-
Working with Metal: Fundamentals
Start learning how to code with Metal in this step-by-step walkthrough of basic scene rendering. See the code you need to get your first Metal-based application up and running. Explore how to create graphics and compute shaders and efficiently animate scenes.
リソース
-
このビデオを検索
So welcome. So- -oh, thank you.
So, my name's Richard Schreyer, and I've been working on the design of Metal for quite a while now. And so it's really exciting to finally be able to talk to all of you about it. So this is the Metal fundamentals session. It's the second in our trio of sessions, following concepts and to be followed by Metal advanced usage. So this session is going to be split into two major parts.
The first half, which I'm going to present, is going to be how to build a basic Metal application.
I want to take all of the concepts that Jeremy just described, a bunch of block diagrams and arrows. And turn those into actual code.
So, we'll try to make everything more concrete.
During the second half of the session, I'm going to turn the stage over to my colleague Aafi , who will take you into a deep dive into the Metal shading language.
Talk about, you know, the various syntax and data types. How to express vertex, pixel and compute shaders. And then a bunch of grab bag of other interesting topics.
So, getting right into building a Metal application. So as I said, this is going to be a fairly -- a set of slides that are fairly heavy on code. That's really what I want to try to get across is, you know, what you're going to actually want to put down in Xcode. So I'm going to try and keep this application as simple as possible. So it's going to be a very "hello world" kind of thing.
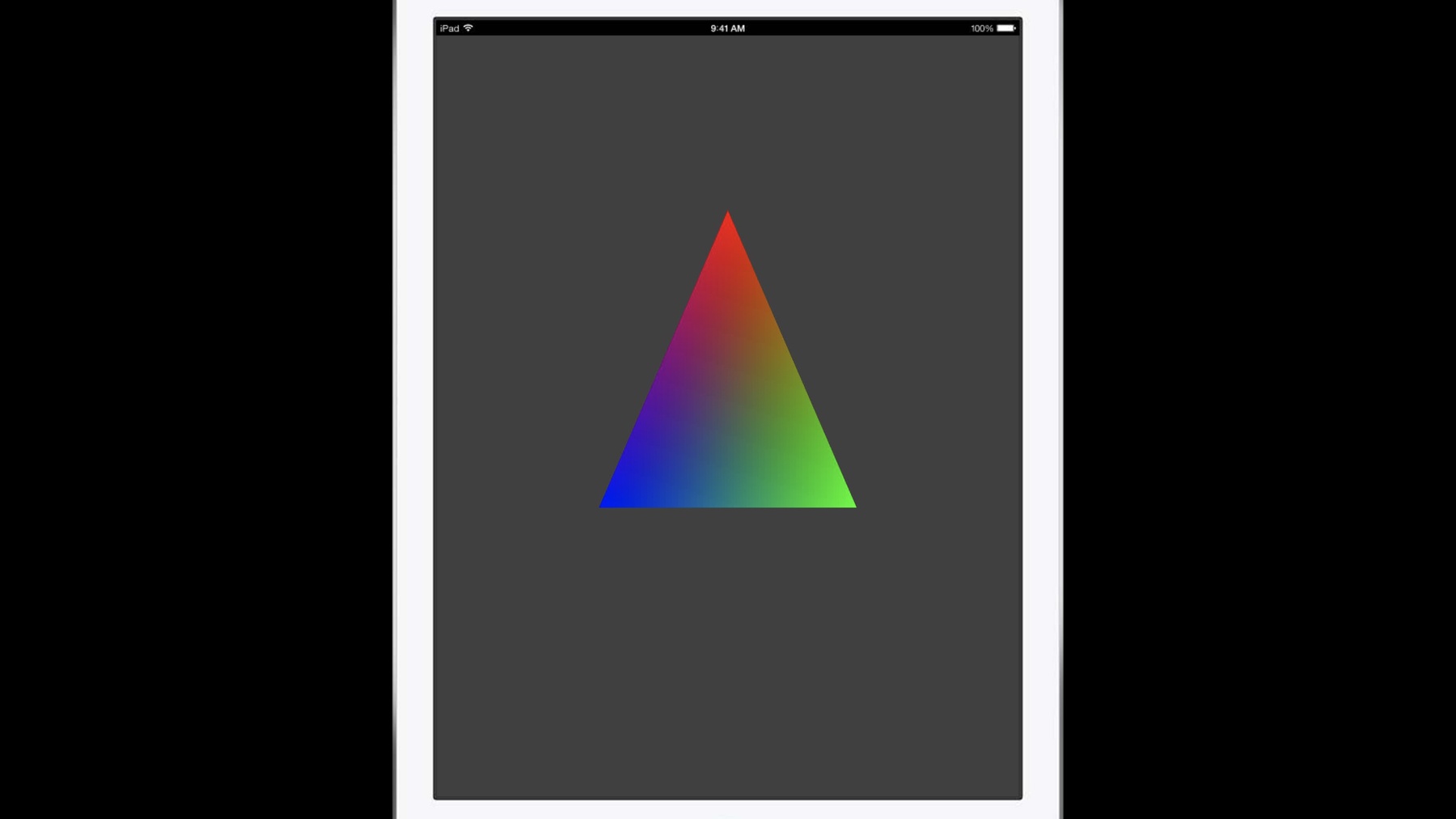
So in the interest of, is it always that way in graphics? So the application I'm going to build is basically just a triangle. We're going to go through all the steps to go put a single shaded triangle on the screen. I know, really exciting stuff.
