-
Your App and Next Generation Networks
IPv6 is growing exponentially and carriers worldwide are moving to pure IPv6 APNs. Learn about new tools to test your apps for compatibility and get expert advice on making sure your apps work in all network environments. iOS 9 and OS X 10.11 now support the latest TCP standards. Hear from the experts on TCP Fast Open and Explicit Congestion Notification, and find out how it benefits your apps.
リソース
関連ビデオ
WWDC21
-
このビデオを検索
PRABHAKAR LAKHERA: Thank you and good morning.
Welcome to Your App and Next Generation Network session.
I am Prabhakar Lakhera and with me I have my colleague Stuart Cheshire.
And this session is in two parts. For the first topic I will talk about IPv6, and for the second topic Stuart will talk about how to make your applications run faster.
We will start off with IPv6 first. Now, what's new in IPv6? IPv6 RFC was published almost 17 years back.
So you must be wondering, why are we talking about IPv6 now? We are seeing more and more of IPv6 deployment in enterprise and cellular networks.
And you want to make sure that your applications work in those networks. That is the reason we will also be mandating your applications to be IPv6 compliant. Now, we will talk more about that and what it means to you as developers, but before we do that, let's begin with a bit of history. Now, a long, long time ago, client devices had real and unique IPv4 addresses; these were the good olden days and you had end-to-end network connectivity.
However, we soon realized that we were running out of IPv4 addresses way too fast.
So we added a NAT in the middle.
Now, this works, but the larger scale NAT device is both expensive and fragile.
So carriers are now deploying IPv6 in their network. Now, with this, they again have end-to-end network connectivity and there's no translation needed in the data path. I will now show you how IPv6 deployment looks for three major cellular carriers in the USA. Now, two things are obvious here. One, all the lines are going up. And second, more than half of the subscribers are now connecting to cellular data networks over IPv6.
So that's great, right? Turns out it's actually worse for cellular carriers than it was before.
And the reason is now they are having to support both IPv4 as well as IPv6 in their network.
So what they really want to do is to drop IPv4 from their access network.
Now, when you do that, you lose connectivity to the IPv4-only part of the Internet, which is still in majority.
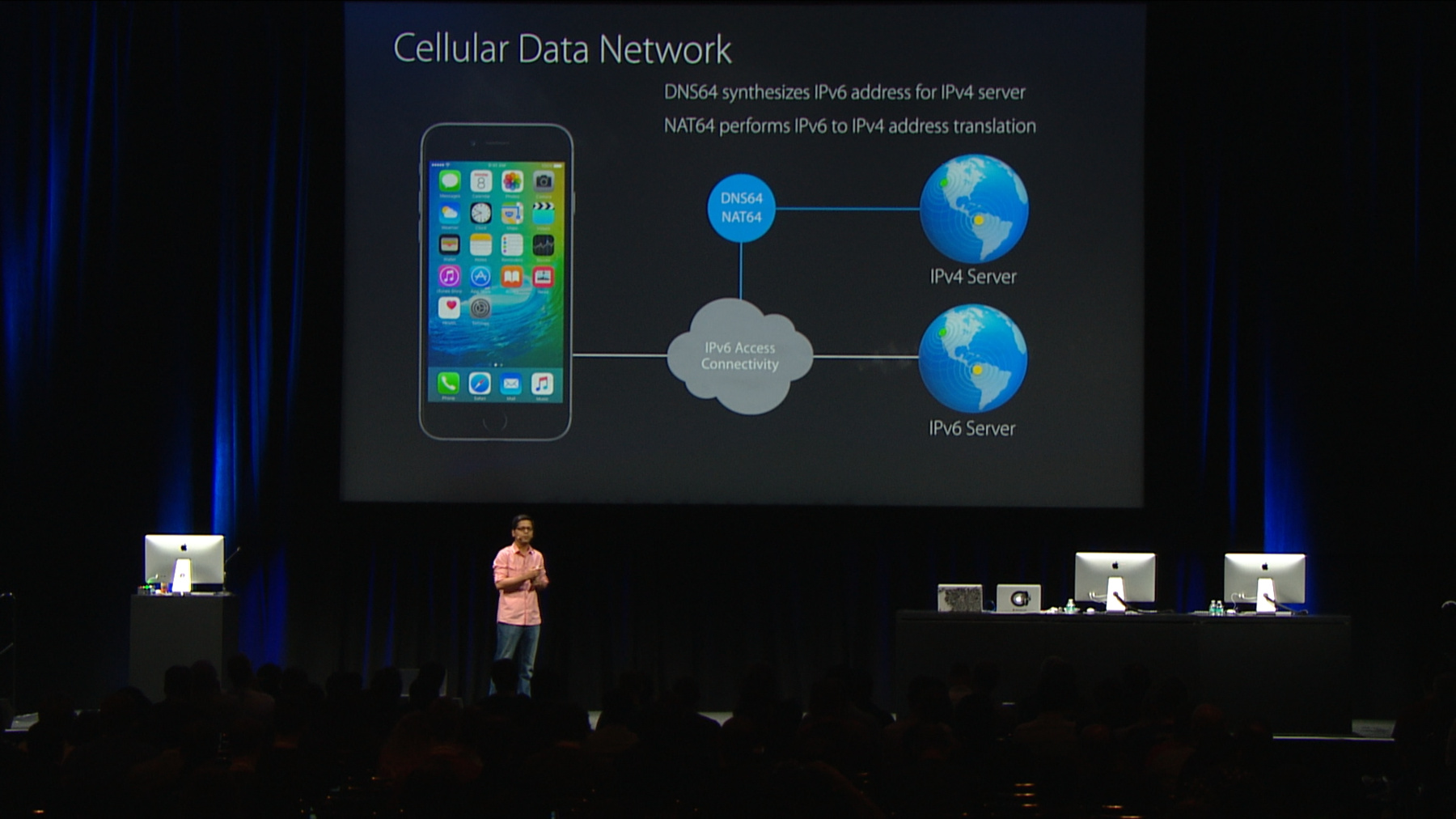
So now they have deployed DNS64 and NAT64 in their network, and the way it works is when the application on the client device makes a hostname query to get the IPv6 address for an IPv4-only server, DNS64 and the network synthesizes an IPv6 address and gives it back to the client device. Now that the client device has this IPv6 address to work with, it can start writing traffic to the network.
The network itself is configured in a way that search packets get shorted to the NAT64 engine, which then translates IPv6 traffic to IPv4 and vice versa on the way back. Now, the important thing to note here is that to the applications running on the client device, your IPv4-only server looks like an IPv6-only server.
