-
Apple GPUでコンピューティングワークロードを拡張する
コンピューティングワークロードを作成して、Apple GPUで効率的に拡張する方法をご覧ください。作業配分を改善してGPUを飽和させたり、効果的なパイプライン化と同時ディスパッチでGPUタイムラインのギャップを最小化したり、アトミック操作を効果的に使用したりする方法を紹介します。また、XcodeやInstrumentsの最新のカウンタやツールについても解説します。これで、空間および時間のメモリアクセスパターンを最適化することができるようになります。
リソース
関連ビデオ
WWDC23
WWDC22
Tech Talks
-
このビデオを検索
(音楽)
こんにちは 私の名前はMarco Giordano GPU Software Engineering teamのメンバーです このセッションではApple M1 GPUでの スケールの方法についてお話しします 複雑な作業負荷に携わっていて Apple Siliconを最大限に使いたいなら ここに来て正解です まずスケーリング概念で M1 GPUを使ってのスケーリングについて話し その方法を順番に見ながら スケーリングを最大限に行うための ツールについてお話しします まずスケーラビリティと その重要性について理解しましょう
Apple M1 GPUはスケーリングと 優れた性能を念頭に一からデザインされました 8-core iPadから64-core MacStudioまで Metal3を全面サポートしています
このハイレベルのスケーリングで M1に最適化することはいい出発点になります 多くのプロAppはすでに最適化されており 素晴らしいスケーリングを達成しています
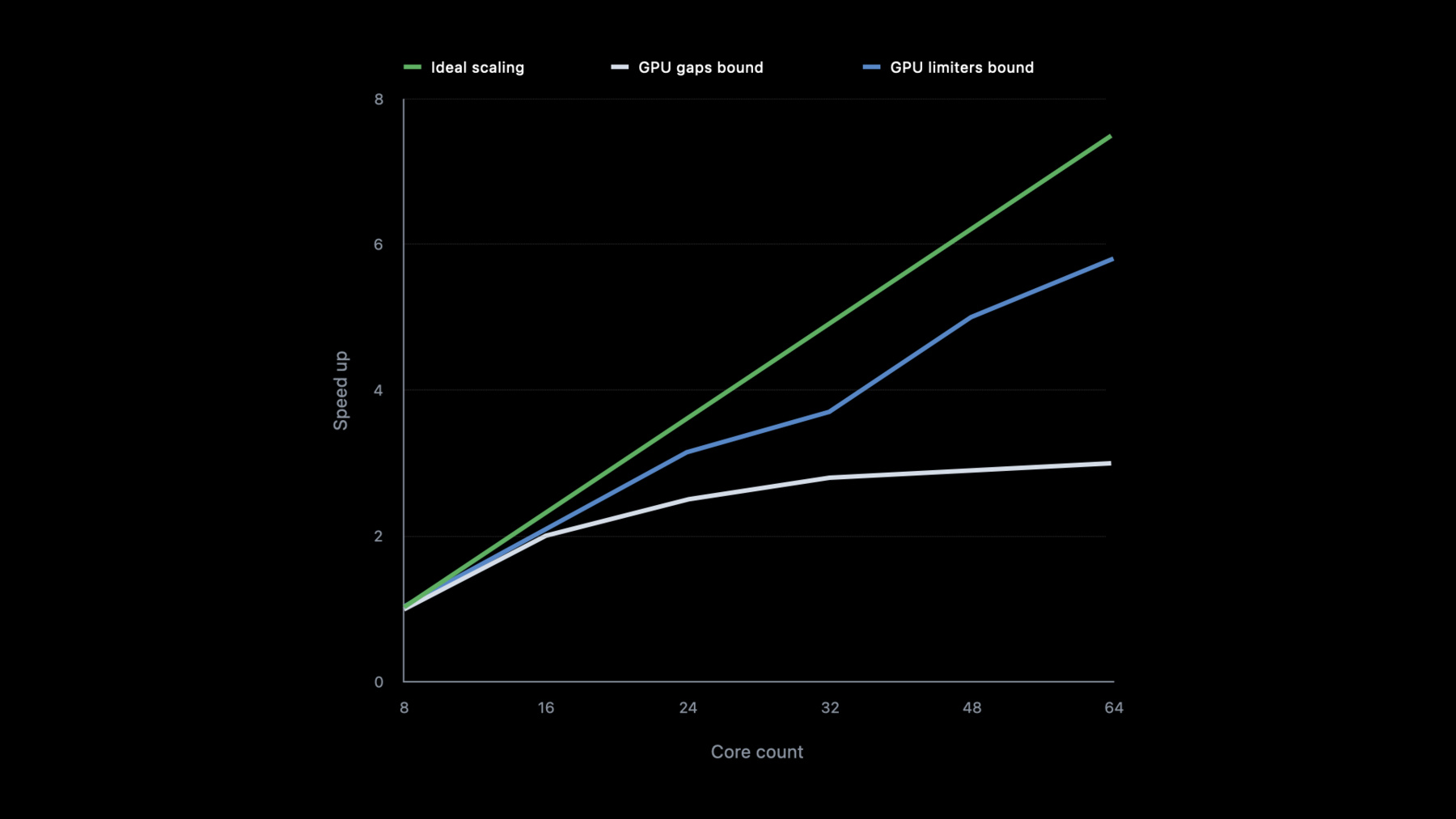
例えばAffinity Photoと DaVinci Resolveがあります これらの写真と映像の編集Appは 見事なスケーリングを達成しています スケーラビリティを定義し 達成方法を見てみましょう GPU workload scalabilityは GPU coreを増やすことで 性能を向上できる容量のことです このグラフはGPU core数の増加による Appの速さを示しています 直線的な向上が理想的です
しかし あなたのAppはピークに達してしまい GPU timeline gapsで性能が落ちるか まったくスケールしていないかもしれません もしくは性能は向上しているものの その向上にはムラがあり GPUが限界に達しているかもしれません ここでは24と32 48と64 coreの間です
あなたのゴールは直線ゴールに近づけることで 問題の原因を発見し性能を向上させる ツールとテクニックをお見せします
次はGPUスケーリングを 最大化する方法についてです どの作業負荷でもまずネックの原因を調べます 原因は計算かバンド幅にあるかもしれません 最適化する過程で 両方の原因の間をバウンスするかもしれません 計算が原因ならメモリーにある程度移し 計算量を減らす必要があるかもしれません スケールアップと共に ネックが動くかもしれません 解決策の一つはMPSやMPSGraphなど Appleフレームワークの使用かもしれません それらの基本要素を利用すれば compute kernelが最大限を尽くすはずです しかしすべてをMPSに置き換えられません ですので作業負荷を理解することが大切です
まずGPU gapsを最小化する 3つの方法のお話しをします 作業負荷分配の向上GPU timeline gapsの削除 及びAtomics operationです そしてgridとlayoutの影響を調べ Blender Cyclesで具体的な例を見て GPU limitersを どう最適化するかについてお話しします まずGPU gapsの最小化についてです これはハードウェアが待機中 GPU timelineにgapsが生じ GPUが最大限に活用されていないのが原因です
では作業負荷の分配で 向上できるか見てみましょう
