-
Metalで機械学習を加速する
Metalを使用して、macOSでのPyTorchモデルトレーニングを加速する方法をご覧ください。TensorFlowトレーニングサポートの最新情報をはじめ、MPS Graphの最新機能や操作、優れたパフォーマンスで機械学習のあらゆるニーズに対応するベストプラクティスを紹介します。 機械学習でのMetalの使用について、詳しくはWWDC21の「Metal Performance Shaders Graphによる機械学習の加速」をご覧ください。
リソース
関連ビデオ
WWDC23
WWDC22
WWDC21
-
このビデオを検索
♪ ♪
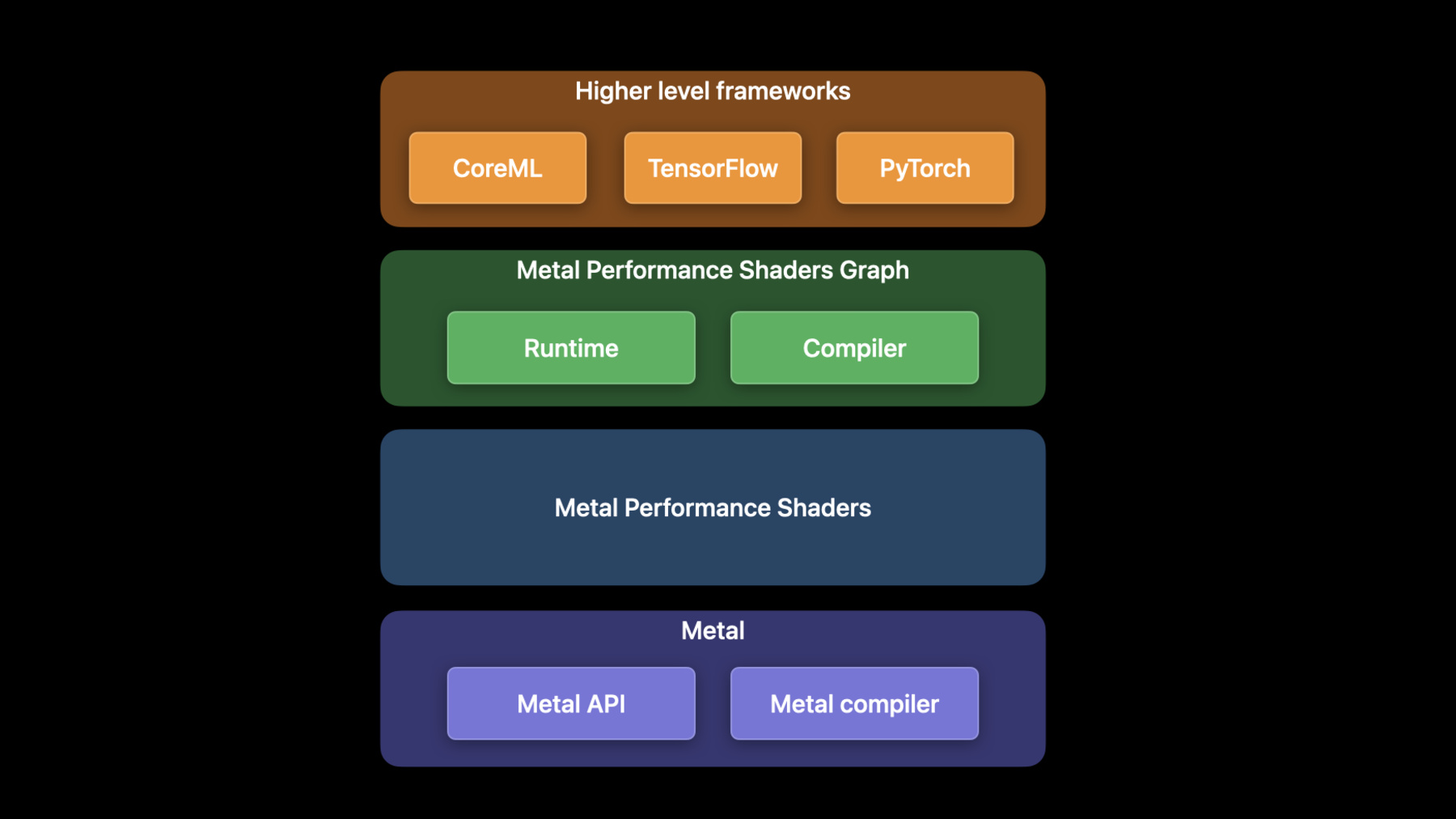
WWDC 2022へようこそ GPUSW EngineerのDhruvaです 同僚Matteoと共に今年Metalに導入された 機械学習の新機能や機能拡張を紹介します 機械学習はMLパイプラインの中で 最も計算量の多いプロセスです GPU は MLワークロードを得意としています Metal 機械学習API は MPS - Metal Performance Shadersの フレームワークを通じて公開されています MPSは 画像処理や線形代数 Ray Tracing機械学習 など 高性能GPUプリミティブの集合体です Metalカーネルは最高の性能を発揮する様に 最適化されています 例えばMPSImageCannyフィルタは 入力画像のエッジマップを返します 画像の境界検出でよく使われる操作です 今年 Cannyフィルタは4Kの高解像度画像を 最大8倍高速に処理することができます MPS Graph は汎用的な計算グラフで MPSフレームワークに乗っているGPUの為の 多次元テンソルへのサポートを拡張しています MPS Graphの使い方は前回のセッションを ご覧ください CoreMLやTensorflowの 高レベルMLフレームワークは MPS Graphの上に乗っています TensorFlow Metalプラグインを使用すると GPU上でTensorFlowネットワークを 高速化できます TensorFlowの活用方法については 昨年のセッションをご覧ください これから3つのトピックを取り上げます まずApple GPU に搭載される 最新のMLフレームワーク PyTorch を紹介します 次に TensorFlow の追加拡張を説明します MPS Graphフレームワークの 新機能を最後に説明します
あなたのMacのGPUでPyTorchのネットワークを 高速化できるようになります PyTorchはオープンソースの 機械学習として有名です 最も要望の多かった機能は Appleシリコン上での GPUアクセラレーションのサポートでした PyTorchのエコシステムに 新MPSバックエンドを導入し PyTorch に Metal のパワーをもたらします PyTorch 1.12 リリースの一部となる予定です MPSバックエンドはPyTorchの演算カーネルと Runtime フレームワークを実装しています 操作は MPS Graph とMPS に呼び出され RuntimeコンポーネントはMetalを使用します これにより PyTorch はMPSの高効率カーネルと Metalのコマンドキューとコマンドバッファ 同期プリミティブを使用することができます
オペレーションカーネルと PyTorch MPS Runtimeコンポーネントは オープンコードの一部で PyTorch 公式 GitHubにマージされています MPSのPyTorchバックエンドの使い方は 3ステップです まずPyTorch 1.12からpip install torch で 基本パッケージをインストールします Pythonの公式パッケージリポジトリから 入手可能です 環境設定やインストールの詳細は Metalデベロッパリソースページを ご参照ください 次にPyTorchをインポートし MPSデバイスを作成します MPSデバイスバックエンドが 利用可能な場合はそれを使用し そうでない場合はCPUにフォールバックします MPSデバイスを使用する為に モデルや入力を変換します デモするためにtorchvisionから事前に トレーニングされたResNet50モデルで 推論を行う例を紹介します デフォルトではCPU上でモデルが動作します “to”メソッドでMPS デバイスを使用する モデルに変換できます これはモデル内部の中間テンソルも 高速化されたMPSバックエンドの使用を 保証するものです 最後にモデルを実行できます 例ではランダムなテンソルを MPSモデルに渡しています デフォルトでは全てのテンソルは CPU上に配置され MPSバックエンドを使用するためには ここでmpsDeviceも提供する必要があります このテンソルに対する演算は 全てGPUで高速化されます 