And this is important because till now, some of you in the room may have been thinking that my server is only configured for IPv4, so I do not need to test for a client accessing it over an IPv6 network.
Your assumption just got broken. Now the transition to this type of network will happen very soon, and when it happens, we want it to be an absolutely seamless experience for our consumers.
And that is the reason your app has to be IPv6 compliant, and this will be an app submission requirement.
So great, we have a new app submission requirement, right? And you must be wondering how do I test my application for this network? Where will I find this NAT64 type of network? I have a great news for all of you.
Starting today, with just your Mac devices on top of IPv4 connectivity, you can create your very own NAT64 networks and start testing your applications. Now, this feature is meant to be used by the developers, so it's somewhat hidden, and to make it visible, all you have to do is to Option-click on Sharing, then Option-click on Internet Sharing, and now you will see everything looks just the same.
But there's a new checkbox here that says "Create NAT64 Network." So you check that, you choose your interfaces for Internet sharing, and now you can host this NAT64 network and start testing your applications.
Now, for the example here, I have my IPv4 connectivity on the Internet and I'm sharing this as an IPv6-only access network with NAT64/DNS64 on my Wi-Fi interface.
So when I start it, I see that the Wi-Fi icon has grayed out and it has an arrow pointing up.
That means now the Wi-Fi interface is in access point mode. What that really means is now it's hosting a Wi-Fi hotspot, and you can connect your other client devices and start testing your applications.
Now, a typical test bed will look like this. Now, here I have my IPv4 Internet connectivity on the WAN side, my iMac has the DNS64/NAT64 engine running on it, and it is hosting an IPv6 network on the Wi-Fi interface.
Now the application that you want to test is either installed in one of the client machines, or you could very well be testing it on a simulator that's running on another Mac device that's a client of this Internet sharing environment. So now that we have made testing easy for you, for this type of network, what we really want you to do is to make sure it is part of your development process. That is, any time you are writing a new application, or you are writing an update for your application, make sure you are testing for NAT64 network environment before you submit your applications. Now, the good news is for almost 70% of you, you will see that your applications are working just fine. And that's great, right? Just keep testing your applications, release after release and make sure there's no regression. But for almost a third of you, you will see that either your application is severely limited in a NAT64 network environment or it does not work at all.
