-
Metal for Pro Apps
Metal is the platform-optimized graphics and compute framework at the heart of GPU acceleration on Apple platforms. Learn key aspects of the Metal architecture that support the techniques for modern high-performance pro applications and workflows. Learn how to leverage Metal capabilities to optimize performance and maintain a steady frame rate in video editing pipelines. Understand how to leverage CPU and GPU parallelism, and dive into best practices for efficient data throughput.
리소스
관련 비디오
WWDC21
WWDC19
-
비디오 검색…
Welcome to the Metal for Pro Apps session. My name is Eugene, and together with Dileep and Brian, we'll be talking about utilizing Metal to enable new workflows and unleash all the power of Macs and iPads for your Pro applications.
But what is a Pro App? We at Apple define it as an application used by creative professionals in the content making business. That includes animators and live TV, photography, 3D animation, print media, and audio production.
Additionally, it includes both first party as well as third-party apps created by developers like you. These are apps such as Autodesk Maya for 3D animation rigging and visual effects or maybe Logic Pro for audio and music production. Serif Labs Affinity Photo for professional image editing or Black Magic's DaVinci Resolve, professional application for video editing.
Pro apps have always been an important of our ecosystem, and with the recent release of the new Mac Pro our new Pro Display XDR robust support for external GPU's and the new A12X bionic-powered iPad pro. We really doubled down on our focus and commitment in this space.
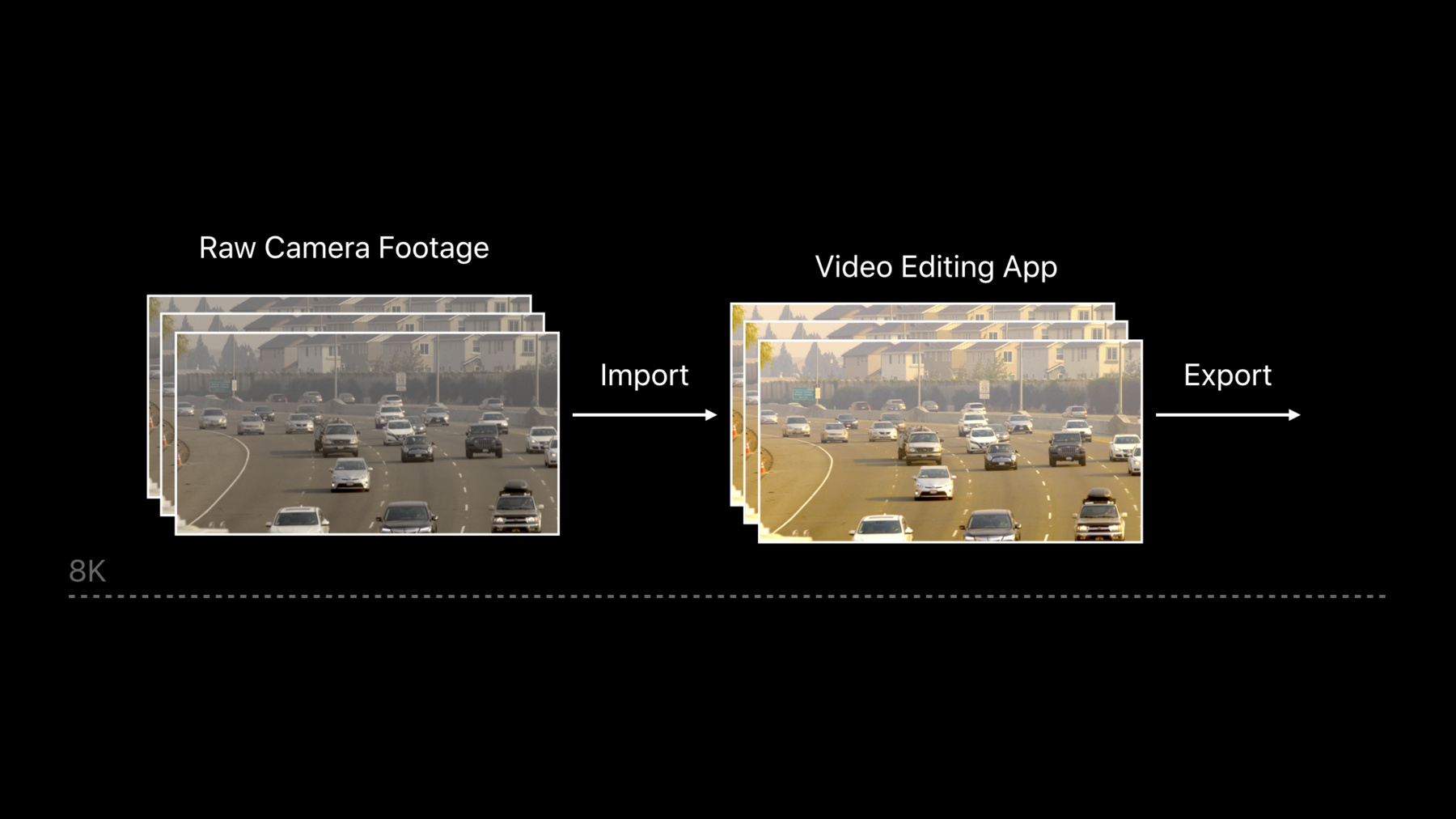
So why are pro apps different from other workloads? One key thing is that they operate on really large assets. This includes up to 8K video, billions of polygons, thousands of photos, hundreds of audio tracks.
They also require a lot of CPU and GPU horsepower. Finally, there is always the challenge of achieving real-time interaction while maintaining the full fidelity of the original content. So let's go to the agenda of today's talk.
First, we'll introduce the video editing pipeline on our platforms and discuss how to optimize it for groundbreaking 8K. Next, we'll talk about how you can add HDR support to your app. Then, we show you how to scale across all CPU ports and GPU channels. And finally, we'll discuss how to achieve most efficient data transfers.
So let's start by talking about the video editing pipeline with 8K content in mind.
We at Apple find video editing as one of the most demanding and creative workloads. So we will use video apps as a use case to show how Metal helps you. But before we start, I'd like to give a huge thanks to our friends at Black Magic Design. We've been working with them really closely optimizing both DaVinci Resolve and our platform to unleash new 8K workflows, and we're really proud of what we have achieved together.