最後にサンプル入力をMPSモデルに渡して 予測を得ます これでMPSデバイスの使い方が分かったところで PyTorch の動作例を紹介します アーティストになりたいと思っていました そこで機械学習とGPUを使用して StyleTransferネットワークによる 作品制作を手掛けることにしました 画像に多様なスタイルを 適用することができます 今回はゴッホの『星月夜』の 作風を この猫の絵に どう活かすかを学ぶのが目的です 新しいMPSデバイスではGPUを使って PyTorchのネットワークを大幅に 高速学習させる事ができます これを実証する為にM1 MaxでCPUとGPUの両方で 同時にこのネットワークの トレーニングを開始します このスタイルを学習するには 数千回の反復が必要ですが GPUは短時間で合理的なモデルに収束できます
StyleTransferに加え 全ての PyTorchベンチマークで 驚くべきスピードアップを確認しました M1 Ultraでは最大20倍 平均8.3倍の 高速化が確認されました PyTorchは機械学習モデルを簡単に開発でき Apple GPUを使って学習して 時間を大幅に節約できます 次にTensorFlowの機能強化について説明します 加速化したTensorflow Metalは Tensorflowバージョン2.5から Tensorflow Metalプラグインを通じて 利用できます いくつかの機能追加や改良が行われました これには大きなバッチによる トレーニングの改善 新しいオペレーションと カスタムオペのサポート RNNの改善やトレーニングなどが含まれます TensorFlow Metalプラグインのリリースは TensorFlowメジャーリリースに合わせて 行われるため TensorFlowパッケージをアップデートして 最新の機能と改善点を 入手するようにして下さい まずは大きなバッチサイズから始めましょう 今年はTensorFlow-Metalの ソフトウェアの改良により Appleシリコンの利点を活用できます これは様々なバッチサイズでResNet50モデルを 学習させた場合のスピードアップを表してます データからバッチサイズを大きくすると データ更新がより真の値に近くなる為 性能が向上すると分かります AppleシリコンのUMAにより 大規模なネットワークや 大きなバッチサイズを実行することができます これでクラウドクラスターに 分散させることなく 1台のMac Studioで実行できるようになります またAppleシリコンはワットあたりの動作が高く ネットワークが今まで以上に効率的に動作します 次に新しい操作とカスタムについて説明します Tensorflow Metalプラグインでは argMin all pack adaDeltaなど 様々な新しい操作の GPUアクセラレーションを備えています しかし現在tensorflow APIで サポートのない操作の為に GPUアクセラレーションが必要な場合は どうすれば良いでしょうか? カスタムオペレーションを 作成する必要があります こちらは単純な畳み込みネットワークを 2回反復して動作させた例です これはGPUとCPUで行われる作業を それぞれ上と下で表しています ネットワークは畳み込み・最大プール化 そしてSoftmax Cross Entropy Lossを行います これらの操作はすべて TensorFlow Metalプラグインで MPS Graphを通じて GPUアクセラレーションが行われます しかし自作の損失関数を 使いたいと思うかもしれません この自作の損失のために MPS GPUアクセラレーションがなければ その作業はCPUのタイムラインで 実行する必要がありGPUを消耗させます これをGPUで行うと遥かに 高い動作を発揮できます 自作操作を実装する為に TensorFlow-Metal Streamの プロトコルを理解する必要があります GPUの操作を暗号化するためのプロトコルです GPUカーネルを暗号化する際に使用する MTLCommandBufferへの参照を保持します また暗号化処理中に複数の スレッドから処理が投入され CPU側の同期を取る為に dispatch_queue を公開しています Commit又CommitAndWaitで 作業をGPUに提出します CommitAndWait は現在の コマンドバッファが終了するまで待機し シリアル化された送信を観察できる デバッグツールです ではカスタムオペ実装方法を見てみましょう カスタムオペレーションを作るには 3ステップあります まずオペレーションを登録します 次にMetalStreamを使った操作を実装します 最後トレーニングスクリプトに インポートします まず登録してみましょう TensorFlowコアで公開してる REGISTER_OPマクロを使用して Opのセマンティクスと TensorFlow-Metalプラグインでの 定義方法を指定します 次にTensorFlow_MetalStreamを使用して Opを実装します まず Compute 機能の定義から始めます さて関数内部でオブジェクト TensorFlow_Tensorを取得し アロケーションが必要な 出力を定義します Metalストリームのコマンドバッファで エンコーダを作成します 次にカスタムGPUカーネルを定義します あなたの Op は Metalストリームが提供する dispatch_queue の中にエンコードされます よって複数スレッドの送信が 確実にシリアル化されます
