-
Natural Languageフレームワークの最新情報
Natural Languageは、すべてのAppleプラットフォームで自然言語処理タスク用のハイパフォーマンスなオンデバイスAPIを利用できるようにするためのフレームワークです。このセッションでは、Natural Languageフレームワークに追加されたセンチメント分析およびテキストカタログのサポートについて説明します。テキストベースのモデルで利用できる転移学習や、Appの検索機能を強化できる単語埋め込み機能に新たに対応したことについて、より深く理解していただけます。
リソース
関連ビデオ
WWDC23
WWDC20
WWDC19
-
このビデオを検索
(音楽)
(拍手) こんにちは 皆さん Natural Languageの セッションへようこそ 私はヴィヴェク 同僚のダグと 一緒にセッションをします では始めます
ご存じのようにテキストは ユビキタスです どこでも見つけられます テキストでインタラクティブな 使用方法を考える場合― 主なモードが2つあります 1つはNatural Languageによる入力です ユーザがApp内でテキストを 書き込んだり生成したりします ユーザがアプリケーション内部の キーボードを使う場合があります
例えばメッセージがあります テキストを書いて他人と共有します メモや生産性のある他のAppにも 書き込めます
もう1つのインタラクションは Natural Languageによる出力です アプリケーションがユーザに 表示したテキストを― ユーザが 使用したり読んだりします Apple Newsのような アプリケーションでは 情報やテキストが表示され ユーザがこれを読みます テキストの入力と出力 どちらの場合も― プレーンなテキストから 実行可能な情報を引き出すのに― Natural Languageが重要です 昨年 発表した Natural Languageフレームワークは 全Appleプラットフォームでの NLPの主力製品です 我々が提供する NLPビルディングブロックは 言語識別 トークン化 品詞タグ付けなどです これらの機能は 複数の言語で提供されます シームレスに一体化した 言語と機械学習により このAPIでの App作成だけに集中できます 難しく手間がかかる部分は Appleが担当します
元に戻って全機能を見てみましょう 最もNLP機能らしい部分は― 大きな2つのタスクカテゴリに 分けられます 1つはテキスト分類です テキスト分類のオブジェクトに 1つのテキストを与えます このテキストは1文でも1段落でも 1文書でも構いません このテキストにラベルを 割り当てます ラベルはセンチメントやトピックなど 割り当てたいものです NLPによるタスクの他のカテゴリは 単語のタグ付けと言います タスクまたはオブジェクトには トークンが与えられます このシーケンスの全トークンに ラベルを割り当てます 今回 この2つのタスクの 新しいAPIを紹介します まずセンチメント分析から 始めましょう センチメント分析は テキスト分類APIの1つです テキストをAPIに渡すと APIがテキストを分析し センチメントスコアを生成します これはセンチメントの 度合いをキャプチャしたもの スコアは-1から+1で センチメントの度合いを示します -1は 最もネガティブな― +1は最もポジティブな センチメントを示します 我々が提供したスコアを 測定させるのです “家族とハワイで楽しく過ごした” という文を例に取ります APIがスコアを0.8とし ポジティブな文であると示します 逆に“母が足首をひねってハワイは 楽しくなかった”という文では― ポジティブにはなりません スコアは-0.8でセンチメントは ネガティブだと測定されます
どのように使えばよいでしょう? 本当に容易に使えます NaturalLanguageに 慣れている人には非常に簡単です NaturalLanguageを インポートします NLTaggerのインスタンスを作成し 新しいタグスキームを指定するだけです 新しいタグスキームを センチメントスコアと言います これを実行すれば タグ付けツールに 分析したい文字列を添付し― 文か段落でセンチメントスコアを 要求するだけです では動作を確認してみましょう
