-
プロフェッショナル向けのAppのためのMetal
Metalは、AppleプラットフォームにおけるGPUによる高速処理の心臓部となる、プラットフォームに最適化されたグラフィックスおよび演算のためのフレームワークです。このセッションでは、最新の高パフォーマンスなプロフェッショナル向けのAppとワークフローに向けたテクニックに対応した、Metalアーキテクチャの主要な側面について説明します。Metalの機能を使用してパフォーマンスを最適化し、ビデオ編集パイプラインで安定したフレームレートを維持する方法についてご確認ください。CPUとGPUの並列処理を活用する方法と、効率的なデータスループットのためのベストプラクティスも紹介します。
リソース
関連ビデオ
WWDC21
WWDC19
-
このビデオを検索
(音楽)
(拍手) “Metal for Pro Apps”セッションへ ようこそ 私はユージーン 今日は同僚と一緒に― 新ワークフローでの Metal活用法を紹介します MacとiPadの機能を 最大限に引き出していきます まずPro Appとは何でしょう それは コンテンツ作りのプロが 利用するアプリケーションです 例えば テレビ番組や― 写真 3Dアニメーション 活字や音声制作で使います 皆さんのような サードパーティーデベロッパの 開発したAppもそうです 例えば Autodesk社のMaya
3Dアニメーションなどのソフトです オーディオや音楽制作が可能な Logic Pro
写真編集ソフトの Affinity Photo
動画編集ソフトの― DaVinci Resolveも
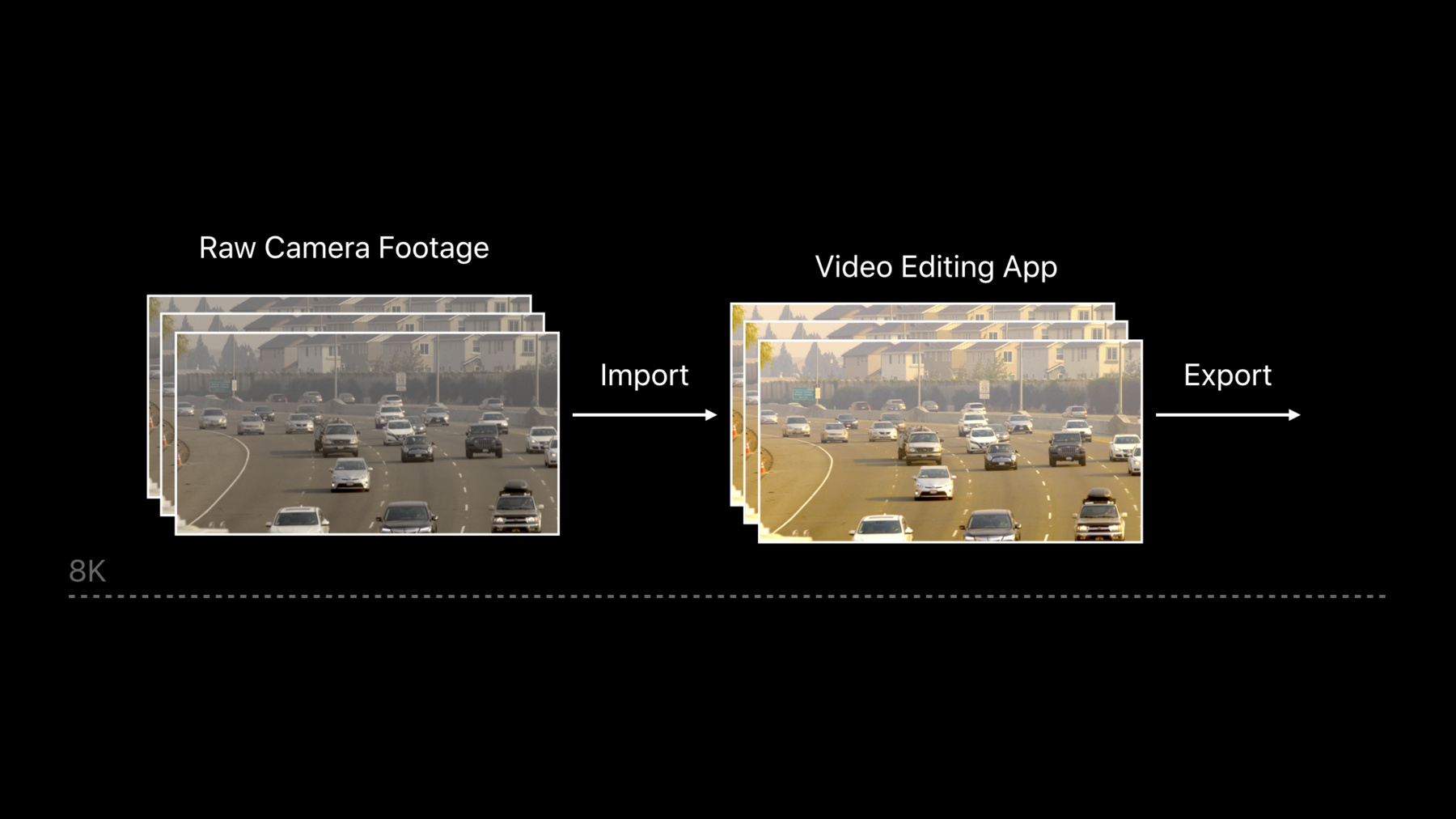
Pro Appは我々の エコシステムに必要不可欠です 最新のMac Proと Pro Display XDRは 強力なGPUに対応 そして A12X Bionicで この分野での進化に コミットしていきます Pro Appの作業負荷は大きいです 膨大なアセットを処理するからです 8Kビデオや何十億ものポリゴン 何千もの写真や 何百もの音声トラックなどです これらはCPUとGPUの 多くの処理能力を必要とします そして常に挑戦なのは
コンテンツの忠実性を保ちつつ 処理時間を短くすることです 今日のトピックを紹介します まずはプラットフォームでの ビデオ編集 そして革新的な8Kへの最適化 次にアプリケーションへ HDRサポートを追加する方法 また すべてのCPUポートと GPUチャネルにスケールさせる方法 最後に 効率の良いデータ転送方法を 説明します まずは8Kコンテンツを 念頭においた― ビデオ編集パイプラインです ビデオ編集は要求が多く 創造性に富んだ作業です ビデオアプリケーションを使い Metalが どう役立つか説明します 我々は Blackmagic Design社と共に 開発を重ねてきました ソフトとプラットフォームの 8Kの作業最適化において 到達した成果を誇りに思います まずは 最初に8Kコンテンツを 試した時の結果からです リアルタイムではありませんね 動きもスムーズではありません これではダメです そこで 対処方法を使いましょう 8Kの編集前の大きな映像があります まずトランスコードして 色情報を取得 次にサブサンプルして4Kに縮小 編集がリアルタイムに適用できます しかし1つ 問題点があります 正確ではないので カラーグレーディングできません そこで 元のコンテンツに 編集を適用させますが レンダリングに時間が掛かります 確認後は同作業の繰り返しです そこで 時間を短縮すべく― 8Kコンテンツを そのまま使えるようにしました このようにリアルタイムの 編集を可能にしたのです
まず効率的なビデオ編集パイプラインを 作ります パイプラインの基本デザインと ハードウェアの活用法 フレームワークを説明します そして巨大なアセットへの対処法 そして最後に 予測可能なフレームレートを 維持するための― 対処法も紹介します まずはビデオ編集パイプラインです
これらは ビデオ編集Appに必要な ビルディングブロック コンテンツを読み込み デコードします そして処理後に 表示かエンコードします ここでは デコード処理や エンコードと表示を説明します AVFoundationを使った インポート法なども含みます AVAssetReaderとAVAssetWriterの サンプルもご参考に
