-
MetalのAppとゲームを最適化する
リソース消費量の高いMetalのAppやゲームにおいて、パフォーマンス、メモリ、帯域幅の最適化を検討することは重要です。このセッションでは、レンダリングを円滑にして高いフレームレートを達成するための鍵となるベストプラクティスについて説明します。また、GPUへの負荷が高い処理や想定外の処理を特定するために役立つ強力なツールも紹介します。高いパフォーマンスを引き出せるGPU機能と、メモリの効率的使用に関するエキスパートからのアドバイスについてご確認ください。
リソース
関連ビデオ
WWDC23
WWDC21
WWDC20
WWDC19
-
このビデオを検索
(音楽)
(拍手) ようこそ 皆さん Metal Ecosystemチームの ギエムです この1年 ゲームデベロッパと協力し― 問題を突き止めてきました そして この講演を 行うことにしました 今日はMetalアプリケーションを 改善できる― 18のベストプラクティスを ご紹介します
悪くはない もしくは許容可能な― プラクティスではありません まして 間に合わせでは 絶対にありません 今日の焦点は ベストプラクティスです ご覧ください
まずDigital Legendsに 感謝を捧げたい バルセロナの精鋭集団で 「アフターパルス」の デベロッパです これは最高の映像美を 誇るゲーム カスケードシャドウマップや 遅延レンダリングなど― 多数のレンダリング技術と― ブルームやFXAAなど ポストプロセスを駆使 このゲームでデモを行い― ベストプラクティスを ご紹介します
この講演は3部構成です “全体的なパフォーマンス” “メモリ帯域幅” “メモリフットプリント” 最初は 全体的なパフォーマンスです
正しい解像度の選び方や オーバードローの回避や― フラグメントシェーダーの 呼び出し回数の減らし方 GPUサブミッション リソースストリーミング 熱問題も少し触れます
ではベストプラクティス 1 “正しい解像度を選ぶ” 必要な解像度が 効果ごとに異なる場合があり 画質とパフォーマンスの トレードオフを― よく考えて選ぶことが 重要です ネイティブか それに近い解像度で ゲームのUIを構成すれば― 表示サイズに関係なく 鮮明に見えます
解像度の確認には メタルフレームデバッガ
メタルフレームデバッガ内の 依存関係ビューアは― レンダーパスを 図式で表示します これはMetalの サンプルアプリケーション “CommandBuffer”で ビューアを開きます
ここではそれぞれの解像度内で 複数の効果が― 使われていると分かります 例えばシャドウマップと SSAOは― ライティングパスとは 解像度が違います また UIの解像度はネイティブで 鮮明です これらは このアプリケーションに 適した解像度です このような選択を してください ではベストプラクティス 2へ
“不透明でない オーバードローを減らす” オーバードローは フラグメントシェーダーの処理量です 不透明なオーバードローなら うまく減らすGPUなので 少し手助けするだけです 先に不透明なメッシュを レンダリングし― 透明なメッシュは後にする 完全に透明な場合 レンダリングしないことです メタルフレームデバッガを 再度 使います 今度は“Counters”で 所定のレンダーパスの― オーバードローを確認します ここではライティングパスに 注目します
オーバードロー数の計算は― フラグメントシェーダーの 呼び出し回数を― 保存ピクセル数で割ります カウンタは一番下のフィルターバーで すぐに探せます
このシーンは 完全に不透明で― オーバードローがなく 次に進めます 次に進んでいいか このように確認してください では次の ベストプラクティスへ
“GPUの作業を早く送信する”
GPUのオフスクリーン作業を 早めに予定すれば― ゲームのレイテンシと 反応性が改善し― システムがワークロードに より適応します フレームのGPUサブミッションを 複数にすること 特に レンダリングスレッドを 遅延させる― drawable待ちに入る前に 送信することが重要です drawableはフレーム終盤なので その取得後では― UIのコンポジションパスを 予定する― GPUサブミッションが 遅くなってしまいます 説明が難しいので デモを用意しました Metal System Traceで これを特定します