ここにあるのは 仮のチーズアプリケーションです このアプリケーションで ユーザは多くのことができます チーズのコメントやレビューを書き 様々なチーズの意見を交換できます このアプリケーションは実際に チーズの細かな点を扱います ユーザがレビューを書く場面を お見せします レビューが書かれるとテキストが センチメント分類APIに渡されます 入手したセンチメントスコアに 基づいてテキストが色付けされます 見てみましょう すばらしい味や本当に おいしいなどと入力した場合― ポジティブなセンチメントが 表示されます
逆に最初はよかったが―
後味が最悪だった場合 ネガティブなセンチメントです これが全てリアルタイムで 起こっていることも分かります APIが非常に高性能だからです ニューラルネットワークモデルは Appleの全プラットフォームに 有効なハードウェアで― リアルタイムで使用できます センチメント分析のAPIでは 7言語をサポートしています 英語 仏語 伊語 独語 西語 葡語 簡体字中国語です 実際に気に入ると思います
(拍手) これは完全にデバイス上の動作で ユーザデータは移動しません デバイスを強化するだけです 言語アセットについて 少し説明します お話ししたようにNLP機能は― とても多様なので 複数言語対応にしました アプリケーションのユーザは 興味のある言語のアセットを― 常に使用できます しかし開発側としては― アセットはオンデマンドがいいと よくリクエストされます Request Assetsという便利なAPIを 紹介します 特定のアセットのダウンロードを オンデマンドでトリガーできます 必要な言語とタグスキームを 指定するだけで― バックグラウンドでダウンロードし 適切なタイミングで入手できます 実際 開発に役立ちますし Appのビルドの生産性が向上します
テキスト分類の次は 単語のタグ付けについて説明します
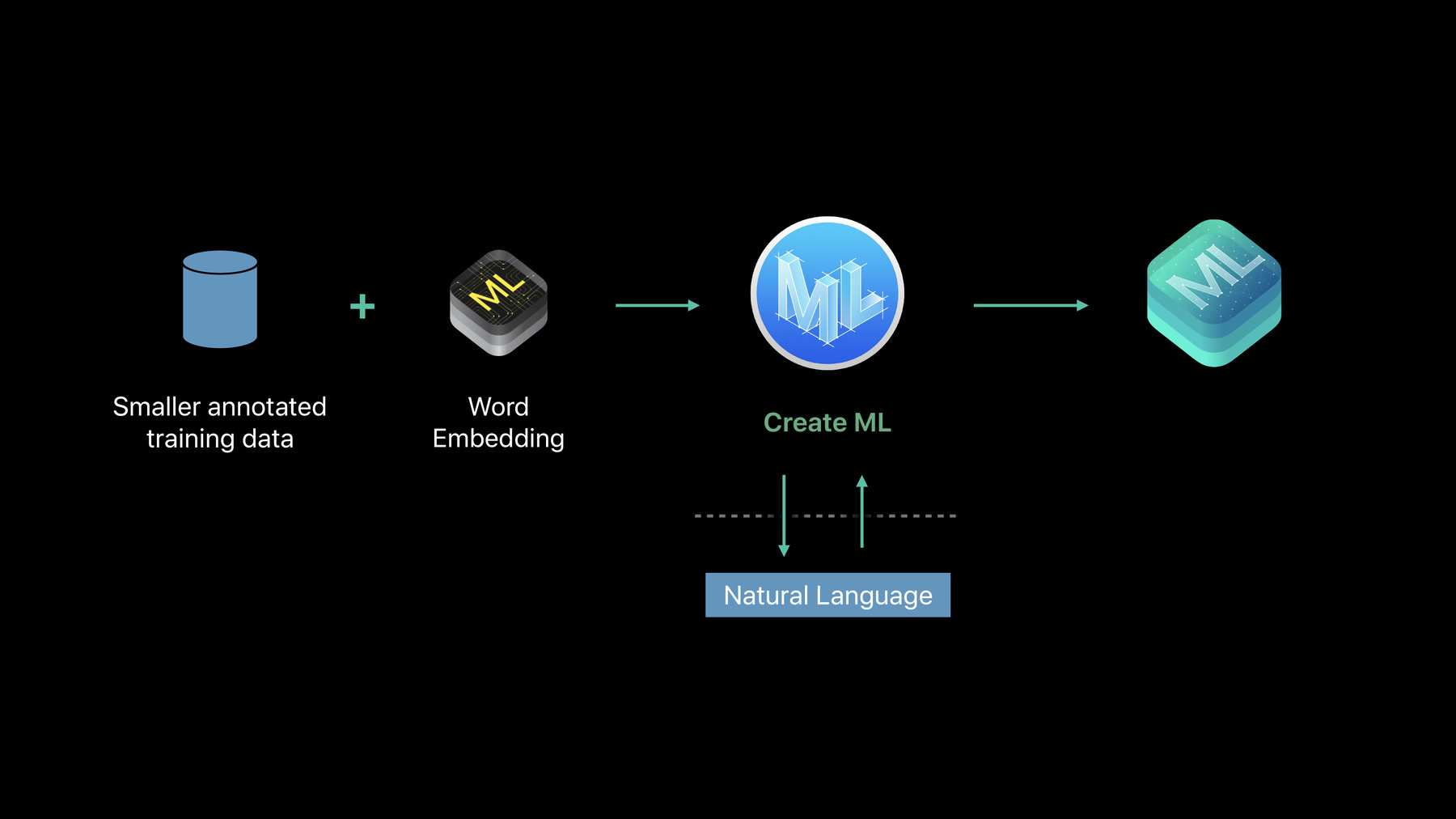
単語のタグ付けは ラベルを割り当てたいシーケンスの 単一トークン全てにトークンの シーケンスを与えるタスクです
例えば多くのトークンに別々の ラベルを割り当てるとします ティモシーは人の名前で スイスは場所の名前です このセンテンスには 多くの名詞があります APIを使用して 固有表現抽出か― 品詞のタグ付けを したい場合はいいですが カスタマイズする必要のある インスタンスもあります グリュイエールチーズが2つの 名詞だと知りたいのではなく― スイスチーズであることを 知りたいのです チーズアプリケーションなので 後者の方が重要です ではデフォルトのタグ付けツールに チーズの情報がない場合は? Text CatalogというNatural Language フレームワークの新機能があります Text Catalogはとても簡単です カスタムリストを提供するだけです リストの各エンティティに対して ラベルが作られます 実際にリストは数百万でも 数億でも構いません この辞書のような物を Create MLに渡します MLGazetteerのインスタンスを 作成します アウトプットとして Text Catalogを受け取ります これは圧縮され効果的な形式の 入力ディクショナリです
使い方は簡単で このディクショナリを提供するだけ ここでは100万のエントリではなく 2~3の例で確認します このディクショナリは 非常に膨大です ここでMLGazetteerの インスタンスを作成し ディクショナリを渡して ディスクに書き出します ただ書き込んでるように 見えますが 正しい呼び出しを行ってみましょう 内部でCreate MLが Natural Languageを呼び出します Natural Languageが この膨大なディクショナリを入手すると ブルームフィルタに圧縮し 非常に小さな構成にします 出力として入手できるのが Text Catalogです 実際にこれを使用して 内在的な効果がありました ウィキペディアでは人や組織や 場所の名前全てが圧縮され 250万ほどの名称が 2MBのディスクに収まっています