Now, fortunately, most of the issues are simple to fix, and here's a sample list. Now, if you are using only IPv4-only data structures or IPv4-only APIs, or you are using an API that supports both IPv4 and IPv6, but maybe you're passing an argument that says that only get me results for IPv4, all of these things will make your application IPv4 only. And what that means is it will not work in an IPv6-only access network environment. Now, there's another interesting thing that we have seen with some of these applications that do not work, that sometimes there's a preflight check that checks for IPv4 connectivity even before attempting a connection.
And that is the reason sometimes you get errors like this.
So in this case, my iPhone was actually connected to the NAT64 network I had just created on my Mac device, and I could browse Internet with Safari, I could stream videos, music... I had my Internet connectivity, but for some reason this application thinks I have no Internet connectivity whatsoever. And if you read the error message it says that my device is in airplane mode, but if you look at the top bar, that's not the case, right? So what's going on here? It's precisely the application making a preflight check to check for IPv4 connectivity, and if you remember, in IPv6-only access network like NAT64 network, you do not have IPv4 connectivity; the entire world looks like an IPv6-only world to you. Even the IPv4-only server looks like an IPv6-only server. So if you do this check, it will fail.
Now, in this case, application is saying retry. So I retried and it gave me the same error message, and then I retried again, and the same error message. And it never went off, and I was just stuck with this application.
So, what are the recommendations? Well, just attempt a connection.
Right? If it connects, that's great. If it does not, then handle that case gracefully.
The second recommendation would be to use higher networking frameworks like NSURLSession or CFNetwork API, and the reason is networking with multihome devices like iPhone and Mac devices can be somewhat complex. Like for iPhone, you have Wi-Fi interface and you have cellular interface. And with Mac devices, you may have multiple Ethernet interfaces, and you have a Wi-Fi interface also, and at a given time, you may have different kinds of connectivity to all these interfaces.
Now, which interface you use and how to connect which type of connectivity do you use for a given destination, writing that code yourself can be a lot tedious. So please use higher networking frameworks. It will make your application code a lot cleaner and simpler. Now if for some reason you cannot use a higher networking framework and if you are having to work with sockets, we will definitely recommend you to read RFC 4038, and it talks about in great length how to write your applications in a way that's address-family agnostic.
Now, our final recommendation would be to use hostnames when possible and not to use IP address literals, whether IPv4 or IPv6. When you are writing your very own protocol, a proprietary protocol, or when you are writing your application, make sure you are not using IP address literals but preferring hostnames. And the reason is, remember, in a NAT64/DNS64 network environment, the client device first has to make a DNS query, right? To get the IPv6 address for the IPv4 server. So you have to work with the hostname. If you are working with an IPv4 address literal, the client device will not make that DNS query, and the DNS64 network will not synthesize the IPv6 address for you. So, given that, we do understand that sometimes there's no way to avoid working with an IPv4 address, and an example of that would be Safari. So you go to a web page, it loads up just fine. But within the web page, there may be some other links, and some of those links may have IPv4 addresses embedded.
Now, before today, on Safari if you clicked on one such link, it would not load up.
Starting iOS 9 and OS X 10.11, not only Safari but any user of NSURLSession or CFNetwork API will be able to work even with IPv4 address literals in a NAT64/DNS64 network.
The way it works is when you are using hostnames, the DNS64 in the network is synthesizing IPv6 addresses for you.
But when you are working with an IPv4 address literal and using one of the higher networking API, the OS is discovering what the network would have done and how it would have synthesized an IPv6 address for you, and it will do that locally. So this is another reason why you should be working with higher network frameworks. So please do that. Now, with these data points and with the new tool, we really hope that you will be able to find and fix issues with your applications.
Now, what we want you to do is after this session is over, install the seed build on your Mac devices and start creating your very own NAT64 networks, and then use them to test your applications.
Now, remember this will be an app submission requirement.
So please take this message to other developers who are not in this session and also take this message back to your company and make sure you are doing NAT64 testing for your applications. Now, with that, I now invite Stuart Cheshire to talk about other networking features we have for you that make your applications faster and be more responsive to the users. Stuart? STUART CHESHIRE: Thank you, Prabhakar.
What I want to talk about now is making your applications run faster.
In the last couple of decades, we have seen a phenomenal increase in network throughput.
I remember a time when the 56-kilobit modem was the latest technology; now we live in a world where 50 megabits per second is quite commonplace.