では デコードをMetalに近づけます
Video Toolboxフレームワークは 効率的で高性能な 映像処理をします iOS macOS tvOSなど 幅広いフォーマットに対応し Appleのどのハードウェアでも 利用可能です デコードの基盤は 復元セッションです 設定を説明します まず ハードウェアデコードと指定し 各映像ストリームに セッションを作ります completionHandlerを配置します
ビデオのストリーム中に デコードフレームを呼びます コードがブロックしないよう Asyncフラグを含みます デコードが完了すると コールバック関数が呼ばれます 最後に整理するのもお忘れなく これがフレームの復元方法です あなたの作業が最善な方法か 確認する方法があります
ハードウェアデコードの ブロックがすでにある場合は? コピー無しで 同じ物理メモリを使うよう― IOSurfaceという 内部オブジェクトを利用します IOSurfaceは ハードウェアアクセラレーションの― イメージバッファです 同じGPU内をプロセス間で共有でき このシナリオにピッタリです Core VideoやMetalは CVMetalTextureCacheを使い IOSurfaceの利点を 生かしてくれます 設定を説明します
CVMetalTextureCacheを作り Metalデバイスを使い ピクセル処理をします CVピクセルバッファを得たら Metalテクスチャへ変換します IOSurfaceを使っていれば 無料で自動的に変換されます テクスチャやピクセルバッファの 整理もして 格納キャッシュを見やすくします
MTLテクスチャのフレームができ ピクセル処理の準備が整いました ここで選択肢が生まれます 独自に処理などのカーネルが 書けますね Metalの言語がC++なので 簡単ですが Performance Shadersの利用を お勧めします パイプラインに ニューラルネットワークも構築できます では MPSを使い ブラーフィルタを実行します Metalキューと共通バッファからです
ブラー(ガウス)カーネルを 作成します MPSに組み込まれています ここでエンコードを試み 念のためフォールバックを 割り当てます 最後に共通バッファをコミット MPSはとても強力なフレームワークで どのデバイスにも有効です 更に学んで ぜひ使ってください
ピクセル処理が完了しました 次はMTLテクスチャを 出力フォーマットにエンコードします またVideo Toolboxを使い 効率の良い方法を紹介します
新しいMac Proには いくつかのGPUがあり それぞれに複数の エンコードエンジンがあります
Video Toolboxを デバイスとしてもいいですが コピーの負担を最小にするため 指定しましょう その場合 次の方法が有効です CVPixelBufferPoolで メモリをリサイクルさせます
こちらが利用可能な エンコーダです まず EnableHardwareフラグで ハードウェアエンコードと設定 そして デバイスを指定 ピクセル処理と 同じデバイスを使うことが とても重要です CVPixelBufferPoolを使うことで ハードウェアエンコーダと同じ フォーマットを得られます
このように バッファを取得し 再度MetalTextureCacheを使います そして合わせたデータを― バイプラナ形式に変換します Video Toolboxに必要な形式です そして整頓し バッファをリサイクルさせます
これで効率的な パイプラインが構築できました すばらしいですね 表示の説明の前に 8Kについて話しましょう 8Kはとても大きなアセットです 対処法をご説明します まず考えてみてください 8Kフレームは巨大です HDフレームの16倍 非圧縮で270メガバイトです
毎フレームに 約300メガバイト必要です 1秒30フレームで 処理能力は9ギガバイト PCI Expressの最大領域に近いです ProResの4x4圧縮でも 10分のクリップが 簡単に1テラバイトになります これではリアルタイムの再生が困難です では XcodeのInstrumentsを使い トレースしてみましょう