このモデルを知らない間に 使用しています NaturalLanguageの 固有表現抽出APIを呼び出す場合― この静的モデルと併せてブルーム フィルタとGazetteerを使用します これで強化されました
GazetteerまたはText Catalogを 一度作成すると使用は簡単です
ディスクに書き出したText Catalogへのパスを使用して― MLGazetteerのインスタンスを 作成します
ディクショナリ分類 名前タイプなど 好みのタグスキームを使用できます Gazetteerをこのタグスキームに 簡単に付けられます これをすると テキストが1つできる毎に― カスタマイズされたGazetteerが デフォルトタグより優先します その結果アプリケーションを カスタマイズできます “カマンベールより薄味”などの文が チーズアプリケーションにあると― チーズのText Catalogを 使用できます フランス産のチーズだなどと 分かります 皆さんはハイパーリンクを用いて もっといいAppを作成できますね
単語タグ付けツールの Text Catalogの使い方でした
テキスト分類と単語のタグ付けについて お話ししました NLPの分野はここ数年間 非常に大きく動いていました この変化のきっかけがありました 1つはWord Embeddingの概念です Word Embeddingは 言葉のベクトル表示に他なりません もう1つはNLPにおける ニューラルネットワークです
今年はNaturalLanguageを 使用する― アプリケーションで この2つを採用します
Word Embeddingの説明を始めます そうです
Word Embeddingの詳細の前に 数枚のスライドで― Embeddingについて説明します 概念の段階ではEmbeddingはただの オブジェクトの離散集合から― 連続ベクトル表現への マッピングです そのため多くの 離散オブジェクトがあります この集合の各オブジェクトは数種の 小さなベクトルで表現できます ここでは3次元ベクトルで示します 3次元はプロットも視覚化も 容易だからです 実際にはこのベクトルの次元は 任意です 100次元でも300次元でも 場合によっては― 1000次元ベクトルもあり得ます Embeddingの適切なプロパティは プロットする場合に― 意味上似ているオブジェクトを クラスタ化することです この例ではペンキの缶とはけ••が クラスタ化されます またはスニーカーとハイヒールが クラスタ化されます Embeddingの とても適切なプロパティです このEmbeddingのプロパティでは 言葉の証明というだけでなく― 実際に いくつかの違った モダリティにわたっています 画像のEmbeddingを考えてみます 画像をVGGネットワークまたは ニューラルネットワークで― 送信する場合 機能の出力は 画像Embeddingsだけになります 言葉やフレーズのEmbeddingも 同様に得られます 曲名や製品名を探す時に 推奨システムを使用する場合― ベクトルを使用して表現します これがEmbeddingです まとめると Embeddingは文字列から― 連続な数値または数字のベクトルの マッピングに他なりません
実際にiOS 12でEmbeddingを 使用して成功しています 写真でどのように使用しているか 説明します
写真の検索で特定の言葉を 入力する場合です 雷雨の写真を検索します 裏側でやっていることは 写真ライブラリの全画像に― 畳み込みニューラルネットワークで インデックスを付けます 出力はクラスの一定値に 固定されます 1000クラスか2000クラス あるかもしれません 畳み込みニューラルネットワークが 雷雨を知らない場合― インデックスを付けられた画像を 検索できません “雷雨”の文字が 付いていないからです しかし Word Embeddingsを使用すると― 雷雨は実際に空と雲に 関連することが分かります これが畳み込みニューラル ネットワークが使えるラベルです iOS 12では Word Embeddingsを使用して― 写真のあいまい検索を 有効にできます この結果として画像が見つかります これがWord Embeddingsの力です 実際にはどのAppにも適用できます ある文字列で あいまい検索をする場合― Word Embeddingsを使用して 関連する単語を検出できます
