-
Core MLの使用を最適化する
Core MLが、CPU、GPU、ニューラルエンジンと連携して、オンデバイスでプライバシーを保護する機械学習エクスペリエンスをAppに促す仕組みについて解説します。さらに、最新ツールについても解説するので、ご利用のモデルのパフォーマンスを把握し、最大限に活用することができるようになります。また、ご利用のモデルのパフォーマンス特性を簡単に把握できるレポートの生成方法も紹介するので、Core ML Instrumentでご利用のモデルに対するインサイトも得られるようになります。さらに、APIを強化して、AppとのCore ML統合を最適化しますのでご覧ください。 このセッションを最大限に活用するには、WWDC21の「Core MLモデルのチューニング」をご覧ください。
リソース
関連ビデオ
WWDC23
WWDC22
-
このビデオを検索
♪音楽♪ ♪ こんにちは、Benです Core MLチームでエンジニアを務めています 今日はみなさんにCore MLに追加された 新しい機能を紹介します ここではCore MLを使用する際の 最適化方法について焦点を当てます このセッションではCore MLを使用する際に モデルのパフォーマンスを 理解し最適化するために 必要な情報を提供する パフォーマンスツールについて説明します 次にこれらの最適化を可能にする いくつかの拡張APIについて説明します 最後に追加のCore MLのケーパビリティと 統合オプションについての 概要をお話しします パフォーマンスツールに ついてから始めましょう まずは背景を説明するために App上でCore MLを使う際の 標準ワークフローについてお話しします 最初のステップはモデルの選択です 様々な方法がありますが CoreMLツールを使って PyTorchやTensorFlowモデルを CoreML形式に変換したり 既存のCoreMLモデルを使ったり CreateMLを使ってモデルトの レーニングとエクスポートも可能です モデルやMLの作成については これらのセッションを おすすめします 次のステップはモデルのAppへの統合方法です モデルをAppにバンドルし Core ML APIを使ってApp実行中に 該当モデルでの推論のロード・実行を行います 最後のステップはCore MLの最適化です 始めにモデルの選び方を説明します Appに使うモデルを選ぶ際には たくさんの要素を 考慮する必要があります そこにはいくつかの選択肢があると思いますが どのようにして 選べばよいのでしょうか? 要件や使いたい機能にあわせた モデルを選ぶ必要があります ここにはモデルの正確性や パフォーマンスへの理解が含まれます Core MLモデルを理解する一番良い方法は Xcodeで開いてみることです どのモデルもダブルクリックで 開いて見てみることができます 一番上を見るとモデルのタイプや サイズ OS要件が確認できます Generalタブではモデルのメタデータに キャプチャされた追加の詳細 その計算と保存の精度 予測可能なクラスラベルなどの 情報が表示されます Previewタブは例を入力して モデルが何を予測するかを確認して モデルをテストします Predictionsタブは モデルが実行時に期待する インプット アウトプットの タイプとサイズを表示します そして最後にUtilitiesタブは モデルの暗号化と配信をサポートします ここまでがモデルの機能と正確性に関する 概要の説明です モデルのパフォーマンスはどうでしょうか モデルのロードコスト単一の予測にかかる時間 モデルが使用するハードウェアは ユースケースにとって 重要な要素になる場合があります リアルタイムのストリーミングデータで 制約に関する厳格な目標がある場合や 想定される待ち時間に応じて ユーザーインターフェイスに 関連する重要な設計上の 決定を行う場合があります モデルのパフォーマンスを洞察する 1つの方法は Appに最初に統合するか計測して測定できる 小さなプロトタイプを作ることです そしてパフォーマンスは ハードウェアに依存するため サポートされたハードウェア上で様々な対策を 取ろうとするでしょう Xcode とCore MLはこのタスクを コードを1行も書かずとも助けてくれます Core MLはパフォーマンスレポートの 作成をサポートします 実際に見てみましょう