いいですね これは「アフターパルス」の キャプチャ 昨年 古いビルドから 取ったものです 昨年 ご紹介したGame Performance テンプレートを使いました Instrumentsは ご存じでしょう 今年 追加したのは “Thermal State”と― “Metal Resource Allocations” 後で取り上げます 今は起こりうるスタッタなどの 問題に注目します このDisplayのパネルの 下部を見ると― イベントが多く サーフェスの表示が 予想より長くなっています 取り上げるべき問題でしょう ここを拡大してみます “option”キーを 押しながら― カーソルを そこにドラッグします
ここでは 2つのフレームが― 予測より遅くなっているようで しかも― GPUが長時間 アイドル状態です デバッグしたい問題の 原因かもしれません 詳しく調べましょう Metal System Traceの トラックを― すべて開きます アプリケーションが 作業をどうエンコードし― それをGPUがどう処理するか 分かります オレンジのフレームに注目 多くの作業が エンコードされています シャドウマップや 遅延パスや― ブルームチェーンなどが あります GPUは実際には この処理をしておらず― このスレッドは drawableを待っています アイドル状態の原因です しかしエンコード済みの作業を 送信していないだけ これがベストプラクティスです drawable待ちの前に エンコードできる― オフスクリーン作業を 送信することです 解決策は1つの GPUサブミッションです GPUサブミッションは フレームの終盤の1つだけです つまりGPUの作業は 最後に発生
幸い 修正は簡単ですし Digital Legendsは 既に修正しています 「アフターパルス」の 新バージョンを見てみます
拡大してみましょう drawable待ちの間 アイドル時間がないですね Metal System Traceのトラックを 開きましょう 予定していた作業を GPUが― 既に処理していることが 分かります drawableを取得する前にね これでアイドル時間が 大幅に減ります そしてシステムが ワークロードに適応でき― 問題は生じません これで次に進めます 複数のGPUサブミッションが 既にあり― drawable待ちの前なので 遅延は起きません スライドに戻ります
この修正は非常に簡単で 問題を説明するよりも 簡単です 各フレームに 複数のコマンドバッファを作成 オフスクリーン作業の エンコード用をまず作ります これが早めの GPUサブミッションです コマンドバッファを コミットし― スレッドを遅延させる drawableを待ちます drawableを取得したら 最後の― エンコード用 コマンドバッファを作り― drawableを表示します これが最後の GPUサブミッションです これでフレームペーシングも 良好になります
複数のコマンドバッファを 使うだけです ではベストプラクティス 4へ “リソースを 効率的にストリーミング” リソースは 割り当てに時間がかかり― スレッドからのストリーミングは 遅延が起きかねない ベストプラクティスは メモリとパフォーマンスの― トレードオフを考えることと 起動時に割り当てと読み込みを 行うことです 実行時には 割り当ては不要です 実行時のストリーミングは 必ず― 専用スレッドから 行ってください 遅延回避のために 重要なのです このストリーミングと トレードオフに関しては― メモリフットプリントの部で 再検討します 今はMetal System Traceでの 調整のみにします 新登場の“Allocation”トラックが 表示するのは― リソース割り当てのイベント そして他のinstrumentsと― 同じタイムラインの割り当てです メインスレッドからストリーミングし 遅延の原因になりうる― リソースを特定できます
