-
Appleシリコンゲーム向けのCPUジョブスケジューリングの調整
グラフィックスを駆使したゲームはハードウェアリソースに大きな負荷がかかり、各フレームの処理に何百、何千というCPUジョブが発生することがあります。CPUのジョブを整理して、CPUの効率性と、M1、M1 Pro、M1 Maxの各チップでのパフォーマンスを最大限に高める方法を確認します。さらに優れたゲーム体験をプレイヤーに提供するために、ゲームを調整し改善する方法を紹介します。
リソース
-
このビデオを検索
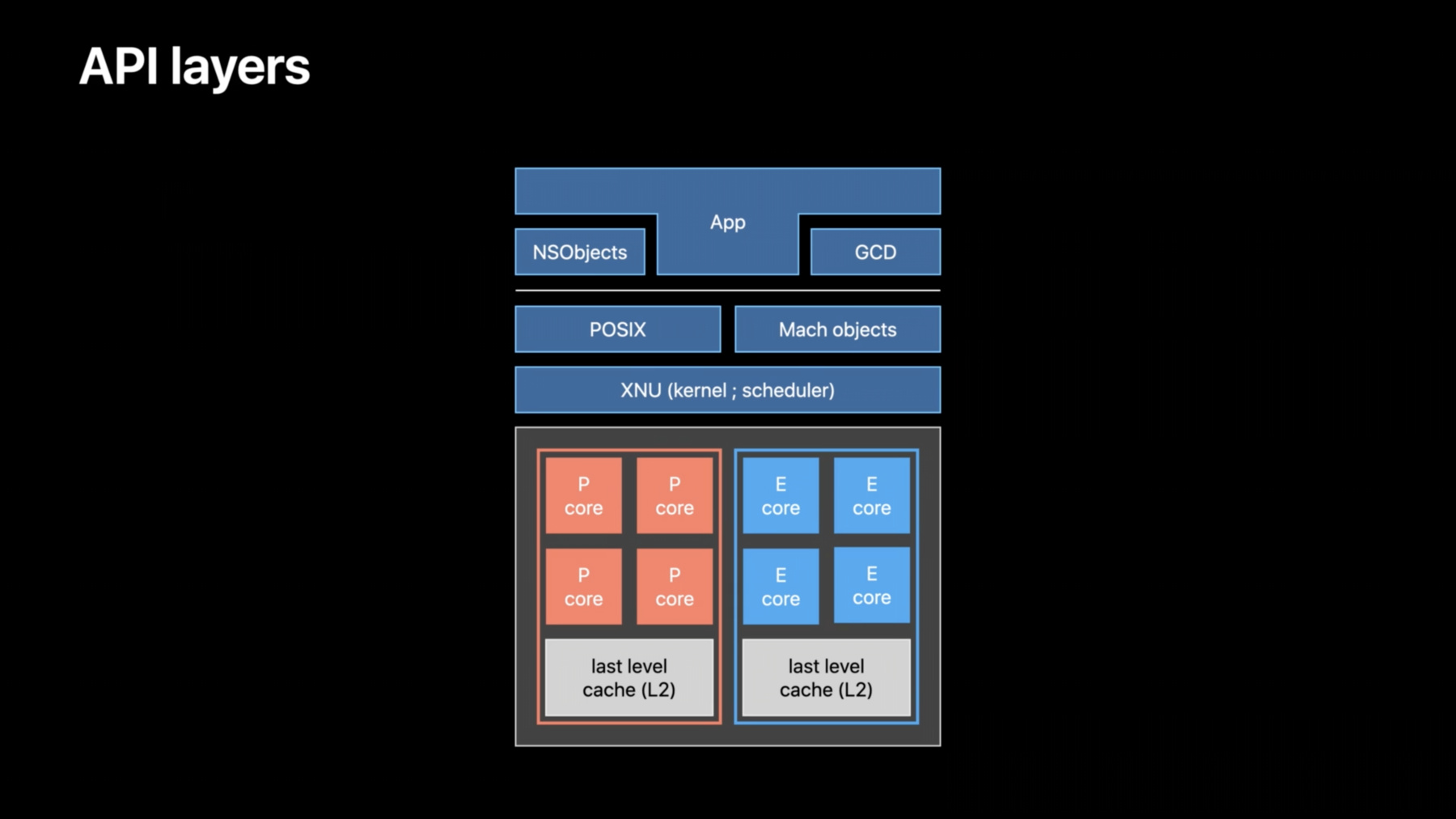
このセッションでは Appleシリコンゲーム向けの CPUジョブスケジューリングの 調整方法について説明します Metal Ecosystemチームの Pierre Morfです 私はこれまで Appleプラットフォームでの GPUとCPUのワークロード最適化について 複数のサードパーティデベロッパを サポートしてきました 今回 CoreOSチームの協力を得て ゲームにおけるCPUのパフォーマンスと 効率性を向上させるための 情報とガイドラインを まとめましたので ここで紹介します このセッションでは ゲームに焦点を当てます 多くの場合 ゲームでは ハードウェアリソースという面で 高い負荷がかかります また 一般的なワークロードでは フレームごとに何百 または何千ものCPUジョブを 処理することが求められます これらを16ミリ秒以下で行うためには CPUのスループットが最大になるように ジョブを調整し ジョブ投入時のオーバーヘッドを 最小に抑える必要があります まず AppleシリコンのCPUの概要と 独自のアーキテクチャについて説明します 次に CPUの効率を 最大限に高めるために 作業を整理する方法について 基礎的なガイダンスを説明します 最後に そのガイダンスを 適用した後に活用できる 便利なAPIについて説明します まず Apple CPUのアーキテクチャから 始めましょう Appleは10年以上 独自のチップの開発に 取り組んできました それらのチップは Appleデバイスの 核となるものです Appleシリコンは 高いパフォーマンスと かつてない効率性を実現します Appleは昨年 M1チップを発表しました このチップは Macコンピュータに搭載された 初めてのAppleシリコンチップでした そして今年 M1 ProとM1 Maxが発表されました この新しい設計は Appleシリコンにとって 大きな飛躍であり 非常に高負荷なワークロードも 効率的に処理できるようになりました M1チップには 多数のコンポーネントが 搭載されています
CPU GPU Neural Engineなどです また 広帯域で低遅延の ユニファイドメモリを搭載しており Apple Fabricを介して チップ内のすべてのコンポーネントに アクセスできます つまり CPUとGPUが 同じデータをコピーせずに 処理できるということです CPUを詳しく見ていきましょう M1には CPUに2つの種類のコアが 搭載されています PerformanceコアとEfficiencyコアです これらは物理的に別個のコアで Eコアの方が小さいです Efficiencyコアは 非常に低いエネルギー消費で タスクを処理することを 目的としています これは非常に重要な点ですが PコアとEコアでは同じような マイクロアーキテクチャが採用されており 内部の動作を制御しています つまりデベロッパは スレッドが PコアとEコアのどちらで 実行されるかを気にする必要は ありません どちらかのコアで動作するように 最適化されたプログラムは もう一方のコアでも問題なく 動作することを期待できます これらのコアは 物理的に種類ごとに クラスタにまとめられて 配置されています M1では 各クラスタに最終レベルの キャッシュであるL2があり すべてのコアで共有されています クラスタ間の通信は Apple Fabricを経由します ここで紹介しているCPUトポロジーは M1チップに特有のものです