ではEmbeddingで 何ができるでしょうか Word Embeddingsでできる 主な操作は4つあります まず1単語を与えると 単語のベクトルが明らかになります 2つの単語を与えると 2単語の間の距離がわかります 各単語について 対応するベクトルがあるからです 犬と猫と言って距離を要求すると 距離が入手できます その距離は 互いにとても近くなります 私が犬とブーツと言うと― セマンティックスペースでは遠く 先ほどよりも離れます 3つ目にできることは 最も関連する単語の取得です Word Embeddingsを使用する 最もよくある方法でしょう 写真の検索アプリケーションが この方法です 1単語を与えると 最も関連する単語を検索します 最後はベクトルに最も関連する単語も 入手できます 1文あって その文には 複数の単語があると仮定しましょう Word Embeddingを入手して 文の各単語をまとめます 新しいベクトルを入手できます そのベクトルによって それに近い単語を全て要求できます これもWord Embeddingsを 使用する適切な方法です
Word Embeddingsには 多くの要素があります しかし最も重要なことは OSでこれを使用可能にすることです Word EmbeddingsがOS上で 7つの言語によって― 説明した機能を全て使用できます 1行や2行のコードでも 使用できます 7つの言語をサポートしています 英語 仏語 伊語 独語 西語 葡語 簡体字中国語です
すばらしいことです OS Embeddingsは大量のテキストや 膨大な単語のある― 一般的なコーパス上で 組み立てられています 特定の単語との関係についての― 一般的な概念があります 多くの場合 カスタマイズしたいと思うでしょう 恐らく皆さんは異なる分野で 働いているでしょう 医療系だったり法律系だったり 金融系だったりします 分野が全く異なる場合― アプリケーションで使用する 用語集が全く異なります OSでサポート対象外の言語の 訓練もしたいでしょう そちらの対策も用意しています カスタムWord Embeddingsを 使用できます Word Embeddingsの分野は 発展を遂げ― Embeddingsを訓練する 他社製のツールが多くあります word2vec GloVe fasttextなどです 自分のテキストを持ってくるか― カスタムニューラルネットワークを 使用して訓練ができます つまり生データから始めて 自分のEmbeddingsをビルドできます いずれかのWebサイトにアクセスし 訓練済みWord Embeddingsを入手します 問題なのはダウンロードする Embeddingsはどれも大きいことです 1GBか2GBもあります Appで使用するにもコンパクトで 効果的にしたいでしょう ではやってみます 他社製のAppから入手した Embeddingsが本当に大きい場合― 自動的に圧縮して 非常にコンパクトな形式にします このコンパクトな形式があれば OS Embeddingsと同様に使用できます OSとカスタムのEmbeddingsの 使用方法を説明するために― ダグと交代し 残りのセッションを彼に任せます 交代だよ ダグ (拍手)
ではここにデモ機があるので 動作を見てみましょう Word Embeddingsを体験できる アプリケーションです ここに単語を入力すると Embedding空間内で 最も関連する単語を表示します chairという単語を入力します 椅子に最も近い単語が 一覧に表示されます sofaやcouchなどです 次にbicycleを入力します 最も関連する単語は bikeやmotorcycleなどです これが自転車に近い意味の 単語になります 次はbookです 本に似た意味の単語が表示されます ここから分かるのは 内蔵OS Word Embeddingsが 単語の一般的な意味を表示し 