他に発熱調整も必要になります 重要なのは パフォーマンスが持続する設計です これはシステムの 発熱状態と― ゲームの安定性と反応性を 改善します ベストプラクティスは 発熱状態を“serious”で試すこと また この状態に合わせて ゲームを調整すれば― サーマルスロットルの把握に 役立ちそうです
今年 Xcodeに追加する Device Conditionsは― デバイスのウインドウから 発熱状態をseriousに設定できます “Designing for Adverse Network and Temperature Conditions”も― ぜひご覧ください
XcodeのEnergyゲージでも― デバイスの発熱状態を 確認できます この例では発熱状態を seriousに設定し― その状態のデバイスを 効率的に検証できます 2~3秒で その状態になるのです それでは 第2部に移りましょう テーマは “メモリ帯域幅”です
メモリ帯域幅が 重要なのは― メモリ転送は 負担が大きいからです 電力を消費し 熱を発します これを軽減するために― iOSデバイスはCPUとGPU間で システムメモリを共有 タイルメモリを GPU専用にしました Metalでは この両方を利用できます まずはテクスチャを 調べてみましょう 最も帯域幅を消費するのが テクスチャサンプリング 正しい設定の ベストプラクティスを提供します この部はゲームアセットのテクスチャの オフライン圧縮と― GPU圧縮を説明します 正しいピクセル形式の 選び方も まずはテクスチャアセット
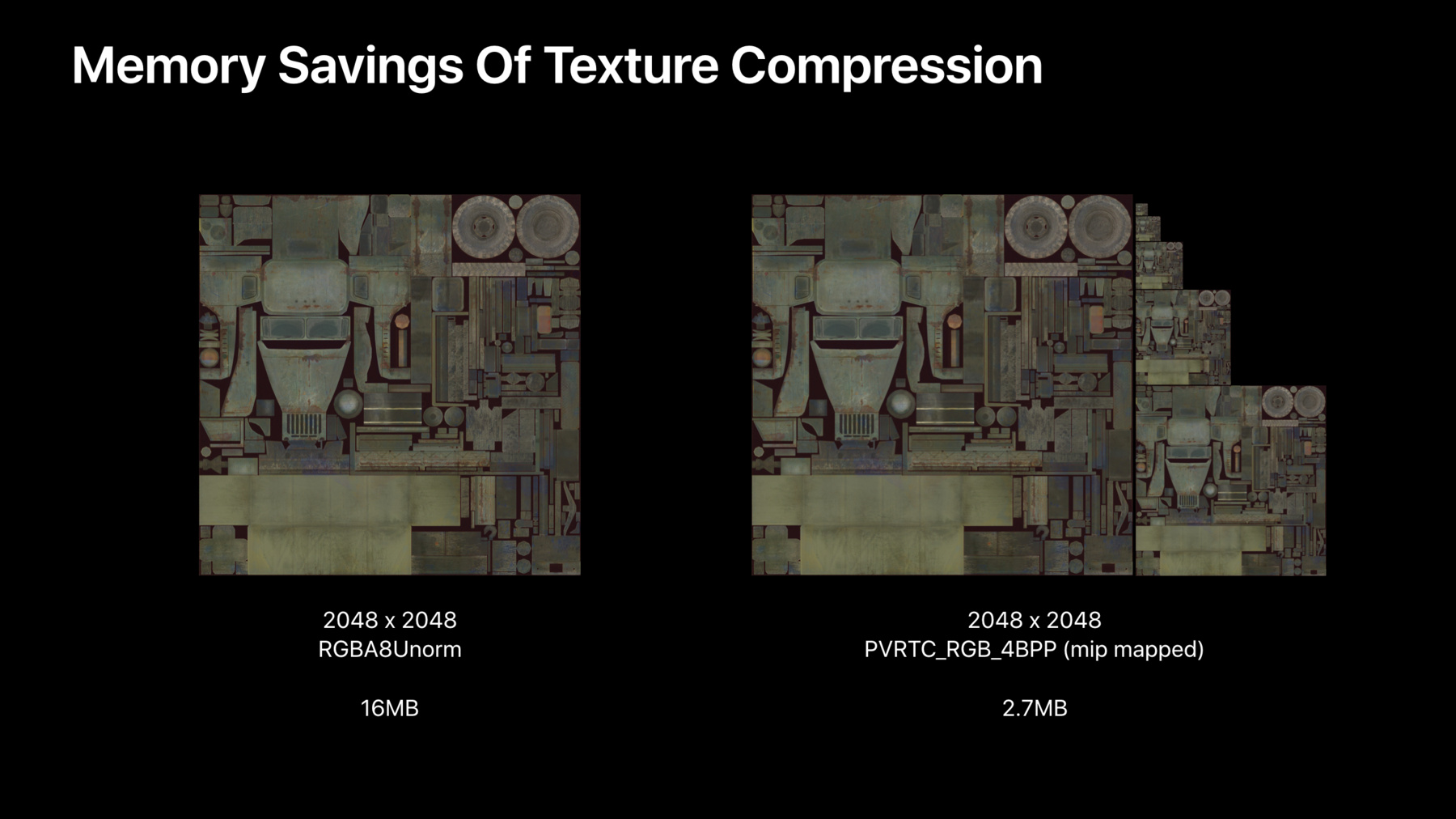
これを圧縮することは 非常に重要です 大きなテクスチャの サンプリングは時に非効率で アセットも 勝手に大きくなりかねません 必ずすべて圧縮して― 縮小しそうなテクスチャの ミップマップも生成してください 圧縮により メモリが節約できます
これは「アフターパルス」の 最大級のテクスチャ 圧縮されてなければ 読み込むために― 約16メガバイトの メモリが必要です テクスチャ圧縮により― ミップマップチェーンを含め 3メガバイト未満にできます メモリの大幅な節約です しかし「アフターパルス」は PVRTCを使用 iPhone 5Sなどの A7デバイスで動作するからです 新しいデバイスが対象の ゲームは― STCを使ってください 画質の圧縮率が向上します
正しく圧縮されたか 確認できるのが― メモリビューアです
Metalメモリビューアは 次の部で詳しくご紹介します 今は これを使って 全アセットを調べます 圧縮 ミップマップ生成 見栄えを ダブルチェック
しかし事前に圧縮できないテクスチャは どうなるでしょう? レンダーターゲットや 実行時に生成された分です
最新のGPUは ロスレス圧縮をサポート テクスチャを圧縮し アクセスを高速化できます ベストプラクティスは― GPUの高速アクセスのための テクスチャの最適化 テクスチャの正しい設定は 非常に重要です ストレージモードを privateにすれば― GPUだけがテクスチャデータに アクセス 内容を最適化できます それとunknown usageフラグを 設定しません shaderWriteやpixelViewなど 不要な使用状態フラグもです 圧縮が無効になりかねません CPUとGPUがアクセスできる 共有テクスチャを― CPUがデータを更新した後 明示的に最適化します これも重要です これらが 少しのコードでできます 本当に少しだけです 最適なテクスチャの作成には ストレージモードをprivateに GPUのみアクセスします それと明示的で しかも保守的な 使用状態フラグを設定します テクスチャが 中間レンダーターゲットなので― 他の使用状態フラグは不要です
では共有テクスチャは? こちらは少し難しい CPUとGPUの両方から アクセスできるので― CPUがテクスチャの領域か テクスチャデータを更新する場合― コンテンツの最適化をGPUに 明示的に要求すべきです CPUのデータ更新回数と その後の GPUのデータへの― アクセス回数には トレードオフがあります