その他のデバイスでは CPUの配列が異なる場合があります 例えば iPhone XSの場合 2つのPコアを持つクラスタが1つ 4つのEコアを持つクラスタが1つ 搭載されています このアーキテクチャにより システムは必要に応じて パフォーマンスを最適化したり パフォーマンスが優先事項でない場合には 代わりに効率性を最適化して バッテリー駆動時間を 延ばすことができます 各クラスタは 現在のワークロードや そのクラスタの熱圧力 その他の要素に応じて 独立して起動したり カーネルのスケジューラによって 周波数が調整されたりします 最後に Pコアを常に利用できるとは 限らないことに注意してください 重大な発熱シナリオが発生した場合 システムはPコアの利用を 中断することがあります これは CPUと連動する 異なるAPIレイヤを 表した図です まず XNUですが これはmacOSとiOSを実行するカーネルです ここには CPU上で 何をいつ実行するかを 決定するスケジューラがあります その上には 2つのライブラリがあります Pthreadを処理するPOSIXと Machオブジェクトです どちらも 基本的なスレッド処理と 同期プリミティブをAppに提供します その上に 上位のライブラリがあります スレッド処理関連のNSObjectが POSIXハンドルをカプセル化します 例えば NSLockは pthread_mutex_lockをカプセル化し NSThreadはPthreadを カプセル化します ここにはGCDもあります GCDは高度なジョブマネージャです これについては 後ほど説明します このセッションでは 下位のレベルから始め APIの機能まで説明していきます まずは CPUにとって最適な事項と スケジューラにかかるワークロードを 軽減する方法について説明します これが 基本的な 効率性ガイドラインとなります このガイドラインは APIに依存せず あらゆるジョブマネージャの 実装に適用できるほか Appleシリコン搭載のMac およびIntelベースのMacを含む 様々なプラットフォームにも適用できます ここで 理想的な環境で このジョブを処理するところを 想像してみましょう このジョブを4つのコアに 分散させるとすると ちょうど4倍速く 処理されるはずですよね しかし 現実のCPUでは そう簡単にはいきません 実際には 事務的な作業が実行されており それぞれに実行時間というコストが かかっています 効率性という観点で 3つのコストが存在します Core 1 2 3を見てください これらのコアは ジョブを処理する前 何もしていませんでした CPUコアは 長時間何もすることがないと エネルギーを節約するために アイドル状態になります アイドル状態のコアを再起動するには 少し時間がかかります これが最初のコストである コアの再起動にかかるコストです 次のコストです CPUの作業は まずOSスケジューラによって 開始されます スケジューラは 次にどの処理やスレッドが どのコアで実行されるかを 決定します それによって CPUコアが切り替わります これは スケジューリングコストと呼ばれます さて 最後の 3つ目のコストです Core 0で処理されているスレッドが Core 1 2 3で処理されているスレッドに シグナルを送っていると想定します 例えば セマフォの場合です このシグナルの送信には 若干の時間がかかります この間に カーネルは どのスレッドがプリミティブ上で 待機しているかを特定する必要があり スレッドがアクティブでなかった場合は スケジュールする必要があります この遅延は 同期遅延と呼ばれます これらのコストは ほとんどのCPUアーキテクチャで 様々な形で発生します これらにかかる時間は ごくわずかなので これらのコスト自体は問題ではありませんが これらが蓄積されたり 繰り返し または頻繁に 発生したりすると パフォーマンスに影響を 与えることがあります では これらのコストを 実例を通して見てみましょう これは M1で実行されているゲームの Instrumentsトレースです このゲームでは 