TensorFlow_MetalStream プロトコルで提供される メソッドを使用してカーネルを実行します
最後に割り当てたテンソルの参照を削除します
最後にこのオペレーションをトレーニング スクリプトにインポートして使用を開始します ここではzero_out.soというカスタムopの 共有ダイナミックライブラリをビルドします .soファイルをビルド・インポートする方法は Metalデベロッパーリソースを参照ください この例ではTensorFlowの load_op_libraryを使用し オプションの手順で操作を トレーニングスクリプトに インポートしています これでPythonのラッパーの様 動作しトレーニング スクリプトの中で自作Opを 呼び出すことができます 次に面白いAppの例を見せます Neural Radiance Fields (NeRF)です より良いアルゴリズムの為に GPUアクセラレーションを有効にして ネットワークの高性能自作Opを作りました
NeRFは3Dビュー合成用のネットワークです NeRFは学習用に様々な 角度から撮影した画像を入力します NeRFネットワークは2つの 多層パーセプトロンを積み重ねたもので 出力はモデルの体積を表現しています リアルタイムトレーニングの 重要な性能最適化は ハッシュテーブルの実装を使用します 更新で多層パーセプトロンの サイズを大幅に小さくできました ハッシュテーブルを ネイティブにサポートしていないので 自作Op機能を使って Metalプラグインに実装しています GPUで高速化することで NeRF学習を更に高速化できます まずはこのMacBookで 独自の多層パーセプトロンを実行します
合理的なレンダリングには 最低20回のエポックが必要ですが 1回のエポックに約100秒かかっています つまり約30分かかるということです そこで事前に30分放置した チェックポイントファイルから 学習を再開します エポック20から開始です 30分程度でも3Dモデルがぼやけて不鮮明です より明確に3Dモデルを学習するには 長い学習時間が必要です カスタムハッシュテーブルを使用しない 多層パーセプトロンのアプローチでは遅すぎます それではMacBookでカスタムハッシュテーブルを 使用した最適化版をキックオフします この実装では明確なモデルを 描画することができ 各エポックの学習には 僅か10秒しかかかりません このプロジェクトの詳細については Metalデベロッパリソースをご参照下さい
NeRFは独自のカスタム操作に GPUアクセラレーションを実装して ネットワークを高速化する方法を示す 数多くのネットワークの1つに過ぎません 是非あなたの工夫を凝らした カスタムを教えて下さいね Apple GPUを使ってMLワークロードの トレーニングを実行する方法を紹介します ワークロードのトレーニングを分散するために トレーニングスクリプトの 複数インスタンスを 別々のプロセスで実行して 単一の反復評価ができます
中央データストアからデータを読み込みます その後モデルを実行し勾配を計算します 次に各プロセスは勾配を平均化し 次の反復前に各プロセスが同じ勾配を 持つようにこれを互いに伝達します 最後にモデルを更新し 全ての反復を終えるまで このプロセスを繰り返します TensorFlowで実演するために Horovodという有名なオープンソースを使った 分散学習の例を紹介します
リングオールリデュース方式を採用しています このアルゴリズムではN個のノードが 各2個のピアと複数回通信を行います この通信を利用してワーカープロセスは 各反復の前に勾配を同期させます 4台のMac StudiosをThunderboltケーブルで 接続しその様子を紹介します 画像の識別器であるResNetを学習させます 各Mac Studioの横にあるバーは ネットワーク学習時の GPU使用率を示しています Mac Studio1台の場合約200枚/秒の性能です Thunderboltで接続したもう1台を追加すると 両方のGPUをフルに活用できるため 1秒間に400枚とほぼ倍増します さらに2台を接続すると 800枚/秒まで性能が向上します 入出力バウンド作業量に対し ほぼ直線的に拡張できます