But let's see how it all worked before when we first tried 8K raw content. You see the result is not real time. We have heavy stuttering, and the experience is not great.
So that doesn't work.
Let's see how professionals worked around this problem. So they have huge raw footage in 8K. First, they transcoded to get all the color base. Then they sub-sampled and downscaled it to 4K proxy. So they can apply edits and affects in real time, but there is one really important catch.
You cannot color grade proxy data simply because it's not accurate. So now you have to go back and apply all of your edits to the original content, run an offline render job which may take hours. Review it with your director and then rinse and repeat.
We at Apple want to make it faster for our users.
We really want all the professionals to work straight in 8K content out of the box. So let me tell you the story of how we enabled real time video editing in 8K.
So it starts with building an efficient video editing pipeline. We'll cover the general design of an efficient pipeline, what frameworks to use, and how to maximize all the available hardware.
Then, we'll discuss how to manage real large assets. And finally, we'll tell you about some challenges you might face trying to maintain a predictable frame rate and how to overcome them.
So let's dive into the video editing pipeline.
Here are typical building blocks most video editing apps need to have. So we start by reading the content, then we need to decode it so we can process it. And finally, present or encode. In today's session, I'll be focusing on the decode process, encode and display blocks. We will be covering the import and export blocks which typically use AVFoundation framework. I encourage you to check out our samples on AVAssetReader and AVAssetWriter. Let's dive in how to make decoding part closer to Metal.
Apple provides a flexible low-level framework called Video Toolbox to achieve efficient, high-performance video processing. It can be used on iOS, macOS, and tvOS, supports a huge number of formats and leverages any available hardware on our devices.
The building block for the decode is a decompression session, and let me quickly show you how to set it up. First, we specify that we want to use hardware video decoding.
Then we create a session for each video stream. We set it up with a completion handler here.
While we go through our video stream we call decode frame with an async flag. This is really important to make the call a non-blocking one. Apple frame decode completion, our callback is going to be called. And finally please don't forget to clean up after you are done. So now we know how to decompress our frames. Now let's talk about how to make sure that we are doing it in a most optimal way.