先ほどお見せたビデオ再生の システムトレースです Virtual Memory Trackをズームすると 膨大なページが確認できます ゼロ埋めコストも高いです 下の方ですね デコードのスレッドが 行き詰まりになっています メモリの管理が重要になります
現代のOSは実際に使うまで メモリを配分しません デコードで新しいページに 接続するためには システムの処理を待つ必要があります 解決方法は簡単です 再生が始まる前に CPUバッファに― 全ページを準備しておくのです メモリ管理に関するヒントを紹介します
すべての配分はシステムの 指令があります 大切なのは早めに処理し 中間処理を避けることです そして常にバッファを 再利用することです ですので CVPixelBufferPoolや― CVMetalTextureCacheなどの オブジェクトを使いましょう フレームの管理状況が向上しました しかしアプリケーションでは 多くの細かい配分が必要になります それらの対処法を紹介します
MTLheapではメモリ配分を 効率よくできます ヒープは作成時に 配分されているため カーネル指令は必要ありません ヒープがモノリシックだからです まとめて常駐しています ヒープからの割り当ては 厳しいメモリ内でも可能 また共有バッファから エイリアス可能です 通常のバッファでは無理でした これからお見せします 割り当てをエイリアスする例です まずデバイスでヒープを作成します
フィルタ適用時に ヒープからblurUniformsを作成します
次に 同じヒープから別のバッファを colorgradeUniformsに
カラーグレーディング以降は 不要になるので エイリアスできるようにしておきます するとメモリがリサイクルされます 新しい中間バッファを割り当てると ヒープはマークされたメモリを 再利用します とても効率がいいです リソースの割り当て方法でした 次は フレームを 予測可能なレートで― 表示する方法の説明です
これは トリプルバッファリングの 一例です 30ヘルツのビデオを 60ヘルツのディスプレイで見ています 不均一にフレームが 表示されていますね スムーズではありません この理由は何でしょう タイミングを無視して GPU処理が発生しています 3フレーム目のエンキューで CPUはブロックされます 1つ目のフレームが出るまで 次を待ったままとなります この方法では最大限のGPUで 残念な結果にしかなりません 各フレームが同じ長さで あるのが理想です 解決法はCore Videoが提供する CVDisplayLinkです これは高精度の低水準タイマーで リフレッシュ速度で VBLANK前に通知します
CPUに可能な限りのフレームを エンキューさせず DisplayLinkで タイミングを計ります そしてGPUへフレームを送ります これで再生の乱れが軽減できます コードスニペットで説明します まずディスプレイとリンクさせます
次にコールバックハンドラの設定です 呼び出すと 現在の時間と VBLANK時間を取得します そして これらの値を基に 呼び出しの― タイミングを決定します 希望の頻度に調整することもできます これで再生がスムーズになりますが 更に1歩進めます 60ヘルツのディスプレイで 24ヘルツのコンテンツを再生する場合 3:2プルダウンが必要です VBLANK3つに対し偶数のフレームを 2つに対し奇数を表示します 不一致に対応するには この方法しかありません しかし先ほどのスニペットで 解決できます 更にその上の結果が出ます 新しいPro Display XDRは 48ヘルツにも対応しています 24ヘルツのコンテンツは スムーズに動くでしょう
私たちは多くの最適化を 実現してきました 最終的な結果をお見せします 先ほどの8Kのビデオを DaVinci Resolveで再生中です プレーバックがスムーズですね
Blackmagic Design社と協力し すばらしい結果に到達できました 皆さんも この高性能な フレームワークを使い 新しいPro Appを作ってください
8Kについては以上です 次はディリープが HDRのサポートや アプリケーションへの応用を説明します ディリープ (拍手) ユージーン どうも 近年 ハイダイナミックレンジ 技術の改良で― 映像の質が大きく向上しました Appleでは常に イメージ技術の向上のため サポートを加えてきました 技術開発にも力を入れ 例えばRetinaディスプレイ 4Kや5Kの解像度 広色域の色空間などが含まれます 結果 デベロッパの皆さんは 高画質の映像を 作り出せたでしょう これまでに続き 今年は Mac OSで HDRのサポートを含みました HDRレンダリングやディスプレイを 紹介します
