-
Metalによる最新のレンダリング
MetalはGPUを活用したグラフィックスおよび演算のためのフレームワークで、プロフェッショナル向けのAppからコンソールスタイルのゲームに至るまで、あらゆるAppの構築に役立ちます。このセッションでは、Metalの機能を利用して、遅延レンダリングやタイルベースのフォワードレンダリングといった最新のグラフィックステクニックを実装する方法について説明します。GPUで処理される機能により、Metalで処理のスケジュールが自動的に決定され、シーン全体の描画や演算処理の実行が、CPUとほとんど、またはまったくやり取りせずに行われる仕組みについてご確認ください。GPUファミリーを使用することで、さまざまなAppleプラットフォームに対応できるAppを簡単に構築する方法や、MetalによってAppやゲームでまったく新しいレベルのパフォーマンスと機能を実現する方法を紹介します。
リソース
関連ビデオ
WWDC21
WWDC19
Tech Talks
-
このビデオを検索
(音楽)
(拍手) ヤープ・ヴァン・マーデンです “Modern Rendering with Metal”の セッションへようこそ
前半は 高度なレンダリング手法をご紹介 早速 皆さんも使用できます 後半はシュリーニバスより GPUパイプラインへの移行について お話しします 最後はクロスプラットフォーム開発を 簡素化する― 新しいGPUファミリです
このセッションでは Metalを初めて使う方でも さらに使いこなしたい方でも歓迎です 今回 お伝えするレンダリング手法は きっとニーズに合致するはずです
では現在の アプリケーションなどに使われる― レンダリング手法を見てみましょう
まず標準的なDeferred ゲームやグラフィック系では 最も一般的でしょう このレンダリング手法について Metalへの実装方法と iOSへの最適化を紹介します 次にライトパスを拡張できる Tiled Deferredです 複雑な光源の設定にはうってつけです
そしてForward 複雑なマテリアルの Metalアプリケーションと相性がよく アンチエイリアスや透明処理などにも 向いています
最後はVisibility Bufferです ジオメトリをライトパスまで 遅延させます Metal 3では より簡単に実装可能です ではDeferredから始めます
Deferredはレンダリングを 2パスに分けます ジオメトリパスで基本的に全体像を 中間のG-bufferに描画します ここでのテクスチャは 法線 アルベド 粗さ そして必要に応じた 表面やマテリアルの属性です 次に2つ目のパスです ライトパスは光量を調整し 最終的なシーンを構築します 遅延シェーダはG-bufferでバインドされ 表面のカラーに割り当てられます では流れを確認して Metalの実装に移ります
2つのパスがあり GPU上で連続して動作します ジオメトリパスでは深度を書きます 深度を呼び出すだけでなく ピクセル位置と空間の計算にも 必要となります
G-bufferテクスチャも出力 この例では 法線 アルベド 粗さを使います
そしてライトパスで そのテクスチャを読み戻します 光量を調整して 出力するテクスチャに重ねます
ではMetalで実行します
始めるには Render Passディスクリプタが必要です 出力が最も重要になってきます アタッチメントで定義され
深度は1つ カラーは複数 持たせることができます アタッチメントを保存するデータを指す テクスチャを定義し テクスチャから既存データを ロードする動作を定義します またレンダリング結果をテクスチャに 保存する動作も定義します 全アタッチメントの属性を定義すると Render Command Encoderを 生成できます Render Passに オブジェクトを加えられます
では実際にやってみます
セットアップ関数を用意しました まずRender Passを作成 アタッチメントを書き込みます まずは深度です 必ず深度が明確な状態で シーンを描画したいので loadActionはclearに 深度を保存するため storeActionはstoreです 次にカラーアタッチメントは G-bufferで 各テクスチャに1つ必要になります どのテクスチャも処理は同じです
描画中は SKYBOXや背景のように扱うため 全フレームの全ピクセルを オーバーライドします テクスチャの過去の値を 気にせず済みます loadActionはdontcareにします
G-bufferの結果を保存するため storeActionはstoreです ではライトパスのディスクリプタです オブジェクトを生成し 蓄積バッファのアタッチメントを定義 確実にデータを蓄積するように loadActionはclear 画像を保存するため storeActionをstoreにします