But it's actually pretty cool because, and we're going to go through some boiler plate and some setup. But once you get through that, that's really the same foundation you need to start building, immediately, much more complex content on top of that.
So we're not going out of our way to draw just a triangle.
So the first set of things I'm going to go through are just the initialization. I mean what's the one-shot setup you'll do when your application launches or you start using Metal? Then I'll get into the contents of what, you know, the actual drawing will look like.
And then we'll get on to extending the application to do a little bit more stuff. So these are the steps that I'll walk through in the code, in order.
So right at the top is getting the device.
So what is the device API? So in Metal, a device is sort of the root object of a whole API. It's your direct connection to the GPU driver and the GPU hardware.
Now as far as the actual API that the device sends out, what it really does directly, it's the source that you go to to create all of the other objects in the Metal API.
So if you want to go create a new texture or a new buffer or a new RenderPipeline, the device is where you'll find that.
So, we want to go create some stuff, and so we need a device to create them on.
So that's really easy. So our first initialization step is to just say, "hey, I want the default device." Our second initialization step is we need a command queue.
The CommandQueue is our channel to submit work to the GPU.
Now we're not actually going to do any of that until we get to drawing, so I'm going to create a CommandQueue now from the device and save it aside.
The third initialization step is to go create all of my buffers and textures and other resources.
My application is simple enough that I have exactly one of them. I need a vertexArray. And so I'm going to go back to the device yet again and say newBuffer.
This particular variance will go allocate a new block of CPU/GPU shared memory, copy the provided pointer into it, and give me back a handle to that buffer.
So right off the bat we've gotten through three of our five initialization steps. We're making pretty good time.
The fourth one is going to be quite a bit more involved. We're going to spend some time on that one.
And that is creating the RenderPipeline.
So this is all -- so as we saw in the concepts session, the RenderPipeline is a collection of quite a bit of stuff. Most importantly, the vertex and the fragment shaders, but it also incorporates every other piece of state that the shader compiler needs to generate the final machine code for the A7.
That includes some information on vertex layout, some rasterizer configuration, all of the framebuffer, blend modes, and some information about the framebuffer configuration that this pipeline will draw to. That's actually quite a bit of stuff.
And so we've split the RenderPipeline into two separate objects. The RenderPipelineDescriptor, which is your object that provides all the configuration API, and the RenderPipelineState, which is the sort of baked, finalized form of that. It's just small, it's compact, and they're really cheap to switch between.
So let's go look at the code to build -- I'm going to build one RenderPipeline in this application, so let's go look at the code. So first, I'm going to conjure up a new descriptor.
And the very first things I'm going to set on it are my vertex and my fragment shaders.
And you'll notice that I'm not providing any source code here.
So this is what the runtime API looks like when Xcode builds your shaders offline for you. Xcode's going to package up all of the offline-built shaders into a device independent bytecode file...
and ship that in your application bundle. And at runtime I can go ask the device to load that default library.
Once I have that, I can go start picking functions out of that by name.
The second piece of configuration I need on the RenderPipeline is the framebuffer format.
So, I'm only going to have one color attachment I'm rendering to, and so I'm going to say, "hey, this is going to be a BGRA render target." A RenderPipeline has a whole bunch of other stuff I can set on it, but for my simple little application, that's really all I need. The default values of all the other properties are already appropriate. So I'm going to go ahead and compile and ask the device to compile a RenderPipeline state. I'll just go to the device and call newRenderPipelineState WithDescriptor.
So this is actually the expensive API.
This is the API that is going to, if necessary, go call over to the shader compiler and finish the code generation, taking into account all of the other information that you have provided. Once we have this RenderPipeline, now you, you know -- it's all baked. It's all finalized, and we can toggle between them at draw time very, very cheaply.
So that's our fourth initialization step, building the RenderPipeline. But before I move on from that, you know, since we're pointing at our vertex and fragment shader here, I do want to take a really quick little detour and show you the vertex and fragment shader code itself.
So I'm not going to explain to you every part of the syntax, because Aafi is going to tell you all about that in just a few minutes.
But I'm going to show you just, I'm going to focus on just the dataflow from the vertexArray through the vertex and fragment shader and into the frame buffer.
So, I've split this up into two slides. My first slide are a couple structures that describe the input and output of the vertex shader.
The vertex structure defines how my vertexArray is laid out in memory. Position followed by a color. My vertex shader is going to be a really simple pass-through shader. I'm going to read my position color from the vertexArray and pass them right out down the pipeline unchanged. So, unsurprisingly, my VertexOut struct looks, well, just like it.
The only difference is that the rasterizer needs to know which of the outputs is the position, so we have to use an attribute to identify that to the compiler. All of the other outputs will get interpolated across the triangle as usual. So on to the body of the vertex shader. So here's my simple pass-through VertexShader.
So we have a normal C-style declaration with some extra key words and attributes. We'll go into more detail on them later.
But I'm getting a pointer to my vertexArray into my VertexShader, along with a vertex ID that tells me which of the three vertexes that this thread is going to be processing.
From those I'm going to read from the vertexArray, copy to the output struct, and I'm going to return an instance of the VertexOut struct. So this is sort of in comparison to GLSL where all of the inputs and outputs are specified as global scope. In the Metal shading language, all of your inputs come in via function arguments. All of your outputs are returned via the C return pipe. Okay, this guy likes that! So now the FragmentShader is of course even easier.
The input to my FragmentShader is again, a single argument. In this case the same VertexOut structs that the VertexShader just returned.