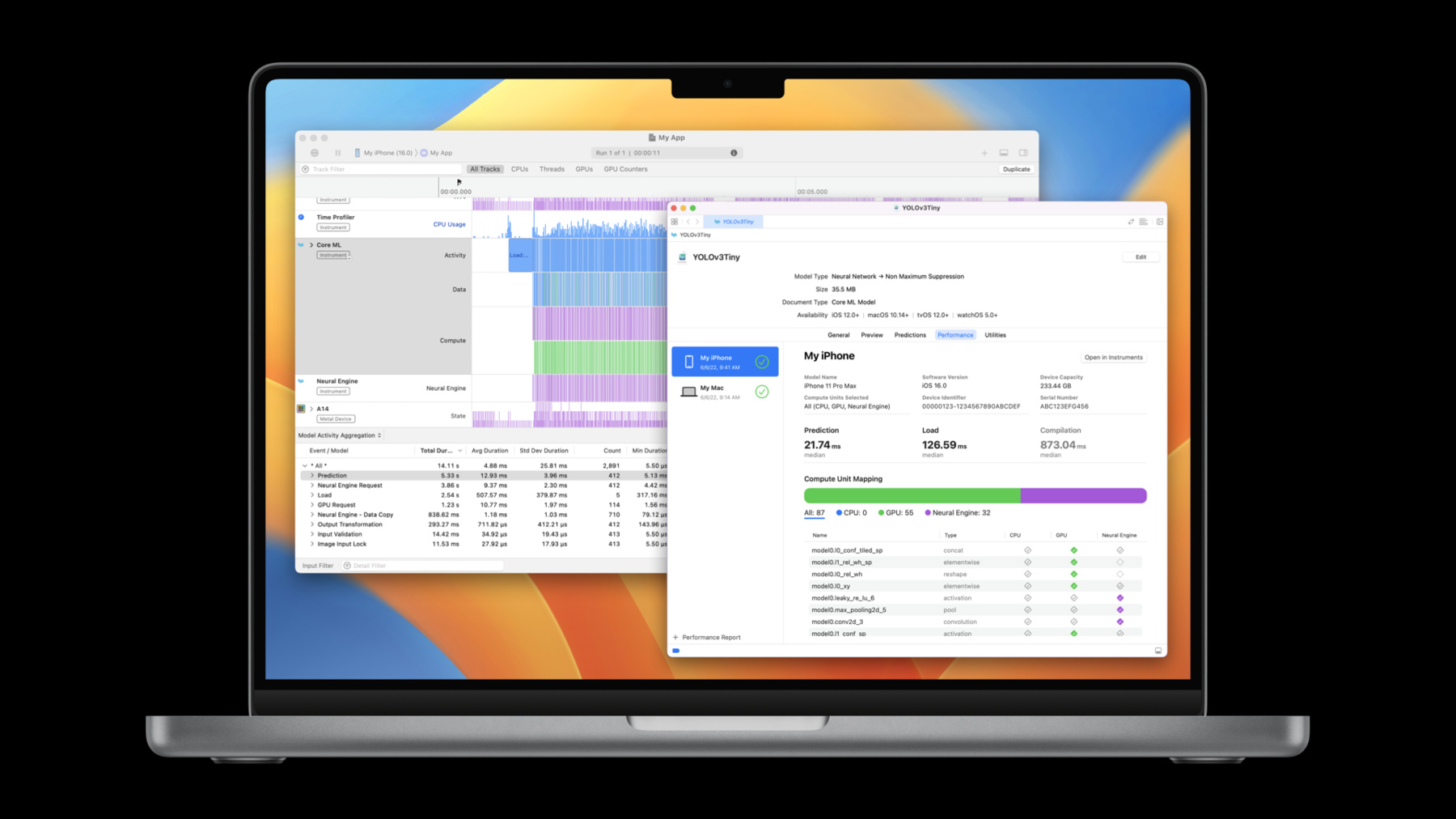
「クリック」 今 Xcodeモデルビューワーで YOLOv3オブジェクト検出モデルを開きました PredictionsタブとUtilitiesタブの間に Performanceタブがあります パフォーマンスレポートを生成するには 画面下部のプラスアイコンをクリックし 実行するiPhoneを 選択してクリックしCore MLを使いたい ユニットを選びます Core MLで使用可能な演算ユニットで レイテンシを最適化できるように Allのままにしておきます ここでテスト実行を選びます 選んだデバイスをアンロックして テストを実行します パフォーマンスレポート作成時中は スピンアイコンが表示されます レポートを作成するために モデルがでデバイスに送信され コンパイルの実行が 数回繰り返されます これが完了したら パフォーマンスレポートの メトリックが計算されます これでiPhoneでモデルが実行され パフォーマンスレポートが表示されます ページ上部では テストが実行されるデバイスや選択された 演算ユニットが表示されます 今 実行の統計が表示されています 予測時間の中央値は22.19ミリ秒で ロード時間の中央値は約400ミリ秒でした また デバイス上でモデルを コンパイルするのなら その時間が約940ミリ秒 あったことを示しています 約22ミリ秒の予測時間は このモデルをリアルタイムで 実行したい場合にこのモデルが1秒あたり 約45フレームをサポート 可能なことを示しています
このモデルにはニューラルネットワークが 含まれており パフォーマンスレポートの下部に レイヤービューが表示されます これはすべてのレイヤーの名前とタイプ 各レイヤーが実行された 演算ユニットを示します チェックマーク入っている演算ユニット上で レイヤーが実行されています チェックマークが入っていなければ レイヤーは演算ユニット上で実行可能ですが Core MLはそのユニットでの実行を 選択しなかった事を示します 空のダイヤモンドはそのレイヤーが その演算ユニット上でサポートされて いないということです この場合54層がGPUで実行され 32層がニューラルエンジンで実行されました クリックしてコンピュータユニットごとに レイヤーをフィルターすることも可能です
これがXcode 14を使った Core MLモデルのレポート作成方法です iPhone上での実行をお見せしましたが 複数のOSやハードウェアと組み合わせて コードを一行も書くことなく 実行することができます モデルを選択できたので 今度はAppにこのモデルを統合してみましょう これにはモデルをAppにバンドルし Core ML APIを使ってモデルをロードし それを使いながら予測を行うことが含まれます この場合Core MLの スタイルトランスファモデルを使って ライブカメラセッションから フレームでスタイルトランスファを 実行するAppをつくりました 問題なく動いていますがフレーム比率が 想定より遅いので理由を考えます これが Core ML使用の最適化である ステップ3です パフォーマンスレポートは パフォーマンスモデルが スタンドアローン環境で 動作するかを検証しますが 実際のAppで実行できるかを 検証しなければなりません ここでXcode14のInstruments にあるCoreMLを使います これはAppでの動作中のパフォーマンスや 潜在的にどんな問題があるかを 可視化してくれます 使い方を見てみましょう 移行App Workspaceの Xcodeを見ています これでAppをプロファイル準備完了です 実行ボタンをクリックして プロファイルを選択します
これで最新バージョンのコードがデバイスに インストールされターゲットのデバイスと Appを選択状態で機能が開きます Core ML使用量をプロファイルしたいので Core MLテンプレートをひらきます ここにはCore ML Instrumentと CoreMLの使用状況をプロファイリングするのに 役立つ他のいくつかの便利な機器もあります トレースするにはレコードを押します
