-
Core MLを使用してデバイス上に機械学習モデルとAIモデルをデプロイ
Core MLによって機械学習モデルとAIモデルを変換し実行する際のスピードとメモリパフォーマンスを最適化する、新しい方法を確認しましょう。モデルの表現、パフォーマンスに関するインサイトの取得、実行、モデルのスティッチングのための新しいオプションについて解説します。これらのオプションを組み合わせることで、デバイス上のプライベートな環境で効果的な体験を実現できます。
関連する章
- 0:00 - Introduction
- 1:07 - Integration
- 3:29 - MLTensor
- 8:30 - Models with state
- 12:33 - Multifunction models
- 15:27 - Performance tools
リソース
関連ビデオ
WWDC23
-
このビデオを検索
こんにちは Core MLチームのエンジニア Joshua Newnhamです 本日はCore MLの 新機能をご紹介します これらの新機能は機械学習やAIモデルを デバイス上で効率的にデプロイして 実行するのに役立ちます
デバイス上でモデルを実行すると 新しい形式のやり取り パワフルなプロ用ツール 健康やフィットネスデータから インサイトに富んだ分析を作成できる 素晴らしい可能性が生み出されます その際 個人データのプライバシーと セキュリティは保護されます
何千ものアプリがCore MLを使用して デバイス上のMLを活用した 素晴らしい体験を生み出しています みなさんにもできます
このビデオではまず モデルデプロイワークフローにおける Core MLの役割を確認します 次は便利な機能について見ていきます まずモデル統合を簡単にする 新しいタイプについて説明します 次に状態を使ってモデルの推論効率を 高める方法を詳しく見ていきます その後は効率的なデプロイのための 多機能モデルを紹介します 最後に モデルのプロファイリングと デバッグに役立つ Core MLパフォーマンスツールの アップデートについて確認します では始めましょう
機械学習ワークフローは 3つのフェーズで構成されています モデルのトレーニングと準備と統合です このビデオではデバイス上での 機械学習とAIモデルの統合と実行に 焦点を当てます トレーニングについては Apple GPUでのMLモデルとAIモデルの トレーニングに関する今年のビデオを ご覧になることをおすすめします モデルの変換と最適化については Appleシリコンへのモデルの導入に関する 今年のビデオをご覧ください
モデルの統合はMLパッケージから始まります MLパッケージは 準備フェーズで作成された成果物です ここからCore MLを使うと このモデルをアプリに簡単に統合して 使用できます
Core MLはXcodeと緊密に統合されており さまざまな種類の機械学習とAIモデルで デバイス上の推論を実行するための 統合APIを提供します
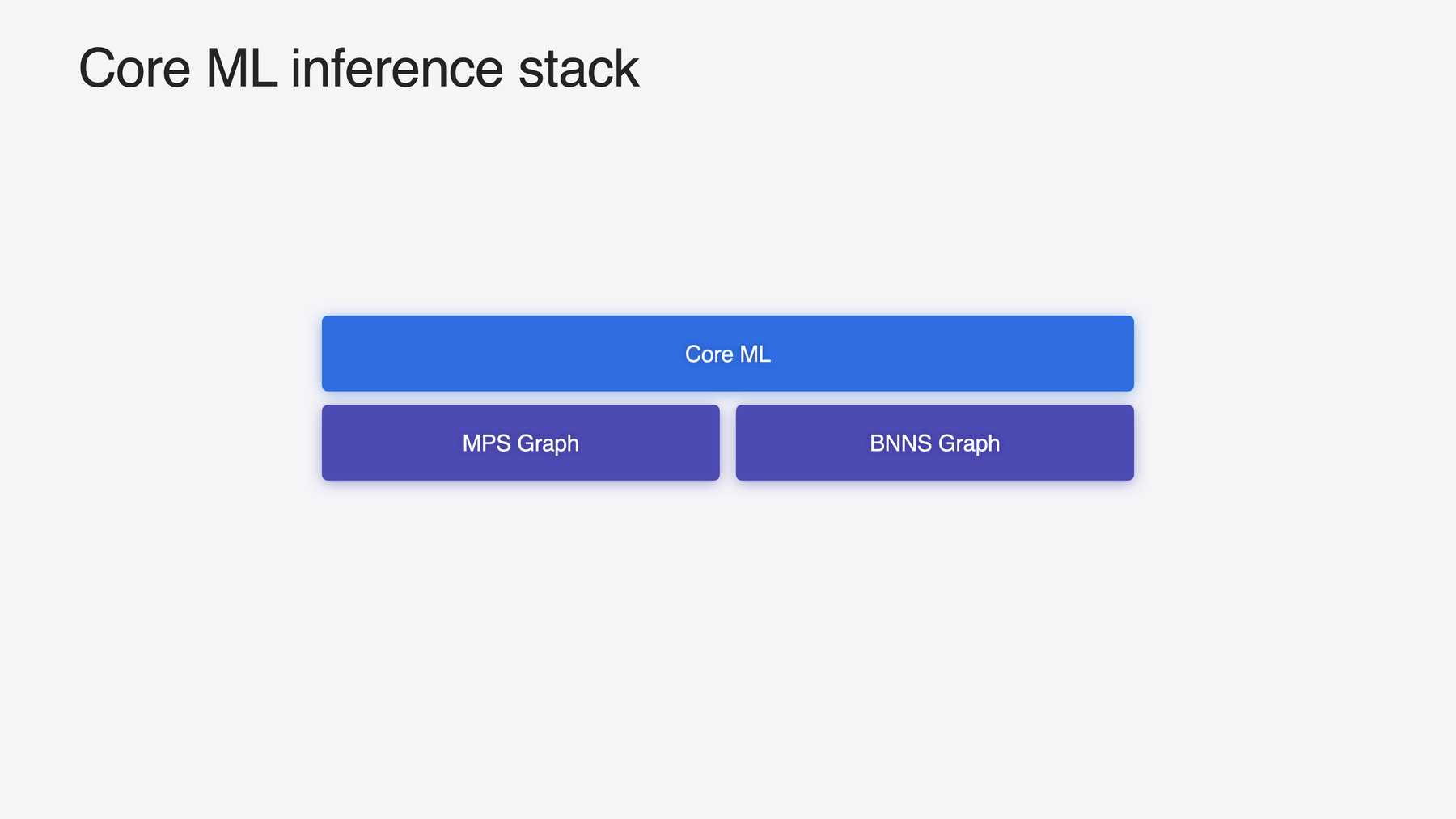
モデルはAppleシリコンの パワフルな演算能力を使用して実行され CPU、GPU、Neural Engineに 作業をディスパッチします これはMPSグラフとBNNSグラフという Core MLモデルも使用できる 他の2つの機械学習フレームワークの 助けを借りて行われます ユースケースで Metalとの緊密な統合や CPUでのリアルタイム推論が 必要な場合に最適です 詳細については 関連するビデオをご覧ください 推論スタック全体で 大幅な改善が行われたため Core MLは今年 さらに優れたパフォーマンスを発揮します
たとえばiOS 17と18の 相対的な予測時間を比較すると 多くのモデルでiOS 18の方が 高速であることがわかります この高速化はOSが実現するもので モデルの再コンパイルやコードの変更は 必要ありません これは他のデバイスにも当てはまりますが 高速化はモデルとハードウェアによって 異なります
モデルを変換したら モデルを効率的に統合して実行する方法を 見ていく準備が整いました