But things don't feel a thousand times faster.
We still spend a lot of time sitting waiting for a web page to load. And why is that? It's because our industry has put a huge focus on increasing throughput and it has sorely neglected the other sources of delay.
The speed of light hasn't gotten any faster and we can't do anything about that, but there are other areas of delay that we can fix and it's time for us to start doing that.
So that's what I'm going to talk about today.
I'm going to talk about four sources of delay when users are using your applications.
The first one is the delay that happens when you have weak Wi-Fi connectivity, and connection attempts are not succeeding.
The second area is a technique called Explicit Congestion Notification, which along with smart queuing reduces delays in the network.
The TCP NOTSENT Low-Water Mark option reduces delays in the sending machine, and then we are going to finish up with a sneak peek of an exciting new technology called TCP Fast Open.
So let's start off with reliable network fallback.
I'm sure everybody in this room has had the experience at the end of the day: They leave work. They go out to their car. They pull out their phone. You want to check maps, weather forecast, email, whatever, and you are staring at the phone and it's not loading and it's not loading and you are walking to your car, and it's still not loading and you get frustrated, you go into Settings, you turn Wi-Fi off. Now you're on LTE and bam! The page loads.
And then you forget to turn Wi-Fi back on, and a week later you've got a huge cellular data bill that you didn't want. Well, that's not a good user experience. What we are doing now is we have some intelligent logic about doing parallel connections.
So if your iPhone thinks it's on Wi-Fi, but the TCP connection setup attempt is not succeeding, then very rapidly, it will initiate a second parallel connection over cellular data. Now, it won't kill the Wi-Fi connection. It won't give up on it. It will let that one continue to run in parallel and if that one completes first, that's great. You have a connection over Wi-Fi. But if it doesn't, and the cellular connection completes first, then that's the connection your application will get with a delay so short, the user won't notice anything odd. Of course, we only use this for apps that are allowed to use cellular data. If the user has gone into the settings and turned off mobile data for that app, we won't do the fallback.
And if we do fall back, then we hide the Wi-Fi indicator, so now the user knows they are not on Wi-Fi anymore. This is something that you get for free, as long as you are using the higher layer APIs, and you should see no difference in your applications apart from a better user experience.
There's one additional thing you can do, and that is when you are running over cellular, whether you started on cellular or whether you fell back to cellular, doesn't matter. The user can walk back in range of Wi-Fi and at that point, if you pay attention to the Better Route notification, you can then decide what to do about that. You may want to tear down the connections you have and reconnect over Wi-Fi, or if you are 99% of the way through sending an email, you may want to just let that complete, but by paying attention to the Better Route notification, you can make an intelligent decision that minimizes the user's cellular data bill.
My next topic is delays in the network.
And this is something that came out of work I did on Apple TV. We are working on trying to make Apple TV more responsive and understanding where the delays came from. And I expect everybody in this room has heard about bufferbloat.
I did some experiments, and I want to share the results of those experiments with you so you can understand too how critically important it is for all of our applications and products that we fix bufferbloat in the network.
I tested a simulated network environment with a 10-megabit downstream connection, which is plenty for watching streaming video, and first I'm going to show you the results using a representative network setup, a simpleminded first-in, first-out queue where packets are buffered until the queue is full and can't hold anymore, and then the new arrivals get dropped. This is very typical of consumer home gateways today. And then I will show you a comparison using smarter queuing and ECN.
I'm going to show you some plots generated using tcptrace.
I expect many people in this room have used tcptrace, but if you haven't, I strongly urge you to go to TCPtrace.org and download it.
If you are working on networking code, and you are not using tcptrace to look at your packets, then you have no way to really know what is going on or understand the performance characteristics of your app and your protocol. When we write apps, we pay attention to the memory usage. We profile the code to find out what's taking the CPU and then we optimize the code that needs it to improve CPU efficiency and improve battery life.
To do those things, to care that much about CPU and memory, but neglect the networking part doesn't make any sense. And tcptrace is the tool that lets you do similar kind of profiling and analysis of your network traffic. Here's a TCP trace of the first 10 seconds of some streaming video. For those of you who haven't looked at tcptrace before, I will give a quick overview. The little white lines represent data packets.
The horizontal position of that white line tells you the moment in time where the packet was captured.
The height of the white line tells you how many bytes of payload are in the packets, and the vertical position of where that line appears tells you where those bytes fall within the overall logical TCP sequence number space.