4つのトピックで説明します 最初は簡単にHDR映像の 特徴を話します 次にHDRレンダリングへの Appleのアプローチ 更にMetalを どのように使うかを説明します 最後にお勧めの ベストプラクティスも紹介します まずはHDR映像の 一般的な特徴からです 何が特別なのでしょうか HDR映像はSDRのそれに比較すると コントラスト感に優れています 明るい部分と暗い部分の 階調が細かいです SDR映像では識別できません 黒潰れや白飛びが発生します HDR映像は色の種類が豊富です より広い色域をカバーし 現実に近い映像になります そしてより明るいです 明るさの情報が 画像にエンコードされています 高い輝度とコントラスト比で 映像にライト効果をもたらし 現実に近い色を表現します 表示するには 対応可能なディスプレイが必要です 画像の細かい情報を 映し出せるディスプレイです ディスプレイには 高い輝度と色忠実性― 高コントラスト比を 映し出す技術が必要なのです 新しいPro Display XDRが最適です
HDRのすばらしい映像コンテンツを デバイスで表示する方法は? Appleではユニークな手法があります Extended Dynamic Range 略してEDRです ディスプレイの輝度の高さを利用し HDR画像の明暗を表現します 詳しく説明しましょう ディスプレイの輝度設定は 室内や見ている環境で変わります もし薄暗い部屋にいる場合 輝度は200ニットに設定されるでしょう それ以下かも SDR映像を見るのに 適した設定になります UIやSafari YouTubeなどです しかしディスプレイが 1000ニットに対応するなら 非常に高い輝度が利用できます 例えばオフィスなどの明るい場所では 輝度は500ニットなど 高めに設定されます SDRコンテンツに最適な輝度です この状態でもまだ 輝度に余裕があります HDRではこの点を利用します ピクセルのレンダリングでは― SDRのピクセルを 設定輝度にマッピングします そして輝度の余裕部分を HDRに使います
どの割り合いでマッピングするかは 映像を見ている環境の 明るさによります
しかし レンダリングでは ピクセルは 特定の構造でなければいけません それには SDR輝度に比例して HDRピクセルをスケーリングします 先ほどの薄暗い部屋を 例にしてみましょう ディスプレイの輝度に比例して ピクセル値も決まります 輝度をX軸で表示します 正規化したピクセル値はY軸です ここではディスプレイの輝度が 200ニットです
レンダリングモデルでは ピクセル値は通常― SDRの場合は 0~14の間に予約します またディスプレイの 輝度にもマッピング 1というピクセル値は 200ニットに対応します 輝度には もっと余裕がありますよね ですので1~5のピクセル値は HDRコンテンツに利用できます SDRに比例して5Xの倍率で― 輝度が最大限に活用できます これを最大EDRと呼びます
明るい場所など環境が変われば 設定は500ニットへと上がります すると最大EDRは低くなります それでも 0~1のピクセル値は SDR用に割り当てられています でもマッピングが異なります ピクセル値1に対して 先ほどの200ニットではなく 500ニットとなります 今度は輝度の余裕が減ったので HDR用のピクセルレンジも減りました つまり SDRに比例し この2X分しか― HDR用に使えないのです ピクセルの割り当ては HDRピクセルを― SDRレンジに比例させます スケーリングも同様です HDR映像の暗い部分には マイナス値を使います
まとめると EDRは ディスプレイに連動した― レンダリングモデルです 輝度の余裕部分を HDRピクセル用に利用します HDRピクセルのスケーリングは SDRの輝度に比例させます
このモデルの利点は 輝度が調整できるディスプレイなら レンダリングが可能なこと Pro Display XDRなど 更に性能が高ければ 輝度の余裕度が高く より美しいコンテンツが見られます
ここまでがHDRのための レンダリングモデルです ではAPIはどうでしょう アプリケーションでの応用方法は?