さてここでTensorFlowの 分散学習性能を見ましょう これは1台2台4台使用時の 相対的高速化を表しています リングトポロジで接続され 最新TensorFlow-Metalと Horovod で ResNet やDistilBERT などの 演算結合型TensorFlow-networkが 実行されています ベースはMac Studio 1台での性能です グラフはネットワーク性能がGPUの追加に応じて スケールアップすることを示しており 複数のデバイスのGPUを活用して トレーニング時間を短縮し 全てのAppleデバイスを最大限に活用できます
今年 TensorFlowに搭載された すべての改良と機能は このグラフに集約されており CPU実装に対する 相対的な動作を示しています MPS Graphフレームワークの 新機能をMatteoに説明してもらいます ありがとうDhruva 私はGPUのSEをしているMatteoといいます PyTorchとTensorFlowはMPS Graph上にあります 一方MPS GraphはMPSフレームワークが公開する 並列プリミティブを使用して GPU上の作業を高速化します 今日はMPS Graphを使って 計算ワークロードをさらに高速化するための 2つの機能についてお話します まず2つのグラフ間で作業を 同期させることができる 新しい共有イベントAPI を紹介します 次にMPS Graphを使って さらに多くのことができる 新しい操作について説明します まずはShared Events API 同じコマンドキューでAppを実行することで ワークロード間の同期を確保します 例では計算ワークロードは後処理や表示などの 他ワークロードがディスパッチされる前に 常に終了することが保証されています この場合 各シングルディスパッチ内で GPU並列性を活用することになります しかしAppによってGPUの第1部分を演算に使い 第2部分を後処理や表示に使うなど より並列性を高めることが 有効な場合があります 複数コマンドキューでGPUに 作業投入して実現できます 残念ながらこの場合計算が結果を出す前に 後処理パイプラインがディスパッチされ データレースが発生する可能性があります Shared Events APIはこの問題を解決し コマンドキュー間の同期を導入することで ワークフローの依存関係を 確実に満たす事ができます これをコード内で使用するのは簡単です 2つのグラフを扱うとします 1つ目は コンピュートワークロードを担当し 2つ目は後処理の作業量を担当します また計算グラフの結果を 後処理グラフ入力として利用 両者が異なるコマンドキューで 実行されることを想定しましょう Metal System Traceの 新しいMPS Graphトラックは コマンドキューが互いに 重複している事を示します これはデータ競合を発生させます この問題はシェアイベントで解決できます Metalデバイスを使用して イベントを作成します 次にイベント アクション値 を指定して 実行記述子のシグナルメソッドを呼びます あとは2番目の記述子に対して イベント変数と値を指定して wait メソッドを呼び出すだけです
現Metalシステムトレースは 2つのコマンドキューが順次実行され computeとpost processingの グラフの依存関係の解消が示されています この様にAppの同期問題を解決するために シェアイベントを利用することができます 次にMPS Graphがサポートする 新操作についてです フレームワークで様々な事が できるようになります RNN から順に新しいOps の詳細を教えます
MPS Graphは RNN Appで 一般的に使用される3つの操作を公開しました RNN LSTM GRUのレイヤーです どれも似ているので 今回は LSTMsにだけ焦点を当てます LSTMs の演算は自然言語処理などに よく使われます これは LSTM の動作の様子を示しています 詳細は 前回のWWDCのセッションをご覧下さい LSTMユニットを自分で実装できますが その場合 複雑なカスタムサブグラフを 構築する必要があります その代わり回帰型ユニットが 必要とする全てのGPU作業を 効率的にエンコードする新LSTMを使用できます よってLSTMベースのCoreML 推論モデルが高速化されます