So here we can see a stream of packets being sent out in order, spaced a few microseconds apart.
One round trip later, we get the acknowledgment back from the receiver saying it was received.
And that green line is the cumulative acknowledgment line. Everything up to and including the green line has been acknowledged by the receiver. So we should never see any white packets below the green line. That would indicate a bug, and we don't see any white packets below the line, so that's good. The yellow line indicates the receive window. When you open up a TCP connection, the receiver indicates how much RAM it has put aside for your data, and you should not exceed the amount of RAM that you have been allocated. If we see any white packets above the yellow line, then that would be a bug, and we don't. So that's good. This looks look a relatively nice, straight line data transfer. The slope of that curve is exactly 10 megabits per second, which is what we expect, but every few seconds, we see something like this going on. So let's zoom in and take a closer look at what's going on down there.
There is so much information on these TCP trace plots, I could spend an hour just talking about this one slide. But we don't have time for that, so I will just cover some highlights that jump out just with a glance at this plot.
One is the white packet line is kind of pulling away from the green ack line. What that means is the rate that we are injecting data into the network is faster than the rate data is coming out of the other side and being acknowledged. Well, if we are putting it in faster than we are pulling it out, something has got to be going somewhere. It's sitting in buffers and we can see that the amount of stale data sitting in buffers in the network is growing. And because the amount of buffering is growing, that means the round trip delay between when a packet is sent and when it's acknowledged is getting longer. When we have so much buffered that the gateway can't buffer anymore, we start losing packets. And then this mess happens, and it really is quite a big mess, because packets are coming into the tail of the queue faster than the queue is draining, and we get a packet, we lose it, we get another one, we lose it. The queue drains a bit, we get a packet, we accept it. So, at the tail end of the queue, it's carnage. It's get a packet, lose one, lose one, lose one, get one, lose one.
But over at the front of the queue, we've got 200 packets queued up, in order, they are neatly going out over that 10-megabit bottleneck link, in order, no gaps, no problem. It's only after that entire queue has drained that we actually witness the results of that packet loss carnage at the receiver; that gets reflected back to the sender in the selective acks and the recovery starts. So this is a big mess.
Because of the way networking APIs work, data has to be delivered in order.
If you lose one packet, then all the packets that arrive after it get delayed in the kernel until the gap has been filled in. Now, there are good reasons for this. People have talked many times about out-of-order delivery, but it turns out with almost all applications it's hard to use data out of order. If you are trying to decode H.264 video, having frames that depend on an I-frame you don't have is not helpful. So it turns out that in-order delivery really is the model that applications want. Because of that in-order delivery, we get these long plateaus where no data is delivered. And for the Apple TV, video playback process, that equals a period of starvation where it's getting no data. And because we don't want the video to freeze, that's why all streaming video applications need a playback buffer.
And having a big playback buffer is why when you watch a streaming video, you see that spinning wheel saying buffering, buffering, buffering, because it has to fill up the playback buffer so that it can weather the storms when no data arrives for a long period of time.
When the missing packet arrives, we then fill in the gap and deliver it all at once.
That puts an excessive burden on the network receiving thread which takes away CPU time from the video playback threads, and that results in the stuttering of the smooth video playback. So that's bad. So this uneven delivery in the network has bad consequences for a device like Apple TV; when we are trying to make a very affordable, cost-effective device, these long plateaus of starvation equate to needing more RAM in the device for more buffering and slower video start-up and a poor user experience.
And these spikes in delivery result in needing a faster CPU in the device than we otherwise might have needed, which pushes the price up. So this uneven delivery is very damaging for streaming video.
One interesting thing to note, though: If you visually track the slope of the yellow ack line -- the yellow window line and the green ack line, you'll see that at the end of the trace, they pretty much end up back where they should have been, if no loss had happened because TCP does do an awesome job of filling in exactly what needs to be retransmitted, exactly once, and not retransmitting anything that didn't need to be retransmitted. So it gets back to where it should have been.
If you measure this network using Iperf and look at the number that comes out, it will tell you 10 megabits per second, and you will say thumbs up, my network is working perfectly.
But distilling all of this information down to a single figure loses all the subtlety of what's really going on on the network. So now that I understood what was going on and causing the sluggish performance, I decided to experiment with a smarter network. For this experiment, I used a smart cueing algorithm called CoDel, which is short for Controlled Delay.
The way it works is instead of filling the queue until it overflows and loses data, it monitors the state of the queue and as soon as a standing queue starts to build up, then it considers that to be a sign of congestion.