モデルをアプリに統合するのは 必要な入力を渡して 返された出力を読み取るだけの 簡単な作業です
ただし より高度なユースケースでは 急激に複雑さが増す可能性があります たとえば生成AIは反復的であることが多く 複数のモデルが含まれる場合があります
このようなユースケースでは モデルの外部に計算が存在し エンドツーエンドのパイプライン実行に必要な 接着剤やスティッチングとして機能します この計算をサポートするには 多くの場合 操作を一から実装するか 様々な低レベルAPIを使用する必要があり どちらもコードが長くて複雑になります でも これは今までの話です
Core MLの新しいタイプである MLTensorをご紹介します MLTensorはこの計算をサポートする 便利で効率的な方法を提供します
MLTensorは 機械学習フレームワークに典型的な 多くの一般的な演算操作と 変換操作を提供します
これらの操作は Appleシリコンのパワフルな 演算能力を使用して実行され 高いパフォーマンスを実現します
また人気のPython数値ライブラリに 似ているため 機械学習をすでにご存じの場合は より簡単かつ直感的に導入できます いくつかの例を見ながら APIを詳しく見てみましょう
まずテンソルをいくつか作成して操作します テンソルには様々な作成方法がありますが ここでは2つを紹介します
1つ目はMLShapedArrayから テンソルを作成し 2つ目はネストされたスカラの コレクションを使用します MLShapedArrayと同様に MLTensorは多次元配列で 形状とスカラ型で定義されます 形状は各軸の長さを指定し スカラ型は保持する要素の型を示します テンソルの作成方法がわかったので テンソルの操作方法を見ていきましょう 基本的な計算から始めます テンソルは幅広い演算に対応します この例では 要素ごとに加算と乗算を実行し その後 結果の平均を計算します テンソルはリテラルとシームレスに連携し フレームワークは互換性のある形状を 自動的にブロードキャストします 次に結果をその平均と比較することで ブール型マスクが作成されます このマスクに結果を乗算して フィルタ処理したバージョンを作成し マスクがfalseである値をゼロにします 次にテンソルの形状をインデックス付けして 変換する方法を説明します Pythonの数値ライブラリと同様に 各次元にインデックスを付けることで テンソルをスライスできます この例では行列の最初の行を取得し reshapeメソッドを使用して 展開し直します すべてのテンソル操作は 非同期でディスパッチされます このため テンソルはその基礎となるデータに アクセスする前に 明示的にMLShapedArrayに 具体化される必要があります そうすることで 上流のすべての操作が完了し データが利用可能になります
ここまでテンソルを作成して 操作する方法を見てきたので 次はもっと面白いことに目を向けましょう MLTensorがどのように 大規模な言語モデルの統合を 簡素化するかを見てみましょう
まずモデルの例と その出力について簡単に紹介します モデルは自己回帰言語モデルです つまり前の単語のコンテキストに基づいて 次の単語またはトークンを 予測するようにトレーニングされます
文を生成するには 予測された単語を入力に追加し シーケンス終了トークンが検出されるか 設定された長さに達するまで この処理を繰り返します ただし言語モデルは 1つの単語を出力するのではなく 語彙に含まれるすべての単語の スコアを出力します 各スコアは次にその単語が来ることに対する モデルの信頼度を表します
デコーダはこれらのスコアをもとに さまざまな戦略を使用して 次の単語を選択します たとえば スコアが最も高い単語を選択したり 調整された確率分布で ランダムにサンプリングしたりします デコード方法は変更できるため このステップは通常 モデルとは別に保持されます これはMLTensorにとって最適です MLTensorの導入前と導入後の いくつかのデコード方法の実装を比較して どのように変化するかを見てみましょう
