-
Core ML Toolsを使った機械学習モデルの圧縮法
Core ML Toolsを使って、アプリ内の機械学習モデルのフットプリントを削減する方法を紹介します。パレット化、プルーニング(刈り込み)、量子化などのテクニックを使用して、モデルのサイズを劇的に圧縮しつつ、優れた精度を実現する方法を紹介します。トレーニング段階での圧縮と、完全にトレーニングされたモデルでの圧縮を比較し、Apple Neural Engineを最大限に活用することで、圧縮されたモデルをさらに高速に実行する方法を学びます。Core MLの最適化については、WWDC23の「Improve Core ML integration with async prediction」をご覧ください。
リソース
関連ビデオ
WWDC20
-
このビデオを検索
♪ ♪
こんにちは Pulkitです Core MLチームのエンジニアです Core ML Toolsにいくつかの アップデートが加えられました このアップデートは 機械学習モデルのサイズと パフォーマンスの最適化に寄与します モデルの機能が大幅に向上し 機械学習によって動作する 機能がますます増えています その結果 1つのアプリにデプロイされる モデルの数が増加しています それに伴い アプリ内の 各モデルも大きくなり アプリサイズの肥大化を招いています そのため モデルのサイズを 確認することが重要です モデルサイズを小さくすることには 複数の利点があります 各モデルが小さければ 同じメモリBudgetで より多くのモデルを配布できます また より大きく高性能な モデルの配布も可能になります また モデルの実行速度も速くなります これは モデルが小さくなると メモリとプロセッサ間を 移動するデータ量が減少するからです モデルのサイズを小さくすることは 素晴らしいアイデアに思えます 何がモデルを大きくさせるのでしょう? 理解を助けるため 例を挙げて説明します ResNet50は人気の画像分類モデルです その最初の層となる畳み込み層は 約9千のパラメータを持っています そして 全部で53の畳み込み層があり その大きさは様々です 最後に 約210万の パラメータを持つ線形層があります パラメータ数は全部で2500万になり Float16の精度でモデルを保存すると 重みごとに2バイトを使用し モデルのサイズは50メガバイトになります 50メガバイトのモデルは大きいですが Stable Diffusionのような 新しいモデルは さらにサイズが大きくなります では より小さなモデルを得るための 方法についてお話します 1つの方法は より少なく小さな重みで優れた パフォーマンスを達成できる 効率的な モデルアーキテクチャを設計することです もう1つの方法は 既存モデルの 重みを圧縮することです このモデル圧縮の方法に 焦点を当てたいと思います 始めに モデル圧縮に役立つ 3つのテクニックを説明します 次に これらのモデル圧縮テクニックを 統合した 2つのワークフローを デモンストレーションします そして これらのテクニックと ワークフローをモデルに適用する際 最新のCore ML Toolsが どのように役立つかを説明します 最後にSrijanが モデル圧縮が 実行時のパフォーマンスに 与える影響についてお話します では 圧縮のテクニックについて説明します モデルの重みを圧縮する方法は複数あります 1つ目の方法は 疎な行列表現を用いて より効率的に詰め込むことです これはpruningと呼ばれるテクニックを 使うことで実現できます もう1つの方法は 重みを保存する際の 精度を下げることです これは 量子化またはパレット化と 呼ばれる手法で達成できます どちらの戦略も非可逆的であり 圧縮されたモデルの精度は 非圧縮のモデルに 比べると若干劣ります
では 各テクニックを 詳しく見ていきましょう
