-
MacBook ProでのMetal演算
最新のMacBook ProでMetal演算を活用する方法を確認します。高パフォーマンスなMetal演算における基本的な原則を学び、フレームワークを活用する方法を確認します。開発プロセスのワークフローを向上させ、クリエイティブなプロ向けのさらに優れたAppを構築する方法を紹介します。
リソース
関連ビデオ
WWDC22
-
このビデオを検索
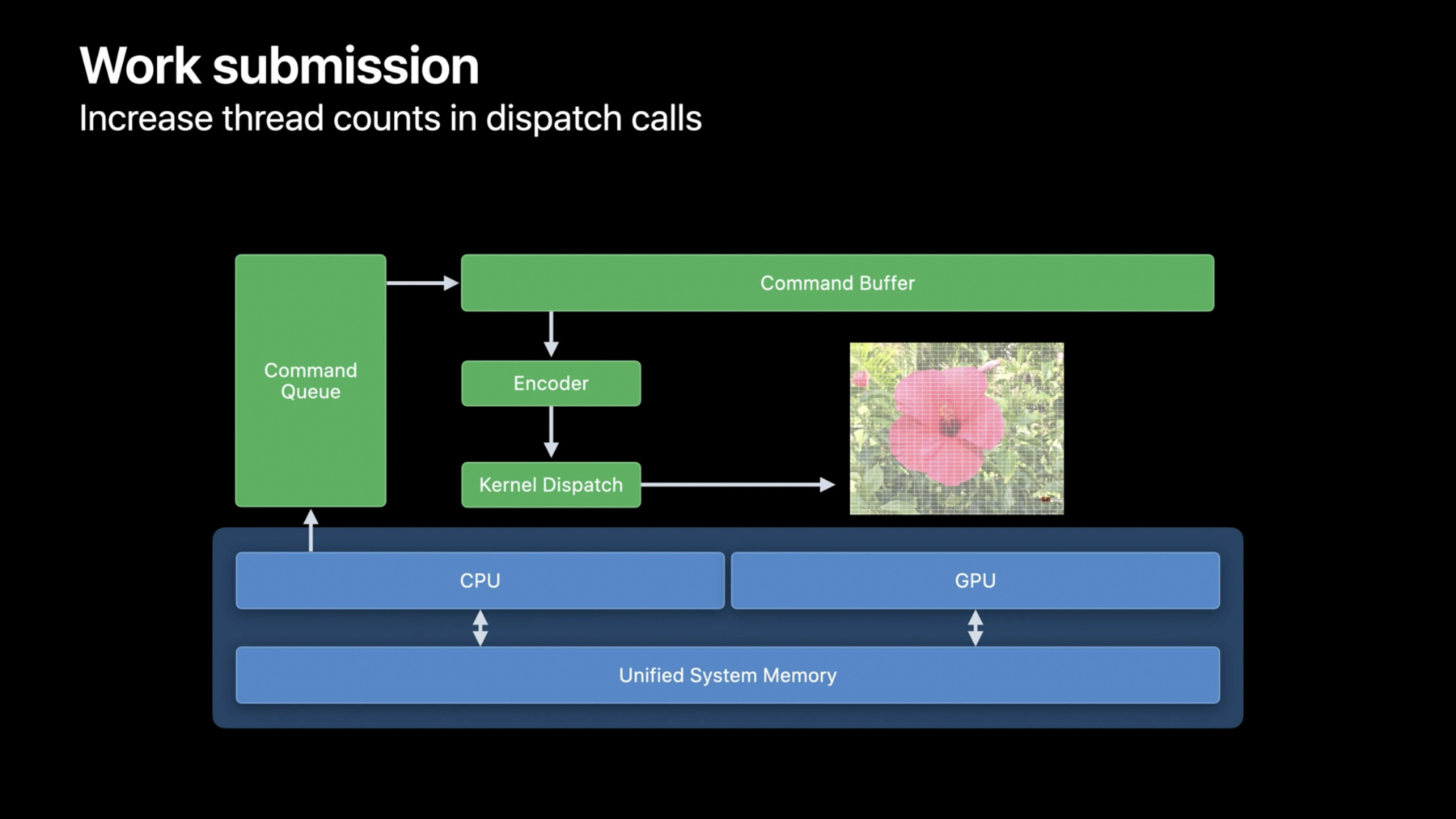
こんにちは Jason Fielderです AppleのGPU Software Engineering Teamのメンバーです これから 新しいM1 Pro またはM1 Maxを搭載した ノートブックの素晴らしい グラフィックス処理能力を 活用する方法や AppがGPUで 優れたパフォーマンスを発揮するための ベストプラクティスを紹介します 最新のMacBook Proには Apple史上最もパワフルな チップが搭載されています M1 Proは最大16コアのGPUを搭載し M1 Maxはその2倍で 32コアです これに加え より高いDRAMの 帯域幅を備えたことで MacBook Proのパフォーマンスが 大幅に向上しました ユニファイドメモリアーキテクチャにより GPUにシステムメモリを使用できるようになり 最大64GBのユニファイドメモリを 搭載しているので GPUのAppは かつてないほど多くのメモリに アクセスできるようになりました これらのMacBook Proは デベロッパやクリエイティブのプロに まったく新しい可能性をもたらし 以前はデスクトップコンピュータ のみを想定していたワークフローが 可能になります では このGPUの新しい可能性を 切り開くにはどうすればいいでしょうか まず GPUで作業をスケジュールできる Metal演算について振り返りたいと思います その後 APIとGPUの アーキテクチャを理解した上で Appの各段階におけるベストプラクティスを 見ていきます 最後に 適用できるカーネルの最適化を いくつか紹介します ではまず Metal演算の概要を説明します Metalは GPU処理のために Appleが用意した 最新の低オーバーヘッドAPIです 究極の薄さと効率性を実現し グラフィックスと演算インターフェイス が統合されています Metalはマルチスレッドに対応しており 複数のCPUスレッドから簡単に 作業をキューイングできるほか デベロッパはオフラインでもオンラインでも シェーダコンパイルのパイプライン を柔軟に使用できます 内部のハードウェア層では CPUとGPUが 同じ物理メモリに接続されています 統合されたメモリブロック内に CPUはGPUリソースを作成し GPUとCPUのどちらも そのリソースへの読み込みと 書き込みが可能です GPUで実行されたカーネルを表示するには APIのいくつかのレイヤーを 通過しなければなりません 最上層のレイヤーはコマンドキューです その名の通り GPU上のいくつかの ポイントで実行されるよう Appが作業をキューイングできる ようにするオブジェクトです コマンドはコマンドバッファ経由で CPU上にバッチ処理されます コマンドキューのオブジェクトは 一過性のもので Appに合わせて細かく多数設定します コマンドキューを設定するよう CPUとGPUの同期に関する 要件で定められていますが 要するに GPUが十分に稼働できる 作業量を確保するということです コマンドバッファに命令を格納するには コマンドエンコーダが必要です コマンドエンコーダには 作業内容に応じて 様々なタイプがあります 3D描画用のグラフィックスエンコーダや リソースをコピーするための blitエンコーダなどもありますが ここではカーネルディスパッチ用の 演算エンコーダに焦点を当てます 演算エンコーダを準備できたら カーネルディスパッチをエンコードします エンコーダは カーネル関数と連動して カーネルが必要とするリソースを どのように束ねるかを 設定します 実際 複数のカーネルディスパッチを 同じエンコーダに エンコードできます カーネルを変更したり 各ディスパッチ間でリソースを 束ねたりできます また ディスパッチを同時に実行するか またはシリアライズして 