類似性を認識して 同じ言語の一般的な文言で 表現することです もちろん ここで一番気になるのは― このEmbeddingsがチーズを 理解するかということです チーズのアプリケーションなので チーズと入力します ここから分かるのは 内蔵Embeddingsは チーズが何であるかは理解しました しかし残念なことがあります このEmbeddingsがチーズの 微妙な点を知らないと分かりました そうでなければ こんな特別なチーズと― チーズに関する物を並べません ここではチーズの関係性について 理解する物が必要なので カスタムチーズEmbeddingを 訓練してみました 類似点に基づいてチーズを 分類します そちらに切り替えましょう 自分のカスタムチーズEmbeddingsに チェダーの関連語があります チェダーのテクスチャに近い単語として ランカシャー ダブルグロスター チェシャーなどが表示されました これは使えそうなので アプリケーションに戻ります
いくつかのアイデアを 見てみましょう ユーザが入力すると― まずセンチメントスコアを確認 ポジティブなセンチメントであれば タグ付けツールを使い 全体を調べます カスタムチーズGazetteerも使用し チーズに関する記述を調べます ユーザが記述している場合は― カスタムチーズEmbeddingに渡し 関連語を検索します では試してみましょう
チーズアプリケーションを 起動します
それから― 昨年行ったオランダのチーズが 気に入ったのでAppに教えます はい
これが― 特定のチーズを参照した ポジティブセンチメントの文です 送信します これで私がコメントしたチーズを Appが提案できます Word Embeddingsの実力が 分かりました しかし他にもあります 自然で多様な NaturalLanguageAPIが― 一緒に動作します (拍手) ではスライドに戻ります APIでどのように見えるのか 振り返ります 内蔵のOS Word Embeddingを 使用するのは簡単です Word Embeddingに特定言語を 要求するだけです NL Embeddingオブジェクトで いろいろできます 特定の入力に対応する ベクトルコンポーネントも入手できます Embedding空間で2つの単語の距離が 近いか遠いか分かります チーズアプリケーションで 見たように Embedding空間の 特定のアイテムに― 一番関連する単語が見つかります
カスタムWord Embeddingを 作成するには Create MLを使用します Embeddingを表す 全てのベクトルが必要です スライドで実際に表示できませんが 50や100のコンポーネントがあります この例で様子が分かるでしょう Create MLの多種ある機能を使用し データをファイルからロードします
そこからWord Embedding オブジェクトを作成し―
ディスクに書き出します
実際には― Embeddingは 非常に大きくなりがちで 数千エンティティの数百次元にも なります 大きいと ディスク容量を消費しますし 検索に負荷がかかります Word Embeddingオブジェクトに コンパイルする場合は プロダクトの量子化技術を使用し 高圧縮を達成します そしてインデックスを追加 例で見たように最も関連する単語の 検索が速くなります 試してみましょう 実際にオープンソースで利用できる 膨大なEmbeddingsを取得しました GloVeやfasttextのEmbeddingsの ような物で 非圧縮形式で1GBか2GBあります NL Embeddingの 圧縮形式に入れると― たったの数十MBになります 最も関連する単語の検索は 2ミリ秒でできました
元に戻って… (拍手) Appleには 多くのPodcastがあります Podcastのチームと話しました 起こるべくしてPodcast用の Embeddingを作成しました 多様なPodcastとの 類似性が示されています このEmbeddingを使って NLEmbedding形式に入れてみます 6万6000種類の Podcastを表現できます ソース形式は167MBですが 圧縮すると たった3MBで ディスクに入りました NL Embeddingは効果的に― これらのEmbeddingを含め デバイス上のAppで使用できます
