-
Create ML Componentsで高度なモデルを作成する
Create ML Componentsで、カスタム機械学習モデルを次のレベルに引き上げます。動画やオーディオなどの時間データの操作方法をはじめ、人の反復動作をカウントしたり、高度な音声分類を提供するモデルの作成方法を紹介します。また、インクリメンタルな調整で、新しいデータを使用したモデルトレーニングを迅速化するベストプラクティスも紹介します。 カスタム機械学習モデルの導入については、WWDC22の「Create ML Componentsについて学ぶ」をご覧ください。
リソース
関連ビデオ
WWDC23
WWDC22
WWDC21
WWDC20
WWDC19
-
このビデオを検索
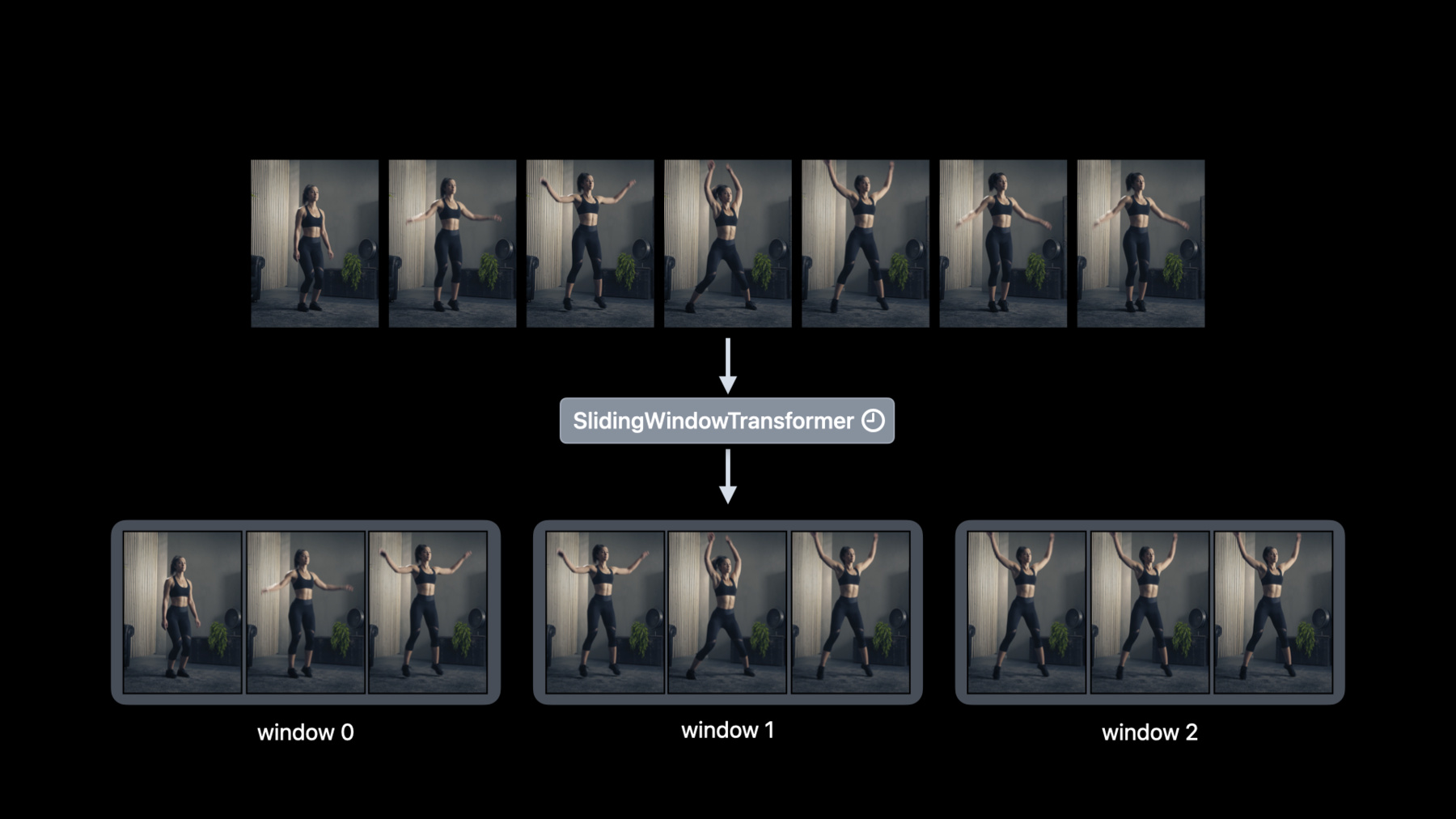
♪音楽♪ ♪ こんにちはCreateMLチームの エンジニアDavid Findlayです このセッションでは 独自の機械学習タスクを構築する MLコンポーネントを作成します 同僚のAlejandroが 「Create ML Componentsについて学ぶ」で MLコンポーネントについて紹介しました Create MLタスクを コンポーネントに分解する方法と いかに簡単にカスタムモデルが作成できるかを 紹介しました トランスフォーマーとエスティメータは 画像回帰などのカスタムモデルを 構築するために 構成できる重要な要素です このセッションでは基本レベル以上の Create MLコンポーネントで できることを紹介します アジェンダを見てみましょう まずビデオデータの説明をし 時間の経過で値を処理する 新たなコンポーネントに関して説明します 次にこれらの概念を機能させて トランスフォーマーだけを使って 人の繰り返し動作のカウンターを設定します 最後にカスタムサウンド分類モデルの トレーニングに移ります モデルをバッチで更新し トレーニングを早期に停止し モデルをチェックポイントできる インクリメンタルフィッティングについて 説明します この柔軟性には多くの機会があります たくさんのコンテンツがあり待ちきれませんね それでは見てみましょう WWDC2020ではCreate MLに アクション分類を導入しました これによりビデオから アクション分類が可能です またスクワットなどトレーニングルーチンを 認識するためのフィットネス分類器を 作成する方法を示しました 例えばアクション分類器を使って このビデオのアクションを ジャンピングジャックとして 認識しますが回数を 数えたい場合はどうでしょう 最初に考えるべきなのは ジャンピングジャックが 連続するフレームにまたがり 時間の経過とともに 値を処理する方法が必要です SwiftのAsyncSequenceはこの場合 非常に役立ちます AsyncSequenceに慣れていない場合は ご覧のセッションをご確認ください Create MLコンポーネントは ビデオリーダーを使ってフレームの非同期 シーケンスとして ビデオを読み取れます 例えばmapメソッドで各ビデオのフレームを 非同期で簡単に変換することができます これはフレームを一度に処理する時に便利です しかし一度に複数のフレームを 処理する場合はどうでしょうか 一時的なトランスフォーマーがここで活躍します 例えばフレームをダウンサンプリングし ビデオのアクションを 