ここでもメモリビューアが 助けてくれます メモリビューアは ストレージモードも― 使用状態フラグも 表示できるからです この画面だけで 圧縮されたテクスチャと― 正しく設定できたテクスチャを 特定できます 優れたツールです テクスチャの設定は ほぼ完了で あとは― 正しいピクセル形式の 選択です 大きいと帯域幅を使うので ベストプラクティスは― 不要なチャネルの ピクセル形式を避け― 可能な時は 精度を下げることです しかしサンプルレートも ピクセル形式に左右されます ここではピクセル形式の― テクスチャのサンプルレートへの 影響が分かります 特に注意すべきは RGBAの32ビットフロートなどの― 128ビット形式です サンプルレートが 4分の1なのです ポストプロセス効果の 参照テーブルや― ノイズテクスチャに 多い形式です
ここでもメモリビューアが 助けてくれます テクスチャを名前かピクセル形式で 絞れます このデモがSSAOの実装に― 16ビット形式を使っているか 確認します ノイズテクスチャには重要です しかし要注意なのは― テクスチャの大半が レンダーターゲットの場合です ゲームが複雑になるにつれ それらのテクスチャが― 多くの帯域幅を 消費しかねません 詳しく見ましょう
MSAAに注意しつつ レンダーパスのアクション― “読み込み”“保存”を 検証し タイルメモリにも触れます
まずはアクションの最適化です
不要なレンダーターゲットの 読み込みや保存は避けます 見過ごしやすい アクションなので― 問題になりかねません ですから必ず防いでください これも少しのコードで かなり簡単にできます renderPassDescriptorを 設定します colorアタッチメント1は “一時的” そこから 読み込みも保存もしません 正しいアクションの設定は 非常に簡単です “読み込み”の設定はclear 後で内蔵のGPUに 転送しないよう― “保存”は dontCareにします レンダーパスの最後に データを書き込みません これだけです 正しくできたか検証するのも 簡単です 依存関係ビューアが使えます
この例は 後で使わない colorアタッチメント1を 保存しています この問題があることを アイコンが示します 前のスライドで見たとおり 設定をdontCareにすれば― 問題は片づきます このとおり 実に簡単です
マルチサンプルレンダーターゲットには 特に重要です iOSデバイスには 高速のMSAAがあります タイルメモリからの リゾルブ処理で― 帯域幅は 余分に消費されません マルチサンプルテクスチャを “一時的”と宣言できます 補助のシステムメモリの 割り当て自体が不要です ですからネイティブ解像度より MSAAを考えること 非常に効率的です また マルチサンプルテクスチャの 読み込みや保存をせず― そのストレージモードは memorylessに設定すること memorylessは後ほど詳しく 今はマルチサンプルテクスチャの 設定方法を見てみましょう
ストレージモードを memorylessに設定 レンダーパスに 使われていることと― 内容のクリアと サンプルの破棄も確認します マルチサンプルテクスチャは リゾルブ処理のみ このような中間データは 保存不要です 最終的なresolve textureのみ 保存します これも依存関係ビューアで 正しくできたか確認できます
この例はマルチサンプルテクスチャを 読み込んでいます 非常に負担が大きいです 先ほどの正しいフラグを 設定すれば 85メガバイトのメモリ帯域幅と フットプリントを 節約できます マルチサンプルアタッチメントの検証は 重要です ただし こうした節約が 可能になるのは― MSAAを使用して タイルメモリを― 暗黙的に 利用した場合のみです 次のベストプラクティスは タイルメモリの明示的な利用 タイルメモリに アクセスできるのは― プログラマブルブレンディングなどの 機能です ベストプラクティスは その明示的な利用です 特に より高度なレンダリング技術を 実装すること “Modern Rendering with Metal”で 詳細に取り上げています 今は遅延シェーディングを 見てみます