実際にシーンを描画した時の レンダーループを確認します まずはジオメトリパス Render Command Encoderを生成し シーン内の計測を順に処理します これは非常に単純な方法です セッションの後半では シュリーニバスから レンダーループの移行に触れます LODを備えた GPUパイプラインに切り替えます それではジオメトリパス全体を エンコードしたので ライトパスに移り Render Command Encoderを生成します すべての光源の処理を順に行います 光源ごとに遅延シェーダが テクスチャとバインドし 光の色を計算します
この2パス方式は全プラットフォームで macOSとiOSに完全に対応します ハードウェアの種類も問いません 手順を踏めばiOSへの さらなる最適化も可能です 概要のスライドに戻って説明します 2つのパスは 大きなバッファを経由します ジオメトリパスの全データが保存され ライトパスに流れます 光源が複数だとその分 リードバックが繰り返されます Metalの Programmable Blendingを使えば この処理をデバイスのメモリで行えます iOSデバイスのアーキテクチャを 利用するのです この手法を実行するには ジオメトリパスとライトパスを 統合します そして単一のRender Encoderを生成
iOSアーキテクチャの性質から エンコード中 アタッチメントは タイルメモリに残ります つまり書き出しながら リードバックが可能 ピクセルの値も読み戻せます 光を算出する時に重宝します ピクセルのG-bufferアタッチメントを 読み出すからです ではシェーダを見てみましょう ライトパスのフラグメントシェーダです まずは全テクスチャを バインドさせていき― G-bufferのデータを取得します そして このすべての テクスチャを読み込み 表面などの情報を得ます この情報から 最終的なカラーが算出されるのです Programmable Blendingを使ってみます
テクスチャではなく カラーアタッチメントをバインド
値はそのままLightingModelに使えます
G-buffer用に 新しいアタッチメントができました 深度アタッチメントに アクセス不可だからです
もうテクスチャの調整は不要なので メモリ配置の最適化に使います
G-bufferテクスチャの 書き出しや読み込みは不要なので storeActionをdontcareに変更します まだデバイスの容量を占める Metalオブジェクトがあるので G-bufferテクスチャの物理メモリを 消去させます そこでstorageModeを memorylessにします これで基本的に保存は実行されません メモリも不要です このようにして優れた機能を備えた― iOSへの実装が完了します G-bufferによるオーバーヘッドが 排除できます
次に移る前にまとめておきます パスが分かれた手法は 幅広く使うことができます 複雑なジオメトリや光源に対応 G-bufferが後処理パイプラインを 促進させます Programmable Blendingで パイプラインの一本化が可能
ただしmacOSでは まだG-bufferが必要です
では 次はTiled Deferredです 光を最大限に与えて描画する場合 ライトパスの処理に負担がかかります
Tiled Deferredは この処理性能の向上を図っています Deferredでは光源を個別に描画し G-bufferの処理に負担をかけます
Tiled Deferredは 計算用のプリパスを追加し シェーディングをタイル別で行います
プリパスが画面を格子状に分割し タイルごとに 光源リストを作ります すると次のステップで 単一のフラグメントシェーダで 効率よくタイルを照らせます リスト内の光源が対象です 実装の詳細に触れる前に 光源リストの生成方法を紹介します
表示領域を タイルとなる サブ領域に細かく分けます
そしてシェーダでサブ領域を調整 タイルの位置や深度から計算します ジオメトリパスを実行しているので 深度バッファも実装済みです
これで光量の対象となる領域だけを テストして 光源リストに交点を加えられます
この処理はカーネルに最適で 全タイルで並行して実行されます ではDeferredパイプラインに統合します
先ほどの2パス手法ですね
この演算パスを中間に加えます
生成された光源リストは バッファを介し デバイスのメモリに保存されます この手法も 全プラットフォームで機能します 必要なのは演算パスの追加と 光源のロジックの変更 シェーダでループ処理を 実行させるロジックにします 前のレンダリング手法と同様に iOSでは さらなる最適化が可能です それでは iOSへの実装手順を 見ていきましょう