高速化することが可能です AsyncSequenceを取得しダウン サンプリングされたAsyncSequenceを返す ダウンサンプラーを使うことができます またはフレームをウィンドウにグループ化 することもできますこれはアクションの 繰り返しをカウントするのに重要です ウィンドウにグループ化する フレームの数のウィンドウの 長さとスライド間隔を制御するストライドを 指定することが可能です ここでも入力はAsyncSequenceです 出力はウィンドウ化された AsyncSequenceです 一般的に一時的なトランスフォーマーは AsyncSequenceを新しいAsyncSequenceに 処理する方法を提供します それではこれらの概念を機能させましょう 例えば私は運動するときに いつもカウントするのを忘れてしまいます 少し振り返ってCreateML Componentsを使いアクション繰り返し カウンターを作成するとします この例ではトランスフォーマーと 一時的なトランスフォーマーを一緒に構成する 方法を説明します 人体ポーズエクストラクタを 使ってポーズを抽出できます 入力は画像で 出力は人体のポーズの配列です 舞台裏ではVisionフレームワークを 使ってポーズを抽出します 画像には複数の人が含まれる 場合があるので注意します これはグループワークアウトでは一般的です そのため出力はポーズの配列になります しかしここでは一度に1人のアクションを 繰り返して数えることにフォーカスします そこでポーズセレクターで 人体ポーズエクストラクター を作成します ポーズセレクターは一連のポーズと 選択戦略を取り単一のポーズを返します 戦略はいくつかありますが 今回はご覧の戦略を 使ってみようと思います 次はポーズをウィンドウにグループ化します スライディングウィンドウ トランスを追加してみます そしてウィンドウの長さとストライドを 90として使用し90のポーズの重なり合わない ウィンドウが生成されます スライディングウィンドウ トランスフォーマーは 一時的なものであるため タスク全体が一時的なものになり 予想される入力はフレームの AsyncSequenceになります 最後は人のアクションカウンターです この一時的トランスフォーマーは ウィンドウ化された非同期の シーケンスポーズを消費し これまでのアクションの 繰り返し累積カウントを返します ここまででカウントが 浮動小数点数であることに 気付いたひともいるのではないでしょうか これはタスクが部分的なアクションも カウントするためです 簡単ですね これでワークアウトビデオで動作を数え 不正行為をしていないと確認できます ただし現在のワークアウトを追跡できるよう App内でライブで繰り返し カウントしたほうが良いです その方法をご紹介します まずカメラ構成を取得し カメラフレームのAsyncSequenceを返す readCameraメソッドを利用します 次にストライドパラメータを 15フレームに調整して 更新されたカウントを頻繁に取得します カメラが毎秒30フレームの 速度でフレームをキャプチャすると 0.5秒ごとにカウントが取得されます これで運動するときも心配ありません これまでAsyncSequenceを変換するための テンポラルコンポーネントについて 説明しました 次に時間データに依存するカスタムモデルの