問題のあるパターンが ほとんどのフレームで 繰り返し発生しています 非常に細かい粒度で ジョブを並列処理しようとしています これはタイムラインを 大きく拡大したものです ちなみに この部分は18マイクロ秒しか かかりません このCPUコアと これらの2つのスレッドに注目しましょう これらの2つのスレッドは 並列して実行できたはずですが 同じコア上で 直列に実行されてしまいました その理由を見てみましょう これらのスレッドは 非常に高い頻度で 同期しています 1番目のスレッドは 2番目のスレッドに 処理を開始するようシグナルを送った後 2番目のスレッドの処理が終わるまで ごく短い間待機します 2番目のスレッドも 処理を開始した後 1番目のスレッドにシグナルを送り ごく短い間待機します このパターンが 何度も繰り返されます ここには2つの問題があります 1つ目の問題は 同期プリミティブが 非常に高い頻度で 使用されていることです これにより 処理が中断され オーバーヘッドが発生します 赤い部分で示されているのが オーバーヘッドです 2つ目の問題は 青い部分で示されている実行中の処理が 極端に短いことです 4〜20マイクロ秒しか 継続していません これは非常に短い間隔で CPUコアの起動に かかる時間よりも短いくらいです これらの赤い部分では OSスケジューラはほとんど CPUコアが起動するのを 待機していました しかし その直前に スレッドがブロックして コアを解放しています その後 2番目のスレッドが 1番目のコアが起動するのを待たずに 同じコア上で 実行されています これにより 2つのスレッドが 並列実行される機会が 失われています この観察結果から 2つのガイドラインを 定義することができます まず 適切なジョブの粒度を選択する必要が あるということです これには 小さなジョブを大きなジョブに 統合する必要があります スレッドのスケジューリングには どうしても時間が少しかかります ジョブが小さくなると スケジューリングコストの スレッドのタイムラインに占める割合が 相対的に大きくなります CPUが十分に活用されなくなってしまいます 一方 大きなジョブは 実行時間が長いため スケジューリングコストを 償却することができます 例えば あるプロ向けAppでは 多数の30マイクロ秒の ジョブアイテムを 統合することにより パフォーマンスを劇的に 向上することができました 2つ目は スレッドを活用する前に 十分なジョブを用意しておくということです 毎フレームで ほとんどのジョブを 一度に処理できるように用意しておきます シグナルを送り スレッドを待機するということは 一部のジョブはCPUコア上で スケジューリングされ 一部のジョブはブロックされて コアから離れてしまうことを 通常意味します これが繰り返されると パフォーマンスに影響します スレッドの起動と一時停止が 繰り返されると 先ほど話したようなコストが さらにかさみます 逆に スレッド内でより多くのジョブが 途切れることなく処理されるようにすると 同期ポイントを除去することができます 例えば ネストしたforループを扱う場合 外側のforをより粗い粒度で 並列処理する方が はるかによいでしょう これにより 内側のループが 途切れることなく処理されます これにより 一貫性が向上し キャッシュの使用率が高まり 全体的に同期ポイントを 削減することができます より多くのスレッドを活用する前に それがコストに見合うかどうかを 判断してください では 別のゲームのトレースを 見てみましょう これは iPhone XSで 実行しているものです これらのヘルパースレッドに 注目してみましょう この部分で同期遅延が 発生していることが分かります これは カーネルが これらの異なるヘルパーに シグナルを送るのにかかった時間です ここでは2つの問題があります 1つ目は 実際の処理が 特に全体のオーバーヘッドと比較して およそ11マイクロ秒と 今回も非常に短いということです これらのジョブを統合すれば よりエネルギー効率が良くなります 2つ目の問題は その間に 3つのコアで80の異なるスレッドが スケジューリングされていたことです ここでは コンテキスト切り替えと呼ばれる ジョブの合間のわずかな 間隔を見ることができます この例ではまだ問題ありませんが スレッド数が増えると コンテキスト切り替えの時間が蓄積し CPUのパフォーマンスに 支障をきたす可能性があります 一般的なゲームでは フレームごとに 少なくとも数百のジョブが発生しますが このような様々な種類のオーバーヘッドを 最小限に抑えるにはどうしたらよいでしょうか? 