前のディスパッチが完了した後に 実行されるようにするかを Metalに指定できます エンコーディングが完了したら エンコーダを終了して コマンドバッファを使えるようにし 新しいエンコーダの エンコーディングを開始するか コマンドバッファをGPUにコミット して実行するかを選択します ここでは 合計3つの演算エンコーダを GPUにエンコードしています これが最初から最後までの一連の流れで GPUに実行を指示する準備が整いました コミットの呼び出しはすぐに返されて Metalは作業がスケジュールされ キューでその前にある作業が すべて完了したらGPUで 実行されるようにします CPUスレッドを利用できるようになったので 新しいコマンドバッファの構築を開始したり GPUがビジー状態の間に Appのその他の適切な タスクを実行したりできます ただし 一連の作業工程が完了したら CPUはその結果をリードバックするため 完了したことを通知される必要があります ですので コマンドバッファには 2つの手法が用意されています まず 作業をコミットする前に Appは完了ハンドラ関数を追加できます この関数は作業完了時に Metalによって呼び出されます 単純なケースでは 呼び出し元のCPUスレッドをブロックする waitUntilCompleteという 同期型メソッドもありますが ここでは非同期型メソッドを使用します これが基本的な実行モデルです APIの特徴として最後に挙げられるのは 複数のコマンドバッファを 同時にエンコードできることです 複数のCPUスレッドが 複数のコマンドバッファを同時にエンコードし エンコーディングが完了したら 作業をコミットできます エンコードする順序が重要な場合は enqueueを呼び出して 特定のコマンドバッファを実行する 領域をコマンドキューに確保するか 単純にコミットを任意の順序で 呼び出すことができます Appに合う方法を選んでください 複数のコマンドキューを 作成することも可能なので Metalでは柔軟に Appのニーズに 合わせて最も効率的なパターンで 作業をGPUにエンコードできます 以上 Metalの実行モデル について考えました それを踏まえて 実行モデルを最適化する方法を確認しましょう 例えば ユニファイドメモリアーキテクチャを 活用するための AppのGPUメモリへのアクセス方法や 先ほど説明した演算モデルに 合わせてGPUに作業を送信する方法 およびUMAに最適なリソースを選択し 割り当てる方法などについて 推奨事項をいくつかお伝えします まず取り上げたいのは 何と言っても ユニファイドメモリアーキテクチャです 一連のベストプラクティスは GPU上で必要な作業を 最小限に抑えるためのものです ユニファイドメモリアーキテクチャでは システムRAMとビデオRAM間で 従来行っていた コピーの管理が不要です Metalは GPUとCPUが 同じメモリに読み書きできる 共有リソースを通じてUMAを提供します それで CPUとGPU間のアクセスを 適切なタイミングで安全に 同期させることによって リソース管理します システムメモリとビデオメモリ間で データを複製したり シャドウイングしたりする必要はありません メモリにあるリソースの単一インスタンス から作業を行うことで Appに必要なメモリ帯域幅が著しく削減され パフォーマンスを大幅に 向上させることができます GPUが最初のバッチを実行している間に CPUが2番目のバッチ作業で バッファを更新する必要があるなど 競合が発生する可能性がある場合は 明示的なマルチバッファモデルが必要です ここでは CPUはバッファnに コンテンツを用意し GPUはバッファn-1から読み込み その後 次のバッチのためにnを インクリメントしています これにより Appのデベロッパは メモリのオーバーヘッドやアクセス パターンに合わせて調整し CPU/GPUの不要なストールや コピーを回避できます Appが割り当て可能な GPUリソース量の制限では 2つの値に注意する必要があります まず 割り当て可能な GPUリソースの総量です そしてより重要なのは 1つのコマンドエンコーダが 一度に参照できるメモリの量です これはワーキングセット制限 と呼ばれることもあり recommendedMaxWorking