このデモではHuggingFaceの Swift Transformerパッケージと Chatアプリの修正バージョンに加えて 準備のビデオで変換および最適化された Mistral 7Bモデルを使用します デコーダの実装を比較する前に モデルの動きを見てみましょう スーパーヒーローのコーギーが登場する 架空の子供向けストーリーの タイトルの候補を生成するように モデルに指示します
スタートとしては素晴らしいですが さらにクリエイティブにしたいと思います アプリはデフォルトで 最も可能性が高い単語を選択します これは貪欲デコードと呼ばれる手法です
別のデコード方法を見てみましょう
top-kサンプリングを有効にすると アプリは次の単語を選択する際に 常にスコアが最大の単語を選ぶのではなく top-kの最も可能性の高い単語を ランダムにサンプリングします
最も可能性の高い単語をランダムに サンプリングすることに加えて 温度を調整することで確率分布に影響を 与えることもできます 温度が高いと分布が平坦になり より創造的な応答が得られますが 温度が低いと逆の効果が生まれ より予測可能な出力が得られます
温度1.8で top-kサンプリングを使用して モデルを再実行してみましょう
これはもう少し興味深いものになります 2つのデコード方法の結果を確認したので MLTensorを使う場合と使わない場合の 実装を比較してみましょう 2つの実装を比較すると 明らかな違いが1つあります それはMLTensorを使用して 同じ機能を実現すると 必要なコードが いかに少なくなるかということです といっても 元のバージョンが 間違っているという意味でも 低レベルAPIが不要 という意味でもありません それどころか これは適切に作成された パフォーマンスの高いコードであり 低レベルのAPIが必要なインスタンスも 多数あります しかし多くの一般的な機械学習タスクでは MLTensorは簡潔な代替手段になります これにより低レベルの詳細ではなく 優れた体験を作成することに もっと集中できるようになります 前のセクションでは MLTensorが言語モデルからの 出力のデコードを簡素化する方法について 説明しました このセクションでは状態について説明し 状態を使用して 言語モデルから各単語を生成するのに かかる時間を短縮する方法を探ります まず状態の意味を説明します 皆さんがこれまで操作したモデルの大半は おそらくステートレスです つまり履歴を保持せずに 各入力を個別に処理します たとえば畳み込みニューラルネットワーク に基づく画像分類器は 各入力が前の入力から独立して 処理されるため ステートレスです
これはご想像のとおり 前の入力の履歴を保持する ステートフルモデルとは対照的です シーケンスデータに使用される 再帰型ニューラルネットワークなどの アーキテクチャは ステートフルモデルの一例です
現在ステートフルモデルは 状態を手動で 管理することでサポートできます 状態は入力として渡され 更新されたバージョンが出力から取得され 次の予測に備えられます ただし 各時間ステップで状態に使用される データをロードおよびアンロードすると オーバーヘッドが発生します このオーバーヘッドは状態の規模が 大きくなるにつれて顕著になります
今年 Core MLでは ステートフルモデルの サポートが向上しました 状態の維持を手動ではなく Core MLで実行するようになったため 前述のオーバーヘッドの一部が削減されます では状態が役立つ可能性がある 1つのモデルタイプに 注目してみましょう 前のセクションでは言語モデルが 語彙に含まれる すべての単語のスコアを出力し そのスコアが次に来る単語に対して モデルが割り当てる信頼度を 表すことを学びました スコアに加えて 使用されたモデルは特定の単語の キーとバリューのベクトルも出力します これらのベクトルは単語ごとに計算され ネットワーク全体に埋め込まれた アテンションメカニズムに使われることで モデルの自然な出力と 文脈的に関連のある出力を 生成する能力が向上します 各ステップで前の単語ベクトルの 再計算を避けるために ベクトルは保存・再利用されることが多く これはキーバリューキャッシュ 略してKVキャッシュと呼ばれます このキャッシュは新しい機能に最適です その方法を見てみましょう