新LSTM演算を使用するには MPS GraphLSTMDescriptorを作成します 必要に応じて活性化関数を選択するなど 記述子のプロパティを変更することができます 次に LSTM ユニットをグラフに追加し 入力テンソルを提供します また バイアス ベクトルや演算の初期状態や セルを指定することも可能です 最後にディスクリプタを提供します 以上でLSTMの設定は完了です 他のRNNの動作も同様です 是非これらの操作を試してあなたのAppで どの程度 高速化されるか試してみてください 次にMaxPoolingのサポートが 強化されたことを紹介します TMaxPooling 演算は入力テンソルと ウィンドウサイズを受け取り ウィンドウを適用するごとに ウィンドウ内の入力の 最大値を計算するものです 画像次元を減らすためによく使われます Pooling演算子で抽出された最大値位置の 指標を求めるAPIが拡張されました 最大値が抽出された場所を介して 勾配を伝達する必要がある場合 勾配パスでインデックスを 使用することができます 新しい API はトレーニングにも有効です 学習時にインデックスを再利用することで PyTorchとTensorFlowでは 最大6倍高速化できます
まずGraphPoolingディスクリプターを 作成します returnIndicesModeを指定します 例えばglobalFlatten4Dです Return Indices API を使い プーリング操作を呼び出す 操作の結果は2つあります まず poolingTensorそして indicesTensor indicesTensorをキャッシュしておくと 後で学習パイプラインなどで利用できます
MPS Graphは新たに並列乱数発生器を公開し 学習用グラフの重みの初期化などに 使用できるようになりました 今回のランダム演算は Philoxアルゴリズムを使用し 与えられたシードに対し TensorFlowと同じ結果を返す newは入力として状態テンソルを受け取り 出力としてランダムテンソルと 例えば2番目のランダム操作の入力として 使用できる新しい状態テンソルを返します 新しいランダム演算を使用するには randomPhiloxStateTensorメソッドを呼びます これで指定されたシードで 入力状態テンソルを初期化します 次に RandomOp の記述子を定義し 分布とデータ型を入力として受け取ります この例では記述子は 32bit 浮動小数点数の truncatedNormal 分布を指定します また正規分布や一様分布も使用できます
さらに平均値や標準偏差 最小値や最大値を指定することで 分布の特性を定義できます 最後に形状テンソルと記述子 そして先ほど作成した stateTensorを指定して ランダム操作を作成します
MPS Graph はRandom に加え 2つのビットベクトル間の ハミング距離を計算する GPU加速演算を新たにサポートしました ハミング距離は同じ長さの2つの入力間で 異なるビット数として定義され 2つの配列間の編集距離の指標となり バイオ情報学から暗号学まで いくつかで使用されています HammingDistanceを使うには グラフ上でAPIを呼び出し primaryTensorとsecondaryTensor resualtDataTypeを指定します 新カーネルはGPU上のバッチ次元での ブロードキャストをサポートします それでは新しいテンソルの 簡単な操作を紹介します これで例えばテンソルの次元を 2次元から3次元に拡張できます そして次元を削減して戻すことができます
またテンソルを軸に沿って分割したり 重ねたりする事もできます
また与えられた入力形状に対して テンソル次元に沿った座標値を生成できます 例えば2×4の形状のテンソルに 0軸に沿った座標を入力できます これは range1D 操作の実装にも利用できます 例えば3から27までの数字の範囲を 4刻みで生成したいとする その場合 まず形状6のテンソルの0次元に 沿った座標を作成すればいいのです あとは増分値を掛けて補正値を足すだけです 以上が今年新たに加わった操作です これらの新しい操作によりMPS Graphを使用して Appleエコシステム全体で 更に高い成果を上げれます ではMPS Graphのうち Appleシリコンで得られる 高性能化の方法を紹介します BlackmagicはMPS Graphを使用して 機械学習のワークロードを加速させる DaVinci Resolve18リリースしました Magic Maskは機械学習により 画面上の動くものを識別し その上に選択的フィルターを適用する Resolveの機能です まず旧バージョンのResolveでこの機能を実演し 次に現バージョンと比較します マスクを作成するには 対象となるオブジェクトを選択して オーバーレイの切替でマスクを表示できます マスクは赤い範囲で識別され 被写体の形状をマークします 動画再生時マスクは画面上で 動くオブジェクトを追跡します 見た目は素晴らしいのですが 機械学習のパイプラインが フード下で動いている為 低フレームレートの動作です 今度はMPS Graphを使って Magic Maskネットワークを高速化した Resolveの最新版に切替えてみます 再び同じ時間軸を実行すると フレームレートは速くなります その結果 Appleシリコン上で より良い編集体験ができます