SetSizeを読み込むことで 実行時にMetalデバイス からフェッチされます Appでこの機能を活用して 参照可能および使用可能なメモリの量を 制御することをお勧めします 1つのコマンドエンコーダには このような ワーキングセット制限がありますが Metalはこの制限を超えて さらに リソースを割り当てることができます Metalでは リソースの常駐を管理し システムメモリの割り当てと同様 GPUの割り当ても実行前に 仮想的に割り当て 常駐させます 複数のコマンドエンコーダで リソースを分割して使用することで Appはワーキングセットサイズを超える リソースをフルに使用でき 厳しいVRAM制限による 従来の制約から解放されます 新しいMacBook Proの場合 GPUのワーキングセット サイズはこの表の通りです 現在 システムRAMが32GBの M1 ProまたはM1 Maxの場合 GPUは21GBのメモリにアクセスでき RAMが64GBのM1 Maxの場合 GPUは48GBのメモリにアクセスできます これは MacのGPUで利用可能な メモリ量としては圧倒的に多く 新しいMacBook Proのラインナップは ユーザーに大きな可能性を提供します デベロッパの皆さんがユーザーに どのようなApp体験を届けるのか また ユーザーはAppを どのように活用するのか 非常に楽しみです 以上が UMAを活用するため のベストプラクティスです 次のトピックに進みましょう コマンドバッファレベルでは 送信遅延が発生します 少量の作業では 作業する時間よりも 待つ時間の方が長くなってしまいます それで 呼び出しをコミットする前に より多くのエンコーダを各コマンド バッファにバッチ処理しましょう AppでGPUの結果が出るのに時間がかかって 次に実行するディスパッチを通知できない場合 GPUタイムラインに吹き出しが表示されます 吹き出しが表示されている場合 GPUは 次のディスパッチを待っている アイドル状態です 吹き出しが表示されないようにするには 複数の作業を実行する 複数のCPUスレッドを使って GPUをビジー状態に保ちましょう 方法としては 複数の コマンドバッファを作成するか 複数のコマンドキューを作成 するかのどちらかです カーネルディスパッチには 十分な数の作業スレッドがあり 各スレッドには起動時のオーバーヘッドを 正当化する十分な作業があるので GPUをビジー状態に保てます この画像処理では 各ピクセルが 単一のスレッドで処理されています できれば カーネルディスパッチの 総スレッド数を増やして GPUのすべての処理コアが 使用されるようにしましょう この例では 単一のカーネルディスパッチを 使用して画像全体を処理することで MetalとGPUが作業を 利用可能な すべての処理コアに最適な方法で 分配できるようになりました 最後に 小さなスレッド数の場合は デフォルトのシリアライズモデルではなく 並列ディスパッチモデルを使用してください M1では素晴らしい動作をするのに M1 ProやM1 Maxでは その能力を発揮できないAppが 多く見受けられます 紹介したテクニックを使って作業を 大量に送信すれば デベロッパは 簡単にAppをスケールアップし Appのポテンシャルを最大限に 発揮させることができます 次にお話ししたいのは L1キャッシュです AppleシリコンのGPUは テクスチャ 読み込みとバッファ読み込み用に 別々のL1キャッシュを搭載しています Metalはグラフィックスと演算が 統合されたAPIであるため テクスチャオブジェクトとサンプラ一式を Appで使用できます そのため Appのデータソースにバッファしか 使用していない場合は リソースの一部をテクスチャに移行することで パフォーマンス上のメリットが得られます これにより GPUの高性能なキャッシュを より有効に活用できて RAMからのトラフィックを減らし パフォーマンスを向上させることができます 実際に見てみましょう すべてのリソースを読み込むため GPUはRAMにアクセスしますが 同じローカルメモリ領域を使用する 今後のバッファの読み込みに備えて パフォーマンスを向上させる ためのキャッシュがあります ただし キャッシュのサイズは限られており すぐにいっぱいになってしまうため