統合したパスで Programmable Blendingを使うには 1つのRender Command Encoderに 収める必要があります Metalではタイルベースの アーキテクチャを使い 復元した各タイルに コンピュータモデルを描画します そこでiOS上では Render Command Encoderがシェーダの パイプラインをエンコードします 外側の光源に最適です コンセプトをHardware Tileに 直接マッピングできるからです
Hardware Tileで 直接 プリパスを実行できるため Persistent Threadgroup Memoryを 使うことができます タイルメモリと並行して 光源リストを保存します
リードバックすると Render Command Encoderに取り込まれます 今回は光源1つにつき実行されます
ライティングは グラフィックに合わせて タイルメモリ内で完結します ではMetalで行ってみましょう
タイルシェーダは 標準的なパイプライン構成です ディスクリプタを生成し カラーアタッチメントを設定 実行したい演算機能を設定し パイプラインを構成します Persistent Threadgroup Memoryを 使うので 少しメモリを確保しておきます Render Passに戻り 光源リストの保存用データを確保します
ディスパッチを確認するため レンダーループへ Render Command Encoderを1つ用意 そしてシーンの 全メッシュをループ処理します
まずはタイルシェーダを実行します パイプライン構成を設定し すべての光源を保持する バッファをセット Threadgroup Memoryのバッファを タイルメモリにバインドします そしてシェーダをディスパッチ タイルシェーダと Threadgroup Memoryを実行したので 光の描画に光源リストが使えます 各ピクセルが光源リストにアクセス可能 Persistent Threadgroup Memoryにより 効率的にシェーディングできます
セットアップが完了し 次はシェーダです
2つのうち 上がタイルシェーダです Persistent Threadgroup Memoryに 光源リストをバインド
全光源をループ処理して マスクを出力します Persistent Threadgroup Memoryに 入ります そして2つ目のシェーダが読み戻します タイル内の可視光すべてを対象に ピクセルを調整します
タイルベースを実装する上での要点を 見てきました では この仕組みを使って レンダラを拡張し 追加のフォワードパスを 効率よく構成してみます
Persistent Threadgroup Memoryの 光源リストデータは フォワードパスを加速させるために 使えます
ジオメトリをシェーディングする時 同じPersistent Threadgroup Memoryを 使い光源リストを読み込みます 遅延ライティングと 同じLight Loopを使い 効率的にシェーディングします このフォワードパスは 透明処理や特殊効果の他 複雑なシェーディングも可能にします
遅延パイプラインには限界があり アンチエイリアスや 複雑な描画などは困難です 中間のG-bufferが原因です タイルベースの手法を使うことで 効率よく― Forwardレンダリングを加速できます そこでフォワードパスのみに注目します タイルベースの手法と並んで 解決策となるからです
Deferredのジオメトリパスと ライトパスを除きます しかしサブ領域に合わせる 深度が必要です
そのためジオメトリパスを 深度プリパスに置き換えます すでに備わっているなら 問題ないはずです
オーバードローや最適化などには 強い味方となる手法でしょう しかしiOSハードウェアでは 不要になることも その場合 Clustered Lightingが 効果的かもしれません この手法は光源リストを生成する時に 深度を求めません タイルに深度の範囲を定めておらず 軸に沿って表示領域を分けているだけ
そこで3D光源リストマップを放出
タイルベースのサブ領域より 非効率かもしれませんが 各ピクセルで光源リストを使い分け ライティングの性能を向上させます
タイルシェーディングとPersistent Threadgroup Memoryを兼ねれば Forwardは性能が増します
定番の手法と Metalへの実装方法を紹介しました 最後はVisibility Bufferです G-buffer処理を軽減し 旧式ハードウェアへの対応を促します
一旦 Deferredに戻ります 現状 最適化できるのは iOSアーキテクチャのみでした