macOSとiOSには いくつかの選択肢があります 1つ目はAVFoundationの利用です このAPIはメディア再生Appに最適です トーンマッピングや カラーマネージメントを行います 2つ目は直接 Metalを使うことです Metalは多くのオプションと 柔軟性を提供します CAMetalLayerやEDR APIを使うと HDRレンダリングを 完全に管理できます トーンマッピングや カラーマネージメントも含みます コンテンツ作成に理想的なAPIです スニペットを使い CAMetalLayerなどが どう組み込まれるかを 見てみましょう
何よりもまずベースのコードで EDRサポートが オンになっているのを確認します プロパティが表示されます 通常どおりMetalレイヤを作成します その際 アプリケーションに合う― 広色域を選ぶ必要があります Metalは幅広い色領域を サポートしています BT.2020や P3などです 次にコンテンツに合う 伝達関数を選びます APIはすべての業界標準を サポートしています PQやHLG ガンマ関数などです
HDRレンダリングの ピクセル形式も選びます ほぼすべてのHDRレンダリングには FLOAT16が適しています HDRの色と輝度情報を届ける― 精度が十分にあるからです
最後に EDRレンダリングモデルを 使うと― Metalに指定します 典型的なレイヤが完成しました 次はメインレンダーループです 先ほど話した輝度の余裕部分― つまり最大EDRの情報が必要です NSScreenにプロパティが出ます このプロパティは動的で 見る環境やディスプレイの設定で 数値が変動します 変化があれば通知するよう 設定しておきましょう 最大EDRが変化したら コンテンツの更新が必要です
トーンやカラーを 自分自身で設定する場合 シェーダーで ピクセルの追加処理が必要です 一般的な手順をお見せします
通常 ビデオはYUVや YCbCrフォーマットです 最初の手順は ビデオをRGBに変換することです そしてビデオは非線形の 伝達関数がエンコードされています PQなどです 次に行うことは 逆伝達関数の適用と ピクセルの直線化です そして0~1の間に正規化します
NSScreenから得た 最大EDRを使い― ピクセルをスケーリングします
そしてアプリケーション向けの 編集やグレーディングなどを行い トーンマッピング処理を行います 輝度が変更すれば 再度 トーンマッピングを行います コンテンツの色域が ディスプレイと異なる場合も 適当なカラー変換を行う必要があります トーンマッピングや遠隔処理を 行いたくない場合 Metalに頼ることができます Metalレイヤを作成したら EDRメタデータオブジェクトを 加えます マスタリング表示の情報を 提供し― マッピング方法を Metalへ指示します またMetalのリニア色空間も 使います
すべてのピクセル処理が完了したら フレームは準備完了 Metal APIを使い フレームをスクリーンへ映し出します
先ほども言ったとおり Pro Display XDRなどの 適応性のあるディスプレイが必要です HDR10やドルビービジョンにも 対応しています ここまでは HDRのレンダリングにおける― MetalレイヤやEDR APIの 活用方法でした セクションの最後に 重要な点とベストプラクティスを お伝えします
輝度の変化に合わせて コンテンツを更新すること HDRレンダリングには FLOAT16が最適です
Metalレイヤでは コンテンツに合った 色空間や伝達関数を選ぶこと シェーダーの追加処理も 行ってください 最後にもう1つ HDR処理は オーバーヘッドやメモリに 大きく負担が掛かります 不要なトーンマッピングはしないこと 重視したいのが 色の精度より― パフォーマンスの場合です 強固なAPIをご紹介しました iOSとmacOSの両方に対応の EDRレンダリングモデルや Pro Display XDRのサポートもです これらを駆使し すばらしい HDRコンテンツを作りましょう
次のトピックは プラットフォーム上の― 計算資源を利用して パフォーマンスを最適化する方法です ブライアンにお願いします (拍手)
ディリープ ありがとう CPUとGPUの並行性を利用するのは 重要で 時に最も容易な 最適化の手段です
ここでは パフォーマンスの スケーリングついて説明します まず いくつのCPUコアでも Metalが対応可能であること 次は 非同期GPUチャネルの 活用方法について セクションの最後には 複数のGPUを使う方法を説明します
Propsは複雑化しています デコーディングや RenderGraphなどに― CPUサイクルを要します 1つのCPUだけでは 足りなくなっています 最新のiPhoneにはコアが6つ Mac Proは28もあります 拡張可能なマルチスレッド アーキテクチャは デバイスの動作には必須です Metalはマルチスレッド対応です ここでは2つの方法から エンコーディングの並列化を説明します
例として一般的な ビデオフレームを用意しました シングルスレッドのレンダリングでは フレームを連続的にデコードし 実行順に1つの コマンドバッファとします この少ないフレームタイムに すべてを入れます すると 待ち時間が発生 すべてのコマンドバッファを エンコードするからです もっと良い方法があります CPUで並列性を作ります
Metalのマルチスレッディングは render blitやcompute passで 構成されます 必要な手順は 複数のコマンドバッファを作り 異なるスレッドで エンコーディングを行います どの順でも構いません 実行の順序は コマンドキューに 追加した順番です 次はコードで説明します
実は意外とシンプルです まずコマンドバッファのオブジェクトを いくつか作成します