しばらく読み込まれていない 古いデータは破棄され 新しいデータが読み込まれます 仮にカーネルが小さなデータセットを 処理したとして 一度キャッシュが生成されると その後のすべての読み込みでは キャッシュヒットし ストールや 遅延なしに読み込めます システムメモリにロード中の ストールや遅延は発生しません キャッシュはシステムRAMよりも 帯域幅がはるかに高く 低遅延です 読み込みでキャッシュミスが発生すると データがRAMからフェッチされて キャッシュに格納される間 呼び出し元のスレッドは ストールします データの読み込みはオンチップ キャッシュの帯域幅ではなく システムメモリの帯域幅によって 制限されます カーネルがバッファからの 大量のデータにアクセスすると このようにキャッシュを スラッシングしてしまい パフォーマンスの低下につながります AppleシリコンのGPUには バッファキャッシュに加えて テクスチャ読み込み専用の 第2のキャッシュがあります Appはソースデータの一部を Metalのバッファオブジェクトから テクスチャオブジェクトに移行することで キャッシュスペースを効果的に増やし パフォーマンスを向上させることができます テクスチャデータを操作することも可能であり Metalによってアップロード時に 自動的に行われます テクスチャデータを操作するとは テクセルを ランダムアクセスパターンに最適な順序で 配置することで キャッシュ効率をさらに向上 させることができるため 通常のバッファよりもパフォーマンス上の メリットが得られます また この操作は読み込み時に カーネルに対して透過的なので カーネルソースが複雑になることはありません 実は テクスチャのメリットはまだあります Appleシリコンでは テクスチャの作成後および可能な場合は常に テクスチャをロスレス圧縮できます ロスレス圧縮することで 読み出し時のメモリ帯域幅をさらに削減し パフォーマンスを向上させることができます ロスレス圧縮したテクスチャは 読み込みやサンプル処理の際に 自動的に解凍されるため これもシェーダカーネルに対して透過的です GPUに対してプライベートな Metalテクスチャは デフォルトで圧縮されますが 共有および管理されたテクスチャは アップロード後にblitコマンドエンコーダで optimizeContentsFor GPUAccessを呼び出して 明示的に圧縮します テクスチャのロスレス圧縮を使用するには テクスチャの用途を shaderRead またはrenderTargetに 設定する必要があります テクスチャオブジェクトを作成する際は 記述子でそのように設定され ていることを確認してください また テクスチャデータが 実際の画像データであったり ロッシー圧縮が許容される 用途であったりする場合は ASTCやBCといった より圧縮率が高い ロッシー圧縮形式を検討してください そうすれば メモリフットプリントと 帯域幅使用量の両方を さらに削減でき カーネルのパフォーマンスが向上します BCとASTCはどちらも オフラインツールで生成でき 画質が良く 圧縮率も4:1から 36:1まであります さて 作業は最適にバッチ処理されました データ入力にはバッファとテクスチャを使用し UMAを意識して コピー作業の量を減らすこともできたので 今度はカーネルの最適化について考えましょう 紹介するベストプラクティスはすべて カーネルのパフォーマンス向上を 目的としています 具体的にいくつか見てみましょう これから カーネルの活用で 改善の余地がある領域として メモリインデックスの作成 グローバルアトミック および 占有率に焦点を当てます また カーネルのボトルネックを特定するために プロファイリングツールで確認すべき箇所や 最適化の効果を 評価する方法についても説明します 昨年のWWDCでは Appleの GPU Software Teamが Appleシリコン向けにMetalを 最適化する手法を紹介した ビデオを公開しました ここでは その手法に簡単に触れますが 詳しい内容や事例については そのセッションを視聴してください まず メモリインデックスの 作成についてお話します 配列にインデックスを作成する際は 符号なし整数型よりも 符号付き整数型を使用してください