トレーニングに焦点を当てたいと思います 2019年はCreateMLで サウンド分類器のトレーニング方法 2021年はサウンド分類の 機能強化を導入しました ではカスタムサウンド分類器を トレーニングしてみましょう Create MLフレームワークの MLSoundClassifierは カスタムサウンド分類モデルを トレーニングする簡単な方法です ただしカスタマイズ性と制御が必要なら 内部でコンポーネントを使えます 最も単純な形式ではサウンド分類器には Audio Feature Print抽出機能と 分類器の1つの要素があります AudioFeaturePrintはオーディオバッファの AsyncSequenceから特徴を抽出する 一時的なトランスフォーマーです スライディングウィンドウ トランスフォーマーと 同じでAudio Feature Printウィンドウの 非同期シーケンスが特徴抽出を行います 選択できる分類器はいくつかありますが この例ではロジスティック回帰分類器を使って それを特徴抽出器と組み合わせて カスタムサウンド分類器を作ります 次のステップはカスタムサウンド分類器を ラベル付きのトレーニングデータに 対応させます トレーニングデータの収集については 「Create ML Componentsについて学ぶ」 のセッションから始めることをお勧めします とりあえず今までうまくやって来れました しかし機械学習モデルの構築は 反復的なプロセスになる可能性があります 例えば新しいトレーニングデータを 見つけて収集して モデルの品質を向上させる場合です ただしモデルをはじめから 再トレーニングするには 以前のすべてのデータに対して 特徴抽出をやり直す必要があるので 時間がかかります 新たに発見されたデータを使って モデルをトレーニングする際の 時間の節約方法を示します 重要なのはモデルのフィッティングとは別に トレーニングデータを前処理することです この例では分類器のフィッティングとは別に オーディオの特徴を 抽出することができます これも一般的に機能します トランスフォーマーの後に エスティメータが続くようであれば エスティメータに至る トランスフォーマーを介して 名前の入力を行うことができます 前処理メソッドを呼び出してから 前処理されに特徴に モデルを適合させるだけです サウンドクラシファイアの構成を変更せずに 済むようになったので便利だと思います 特徴を個別に抽出したので 新しいデータのオーディオ特徴だけを 抽出する柔軟性があります モデルの新しいトレーニングデータだけを 別途短時間で前処理できます 次に以前に抽出した特徴に 補足の特徴を追加します これは前処理によって時間を節約できる 最初の例にすぎません モデル構築サイクルにもどります モデルの品質に満足するまで エスティメータのパラメータを 調整する必要があることがあります 特徴の抽出をフィッティングから分離して 抽出は一度だけ行い 様々なエスティメータの パラメーターでフィッティングできます 例を見てみましょう 特徴抽出をやり直さずに 分類器パラメーターを変更してみましょう すでに特徴を抽出していると仮定し 分類器のL2ペナルティ パラメータの変更をします 次に新しい分類器を古い特徴抽出機能に 追加してみましょう エスティメータを調整する際に 特徴抽出器を変更しないことが重要です 変更すると無効になります