Your Mac might have set several hardware decoding blocks available. To make sure we are using the same physical memory with zero copies we'll leverage an internal object called an IOSurface.
IOSurface is a hardware accelerated image buffer with GPU residency tracking. It also gives you interprocess and interframework access to the same GPU memory so it's perfect for this scenario.
Core Video and Metal provides you an easy way to leverage the benefits of IOSurface using an object called CVMetalTextureCache. Let's see how to set it up.
So here we create our CVMetalTextureCache, and we want to make sure we use the Metal device we're going to be using for pixel processing. So next whenever we get a new CV pixel buffer, we need to turn it into a Metal texture. It happens automatically at zero cost if our pixel buffer is backed by an IOSurface. Finally, don't forget to clean up your textures and pixel buffers to ensure proper reuse in the texture cache. So now we have our frame as an MTL texture, and we are ready to do some pixel processing. Here we have several options.
Of course, we can write our own processing and grading kernels and it's really easy since Metal's shader language is C++ based. At the same time, we highly encourage you to use Metal performance shaders to do your pixel processing. You can even build your own neural network as part of your pipeline.
Now let's see how to use MPS to run a typical blur filter.
So we start with the Metal queue and the common buffer.
We create a Gaussian blur kernel, one of many built into MPS. And now, we can attempt to encode the work in place and we provide a fallback allocator in the case it fails. And, finally, we commit our common buffer. MPS is a really powerful framework tuned for every device on our platform. We encourage you to read more and start using it.
So we are done with the pixel processing and we are ready to encode our MTL texture to the output format. Of course, we will again use Video Toolbox here and let me show you how to do that in the most efficient way. Your new Mac Pro might have several GPU's and each of them might have more than one encoding engine.
Of course, we can let Video Toolbox be the best available device, but in many cases you'll want to specify a device explicitly to minimize copy overhead. So let's see how we do this and how to use CVPixelBufferPool to keep memory recycled.
So here is how we get a list of all available encoders.
First, we use the enable hardware flag to ensure we are leveraging hardware encoding. Then, we tell Video Toolbox which device we want to use. This is a critical step to ensure we're encoding on the same device we did our pixel processing.
Another great thing here is we can use CVPixelBufferPool to get the surfaces in the exact format used by the hardware encoder.
So this is how we get a buffer from the pool and then we use MetalTextureCache again. Now we can convert our interleaved process data to biplanar format which is what Video Toolbox needs.
And, as usual, we clean up everything to keep buffers recycled. So we can now build the most efficient pipeline possible and that's really great. We'll cover display section separately and now let's talk about 8K for a bit.
8K means really large assets. So let's see how to deal with them.
First, let's do the math. An 8K frame is just huge. It is 16 times larger than an HD frame totaling up to 270 megabytes uncompressed. And we have to send almost 300 megabytes every frame. So for 30 frames per second we have nine gigabytes per second of bandwidth. It's really close to the PCI Express limit. Moreover, even with ProRes 4 by 4 compression, a 10-minute clip can easily take massive one terabyte. This creates a real challenge for real-time playback. So let's see what it looks like when we trace it using Instruments in Xcode. So here is a system trace for the video playback session we showed earlier.
If we zoom into the Virtual Memory Track, we see a huge amount of page folds.
And the associated zero fill cost is really high. We can see it below.
So that naturally explains why all the decoding threads are stuck and cannot proceed.
We need to manage our memory more carefully. Modern operating system don't actually physically allocate memory pages until they are used. So once we start accessing all of these new pages from many decoding threads we have to wait for the system to map all those pages for us.
The way to figure that is simple. Pre-warm your CPU buffers before use to make sure all the pages are resident before playback starts. Now let me give you a few more memory management tips. Every allocation has a system call. One simple rule is to allocate early enough and avoid mid-workflow allocations. Another good advice is to always reuse your buffers. This is why it's so important to use objects such as CVPixelBufferPool and CVMetalTextureCache.
So now we have improved the way we manage our frames but there are always many, many smaller allocations needed along the lifetime of your app. Let me give you some tips on how to manage those. With MTLheap's we can efficiently manage all of our transit allocations. Allocating from a MTLheap doesn't require a kernel call since the entire heap is allocated at creation time. The heap is a monolithic resource from the system's point of view. So it's made resident as a whole.