これらはMPS Graphを採用するだけで 得られる高速化です どんな動作をもたらすのか探ってみてください まとめです これからあなたができることは PyTorch の GPUアクセラレーションの活用 そしてプロジェクトは オープンソースとなりました TensorFlow-Metalプラグインを使用した 学習ワークロードの 高速化についてカスタム操作 分散学習など新しい方法を 見つけることができます 最後にAppleシリコンを最大限に活用するために MPS Graphフレームワークを用いて 共有イベントや新しい操作で最も要求の厳しい 機械学習タスクを最適化できるようになります 新機能を皆さんがAppで どう使うか楽しみです
-
-
3:44 - Install PyTorch using pip
python -m pip install torch -
3:59 - Create the MPS device
import torch mpsDevice = torch.device("mps" if torch.backends.mps.is_available() else “cpu”) -
4:15 - Convert the model to use the MPS device
import torchvision model = torchvision.models.resnet50() model_mps = model.to(device=mpsDevice) -
4:46 - Run the model
sample_input = torch.randn((32, 3, 254, 254), device=mpsDevice) prediction = model_mps(sample_input) -
9:27 - TensorFlow MetalStream protocol
@protocol TF_MetalStream - (id <MTLCommandBuffer>)currentCommandBuffer; - (dispatch_queue_t)queue; - (void)commit; - (void)commitAndWait; @end -
10:25 - Register a custom operation
// Register the operation REGISTER_OP("ZeroOut") .Input("to_zero: int32") .Output("zeroed: int32") .SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) { c —> set_output(0, c —> input(0)); return Status::OK(); }); -
10:41 - Implement a custom operation
// Define Compute function void MetalZeroOut::Compute(TF_OpKernelContext *ctx) { // Get input and allocate outputs TF_Tensor* input = nullptr; TF_GetInput(ctx, 0, &input, status); TF_Tensor* output; OP_REQUIRES_OK(ctx, ctx->allocate_output(0, input.shape(), &output)); // Use TF_MetalStream to encode the custom op id<TF_MetalStream> metalStream = (id<TF_MetalStream>)(TF_GetStream(ctx, status)); dispatch_sync(metalStream.queue, ^() { id<MTLCommandBuffer> commandBuffer = metalStream.currentCommandBuffer; // Create encoder and encode GPU kernel [metalStream commit]; } // Delete the TF_Tensors TF_DeleteTensor(input); TF_DeleteTensor(output); } -
11:30 - Import a custom operation
# Import operation in python script for training import tensorflow as tf zero_out_module = tf.load_op_library('./zero_out.so') print(zero_out_module.zero_out([[1, 2], [3, 4]]).numpy()) -
19:29 - Using shared events
