-
Visionフレームワークでのテキスト認識
Visionフレームワークのドキュメントカメラ機能とテキスト認識機能を使用すると、画像からテキストデータを抽出することができます。このセッションでは、このビルトイン機械学習テクノロジーをAppで活用する方法について説明します。高速な処理と正確な処理の違いと、文字ベースでの認識と言語ベースでの認識の違いについて、詳しい情報についてご確認ください。
リソース
- Structuring Recognized Text on a Document
- Extracting phone numbers from text in images
- Locating and displaying recognized text
- プレゼンテーションスライド(PDF)
関連ビデオ
WWDC21
WWDC20
WWDC19
-
このビデオを検索
(音楽)
(拍手) こんにちは フランク・ドウプクです Vision Frameworkの テキスト認識を紹介します
このフレームワークの 利用者は― 矩形検出の機能を すでにご存じでしょう 画像上のテキストを 検知します
しかし“テキストとは何か” が問題だったので― 追加コードが必要でした
結果の配列を生成します このためには Core MLモデルの― トレーニングも必要です 不要な定義を取り除き― 必要なデータのみに 絞り込みます すべての文字を 文字列に入れ― 実際に文章を構成する ヒューリスティックを作成します テキスト認識の説明は 時間を要するので―
今日は手短に話します 新機能のVNRecognize TextRequestです 今から機能をお見せします (拍手) こちらです
このような画像から―
テキストを認識します (拍手)
今日 紹介したいのは― まずテキスト認識の 機能の仕方です 複数のサンプル アプリケーションと― サンプルコードが ダウンロードできます 後半でテキスト認識の 最良の方法を紹介します 機能の仕方から始めます
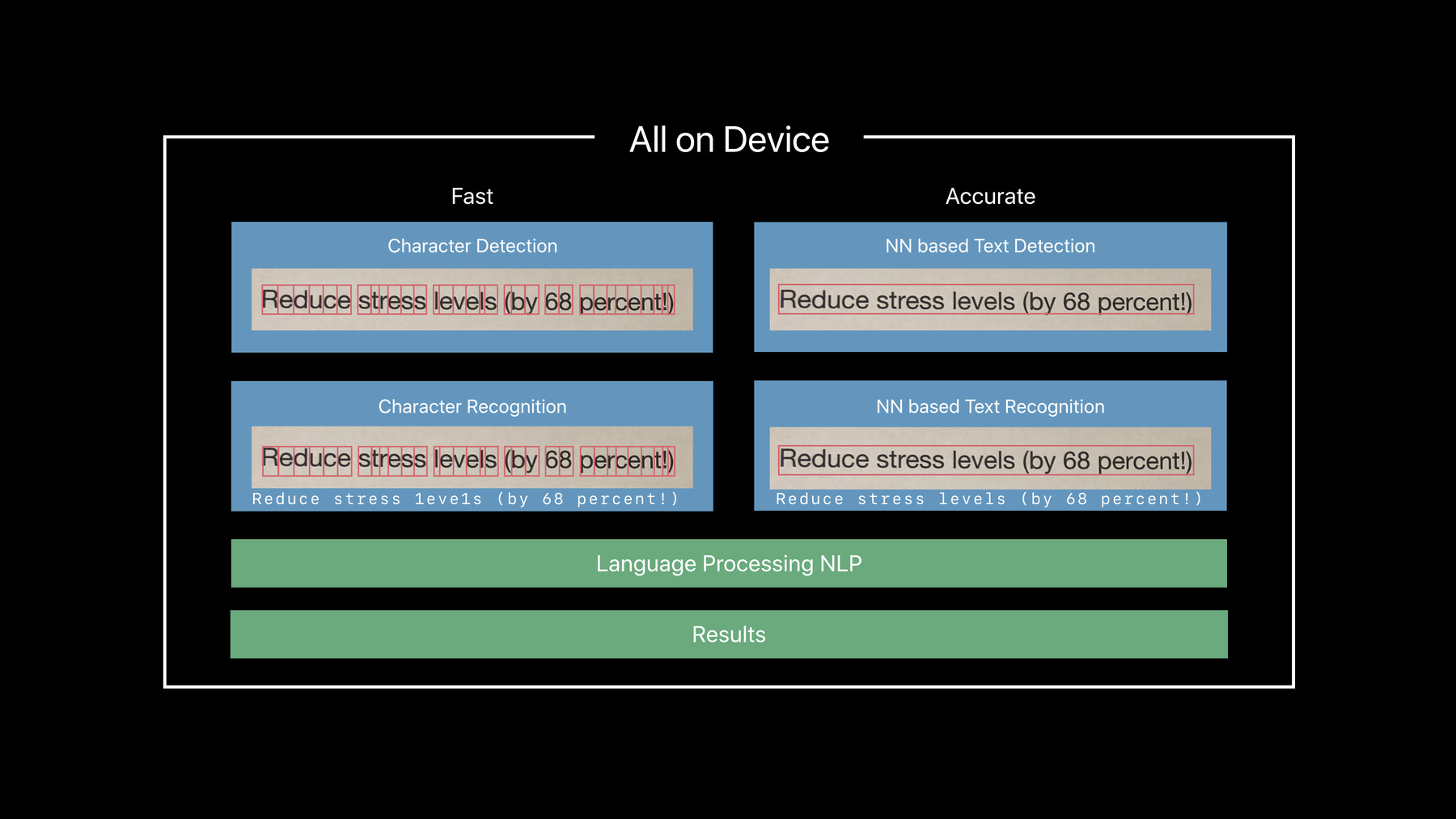
2つの選択肢があります “高速”と“確実”です