Except now it contains an interpolated position and an interpolated color. So I'm going to go read my color. And I'm going to return a float4, which will write into the framebuffer.
And because we told them -- put in the pipeline state what the framebuffer for it is, the compiler knows how it needs to pack this down and compress it to the actual, final framebuffer format.
So that's the vertex and frag-pass-through vertex and FragmentShaders.
And that's really the end of how to build a RenderPipeline. The one last bit are just the function names themselves, which are the strings that I use to pull up these functions up when building another pipeline.
So our fifth and final step to initialize is creating the view. So if you've been working on iOS for a while, you're probably aware that if you want to get anything on the screen, it basically needs to be part of a core animation layer tree.
So, iOS 8 provides a new subclass of CA layer called CAMetalLayer.
And that class is really interesting because it can vend out textures. It will manage a swap chain of typically three textures, and you can ask for the next one in the chain.
And I can say, "Give me a texture," render into it, and when I'm done I can push it back to be swapped on to the display.
To create a layer, that's typically owned by a UIView subclass.
I'm going to show you a very, very bare bones UIView subclass on the next slide. And you can find a much more complete implementation, with a bunch of functionality, in our sample code.
And then because this is iOS, and this is you know, entirely typical, your view is then typically owned by a ViewController, which is usually typically completely custom to your application.
So let's go look at our really bare bones view.
So really this is all you really need to do. I need to subclass UIView, and I need to override the layerClass method and say, "I want this view to own a Metal layer as opposed to any other kind of layer." There is some other configuration we could do on this view in this layer (primarily for efficient compositing) but this is really the bare minimum that you need to get something on to the screen.
So with that, we've been through all five our initialization steps.
We breezed through getting the device, getting a CommandQueue, and creating a resource.
Spent a little bit of time on the RenderPipelineDescriptor and RenderPipelineState.
Also looked at the shaders. And then we created a view. So with that we can actually get to drawing something. And so that has a few more steps. So, we need to get a command buffer, since all of our work that goes to the GPU will be enqueued into a command buffer.
We're going to encode a renderToTexture pass into that command buffer. We're going to put some stuff in that render texture pass.
And then finally we're going to send that CommandBuffer to the GPU hardware to be executed.
So, step 1, getting the CommandBuffer.
That's another one-liner.
You can simply go to the command queue and say, "give me the next available CommandBuffer." The second step is setting up my renderToTexture pass.
One thing that sets Metal apart from other graphic APIs is that we have a, sort of, very rigorous definition of when a rendered texture pass begins and when it ends.
And when you start a renderToTexture pass, we require that you tell us all of the framebuffer configuration right up front so we know how to configure the hardware.
And most of what goes into that configuration looks a lot like a framebuffer object in open GL.
There's, you know, what color textures am I rendering too? Up to four of those. What depth texture? What stencil texture? Which bitmap levels that, the load actions and store actions that you saw in Jeremy's presentation.
So given that there's so much configuration that happens here, we've again taken that and packaged it all up into a descriptor to do convenient configuration on.
And then once you have the descriptor configured, you can then create the renderToTexture pass. So, putting that into code.
Right off the top, we need to know what texture we're going to render into. So we're actually going to go back to our CA ,metalLayer and say, "give me the next available drawable." And a drawable is pretty much just a wraparound to texture plus a little bit of extra bookkeeping.
This is one of the very few API calls in Metal that will actually block your application if there's no more available textures in the swap chain, if they're all busy.
So this could block and wait awhile, especially if you're GPU bound. Next, I want to set up my RenderPassDescriptor.
I'm going to .colorAttachment zero at my drawables texture. I'm going to configure the RenderPass such that it will clear that texture at the start of the pass, preventing the existing contents of that texture from being loaded into the GPU's tile cache. And then I'm going to then actually, you know, I'm going to choose some really boring array to clear it to.
So again, if I had a more complex framebuffer configuration, there would be a bunch more similar stuff here. But again, that's all I really need for my "hello world" application. So now I can go to the CommandBuffer, and I can say, "the next thing on this CommandBuffer is a renderCommand.
Here's the descriptor. Give me back the interface I can use to encode." And this renderCommand encoder you're getting back is the object that has most of the traditional 3D graphics API you're expecting to find. Things like setting the depth stencil state and binding textures and colNodes and all that stuff.
So let's go actually draw our triangle init. So previously I created my RenderPipeline, and I created my vertexArray. So I want to set them both here: which RenderPipeline we're going to use? And I'm going to say, I'm going to point right at the vertexArray. And I can finally encode the command to draw my single triangle.
So now we've gotten through our third step of drawing the triangle. And now we get to the final one, committing the CommandBuffer to the GPU.
At this point we have basically a fully-formed CommandBuffer just sitting in memory, idle. It's not going -- GPU will not start executing until you've committed.
So before we do that though, we actually want to do one more thing and tell CoreAnimation when you actually want to present this texture.
Because we got a texture from CoreAnimation, and now we need to tell CA when we can display that texture safely.
Because we haven't rendered anything yet, now's not the time.
So we want to be able to -- and so this API addPresent will set up an automatic notification from Metal to CoreAnimation that when this rendering is complete, it will cross-call into CoreAnimation and say, "it's time to put this on the display now." And then finally we have the big red button.
You call commit, and this CommandBuffer gets encoded -- gets enqueued into the end of the command queue, and it will execute on the GPU hardware.
So that is all of the steps to go and draw my single triangle.