Also, allocating from heap allows for tighter memory packing, and with heaps you can alias resource memory within the common buffer. Something we trust impossible with the regular buffers. Let me show you how to do this.
In this sample, we will be aliasing transit allocations. First, we created the heap using our device. Along the filter stages, we created the uniforms for our blur kernel from that heap.
Next, we allocate another buffer for color grade uniforms from that same heap. So after the color grading stage, we don't need those anymore and we mark them as aliasable, and the heap can actually recycle that memory for future allocations.
So when we allocate a new intermediate buffer, the heap is free to reuse any memory marked as aliasable so this is really efficient.
So that was a quick overview of how to manage our resource allocations. Now let's talk about how to present our friends with a predictable frame rate.
So here is a timing sample for triple buffer Metal application.
In this example, we're playing a 30-hertz video on a 60-hertz display. Notice how the frames are showing up on the display at a non-uniform cadence. Users feel it as stutters.
So why is this happening? Note how the CPU is incurring GPU work without regard for timing.
Once the third frame is enqueued, the CPU is blocked waiting for a drawable to become available which is not going to happen until frame one leaves the glass.
So this approach maximizes GPU utilization but produces visible stutters.
We generally want each frame to remain on the glass an equal amount of time. As a solution, Core Video offers an interface called CVDisplayLink. This is a high-precision low-level timer which notifies you before every VBLANK at a displaced refresh rate. Rather than let the CPU enqueue as many frames as possible, We use display link to determine the right time to submit each frame to the GPU. This significantly reduces video playback jitter. So let me show you the code snippet how to do this. We started by making a link with the display we will be using. Then, we set up our callback handler and for every call we will get the current time and the next VBLANK time. And we can use these values to determine when to issue a present call assuming we have processed frames ready. And we can adjust the desired frequency to our needs.
So this will significantly reduce stutters but we can take it a step further. For example, playing 24-hertz content on a 60-hertz display, we need three-two pull down. It means we will present even frames for three VBLANKS and odd frames over two VBLANKS. This is the best we can do given the mismatch, and the code snippet I just showed you will handle this just fine, but the good news is we can do even better. Our new Pro Display XDR supports multiple refresh rates including 48-hertz. So your 24-hertz content will play extremely smoothly jitter free.
So we have made quite a few important optimizations.
Now I'd like to show you the final result. This is DaVinci Resolve now playing that same 8k stream. As you can see, playback is smooth with no stutters. This has been a great collaboration for us with Black Magic. We achieved outstanding results together, and we encourage you to start leveraging our high-performance frameworks and start building new and exciting pro apps for our platform. We have tackled that 8k challenge. Now I'd like to invite Dileep to talk about our support for HDR and how you can enable it in your app. Dileep? Thanks, Eugene. In recent years high-dynamic range rendering and displays have greatly enhanced the quality of images that we see on screen.
At Apple we have been constantly adding support to improve the image technology. As you know, we have added many technologies such as retina display, 4K and 5K resolution, wide gamut color space and many and have enabled you, the developers, to create amazing and high-quality images. Continuing in that part, this year we are adding great support for HDR on macOS. I'm excited to give you an overview of the support for HDR rendering and display.
To do that, I'll cover four topics with you. One, I'll briefly talk about some common traits of HDR images.
Then I'll describe our approach to HDR, our rendering model of HDR. Then I'll go into detail on how to use Metal for HDR rendering. And finally, wrap it up with some recommendations on best practices.
So let's begin with describing some common traits of HDR images. What makes them special? Compared to standard dynamic range or SDR images, HDR images have better contrast levels. They have great details in the dark and the bright areas of the image.
Usually SDR images, these details are not discernible. They're either crushed or washed out.
HDR images have more colors with wide range of colors in them. They look very realistic.
Also, they are really bright. The brightness information is encoded in the image itself with such a high brightness and great contrast ratios, they make it possible to add lighting effects in the scene that look closer to real life. And finally, they need to be viewed on a capable display.
The display that can preserve all the details of the image. The display in itself should have underlying technologies to be able to produce high brightness, high color fidelity, and great contrast ratios.