重みのpruningは モデルの重みを疎な表現で 効率的に詰め込む上で役立ちます 重み行列のスパース化(pruning)とは 重み値のいくつかを 0に設定することを意味します ここに重み行列があります これを刈り込むために 最も小さい重みを0にします
これで 非ゼロの値だけを 保存すればよくなります 最終的に ゼロが増えるごとに 約2バイトのストレージを節約できます もちろん 後で密行列を再構成するために ゼロの位置を保存する必要はあります モデルサイズは pruningのレベルに応じて 直線的に小さくなります 50%のスパースモデルとは 50%の重みがゼロであることを意味し ResNet50モデルの場合 およそ28メガバイトのサイズとなり Float16の約半分のサイズになります
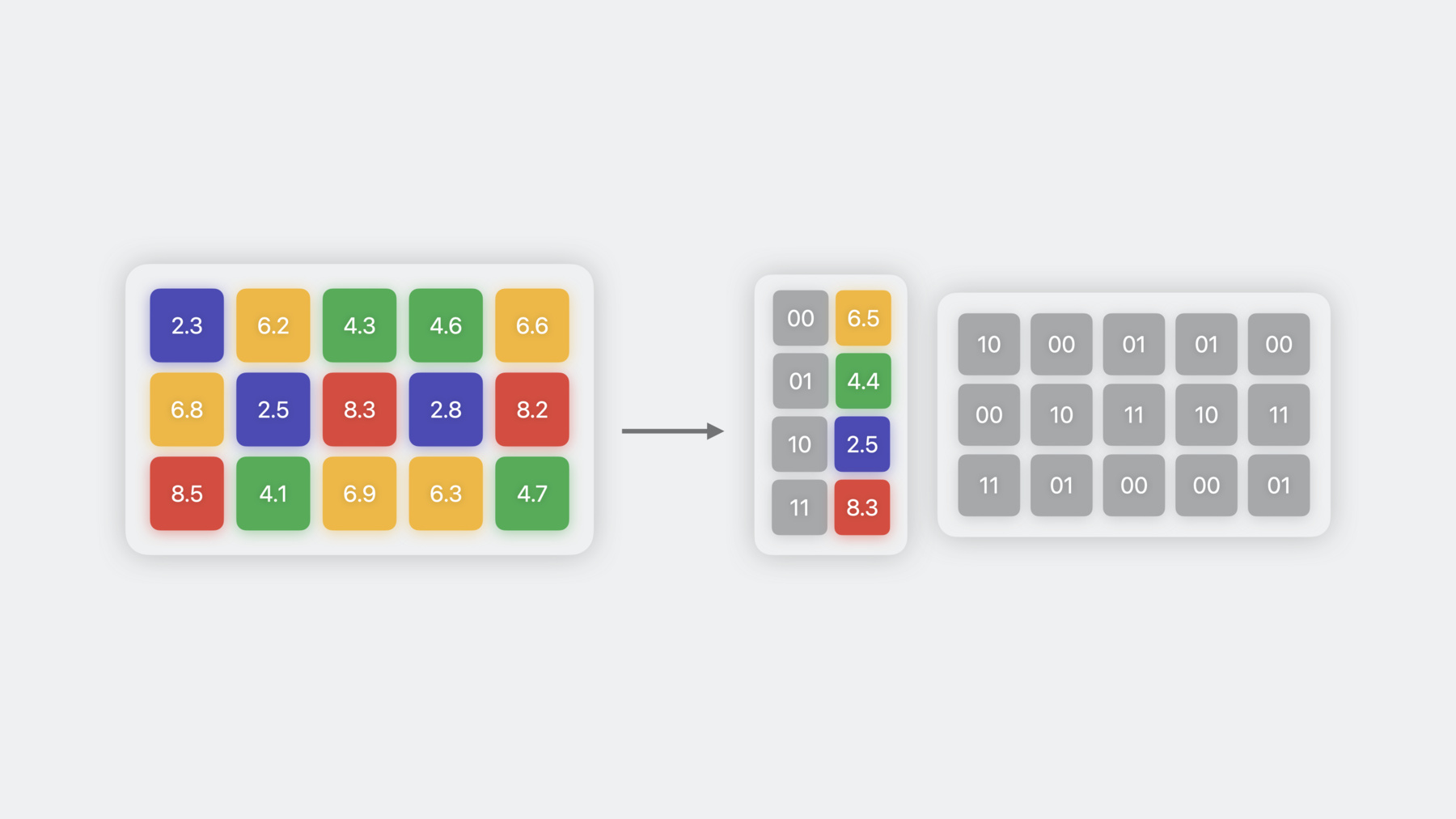
2つ目の重み圧縮技術は量子化で 8ビットの精度で重みを保存します 量子化を行うには 重み値を取得し INT8の範囲に収まるように スケール シフト 丸め処理を行います この例では スケールを2.35とし 最小値を-127 バイアスを0にしています モデルによっては 0以外のバイアスも使用され 量子化誤差の低減に役立つ場合があります スケールとバイアスは 逆量子化の際に 重みを元の範囲に戻すために使用されます 重みの精度を8ビット以下にするために 重みのクラスタリング またはパレット化と 呼ばれる技術を使うことができます この手法では 似たような値を持つ 重みはグループ化され それらが属するクラスタの 重心値を用いて表現します この重心値はルックアップテーブルに 保存されます そして元の重み行列は 各要素に対応する クラスタ重心を指す インデックステーブルに変換されます この例では 4つのクラスタがあるので 各重みを2ビットで表すことができ Float16に比べ 8倍の圧縮率を達成しています 重みを表現するために使用する ユニークなクラスタ重心の数は 2のn乗に等しく ここでのnは パレット化の精度を示しています つまり 4ビットのパレット化は 16のクラスタを持てることを意味します 量子化によってモデルサイズが 半分になるのに対し パレット化では最大8倍まで 小さくすることができます
まとめると 重み圧縮には 3つの異なる手法があります それぞれが異なる方法で 重みを表現しています 圧縮のレベルは様々で pruningのスパース性や パレット化のビット数など それぞれのパラメータで コントロールできます では、これらの手法を モデル開発のワークフローに 組み込む方法について説明します まず Core ML用にモデルを変換する ワークフローからお話します お好きなPythonトレーニング フレームワークでモデルをトレーニングさせ Core ML Toolsを使ってそのモデルを 変換すると想定します このワークフローをさらに一歩進めて トレーニング後に圧縮を行うことができます そのためには 全体のサイズを 小さくするために すでにトレーニング・変換されたモデルの 重みを操作する圧縮ステップを追加します このワークフローは どの時点から始めることも可能です たとえば トレーニングデータを 必要としない トレーニング済みモデルや 変換済みの Core MLモデルから始めることもできます
このワークフローを適用する際 圧縮量を 選択するオプションがあります 圧縮率が高くなるほど 出来上がるモデルは小さくなります ご想像の通り その代償もあります 具体的には 一定の精度を確保できる 非圧縮モデルから始めます 圧縮をかけると サイズは縮みますが 精度に影響が出る恐れがあります より高い圧縮をかけると この影響が高まり 許容できない 精度の低下が発生する可能性があります