“高速”はテキスト認識の 経験に基づいて― 文字を見つけます そして機械学習モデルを 使って― それぞれの文字を 実際に認識します
“確実”は― 最先端のニューラル ネットワークを使用 文字列と行を見いだすことで テキストを検出し― さらに単語や文として 認識することができます
必要となるディープラーニング モデルは― 時間を要します しかし読む量は 人間を上回ります 我々は文字ではなく 単語を見るので― 難しいスペルでも 全体として捉えます 同様にテキスト修正の際に 誤字を見落としてしまうのは― 脳がミスを改変するからです “確実”は この技術を使い ミスの認識をしてくれます
このあと両方の道は― 言語修正を通過します ここで典型的なミスが 取り除かれ― 最後に結果が出ます
複雑そうに聞こえますが― すべてデバイス上で 行われることです (拍手)
“高速”と“確実”の 違いをお話しします
このスクリーンショットを 撮ったのは― 古いMacBook Proです そのため実際に かかる時間は異なります まずは“高速”を試してみます
終わりました
次は“確実”を試します 先ほどより少し長めでした 要した時間は 目安と考えてください “確実”のほうが― テキスト全体を 正確に読みました “高速”の問題は― 上部の筆記体です この2つには トレードオフがあります
比較してみます “高速”は― リアルタイムの読み込みに 適しています “確実”は非同期での 利用に向いています
メモリの負担は― ニューラルネットワークが不要の “高速”のほうが少ないです
斜めの文字や並びが そろっていない場合は― “確実”のほうが 信頼性が高いです
先ほど例で見たように 文字スタイルやフォントも― “確実”のほうが 網羅する範囲が広いです
もう1つ重要な点は― 自然言語の読解です “確実”のほうが 上回る結果を出します
どちらを選ぶべきか? ユースケースによります 要求に合わせることが 重要になります
判断基準は以下です インプットは? カメラを使用するか? 使用する画像が すでにライブラリにあるか?
処理上の制約は? 時間的な余裕があるか? メモリの空き容量は? 処理によって 使用量も異なります 結果をどんな用途に使うか? 転写か それとも精査か? または何か 他の作業のために使うのか?