Our new Pro Display XDR is a great example of that. Now, how do we render and display these amazing HDR contents on our devices? At Apple, we have a unique approach for this. We call this EDR, extended dynamic range.
In this approach, we use the brightness headroom available on the display to show the highlights and shadows of HDR images. Let me explain the concept in detail. As you know, the brightness set on a display is dependent on the viewing conditions or the ambient conditions.
For example, if you're in a dimmed room the brightness set on your display could be 200 nits, maybe low, and the brightness set is ideal to view SDR contents such as UI or Safari or YouTube video.
But if your display is capable of producing up to thousand nits then you have a huge brightness headroom available on the display. Similarly, if you're in well-lit conditions such as office space, the brightness set on the display could be higher, say 500 nits. And again, the brightness set is ideal to view SDR contents but still you have brightness headroom left on the display in this condition too. In an approach to HDR, we take advantage of this. When we render the pixels, we map the SDR pixels to the brightness set on the display and use the headroom to map the HDR pixels. The extent to which we map these two categories really depends on the viewing conditions as you can clearly see in the two examples here.
However, too, rendering this model, the pixels needs to be structured in a certain way and we do that by scaling the HDR pixels relative to the SDR brightness of the display.
Let's use our previous example of a dimmed room and see how the pixel values are structured relative to the brightness of the display.
In here, we represent the brightness in X axis and the normalized pixel values in Y axis. In this example, the brightness of the display set to 200 nits. In our rendering model we always reserve the pixel values, the normalized pixel values in the range 0 to 14 SDR contents and we map it to the brightness set on the display.
So a pixel value of one here corresponds to 200 nits.
But as you can see, there is a huge headroom available on the display. So you have pixel values from one through five available to represent HDR contents.
A scale factor of 5x relative to the SDR range to take full advantage of the display brightness.
We call this scale factor as maximum EDR. If the viewing conditions change or you're in a well-lit room and the brightness is increased to 500 nits, then the maximum EDR drops down but note the pixel values in the range zero to one are still dedicated for SDR contents. But they're mapped differently now, so now a pixel value of one corresponds to 500 nits instead of 200 in the previous example.
And since you have a smaller headroom available here, in this case, you have a smaller range of pixel calls available to represent HDR contents.
So merely 2x here in this example, relative to the SDR range to represent HDR pixels.
As you can see, we structured our pixels in such a way that the HDR pixels are relative to the SDR range and they scale relative to the SDR range.
We also use negative pixels for representing the darker side of the HDR image.
So in summary, EDR or external dynamic range is a display referred rendering model in which we use the brightness headroom available on the display for HDR pixels, and we scale the HDR pixels relative to the SDR brightness of the display.
The advantage of this model is that you can do HDR rendering on pretty much any display on which we can set brightness, but if you have more capable display such as of a new Pro Display XDR with its huge headroom availability then the contents are going to look just better. Now that we have looked into our rendering model of our approach to HDR, let's look into what API's do we have and how you can use those API's in your application.
On both macOS and iOS, you have a couple of options.
One, you can use AVFoundation API's. These API's are ideal for media playback applications. They handle all aspects of tone mapping and color management for you.
Two, you can directly use Metal. Metal provides with a lot of options and great flexibility.
Using the CAMetalLayer and EDR API's, you can take full control of HDR rendering in your application including tone mapping and color management.
These API's are ideal for content creation.
Now using a code snippet, let's look at how the metal layer and the EDR API's all come together in an application, shall we? So the first and the foremost that you do in your code base is to check for the EDR support on the display, and this screen provides you with the property for that. Then as usual, you create and set up your metal layer.
When you set up the metal layer, you need to choose a wide gamut color space that suits your application.
Metal supports rendering into wide gamut color spaces such as BT2020 or B3.
Next, you need to choose the transfer function that matches your content. Again, the API's have support for all industry standard transfer functions such as PQ, HLG, or Gamma.
Then you need to choose pixel format for your HDR rendering. We recommend that you use float 16 as a preferred pixel format for most of your HDR rendering needs because float 16 has enough precision to carry the color and the brightness information for HDR contents. And finally, in the layers set up you need to indicate to Metal that you have opted in to EDR rendering model.