And when I say congestion, a lot of people think I'm talking about something that happens rarely at peak times, and it's not. It's important to understand that in networking, congestion is what happens all the time. It's the steady state of the network. It's the job of any transport protocol like TCP to maximize its use of the network, to find out how much the network can carry and make the best use of that. And the way a transport protocol does that is it sends data faster and faster and faster. It keeps probing and it keeps trying a bit more, until it loses a packet, and then it knows that was too much and it backs off. So it's constantly doing this hunting to track to find the right rate and what that means is it's always pushing the network into congestion, and then backing off, and then congestion and backing off.
What CoDel does is not wait until things have gotten really, really bad before it signals congestion. As soon as the first sign of it starts to happen, it tells the sender.
The other thing that I did for this experiment was instead of indicating congestion by losing packets, which requires a retransmission, we used a new technology called Explicit Congestion Notification, and that way the smart queuing algorithm, instead of dropping the packet, it sets a bit in the IP header saying congestion experienced. That is echoed back to the sender and it responds by slowing down without the destructive effects of a packet loss. So this is our graph of the same data transfer, using CoDel and ECN, and if I zoom in to the same part we were looking at before, you can see an absolutely phenomenal difference. When I was doing these experiments, I had planned a week to do the work and gather the data, and I was finished after two hours. I did one plot with the standard configuration and one plot with CoDel. This is my first experimental run that I'm showing you. I was expecting to have to tweak parameters and retry and rerun the experiment. No. This is -- the difference is that obvious, that one trial was all it took. I'm hearing applause. Thank you. We have no plateaus of starvation. We have no spikes of peak delivery. Every time the slightest hint of a queue builds up, we get these little polite nudges from the CoDel algorithm saying slow down. The CWR on that plot is Congestion Window Reduced. That's TCP's acknowledgment saying message received and understood; I have slowed down. Absolutely wonderful! So, simple summary, CoDel and other smart cueing algorithms are great. ECN are great. Put them together, it's totally awesome.
So if it's so great, where is it? Well, historically, packet loss and retransmission has not caused big problems for the traditional networking applications like file transfer and sending email.
When you transfer a file, the transport layer in principle could send the first packet last and the last packet first and all the ones in the middle in a random order; as long as they all get there and they are reassembled in the correct order you have your file, and that's all you care about. But when you are watching streaming video, you don't want to see the end first, and the start last. You want it in order. So in order delivery has become a much more pressing problem, now that we are using the Internet for streaming video.
One way I characterize this is that we used to have applications like clicking send on an email, where you have a predetermined amount of data and how long it takes to send it is variable.
Basically, the time you'd like the network to take to send your email is as little as possible. There's really no such thing as sending an email too fast.
So the time is variable. You would like it to be fast. Now we have applications where you are watching a two-hour movie, streaming over the Internet.
It doesn't help to watch it in half an hour or in eight hours. It has to take two hours.
So now we have adaptive applications where the time is fixed but the amount of data that could be sent in that time has to adjust to accommodate the network conditions.
Where are we now? Well, amazingly, because it is in Linux and turned on by default, more than half of the top million web servers in the world already support ECN, which is phenomenal adoption for a technology that no one is using. Clients. Well, the clients are not asking for ECN connections. They are not requesting ECN because pretty much none of the Internet supports ECN marking. So if you turn on that option, there might be some risk of exposing bugs and there's no immediate benefit.
What are the routers doing? Well, none of the routers are doing marking because none of the clients are asking for it, so why put engineering into something that might have risk that no one is asking for? Well, I'm happy to announce today that Apple is taking the initiative to break this log jam. In the seeds that you all have, ECN is now turned on by default for all TCP connections for all applications. We're not expecting to see any problems; in our testing, everything has gone smoothly. I have been running it on my own laptop for a long time; of course, we want to hear your experience. Please take the seed builds, run them on your networks at home, at work, in your hotel, at the airport, and as usual, if you find any bugs, please report them to Apple. If we are successful, in a few months' time we could have a billion devices running ECN, and that should be enough incentive for the ISPs to start offering that service. Now we are going to move on from network delays to end system delays.
Like many advances in technology, this was borne out of a personal pain point for me.
I use screen sharing to connect to my Mac at home, and it's absolutely wonderful. Being able to control it remotely, being able to access data on it, being able to start a long video transcode going that I want to have finished when I get back home: these are all wonderful things.
