-
Metalアプリにおける機械学習の最適化
Metalにおける、高速なMLトレーニング方法に関する最新の機能強化について解説します。PyTorchとTensorFlowのアップデート情報、JAXのMetalアクセラレーションについて紹介します。GPUとApple Neural Engineの両方を使用する際に、MPG GraphがML推論を高速化をサポートする仕組みについてや、同じAPIを使用してCore MLとONNXモデルを迅速に統合する方法について解説します。Metalを使った機械学習の詳細については、WWDC22の「Accelerate machine learning with Metal」をご覧ください。
リソース
関連ビデオ
WWDC22
-
このビデオを検索
♪ ♪
こんにちは Denis Vieriuです AppleのGPU グラフィックスディスプレイ ソフトウェアグループのエンジニアです 本日は Metalに今年導入された 機械学習の新機能と 改善点を皆さんに紹介します まず 既存の機械学習バックエンドについて 簡単にまとめます Metalの機械学習APIは Metal Performance Shaders(MPS)を 介して公開されています MPSは 画像処理 線形代数 機械学習など 様々な分野における 高性能なGPUプリミティブを まとめたものです MPSGraphは汎用の計算グラフで MPSフレームワークの上位に位置し 多次元tensorsのサポートを拡張します CoreMLなどの 機械学習推論フレームワークは MPSGraphバックエンド上に構築されています MPSGraphは TensorFlowやPyTorchなどの トレーニングフレームワークも サポートしています MPSGraphや ML Frameworksについての詳細は こちらの過去のWWDC動画を ご覧ください
今回のセッションは PyTorchと TensorFlowのMetalバックエンドに 追加されたアップデートと改善点 JAXの新しいGPUアクセラレーション MPSGraphに今年追加された ML Inferenceの機能に焦点を当てています
PyTorchとTensorFlowの Metalアクセラレーションを使用すると Mac上で最高のパフォーマンスを得るために MPSの高効率なカーネルを利用できます PyTorch Metalアクセラレーションは MPSバックエンドを介して バージョン1.12から利用可能です これは昨年PyTorchエコシステムに導入され それ以来 メモリ使用量やビューテンソルの 最適化に関する複数の改善が行われています 今年 PyTorch 2.0 MPS Backendは 大きく進化し ベータステージに到達しました しかし 改善点はこれだけではありません 最新のPyTorchビルドには MPS操作のプロファイリング カスタムカーネル 自動混合精度の サポートなど 多くの新しいアップデートが含まれています すべてのナイトリービルドの 機能について説明する前に PyTorch 2.0の新機能から説明します
PyTorch 2.0では grid samplerやtriangle solve topkなどを含む Torchで最もよく使われる 上位60の演算がサポートされています
テストカバレッジも大幅に向上しました ほとんどのTorch Operatorのための gradientテスト ModuleInfoに基づくテストが 含まれています
リリース以降 MPSを 公式バックエンドとして採用した 多くの人気モデルによって ネットワークのカバレッジが拡大しています この中には WhisperAIなどの基本モデル YOLOなどの物体検出モデル StableDiffusionモデルなどが含まれています 最新のPyTorch 2.0を使って これらのモデルを1つ確認してみましょう この例では 物体検出ネットワークの YoloV5をM2 Max上で実行しています 左側には PyTorch MPS バックエンドを使用して ライブ画像を生成する ネットワークを実行しており 右側では同じモデルを CPU上で実行しています 左のMPSバックエンドを使用している方が 明らかに高フレームレートで動作しています
さらに デベロッパたちは 外部ネットワークに PyTorch MPSバックエンドを 採用しただけでなく ヒストグラム group_norm signbitなど 複数の新しいOperator向けの コードにも貢献しています
