-
デバイス上の音声認識のカスタマイズ
語彙を追加し基礎モデルをカスタマイズすることで、アプリのデバイス上音声認識を向上させる方法を紹介します。音声認識がデバイス上でどのように動作し、より予測可能な転写(トランスクリプション)のために特定の言葉やフレーズをどうしたら促進できるのか説明します。すべてランタイムで言葉の特定の発音を提供し、カスタムフレーズのフルセットを素早く生成できるテンプレートサポートを利用する方法について確認しましょう。スピーチフレームワークついて、詳しくはWWDC19の「Advances in Speech Recognition」をご参照ください。
リソース
関連ビデオ
WWDC19
-
このビデオを検索
♪ ♪
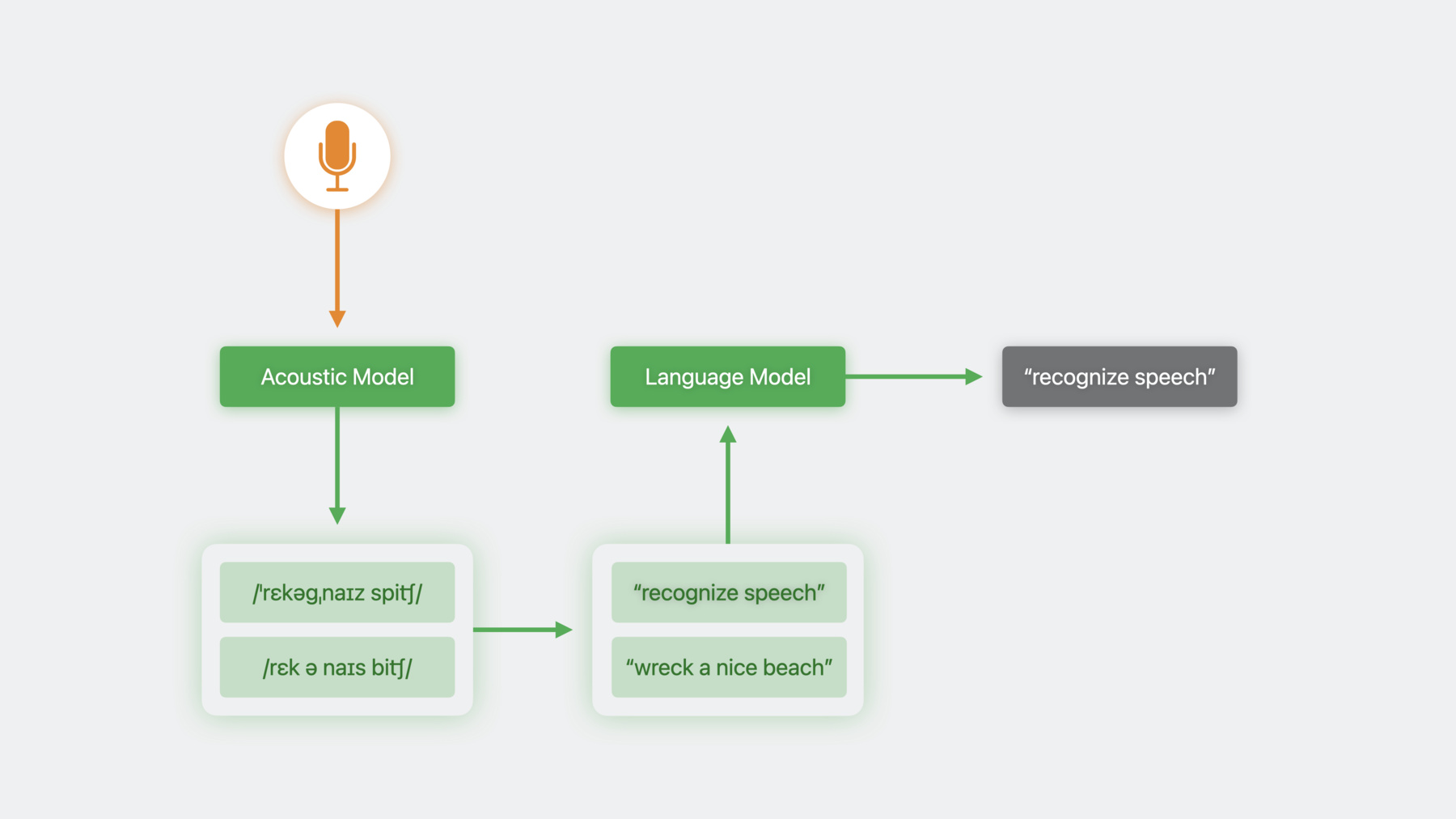
こんにちは Ethanです Siri Understandingチームのメンバーで 音声認識の進展についてお話しします iOS 10でスピーチフレームワークが登場し Siriや音声入力の技術を利用し 簡単で直感的なインターフェイスの 音声で操作できるアプリの作成が 可能になりました しかしspeech recognizer classは そのままではアプリに適していません これを説明するため まず音声認識について話しましょう 音声認識システムはまず 音声データをAcoustic Modelに送り 発音表記を作成します その発音表記が書体つまり転写に 変換されます 時として幾つかの発音表記が 音声データに合致したり 一つの発音表記が 複数の転写となることがあります これらの場合 幾つもの転写候補ができ 曖昧さを解消する必要があります そのために言語モデルを使用します 言語モデルは次に来るであろう言葉を 予測します 文章全体に使用するとその文章が 無意味に感じられる場合もあります 言語モデルは訓練中に 使用されたパターンに基づき 可能性の低い候補を却下します iOS10以来 スピーチフレームワークは 簡単なインターフェイスを表すため この全過程を包括しました これが理想的でないこともあるため 例を見てみます 私はチェスが好きで よく使われるオープニングの展開や ディフェンスなどを声で指示できる アプリを作ろうとしています ここでは対戦相手が クイーンズ・ギャンビットで出ました チェスを勉強したのでE5で応戦します アルビン・カウンターギャンビットです
アルビン・カウンターギャンビットをプレイ
おっと問題が発生しました リコグナイザが誤解して 音楽リクエストと認識したようです リコグナイザが使う言語モデルは 訓練中に音楽リクエストを数多く受けたので 「アルバムをプレイ」のようなクエリの 準備ができています 逆に言えば私が意図した内容の 転写に出くわしたことはないのです 分野により対応する動作が異なりますが スピーチフレームワークは この言語モデルの習性を抽象化し すべてのアプリに同じモデルを適用します iOS17からはアプリに合わせ 正確さを向上させるため SFSpeechRecognizerの 言語モデルの習性を カスタマイズできます
言語モデルのカスタマイズは まず訓練データの収集からです これは開発過程中に行えます そしてアプリでデータを準備し 認識リクエストを構成し実行します
訓練データの収集過程について お話ししましょう 上位レベルでの訓練データは ユーザーが話すであろう文を示す テキストから構成されます モデルにそれらの文を予期するよう教え 正しく認識する可能性を高めます 頻繁に試すとリコグナイザが有能で 時間と共に向上するのがわかります 訓練データのコンテナとなる 新しいクラスがあります Result builder DSLで作成されます PhraseCount objectで完全な文 または文の一部を供給できます またPhraseCountは最終データセットで 何度サンプルが供給されるか記述します