explodeです これは 要素の配列を含む列を受け取り 配列の各要素に対して 新しい行を作成するものです この例を見てください この例では Scoresの列に 各人のスコアの配列が 埋め込まれています DataFrameにexplodeの 操作を適用すると これらの要素がそれぞれ 新しい行になります 複数のスコアがある人は 名前が繰り返し出てきます この方法は フィルタリングなど 個々のスコアを見る必要がある 操作をする際に便利です こうしたツールを使って パーキングメーターのデータを 必要な形式に 変えることができます ここからはDavidが説明します David コードの説明をお願いします David:ありがとう Alejandro 皆さんはどうかわかりませんが 私の場合 駐車場に関して 最も重要な要素は その位置情報です 幸い 必要なデータを含む 別のCSVファイルがあります その中身をお見せしましょう 先ほどと同じように まず データの読み込みから始めます でも今回は 必要な列が すでにわかっています POST_ID STREET_NAME STREET_NUM LATITUDE LONGITUDEの列の結果を 先ほどのデモで使った formattingOptionsで 出力してみたいと思います 最初に行う補強は 緯度と経度の列を CoreLocation型の 新しい列にまとめることです combineColumnsメソッドは この処理に最適です ここでは 緯度と経度の列を 組み合わせて locationという名前の 新しい列にしています クロージャでは 緯度と経度の パラメータの型と CoreLocationの 戻り値の型を指定しています 次に オプショナルの緯度と 経度の値をアンラップして どちらかがnilの場合は nilを返します 最後に 緯度と経度の値を CoreLocationの イニシャライザに渡します DataFrameに 位置情報があれば Appの最初の機能を 作り始めることができます 場所に応じて 最も近い パーキングメーターを検索する機能です closestParkingという名前の 関数を書いて 検索結果に含める位置情報 DataFrame パーキングメーターの台数を 受け取るようにします まずローカルのコピーから始め 先ほどAlejandroが紹介した transformColumnメソッドを使って 位置情報を距離に変換します そしてもちろん location列の名前を distanceに変更します 最後に distance列を 昇順にソートして 返す場所の数を制限します 試しに サンフランシスコの Apple Storeで テストしてみましょう Appleマップで調べた座標と メーターのDataFrameを入力して 検索結果を5つの駐車場に 制限してみます できました!Post Streetの Apple Storeの近くには たくさんの駐車場があるようです このAppの最初の機能は 正しく機能していますが もし最も近い駐車場がすべて 埋まっていたらどうしますか? このAppに次に必要な機能は 駐車場の多い通りを探すことです しかし その機能を実装する前に グループ化という新しい概念を 紹介したいと思います グループ化とは グループ化の列を使って データをグループに分けることです 例えば STREET_NAMEという 列があるとしましょう groupedメソッドでは まず Post Street California Street Mission Streetといった 通りの名前の一意な値を識別し それから行を対応するグループに分けます 各グループはDataFrameのスライスです では コードに戻りましょう groupedメソッドを使って メーターを通りの名前で グループ化します そうすれば それぞれの通りにある パーキングメーターの数を数えて その結果を降順に並べて 出力することができます 最も駐車場の多い通りが 結果の一番上に表示されます これこそ 私が作りたいAppです かなり便利ですね! 2つの優れた機能ができました でも ちょっと待ってください たった今 1つ目の機能に バグがあることに気がつきました メーターのDataFrameだけで 最も近いメーターを探していましたが 本当に必要なのは 有効なパーキングポリシーがあり かつ最も近いパーキングメーターです これは面白くなってきました その情報は1つ目のデモで 使ったデータに入っていますよね では このバグを修正するために 2つの異なるソースからのデータを 結合する方法を説明します 関係データベースを使ったことがある方は 結合についてよくご存知かもしれません 関係データベースでは キーを使って2つのDataFrameを 結合することができます 両方のDataFrameに 現れる値がキーです メーターとポリシーの DataFrameでは パーキングメーターを 一意に識別するPOST_IDが キーとなります 結合操作の結果 メーターからのPOST_IDと ポリシーからのPOST_IDが 一致する行を持った DataFrameが得られます 行は 左のDataFrameと 右のDataFrameからの 一致するデータで構成されます 列名に leftまたはrightの プレフィックスが付いています これは その列が結合のどちら側から 来たかを示しています これにより 結合によって 名前の競合が発生するのを防止できます この操作は内部結合で