Visibility Bufferは別の手法で 中間バッファの処理を軽減します 限りなく少ないデータ量で 保存するのです ピクセルごとに属性を保存するのでなく プリミティブ識別子と 重心座標のみ保存します
直接 シェーディングには使えません しかし元のジオメトリの再構築に使用し シェーダ内でマテリアルロジックを 実行できます これはタイルベースの手法で 非常に効果があり 各ピクセルが一度の再構築で済みます
しかし最大の難点があります プリミティブ識別子と重心座標を いかにして―
少ない作業で生成するかです そこでMetal 3の出番です これらの属性を使えば フラグメントシェーダ内で 読み出すことができます
これまで以上に ジオメトリパスを高速にして 実装をより簡単にしてくれます
Metalでの描画に使える 様々な手法の中から いくつか実践してご紹介します
複雑なジオメトリとPBRマテリアル― 異なるシェーダを有する テストシーンです Deferred Tiled Deferred Forward いずれの手法も使えます では Deferredを使ってみます Deferredは2パスの手法です 第1パスがG-bufferを介し 描画します ではテクスチャを見ます
これはアルベドです
そして法線
これが粗さのテクスチャです もっと複雑なモデルなら G-bufferの保存量は増えるでしょう このシーンは第2パスで 光を当てています 夜のシーンで光源を確認します
このシーンでは 多くの光源を描画しています 可視化します Deferredでは 光源を1つずつ処理し 複雑に重ね合わせているのが分かります 次はTiled Deferredです
先ほどと同じシーンを Tiled Deferredで描画しています
可能な限り可視化したので それぞれのタイルで描画されている― 光源の量をご覧いただけるかと思います タイルに分けることで差が生まれ 一度に全ピクセルに光を当てられます
紹介した手法を用いて シーンをご覧いただきました では後半はシュリーニバスより GPUパイプラインへの移行を説明します (拍手) ありがとう
Metal 2のGPUパイプラインの構成は Argument Buffersと Indirect Command Buffersでした 今回 CPUベースから GPUの操作に切り替えます 前半ではMetalへの実装方法を ご紹介しましたが 後半はGPUへの切り替え方法を お見せします レンダーループが改善されるだけでなく CPUが解放されます 他の処理に回せますね まずレンダーループで どんな操作があるのか確認します
大型のシーンの場合 効率的に描画する際 一連の操作が必要です 最初にフラスタムカリング 表示領域外のオブジェクトを 無効にします 次にオクルージョンカリング 重なって見えないオブジェクトを 無効化します 他にはLODの選択が一般的でしょう カメラとの距離に応じて モデルのLODを調整します CPUベースの典型的な操作は このような形です 無効化の対象物とテストデータを Command Bufferにエンコード GPU上のレンダーパスで実行し 次フレーム用にデータを生成します フラスタムカリングで 表示領域外のオブジェクトを無効化し LODでモデルの詳細度合を調整します そしてオクルージョンカリングで 重なったオブジェクトを無効化 最後にドローをエンコードして Render Passを実行するという流れです しかし ここで非効率な箇所があります オクルージョンカリングでは 現在のフレームデータを無効化します しかし どんな同期も 導入したくないため 低解像度で取得した 過去のフレームデータを頼ります 無効化の失敗につながります 適切な手順を踏む必要があります また並列化できそうな操作として フラスタムカリングが挙げられます このような単一のCPUスレッドでは 順番にフラスタムカリングが 実行されます しかし複数のCPUスレッドに 分配しても 使えるスレッドは限られます オブジェクトごとに異なる操作を含むと このようになるでしょう 確かにスレッドを増やせば シーン内の各オブジェクトを 平行して処理することができます しかし大抵の場合 シーン内に オブジェクトは数千個あるのです そんな処理に対応できるのがGPUです GPUは数千個のスレッドを駆使して 並行に処理を行います 各スレッドで実行したい操作を オブジェクトに与えられます 数千個を同時に処理できるのです GPUなら より効率的な レンダーループが可能です CPUは解放されるため 他の処理を割り当てられます ではGPUへの移行方法です GPU上の演算パスと Render Passを結合すると GPU上でレンダーループ全体を 実行できます 一連のレンダリング操作が 完全にGPU上で行われるのです では これらのパスを GPUでレンダーループしてみます オクルージョンカリング用の オクルーダーデータを得るため 演算パスにシーンデータを移し オクルーダーのコマンドをエンコード そのコマンドがレンダーパスで実行され オクルーダーデータを生成します オクルーダーデータの形式は様々なので さらに処理が必要です 別の演算パスを使います ここでオクルージョンカリングに 適した形式に変更されます そしてさらに用意した演算パスが カリング LOD コマンドエンコードに 対応します ここでのオクルージョンカリングは 過去のフレームデータに頼りません 最初の2パスで生成された オクルーダーデータは 現在のフレーム用なので より正確です