So this is a typical layer set up that you would do. Next, moving on to main render loop. In the main render loop you need to get the brightness headroom that we talked about or the maximum EDR information, right? So NSScreen provides you with the property for that. But note, this property is dynamic. It keeps changing with the viewing conditions or when the brightness of the display changes. So you need to register for a notification for any changes on this property and as maximum EDR changes, you need to redraw your contents.
Now, if you are handling tone mapping and color management yourselves in the application, you need to do some additional pixel processing in the shaders. Let's review some common steps that you would do. Typically the video come in YUV or YCBCR color format. So the first step in your application or in your shaders is to convert it to RGB.
Also, the video contents come encoded with some kind of non-linear transfer functions such as PQ.
So the next step in the shader is to apply inverse transfer function and linearize your pixels, and then normalize it in the range zero to one.
And then use the maximum EDR that you got from NSScreen and scale the pixels as we discussed in the EDR section. And then perform editing, grading, or any processing that suits your application, and finally, perform tone mapping.
If the brightness changes then you need to do the tone mapping with different set of parameters.
If your contents are in a color space that is different from the one on the display then you also need to apply proper color conversions.
However, if you don't want to handle tone mapping or teleprocessing, and you want Metal to handle it for you, you can easily do that.
When you create a Metal layer, attach an EDR metadata object with it.
Typically the EDR metadata object provides the information on the mastering display and it also tells Metal how you want to map your pixels.
You also need to use one of the linear color spaces available with Metal. So once all your pixel processing is done, your frame is ready. Use the existing Metal API's to present your frame on the screen. As we noted earlier, you need a capable display such as of a Pro Display XDR to view these contents.
We also support HDR 10 and Dolby Vision TV's available in the market.
So this is a simple illustration of how you can use Metal layer and EDR API's for HDR rendering in your application.
So before we end this section, let's review some key takeaways and some recommendations on best practices.
Remember to redraw and update your content as the brightness changes.
Use float 16 as a preferred pixel format for most of your HDR rendering needs.
When you set up the Metal layer, select the color space and transfer function that matches your content and then perform any additional processing in the shaders as necessary. Last, but not the least, HDR processing adds to computational overhead and adds to memory pressure. So bypass tone mapping if your contents are already tone mapped or if performance is more important for you than color accuracy.
So, in summary, we have provided you with powerful API's, a display for EDR rendering model support on both iOS and macOS, and a great support for our Pro Display XDR.
I'm sure you can use these tools to create amazing HDR contents.
In the next section, we are going to talk about how you can leverage the computational resources available on the platform to get the best possible performance and to tell you all about it, I invite Brian Ross on stage.
Thanks, Dileep.
Scaling your performance to harness both CPU and GPU parallelism is the most important and sometimes the easiest optimization you can do.
In this section, I'm going to talk about several ways to scale your performance based on the architecture of your hardware. So first, I'll talk about how Metal can help you to scale across any number of CPU cores.
Next, I'll talk about how to leverage, utilize asynchronous GPU channels. And finally, I'll close this section by going over a few ways to use multiple GPU's. So today's props are adding more and more complexity.
They demand more CPU cycles to decode frames, build render graphs, and encode metal render passes.
Doing all this on a single CPU thread is not sufficient for today's devices.
The latest iPhone has six cores and a Mac Pro can have up to 28.
Therefore scalable multithread architecture is key to great performance on all of our devices.
Metal is designed for multithreading.
In this section, let's look at two ways how you can parallelize your encoding on the CPU. So I'm going to set up an example of a typical video frame. With a classic single threaded rendering, you could serially decode frames and build commands into a single command buffer in GPU execution order. And you typically have to fit this into some tiny fraction of your frame time.
And of course, you're going to have maximum latency because you have to encode the entire command buffer before the GPU can consume it. Obviously, there's a better way to do this. So what we're going to do is start by building in parallelism with the CPU. Render blit and compute passes are the basic granularity of multithreading on Metal. All you need to do is create multiple command buffers and start encoding passes into each on a separate thread.
You can encode in any order you wish. The final order of execution is determined by the order that you added to the command queue. So now let's look at how you can do this in your code.