モデルの入力と出力を使って KVキャッシュを処理する代わりに Core MLの状態を使用して 管理できるようになりました これによりオーバーヘッドが削減され 推論の効率が向上し 予測時間が短縮されます
状態のサポートは準備フェーズで モデルに明示的に追加する必要があります 方法については Appleシリコンへの モデルの導入に関するビデオをご覧ください
モデルに状態があるかどうかは Xcodeでモデルを調べることで 簡単に確認できます
状態が利用可能な場合は モデルプレビューの予測タブの モデル入力のすぐ上に表示されます
では次の単語予測に使用される コードを更新して 状態をサポートする手順を見ていきましょう まずは必要な変更点を強調するために 状態のないバージョンを確認します 関連する部分だけに焦点を当てて キーとバリューのベクトルを格納するための 空のキャッシュを作成することから始めます
このキャッシュは入力として モデルに提供され モデルから返された値を使用して 更新されます それでは状態をサポートするために 必要な変更を見ていきましょう
ほとんどのコードは若干の調整を除けば 見慣れているはずです
各状態を手動で事前割り当てする代わりに モデルインスタンスを使って 状態を作成します この例では Core MLはキーとバリューのベクトルを 格納するためのバッファを事前割り当てし 状態を参照するハンドルを返します このハンドルを使って これらのバッファにアクセスし 状態の存続期間を制御できます
各キャッシュを入力として渡すのではなく モデルインスタンスによって作成された 状態を渡します 更新はインプレースで実行されるため キャッシュを更新する 最後の手順を省略できます これだけです 状態をサポートするようにコードを更新し 次の単語を予測する際に 高速化された機能を利用しました
これはM3 Maxを搭載した MacBook Proで実行されている Mistral 7Bモデルを使用した KVキャッシュ実装の簡単な比較です 左は状態なしで実装されたKVキャッシュ 右は状態ありで実装された KVキャッシュを示しています 右は約5秒で完了しますが 左は約8秒かかりました 状態を使うと1.6倍高速になります パフォーマンスはもちろん モデルやハードウェアによって異なりますが 状態を使用した場合に期待できる メリットの概要はこれでわかります
次のセクションでは 複数の機能を備えたモデルを 柔軟かつ効率的にデプロイできる Core MLの新機能について説明します 機械学習モデルについて考えるとき 通常は関数のように入力を受け取り 何らかの出力を生成するものを 思い浮かべます
関数は実際 Core MLでニューラルネットワークを 表現する方法です 関数は通常 一連の操作を含む 1つの関数で構成されます この機能の自然な拡張は 複数の関数をサポートすることで 現在Core MLで利用できます この機能の具体例として 複数のアダプタを備えたモデルを 効率的にデプロイする方法を説明します
アダプタとは 既存のネットワークに埋め込まれる 小さなモジュールで タスクに合わせた知識でトレーニングします 大規模に事前トレーニングした モデルの機能を 重みを調整せずに 効率的に拡張できます これにより1つのベースモデルを 複数のアダプタで共有できます この例ではアダプタを使って 潜在拡散モデルによって生成される 画像のスタイルに影響を与えます
しかし複数のスタイルを デプロイしたい場合はどうでしょうか
各アダプタにそれぞれ 2つ以上の特化モデルをデプロイするか アダプタの重みを 入力として渡す方法がありますが どちらも理想的とは言えません
複数の機能に対応したことで 今後はより効率的なオプションを 利用できます
複数のアダプタを共通のベースで 1つのモデルにマージし それぞれに関数を公開できます
Appleシリコンへのモデルの導入に関する ビデオをご覧になり 複数の関数を含むモデルを 書き出す方法をご確認ください 特定の関数を含むモデルを読み込むために 必要なコードを見てみましょう
多機能モデルの読み込みは 関数名を指定するだけです