最後に別のRender Passで コマンドを実行し シーンを描写します これなら すべての処理が GPU上で行われます どの段階でも CPUとGPUの同期は不要です ではビルドする方法です そのためには 少なくとも2つの工程が必要です 1つ目はドローコマンドを GPU上でエンコードする方法です 演算パスがRender Passに エンコードします またMetalがIndirect Command Buffersでサポートします 次にシーンデータが要ります フレームを介してGPU上の シーンデータにアクセス これでシーン全体を描画できます ジオメトリや引数 マテリアルなどです またMetalが提供する要素に Argument Buffersがあります では 2つのBuffersに触れます
Argument Buffersは 複雑なデータ構造で描画を可能にし どの段階でもシーンデータに アクセス可能にします Indirect Command Buffersは 呼び出しをビルドし 膨大なコマンドを並行して生成します ではオブジェクトモデルで さらに詳しく触れます
まずシーンデータへのアクセスです 構成要素の1つがメッシュです ジオメトリを表す メッシュオブジェクトの配列です 次がマテリアルの配列で 属性やテクスチャを備えています パイプライン状態オブジェクトは 影のパイプラインを描きます そしてモデルの配列です 各モデルはLODが調整されており LODごとにメッシュや マテリアルの配列で構成されます シーンオブジェクトが 3つの構成要素を関連付けています ではArgument Buffersで構成してみます
非常に簡素な 1対1のマッピングになりました 例えばScene argument bufferは 3つのオブジェクトのみで構成されます 先ほどの メッシュとマテリアルとモデルです シーン全体が Argument Buffersで描かれます では シェーダ内で確認してみます
各Argument Buffersの構文は ご覧のとおりです オブジェクトモデルのメンバを 含んでいます それぞれが非常に柔軟な構文なので 配列やポインタなどを 加えることもできます 例えばMaterial argument buffer テクスチャに必要な定数を含み パイプライン状態オブジェクトもあります 1つのBufferに すべて詰まっています Scene argument bufferも オブジェクトモデルと同様です Argument Buffersでの モデル構築は非常に簡単です ではArgument Buffersへの アクセス方法です
フラスタムカリングを行う 演算カーネルです ドローコマンドを Indirect Command Buffersにエンコード カーネルのインスタンスを実行する 各スレッドが オブジェクトを処理し ドローコールをエンコードします 詳しく見ていきます 高水準のScene argument buffer内で パスしてシェアへ シェーダやシーンにアクセスすれば 他のものにも簡単にアクセスできます CommandArgsはIndirect Command Buffersの参照を含みます
スレッドIDに従い シーンからモデルを処理 全スレッドが特定のオブジェクト上で 並行して機能しています フラスタムカリングで 表示領域外を無効化します オブジェクトが見える時は カメラからの距離を基準にLODを計算 LODがあれば距離に応じたメッシュ マテリアルの引数 Argument Buffersを 簡単に読み込めます Argument Buffersがシーンに必要な リソースを結び付けるからです 必要な情報を得たのでエンコードします Indirect Argument Buffersに エンコードしていきます Indirect Command Buffersの出番です