これで特定の文に 重要性を持たせることができます データには限りがあるため 訓練データ量と強調する文のバランスに 気をつけましょう またテンプレートで多くのサンプルを 生成することもできます ここにチェスの手を示す 3つのクラスの言葉を定義しています 「piece」はターゲットも兼ねた 動かす駒 「royal」はボードのどちら側かを定義し 「rank」は動かす先です これをパターン化して あらゆる手を示すデータサンプルを 簡単に生成することができます 「count」はテンプレート全体に適用し 10,000のチェスの動きのサンプルが データサンプルに均等に分配されます データオブジェクトの構築が終わったら ファイルに書き出し ほかのアセット同様アプリに配備します
製薬名などを含む医療アプリのように アプリが特殊な用語を使用する場合 それらの綴りと発音を定義でき 使用を示すphrase countsを提供できます 発音はX-SAMPA文字列として 受け入れられます 各ロケールでユニークな発音シンボルが サポートされています ロケールとサポートされる シンボルについては ドキュメントをご覧ください 私のアプリでは フレンチ・ディフェンスである ワイナウアーを理解させるため このロケールでサポートされる X-SAMPAシンボルで 発音を記述します ランタイムでアクセスできる同じAPIで データ訓練できます こうすることでユーザーが学ぼうとしている オープニングやディフェンスに集中するなど ユーザー特定の使用パターンを サポートできます 名前による訓練も可能です ユーザーの連絡先に対する ネットワークプレーのサポートに役立ちますが もちろんユーザーのプライバシーを 尊重すべきです 例えば履歴に現れる 連絡先の頻度に応じて連絡先への 電話の命令を促す 通信アプリなどがその例です このような情報は デバイスに留まるべきです データオブジェクトを生成するため アプリ内で同じメソッドを呼び ファイルに書き込み 先程のように取り込みます
訓練データが生成されると 単一のロケールにバウンドされます 一つのスクリプトで 複数のロケールをサポートしたい場合 NSLocalizedStringのような 標準のローカリゼーション機能を 利用できます ではアプリでのモデル配備についてです まず新しいメソッド prepareCustomLanguageModelで 先程生成したファイルを受け入れ 後に使う2つの新しいファイルを作ります このメソッドコールは 大量のレイテンシがあるため メインスレッド外でコールし 起動画面などのUIの背後に置いて レイテンシを隠すべきです また プライバシー尊重のため データをデバイス上に留めるべき 場合があります LM customizationはこのような ユースケースをサポートし カスタマイズされたデータを 決してネットワーク上に送りません すべてのカスタマイズリクエストは デバイス上で実行されます 音声認識リクエストが作成されると デバイス上で認識を実行するようにします これを行わないとリクエストは カスタマイズなしで実行されます そして言語モデルを リクエストオブジェクトに取り付けます アプリでLM customizationがオンで⋯ アルビン・カウンターギャンビットをプレイ カスタム用語も上手く使えます ワイナウアーバリエーションをプレイ
言語モデルをカスタマイズし リコグナイザをアプリの分野に調整し その動作を制御できるようになりました そして何よりも アプリ上での音声認識の 正確さを向上できました スピーチフレームワークは アプリやユーザーに順応でき よりパワフルで 素晴らしい体験を創造できます 言語モデルのカスタマイズで 音声リコグナイザを向上させ アプリに合わせてカスタマイズできます みなさんが今後このテクノロジーを どう活用されるか とても楽しみです ご視聴ありがとうございました ♪ ♪
-