Encoding multiple command buffers is actually quite simple. The first thing we do is we create any number of Metal command buffer objects from the queue.
Next, we define the GPU execution order up front by using the enqueue interface. This is great because you could do it early and you don't have to wait for encoding to complete first. And finally, for each command buffer we create a separate thread using the asynchronous dispatch queue and encode passes for the frame and that's it. It's really fast and it's really simple.
So as you could see in our example, we've done a good job parallelizing with multiple Metal command buffer objects, but what if you have one really large effects and blending pass? In this case, Metal offers a dedicated parallel encoder that allows you to encode on multiple threads without explicitly dividing up the render pass or the command buffer. Let's take a look at how easy this is to doing your application.
So here, the first thing we do is create a parallel encoder from the command buffer.
Then we create any number of subordinate coders and this is actually where we define the GPU execution order by the order that we create the subordinates.
Next, we create a separate thread and call our encoding function for each. This is where the effects and blending will be processed.
And finally we set up a notification when the threads are complete and we end parallelizing encoding, and that's it. That's all you have to do. It's very simple and very efficient. So I've shown you two ways on how to parallelize on the CPU. Now let's see how Metal can help you to leverage asynchronous GPU channels.
Modern GPU's today have a common capability. They each contain a number of channels that allow you to execute asynchronously so this means that you can potentially decode video on one channel while also executing 3D effects on another.
Metal could extract this type of parallelism in two ways. The first comes naturally just by using the render, blit, and compute encoders for the appropriate workloads. The other way Metal extracts parallelism is by analyzing your data dependencies. But the most compelling detail of all here is you get most of this for free. Metal does a lot of this for you under the hood.
Let's see how. So let's look at how the GPU executes a series of these frames. Here I have another video frame example. In your application we're going to be decoding with Video Toolbox followed by using the blit encoder to upload those frames from system to VRAM. Then we'll apply filtering with compute and effects and blending with render.
This work will happen repetitively for each frame. So now let's see how this gets executed on both the CPU and the GPU in a timeline diagram. Let's also see if we can apply some optimizations to improve concurrency. The first thing we're going to do is encode frame one commands using the various encoders on separate threads. This work is going to get scheduled and eventually executed across all the channels. And then we continue on with frames two, three, and four. Thanks to Metal, you can see that we're already achieving some parallelism for free.
But we can also see there's a lot of gaps. This means that some of the threads and channels are sitting idle during our valuable frame time. To maintain efficiency, we want to saturate our channels as much as possible.
Metal can't always do all this for us. So in this case it's time to apply some optimizations.
You'll notice on the CPU there is extremely large gaps. This can happen for many reasons but for simplicity I'll focus on a common mistake. Sometimes applications gratuitously call or wait until completed after encoding and committing a command buffer.
In this scenario it's creating large gaps or bubbles for the duration of our decode workload. It's also causing small gaps in the decode channel in the GPU. To fix that, we can try to replace the weight with a completion handler.
This will avoid blocking on the CPU and schedule any post processing after the GPU is completed. Let's try that and see where it gets us.
So you can see that's much better. We're now keeping our CPU threads busy. You will also notice that the decoding channel is saturated really nicely. We could still see quite a few gaps in the blit, compute, and render channels.
Looking closely, you can see that there is a rewrite dependency where the upload can't begin until the decode is finished.
One solution to fix this problem is to decode say 10 frames ahead. This will remove that dependency. Let's try it and see what happens.
So now our resource updates look great. We're saturating both the video and the blit channels, but you'll notice that there is still a few gaps in the compute and render channels.
Similar to last time if you look closely, you could see that there's another dependency but the filtering cannot begin until the blit channel has uploaded all the data.
Similar to before, we can fix this by preloading our bit maps ahead of time. This will remove that dependency.
And with this, we've now closed most of the gaps and we have a really efficient pipeline. So now that I've reviewed the GPU channels and some example optimizations, let's see how to continue scaling performance on more GPU's.
GPU's are quickly becoming a performance multiplier.
Supporting more GPU's can accelerate image processing, video editing, and improve your overall frame rate. In this section, I'm first going to go over how Metal can be used to leverage multi GPU configurations.
Then I'll show you a few load balancing strategies proven effective by Pro App developers today. And finally, I'll discuss how to synchronize operations between your GPU's.