次にenqueueを使って GPUの実行順序を決定 エンコーディング完了前に 指定できて便利です
そして 非同期の Dispatchキューを使い 別のスレッドを作ります エンコードして完了です 早くてシンプルです
例では いい感じです 複数のコマンドが並列化しました 1つのエフェクトと ブレンディングパスが大きい場合は? その場合 Metalの 並行エンコーダを利用 レンダリングのパスや コマンドバッファを分割せずに マルチスレッディングで エンコード可能です アプリケーションへの応用方法です
まずコマンドバッファから 並列のエンコーダを作成 必要な数の下位コーダもです この下位コーダの作成順に GPUの実行順が決まります 次は別々のスレッドを作り エンコード関数を呼びます エフェクトとブレンディングが 処理されます 最後にスレッド完了の通知を設定 エンコーディングの並列化を終了 シンプルで効率的です CPUの並列化の2つの方法を 説明しました 次は 非同期のGPUチャネルの 活用法です
現代のGPUは共通の機能があります それぞれに非同期に実行できる― チャネルが含まれています 1つでデコーディングをして 別でエフェクト処理という風にです Metalは 並列処理を 2つの方法で行います 1つ目は処理に合わせて レンダーやblit― encodersを使うことです 2つ目はデータの依存状態を 分析することです これらの大半は無料で提供されています デベロッパの助けになります では具体例を
GPUが実行するフレームを見てください こちらもビデオフレームの例です Video Toolboxでデコードを行い Blitエンコーダを使い VRAMへアップロードします Computeにfilteringを レンダーにeffectsとblendingを適用
各フレームで反復的に 繰り返されます こうしてタイムライン図では CPUもGPUも実行されています 更に同時性の最適化も図りましょう
まず最初は 別々のスレッドで 1フレーム目のコマンドを処理します スケジュール化され 全チャネルで実行されます 2つ目以降のフレームも 同様に処理します
Metalのおかげで 並行処理ができています しかしギャップも多いです 遊休状態のスレッドが あるという意味です 無駄があっては 効率性が下がります Metalだけに頼らず 最適化が必要です CPUには大きなギャップが見られます 理由は多くありますが 一般的な失敗を取り上げます アプリケーションは エンコード後などに― 根拠もなく止まります 例では デコーディング処理に 大きなギャップが生じています GPUにも小さなギャップが見られます これを直すには CompletionHandlerで比重を変えます CPUのブロックを防ぎ GPU完了後の 事後処理を予定します 試してみましょう
改善しました CPUスレッドが連続的で デコーディングも 詰まっていますね しかし BlitとCompute Renderには― まだギャップがあります よく見ると 依存性があり デコードが終わらないと アップロードが始まりません そこで 10フレーム先で デコードさせると 依存性が解消されます 試します
改善しましたね VideoやBlitのチャネルもです ComputeとRenderは まだ気になります また 依存性があるようです Blitのアップロードが完了するまで Filter処理が始められません 前回同様 ビットマップを先に取り込めば 依存性が解消できます
大半のギャップが消え 効率的なパイプラインになりました GPUチャネルと その最適化についてでした 更にGPUパフォーマンスを スケーリングするには どうすればよいでしょう
GPUはパフォーマンスの 助長もします GPUを増やせば 映像処理や編集が速まり フレームレートも改善します
では Metalを利用して マルチGPU構成を活用する方法です Pro Appデベロッパが実証済みの ロードバランシングも説明します GPU処理の同期化についても お話しします
Pro AppにとってMetalは 必要なツールを与えてくれます GPUをつなぎ 能力を向上させます GPU管理が簡単です それぞれがMetalの デバイスオブジェクトだからです 1つのGPUと扱いは同じです Metalは 新しく Peer Group APIをサポート Remote Texture Viewに対応し GPU間でデータをコピーできます 更に 強力な共有イベントもあり GPU間で作業を同期できます では マルチGPU構成の検出方法です
Metalは デバイスのプロパティに ロケーションや 最大転送速度などを表示します この情報は最短処理速度の 算出などに使われます デバイスの独立性や 低出力なのか― ヘッドレスなのかなどが 分かります 複数のGPUで情報を得られるなら 作業量のバランス化が必要になります
GPU間の負荷平衡の方法は 多くあります 選択する戦略によって デザインも分かれます 一番 選びたいのは スケーリングできる シンプルで高効率な方法です Pro Appデベロッパが使う 実績のある手段を紹介します
最も容易なのは 交互のフレーム対応です 2つのGPU間で 奇数と偶数を行き来します 既存の構成に適用できれば フレーム処理速度が 倍にもなります しかしアプリケーションには 変化しやすい作業負荷も多いです それらは負荷の分配が うまくいきません 別の方法も見てみましょう
縦横32ピクセルのタイルです レンダリングの分配が均一です 4つのGPUに― タイル群を事前に割り当てます ランダム化することも可能です これで タイルのマッピングが 一定となります 重たい計算処理には効果的ですが 帯域幅の広い 複雑な処理には向きません 詳細はRate Tracingセクションを