この傾向と許容できるトレードオフは ユースケースごとに異なり モデルやデータセットに依存します 実際のトレードオフを見るために 画像中のオブジェクトを セグメント分けするモデルを見てみましょう この画像において モデルは 各ピクセルがソファに属する確率を返します 基準となるFloat16モデルは オブジェクトを うまくセグメント分けしています 10%のpruning済みモデルの出力は 基準モデルと非常に似ています 30%のpruningから アーティファクトが現れ始め レベルが上がるにつれて増加します 40%のpruningを行うと モデルは完全に崩壊し 確率マップは認識不能となります 同様に 8ビットの量子化と 6ビットのパレット化は 基準モデルの出力を維持します 4ビットのパレット化では 複数のアーチファクトが見え始め 2ビットのパレット化では オブジェクトを 全くセグメント分けできなくなります 高圧縮率におけるモデルパフォーマンスの 劣化を克服するには 異なるワークフローが必要です このワークフローは トレーニング時圧縮と呼ばれます ここでは 重みを圧縮しながら 一部のデータでモデルを 微調整します 圧縮は徐々に微分可能な方法で導入され 重みに課した 新たな制約に対して 再調整できるようにします モデルが十分な精度を達成したら それを変換し 圧縮Core MLモデルにします トレーニング時 圧縮は 既存のモデルトレーニング ワークフローに組み込むか 事前トレーニング済みのモデルから始めます トレーニング時圧縮により モデルの精度と 圧縮量のトレードオフが改善され 高い圧縮量でも 同じモデルパフォーマンスを 維持することが可能です 同じ画像セグメント分け モデルを見てみましょう トレーニング時のpruningでは モデル出力は40%のスパース性まで 変化しません トレーニング後に圧縮したモデルは ここで崩壊しました 実際は50%や75%のpruningを行っても モデルは基本モデルと 同様の精度を達成しています 90%のpruningを行うと モデルの精度が著しく低下し始めます 同様に量子化やパレット化時の圧縮でも 基本モデルと同等の出力を維持し この場合は2ビットの圧縮まで可能です まとめると重み圧縮は モデル変換時かモデルトレーニング時の いずれかで行います 後者の方が トレーニング時間が 長くなる代わりにに 精度が良くなります 2つ目のワークフローは トレーニング中に圧縮を行うため 圧縮アルゴリズムを実装するために 微分可能な演算を行う必要があります では これらの圧縮ワークフローを Core ML Toolsで 実行する方法を見てみましょう ポストトレーニングモデル圧縮APIは Core ML Tools 6の 圧縮ユーティリティサブモジュールで pruningパレット化 量子化を行えました しかし トレーニング時 圧縮用のAPIはありませんでした Core ML Tools 7では 新しいAPIが追加され トレーニング時の圧縮機能も 提供するようになりました そして 新旧のAPIを coremltools.optimizeという 単一のモジュールに統合しました ポストトレーニング圧縮APIは coremltools.optimize.coremlに移行し 新しいトレーニング時APIは coremltools.optimize.torchで 利用可能です 後者はPyTorchモデルで動作します まず ポストトレーニングAPIを 詳しく見てみましょう ポストトレーニング圧縮ワークフローでは 入力はCore MLモデルです optimize.coremlモジュールで利用可能な 3つの方法でアップデート可能で これまでに説明した 3つの圧縮手法を適用します これらの手法を使うには まず OptimizationConfig オブジェクトを作成し モデルの圧縮方法を記述します ここでは75%の目標スパース性で マグニチュードプルーニングを行います 設定を定義したら prune_weightsメソッドを使って モデルをpruningします 簡単かつワンステップで 圧縮モデルを得られるプロセスです 各手法に特化した設定を使用して 同様のAPIを 重みのパレット化と量子化に使用できます トレーニング時の 圧縮ワークフローを考えてみましょう この場合 先ほど説明した通り トレーニング 