And at the time I was doing these experiments, I had a fairly slow DSL line.
And, of course, DSL is asymmetric. It's typically ten times faster in the downstream direction than the upstream direction, and when you are doing screen sharing, the data is coming in the wrong direction in that sense. So it's kind of to be expected it will be a bit slow.
It's like the famous joke about the dancing bear: when you see a dancing bear, you are not supposed to be impressed that it dances well. You are supposed to be impressed that it dances at all. So for many years, like many of us, I kind of suffered with this painful, barely usable experience, and I would find that when I clicked on a menu, it took three or four seconds for the menu to appear, and after a few minutes of using the computer this way, it's really, really frustrating. There were times it felt like it would be quicker to drive home and do it. And I had been working on bufferbloat and excessive queuing in the network. So naturally, that was the first thing I blamed, and I started digging in. I started investigating. I was all ready to be thoroughly indignant about this stupid DSL modem that had all of this excessive bufferbloat in it. And I pinged the machine, and the ping time was 35 milliseconds, but when I click the mouse, it takes 3 seconds for a menu to appear.
So now I'm realizing this is not as obvious as I thought. Where is the delay coming from? Well, I did some investigation.
The default socket send buffer at that time was 120 kilobytes, my throughput was about 50 kilobytes a second, so that's about 2.5 seconds, which was about the delay I was seeing.
Now, the socket send buffer serves a very important purpose.
When we use a transport protocol like TCP, if it just sent one packet and waited for the acknowledgment and one packet and waited for the acknowledgment, we would get terrible performance. We need multiple packets in flight; we need enough packets in flight to fill the bandwidth delay product of that path to the destination and back, and those packets have to be buffered so that if they are lost, they can be retransmitted. That's all good and useful and necessary to maximize the throughput of that connection. But any excess buffering above that requirement just adds delay for no benefit. It doesn't help the throughput. It just adds delay.
And we end up with something that looks like this. We have a little bit of data in flight, which is buffered, in case it needs to be retransmitted, and we have a whole lot, just sitting in the kernel waiting for its turn to go out.
Well, this was an eye-opening revelation for me. There aren't just delays in the network. There are big delays in the hosts themselves.
Screen sharing would grab a frame, put it in the buffer, grab a frame, put it in the buffer, grab a frame, put it in the buffer, and then the kernel would let those frames mature like a fine wine before it was time to put them out on the network. Because of that, we came up with the TCP NOTSENT low-water mark socket option. When you send that option, the socket send buffer remains unchanged.
The difference is that kevent or your run loop will not report the socket as being writable until the unsent data has drained to some fairly low threshold, typically 8 or 16 kilobytes works well.
When the socket becomes writable, you then write a single useful atomic chunk into the buffer. You don't loop, cramming as much data into the kernel as it can take, because RAM is cheap these days, it can take a lot.
You just write a sensible unit. And in the case of screen sharing, that's one frame.
And now the picture looks like this.
We have data in flight, that's buffered. We have a little bit waiting for its turn to go out.
As that drains and reaches the threshold, the socket becomes writable. We write a single chunk and let that drain before we write some more. So with that, I would like to show you a demo of this in action.
Here I'm using screen sharing from this machine, connecting to this.
I'm using a gateway running sarawert to simulate a DSL performance connection.
And let's bring up a Terminal window.
Okay, there we go.
I'm going to move this window.
You can see the mouse pointer move because it's generated locally. The actual graphical updates are generated by the remote machine. So let's move this window over here. No, not over here. So let's move it -- actually, no I like it back where it is. Hands off the keyboard.
Let's pull down some menus: Shell.
There we go. Let's look at Edit. No, maybe View.
If this feels like a demo that's going painfully badly, this is what my life was like trying to use my computer remotely. It takes the patience of a saint to put up with this.
Well, now I have a new option. Let's turn on the not sent low-water mark, and once we reconnect, now I will try dragging this window around.
Thank you. And that was years of suffering unusable screen-sharing connections just for the sake of a silly oversight in the BSD networking stack.
The great news is that we have fixed this.
It is available in -- it's now being used by screen sharing in the last software update in 10.10.3, so if you noticed that screen sharing seemed to get a lot more snappy, then this is the reason why. It's used by AirPlay, and it's available in Linux too because this option applies at the source of the data on the sending side. So for those of you who are running Linux servers, this option is available for your servers too. The benefit of this delay reduction is really obvious for real-time applications.