最善の方法は ジョブプールを活用することです ワーカスレッドは ジョブプールから ジョブを取得します スレッドのスケジューリングは カーネルが行いますが これには時間がかかります また CPUもコンテキスト切り替えなどの 作業をしなければなりません 一方 ユーザースペースで 新しいジョブを開始する場合 コストを大幅に抑えられます 通常 ワーカは アトミックカウンタをデクリメントし ジョブへのポインタを取得するだけです 2つ目に あらかじめ決められたスレッドとの やり取りを避けることです ワーカを使用することで コンテキスト切り替えの回数を削減でき ワーカがジョブをさらに取得することで すでにアクティブなスレッドを すでにアクティブなコアで 活用することになります 最後に プールを賢く利用しましょう キューに入っているジョブに必要なだけの ワーカを起動してください 前述のルールがここでも適用されます ワーカスレッドを起動するのに 値するだけの十分なジョブを用意しておき 忙しくさせておきましょう ここまでで オーバーヘッドを減らしました 今度は CPUサイクルを 最大限に活用できるようにしましょう ここでは 避けるべきパターンを紹介します 1つ目は 待機時間を避けることです 待機時間が多いと Pコアを有効に活用できずに ロックしてしまう可能性があります また スケジューラが スレッドをEコアからPコアに 昇格させることもできません エネルギーを浪費したり 不必要な熱を発生させたりして 熱ヘッドルームを 消費することにもつながります 2つ目の点として yield関数の定義は プラットフォームやOSによって 異なるという点です Appleのプラットフォームでは 「現在使用中のコアを 優先順位に かかわりなく システム上の別のスレッドや その他のものに譲る」 という意味になります これにより 現在のスレッドの優先度が 実質的にゼロになります また yieldには システムで定義された期間があります 最大で10ミリ秒という 非常に長い時間になります 3つ目の点として スリープの呼び出しは 避けた方がよいでしょう 特定のイベントを待つ方が はるかに効率的です また Appleのプラットフォームでは sleep(0)には意味がなく その呼び出しは破棄されます このようなパターンは そもそも根本的な スケジューリングエラーが 発生していることを示しています その代わりに セマフォや条件付き変数で 明示的なシグナルを待ちましょう 最後のガイドラインは CPUコア数に合わせて スレッド数を調整することです 使用しているフレームワークや ミドルウェアごとに新しいスレッドプールを 再作成することは避けてください また ワークロードに応じて スレッドを調整することも避けてください ワークロードが大幅に増えると スレッド数も大幅に増えてしまいます その代わりに CPU情報を照会して スレッドプールのサイズを適切に決定し 現在のシステムで並列処理を 最大限に活用できるようにします この情報を照会する方法を 見てみましょう macOS MontereyとiOS 15からは sysctlインターフェイスを使って CPUレイアウトの詳細を 照会できるようになりました すべてのCPUコアの 全体的なカウントに加え マシンが何種類のコアを搭載しているかを nperflevelsで 照会できるようになりました M1では PコアとEコアの 2種類のコアがあります この範囲を使用して コアの種類ごとにデータを照会します 0が最も性能が高いことを示します 例えば