ここにforループ構文があります カウント変数は符号なしと宣言されたiです シェーダ言語仕様における uintのラッピング特性により このままではベクトル化された ロードが無効になります 通常 それは望ましくありません 符号付き整数型を使用することで 追加のコードが生成されるのを 回避できます また この構文ではintのラッピング 動作が未定義であるため ロードはベクトル化され パフォーマンスが向上すると思われます 搭載されているGPUコアと メモリ帯域幅が増加したことで 新しいMacBook Proでは 一部のGPUワークロードの 主要なボトルネックが ALUやメモリ帯域幅の使用から その他の領域に変わってきています そうした領域の1つがグローバルアトミックです それで カーネルでの アトミック操作の使用は最小限にするか 代わりにスレッドグループのアトミックを 使った手法を用いることをお勧めします 大抵の最適化ワークフローで指示されるように まずシェーダをプロファイリングして この問題が発生している かどうかを確認してください アトミックの多少の使用は問題ありません では この重要なプロファイリング情報を どのように入手すればよいでしょうか Xcode内のGPU Frame Debuggerを使用します この評価作業には最適なツールだと思います GPUで実行されている作業についての 豊富な情報が得られますし 取得したキャプチャを 閲覧することもできます Debuggerのタイムラインビューでは ワークロードの概要を把握でき GPUの主要なパフォーマンスカウンタを 視覚化したグラフが表示されます これらのカウンタの多くでは 使用率と制限値の 両方が表示されます このALUの例では 使用率の数値から カーネル実行中に GPUのALU性能の 約27%が使用されたことがわかります それ以外の時間は データの読み書きや 制御ロジックの決定など 様々な作業を行っていました 制限値からは ALUの使用率が カーネル実行時間の約31%を占めることから GPUのボトルネックになって いることがわかります GPUのALU性能の27%を 使用しているにもかかわらず 31%でALUがボトルネックに なっているのはなぜでしょうか 制限値は 実行されたALU作業の 効率化と考えることができます 制限値は作業にかかった 実際の実行時間と 内部のストールや非効率な作業 に費やした時間によって決まります ベストケースでは これらの 時間は等しいのですが 実際には差異があります 差異が大きければ GPUは 割り当てられた作業を 何らかの理由で実行できていないことになります 例えば log()などの複雑なALU演算や 高価なテクスチャフォーマットの使用が 使用率の低下を招いて カーネルの演算を最適化する余地があると わかるかもしれません この2つの数値は カーネルが実行している作業の 一般的な構成を確認し 各カテゴリの作業がどの程度 効率的に実行されているかを 理解するのに役立ちます このカーネルでは 占有率が37%になっています この値はまだ低いので この占有率を高める余地はないか 調査する価値があります 占有率について詳しく見てみましょう 占有率は GPU上で現在 アクティブになっているスレッド数の 最大値に対する割合を示す指標です この数値が低い場合は その原因を究明し それが想定どおりの状況なのか それとも問題があるのかを 判断することが重要です 例えば 実行する作業が単純に小さくて 送信した作業のスレッド数が比較的少なければ GPU占有率が低いのは当然のことですし 避けられないことです また GPUがALUなどのほかのカウンタ によって制限されている場合も あるかもしれません とはいえ 占有率が低く カウンタの制限値が小さい場合 それはより多くのスレッドを 同時に実行する処理能力が GPUにあることを意味します 問題となる事象で占有率の低下を 招いているものは何でしょうか 一般的な原因の1つは スレッド またはスレッドグループのメモリを 使い果たしてしまうことです どちらもGPU上で有限のリソースであり 実行中のスレッド間で共有されています スレッドメモリはレジスタ によって支えられており レジスタプレッシャーが高まると それに合わせて占有率が 低下することがあります スレッドグループのメモリ使用量が多い場合 