これから話す カメラキャプチャは― live captureとして使えます ライブで読み込み フレームレートで記録します この場合は “高速”のほうが適しています
素材に応じて選べます 撮った写真に文字があり― それを認識させたい場合など フレームレートでの記録では ないので― “確実”のほうが よりよい結果が得られます
カメラについての注意が もう1点あります 解像度の設定です テキストのサイズに 合わせます 法的文書などの 細かい文字の場合― 解像度は上げるべきです 看板などの大きな文字は― 解像度を下げて 作業することができます
次は すでに保存してある データを使う場合です 精度の高さと 速度を考慮すると― “確実”を選択する人が 多いでしょう
次は言語処理です これはテキスト認識で 利用できる段階の1つです 我々が起こす見落としなどを 解消してくれますが― その逆もあり得ます 番号やシリアルナンバーです 例えば“C001”などは 誤解を招きやすい表記です
さらにこの言語修正は― 処理時間とメモリが 必要になります
基本情報はここまでです 実際にテキスト認識を 実行してみます
すべてはRequestHandlerから 始まります リクエストを作成します
completionHandlerの 設定で結果を扱います
recognitionLevelを設定 “高速”か“確実”かを ここで指定します
そしてリビジョンの設定を 推奨します 現在は最新版ですが― 将来的に改訂版が出ます 改訂版でアルゴリズムを 調整するかもしれません リビジョンを行わないと― 改訂版で不具合が 出る可能性があります そのためリビジョンの設定を 勧めています
言語修正のオン/オフも設定 そして最後に リクエストを実行します
実行すると結果が出ます VNRecognizedTextObservation として出ます 文字列と行に関しては ほぼ取得できます これらの結果を反復します
テキストを抽出する時― 複数の候補が出ますが あとで話します ここではトップに出た 候補を採用します 画像上のテキストに 境界ボックスが― 表示されています スクリーン下方です
例えばユーザが ある単語を打ち込んで― 画像上のどこにあるか 見つけたかったとします 境界ボックス内のどこに 探している単語があるか― 表示ができます
理論はここまでにして― 実演してみましょう 先に“高速”を試します ここでは例として― シリアルナンバーなどの 数字にします 電話番号を使いましょう 一番身近な番号だからです バーコードリーダーと 同じ感覚です
カメラの機能を 制限することも可能ですが― 即座の反応が重要です ユーザがすぐに 導かれるよう― 速度を優先します
だからこそ“高速”を選びました デモを見てみましょう
さて
ここにサンプル用の 番号があるので― 読み込んでみます スキャナを向けると 白いボックスが表示されます 郵便番号では反応せず まだ読み込みません 電話番号を見つけて スキャンしました もう一度 (拍手) 非常に簡単に 読み込みができました 手が震えてましたが
コードを見ましょう 大変興味深いはずです
まずはリクエストを入れます
今は“高速”を指定します 探したいのは番号なので 言語修正は無効にします
regionOfInterestの 設定が有効です 白いボックスが ユーザを導くように― 必要なテキストを囲います つまり関心のある領域のみに― アプリケーションの作業を 集中させるのです 不要な情報を 対象外とするので― 扱うデータが限られ パフォーマンスが向上します リクエストは指定しました AVCaptureSessionを 使っています AVCaptureOutputですべきことは Sessionから画像を取得 RequestHandlerを作成し 実行するだけです ここは主に 白いボックスの部分です 興味深い箇所は StringUtilsです
先ほど言ったように 言語修正は無効です ただし特定の修正を 指定します 想定される問題点が 分かっているからです 探したいのは電話番号です 文字ではなく あくまで数値を探しています 例えばSを5と判断したり― Lと1の誤認があり得ます ドメイン知識を使って 読み間違いを事前に防ぎます
文字と数字を 区別させるのです 問題はまだあります 郵便番号と電話番号の 見分けは? 数字の並びです アメリカの電話番号は 単純です 間違い防止のために ドメイン知識を使います
最後に重要な ポイントがあります 文字列のトラッカーに 仕掛けをします 実際に読み込もうとすると 画像によって― 違う結果が出ます ノイズや照明に 左右されるからです