小さい作業負荷は通常GPU全体を使わず kernel synchronizationが使われるため 適切なスケーリングを 妨げているかもしれません 作業負荷がハードウェアにどう分配されるか 理解することが重要です 作業負荷はthreadgroupsの 3D gridとして送られます ThreadgroupsはGPU coresに均等に分配され サイズに限りはあるものの速くローカルな threadgroup memoryにアクセスします threadgroupはwavesやwarpsとして知られる SIMD-groupsに分類されます Thread Execution Widthを調べると SIMD-widthがわかります Apple GPUはすべて32です
Threadgroupには最大1024 threadsあり threadgroup memoryを32KBまでシェアできます
すべてのGPU coresにおいて 十分な作業があるべきです
これはgridへの配布例です ThreadgroupsがGPU Clustersに配布され GPU coresに分配されます
threadgroupsが少ないと マシン全体に作業が分配されません こうやって直します
まず いくつのthreadsがあるか計算し マシン全体を供給するか見てみます 比較的複雑なkernelsの場合 1Kから2Kのthreadsが 妥当な量だとされています ですのでGPU core1つあたり 1K〜2Kを目安にします ここから十分分配される作業があるか計算します この表はSOCsを満たすことができる 最低限のthreads数を示しています
また必要以上に大きい threadgroupサイズを避けることです threadgroupsを小さくすれば より均等に分配されます 大きいthreadgroupsは均等な配分を妨げ GPU coresのバランスに影響します
作業負荷にあう最小限のSIMD widthの倍数を 使用するべきです 小さいthreadgroupsを使用することで GPUは作業負荷をバランスできます
XcodeかInstruments GPU Toolsで 常にkernel runtime performanceを確認してください
このGPU captureの例ではkernelが計算中です 使用量は意外にもかなり低めです compiler statisticsがXcode 14に新登場の max theoretical occupancy が100%を示しています つまり十分なthreadsがないことを意味し アルゴリズムでthreadsが徐々に減少しており マシンを満たしていません
原因は他にもあるかもしれません 詳細は以下のビデオをご覧ください さて 作業負荷が正しく配分され GPUが常に稼働するようにせねばなりません
GPUを活用しないと理想のスケーリングはできず 最悪の場合待機状態にしてしまいます それはGPU timeline gapsがあるからです
この例を見てください CPUとGPUのシリアライズにより 作業負荷はGPUを50%しか使用していません この場合 全行程の時間は CPUとGPUの作業の合計で 重複はありません
GPU coresを倍にすると GPU trackが速くなりますが CPU track は影響しません 全体性能は33%速いものの まだ理想ではありません
再びGPU coresが倍になると GPUの作業が速くなるものの 全体的レイテンシは60%しか減少しません つまり結果が少なくなるということです 理想ではないので正しましょう
このM1 proのInstrument traceには大きなgapsがあり 理想のスケーリングを妨げます
M1 Ultraでは少し速いものの GPU idle timeが大きくなり 作業負荷はスケーリングできていません command bufferでwaitUntilCompletedにより CPU synchronizationでgapsが生じています waiting logicを変更しserializationを除くと GPUがフルに利用されます
スケーリングを 前後で比べると 理想のスケーリングに 近づいたと言えます