We needed to get a command buffer, configure a render pass with one target texture that we got from CoreAnimation, draw my triangle with the vertexArray and a pipeline state. And commit the command encoder.
So that's my triangle. That's pretty much all the codes you need.
Go -- do it, yeah. So it's kind of a boring application. So let's add at least one little thing more that every single application is going to need because I imagine you're all not going to be happy drawing exactly the same thing over and over again. We need to load some shader uniforms because, you know, we actually want to make things move over time or what have you. So, this is going to take the form of -- so I want to use this opportunity to show you how to load shader uniforms, also known as constants.
So, in Metal, shader constants come in through buffers. Just like vertexArrays or anything else.
So back to my vertex shader code.
I have declared a new struct, which describes to the compiler how my uniforms are laid out in memory.
In this case it's just a single 4x4 matrix.
And I've added a second argument to my function. I'm going to read from a different buffer. Now I'm going to read from buffer location 1, and that's where the compiler is going to expect to find a buffer that it's going to actually load that struct from. So that's the extent of the shader changes.
On the API side, I've allocated a second buffer to -- hold my uniforms. And I'm going to call the contents property, and that's just going to return to me a void star.
And, err, these are CPU/GPU shared CommandBuffers, or shared -- not Command Buffers. These are CPU/GPU shared memory.
The GPU is reading from exactly the same memory that GPU's writing. There's no lock or unlock API calls or flushing or any of that.
You can get a pointer, it to a type of your choosing and start writing.
And then finally, I'm going to set a second buffer argument to the vertex stage to point the hardware at uniformBuffer.
This is almost okay but not quite. Because we actually have a race condition here.
So your application encodes a frame and also writes to a uniform buffer at the same time. And then we ship that off to the GPU to be executed.
The execution is going to take some amount of time depending on the complexity of your scene.
So if you have like a conventional game loop, you're probably going to turn around and immediately jump back up to the top of your loop and start encoding the next frame right away.
Of course the GPU, being an asynchronous device, is still executing the previous commandbuffer.
So if I have go right to that unit, I have a new frame. It's a new time stamp. It's a new model view matrix. But if I write that into my buffer right now, I'm writing into the same memory that the GPU is reading from. And I've created a race condition.
At that point what the GPU reads is completely undefined.
So, the easy thing to do is write to a different buffer.
So there's no conflict here.
Then I come down into my third frame and so forth. But there comes a point where you just, where you, you know, you can't allocate new buffers forever. There comes a point where you're going to want to recycle an existing buffer again.
And the problem here is that, a CPU can get, sometimes, depending on how you structure your application, several frames ahead of the GPU.
And the GPU might still be working on that frame that you submitted two frames ago.
And we still have a race condition.
So the final step to resolving this is that we need to wait. That your application needs to not write to that buffer until you know that your code on the GPU is no longer reading from it. Fortunately, that's pretty easy. It takes about four lines of code. So I'm going to show you that now.
So I'm going to do this with dispatch semaphores, which are, you know, a common low-level synchronization primitive on iOS.
So for this example, I'm going to have a pool of three uniform buffers I've created. So I'm going to create a dispatch semaphore with a count of 3.
I'm going to add my common CommandBuffer loop. I'm going to build a Command Buffer. And I'm going to send it to the GPU.
But right at the top, before I write to any shared memory that I'm recycling, that the GPU is potentially still reading from, I'm going to wait. And I'm going to make sure that the GPU has actually finished executing that previous CommandBuffer before I reuse the memory. So this is the second place, apart from next drawable, where you probably see an application block when using Metal.
Now the other side of this is we need to signal the semaphore when it is safe for the application to proceed.
So, in Metal, you can add a completion handler to a CommandBuffer.
When the GPU finishes executing this CommandBuffer, the OS will invoke the block that you provide, and you can do whatever you want in there.
In this case, I'm going to signal the semaphore and say, "Hey a CommandBuffer finished. There's a uniform buffer available.
Start writing to it. Have a blast." And that's really it.
So that's really the basic walk-through through a simple "hello world" application with some animation. It does shader constants. Does vertexArrays, and we still have this setup 3D state.
Went through some of the basic initialization process.
We showed how to set up basic CommandBuffer draw. And we said hey, the moment you produce any CPU dynamically produced data, we saw how you have to synchronize access to that because we're just giving you the raw memory pointers now.
So, that thing -- these design patterns actually go really far. For example, that same pattern of synchronizing with semaphores or any other permit of your choice, and the callbacks, for example, are just as useful for dynamic vertex data, for streaming image up-, texture updates, if you have a large open world kind of scene.
Or even if you're going the other direction and having the GPU produce data, you know that the CPU can read it as soon as that callback fires.
So that's really your introduction to a really simple "hello world" application. We made a spinning triangle. Hooray. So, with that, that wraps up this. And so I'm going to turn the stage over to my colleague Aafi, to talk to you in detail about the Metal shading language. So thank you. All right. Thanks Richard.
All right, so we're going to talk about the shading language. And so Jeremy mentioned in the first presentation that this language is based on C++, so a lot of you -- most of you -- are all familiar with writing C++ code. What we're going to talk about is how we extended this to be able to write shaders in Metal.
So the things, the things we're going to cover in this session is how to write shaders. We're going to take a simple vertex in the fragment shader and see how we can take C++ code and make it into a vertex fragment shader. We will talk about data types that Metal supports. We will talk about, you know, well, shaders need inputs and outputs, so how do you specify that in Metal.