可能なモデルとデータが必要です より具体的に言うと Core ML Toolsで モデルを圧縮するには 重みをトレーニング済みの PyTorchモデルから始めます 次に optimize.torchモジュールで 利用可能なAPIのいずれかを使い更新し 圧縮レイヤーを挿入した 新しいPyTorchモデルを取得します そして データと元のPyTorchトレーニング コードを使用して 微調整します この段階で重みを 圧縮できるように調整します これは MPS PyTorchバックエンドを使い MacBookローカルで行えます モデルをトレーニングして 精度が回復したら Core MLモデルに変換します サンプルコードを通して 詳しく見てみましょう 圧縮したいモデルを微調整するために 必要なPyTorchのコードから始めます 数行のコードを追加するだけで 簡単にCore ML Toolsを活用して 学習時のpruningを追加できます まずモデルのpruning方を記述した MagnitudePrunerConfig オブジェクトを作成します ここでは目標のスパース性を 75%に設定します 設定をyamlファイルに記述して from_yamlメソッドで 読み込むこともできます 次に 圧縮したいモデルと 先ほど作成した設定で prunerオブジェクトを作成します 次に モデルに pruningレイヤーを挿入します モデルを微調整しながら ステップAPIを呼び出し prunerの内部ステートを更新します トレーニングの最後に finalizeを呼び出して pruningマスクを重みに畳み込みます このモデルは 変換APIを使って Core MLに変換できます 量子化とパレット化にも 同じワークフローが使えます では SrijanがCore ML Tools APIを使って 物体検出モデルを パレット化するデモをお見せします ありがとう Pulkit 私の名前はSrijanです 今からCore ML Tools optimize APIのデモをお見せします ResNet18をバックボーンに持つ SSDモデルを使って 画像中の人物を検出します まず 基本的なモデルと トレーニング ユーティリティをインポートします 先程の SSD ResNet18モデルの インスタンスを取得するところから始めます 作業を簡略化するために あらかじめ書かれた get_ssd_model ユーティリティを呼び出します モデルが読み込まれたので 数エポックトレーニングします これは物体検出モデルなので トレーニングの目標は 検出タスクのSSDロスを減らすことです 簡略化するために train_epochユーティリティは 異なるパッチを通して forwardを呼び出したり ロスを計算したり 勾配を降下させたりする モデルトレーニングのエポックに 必要なコードをカプセル化してあります トレーニング中 SSDのロスは 減少しているようです このモデルを Core MLモデルに変換します そのために まずモデルをトレースして coremltools.convert APIを呼び出します インポートユーティリティを呼び出して モデルのサイズを確認します
モデルのサイズは23.6メガバイトです では Core MLモデルで 予測を実行してみます ロンドンを旅行中の自分の画像と 検出テストに使う別の画像を選びます 物体検出モデルの信頼度のしきい値は 30%に設定されているので 少なくとも30%の信頼度で 物体が存在すると確信できる ボックスが描画されます
正確に検出されています では モデルのサイズを 小さくできるか調べたい思います まずは ポストトレーニング パレット化を試してみます そのために いくつかのconfigクラスと メソッドをcoremltools.optimize .coremlから呼び出します