先ほどの例ではCPU/GPU synchronizationを 同時に除くことができました しかしApp次第でいつもそうだとは限りません 待機時間を減少する方法は他にもあります MTLSharedEventsでCPUに合図して さらに作業を取り込みGPU-driven encodingで concurrent dispatchesを使用できます どうすればGPU timeline gapsを減らせるでしょうか 作業負荷にあうものもあります
GPUのcompletionを待つのは 理想的ではありません WaitUntilCompletedを使っているなら MTLSharedEventsを使ってみるべきです
MTLSharedEventsはオーバーヘッドが少なく timeline gapsを減少できます もう一つは パイプライン方式です
次の仕事に必要なデータが アルゴリズムにあれば MTLSharedEventを待つ前に いくらかエンコードすることが可能です これでGPUを使い果たすのを避け 常に処理する仕事があります
もし同じキューで予めエンコードできないなら 2つ目のキューで重複させてみてください いくつかのキューを使うと仕事は独立しており eventを待つ間 他のthreadを立ち往生させません こうすればGPUは常に 仕事を受け入れ処理できます
GPUから直接処理できるアリゴリズムもあります
間接的なcommand bufferで 次のバッチの処理をGPUで直接動かせ synchronizationを避けられます これらについての詳細はこちらをご覧ください 「Metalによる最新のレンダリング」 これで作業負荷はCPUと GPU間のsynchronizationsを 省くか最小化できます しかし まだ問題があるかもしれません 調べてみましょう このグラフは画像処理の作業負荷で 画像が1フレームずつ処理されています こうした連続的処理作業も スケーリングに影響します GPUは稼働中ですが kernel synchronizationで 負荷がありthreadgroupsに ムラがあるため coresが満たされていません またthreadgroupsが終了すると coresを満たすのに十分な 作業がないかもしれません この場合 できる限り作業を重複させることです 図で見てみましょう ここでは2つの画像を続けて処理しています 通常kernelsはシンクロ ナイズする必要があります しかし これ以外にも方法があります concurrent dispatchesで処理を挟み込むです concurrent dispatchesで別の作業を 挟み込むことができます 連続的だった2つのkernelsが 独立作業で分割されました しかしMTLDispatchType Concurrentで バリアが手動で入れられねばなりません Concurrent dispatchesは 作業を詰め込むことができ kernels間のsynchronizationを控え 様々なkernelsの穴埋めをすることができます この最適化で作業負荷能力が向上し M1 MaxからM1 Ultraへの スケーリングも向上します 2つの画像を挟み込んだ場合 作業負荷が30%速くなり 3つの画像が並行すると 以前より70%速くなります
Atomic operationsを考慮するのも重要です 最も効率的であることを確かめましょう Atomic operationは幾つものthreadsから 安全な方法でデータの読み書きを可能にします Global atomicsはGPU全体で一貫しています いくつものthreadsが同じ 大域的値を読み書きすると 競合につながります GPUの数を増やしてもさらに競合が増すだけです ではAtomics behaviorをどう向上できるか アルゴリズムで見てみましょう
ここにバッファーにある すべての値が合計される 還元アルゴリズムがあります 単純なアプローチは 主要メモリーでthreadごとに Atomic add operationを行うことです しかしこれは一つの値に 圧力をかけメモリーの書込を シリアライズしてしまうので 理想的ではありません
Atomicメモリー競合に対し 2つの対策があります SIMD-group instructionと threadgroup atomicsです