Indirect Command Buffersは レンダーコマンドの配列です 各コマンドは異なる属性と パイプライン状態オブジェクトを含んでいます また頂点バッファや フラグメントバッファもあります 基本的にエンコードは オブジェクトが見えると 全属性を読み込み Indirect Command Buffersにエンコードします オブジェクトを処理する各スレッドは Indirect Command Buffersの枠に エンコードします スレッド同様 コマンドも並行してエンコードされます 引き続きカーネルの例を使って 実際のエンコードを見ていきます
まずドローコマンドを エンコードするために draw idを使って Indirect Command Buffersの枠を得ます ドローコールに必要な パラメータを設定します それに必要な情報はMaterialと Mesh argument bufferにあります 例えばマテリアルには パイプライン状態オブジェクトを設定 メッシュには 頂点バッファなどを設定できます フラグメントバッファも同様に設定 これでエンコードが完成しました 非常にシンプルな手順で簡単にできます
ではPathの設定を行います
エンコード用の Indirect Command Buffersが要ることは GPUレンダーループに関して 最初に話したとおりです カリングを実行する 演算ディスパッチから始め オクルーダードローコマンドを エンコードします 各スレッドが独立してドローを エンコードするので Indirect Command Buffers内の 状態の設定は様々でしょう 任意で Indirect Command Buffersを最適化し その設定を省けます これはオクルーダードローを実行する Render Passです 同様に他のPathも設定できます 例えばこちらだと
カリングカーネルをローンチする 演算ディスパッチです カリングやLODの選択などを話した時に 触れました 最後にコマンドを実行する レンダーパスをローンチ これでシーンを描けます ではドローコマンドのエンコード後 Indirect Command Buffersの 流れを見てみましょう
穴だらけの状態です これはオブジェクトが見えていない時 スレッドがドローコマンドを エンコードしていないからです この例だとオブジェクト1と3です Indirect Command Buffersの枠が 空の状態です このbufferをGPUに渡すと 空のコマンドが無数に実行され 非効率になります そのため空のコマンドは 詰めてしまいたい どうすればエンコード時に 詰められるでしょうか そこで間接的な手法を用います Indirect Rangeを通じて 実行すべきコマンドを GPUに伝えます Indirect Range Bufferは 開始地点とコマンド幅を含みます このバッファはGPU上に 存在しているものです 実行されると開始地点と コマンド幅が拾えるので コマンドを詰める時に使えます ではコードの例を見てみましょう
これは先ほど触れた カリングカーネルです Indirect Range Bufferに対応させ コマンドを詰めています
最初にIndirect Range Bufferの 幅のメンバを渡します コマンドを読み出すと 自動的に幅をインクリメントします 各スレッドがアトミックに 幅をインクリメントするので 幅は自動的に設定されます 同時にコマンドも詰められます このatomicという指示により 過去の幅の値が返されるからです 例えば0で始めると 0の枠は 幅が1にインクリメントされます 1の枠なら幅が2に インクリメントされます コマンドを詰め なおかつ 幅をアップデートできるのです ではアプリケーションでの Indirect Range Bufferの設定方法です
まず演算パス用に Indirect Range Bufferを生成 次にカリングカーネル用に そのrangeBufferを設定します カリングカーネルをローンチする 演算パスを用意 オブジェクト処理と同時に 自動で幅がアップデートされます 最後にIndirect RangeのAPIで 実行コマンドのパスを調整 これでIndirect Range Bufferの 開始地点とコマンド幅を呼び出します Indirect Command Buffersを より効率的に実行できます
GPUパイプラインでは全コマンドが GPUの演算パスでビルドされています 通常 ディスパッチが起こる 演算パスもです そうなるとGPU上の演算ディスパッチを Indirect Command Buffersに エンコードしたいはず そこでMetal 3の新たな追加機能を ご紹介します このエンコードをサポートします GPUでも演算ディスパッチをビルド可能 Indirect Command Buffersの機能面は レンダリングに近く― 繰り返し使用することができます CPUの処理を軽減します そしてレンダリングと計算が GPU上で行えます より柔軟なGPUパイプラインを 構築できます では使用例を見てみましょう