では モデルの重みを 6ビットでパレット化してみます OpPalettizerConfig オブジェクトを作成し modeにkmeans nbitsに6を指定します これでopレベルでパラメータを設定し opごとに異なるパレット化ができます ですが 今はすべてのopに 同じ6ビットモードを適用します そのためには OptimizationConfigを定義して このop_configを グローバルパラメータとして渡します
この最適化設定は変換された モデルとともに palettize_weightsメソッドに渡され パレット化されたモデルが得られます サイズがどれくらい 小さくなったか見てみます
モデルのサイズは 約9メガバイトまで小さくなりましたが テスト画像でのパフォーマンスに 影響はあるでしょうか? 調べてみましょう 検出はまだうまく行っています さらに圧縮すべく ポストトレーニングモデルを 2ビットでパレット化してみましょう OpPalettizerConfigを6から2に変更し palettize_weights APIを 再度実行するだけなので簡単です
ユーティリティを使って Core MLモデルの サイズとパフォーマンスを見てみましょう
予想通り モデルのサイズは小さくなり 約3メガバイトになりました しかし モデルはどちらの画像でも 人物を検出できず パフォーマンスは不十分です モデルが予測したボックスは 30%のしきい値を超える信頼度が得られず 表示されていません トレーニング時パレット化を2ビットで試し パフォーマンスが 向上するか見てみましょう
まず coremltools.optimize.torchから DKMPalettizerConfigと DKMPalettizerをインポートします DKMはattentionに基づく 微分可能なkmeans演算を行うことで 重みクラスタを学習するアルゴリズムです では パレット化の設定を定義しましょう global_configでnビットを 2と指定するだけで サポートされているすべてのモジュールが 2ビットでパレット化されます そして ここでmodelとconfigから palettizerオブジェクトを作成します prepare APIを呼び出すと パレット化に適したモジュールが モデルに挿入されます モデルを数エポック微調整しましょう モデルが微調整されたので finalize APIを呼び出して パレット化された重みを モデルの重みとして復元し 処理を完了させます 次のステップは モデルサイズの確認です そのために torchモデルを Core MLモデルに変換します まず torch.jit.traceを使って モデルのトレースから始めます そしてconvert APIを呼び出し 今度は PassPipelineという追加フラグを使い その値を DEFAULT_PALETTIZATIONに設定します これでコンバーターに 変換された重みに パレット化された表現を 使うように指示できます
モデルのサイズと テスト画像での パフォーマンスを見てみましょう トレーニング時にパレット化したモデルも 約3メガバイトで 圧縮率は8倍になりましたが ポストトレーニングパレット化モデルと違い このモデルはテスト画像を 正しく検出しています これはデモなので 2つのサンプル画像だけで モデルのパフォーマンスをテストしています 実際のシナリオでは mean Average Precisionのような 指標を使用して 検証用データセットで 評価することになるでしょう
おさらいです 学習済みモデルから始めて Float16の重みを持つ 23.6メガバイトの モデルに変換しました その後 palettize_weights APIを使って 6ビットの重みを持つ より小さなモデルを作成し テスト結果は良好でした しかし 2ビットで圧縮すると パフォーマンスの低下は明らかでした そこで optimize.torch APIを使って torchモデルを更新し 微分可能なkmeansアルゴリズムを使って 数エポックの間 微調整を行いました その結果 2ビットの圧縮オプションでも 十分な精度を得ることができました