遅延シェーディングが帯域幅を 大量に消費するとされるのは ピクセルプロパティを示す テクスチャとして― Gバッファを保存するよう 要求するからです テクスチャは2番目のパスで サンプリングされ― 最終色がレンダーターゲットに 蓄積されます 全データをGバッファから保存し 読み込んでいるので― 帯域幅を大量に消費します iOSは はるかに 効率的にできます
プログラマブルブレンディングで― フラグメントシェーダーが タイルメモリから― 直接アクセスできます つまり蓄積するシェーダーにより Gバッファデータが― タイルメモリに保存でき 単一のパス内でアクセスできます 非常に強力な機能で Digital Legendsは 長年 使っています これは「アフターパルス」の 単一パスでの― 遅延レンダリングです 見事です 4つのGバッファは一時的で 最終的な色と深度のみ保存され 美しく 効率的です ここで サミュエルの 依存関係ビューアのデモです (拍手)
ありがとう 旧バージョンの 「アフターパルス」で― パフォーマンス向上のため 最適化できる所を探します メタルフレームデバッガの 依存関係ビューアで― ギエムが挙げた問題を お見せします
CommandBufferをクリックし ビューアを開きます
エンコードされたGPUパスが 表示されます
「アフターパルス」の CommandBufferは1つで 冒頭でシャドウマップを レンダリング 次が遅延フェーズ
ここから輝度計算と 粒子シミュレーションと― 最後のスクリーンパスが使う ブルームチェーンへ
今年の依存関係ビューアは 非常にコンパクトで レンダリング方法が 上位レベルで簡単に見られます どのグループも さらに詳細を見られます このブルームチェーンは 12パスから成ります
このビューアで ギエムが挙げた問題を特定できます この最後のパスにも問題が アイコンをクリックして 見てみます
先ほど挙げられた アクションの問題のようです “保存”を storeにしていますが― 使っていないテクスチャです ですからdontCare設定が 推奨されています この2つで約14メガバイトの メモリ帯域幅を取り戻せます
今年はグラフ内の問題を 見つけやすくしました 右下の“!”ボタンを クリックすれば― 問題が表示されます
もう1つのベストプラクティスは “正しいピクセル形式を選ぶ” 今年はiOSに Depth-16を導入しました 新しい検索で Depth 32のテクスチャを探します
ShadowMapテクスチャに 36メガバイトのメモリ Digital Legendsのメンバーは この後 帰国して― この新形式を使って 調べられます そして条件が許せば メモリの半分を節約できます こうして検索してみると― メモリをもっと大幅に 節約できそうです
こうして 依存関係ビューアを使い― 旧「アフターパルス」の 問題を調べました Digital Legendsは 既に改善しています 見てみましょう
複数のCommandBufferを 使っていますね これで ギエムが挙げた問題― “drawable待ちでGPUが アイドル状態”は解決します
最後のパスを拡大すると― “保存”アクションの問題も 解決済み この2つは 一時的なテクスチャで ストレージモードは memorylessです システムメモリを 全く使ってません レンダリングパイプラインの デバッグを始めるのに最適です 次はメモリフットプリントを 最適化する― ギエムのベストプラクティスです (拍手)
すばらしいデモをありがとう 皆さんにも 使っていただきたいです では第3部に進みましょう メモリフットプリント ゲームにとって 非常に重要です アプリケーションの 両システムの応答性を維持すべく― iOSが厳しいメモリ制限を 実行するからです
ご存じでしょうか iOS 12では メモリアカウンティングを変更 この変更は Metalのリソースに影響します バッファや テクスチャなどです メモリフットプリントの 大半を占めます そこで重要なのが メモリフットプリントの測定 XcodeのMemoryゲージを 使います これが報告する既存の数値は ゲームの― メモリフットプリントの 測定にも使われます それでゲームの数値を 確認することが大切です 今年はゲーム終盤の アプリケーションが課す― メモリ制限も表示されます
しかしMetalのリソースの メモリを― 絞り込んで調べたい時は?