次に 最新のPyTorchビルドで 利用可能な新機能について説明します まず MPS操作の プロファイリングのサポートです PyTorchのナイトリービルドでは OSのサインポストを使用して 操作の実行時間 CPUとGPU間のコピー サポートされていないOperatorによる CPUへのフォールバックの実行時間を 正確に表示する プロファイリングサポートが 提供されています プロファイリングデータは Instrumentsの 一部である Metal System Traceという 非常になじみのあるツールで 視覚化することができます Metal System Traceを使った MLアプリケーションの プロファイリングについては 昨年のセッション 「Accelerate machine learning with Metal」をご覧ください プロファイラの使用方法は 非常に簡単です MPSプロファイラパッケージのstart メソッドを呼び出してトレースを有効にし スクリプトの最後でstopメソッドを使用して プロファイリングを終了します では プロファイラを使った デバッグの例をお見せします このサンプルネットワークは 合計7つのレイヤーからなる 線形変換とSoftshrink アクティベーション関数で構成された Sequentialモデルを使用しています 現在のモデルのパフォーマンスは 満足できるものではありません この場合 プロファイラを使って ボトルネックを探すことができます
まず os_signpostが有効なことを Metal System Traceで確認します これで PyTorchのOperator情報を キャプチャすることができます 次に デバイスと正しい実行ファイルが 設定されていることを確認します この場合は Pythonバイナリです 次に Recordボタンをクリックします Instrumentsが PyTorchの実行を記録しています 十分なデータをキャプチャするため 数秒間実行します その後 Stopをクリックします
os_signpostタブで PyTorch Intervals タイムラインを表示します このタイムラインでは Operatorの実行時間と共に 文字列の識別子 データ型 コピーの長さなどの PyTorchメタデータも表示されます
タイムラインを拡大すると この例で使用した PyTorchOperatorが分かります このトレースから 7つのレイヤーで構成される カスタムSequentialモデルの パターンが簡単に識別できます
トレースで明らかなように ボトルネックは SoftshrinkのCPUへの フォールバックにあります この処理は非常に効率が悪いです SoftshrinkOperatorのCPUによる実行と 追加のコピーによるオーバーヘッドが発生し GPUが十分に活用されていません GPUタイムラインのほとんどのギャップは Softshrinkアクティベーション関数がCPUに フォールバックすることに起因しています これを修正するために パフォーマンスを 改善するカスタムカーネルを作成します カスタムオペレーションの作成には 4つのステップがあります まず Objective-CとMetalで オペレーションを実装します 次に Objective-Cコードのための Pythonバインディングを作成し 拡張機能をコンパイルします 最後に 拡張機能がビルドされたら トレーニングスクリプトにオペレーションを インポートして使用を開始します まず オペレーションの実装です
Torchの拡張ヘッダの インポートから始めます これにはC++拡張機能の作成に必要な PyTorchの機能がすべて含まれています
次に compute関数を定義し MPSバックエンドAPIの get_command_bufferを使って MPSStream Command Bufferへの 参照を取得します 同様に get_dispatch_queue APIを使用して シリアルキューへの参照を取得します 次にコマンドバッファを使用してエンコーダ を作成し カスタムGPUカーネルを定義します
複数のスレッドからのサブミッションが シリアライズされるように ディスパッチキュー内で カーネルをエンコードします
全ての作業がエンコードされたら synchronize APIを使って 現在のコマンドバッファの 実行が完了するまで待機し サブミッションが シリアライズされたことを確認します シリアライズが不要な場合は commit APIを使います 次に カスタム関数をバインドします PYBIND11を使用して Objective-Cの関数を Pythonに非常に簡単な方法で バインドできます この拡張機能ではバインドに 必要なコードはわずか2行です