電話番号は間違えたくない 当然 正しい結果を 得たいと思います ここで使うテクニックは― 複数のフレームを調べ エビデンスを構築すること 単に番号を得るために 時間をかけてますが― この構築は非常に単純です 10桁の番号があったら 読み込み― 結果として ユーザに提示します 10とは経験に 基づいた桁ですが― うまく機能します このおかげで― ノイズを取り除くことも できるのです
デモを実行するための 作業は以上です スライドに戻ります
まとめです
フレームレート維持のために “高速”を使います カメラの使い方も 紹介しました 不要なノイズを 除去するために― regionOfInterestを使い パフォーマンスを上げました 今回は 言語修正は無効にしました 電話番号を見つけ 正しく読み取るために― ドメイン知識を使いました そして最後に ノイズ除去にも役立つ― エビデンスの構築を 行いました
次は書画カメラを紹介します
書画カメラは― 2年前にメモで導入 リアルタイム処理が 不要の場合に便利です
今年 メール ファイル メッセージの 各アプリケーションにも導入 文書の読み取りに使えます 必要な文書を見つけて 切り取り― そのままテキスト認識の リクエストができます
これは大変便利です 画像の遠近の補正を してくれます 画像のムラの調整もします 後処理が楽になります
コードを見てみます
新フレームワークなので VisionKitが必要です VNDocumentCameraView Controllerを作成しました これからスクリーン上で 紹介します ユーザの結果が― 自分に フィードバックされます 実際は複数のスキャンを―
まとめた形で 結果を得ることになります その中からCGImageを取得し― visionRequestに送ります そして結果を得ます 最良の方法の達成のために― 同僚のセドリック・ブレイが より詳しい情報を伝えます (拍手) 紹介ありがとう
今年 テキスト認識が― Visionフレームワークに 加わります
新APIを最大限に 利用するために― 最良の方法を紹介します
本セッションでは 最良の結果を得るための― 言語知識について レクチャーします アプリケーションの パフォーマンス向上と― 結果の効果的な処理方法を 学んでいきます
さて ここで処理する画像は― 皆さんが認識している 言語でしょう その特定の言語に関する 情報が必要です そのために言語ベースの コレクションを有効にし― 対象とする言語を設定します 英語には対応しています 修正機能を有効にすると― デバイス上のモデルを使い 転写の質が向上します この言語モデルは― 幅広い分野をカバーします 例えば医療など 特殊な用語を使用する分野 あるいはビジネス文書に 見られる― 記号や呼称などにも 対応しています そして これらの特殊な言語を 認識させるために― カスタム語彙をテキスト認識の リクエストに提供します カスタム語彙が 言語ベースの― 修正を補強してくれます 認識が困難な画像でも― 正確な転写が実現できます コードを見てみましょう まず言語ベースの修正で― 対応している言語を 確認してください 対応している言語リストは 以下によって定義されます 認識レベルと 対象としている― APIのバージョンの 組み合わせです
修正機能の有効化は簡単です テキスト認識のリクエスト プロパティをtrueにするだけ カスタム語彙がある場合は この語彙リストを― テキスト認識リクエストに提供する 文字列のアレイとして指定できます
これは転写の精度を 最適化してくれますが― パフォーマンスはどうでしょう また画像の隅にあるような― 小さな情報は 必要ない人が多くいます その場合は― minimumTextHeightを 調整してください これを設定すると 指定した大きさより― 小さな文字を すべて除外してくれます 小さなテキストは 結果に含まれません 処理範囲が狭まるので―
かかる時間も短くなり 早く結果が得られます メモリ使用量も節約できます このプロパティに関する 重要な点は― 画像の高さに対する 割合を示すということです 例をご紹介します 例えば高さを 0.5に設定した場合― 画像の高さの半分以上の テキストが対象となります
以上は時間を 短縮したい時の設定です
ではテキスト認識が 最優先の作業ではない時は? 他に優先順位の高いタスクが ある場合です フォアグラウンドで ARKitビューを実行中など あるいはARFrameを― リアルタイムで 使っているかもしれません