占有率を高めるには 使用した共有メモリの量を減らすしかありません スレッドグループのメモリを減らすと スレッドレジスタの負荷による影響を 減らすこともできます パイプラインの状態作成時に スレッドグループの最大スレッド数が わかっていれば コンパイラはより効率的に レジスタをスピルできます こうした最適化を有効にするには 演算パイプラインの状態記述子に maxThreadsPer Threadgroupを設定するか Metalのシェーダ言語である max_total_threads_per threadgroup属性を カーネルソースで直接使用します この値を調整しながら お使いのカーネルに最適な バランスを見つけてください 数値は お使いのアルゴリズムに適した スレッド実行幅の最小の倍数になるようにします レジスタプレッシャーについて もう少し詳しく説明します レジスタプレッシャーが高いと XcodeのGPUプロファイラに レジスタスピルが発生します このカーネルは占有率が16%で 非常に低い数値です このカーネルのコンパイラ統計を見ると スピルされたバイトを含め 相対的な命令コストがわかります このスピルと一時レジスタが 占有率の低下を招いていると思われます スレッドのメモリは使い果たし 今後実行するスレッドに備えて より多くのレジスタを解放するために 占有率が低下しました レジスタはレジスタブロックのカーネルに 割り当てられるため 占有率を高めるには ブロックサイズ分まで 使用量を減らす必要があります 複雑なカーネルのパフォーマンスを 劇的に向上させる優れた方法は レジスタの使用量を最小限に 抑えるように最適化することですが どのようにすればよいのでしょうか 32ビットタイプよりも 16ビットタイプを優先すると カーネルのほかの部分で使用できる レジスタの数が増えます これらのタイプから32ビット 対応のタイプへの変換は 通常は自由に行えます 加えて スタックに格納されている データを削減できます 例えば 大きな配列や構造体は 大量のレジスタを消費することがあり それらを削減するのは有効な手段です 一定のアドレス空間を 最大限に活用できる設定になるよう シェーダ入力を調整してみてください これにより 不必要に使用される 汎用レジスタの数を大幅に 減らすことができます 最後のヒントは スタックに 格納されている配列や 定数データに 動的インデックスを 作成しないことです これは 実行時に 配列を初期化する例です このように コンパイル時に コンパイラでインデックスが不明な場合 配列がメモリにスピルされて しまうことがあります しかし2つ目の例では コンパイル時にインデックスを認識しているので コンパイラがループをアンロールして スピルされたものを最適化できるでしょう 紹介した手法はどれも レジスタの割り当てやスピルを減らし パフォーマンスがより高いカーネルの 占有率を高めるのに役立ちます Appleシリコン向けにMetalを 最適化する手法について 詳しくは WWDC20の 「Metal Performanceを Apple Silicon Macに 最適化する」を参照してください そこで詳しく説明されています さて これまでの内容を振り返ってみましょう まず コマンドキューやコマンドバッファ およびコマンドエンコーダの 役割を確認しながら 作業の送信モデルやMetalで GPUに作業をキューイングする 方法を振り返りました さらに 複数のスレッドから Metalのコマンドをエンコードして CPUのエンコード時間とコストを削減 する方法について紹介しました それを踏まえて Appを調整する方法に関する 推奨事項をお伝えしました 例えば ユニファイドメモリアーキテクチャ を活用するために 不要なコピーを回避すること 作業は大量に送信すること カーネルのリソースには Metalのテクスチャとバッファを 使用することです 最後に パフォーマンスのボトルネックを 特定するためのツールの使い方を 紹介しました GPUの使用率や制限値の解釈方法 そして占有率が低いという問題に 対処する方法を説明しました ご視聴ありがとうございました Apple史上最もパワフルな MacBook Proのラインナップには 大きな可能性が秘められています ぜひご期待ください
-