今年はメモリビューアを― メタルフレームデバッガに 追加しました このビューアは2部構成です 上半分は棒グラフで リソースをカテゴリ別に表示 タイプ ストレージモード 使用状況などです ここでは最大のリソースの― 強調表示ができ リソースの表示時間も分かります 次は下半分のテーブルで 絞り込んだリソースを 示します リソースタイプ固有の プロパティを含みます ピクセル形式 テクスチャの解像度などです 一番下に フィルターバーもあり さらに絞り込んで 調べられます 非常に強力なツールです これを使い GPUのリソースの フットプリントを― 把握していただきたい
これからご紹介する もう1つの優れたツールが― Metal Resource Allocation Instrumentです これは3部構成で “Metal Resources Allocations”は― ゲームの現在の メモリフットプリントです “Allocation”は― リソースの割り当てと解除のイベント そして情報を表示します それと詳細なテーブルビューや キャプチャされた割り当ての 詳細を表示します どちらも非常に強力で ゲームのメモリフットプリントの 概要と― 経時的な変化が分かります
しかし他にも 皆さんが― 求めてきた機能が ありましたね 使用可能なメモリを― 実行時に問い合わせる C言語のAPIです リソースストリーミングの 効率が上がり― メモリ制限が 破られかねない― メモリスパイクを回避できます
すばらしいAPIがもう1つ オンデバイスGPUキャプチャです Xcodeが要求しない GPUキャプチャを― プログラムでトリガできます ゲームのテストと品質管理に 最適です MetalCaptureEnabledを 情報プロパティリストに足すだけです 両方のAPIの 合わせ方を見てみましょう 短いコードにまとめます ここではメモリスパイクなどが原因の メモリ制限が― 近づいているか調べて― GPUトレースをキャプチャ メモリビューアで デバッグするためです やってみましょう まずはメモリ制限が近づいているか 調べます 近ければ次のフレームを キャプチャします それも いつもどおり レンダリングします
そのフレームの終わりまでに キャプチャを停止し― GPUトレースを処理します 処理方法は皆さん次第です お勧めは ゲームを終了するか― ここのGPUキャプチャを 無効に 1つ1つを キャプチャしない方がいいので こうすれば両方のAPIを うまく使えて― メモリフットプリントの 詳細が分かります すばらしいので やってみましょう メモリフットプリントを どう減らせるか ベストプラクティスが 豊富にあります ここでは 無記憶レンダーターゲットと リソースストリーミングと― ゲームアセットと メモリ集中型の効果を取り上げます まずは 無記憶レンダーターゲット メモリ帯域幅の部で 既に触れました
一時的な レンダーターゲットは― 読み込みや保存はされません システムメモリの割り当て自体 不要です だから マルチサンプルアタッチメントは― すべて ストレージモードを memorylessに ほんの少しのコードで これができます
テクスチャ記述子に memorylessを設定するだけ また レンダーパスの 設定で― レンダーターゲットを “一時的”にします Gバッファを “一時的”に設定したい “読み込み”をclear “保存”をdontCareにすれば― Gバッファは保存されません
Digital Legendsの 「アフターパルス」を見てみます 上が旧バージョンの 「アフターパルス」 一時的なGバッファがありますが システムメモリが 補助しています 下は新バーションで こちらの方が― Gバッファが大きいです しかし これは 一時的なGバッファで システムメモリに 補助されていません 中間Gバッファのストレージモードは すべてmemorylessです すばらしいことに この新バージョンは― この設定だけで メモリフットプリントを― 60メガバイトも 節約できたのです しかも何も損なわれてません トレードオフも何もなく 機能しています すばらしい では残りの ベストプラクティスです
こちらの ベストプラクティスには― メモリとパフォーマンスの トレードオフがあります ここでは リソースストリーミングを メモリフットプリントを 増やさないように― メモリとパフォーマンスの トレードオフを考え― 特にメモリ制限があるなら 使うアセットだけ読み込みます それと使わなくなったリソースは すぐに解放すること 特にスプラッシュスクリーンや チュートリアルUIです
これは難しい決断ですが― やはりメモリビューアが 助けてくれます
使わないリソースを フィルタですぐに絞り込めます そうすることで 下のテーブルが更新され― このフレームで使われていない 全リソースを表示 さらなるメモリビューアの使い方は 終盤で触れます ではベストプラクティス 14へ “小さいアセットを使う”