バインディングが終わったら 拡張機能をコンパイルします 始めに torch.utils.cpp_extensionを インポートします これにより 拡張機能のコンパイルに 必要なload関数が用意されます 次に ビルドする拡張機能の名前と ソースコードファイルへの 相対パスまたは絶対パス一覧を渡します オプションで ビルド時に転送する コンパイラフラグを指定することもできます load関数はソースファイルを 共有ライブラリにコンパイルし それが後にPythonプロセスに モジュールとしてロードされます
最後にOperatorをスクリプトに インポートして使用を開始します
まず コンパイルされたライブラリを インポートし 先程のSequentialモデルを カスタムSoftshrinkカーネルを 使用するように変更します
同じモデルを再度実行して 結果を確認しましょう 新しく追加されたカスタムOperatorにより モデルの実行効率は格段に向上しました
CPUへのフォールバックによって 生成されていた すべてのコピーと中間テンソルが無くなり Sequentialモデルの実行が高速化されました では ネットワークを さらに改善する方法を探ってみましょう
PyTorch MPSバックエンドは 自動混合精度をサポートするようになり より少ないメモリで 品質を損なうことなく より高速なトレーニングが可能です 混合精度を理解するために まずサポートされている データ型を確認しましょう 混合精度トレーニングとは 単精度浮動小数点と 半精度浮動小数点を組み合わせて 深層学習モデルを トレーニングするためのモードです macOS Sonomaから MPS Graphは新しいデータ型である bfloat16をサポートしています bfloat16は 深層学習用の 16ビット浮動小数点形式です bfloat16は 1つの符号ビット 8つの指数ビット 7つの仮数ビットで構成されています これは 深層学習アプリケーションを 考慮して設計されていない 標準のIEEE 16ビット浮動小数点 形式とは異なります 自動混合精度は float16とbfloat16の 両方に対して有効になります 自動混合精度は ネットワークのパフォーマンスを デフォルトの精度で測定し その後 各レイヤーごとに適切な精度を選択し 混合精度設定で再度実行することで 精度に影響を与えることなく パフォーマンスを最適化できます ニューラルネットワークの一部の層は 畳み込み層や線形層のように 低い精度で実行することが可能です 一方で 集約などの他の層は しばしば高い精度レベルを必要とします
ネットワークに自動混合精度のサポートを 追加するのは非常に簡単です まず autocastを追加します float16とbfloat16の 両方がサポートされています autocastは コンテキストマネージャとして 機能し スクリプトの一部を 混合精度で実行することができます
この領域では MPSオペレーションは autocastによって選択された データ型で実行され パフォーマンスを 向上させつつ 精度を維持します
MPSバックエンドも大幅に最適化されました PyTorch 2.0とmacOS Sonomaでは MPSバックエンドは以前のリリースに比べて 最大5倍高速化されています PyTorchについては以上です 次は TensorFlowの話題です TensorFlow Metalバックエンドは 安定した 1.0リリースバージョンまで成熟しました このリリースでは grappler リマッピングオプティマイザパスが プラグインに追加されました Metalプラグインに 混合精度のサポートも追加され インストール手順も 以前よりシンプルになりました
TensorFlow Metalバックエンドの パフォーマンスは 認識された演算パターンの 自動フュージョン追加により改善されました これには 融合された畳み込みと行列の乗算 オプティマイザの操作 RNNセルなどが含まれます この最適化は 計算グラフの作成時に grapplerパスを介して自動的に行われます
ここでは 2次元の畳み込み演算の 一般的な計算例を紹介します 畳み込みの後には 加算関数が続くことが多く これは畳み込みニューラルネットワークで よく見られるパターンです このパターンを認識することで grapplerパスは 計算を再マッピングできます