デモでは特定のモデルと最適化 アルゴリズムの組み合わせを採用しましたが このワークフローは 皆さんのユースケースにも適用でき 希望する圧縮量と モデルの再トレーニングに 必要な時間とデータの トレードオフを見極めるのに役立つでしょう そこで最後のトピック パフォーマンスについて説明します このようなモデルをアプリにデプロイする際 より効率的に実行するために Core MLランタイムに加えられた 改良について簡単にお話します iOS 16とiOS 17の ランタイムの主な違いをいくつか紹介します iOS 16では重さのみ圧縮された モデルがサポート対象でしたが iOS 17では8ビットアクティベーション 量子化モデルも実行可能です iOS 16では 重み圧縮モデルは Floatの重みを持つ対応モデルと 同じ速度で実行できます iOS 17では Core ML ランタイムが更新され 特定のシナリオでは より高速に圧縮モデルを実行できます 同様のランタイムの改善は macOS tvOS watchOSの 新しいバージョンでも利用可能です これらの改良点はどのように 実現されたのでしょうか? 重みだけが圧縮されるモデルでは アクティベーションは 浮動小数点の精度であるため 畳み込みや行列の乗算などの 演算を行う前に 重み値を他の入力の精度に合うように 解凍する必要があります この解凍のステップは iOS 16ランタイムで 前もって行われます 従って この場合 モデルは実行前に メモリ内で完全に浮動小数点の 精度のモデルに変換されます 従って 推論の待ち時間に 変化は見られません しかし iOS 17では 特定のシナリオにおいて 演算が実行される直前に重みが解凍されます これには 推論呼び出しのたびに 解凍を行う代償として より小さなビットの重みを メモリから読み出せる利点があります Neural Engineのような 特定の演算ユニットや メモリに制約のある 特定のタイプのモデルでは これは推論の高速化につながります このようなランタイムの利点を説明するため いくつかのモデルを選んで プロファイリングし Float16の バリアントと比較した推論の 相対的な速度をグラフ化しました 予想通り 高速化の度合いは モデルやハードウェアに依存します これはiPhone 14 Pro Maxにおける 4ビットパレット化モデルの 高速化の度合いです 改善率は5%から30%の間です pruningモデルの場合も モデルの種類によって改善度は異なり 一部ではFloat16より75%高速な モデルもあります ここで疑問が生じます 最高のレイテンシ性能を得るには どのような戦略が有効でしょうか? 答えは Floatモデルから始めて optimize.coreml APIを使い モデルの様々な表現を試すことです これならばモデルの 再トレーニングが必要ないので すぐに出来ます そして 好みのデバイスで プロファイリングします XcodeのCore MLパフォーマンスレポートが どこでオペレーションが実行されたかを含め 推論に関する多くの情報を提供してくれます 次に どの構成が 最も良い結果をもたらすかを考慮し 候補を絞り込みます その後 精度を評価し 改善に集中します これにはモデルを最終決定する前に torchとCore ML Toolsで トレーニング時圧縮が必要かもしれません
まとめると モデルサイズの縮小は 重要であり 新しいCore ML Tools APIを使うことで これまで以上に簡単に圧縮を行い より少ないメモリ消費量と 推論の高速化を達成できます より多くのオプションや ベンチマークデータについては ドキュメントをご覧ください また“Improve Core ML integration with async prediction”の 動画では 今日のスライドで 取り上げなかった Core MLフレームワークの 改善点についても話しています ぜひご視聴ください ありがとうございました 圧縮を楽しみましょう
-