// Using shared events let executionDescriptor = MPSGraphExecutionDescriptor() let event = MTLCreateSystemDefaultDevice()!.makeSharedEvent()! executionDescriptor.signal(event, atExecutionEvent: .completed, value: 1) let fetch = computeGraph.runAsync(with: commandQueue1, feeds: [input0Tensor: input0), input1Tensor: input1], targetTensors: [finalTensor], targetOperations: nil, executionDescriptor: executionDescriptor) let executionDescriptor2 = MPSGraphExecutionDescriptor() executionDescriptor2.wait(for: event, value: 1) let fetch2 = postProcessGraph.runAsync(with: commandQueue2, feeds: [input0Tensor: fetch[finalTensor]!, input1Tensor: input1], targetTensors: [finalTensor], targetOperations: nil, executionDescriptor: executionDescriptor2) -
22:03 - Adding an LSTM unit to the graph
let descriptor = MPSGraphLSTMDescriptor() descriptor.inputGateActivation = .sigmoid descriptor.forgetGateActivation = .sigmoid descriptor.cellGateActivation = .tanh descriptor.outputGateActivation = .sigmoid descriptor.activation = .tanh descriptor.bidirectional = false descriptor.training = true let lstm = graph.LSTM(inputTensor, recurrentWeight: recurrentWeightsTensor, inputWeight: weightsTensor, bias: nil, initState: nil, initCell: nil, descriptor: descriptor, name: nil) -
23:35 - Using MaxPooling with return indices API
// Forward pass let descriptor = MPSGraphPooling4DOpDescriptor(kernelSizes: @[1,1,3,3], paddingStyle: .TF_SAME) descriptor.returnIndicesMode = .globalFlatten4D let [poolingTensor, indicesTensor] = graph.maxPooling4DReturnIndices(sourceTensor, descriptor: descriptor, name: nil) // Backward pass let outputShape = graph.shapeOf(destination, name: nil) let gradientTensor = graph.maxPooling4DGradient(gradient: gradientTensor, indices: indicesTensor, outputShape: outputShape, descriptor: descriptor, name: nil) -
24:42 - Use Random Operation