And we started making slides for this presentation where we had two columns. We had the apps that should use the low-water mark option and the apps that shouldn't. And we couldn't think of any to go in the shouldn't column. Every time we thought of a traditional app like file transfer, well, that doesn't need it. We realized you've had that experience where you change your mind about a file transfer and you press Control-C and it seems to take about 30 seconds to cancel.
It's because it had over-committed all of this data into the kernel and it had to wait for it to drain because there's no way to change your mind. So, yeah, actually, file transfer does not benefit from over-committing data, and we couldn't think of any application that does benefit from over-stuffing the kernel. So once we had that realization, we decided starting in the next seed, this option will be turned on automatically for all connections using the higher layer NSURLSession and CFNetwork APIs.
All you have to do to make best use of this is when your socket becomes writable, don't loop writing as much data as you can until you get an EWOULDBLOCK. Just write a sensible-sized unit, and then wait to be told it's time for more. And that way if the user has changed their mind or something else has changed about the environment, next time you find your socket is writable, you can make an intelligent decision.
You can do just-in-time data generation where you generate the data so it is as fresh as possible and based on the current information, not based on the information from five or ten seconds ago. And that brings me to our final part of the presentation, and that is a sneak peek of a brand-new technology called TCP Fast Open. The way TCP traditionally works is this: we do one round trip to set up the TCP connection.
And then we do a second round trip to send the request and get the response.
TCP Fast Open combines the connection setup and the data exchange into one packet exchange.
This is not turned on by default for all applications and there's a reason for that. There is a caveat you need to be aware of, and that is that this is only safe for idempotent data. I'll explain what that means. When you use a TFO operation, the handshake and data are combined, the server gets the message, the server acts on that, sends you the response, and then you close the connection.
But the service model of the Internet doesn't guarantee that packets can't be duplicated.
The success of the Internet has been due to a very simple service model, which is deliver the packets fast and cheap. And don't worry about them being in order. Don't worry if some get corrupted, some get lost, some get duplicated, just be fast and cheap.
And the end systems are smart enough to deal with that network model.
Packets can be duplicated for many reasons. It could just be a bug in a router, it could be Wi-Fi link layer retransmission that accidentally sends the packet twice. It could be end-system retransmission: If you send a packet and don't get an acknowledgment because the acknowledgment was lost, perhaps, you will then retransmit the packet and then immediately you've got two copies of the same packet in the network. Well, if one of those copies is delayed and shows up much later, then to the server that looks like a perfectly valid TFO request, and whatever the operation was, it will do it again.
If that operation was sending you a JPEG image, doing it twice may be no big deal.
If that operation was sending you a pair of shoes from Zappos, then doing it twice might not be what you want. So this is something where you have to intelligently decide when it's appropriate and safe and when it's not for your application.
You use this through the connectx system call.
This is a sneak peek technology preview for the early adopters.
Later, we will look at how to expose this through the higher level APIs but now it's only available through connectx.
The server you are talking to has to support TFO as well, and the application has to opt in. For those of you running Linux servers, if you have the very, very latest Linux kernel as of a couple of weeks ago, that now supports the standard ITF, TFO, TCP option code, the same as OS X. So to wrap up what we would like you to remember from today's session, wherever you can, use the highest layer network API as possible and that way you get the full benefit of all the work that those APIs can do for you.
You absolutely must be testing on a NAT64 network for your applications, and thankfully we have made it really, really easy for you to do that with just an Option click. Reliable network fallback will give your customers a better user experience with your applications.
What you can do is pay attention to the Better Route notification so that you migrate back to Wi-Fi when it's available.
Explicit Congestion Notification is a new feature for the seed.
It will enable the Internet to move to this much more responsive mode of operation with lower queuing and lower packet loss. So we would like you to test that and report any problems.
The TCP NOTSENT Low-Water mark is something that you can set for yourself as a socket option or get for free starting in the next seed, and that will reduce the amount of stagnant data buffered in the sending machine.
And then finally, for the people excited about TCP Fast Open, we've made that available too.
There's a bunch of sources of good documentation that you can look at. I'm not expecting anybody to write down these URLs; you can click those in the PDF version.
There are some good forums where you can ask questions and have discussions with questions you have about networking.
I encourage you to watch the videos of the NSURLSession presentation and the Network Extensions presentation and, of course, come and join us in person after lunch in the networking lab and we can answer all of your questions there. Thank you. [Applause]
-