バックグラウンドタスクの 場合は― テキスト認識は CPU上で実行されます GPUリソースと Neural Engineを― 優先順位の高いタスクに 譲ることができるのです
これはusesCPUOnly プロパティを使います 他のすべてのVNRequestで 利用可能なプロパティです テキスト認識にも 対応しています ただしテキスト認識の速度が 落ちることがあります 単に画像の大きさや テキストの量が原因で― 時間がかかる ケースかもしれません そのため 進捗管理を行わなければ― ユーザが戸惑うでしょう 進捗管理は アプリケーション上で― 行うことを推奨しています これはVisionフレームワークの 新しいコンセプトで― テキスト認識に 実装されてます 2つの形式があります まずprogressHandlerを リクエストに設定します するとtrueとして返され― progressHandlerに 進捗率が得られます さらにキャンセラーにも 対応しています ユーザが実行中の テキスト認識を― 中止するボタンを作れます
ではアプリケーションの サンプルを使って― デモをお見せします これは皆さんにも 使っていただけます My First Image Readerです
ではご覧ください
ではサンプルコードを お見せします My First Image Readerの メインウインドウです
右側は転写パネルです メインウインドウには 画像と結果のジオメトリ 転写パネルには テキストが表示されます
上部のツールバーを ご覧ください 認識の方法を 選択できるようになってます 簡単にモードを 選べるので便利です 先ほどもお話しした 他の設定もあります パフォーマンスの設定と minimumTextHeightは― またあとで話します さらにこの画面では 言語の設定もできます 言語モデルの有効化と カスタム語彙のことです
実際に例を使って お見せしたいと思います
デモのために 作った画像を使います これは本の表紙です とても小さな文字で 私の名前が入ってます
小さな文字で書かれた名前が 検出されました 大きな文字も同様に 転写されました 同じような表紙が たくさんあり― 索引を作りたいとします 作者の名前は不要です 認識の速度を速めるために― minimumTextHeightを 設定します
0.1に設定した場合 テキストの大きさは― 画像の高さの10%以内で なければなりません “Desert Dunes”の 場合の設定です
設定を0に戻します
言語設定を見てみます 特にカスタム語彙に 注目してください
チラシをドラッグします “Hill Side”という企画です 記号も含まれています このチラシの照会番号は― “HI11”です 間違いやすい表記なので 結果を見てみましょう
参照番号が 間違って認識されました 修正を加えます 指定しましょう
“HI11” こうして経験値で カスタマイズしていきます カスタム語彙のリストに この修正を加えます すると正しい照会番号が 得られました スライドに戻ります (拍手)
復習します
アプリケーションの 使用状況に応じて― 最適な認識レベルを選びます 速度と確実性 どちらを優先するか 言語設定は― 文書の種類によって 確認してください 誤解を招く表記や ドメイン特化言語がある場合― カスタム語彙を有効にし 指定します 重要なこととして― 進捗状況に対応してください ユーザ体験のためです
さて これらの注意事項以外にも― 非常に重要な側面が 他にもあります 自身の結果を 処理してください そして独自の“レシピ”を 編み出すのです それをユーザに提供します “レシピ”と言っても― 料理のレシピではないです 最も効果的な― 結果を出す方法を 編み出してほしいのです 最高のユーザ体験のためです その方法をご紹介します
まず重要なことを言います 紛らわしい情報に 備える必要があります コンピュータビジョンであり 答えのない問題です 我々のパラメータの配列は― 処理する画像の内容に 影響を与えます そのため家屋番号は 大変興味深いです デザイン性があるからです テキスト認識を行っても― 番号だという 手掛かりがありません “101”ではなく― 結果は“lol”と出るかも あるいは喜びを表す 絵文字と出る可能性も
あり得ます
これについては先ほども 注意事項として話しました 候補リストを 活用してください 観測に基づいて 上位候補リストを作ります アプリケーションに この候補リストを加え― 上位3位までか それ以上を見てください 画像にインデックスを 付けるのは典型的な例です 再現率を上げたい場合は― インデックスを 多めに付けてください ただし適合率は低下します