perflevel{N}.logicalcpuでは 現在のCPUがいくつのPコアを 持っているかを確認できます これはあくまでも概要です 同じL2をいくつのコアが 共有しているかなど 様々な詳細情報を 照会することができます 詳しくは sysctl manのページや ドキュメントのWebページを 参照してください CPU使用率をプロファイリングする際 2つのInstrumentsトラックが 非常に便利です これは Game Performance テンプレートで利用できます 1つ目のSystem Loadでは CPUコアあたりのアクティブな スレッドの数を確認できます 2つ目は Thread State Traceです デフォルトでは 詳細パネルには プロセスごとの スレッドの状態変化の量と その持続時間が表示されます これはContext Switchesビューに 変更することができます このビューでは 選択範囲における プロセスごとのコンテキスト切り替えの回数を 確認できます コンテキスト切り替えの回数は Appのスケジューリング効率を 測定するのに役立つ指標です このセクションをまとめしょう これらのガイドラインに従うことで CPUを最大限に活用し スケジューラの仕事を 効率化することができます 小さなジョブを 長いジョブにまとめることで キャッシュ プリフェッチ プレディクタといった マイクロアーキテクチャ機能の メリットが大きくなります より多くのジョブを一度に処理することで 割り込み遅延やコンテキスト切り替えを 削減できます 適切なサイズのスレッドプールを 用意することで スケジューラがEコアとPコアの間で ジョブのバランスを取りやすくなります 効率性とパフォーマンスを高めるための 重要なポイントは ワークロードが増減する頻度を いかに最小限に抑えるか ということです それでは このガイドラインを適用しながら どのAPIブロックを活用できるかを説明します このセクションでは 優先順位付けとスケジューリングポリシー 同期プリミティブ マルチスレッド時の メモリに関する考慮事項について説明します その前に まずはGCDについて 考えてみましょう ジョブマネージャを 持っていない場合や 目標にしている高パフォーマンスを 達成できていない場合は GCDが非常に役立ちます GCDは ジョブスティーリングを利用した 汎用的なジョブマネージャです Appleのすべてのプラットフォームと Linuxで利用でき オープンソースです このAPIは高度に最適化されています まず GCDは すべてのベストプラクティスに 従って設計されています さらに XNUカーネルに統合されています つまり GCDは 現在のマシンの 放熱能力や PコアとEコアの比率 現在の熱圧などの内部情報を 把握できます GCDのインターフェイスは 直列および並行の ディスパッチキューに依存しています その中に 様々な優先順位で ジョブをエンキューすることができます 内部的に 各ディスパッチキューは プライベートなスレッドプールから 異なるスレッド数を 活用することができます そのスレッド数は キューの種類や ジョブのプロパティによって異なります この内部スレッドプールは プロセス全体で共有されます つまり どのようなプロセスでも 新しいプールを再作成することなく 複数のライブラリがGCDを使用できます GCDには多くの機能があります ここでは その仕組みを 理解するために 並行ディスパッチキューから 2つの関数だけを簡単に紹介します まず dispatch_asyncです これは 関数ポインタと データポインタで構成される ジョブをエンキューできます ジョブを開始する際に 次のジョブも処理可能な状態であれば 並行キューは追加のスレッドを 活用することができます これは 一般的な非同期型の 独立したジョブに 最適なオプションです しかし 大規模な並列問題には あまり適しません その場合は dispatch_applyを使用できます これなら GCDのスレッドマネージャに 負荷をかけることなく 最初から多くのスレッドを 活用することができます これまで 並列のforを dispatch_applyに移行することで いくつかのプロ向けAppのパフォーマンスを 向上させることができています ここまでで GCDの概要を 簡単に説明しました 詳細情報や避けるべきパターンについては これら2つのWWDCセッションを 確認してください