これにより より最適化されたカーネルを 使用して同じ出力を得ることができ パフォーマンスの向上につながります PyTorchと同様に TensorFlowも 混合精度をサポートしています TensorFlowでは 混合精度を グローバルに設定できます これにより ネットワークのすべての層が 要求されたデータ型ポリシーで 自動的に作成されるため 標準的なワークフローでは 既存のコードに最小限の変更を加えるだけで この変更を有効にできます
グローバルポリシーは Float16または Bfloat16のいずれかを使うよう設定できます
パフォーマンスの向上に加えて Metalアクセラレーションを有効にする際の ユーザー体験も改善されました 今後は 通常の手順に従って TensorFlowホイールと TensorFlow-Metalプラグインを パッケージマネージャを介して インストールするだけで Metalアクセラレーションが有効になります TensorFlow開発の最先端を求める方向けに Metalアクセラレーションのサポートが TensorFlowのナイトリーリリースでも 利用可能です では JAXの新しいGPU アクセラレーションについてお話します 今年から JAX GPUアクセラレーションは PyTorchや TensorFlowと同様に Metalバックエンドを 介してサポートされます JAXは 高性能な数値演算と 機械学習研究を行うための Pythonライブラリです JAXは 大規模な配列を扱うために 人気のNumPyフレームワークをベースに 機械学習の研究に特化した 3つの主要な拡張機能を備えています
第一に grad関数を使った 自動微分をサポートしています これにより Pythonの多くの機能を通じて 微分を行うことができ 高階微分も可能です また JAXは高速かつ効率的な ベクトル化もサポートしています apply_matrix関数が与えられると Pythonでバッチ次元を ループ処理することもできますが 最適なパフォーマンスで 実行できない可能性があります この場合 vmapを使用することで バッチ処理のサポートを自動で追加できます さらに JAXでは jitと呼ばれるAPIを使用して 関数を最適化されたカーネルに ジャストインタイムでコンパイルできます 同様に vmap上でjitを使用して 関数を変換することで より高速な実行が可能になります
M2 Maxを搭載したMacBook Proでは JAX Metalアクセラレーションにより ネットワーク全体で CPUの平均10倍という 驚異的な高速化が実現されます JAXの環境設定や インストールの詳細については Metal Developer Resources Webページをご覧ください
ML推論の話に移ります まず ロード時間の最適化に使用する MPS Graphの新しい シリアライズ形式について紹介します この新しい シリアライズ形式は 他のフレームワークで シリアライズされた 既存のネットワークから生成できます 最後に 8ビット整数の量子化を活用して ネットワークのメモリフットプリントを 最適化する方法を紹介します では始めましょう MPSGraphは 高レベルのAPIを使用して レイヤーごとに 柔軟な作成が可能です 詳しくは Metal Performance Shaders Graphでカスタマイズした カスタムMLモデルを 構築する動画をご覧ください カスタムグラフを定義し コンパイルした後 MPSGraphExecutableを介して実行し 結果を取得します 通常 このプロセスはうまく機能します ただし 多くのレイヤーを持つ 複雑なグラフでは 初期のコンパイルにより アプリの起動時間が長くなる場合があります
この問題に対処するために MPSGraphには MPSGraphPackageという 新しいシリアライズ形式があります この新しいシリアライズ形式では 事前にMPSGraphExecutableを作成できます 一度作成すれば 最適化された MPSGraphExecutableを MPSGraphPackageファイルから 直接ロードすることができます MPSGraphPackageの作成方法は 非常に簡単です