パッチ別Tessellationファクタです 大量のパッチで作られたメッシュがあり 各パッチにTessellationパッチを生成 これを すでに紹介した カリングカーネルで実行できるのです GPUのスレッドが オブジェクトの各パッチを経由して Tessellationファクタを生成します しかしTessellationファクタの生成は それ自体 並列可能な操作なので 効率的とは言えません マルチスレッドで操作を 分配することが効率的です 全パッチを並行して処理します カリングディスパッチの各スレッドが Tessellationファクタの ディスパッチをエンコードします これは別の演算パスでも実行され 操作を並列化します GPUのディスパッチが可能にします では この処理を行う GPUパイプラインに変更します
メインの演算パスがあります カリング LODの選択 エンコードを担います さらにTessellationファクタの ディスパッチエンコードを追加 スレッドがオブジェクトの可視を確認後 Indirect Command Buffersに そのディスパッチをエンコードします そしてコマンドが別のパスで実行され レンダーパスに移ります GPUドローに結び付いた GPUディスパッチが より柔軟なGPUパイプラインを 構築します ではサンプルを作成しましたので ご覧ください
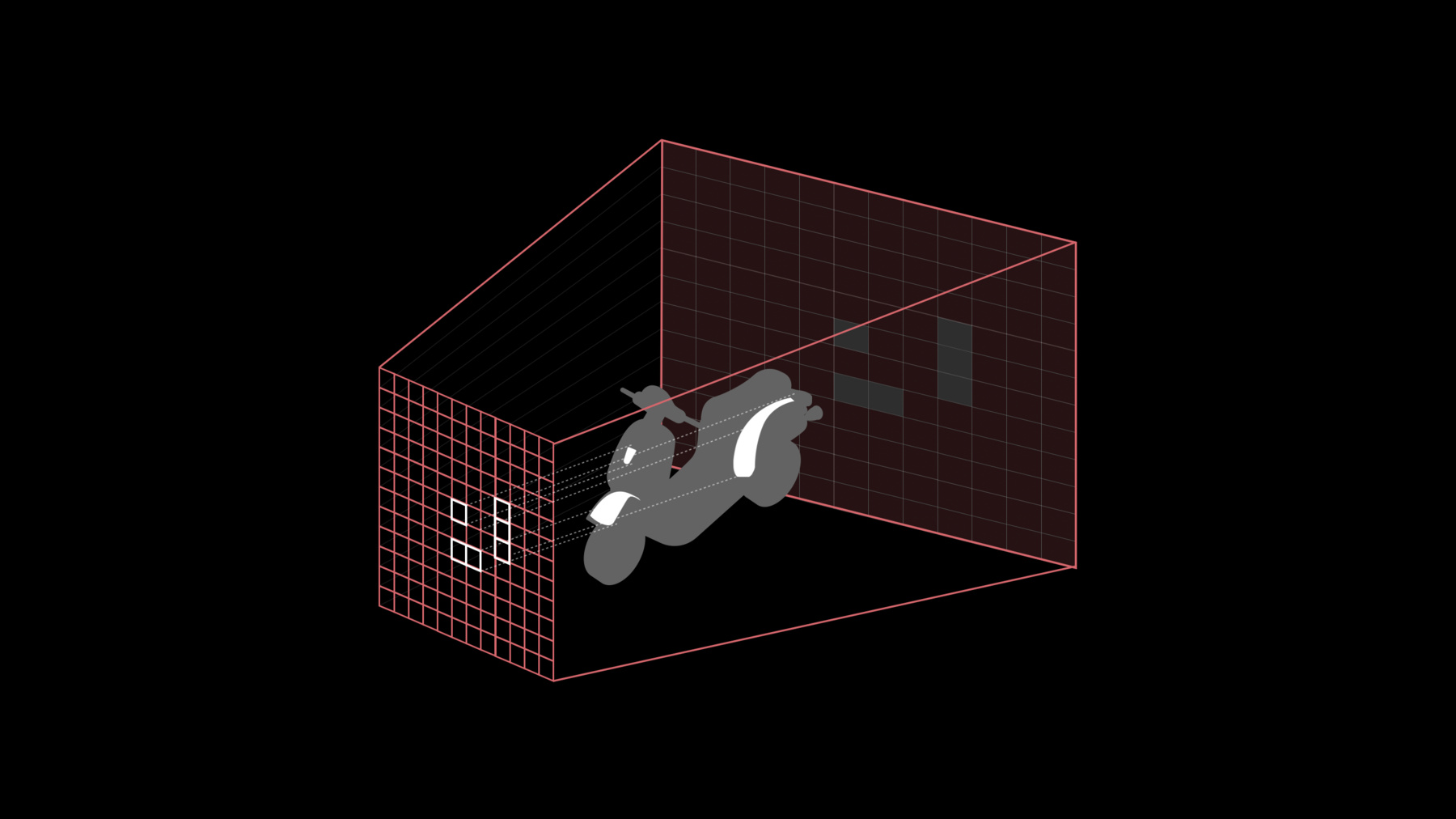
前に見たレストラン街のシーンです 通りを抜けるように進んでいます このシーンは約280万個のポリゴンと 約8000のドローコールを使用し 1つのビューを構成しています 前に使用した カスケードシャドウを想定すると 約4種のビューを扱います CPUでレンダリングすると APIは相当な数になります このシーンは Indirect Command Buffersを使い すべてGPU上で処理しています そのためCPUの負担を 大きく軽減しているのです
もう1つのビューを見ましょう 今度は同じシーンを通り抜ける カメラを映しています 白いオブジェクトがカメラだと 分かるでしょう マゼンタに染まっている部分の ジオメトリは カメラの表示領域外を表しています カメラが通り抜けることで 表示領域内のジオメトリが分かります GPUでフラスタムカリングを行う カリングディスパッチが 領域外のジオメトリを確定しています このジオメトリは GPU上で処理しないので レンダリングの負担を軽減します もう1つビューを見ます
フラスタムカリングと オクルージョンカリングを実行しました シアンの部分が オクルージョンされたジオメトリです 引き続きマゼンタは表示領域外です 画面右側の大部分が オクルージョンされています 表示領域内でも大部分あると 見て分かると思います ここでもGPUでカリングを行う カリングカーネルが 領域外のジオメトリを確定します 色付き部分はGPUで処理されないため レンダリングの負担が減り 性能が向上します
最後にもう1つ お話しするテーマがあります Metalにおける相互参照の記述を 一層簡単にする方法 またiOS tvOS macOSにおいて 機能の特定を手軽にする方法です まずは全プラットフォームで使える Metalの機能を振り返ります
iOSとtvOSに新機能を加えています 先ほどIndirect Command Buffersで パイプラインを GPUベースにする方法をお見せしました またIndirect Rangeで Indirect Command Buffersを より効率的に使えます そしてもう1つが 16ビット深度テクスチャです シャドウマップの最適化に 定評があります macOSにも重要な新機能があります アタッチメントなしでの レンダリングが可能になりました コマンドバッファの所要時間の クエリが可能に 動的にインターバルを調整できます 最後にsRGBと非sRGBの キャストをサポート 光の線形をより適切に整えます では新しいGPUファミリAPIを紹介します
これまで利用可否に応じて Metalの機能セットを使ってきました しかし そんな機能も 今では膨大な種類があります そこでGPUファミリがシステム容量の クエリをより簡単に行います まず4つのファミリに集約し クロスプラットフォーム開発を 簡素化します 次にインスタンスで構成された 機能の階層をサポート 過去の全インスタンスを引き継ぎます そして新APIで Metalのバージョンのクエリを区別し インスタンスの変化を追跡します 最後にファミリに適さない 任意の機能に対して デバイスのクエリを定義します では新しいGPUファミリの 詳細に触れます