モデルをバッチで段階的に 適合させてみましょう 機械学習モデルは一般に 大量のトレーニングデータから利益を受けます しかしAppの使えるメモリは限られています どうすればよいのでしょうか Create ML コンポーネントから 一度にデータのバッチだけを メモリにロードして モデルをトレーニングできます まずは分類器を アップデートしたものと変えます バッチを使ってカスタムモデルを トレーニングするには 分類器を更新できるようにします たとえば全結合のニュートラル ネットワーク分類器が 更新不可のロジスティック 回帰分類器の代わりに 簡単に使えます
ではトレーニングループを作成します デフォルトの初期化モデルを 作成することから始めます トレーニングは始まったばかりなので まだ予測を行うことはできません 次にトレーニングをはじめる前に オーディオの特徴を抽出します 繰返ごとに特徴を抽出したくないので これは重要なステップです 次のステップはトレーニングループを定義し トレーニングしたい 反復回数を指定します アルゴリズムのSwiftパッケージを インポートします トレーニングデータの バッチを作るために必要です 詳細はWWDC2021の 「Swift Algorithmsパッケージと Swift Collectionsパッケージについて」 のセッションをご確認下さい
トレーニングループ内では バッチ処理が行われます チャンクメソッドを使ってトレーニング用に 特徴をバッチにグループ化します チャンクサイズは一度にメモリにロードされる フィーチャの数です 次にバッチを処理して更新メソッドを 呼び出してモデルを更新できます
モデルを段階的にトレーニングすると トレーニングテクニックを いくつかアンロックできます 例えば このトレーニンググラフでは 約10回の繰り返しの後 モデルの精度は95%で横ばいになっています この時点でモデルは収束しており 早めに停止することができます トレーニングループの 早期停止を実装しましょう まず必要なのは 検証セットの予測をすることです 検証予測とその注釈を 組み合わせる必要があるので ここではmapFeaturesメソッドを 使っています 次のステップはモデルの 品質を測定することです ここではビルトインのメトリックを使いますが 独自のカスタムメトリックの 実装を妨げるものはありません そして最後にモデルの精度が95%になったら トレーニングを停止します トレーニングループ以外でモデルを使って 予測できるようにモデルをディスクに書き 込みます早期停止に加えて モデルのチェックポイント についてお話しします
最後ではなくトレーニング中に モデルの進行状況を保存します またチェックポイントを使って トレーニングを再開できます モデルのトレーニングに 時間がかかる場合に便利です トレーニングループでモデルを 書き出すだけですチェックポイント間隔を 定義することにより処理すればよいです とても簡単です 今回はオーディオや ビデオなどの時間データを使って 機械学習タスクを構築する新たな方法である テンポラルコンポーネントを紹介しました 人間の行動の繰り返しカウンターを作るために 時間的要素を一緒に構成しました そして最後に インクリメンタルフィッティング これによって機械学習をAppに組み込むための 新しい可能性が解き放たれます ご参加いただきありがとうございました
-