ではここから カスタムジョブマネージャ について説明します スレッドを直接操作する場合や 同期する場合の 最も重要なポイントを 説明します まずは 優先順位付けから始めましょう 前のセクションでは ジョブ投入時の CPU効率を上げる方法を 説明しました しかし すべてのジョブが平等ではない ということには触れませんでした 中には 緊急なジョブもあり ただちに結果を出さなければならない ジョブもあります その一方で 次のフレームや 2つ先のフレームでのみ必要な ジョブもあります そこで より重要なジョブに 多くのリソースを与えるため ジョブを処理するにあたり ジョブに重要度を 設定する必要があります これは スレッドに優先順位を付けることで 可能になります スレッドに適切な 優先順位を付けることで バックグラウンドのアクティビティよりも ゲームの方が重要であることを システムに伝えることができます これは スレッドに CPU優先度の生の値 またはQoSクラスを設定することで 実現できます この2つの概念は関連していますが 若干異なっています CPU優先度の生の値は 演算スループットの 重要度を決定する整数値です Appleのプラットフォームでは Linuxと異なり この値は昇順になっています つまり 値が大きいほど重要です このCPU優先度は スレッドがPコアとEコアの どちらで実行されるべきかを 示すものでもあります このCPU優先度は スレッドの処理内容について 何も情報を渡さないため システムのその他の リソースには影響しません スレッドには Quality of Service (QoS)によって 優先順位を付けることができます QoSは スレッドにセマンティクスを 付与するように設計されています これにより スケジューラは タスクを実行する タイミングを賢く判断することができ OSの応答性を高めることができます 例えば エネルギーを節約するために 重要度の低いタスクは時間的に 少し延期されることがあります また ネットワークやディスクアクセス などのシステムリソースへのアクセスを 優先させることもできます エネルギーの節約機能として タイマー併合のしきい値も 提供します QoSクラスには CPU優先度も 含まれています QoSクラスは5つあり 最も重要度の低い QOS_CLASS_BACKGROUND から 最も重要度の高い QOS_CLASS_USER_INTERACTIVE まであります それぞれ デフォルトのCPU優先度が 含まれています オプションとして 限られた範囲内で 若干のダウングレードを することもできます これは 同じQoSクラス内の 複数のスレッドのCPU優先度を 細かく調整したい場合に便利です Backgroundクラスの扱いには 十分注意してください このクラスを使用したスレッドは 非常に 長い間 全く実行されない可能性があります 一般的に ゲームでは全体的に5〜47 の範囲でCPUの優先度を使用します では 実際に見てみましょう まず Pthread属性をデフォルト値で 割り当てて初期化する必要があります その後 必要なQoSクラスを設定し その属性を pthread_create関数に渡します 最後に 属性構造を破棄します すでに存在するスレッドに QoSクラスを設定することもできます 例えば この関数は呼び出しスレッドに 影響を与えます なお ここではオフセットを-5とし クラスのCPU優先度を 47から42に下げています 関数名にnpというサフィックスが 付いていることに注目してください これはNonportableの略で Appleプラットフォーム専用の 関数に使われる命名規則です 最後に これらの関数を使わずに CPU優先度の生の値を直接設定した場合は