prefix_exlusive_sumなどの SIMD instructionsは メモリーを介さずSIMD-group内で レジスター間の処理とメモリー交換を行います Threadgroup atomicsは threadgroupメモリで履行 各GPU coreにthreadgroupメモリがあり いくつものGPU coresでスケールできます ではこれらでどう作業負荷が 向上できるか見てみましょう
ここに同じ縮小問題がありますが 今度はSIMD-group instructionである inclusive memory sumを使います このオペレーションは SIMD groupの全数値の合計を 最後のthreadにまとめます 各SIMD groupの最後の threadがAtomic addを行い 全SIMDi groupsをThreadgroup memoryで 一つの値に縮小します SIMD group instructionと threadgroup memoryを使い メインメモリに触れずに threadgroupを縮小しました 各groupが同時にそれぞれ縮小できたのです
単一値に縮小できたので 1threadgroupにつき1threadで メインメモリで1つのAtomicができます 各threadgroupで Atomicが一つになるだけでなく threadgroupsは別々の時間に 終了するため atomicsを時間的に広げることで メモリーの競合をさらに防げます まとめると Atomicsを最大限に使うため メモリの局所性を利用して SIMD group operationや threadgroup memory atomicsを使用します これらで作業負荷を減らし スケーリングを妨げられます
GPU gapsが直りスケーリング が理想に近づいたか調べます XcodeのGPU LimitersとMetal System Traceが GPU cores execution pipelineの問題を改善します 例えば 非能率なmemory access patternsは 常に高いLast Level Cacheや Memory Management Unit MMU limitersを引き起こし 利用度も低くなります まずthreadgroupsとmemory layoutの調整です memory spanと分散を減らす鍵は 空間的および時間的にmemory access patternを 理解することです それを理解すれば2つの調整方法があります 局所性を改善するため data layoutを整理し直すか access patternを調整してdata layoutにあわせ memoryとcacheの局地所性を改善するかです 例を見てみましょう
これはデータが横に並んだmemory bufferです 行ごとに並んでいます しかしcompute kernelが配布されると 四角のthreadgroupsが分配され 2Dパターンのようになり 空間的に局所化されることがあります これはデータの局所性によくありません
例えば最初のSIMD groupが データにアクセスする時 リクエストはcache linesに詰み込まれます そのほとんどは使われませんが cache内で場所をとってしまいます access patternに合わせるため整理し直せば データが一列に広がる代わりに 縞状に局所化されます
これによりthreadgroupは cache lineのデータを ほとんど利用することができ 発散を避けchacheの能率を向上します
もう一つは現在のdata layoutにあわせて 3D gridの配布方法を変更することです threadgroup sizeを調整しmemory layoutにあう グループを作りますこの例で言うと 長方形型です access patternがmemory layoutと一致し chacheの能率が高くなります 作業負荷にあわせて 最適なものを探してください 時として 何かと引き換えにせねばなりません メモリ局所性のために threadの分散を犠牲にしたり data layoutやgrid dispatchの変更などです その作業負荷もaccess patternも違います