それがデフォルトです 他にも 左外部結合 右外部結合 完全外部結合の 3種類の結合があります ここで詳しく説明することはしませんが 詳しく知りたい方は ドキュメントを参照してください さて 表形式のデータの補強についての説明は これで以上です 次のセクションでは Alejandroがベストプラクティス について説明します Alejandro:ありがとう David 必要な形式のデータが すべて揃ったところで いよいよAppの構築に入ります 分析用のコードを再利用しつつ 本番環境に 対応させる方法について 説明します 最初に紹介した CSVファイルの 読み込みに使うコードに 戻ってみましょう これを実行すると 列の種類が 不明になってしまいます これは フィルタや結合のように 事前に型を知る必要がある 操作では問題となります ユーザーが提供したソースから データを読み込む場合 型を仮定することには リスクがあります Appがクラッシュしてしまう 可能性があるからです 代わりに 次の例のように データを読み込む際に 想定する型を宣言してください ここでは 注意する列すべてに ColumnIDを定義しています そして CSVイニシャライザに 列の名前と型の両方を 提示しています 列を参照するすべてのメソッドで 文字列の代わりに ColumnIDを 使用できることを 覚えておいてください これで 無効な値があった場合には 例外が発生し ユーザーに エラーを表示するなどして 対処することができます そうすることで 列や 列の型が想定通りに 処理されるようになります これは カスタムの日付形式を 使う場合に特に重要です 列がDate型であることを 指定していないと 日付の解析に失敗し エラーも出ないまま 代わりに文字列の列が 生成されてしまう可能性があります 強制的に日付にすると 失敗したセルの内容を含む例外が スローされるようになるので 問題のデバッグに役立ちます エラーといえば CSVファイルを読み込む際に このようなエラーが発生するのを 想定しておく必要があります Failed to parseは カスタムの日付パーサーで セルの解析に失敗すると表示されます それ以外のエラーの意味は 読んで字のごとくですが 詳しくはドキュメントを 参照してください 最後に パフォーマンスについて 簡単に触れておきます ほとんどの場合 パフォーマンスを 気にする必要はありませんが 大規模なデータセットを扱う際には パフォーマンスに 大きな影響が及ぶケースも いくらかあります 1つ目は CSVを読み込む際の 日付の解析です 日付の解析には多くの 特殊なケースや考慮事項があり そのために時間が かかる傾向があります CSVファイルの読み込みに 数秒以上かかる場合は まず日付の解析を改善することを 検討してください 方法の1つは 解析を遅らせることです これは特に 日付の情報が すぐには必要でない場合に有効です 例えば フィルタリングやグループ化を 先に行いたい場合などです それができない場合は 日付の文字列の パフォーマンスを最適化するために 独自の日付パーサーを 作成することを検討してください グループ化では 必ずStringやIntなどの 基本的なSwift型を含む列を グループ列として 使用してください これにより グループ化の 処理速度が速くなります 複数の列でグループ化を行う場合は まず列を単純な型の 単一の列に結合してから グループ化することを検討してください 例えば 曜日とメーターの種類で グループ化する場合は この2つのプロパティを組み合わせて 文字列にすると良いでしょう 「曜日-種類」という風にです 同様に 結合する際にも Swiftの基本的な型を含む列で 結合するようにします これで Appを完成させる 準備が整いました David まとめをお願いします David:TabularDataの ベストプラクティスを使って Appの検索機能を書きます Parkingの構造体は メーターとポリシーを結合した DataFrameを格納します また 複数のメソッドで必要となるため 位置情報のColumnIDを 定義しました それでは loadMetersメソッドの 詳細を見てみましょう 一番上では メーターの読み込みに必要な ColumnIDを定義しています 次にメーターを読み込み 各列の想定される型を指定します これで 提供されたCSVファイルに 不一致があった場合には スローされます 次に resolved列が 想定通りかどうかを確認し そうでない場合は カスタムのParkingErrorを スローします 最後に combineColumnsの操作を リファクタリングして latitude longitude locationのColumnIDを使います これで Appの検索機能が 本番環境に対応したものになりました では Alejandroに TabularDataフレームワークの 要点をまとめてもらいましょう Alejandro:ありがとう David では要点のまとめを行います 今日は TabularDataを使って 未知のデータセットを分析し 操作し Appに取り込む方法を 紹介しました データセットを分析し 列やデータの変換方法を説明し 最後にエラー処理や パフォーマンスに関する ベストプラクティスを 紹介しました 皆さんがTabularDataを使って 優れたAppを作成されるのを 楽しみにしています ありがとうございました
-