これはタイルキューを使った方法です ホストアプリケーションが タイルを各キューに 割り当てます アルゴリズムに基づきGPUが要求を出し キューから取り出します 負荷平衡は実現しますが 複雑さが追加されます 負荷平衡のスキームを決めたら GPU間の同期化も必要となります
これにはMTLSharedEventが有効です これで アプリケーションの 同期ポイントを指摘できます コマンド完了のポイントです 全GPUだけでなく CPUとGPU間や プロセス間でも実行可能 実践してみましょう
これは1つのGPUの 2フレームで Motion Analysisをする例です Renderなので 非同期の並列チャネルは ここでは使えません しかしGPUが2つあれば 作業を2つに分け 性能を向上させられます Motion Analysisを 2つ目のGPUに移します 各Motionのパスは― その前のフレームの分析が必須です Motionパスからフレームを読み込み それをフレームごとに 繰り返します
MTLSharedEventを使ってみましょう まずレンダリング完了の通知を その後 Motionパスで フレームを読み込みます
これによりMotion Analysisは 2つ目のGPUへ移り 動きも並行しています 通知はGPUにエンコードされるので CPUの実行をブロックしません コードで説明します
まずはレンダリングするデバイスから SharedEventを作成します 各デバイスに コマンドキューも作ります レンダリングにはコマンドバッファと エンコードがいります その後GPUに終了を通知する シグナルイベントをエンコードします Motionをエンコードします
キューからコマンドバッファを 作成します 混乱を避けるため 待機イベントを入力します Motion Analysisと commitを入力 とてもシンプルな作業で パワフルです 複数のGPUとチャネルが どう働くか見てみましょう
System Traceは 各GPUの作業を表示しています この例では 内部GPU1つ 外部が3つの全4つです
詳細が見て取れます 全チャネル分の 非同期の作業が GPUごとに分かります 作業には関連性のある 名前が付いています
Activity Summaryを見ると 接続中のGPUの 実行データがあります もっと細かいチャネルの情報として フレームごとに見ることも可能です それにはBlitの Page OnやOffの情報や― Computeや Renderワークロードを含みます IOSurfaceへのアクセスの詳細も Pro Appがよく使いますので この情報は大変有用です フレームワークの 相互運用にも必要です
また イベント情報も取得できます 通知と待機がどこかが分かります 待機したミリ秒数や― 依存ラインも表示します 一番下には イベント詳細の リストもあります Metal System Traceは Pro Appにとって便利です マルチGPUの活用法の次は データの転送方法を 見てみましょう
パフォーマンスのスケーリングは 大変重要ですが 妨げがあれば Pro Appの性能も下がります 8Kフレームを移動させているので それが妨げになりかねません
ここでは帯域幅の注意点と 新Mac Proについて話します Peer Groupの転送方法も 説明します すでにPro Appで活用されています 最後は 実用例を用いて Infinity Fabric Linkの 利用法も説明します
まずは 主な接続ポイントの 転送速度からです 基準はPCIe Gen3 x16です まずは Thunderbolt 3 実際の最大値はPCIeの4分の1です 重たい作業に対して 拡張可能なソリューションですが 帯域消費型のものには不向きです 次は異なるPCIレーンのGPUが2つ 帯域幅を倍にできます 今週発表した 新しいInfinity Fabric Linkは PCIeの5倍の速度で GPU間の転送が可能です
一般的なMac Pro構成です この図は帯域消費型の 作業を表しています 新Apple Afterburnerと 2つの内部GPUは いずれも専用のPCIレーンを持ちます Infinity Fabric Linkで GPU間を接続し― 迅速にデータがコピー可能です
Mac Proは 2組のPCIレーンを共有する― 内部GPUを4つ持てます レーンは共有なので 処理集中型向きでしょう Infinity Fabric Linkでの 接続も可能です
多くの転送方法があります Pro Appデベロッパが 活用中のものを紹介します
最もシンプルなのは 全フレームを転送する方法 交互のフレーム処理が前提です 補助装置で処理されたフレームは ディスプレイGPUに転送され ディスプレイへ送られます
次はタイルをGPUに送る方法です フレーム全体の一部分を転送する形です 補助装置で処理したタイルは ディスプレイGPUへ転送され― 出力する映像に再構築されます 負荷バランスの良い例です 2つの方法を確認しました 次はInfinity Fabric Linkを使った Pro Appでの作業を紹介します
この半年間 Final Cut Proのチームと 一緒に働いてきました 結果 最大28コアのCPUと 内部GPUを有する新Mac Pro用に Final Cut Proを最適化しました すべて内部GPUです Infinity Fabric Linkも 活用されます 8K ProResマルチストリームの― リアルタイム編集が可能です 詳しく見てみましょう シンプルなタイムラインです ビデオストリームがCPUから ディスプレイへ転送されます エフェクトを含む― 3つのProRes ビデオストリームを見ましょう 単体のGPUの場合です