And, you know, if I'm going to use them, because in the RenderPipeline, I need a vertex shader and a fragment shader, well how do I make sure I pair these things together? And then we'll talk about math, okay? All right, so how to write shaders in Metal. So let's take this in a pseudo C code here.
So what you see here in this function is it takes three arguments. The first two are some pointers to some structures and the return's this vertex output struct which, you declared it.
And what I want to happen here is -- remember, the vertex shader is executing for each vertex, so if I have N vertices in my primitive I want, there may be multiple threads executing these vertices in parallel. So what I want to be able to do is read in that thread that's executing this vertex shader, which vertex am I actually accessing so I can go and get the right index -- use that index to access the right vertex data. So, just you know, imagine, just imagine that this is that ID, okay. So in this code, what we see is we're going to use this ID and reference into the input arguments. This is the vertex data and UV data. Arguments have passed to this function. And you will typically probably do some computations. In this case I'm not doing much. I'm just going to copy them and return them back.
Well okay, how do I make this into a Metal vertex shader? Well the first thing, note that we don't -- and Metal doesn't -- support the C++ standard library. Instead Metal has its own standard library that has been optimized for the GPU. For the graphics and compute.
In addition to that, so I want to include that. In addition to that, you know, types and functions defined by Metal actually are in the Metal's namespace. So I'm just being lazy. Instead of explicitly calling them, I'm just saying I'm going to use the Metal namespace in my shader here. The next thing I'm going to do is I'm going to tell the compiler, "hey," that "this function is a vertex function." Okay, so that's what I'm going to do. And then Jeremy showed you that any resource that's passed as arguments to your functions, you need to have the argument indices. So in this case, you know, anything that's a pointer is actually a buffer. So I'm going to assign buffer indices. And there's this global thing that I have added here. So just ignore that for now. I'll talk about what that is in a few slides. So almost there.
And I need to tell the compiler that that ID is actually the vertex ID so it can generate the right code for me. And that's it. That's a Metal vertex shader, okay? What, nobody's going to clap? All right.
And you know a fragment shader is just very similar, OK? So I need to tell the compiler it's a fragment function, so I use the fragment qualifier. Now note, remember the fragment shader typically takes inputs that are generated by the vertex shader. The output of the vertex shader goes to the rasterizer and becomes inputs to the fragment shader. So in this case, the vertex shader returns VertexOutput and I want to use that as an input. Now, this is some struct that you have declared. So the compiler needs to know that this is a per instance input. So anything that's user defined and input to a vertex shader or fragment shader that needs to be generated uniquely for instance, also has to be qualified. And so in Metal you do that by declaring that with that stage and attribute, okay? So what I'm doing is in this shader I'm going to look at the texture coordinate per fragment and use that to sample into a texture that'll return the color value. So pretty straight forward. So that's it. It's really, you're going to find that writing shaders in Metal is really, really easy. All right so let's talk about data types. So, I've broken data types into two categories.
One I call the basic types. And then we have resources and state objects. Note that one thing you see is that all the inputs to a shader are passed as arguments. There are no globals. So you declare everything as arguments, and then if these are resources or state objects, then you specify the indices that the runtime will use to set the right resources to. Okay, so let's talk about the base types. What are these? These are scalars, vectors, matrices and atomics. So... the scalar is pretty straightforward. I mean it doesn't usually tell much. We support the C++11 scalar types.
In addition to that, we have the half type.
Okay. All right. So the half type. So this is the IEEE 754 16-bit floating point type. And so any operation you could do with Float, is half of a first class citizen. So anything you can do with Float, you can do with Half. In fact, we really want you to use half because they are both performance and power optimizations that you surely can take advantage of.
Vectors: very similar. So you have you know, two, three and four component vector types. So for example, a half2 is a two-component 16-bit floating-plan vector.
Matrices: we have floating point matrices, and they're stored in column major order, just like they are in GL. The constructors and operators: the things you can do on them are very similar to what you would find in other shading languages, so I'm not really going to cover that. But here's the thing I want to talk about. So, remember your path. You're declaring a struct. You're passing a pointer to that struct as argument to your shader. So what you want to be able to do is declare these -- let's say in a header file -- and then use them both on the host code because you're going to build this data structure on the host.
And then use this header file also in your shader.
Well you can do that because these types -- So, in iOS 8 we have the SIMD math library, and so these define the vector and matrices types. And Metal uses the exact same types. So, what that means is: if you include the SIMD header in your host code and you can build the structures, you can share them.
You don't have to do anything special. It just works, okay? Not every slide, no clapping every slide.
Again, just like I said previously, use the half vector and matrix types whenever you can, okay? All right, so the last -- Oh, so one more point on vector types. So they are aligned at vector length. So what does that mean? So if I look at the struct, what that means is: a float2, which is what b is, is going to be aligned on 8 bytes. And similarly c is going to be aligned with 16 bytes. But if you notice, b is actually at an offset of 4.
So that's a problem. So what the compiler will do is, it's going to generate a padding variable. Okay, so when you do sizeof(Foo), you're only going to get 32 bytes. So depending on how big your data structure is and what kind of scalars and vectors you use, the compiler may potentially have to generate lots of padding. And if you're going to declare an array of these structs, then, you know, it has potential implications to your allocation size and even memory bandwidth when you access these data structures in a shader code. So, well, you may want to be smart and say, "well, let me declare them in order of decreasing size; put all of my biggest data types first, and then the smaller types." Well if you try to do a sizeof(Foo) on that, you're still going to get 32 bytes. And you're like, "why is that?" The reason for that is the compiler still has to guarantee that each struct is aligned to the site of the largest data type in that struct.