AppはiPhone上で動いています 数秒実行してみて いくつか違うものも試してみます ストップボタンを押して終了できます Instrumentsトレースがここにあります Core ML Instrumentは トレースにあったすべてのCore MLを 表示しています 初期ビューではすべてのイベントが アクティビティ データ コンピュートに分かれます アクティビティレーンには負荷や予測など 直接呼び出す実際のCoreML APIと 1対1の関係にあるトップレベルの CoreMLイベントが表示されます データレーンにはCore MLがモデルの 入力と出力を安全に処理できることを 確認するためにデータチェックまたは データ変換を実行するイベントが表示されます 計算レーンは Core MLが計算要求を ニューラルエンジンやGPUなどの 特定の計算ユニットに 送るタイミングを示します イベントタイプごとに個別のレーンがある グループ化されていないビューも選べます 下にはモデルアクティビティ 集計ビューがあります このビューではトレースに表示される すべてのイベントの集計統計が見られます 例えばこのトレースでは モデルの平均負荷は17.17ミリ秒かかり 予測の平均は7.2ミリ秒かかりました さらにイベントを期間ごとに並べ替えられます このリストはモデルのロードに 実際に予測を行うよりも 多くの時間がかかることを 示しています負荷は2.69秒の予測比で 合計6.41秒です おそらく低いフレームレートに関係します これらの負荷の発生経路を見てみましょう
各予測を呼び出す前にCoreMLモデルを リロードしていることに気づきました モデルを一度ロードしてメモリに保持できるので 一般的に適切な方法ではありません コードに戻ってこれを修正してみましょう
モデルをロードするエリアを見つけました ここでの問題は適切に計算されるかどうかで styleTransferModel変数を 参照するたびにプロパティが再計算されます つまり この場合はモデルがリロードされます これをレイジー変数に変更することで これをすばやく修正できます
次に Appのプロファイルを再作成し 繰り返しロードの問題が 修正されたかを確認します
もう一度Core MLテンプレートを 選択してトレースをキャプチャします これは私が期待することと完全に一致しています カウント列にApp使用スタイル数と 一致する合計5つのロードイベントがあり ロードの合計期間は予測の合計期間より かなり短いことが わかります また スクロールしてみると それぞれの間に負荷がかかることなく 繰り返される予測イベントを正しく表示します
もう1つの注意点は全CoreMLモデルの アクティビティを示す ビューを確認したことです このAppではスタイルごとに1つの Core MLモデルがあります Instrumentなら簡単に行うことができます メイングラフでは左上の矢印をクリックすると トレースで使用されているモデルごとに 1つの減算が行われます ここには使用されたさまざまな スタイルトランスファモデルが すべて表示されます 集約ビューはモデルごとに統計を 分類して同様の機能も提供します
次に モデルの1つについて予測を詳しく調べ モデルの実行方法を理解したいと思います ウォーターカラーモデルを詳しく見ていきます
この予測ではComputeレーンは 私のモデルがNeuralEngineと GPUの組み合わせで実行されたと分かります Core MLはこれらの計算要求を非同期で 送信しているため計算ユニットがモデルを アクティブに実行していると確認したい場合は Core ML Instrumentと GPU Instrumentと組み合わせられます このために 該当する機能が3つあります
Core ML Instrumentは モデルが実行された領域全体を表示します