リストの掘り下げは 必要ですが― 1つの切り口にすぎません モデルの精度は調整されますが― 他の切り口は? 像空間は? 結果を関連付けるために― ジオメトリの使用を 再検討してください observation.boundingBoxで― 空間情報を得られます 位置 結果の基準 回転を利用して― 結果を 関連付けることができます ここで例をお見せしましょう レシートの場合です 例を使って商品名と価格を― 結び付けてみましょう
これがジオメトリです しかし結果は独立しています パーサを使うことも あるでしょう 結果の意味を 個別に抽出できます この場合― NSDataDetectorは 強い味方です 皆さんが欲しい情報を 抽出できます 例えば住所 URL 日付 電話番号などです 私の名刺を使って 抽出してみます 各結果に意味付けします
それでも足りない場合は ドメイン固有のフィーチャや― 文字列と適合する独自の語彙 独自の表現を使用します
これらの原理を説明する― iOS向けの アプリケーションがあります Business Companionです
ところで 皆さんがこの会場に 来た理由は― レシートスキャナを 作成したいからですか? または開発したいのは 名刺スキャナですか? このアプリケーションに― ぜひ注目してください 1つのアプリケーションフローに 2つのフローを組み込めます お見せします
まずこちらに― DocumentCategoryPicker があります 必要な文書の種類を 選んでください そしてそこから 書画カメラにいきます 書画カメラから テキスト認識を実行します 重要な工程ですが― 結果に意味付けをするために 分析をします この分析をベースにして― 名刺を読み取るモデルを 作成します 文書の種類の フォールバックがあります この分析から 意味付けができたら― Table Viewsに表示される結果を より適切に視覚化できます 名刺を使って ミニ名刺データを作ります
こちらを見てください
iOSデバイスに切り替えます Business Companionです ここで文書の種類を 選択します レシート 名刺 または他の文書 レシートを選択しました
書画カメラを起動します 影になっていますが
文書を認識して処理します 出ました 結果です 成功です
商品名が出てます カテゴリ名と価格も 表示されています では
名刺で試してみます
同様の処理です
名刺の各項目が 認識されました ミニ名刺データです (拍手)
とはいっても まだ不便を感じます 文書の種類の選択が 手動なので― スムーズではないです より快適な使用感を 実現してみました このアプリケーションの 別バージョン― Better Business Companionです
改善した点を紹介します Create MLを使って 分類モデルを― トレーニングしました 手動での 文書の種類の選択が― 自動になりました お見せします
ご覧ください 書類の選択ボタンが ありません
スキャンのボタンです 同様に読み込んでみます
レシートです
文書の種類を選ぶことなく― レシートであると認識し 処理されました
名刺で試すと どうなるでしょうか 見てみましょう
さて 名刺と認識されました (拍手) Core MLモデルの 組み込み方を見ましょう
Xcodeを開きましょう Business Companionから コードの修正ができます そして ここにCore MLモデルを 挿入しました 具体的にはこちらです
Core MLモデルを ここに挿入しました completionHandlerを使った リクエストです ハンドラの一部として topObservationと― そのデータ識別子の 処理をしました
スキャンモードを設定して― 残りのフローを決定します テキスト認識を利用して アプリケーションの― フローを改善する方法を 検討してください Core MLモデルが 活用できます
では スライドに戻ります
最後のまとめです
必要に応じて― ジオメトリ情報を 利用してください データ検出器を使い 結果に意味付けをします 何が必要なのか― 一番分かっているのは あなた自身です 最高のユーザ経験の 実現に必要なのは― ドメイン知識です
テキスト認識の導入に 役立つ情報をお伝えしました この技術を使って すばらしいアプリケーションを― 作成してください 質問がある場合は― 明日も開催されるラボで 聞いてください ありがとうございました (拍手)
-