Because if you were to use an array of these, if you type index C at index 1, you have to make sure it's aligned on 16 bytes. So that doesn't work.
So what if I wanted to tightly pack all my data structures? Yes, you can do that. And we have packed vector types for that.
So they are just like the aligned vector types. They're declared with this "packed underscore" prefix.
You can do all of the operations on these types as you can on the aligned vector types.
The only benefit is that a line is scalar type length. So if I declare the same struct now, but use the packed types, then these are aligned correctly. And so the sizeof(Foo) is going to be 28 bytes. So then you are ask, "well why shouldn't I always use these packed types?" And the reason, the answer to that depends on how you are going to use these on the host. Because the CPU, these types are not a good fit for the CPU. But the CPU likes vector types to be aligned. So if you're just building a data structure, and just filling it out and going to pass that to the shader (and most of your computations on these data types are going to happen in the shader) then you can use the packed types.
But if you're going to perform computations with these types in host code, then you should use the aligned vector types. So use that to determine like which types you need to use. All right, so the last of the basic types, and these are the atomic types.
And so we support a subset of the C++11 atomic types.
And the question is, "why should I use atomic types?" Well, the operations on these types are race-free. So, let's take an example. Let's say I'm generating a histogram for an image. And so I have 8 bits per channel. So I have 256 bins for each color channel.
So I want to update a bin. So I'm going to read the current value. I'm going to increment it, and then write it out. So what I want to make sure is that after I've read but before I've written, nobody else comes and changes it. And that's what these atomic operations guarantee.
Okay? All right, so that covers the basic types.
So let's talk about resource and state objects that you can pass as data types to your shader.
All right, so we support the traditional texture types like 1d, 1dArray, 2d, 2dArray, but how do you declare these in Metal? So these are declared as a template. He likes it, all right. So the template takes two parameters. One is the color type. And this indicates if you're going to sample from a texture the vector type you're going to return, or as a color value, or if you're going to write to the texture, what is the vector type that would represent the color value? And the access mode. And this tells the compiler whether you're going to be sampling from a texture or reading or writing. Reading is just saying, "hey, go read this specific location pixel in my texture" or "write this color value to this specific location in the texture." You can sample and read or write. You cannot do both to the same texture within a shader.
And that texture is of a different type because the GPU actually optimizes them differently. And so we need to know that you're actually working with a depth texture.
So let's look at some examples.
So in this first one we have a 2d texture, and its color type is float. So if you sample from this, you're going to return the float forward. Notice I didn't specify the access mode because it has a default, which is sample. So the next one is a 2d texture again which uses the half type and its access mode is write. So if I try to read from this texture in my shader, the compiler will throw an error. And then finally we have a depth texture. Okay? Samplers are separate from textures. So, what does that mean? That means I can use the same sampler with multiple textures. Or I can use multiple samplers of the same thing with one texture.
You have the freedom.
How do I pass these? Well, like I said, everything is passed as an argument, so you can pass them as an argument to your shader. In addition though, you can actually declare them in your source.
So it depends. So like in a lot of cases, especially if you're doing, ah, image processing filters -- you know, you just need a handful of samplers that you're going to use.
And data declared is a variadic template. And the reason for that is samples have a number of properties like the filter mode, the addressing mode, whether the coordinates I'm going to use are normalized or pixel, and a bunch of other things. I don't want to have to set them explicitly every time. All of these have defaults. So you only change the one you want to, you are changing from the defaults. So in this example, I'm changing the address more from clamp to clamp to zero, and the other properties take the default.
So you can choose to pass them as an argument, or you can choose them to declare them in your source, depending on your needs.
All right, so last of the types. All right, so buffers is just (as Jeremy mentioned) a bag of bytes. And so you just pass a pointer or a reference to this type. And notice in the first slide I have this global qualifier. Well let's talk about that now. See, anything that's passed as a pointer, or a reference to some memory, you need to say which memory region it comes from.
And that's because GPUs actually implement the member hierarchy.
With compute, you got an additional memory region. But if you're just writing vertex and fragment shaders, the two memory regions (we call them address spaces), you need to worry about our global and constant. So the question is, "well when should I use which?" All right, so if you are writing a vertex shader, you pass pointers to some buffers, you're going to use your vertex ID to index into it. That means for each, if the vertex shader is being executed over N vertices, all of these instances that are executing the vertex shader are going to be unique locations. So when you see that data pattern, you want to use global.
Okay, and the same thing for compute. You will find that out when we talk about computing in the next session.
However, you will also find in your shader that you may, you are actually accessing some data structures where all of these instances actually access the same location. For example, if you have a light descriptor. Or if you're doing skinning. Or if you're doing filtering.
So in this case you will find that all these instances executing your vertex shader go refer to the same light descriptor. Or the same skinning matrix. So let's look at an example.
One more thing here is that when you use constant, we really want you to pass by reference.
Because that tells us what the size is and we can actually optimize by prefetching the data. And that can have a significant impact to improvement of performance of your shader. So definitely take advantage of that. Okay, so let's take an example.
Here I have four arguments passing three buffers and my vertex ID. So let's look at the first data pattern.
Look at normal data and position data. I'm actually accessing using my vertex ID, so which address space should these belong in? Global. But if you look at the other three data pattern accesses and matrices, you notice that if, in a multiple vertices root exiting this function across multiple vertices, they're going to refer to the same normal matrix, the same projection matrix.