アセットは 必要な分だけ大きくし― 画質とメモリのトレードオフを 考えるべきです テクスチャとメッシュは 必ず圧縮する メモリ制限を受けそうなら― 小さいミップマップレベルのみ 読み込む方がいいでしょう メッシュなら 詳細度の低いものを
しかし画質とメモリの トレードオフがあります それをいつ取るかは 皆さん次第です
次のベストプラクティス 15は ほぼ同じで メモリ集中型の効果を 簡素化します
シャドウマップなどは大きな オフスクリーンバッファが必要です ですから こうした効果の― 画質とメモリのトレードオフを 考えること 大きなオフスクリーンバッファは 解像度を下げます メモリ制限が厳しければ― こうした効果を すべて無効にします トレードオフが 生じてしまいますが― 他に選択肢はありません
次のベストプラクティスは 少し異なります この最後の部では― メモリフットプリントを さらに減らせる― より高度な概念をご紹介 Metalのリソースヒープと―
パージ可能なメモリと パイプライン状態オブジェクト まずMetalの リソースヒープから これを使うと アプリケーションは― 事前のメモリ割り当てを 明示的に制御できます ここでは独自の割り当てを持つ 3つのテクスチャから― 単一のリソースヒープへ 3つを別々に保持する 単一の割り当て領域です テクスチャが圧縮され この時点でメモリが節約できます
エイリアシングを行うと メモリを大量に節約できます 特にポストプロセスパイプラインで ゲームが拡大すると― レンダリングに 多くの中間メモリを要します そこで これらの効果に リソースヒープを使い― 多くのメモリを エイリアスすること 例えば依存関係のないリソースに メモリを再利用します SSAOや被写界深度などの リソースです
どんな感じか見てみましょう 先ほどと同じ リソースヒープです 3つのテクスチャが 同時に使われてなければ― エイリアス可能です これでメモリを 大幅に節約できます 複雑な ポストプロセスパイプラインで― ゲームの規模を拡大できます 中間レンダーターゲットと 中間メモリに― 大量のメモリを費やす必要も ありません この優れた機能の活用を お考えください 次は もう1つの高度な概念 パージ可能なメモリです
このメモリ状態は3つ “不揮発性”“揮発性” そして“空”です 揮発性と空の メモリ割り当ては― メモリフットプリントに 加算されません 揮発性の場合は システムが いずれ再利用できるからです 空の場合は 過去に再利用されているから リソースの再生成が 必要かもしれません しかしリソースキャッシュに最適の メモリになります ベストプラクティス 17は― リソースを揮発性にすること 時にフットプリントの大半を 占める一時リソースを― Metalにより 明示的に管理でき― パージ可能な状態を 明示的に設定できます そこで アイドル状態の メモリを― 保持しているキャッシュに 絞ります フットプリントに 加算されないよう― パージ可能な状態を 慎重に管理します これも非常に短いコードで できます やり方を見てみましょう テクスチャキャッシュは― バッファキャッシュだった可能性も キャッシュ内のテクスチャの パージ可能な状態を― “揮発性”に設定 キャッシュが アイドル状態なのです テクスチャを 頻繁には使用しないからです
そのキャッシュから使う リソースには― “不揮発性”と フラグを立て― システムが補助データを 削除するのを防ぎます ここでは空でした これは先に言及した 以前の状態です データを再生成する必要は ないかもしれません キャッシュの種類によります しかし この後は― このリソースを いつもどおり使えます
1つ とてもいいやり方が あります 共通バッファの補完も チェックすること 補完されたらそれを処理し そのリソースに― また“揮発性”と フラグを立てれば― メモリフットプリントに 加算されません アイドル状態のメモリの キャッシュが多い時は― 特に積極的に 明示的にすべきです
最後はPSO パイプライン状態オブジェクト もうご存じでしょう PSOはMetalのレンダリング状態を カプセル化 PSOを構成する記述子は Vertex関数 Fragment関数や― Blend State記述子や Vertex Layout記述子などです これらが最終的なPSOに コンパイルされます
レンダリングに必要なのは このPSOだけです ベストプラクティスは 明示的にそれを利用すること Metalはレンダリング状態の大半を 事前に読み込めるからです しかしパフォーマンスと― メモリのトレードオフを 考えてください メモリ制限がある場合は 不要になったPSO参照は― 保持しないことです もう1つ重要なのが PSOキャッシュを作成したら― Metalの関数参照を 保持しないことです PSOの作成にのみ必要で レンダリングには不要です この意味を 記述子で確認しましょう これはPSOであり PSO記述子でもあります そしてPSOの作成後― Vertex関数 Fragment関数の参照を 解放してください 保持するのは メインのPSOキャッシュを― 読み込み時に追加する時のみ メモリ制限があれば PSOの解放も考えてください 不要と分かっているPSOです