そのスレッドのQoSを オプトアウトすることになりますので 注意してください 後でそのスレッドに QoSをオプトインすることは できません iOSやmacOSは ユーザー向けのプロセスや バックグラウンドで実行されるプロセスなど 多数のプロセスを処理します 場合によっては システムが 過負荷状態になることもあります この場合カーネルには すべてのスレッドがどこかのタイミングで 実行されるようするための方法が 必要となります これは 優先度ディケイで実現できます この特別なケースでは カーネルは時間をかけて 徐々にスレッドの優先順位を下げていき すべてのスレッドが 実行されるようにします 非常にまれですが この優先度ディケイが 問題になることがあります 一般的にゲームには メインスレッドやレンダリングスレッドなど 非常に重要なスレッドが いくつかあります レンダリングスレッドが先取りされると プレゼンテーションウインドウが 読み落とされてしまい ゲームが滞る可能性があります そのような場合は スケジューリングポリシーで 優先度ディケイを無効にすることができます デフォルトでは SCHED_OTHERポリシーで スレッドが作成されます これは タイムシェアリングポリシーです このポリシーを使用したスレッドは 優先度ディケイの影響を受ける場合があります また このポリシーは 先ほど紹介したQoSクラスにも 対応しています 一方で オプションの SCHED_RRというポリシーもあります RRは「round-robin」の略です これを使用したスレッドは 固定の優先順位を持っており 優先度ディケイの影響を受けません これにより 実行遅延の 一貫性が向上します これは 専用のレンダリングスレッドや フレームごとのワーカスレッドなど 一貫性があり 周期的で 優先度の高い作業のために 専用に設計されたポリシーである ことに注意してください このポリシーを使用したスレッドは 特定の時間枠内で動作しなければならず CPUを100%使用し続けることは できません このポリシーを使用すると その他のスレッドが選択されない という状況が生じる可能性もあります 最後に このポリシーは QoSクラスと互換性がありません スレッドは 生のCPU優先度を 使用する必要があります これは ゲームスレッドで推奨される レイアウトです まず ゲームの中で 優先度の高いもの 中程度のもの 低いもの そしてユーザー体験にとって 不可欠なものを それぞれ定義します 優先順位によってジョブを分けることで Appのどの部分が 最も重要であるかを システムに知らせます Instrumentsを使用して ゲームをプロファイリングし 実際に必要なスレッドにのみ SCHED_RRを選択します また SCHED_RRを 複数のフレームにまたがる 長時間のジョブには使用しないでください このような場合には QoSを使用して システムが他のプロセスと パフォーマンスのバランスを 取れるようにします QoSを使用すべき別の状況は スレッドがGCDや NSOperationQueuesなどの Appleのフレームワークと やり取りする場合です これらのフレームワークは ジョブ発行元からジョブ自体に QoSクラスを プロパゲートしようとしますが 発行元のスレッドが QoSを破棄している場合 これは確実に無視されます 優先順位に関する最後の ポイントについて説明します 優先順位の逆転についてです 優先順位の逆転は 優先順位の高いスレッドが 優先順位の低いスレッドにブロックされて 停止する際に発生します これは一般的に 相互排除で発生します 2つのスレッドが同じリソースに アクセスしようとし 同じロックを奪い合うことになります 場合によっては 優先度の低い スレッドの処理を加速させることで システムがこの逆転を 解決できることもあります 仕組みを見てみましょう 2つのスレッドについて考えます それぞれの実行タイムラインを 見てみましょう この例では 青が優先度の低いスレッド 緑が優先度の高いスレッドです 中央には ロックタイムラインがあり 2つのスレッドのうち