シリアライズdescriptorを作成し シリアライズしましょう MPSGraphExecutableの serialize関数に渡すだけです また 保存先のパスも 指定する必要があります パッケージを作成したら このようにグラフをアプリにロードします コンパイルdescriptorと保存した パッケージのパスが必要です それらを使用して MPSGraphExecutableを初期化します すでにMPSGraphを使用している場合は 解説したAPIを使用して 新しい シリアライズ形式に簡単に移行できます しかし 他のフレームワークから 移行する場合は 新しいMPSGraphToolを使って簡単に MPSGraphPackageに移行することができます CoreMLをお使いの方は MLプログラムを MPSGraphToolに渡すことで MPSGraphPackageが作成されます 同様に ONNXの場合も ONNXファイルを入力として 使うことができます この新しいツールを使うと 推論モデルを 手動でエンコードする必要が無く 既存のモデルを 素早くMPSGraphアプリに組み込めます こちらがコマンドラインツールの 使用方法です MPSGraphToolには 入力モデルのタイプを 宣言するフラグを指定します この場合 CoreML Packageです また 出力先のパスと出力モデルの 名前も指定します さらに ターゲットプラットフォームと 最小OSバージョンを定義します 変換後 生成されたMPSGraphPackageは アプリにロードして直接実行できます 次に 8ビット整数量子化を使用して 演算効率を向上させる方法について 説明します 一般的に トレーニングや推論には 16ビット浮動小数点のような 浮動小数点形式が使用されます しかし推論時には これらのモデルは 結果の予測に時間が掛かることがあります 多くの場合では 代わりに精度を下げた数値や 8ビット整数を使用する方が好ましいです これにより メモリ帯域幅を節約し モデルのメモリフットプリントを 削減できます
8ビット整数形式では 量子化にはシンメトリックと アシンメトリックの2種類があります MPSGraphには現在 両方に対応できるAPIがあります シンメトリックな量子化と比べて アシンメトリックな量子化では zeroPointと呼ばれる 量子化バイアスを指定できます
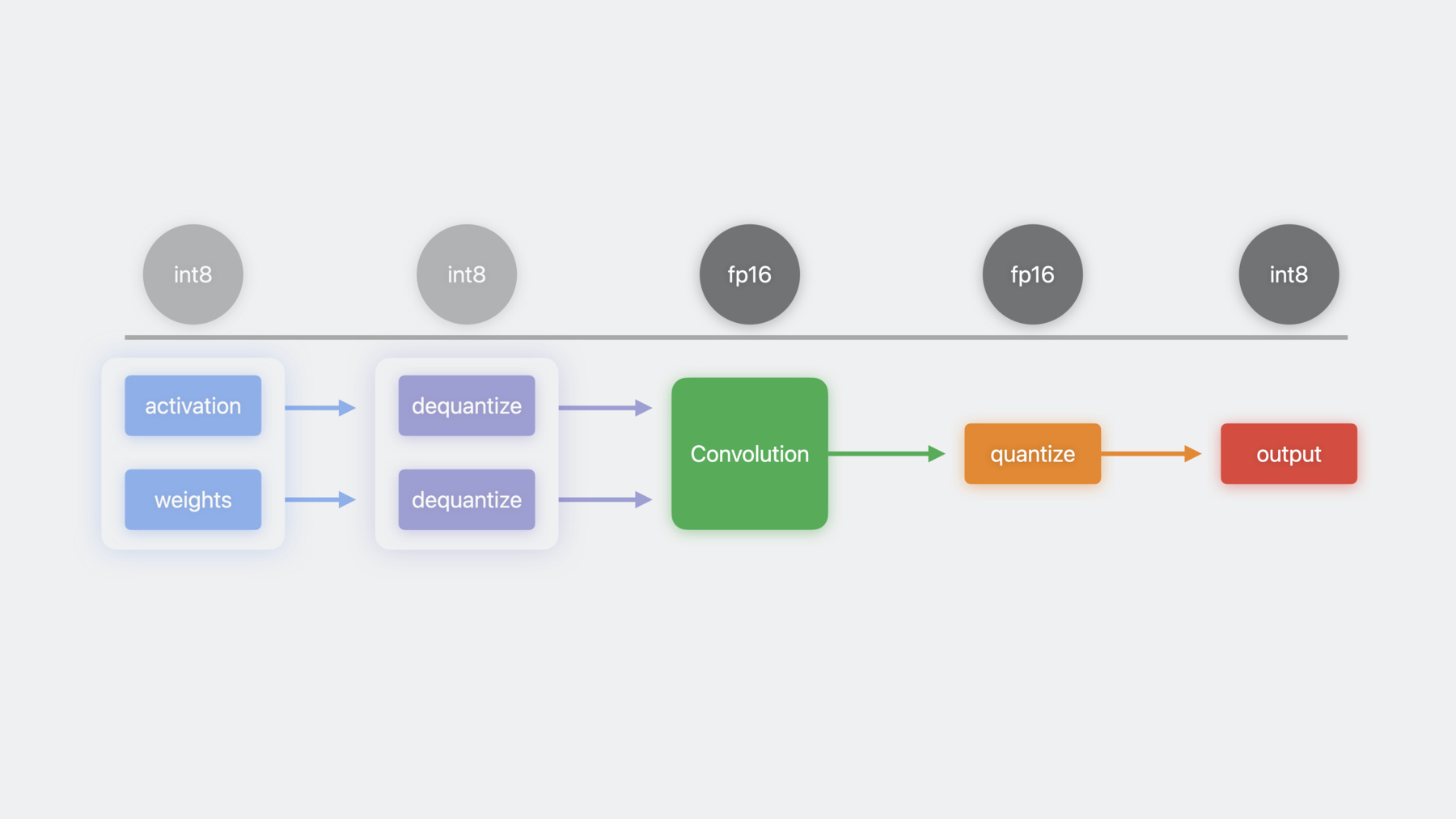
では 例をもとに 量子化された計算の 使用方法について詳しく見てみましょう まず 入力としてInt8形式の アクティベーションと重みを使用します これらの入力は MPSGraphの dequantizeTensorオペレーションを使い 浮動小数点形式に逆量子化されます その後 浮動小数点の入力を 畳み込み演算に入力できます 結果として得られた浮動小数点テンソルは quantizeTensorオペレーションを使い 再びInt8形式に量子化されます MPSGraphはこれらのカーネルを自動的に 1つのオペレーションに統合するため メモリ帯域幅を節約し パフォーマンスが向上する可能性があります 以上が MPSGraphで 量子化サポートを使用する方法です
これまでの新機能に加えて MPSGraphはさらに多くの 機械学習Operatorをサポートしています 今年からは ほとんどのグラフ操作で 複素数型がサポートされています 複素数は 単精度または半精度の 浮動小数点形式で使用することができます 複素数データ型をベースに MPSGraphでは高速フーリエ変換 演算用のOperatorが追加されています 最大4次元までの 複素数から複素数 複素数から実数 実数から複素数への変換を適用できます これらはオーディオ ビデオ 画像処理アプリでは一般的です さらに MPSGraphを使うと 3次元畳み込み グリッドサンプリング SortとArgSort および合計 積 最小値 最大値などの 累積演算を実行できます 以上が MPSGraphの 新機能についての解説です 本日のセッションの内容をおさらいします まず PyTorchやTensorFlowのような 人気のあるMLフレームワークを Metalで高速化するための 改善点について説明しました また Metalで新たに高速化された JAXフレームワークも利用可能になりました また 新しいシリアライズツールを使用して 他のフレームワークから 既存のモデルをMPSGraphにシームレスに 統合する方法について説明しました 今回のトークはこれで終了です これらの機能を活用して作成される 素晴らしい コンテンツを楽しみにしています ご視聴ありがとうございました ♪ ♪
-