まず フレーム1の コマンドをエンコードし ストリーム3つを PCI経由でVRAMにアップロード
そして エフェクト処理をして 表示します
フレームごとの処理が続きます 1秒30フレームなので その中にすべて収まりません 最低3割は フレームが落ちるでしょう Dual GPUでも見てみましょう またフレーム1をエンコードします フレーム2も同じ作業です 並行して作業が進んでいますが フレームレートは倍でしょうか 残念ながら違います
問題は 補助装置で処理したフレームが― ディスプレイのデバイスに コピーされることです
ディスプレイGPUの取得には 265メガバイトの出力バッファを ホストにコピーします 次にディスプレイGPUに 再度コピーです 速くても48ミリ秒を要します フレーム3と4も同様に処理しましょう
かなりのPCI帯域幅を 使用していますが ギャップや依存も多くあります やはり フレームレートも 倍にはなりません PCIの通信で コマ落ちが発生するでしょう
この問題の解決に Peer Group APIを含む Infinity Fabric Linkを導入 GPUコピーが不要になります
すると転送が かなり速くなりましたね PCIの帯域幅が解放され
フレームのアップロードも 早まります
並列のGPUチャネルでも 動作するので Renderチャネルなどと同時に データ転送できます 並行性と待ち時間が改善されます Pro Appで活用すれば 新しい発想も生まれるでしょう タイムライン図に加えて 実際の映像を見てみましょう
Keynoteで紹介した Final Cut Proのデモです 8Kのマルチストリームの再生で エフェクトやトランジションも 含みます リアルタイムでの実現は Infinity Fabric Linkと マルチGPUの力です Final Cut Proは 高効率な転送を利用した― Pro Appの事例です セクションの最後に Infinity Fabric Linkと Peer Group APIの 活用方法を見てみましょう
最初に必要なことは 関係性を見つけることです そこでMetalは 新Peer Group APIや― IDインデックスやカウント値を 定義付けます これで 接続したGPUや そのPCIレーン情報が検知できます 重要なのは 帯域幅を基に 最適な構成と 性能のスケーリングが決定できること
これがGPU間の転送方法です まずは補助装置から sharedEventを作成します renderTextureと remoteTextureViewも作成 このremoteTextureViewで GPUが補助装置に― アクセスできます
次はエンコーダの作成とレンダリング 次にシグナルイベントの エンコードが続きます 続いてblitCommandBufferを作成し 待機イベントをエンコード レンダリング完了を待ちます
最後にTextureViewでコピーします シンプルです
Peer Group APIで Infinity Fabric Linkを活用し PCIの帯域幅消費を減らせます 並列チャネルで 並行性も強化できます セッションの最後に Pro Appの実用例をもう1つ Affinity Photoのデモです Metalが見事に導入されています また プラットフォームリソースを 的確に利用しています 一般的なドキュメントですと 単一のGPUでも10倍の性能です 8コアCPUとの比較です ご覧ください これは Rabbit Trickという― 巨大なドキュメントの ライブコンポジションです 何百ものレイヤが存在します 4Kの解像度で合成します レイヤにはピクセルや 調整の情報が含まれ― リアルタイムで コンポジションされます CPUとGPUへの負荷も膨大です
CPUで動かしてみましょう 18コアシステムです ライブコンポジションは できています しかし あまりに複雑なので UI上は少しぎこちないです
今度は単一のGPUで実行 UIの反応が良くなりました スムーズに動きます フレームレートは1秒18~20です
次がお楽しみです 4つの外部GPUを使います 非常にスムーズで― 1秒60フレーム以上を維持します Affinity Photoのタイルベースの 負荷分散のおかげです いくつのGPUでも分散が可能で パフォーマンスも リニアな拡張になります
これが最後の例です 被写界深度という― メモリ消費型のフィルタ処理です CPUでのリアルタイムプレビューです エフェクト適用からレンダリングへの 瞬間が見えます 十分すばらしいですが GPUの方が上です
今度は外部GPU4つを使います とてもスムーズになり フレームレートも1秒60フレーム以上 メモリ消費型のフィルタですが すばらしい改善です 最新のGPUでは膨大なメモリが 使用可能だからです このように マルチGPUで パフォーマンスが スケーリング可能なのです
セッションを終える前に まとめましょう AppleはPro Appに必要な フレームワークを豊富に提供 このエコシステムを使えば 8Kコンテンツの リアルタイム編集が可能 予測可能なフレームレートで対応します
AV Foundationや Core Animation Metal Layerは Dynamic rangeに対応するAPIを提供 HDR TVや 新しいPro Display XDRを使えば 美しい映像や画像を 映し出せます
Mac Proは 最大28コアCPUで 内部GPUが4つ MetalはAPIであらゆるデバイスに対応 そして Peer Group APIを含む― Infinity Fabric Linkもご紹介 これを利用した接続で 新たな活用事例が生まれるでしょう 詳しい情報は Webサイトへどうぞ ラボにもぜひ参加してください Metal専用のラボもあります ありがとう (拍手)
-