どちらがそのロックを 取得するかを示しています 青のスレッドが実行を開始し ロックを取得します 緑のスレッドも実行を開始します この時点で 緑のスレッドは 現在青のスレッドが 所有しているロックを 取得しようとします 緑のスレッドはブロックされ そのロックが再度利用可能になるまで 待機します この場合 ランタイムはどちらのスレッドが そのロックを所有しているかを 識別できるので 青のスレッドの低い優先度を 上げることで 優先順位の逆転を 解消することができます 優先順位の逆転を解決できる プリミティブと 解決できないプリミティブ について説明します pthread_mutex_tや 最も効率的なos_unfair_lockなど 単一かつ既知のオーナーを持つ 対称プリミティブでは解決できます Pthread条件変数や dispatch_semaphoreのような 非対称プリミティブでは 解決できません ランタイムが どのスレッドが シグナルを送るかを把握できないためです 同期プリミティブを選択する際は この特徴を念頭に置き 相互排除アクセスには 対称プリミティブを 選択するようにしてください このセクションの最後に メモリに関するいくつかの推奨事項を 説明します Objective-Cフレームワークを扱う際 一部のオブジェクトは 自動解放として作成されます つまり 後で割り当て解除が 実行されるようにするため それらのオブジェクトが リストに追加されることになります 自動解放プールは そうしたオブジェクトを どれほど維持するかを制限する スコープとなります 自動解放プールにより Appの ピーク時のメモリフットプリントを 効果的に削減できます すべてのスレッドエントリポイントに 少なくとも1つの自動解放プールを 用意することが重要です 例えばMetalなど 自動解放オブジェクトを 処理するスレッドに 自動解放プールがない場合 メモリリークにつながります 自動解放プールブロックを ネストすることで メモリの再利用時に より適切に コントロールすることができます レンダリングスレッドには 繰り返される フレームのレンダリングルーチンに 2つ目のレンダリングスレッドを 作成するのが理想的です ワーカスレッドには ワーカが起動してから 停止して次のジョブの待機に移るまで 2つ目のワーカスレッドを作成できます 次の例を見てみましょう これはワーカスレッドの エントリポイントです 自動解放プールブロックで始まっています そして ジョブが利用可能になるまで 待機します ワーカが起動すると 自動解放プールブロックを 新たに追加し ジョブが処理される間 そのブロックを維持します スレッドが待機し停止する直前に ネスト化されたプールを 終了します 最後に メモリに関するヒントを 紹介します パフォーマンスを向上させるため 複数のスレッドが 同じキャッシュラインにあるデータを 同時に書き込むことは避けてください これは「False Sharing」と 呼ばれています 同じデータ構造から複数の読み込みを 行うことは問題ありませんが 競合する書き込みを行うと 異なるハードウェアキャッシュ間で そのキャッシュラインが 行ったり来たりしてしまいます Appleシリコンでは 1つのキャッシュラインは128バイトです これを解決する方法の1つは データ構造内にパディングを挿入して メモリの競合を減らすことです これで最後のセクションは終わりです まとめましょう まず AppleのCPUアーキテクチャの概要と その画期的な設計による 効率性の高さについて 説明しました そして OSスケジューラにかかる 負荷を軽減しながら CPUの効率性を高め スムーズに動作させる方法について 考えました 最後に スレッドの優先順位 スケジューリングポリシー 優先順位の反転など APIに関する重要な概念を確認し 最後にメモリに関するヒントを 紹介しました 定期的にInstrumentsで ゲームのプロファイリングを行い ゲームのワークロードを 把握することで パフォーマンスの問題を 早期に発見できるようにしてください ご視聴ありがとうございました
-