iOSとtvOSの全機能の構成は 5つのインスタンスのファミリです 過去のインスタンスに含まれた機能も 引き継ぎます 全機能を一覧にするのではなく ファミリとインスタンスに マッピングします Macの機能構成は2つのインスタンス Mac 2はMac 1の機能を引き継いでいます
機能をクエリして ファミリがコードの記述を簡素化します 全プラットフォームを対象とする 共通のファミリも用意しました クロスプラットフォームの階層に Metal機能を組み込み― Common 1はMetal GPUがサポート 少しMetalを使うアプリケーションに 適しています Common 2はゲーム開発に必要な 全要素を提供します 例えばIndirect Drawや Counting Occlusion Queries Tessellationや Metal Performance Shadersです Common 3は高性能アプリケーション向け Indirect Command Buffersや Layered Renderingなどです 最後にMetal 3には Macをターゲットとした― iPadアプリケーション用の ファミリがあります
iOSMacインスタンスは2つ Macの性能に重要な機能を備えています 注目はMac専用のBC Pixel Formatsと iOSアプリケーションで使える Managed Texturesです iOSMac 1はCommon 2の機能に加えて Common 3の一部にも対応 BC Pixel Formatsと Managed Texturesの他 Cube Texture Arraysをサポート 他にもRead/Write Textures Indirect Tessellationがあります
iOSMac 2はCommon 3の全機能と BC Pixel Formats Managed Texturesです 以上が新しいファミリです では新しいQD APIの使い方を紹介します
Mac 2の機能を利用できるか確認します
まずOSが新ファミリAPIを サポートするか確認 利用可能なら次に Metal 3の機能を確認します 新型なので そこまで厳格な確認は不要です
そして利用したいファミリを確認します ここではCommonファミリの1つや Mac専用ファミリなどを確認します APIかバージョンが適用外なら 旧バージョンの 機能セットAPIに戻ります
ではクエリ可能な セットアップの任意機能です
ファミリはGPUの一般的なビヘイビアを 特定します しかしサポートされない 重要な機能や制限があります 例えばDepth24Stencil8や MSAA Sample Countsです その状況に対処するため Metalは各機能を 直接クエリするAPIを提供します しかし これに属する機能は 多くありません
前半で紹介した手法も 新しいGPUファミリに サポートされています
Deferredは全プラットフォームに対応 Programmable Blendingは 全Apple GPUでサポートされ ゲーム開発にうってつけです Tile DeferredとForwardも Apple専用の最適化で 新しいハードウェアに対応します Visibility Bufferは Macファミリのみです 解像度の条件により 制限されています 最後にファミリにサポートされた GPUパイプラインの機能をご紹介
幅広いサポートを受けることで いくつかの機能は レンダリングエンジンの 中核にもなります ご紹介したArgument Buffersと Indirect Command Buffersは Common 2のサポートを受けています
それでは このセッションのまとめです ぜひ皆さんのアプリケーションに 応用してみてください
前半は高度なレンダリング手法の 実装方法を紹介 Deferredなどの手法は Programmable Blendingを加え 最適化することで iOSに最適な手法となります Macファミリの 重心座標とクエリLODを使えば Visibility Bufferを実装し 高解像度でレンダーが可能 しかし どの手法でも レンダーループはGPUに移行できます 各Buffersを備えて カリング LODの選択はすべて― GPU上で処理されます またGPU上で演算ディスパッチを Indirect Command Buffersに エンコード可能
ハードウェアを 幅広くターゲットにする場合や 高度なMetal機能を使う場合もあります 再設計されたGPUファミリAPIで 機能の利用可否を確認しましょう
Metal機能やGPUパイプラインの詳細は Webサイトをご覧ください サンプルも掲載しています 各手法をアプリケーションに 応用できるでしょう ぜひラボにも お立ち寄りください
本日はありがとうございました (拍手)
-