メモリ局所性の向上方法がわかり Blender Cyclesで別の例を見てみましょう
CyclesはBlenderの物理ベースpath tracerです 物理学ベースの結果を提供できるデザインで artistic controlとflexible shading nodesが特徴です
低いread bandwidth高いTop GPU Limiter 高いcache limiterと 低いcache utilizationです
bandwidthとMMU limitersは スケーリングに需要です TOP limiterがlast level cacheかMMUなら memory spanを減らし局所性の最大化が必要です 例を見てみましょう
Cyclesは分散の減少に データのソートを使用します ray hitsをmaterial typeで ソートすることで実行します thread分散の減少に最適ですが spatial memoryの分散が増加してしまい MMU limiterが高くなってしまいます これに対応するため データの局所性を増やすため ソート前にmemory rangeの分割化を試みました 見てみましょう 光線をシミュレートするため raysをシーンに放つと 物に当たり そのデータが buffersに集めらせます 交差地点でいろんなことがわかります ガラスや金属など光が当たった物のタイプや 当たった場所などの情報です ここでは物のタイプだけに焦点を当てましょう bufferにある物のタイプです
光線ごとにデータが集められるため memory bufferは非常に大きくなります 大量のメモリの移動を避けるため インデックスリストを作りそれをソートします ソート後 同じタイプの物のインデックスが 集められました SIMD-groupsがそれらを ロードし 物質を処理します SIMD-groupはインデックスでoriginal bufferに データを取り込みます
しかしSIMD-groupはメモリ全体を読むため MMUに圧力がかかります 新しい方法を調べてみましょう memory rangeは理想的に分割され 他のパーティションからの インデックスが混ざりません ソートするとデータアクセスが パーティション内のみであるのがわかります これはthreadとmemoryの 分散間におけるバランスです パーティションの数とサイズは 作業負荷次第です どちらが最適化は試してみねばなりません 別のmetal system traceで例を見てみましょう これは最適化された limitersとutilizationsです TOP performanceもlast level cacheも下がりました その結果bandwidthとshader runtimeが向上しました どのくらいでしょう? Top limiterとLLC limiterは20%削減しました データフローの効率が上がったのです GPU Read bandwidthもかなり向上し GPU coresにさらにデータを送れます
全体的に この実験でメモリ局所性を増加し 性能を10〜30%向上させることができました これは性能を向上させる方法のごく一つです いろいろ試し最適化を試みてください GPU toolsには便利なcountersがあります
Xcodeには新しいtheoretical occupancyがあります XcodeとInstrumentsのMMU関連のものには MMU LimiterやMMU Utilization Counter MMU TLB Miss Rate Counterがあります
今日はたくさんカバーしました GPUスケーラビリティとネックについてと それらの問題を解決する ツールについて話しました また いろいろ試して最高の結果を得るためには 何かを引き換えにする 必要があることも話しました Apple Siliconでみなさんの Appがスケールすることを 楽しみにしています ありがとうございました
-