それでは 次の話に移りたいと思います Word Embeddingsと 関連があります テキスト分類の転移学習に ついてです
何をするか 少々説明しましょう テキスト分類器を訓練する場合 何をするか
テキスト分類器を 訓練する場合― 多様なクラスの サンプルのセットを提供します
Create MLが NaturalLanguageを呼び出します 分類器を訓練すると― Core MLの出番です 望ましいのは これらのサンプルが― 多様なクラスについて 十分な情報を与えることです そしてモデルが一般化して― 見たことのない例を 分類できることです もちろん昨年 すでに出荷しています モデルを訓練する アルゴリズムがあります 標準アルゴリズムは maxEntアルゴリズムと呼んでいます 論理圧縮に基づいており とても速く強固で効果的です
ただし提供した訓練データから 学習したこと以外は何も知りません
提供した訓練材料が基本的に― 期待する内容を 全て網羅しているかを 確認する必要があります 実際問題として アルゴリズムは作成済みなので 訓練データの生成が必要です
一方で― 言語の予備知識を活用できたら いいと思いませんか?
さらに― 少ない訓練材料と併せて それらを使ってもいいでしょう モデルの訓練のため― その2つを組み合わせます 訓練材料の妨げにならずに 例をより深く理解するためです
これが転移学習をする際の約束事です NLPではとても活発な研究領域です そのソリューションを発表し 提供できてうれしいです NaturalLanguageがモデルを 訓練した結果がCore MLモデルです では言語の事前知識を組み込む方法は?
Word Embeddingsが言語の知識を 大いに供給します 特に単語の意味を理解しています このソリューションではWord Embeddingsを使用します 提供された訓練材料を用いて― ニューラルネットワークモデルを 訓練します
これが転移学習の テキスト分類モデルです やることは多いですが 使用する場合は 要求するだけです 希望のアルゴリズムの仕様で― 1つのパラメータを 変更するだけです 転移学習モデルを訓練する場合 いくつか選択肢があります つまり― 1つ目は内蔵OS Word Embeddingsを使用できること 単語は通常の意味を示します
カスタムWord Embeddingsも 利用できます
知ってのとおり― ある単語の意味が非常に難しいのは 文のコンテキストによるからです この2文のAppleの意味は 全く違います 転移学習に使用するEmbeddingは 意味とコンテキストによって― 単語に異なる値を与えます もちろん通常のWord Embeddingは 単語をベクトルにマッピングし 表現方法に関わらず 単語に同じ値を与えます ですが―
特定のEmbeddingの訓練は 済んでいます 意味とコンテキストによって 単語ごとの値を与えます この分野の進展は速く 研究を始めてから 1年で開発しました
使用する場合は要求するだけです 動的Embeddingを指定します 動的Embeddingが 変更するのは― 文のコンテキストによる単語の Embeddingの値です テキスト分類の転移学習を行う 強力な技術です
見てみましょう
ここにあるのは― Create MLでテキスト分類を 訓練する標準コードです 訓練を実行します オープンソースを使用した データセットに基づいています DBpediaという百科事典です 多くのトピックに 短い記述があります 著名人 芸術家 作家 植物 動物 などが載っています 短い記述から分類方法を 決定することが今のタスクです 著名人なのか 作家なのか 芸術家なのか 14種類のクラスがあります 例を200だけ使用し 分類器を訓練します 非常に難しいタスクがあります 既存のmaxEntモデルで試してみましょう 実行します スタート 終了しました
とても早くて簡単です 訓練では…
テストセットでの結果を 見てみると― 77%の精度になりました さらによくできるでしょうか?