// Declare Philox state tensor let stateTensor = graph.randomPhiloxStateTensor(seed: 2022, name: nil) // Declare RandomOp descriptor let descriptor = MPSGraphRandomOpDescriptor(distribution: .truncatedNormal, dataType: .float32) descriptor.mean = -1.0f descriptor.standardDeviation = 2.5f descriptor.min = descriptor.mean - 2 * descriptor.standardDeviation descriptor.max = descriptor.mean + 2 * descriptor.standardDeviation let [randomTensor, stateTensor] = graph.randomTensor(shapeTensor: shapeTensor descriptor: descriptor, stateTensor: stateTensor, name: nil) -
25:59 - Use the Hamming Distance API
// Code example remember 2D input tensor let primaryTensor = graph.placeholder(shape: @[3,4], dataType: .uint32, name: nil) let secondaryTensor = graph.placeholder(shape: @[1,4], dataType: .uint32, name: nil) // The hamming distance shape will be 3x1 let distance = graph.HammingDistance(primary: primaryTensor, secondary: secondaryTensor, resultDataType: .uint16 name: nil) -
26:21 - Use the expandDims API
// Expand the input tensor dimensions, 4x2 -> 4x1x2 let expandedTensor = graph.expandDims(inputTensor, axis: 1, name: nil) -
26:30 - Use the squeeze API
// Squeeze the input tensor dimensions, 4x1x2 -> 4x2 let squeezedTensor = graph.squeeze(expandedTensor, axis: 1, name: nil) -
26:35 - Use the Split API
// Split the tensor in two, 4x2 -> (4x1, 4x1) let [split1, split2] = graph.split(squeezedTensor, numSplits: 2, axis: 0, name: nil) -
26:39 - Use the Stack API
// Stack the tensor back together, (4x1, 4x1) -> 2x4x1 let stackedTensor = graph.stack([split1, split2], axis: 0, name: nil) -
26:46 - Use the CoordinateAlongAxis API
// Get coordinates along 0-axis, 2x4 let coord = graph.coordinateAlongAxis(axis: 0, shape: @[2, 4], name: nil) -
27:04 - Create a Range1D operation
// 1. Set coordTensor = [0,1,2,3,4,5] along 0 axis let coordTensor = graph.coordinate(alongAxis: 0, withShape: @[6], name: nil) // 2. Multiply by a stride 4 and add an offset 3 let strideTensor = graph.constant(4.0, dataType: .int32) let offsetTensor = graph.constant(3.0, dataType: .int32) let stridedTensor = graph.multiplication(strideTensor, coordTensor, name: nil) let rangeTensor = graph.addition(offsetTensor, stridedTensor, name: nil) // 3. Compute the result = [3, 7, 11, 15, 19, 23] let fetch = graph.runAsync(feeds: [:], targetTensors: [rangeTensor], targetOperations: nil)
-