NeuralEngine Instrument Neural Engineで実行されている コンピューティングを示し次に GPU Instrumentはモデルが NeuralEngine からGPUでの実行終了を示します これで モデルが実際にハードウェアで どのように実行されているかわかります Xcode14の Core ML Instrumentで App実行時のパフォーマンスを見ました そして モデルを頻繁に リロードしすぎている問題を特定しました コードの問題を修正しAppの プロファイルを作り直して 問題修正を確認しました また Core ML GPU新しい Neural Engine Instrumentを 組み合わせて計算ユニットの 実行方法を確認しました これはパフォーマンスを理解するための 新しいツールの概要です 次に そのパフォーマンスの最適化に役立つ 拡張APIについて説明します まず CoreMLがモデルの入力と 出力を処理する方法を説明します Core MLモデルを作成するとそのモデルに 一連の出入力機能があり それぞれにタイプとサイズがあります 実行時にCore ML APIを使って モデルのインターフェイスの入力を提供し 推論の実行後に出力を取得します もう少し詳細に画像とマルチアレイに 焦点を当ててみましょう 画像の場合 Core MLは コンポーネントごとに8ビットの 8ビットグレースケールおよび 32ビットカラー画像を サポートしています Appが既にこのタイプで動作している場合は モデルに接続するだけです ただしタイプが異なる場合もあります 例を見てみましょう 画像処理とスタイルAppに 新しいフィルターを追加してみましょう このフィルターはシングルチャンネル画像を 操作することで画像を鮮明にします 私のAppにはGPUで前後処理の操作があり この単一のチャネルをFloat16の精度で 表しますこのために coremltoolsで画像シャープニング トーチモデルをCoreML形式変換します モデルはFloat16精度計算する ように設定され画像出入力をします このようなモデルがあります Core MLの8ビットグレースケール画像なので ご注意ください このためには入力を ご覧のようにダウンキャストし 出力をご覧のように アップキャストコードを 作成する必要があります しかし これがすべてではありません モデルはFloat16の精度で 計算しCoreMLは 8ビット入力をFloat16に変換し 変換は効率的に行われますがAppを実行状態で Instrumentsトレースを見ると これが示されています Core MLがニューラルエンジンの 計算前後のデータステップにご注意ください データレーンを拡大するとCore MLがデータを コピーしてNeural Engineで 計算の準備をしていることがわかります この場合Float16に変換されます 残念ながら元のデータは すでにFloat16です 理想的にはモデルをFloat16の出入力で 直接動作させることによりApp内とCore ML内で これらのデータ変換を回避できます iOS 16とmacOSVenturaで CoreMLは1つのOneComponent 16Halfグレースケールイメージと Float16 MultiArrayを ネイティブでサポートしますcoremltools変換 メソッドを呼出し 画像の 新カラーレイアウトか MultiArrayの新データタイプを指定して Float16の出入力に対応するモデルを作成します この場合モデルの出入力を Greyscale Float16画像にし Float16はiOS16と macOS Venturaで 利用でき機能は最小展開ターゲットが iOS16のときだけ使えます モデル再変換バージョンです 出入力はGrayscale 16Halfであり Float16のサポートでAppはFloat16を Core MLに直接フィードできます これによりAppで入力をダウンキャストしたり 出力をアップキャストせずに済みます これは コードでの見え方を表しています 入力データは画面のとおりの フォーマットのため ビクセルバッファを Core MLに直接 送ることができます これによりデータの コピーや変換は発生しません 次に 出力として画面の通りに取得します この結果はシンプルなコードで データ変換は必要ありません もう一つ方法がありますCore MLに予測ごとに 新しいバッファを割り当てるのではなく 出力用に事前に割り当てられたバッファを 埋めるようにCore