So, therefore, I should declare these in a constant address space. So hopefully this gives you an idea of how to declare your buffers in which address space. You don't have to do that for textures. All right, so let's talk about inputs and outputs. So that was a very high-level overview of the data types. So, how do you pass input through your vertex shader? Well there are two ways.
The first one we've actually shown you, right? In all of the examples I have shown you, you pass the input by passing a pointer to a struct, so you've declared, and then you use your vertex ID to index into it. So that means is you actually know the data layout of your vertex inputting in a shader. So if you do, this is the way to do it, okay? So in addition to your vertex ID you can also use your instance ID.
Like in this example, I have two inputs I'm passing in as buffers, and I'm using the vertex ID and instance ID. But there is also the traditional approach.
So in this approach, you don't know the data layout in your shader.
And so if you want it all, you may want to decouple. You may want to declare in your vertex shader the data types you want to use for your vertex inputs because of the computations you're doing in your shader, and have the flexibility to be able to declare the actual input at runtime in the buffers are showing, and they may be different.
So, this is more like the OpenGL's Vertex Array API. And so this, this approach in Metal is actually a good match. And let me talk about how it works. So the thing you'll do in the runtime is you will create a vertex descriptor. So in this descriptor for each input, you're going to specify the buffer it comes from, where inside the buffer, what is the format, things like that.
And you may have one or more buffers for your inputs. In the shader, everything that is an input, you're going to declare them in a struct. And remember I said, anything that's user-defined information that you want to generate per instance, you have to use stage-in. So that's how you declare it.
So let's look at a code example.
Ah, before that.
So I declared my struct and my shader, and I declared my vertex descriptor. All my inputs and my vertex descriptor, I need to be able to say, "hey, this will work -- I need to be able to map one to the other." And the way I do that is by specifying an attribute index, okay? So let's look at an example. Let's say I want to pass four inputs. The first one is going to be positioned, and it's going to be an index 0, and 12 bytes in size. The next one is normal.
It's also at offset 12 and 12 bytes in size. In fact, all four inputs are going to come from the same buffer. And so the next one is color at index 2, 4 bytes in size. And then third is texture coordinate at index 3, 4 bytes in size, okay.
All right, so how do I declare this in the shader? So I have a struct. I have defined the data types I want to use, and the attribute indices they're going to use. And notice that I've declared them with the stage-in qualifier because this is going to be per instance.
For every instance it executes as a vertex shader. Okay, so let's look at the API.
So the first thing I'm going to do is create the vertex descriptor.
So the first imput was my position. So I'm going to say float3 is 12 bytes. So it's going to start us off at 0.
And notice I had a single buffer for all of the input. So my buffer index for all of these is going to be 0.
The attribute index is 0.
So next I set the normal, so at index1. The next I set color, at index2. Texture coordinate.
And for each buffer that I'm using to declare my vertex inputs in my descriptor, I have to say the stride, what is the stride so I can fetch the right vertex data.
So in this case it's 32 bytes. So I did that.
Then I put this vertex descriptor to in my pipeline descriptor. And then I create my pipeline object, my RenderPipeline object. And at that point in time, Metal will go figure out how to generate the code to go fetch your input. So, you have both options available. Use which works best for your problem. All right, outputs: well, there are two ways of writing inputs, so we wanted to make sure you get two ways of writing outputs too.
So, typically what you would do is the output of your vertex shader will go the rasterizer, because you want to show something on the screen, so you want to rasterize triangles.
So anything that you return from the return type of your vertex shader is what's going to go to the rasterizer. So what can I return? I can return a float4. At a minimum I must return a float4, and I'll tell you why. Or you can have a user-defined struct.
What can be in this struct? So there can be a scalar, a vector or a matrix. You can even have arrays of these.
There's some special variables we need to know about like position, point size if you're rendering a point sprite or clip distance.
You must return a float4 because position must always be returned. It's kind of hard for the rasterizer to generate rasterized triangles without knowing position.
So that's why.
All right, so here's an example.
I'm returning four things.
And I use the built-in variables attributes to identify things such as position and point size. This is really pretty straight forward. Declare your struct, declare some attributes and you're done.
Okay. So it's great.
I can generate output, pass it to the rasterizer. But I want to do more.
I want to be able to write some buffer, maybe more than one buffer. I don't want to send anything to the rasterizer. Or maybe I want to do both.
Can I do that? The answer is, "we are here to please." So remember the vertex ID you can use that to input. Well guess what? You can use that to output too. So here is the structure I want to write out. I want to pass that as -- declare that as a struct, ah, create a buffer... Pass that as an argument to my shader, and output to it using the vertex ID.
In fact, I can pass up to 31 buffers if one is not enough. You notice I'm not returning anything here because of the return type. But I could have returned the same struct here, or I could return something completely different. So you have a lot of flexibility here. All right.
So that's per-vertex inputs/outputs. Per-fragments are a lot simpler. There's only one way of doing things here.
So, the inputs to a fragment shader are typically the outputs of the vertex shader because they go to the rasterizer and they generate fragments and that's the inputs.
So what can I -- must be declared in with this stage-in qualifier.
Sometimes the raster also generates information that you may actually want to know about, like, "is my triangle front-facing?" Or if I'm doing multi-sampling.
So things like that, you can use attributes to identify these inputs. And if you wanted to program a blending, you want to read the frame buffer color value. So, you can.