読み込み後 モデルで予測を呼び出すと 指定された関数が呼び出されます 指定がない場合は デフォルト値が呼び出されます 動作を見てみましょう
このデモではオープンソースの Stable Diffusion XLモデルと 修正済みのHuggingFaceの Diffusersアプリを使用して テキストから画像を生成します パイプラインはMLTensorを使用して シームレスにつなぎ合わせた 複数のモデルで構成されています これには2つの関数を持つ Unetモデルが含まれます それぞれ異なるアダプタを使用して 生成された画像のスタイルに影響を与えます Xcodeで開くと モデルで使用できる 関数をプレビューできます
このモデルには2つの関数 「sticker」と「storybook」があり 入力と出力が同じなので 両方に同じパイプラインを使用できます ただし必須ではなく 関数ごとに入出力を変えることも可能です アプリに戻って スーパーヒーロー コーギーのステッカーを 生成してみましょう
素晴らしい 関数を切り替えてスーパーヒーローの スタイルを変えてみましょう
いいですね このデモでは複数のアダプタを使用して 単一のモデルをデプロイする 方法を示しました 各アダプタには それぞれの関数を使ってアクセスします この機能は汎用性が高く 他の多くのシナリオで使用できます 皆さんがどのように使うか楽しみです 最後のセクションでは モデルの プロファイリングとデバッグに役立つ 機能強化と新しいツールについて 簡単に説明します まずはCore MLパフォーマンスレポートの アップデートです パフォーマンスレポートは すべての接続済みデバイスを対象に生成され コードの記述は不要です Xcodeでモデルを開き タブを選択し
ボタンをクリックして 新しいレポートを作成し
プロファイリングするデバイスと
実行する コンピューティングユニットを選択して ボタンを押すだけです
完了するとレポートには読み込み時間と 予測時間の概要とともに 演算ユニットの使用状況の 内訳が表示されます 今年のパフォーマンスレポートでは さらに多くの情報が提供されます 具体的には各操作の推定時間と 演算デバイスのサポートなどです 推定時間は 各操作に費やされた時間を示します これは各操作の推定相対コストに 中央予測時間を掛けて計算されます
ネットワークのボトルネックを 特定するのに役立ちます 推定時間に基づいて 操作を並べ替えることで 簡単に行えます
さらにサポートされていない操作に カーソルを合わせると 特定の演算デバイスで 実行できなかった理由のヒントが 表示されます
この例では データ型が サポートされていないことがわかるので 準備段階に戻って 必要な変更を加え モデルとすべての演算デバイスの 互換性を確保できます
このモデルでは 精度をFloat16に 更新するだけで済みました より多くの情報とともに パフォーマンスレポートをエクスポートして 他の実行と比較できます 比較することで モデルへの変更の影響を簡単に確認できます アプリでコードを記述する必要は まったくありません ただし コードを使用する方が便利な場合もあります MLComputePlan APIを使うなら コードが便利です パフォーマンスレポートと同様に MLComputePlanは Core MLのモデルに関する デバッグとプロファイリングの 情報を提供します APIは各操作のモデル構造と ランタイム情報を表示します 前述のように サポートされる 演算デバイスと推奨される演算デバイス 操作のサポートステータス 推定相対コストが含まれます では このビデオのまとめに 入りたいと思います Core MLの新機能を使用すると 機械学習とAIモデルをデバイス上で 効率的にデプロイして実行できます MLTensorを採用し モデルの統合が簡素化されました 状態を利用すると推論の効率が向上します 多機能モデルを使用して 複数の機能を備えたモデルを 効率的にデプロイできます パフォーマンスツールで 新しい情報を活用して モデルのプロファイルとデバッグを行えます オンデバイスの パワフルな機械学習を活用して 新しい体験を実現してください
-