MLに要求します このためには出力バッキングバッファーを 割り当て それを予測オプションに設定します 私のAppでは ご覧のような関数を作成しました 次に これを予測オプションに設定し 最後に予測オプションを使って モデルの予測メソッドを呼び出します 出力バッキングを指定することで モデル出力のバッファー管理を さらに適切にコントロールできます そのためこれらの変更を加え 8ビットの入力と出力を搭載したモデルの 元のバージョンを使用する際に トレースに表示されたものを次に示します モデルの新しいFloat16バージョンに IOSurfaceでバックアップされた Float16バッファーを提供するように コードを変更後の最終的な見え方が次これです Core MLで実行しなくてよくなったので 前はデータレーンに表示されていた データ変換がなくなりました つまりCoreMLにはFloat16データの エンドツーエンドのネイティブサポートがあり Float16入力をCore MLに提供し CoreMLにFloat16を出力します 新出力バッキングAPIで 出力バッファー作成ではなく CoreMLに事前に割当てられた出力バッファー をいっぱいにすることもできます 最後に 可能な場合は常にIOSurfaceで バックアップされた バッファを使います これでCore MLは統合メモリを使って データコピーなしで異なるコンピューティング ユニット間でデータを転送することができます 次にCoreMLに追加された 追加機能について 簡単に説明します 1つ目は重量圧縮です モデルの重みを圧縮すると モデルを小さくしつつ 同様の精度を達成できる場合があります iOS 12でCore MLはトレーニング後の重圧縮を 導入しCoreMLニューラル ネットワークモデルの サイズ縮小に成功しました 現在 16ビットおよび8ビットのサポートを MLプログラムモデルタイプに拡張し 重さをスパース表現で格納するための新しい オプションを導入しています coremltoolsユーティリティを 使いMLプログラムモデルの重量子化 パレット化 スパース化が可能になります 次は新規計算ユニットオプションです Core MLは常に推論の待ち時間を 最小限に抑えることを目的としています Appの設定で 指定できます 3つの既存の計算ユニットオプションと 新しいオプションもあります Core MLにGPUで計算し Appが他の計算に役立つかもしれないので CoreMLがCPUとニューラルエンジンに 焦点を制限することを優先します 次に 初期化の新しい方法を追加します モデルのシリアル化に関して 追加の柔軟性を提供する CoreMLモデルインスタンスです カスタム暗号化スキームを使って モデルデータを暗号化してロードの直前に 復号化できます これらの新しいAPIを使えば コンパイルされたモデルを ディスク上に配置せずに メモリ内のCoreMLモデル仕様をロードできます 最後の更新はSwiftパッケージが CoreMLでどのように機能するかについてです パッケージは 再利用可能な コードをバンドルして 配布するための良い方法です Xcode 14を使えばSwiftパッケージに Core MLモデルを含めて誰かがパッケージを インポートしたときにモデルが正常に 機能するようになります XcodeはCore MLモデルを 自動的にコンパイルしてバンドルし 今まで通りのコード生成 インターフェイスを作ります Swiftエコシステムでモデル配布が これまで以上に簡単になるので とても良いシステムです これでこのセッションは終了です Core MLパフォーマンスレポートと XcodeのInstrumentは AppのMLを利用した機能のパフォーマンス分析と 最適化に役立ちます 新Float16サポートと出力バッキングAPIで CoreMLにデータがどのように流出入するかを さらに詳細に制御可能です 重量圧縮の拡張サポートはモデルのサイズの 最小化に役立ちます また インメモリモデルとSwiftパッケージの サポートでCore MLモデルの表現 統合 共有方法に関して たくさんの方法があります 以上 Core MLチームのベンでした WWDCの残りのパートも是非お楽しみください
-