So let's talk about how I do that. So here's an example.
In this case, my fragment input was the output of the vertex shader. So I used the staging qualifier to say that this is a per-fragment input.
I want to read whether the triangle is front-facing or not. So I use this attribute to identify that this front face is a front-facing variable. And I also want to do blending in my shader. So I'm going to read front color attachment 0.
Though I passed as a separate arguments here, they don't have to be. I could have declared them in the struct itself, okay? Outputs from a fragment shader work just like outputs from a vertex shader. You can't write to memory though. Only the first one. So you only return type. And you can return a scalar, vector or user-defined struct. A lot of flexibility here. But the only thing you can return in a fragment shader is a color, a depth or a sample mask. And we need to know so you have to four color attachments, one depth. And sample mask. We need to know what you're writing to. And so you identify them with attributes, okay? So in this example, I'm just returning a single and a color value back. This is going to be returned to color attachment zero.
Here's another example where I'm returning more than one color. And notice here that the color attachments don't have to be in the right order, okay? They can be sparse.
All right, you guys ready for some matchmaking? All right, so I've written, you've written a vertex shader and a fragment shader. I want to pair them because I can't do the RenderPipeline without it. So how do I pair? What are the rules? The simplest rule is that types match.
That means the return type of the vertex shader is the input to the fragment sharer. In this example, that's what it is.
And this will always pair, okay? But that's boring. I want to just, I want to declare my own struct as my input to my fragment shader, and that can be a subset. In fact, that's typically very common if I use one vertex shader with many, many fragment shaders. So where's the rule here then? How do I pair? The rule is really simple. For anything that's an input to the fragment, it's attribute name and type must exist in the vertex output. So in this example, you know, I have: position is a float4 in my fragment input.
It exists, and it's the same! Same thing for this attribute, user(T). So anything that's not a built-in variable, you can come up with your own name. It just needs to use the user-parentheses, braces, and tags.
So that's the same thing here.
And so if I create a vertex shader and a fragment shader that uses these types, they will pair.
Note that there is no requirement that all the elements that I have in my fragment input must occur in the same order. They can occur in any order, they just need to occur. That's it. All right so that's matchmaking for you guys.
Okay? All right, my favorite topic: math.
Is anyone interested in math? But why? Well because the two common operations you guys are going to do are loads and stores. And the rest is math.
By default, all operation math operations in Metal are in fast math mode. So want to make sure you get the absolute fastest experience of your shaders running on the GPU. Did anyone say, "well, if you want to give me fast mode, why do I care about precise mode?" Well because, you know, fast mode comes with some caveats, it's fast.
So sometimes, like in fast mode, we tell you behavior of NaNs is not defined. So NaN is not a number.
Well then what do I care about that? It's not a number. "I'm not going to do math on a not-a-number," you're like. Well, sometimes you do.
So for example, if I'm clamping an input with some minimum and a maximum, if I pass an input that's NaN, in fast mode we're going to say "ah, we don't know what the answer is going to be." But if you actually follow iTripoli's rules, there's guaranteed defined behavior. And you may actually care about that.
Or, let's say you're using trigonometric functions in your shader.
In fast mode, they work great over a small range.
If your inputs go above and beyond that range, behavior is undefined.
So, let's say you want correct behavior for those.
Then you want to use precise mode.
So one option is you're going to say, "I want my entire shader to run in precise mode." You can do that. You can set the compiler option. But that may actually... So, you need to really know what you're doing before you set that option. So. But that option does exist. OK? All right, I think the more common scenario is, you know, you're going to do most of your stuff in fast mode.
There may be some functions you want to run in precise mode. So, you can do that in Metal.
Because guess what, these functions actually occur in nested name spaces. So by default, you get the fast name space. But you can call the precise math function explicitly. Okay? So that's it.
Ah! Metal standard library. So we don't do the C++ standard library. We do our own. And it is really optimized for the GPU. And I think you guys are going to love it. I think it has a nice list of functions.
It's all described in the documentation. I'm not going to cover details of these functions, but please refer to the specs, but... these are some of the functions. There's quite a few, okay.
All right, so what did we do? We covered, Richard talked about how you build a Metal application. And he showed you how to draw a simple triangle. But then he took it even further. He showed you how to do stream uniforms, okay, with multiple buffers and how to synchronize them efficiently.
Then I talked to you guys about the shading language. We went on a tour. We didn't go much deeper, but a very high-level tour. We talked about how to write shaders, given that it's based on C++, it's actually going to be really, really easy for you to write these shaders.
We talked about the data types Metal supports.
We talked about inputs and outputs to shaders. We talked about how to match them.
We talked about math.
So really, now it's your turn.
I'm excited about how, the amazing ways you guys are going to use Metal.
And we want to hear from you. We want to know how we can improve this even better. So, please come talk to us.
So, for more information, please -- Filip Iliescu and Allan Schaffer are our evangelists. Their email addresses are here, so bug them as much as you can, okay? And Jeremy talked about documentation. All documentation for both the API and the language are on our website.
Please, you can use the forums to ask questions.
But actually, there's one more session. The next session covers -- goes into a deeper dive in Metal, and we're going to talk about data power computing and tools as well.
The one session I actually wanted to highlight was what's new in the Accelerate Framework. And it actually happened yesterday, okay. But I think this is really important because we talked about sharing data structures between the CPU and the GPU. So this, actually, session talks about the same library. So I definitely recommend you go listen to it.
And that's it. Thank you for coming.
-