もう少しコードを― 変更しましょう 動的Embeddingsの転移学習を使用します 開始します
ニューラルネットワークモデルの 訓練は時間がかかります その間に― 訓練しているデータについて 説明します ニューラルネットワークモデルが 訓練中に― 訓練しているデータに 注意を払うことが重要です 多種のクラスにわたる ランダムな サンプルであることが分かります 各クラスのインスタンスに 同じ番号があったため― 手を加えてあります 均衡のとれたセットです これは訓練用のセットで 確認用のセットもあります クラス全体のランダムなサンプルと 同等です 大きくはありませんが 均衡はとれています 確認用セットはこのような訓練では 特に重要です ニューラルネットワークの訓練は やり過ぎになりがちです 訓練材料を記録しますが 一般化はしません 確認用セットが正当性を保ち 一般化を継続します もちろん テスト用セットもあります 同様にランダムにサンプル化し 均衡がとれています 訓練の確認用テストセットで 不正になるような重複はありません テストセットはうまく動作するかを 試すもので 転移学習モデルの動作が maxEntモデルよりも― よいかを確認します 終了したようですね 確認しましょう
こちらで分かります 転移学習が86.5%の精度に達しました maxEntモデルと比較して― とてもいいです
(拍手)
では―
チーズアプリケーションに 適用しましょう チーズの試食メモを使いました そしてチーズ毎のメモに ラベルを付け チーズ分類器モデルを 訓練しました チーズ分類器モデルは 文を取り込み― 分類して参照対象に 最も近いチーズを決定します アプリケーションに入れます チーズアプリケーションを 使ってみましょう ユーザが特定のチーズを 参照しない場合― 好みのチーズを見つけ出します モデルにテキストでのラベルを 要求するだけです
とても簡単です
やってみます
ここに入力します
するとチーズ分類器が作動して
カマンベールに 最も似ているチーズを決定します チーズEmbeddingが 似ているチーズを表示しました
つまり…
硬くて角ばった物なら チェダーだと分かります 似たチーズも推奨しています (拍手) これがテキスト分類と NaturalLanguage APIとの― 組み合わせによる強みでした テキスト分類を使用するには まず転移学習をサポートする 言語を確認します そしてコンテキストを考慮する― 静的もしくは特別な 動的Embeddingsを使用します
データについてもう少々説明します データを扱う場合の 最初のルールは― 自分の仕事の分野を 理解することです 予想されるのは 実際にはどんなテキストなのか それは文の一部か完全な文か 文章なのか 訓練データをできるだけ 予想されるテキストと同じにして― 実際に分類を試みます アプリケーションでそのテキストと 遭遇した時に 起こりうる単語の違いは できる限り網羅します DBpediaの例で分かるように 次に必要なのは
できる限りランダムな サンプルセットです 訓練用 確認用 テスト用があります 基本的なデータハイジーンです
自分のケースに適したアルゴリズムを 見つけるには 試す必要がありますが ガイドラインもあります とても速いmaxEnt分類器で 始められます maxEnt分類器は 訓練材料で頻出する単語に 注目する方法を採用しています ポジティブとネガティブを 学習する場合― 愛と幸福や 憎しみと不幸などの 言葉に注目するかもしれません 現実での例が同じ言葉を使う場合 maxEnt分類器が上手く動作します
転移学習では 言葉の意味に注目します 現実での例が他の単語でも 同じ意味を表すことがあります
これが転移学習が威力を 発揮する場面で 単純なmaxEntモデルよりいいです
おさらいです センチメント分析で利用できる 新しいAPIがあります MLGazetteerを使用する Text Catalogsにも― NL Embeddingを使用する Word Embeddingsにもあります 新しいタイプの テキスト分類があります 転移学習の際に特に強力です アプリケーションでぜひ ご使用ください オンラインで詳細が確認できます 関連する他のセッションにも ご参加ください ありがとう (拍手)
-