では オニェチによる メモリビューアのデモです (拍手) ありがとう 皆さん こんにちは
ここでご紹介する方法は メモリビューアを使い― メモリパフォーマンス向上のため 最適化された― メモリフットプリントを 把握します
再び「アフターパルス」の 旧バージョンのフレームです 左上 Memoryゲージにある デバッグナビゲータ クリックすると― ビューアが開きます このフレームの ライブリソースの状態が分かります 目的はメモリフットプリントを 減らす機会の発見 まずはオレンジ色の 棒グラフから リソースを タイプ別に表示します テクスチャの割合が 最も大きいですね 約440メガバイトです このセクションに 絞り込むには― フィルターボタンをクリック
グラフもテーブルも テクスチャのみを表示します ギエムいわく メモリフットプリントを減らすには― まず未使用のリソースを 当たってみること 今度は青い棒グラフに注目
使用状況を示しています 未使用のテクスチャが 約200メガバイト 未使用のリソースは― このフレームの 最終出力に貢献しません GPUはアクセスしません
“Unused”をクリックするだけで 簡単にできます 未使用のテクスチャが出ます
次は割り当てサイズで ソートし― 最大のテクスチャを特定 最大のテクスチャは 約13メガバイトで 問題を抱えています 依存関係ビューアのデモで 出てきた問題と同じです 見てみましょう
大きな 未使用のテクスチャです CPUのアクセスも― コマンドエンコーダへの バインドもなし 推奨は“リソースの読み込みを 避けるか―” “揮発性に 設定してください” CPU Accessと Times since Last Boundを見ると CPUやGPUのアクセスが全くないと はっきり分かります これで断言できますが― 必要になるまで解放すべき リソースです 節約できる13メガバイトを 迅速に特定できました では次の問題へ
ここではテクスチャは 一時リソースです 47秒以上 コマンドエンコーダに バインドされていません つまり このテクスチャは47秒間 フレームで使われていません 時々 フレームに貢献するので できれば揮発性にすべき― リソースの有力候補です すばらしい 我々は あっという間に― 節約できる約14メガバイトを 発見しました メモリフットプリントを 減らすには― 未使用のリソースに 当たること それと問題を調べれば 削除候補が見つかります しかし もう1つ 注意すべきは― Times since Last Boundです CPUのアクセスがあり GPUへの送信がない― 未使用のリソースを 探します
少し角度を変えます テクスチャが使われている ケースで― 節約できるメモリが 見つけられるか Usedフィルターに切り替えて 見てみます 約18メガバイトで問題が2つある テクスチャがあります 見てみましょう
1つはロスレス圧縮を 避けたこと “ShaderWrite”使用状態フラグを 理由に避けました レンダーターゲットにしか 使われないのに 2つ目はストレージモード このテクスチャは 一時的なレンダーターゲットで “読み込み”“保存”の アクションは要求されません しかしストレージモードは “Shared” “Memoryless”にすべきです 別々の推奨事項が2つあり― どちらか1つしか選べません しかし現時点では この推奨事項は― 現フレームまでに収集された データに基づくものです このフレーム以外での リソースの使い方は皆さん次第 このテクスチャが一時的で 今後 レンダーパスになるなら― “Memoryless”への 切り替えが優先です この18メガバイト分 メモリフットプリントが減ります 逆に将来のレンダーパスで テクスチャが一時的にならないなら― ロスレス圧縮の選択も 考えるべきです メモリ帯域幅に いい影響を与えるからです この場合は― 冗長な“ShaderWrite”フラグを 削除するだけ
ここまでは―
メモリビューアの能力の ごく一部です 数回クリックするだけで メモリの使用状況が分かり― パフォーマンスに影響しかねない 見つけにくい問題もすぐに発見します ではギエムに 戻ってもらいます どうも (拍手) ありがとう すばらしいデモだった たくさんのベストプラクティスを 今日は見てきました 全部で18ですが じっくり検討すべき内容ばかりです しかも非常に 関連性が高いものばかりです メモリ帯域幅の ベストプラクティスは― メモリフットプリントの削減にも 役立ちます この内容はMetalを使ったゲームや アプリケーションの― 最適化のチェックリストと 考えるのが一番かも これらの要素すべてを 慎重に検討すれば― 最適化されたゲームや アプリケーションが作れる それが この講演のテーマでした
さらなる詳細は ドキュメンテーションや― この後のラボでご覧ください 引き続き どうぞお楽しみください (拍手)
-