So what can Metal do for your Pro App? To start, Metal gives you all the tools you need to detect all the connected GPU's and their capabilities.
With Metal it's easy to manage multiple GPU's because they're essentially just separate Metal device objects. So program them as the same as you do today for a single GPU.
Metal also supports a brand-new peer group transferring PI. This incorporates the concept of remote texture views which allow you to copy data between GPU's.
And finally, Metal offers powerful shared events that allow you to synchronize your workloads between GPU's. Now let's take a quick look at how to detect multi GPU configurations.
Metal exposes device properties to identify the location, location number, and max transfer rate for each device. This information could be used to say determine the fastest possible hosted device transfer device. It can also be used to determine if a device is integrated, discreet, or external or even low power or headless.
So once we're able to detect multiple GPU's with this, it's time to think about how to balance your workloads.
There is many, many ways to load balance between GPU's, and there's a lot of design decisions that you have to consider when you select strategy. At the end of the day what we seek is a really simple load balancing strategy with higher scale and efficiency. Let's go over a few proven strategies that some Pro App developers are using today. The first and most straightforward is supporting alternating frames. So the concept is to ping pong odd and even frames between the two GPU's. This easily fits into existing architectures and can potentially double the rate that you process frames. However, sometimes apps have variable workloads like UI updates or graph building, and this might result in unbalanced load balancing. So let's take a look at another strategy. This one uses small 32 by 32-pixel tiles to distribute rendering more evenly among the GPU's. So if you have four GPU's, you can preselect separate tile groups for each. Here we use a random assignment to avoid too much correlation with the scene. This means that mapping of tiles to GPU's is constant from frame to frame. This is a really good solution for compute heavy workloads but might not be the best choice for bandwidth intensive ones. To see this in more detail, check out the rate tracing section. So here's a similar approach that uses a tile queue. In this case, the host application can populate the queue with all the tiles. They can then be dequeued on demand by each GPU based on an algorithm that keeps the GPU's busy.
This approach may provide really good load balancing but it is adding more complexity.
So once we've decided on our load balancing scheme, we need to think about how to synchronize our workloads between the GPU's. To accomplish this, Metal provides a powerful construct called shared events. They allow you to specify synchronization points in your app where you can wait and signal for specific command completion.
This can be done across GPU's, between a CPU and the GPU, and across processes. Let's put this into practice.
So here's an example of a single GPU workload that performs a motion analysis on pairs of frames. Notice that these are all render workloads so we can't take advantage of the parallel asynchronous channels that we talked about earlier, but if we have two GPU's, we can divide this work between them to improve performance. So the strategy here is to move the motion analysis to the second GPU. Keep in mind that each motion pass has to analyze the previous pair of frames. This means that we have to wait for the previous frames to be written before we read them from the motion pass and this repeats for each frame pair. So we can accomplish this by using Metal shared events. First, we need to signal completion when the frames are done rendering, and then we wait for that signal before reading them with motion pass. And with this, we can safely offload the motion analysis to a second GPU and everything runs in parallel. And because the signal and wait are encoded on the GPU, you don't block any CPU execution.
So now let's take a look at how we can do this in our code. So the first thing we're going to do is create a shared event from the device that renders our frames. We also create two command queues, one for each device.
Now to render the frames, we create a command buffer and encode, then immediately encode a signal event to notify the other GPU's that we're complete.
And finally, to encode the motion, we start by creating a command buffer from the queue. Then immediately encode a wait event to avoid reading the frames before they're done.
And then we encode the motion analysis and commit, and as you can see it's a fairly straightforward process and it's very powerful. And before I move on, let's take a look at how we can look at multi GPU's and channels in our tools. So Metal System Trace shows the work for each of your test GPU's. In this example we're using four GPU's. One internal, and three external GPU's. It exposes detailed visibility into each GPU by showing all the asynchronous workloads across all the channels, and it maps those workloads with relevant symbol names. In the activity summary, you could actually see all the execution statistics for all the connected GPU's.
You could even dive deeper to see more detailed channel information for any GPU on a per frame basis. This includes details for page on and page off in the blit channel or compute and render workloads.
You can even drill down to see IOSurface access. As Eugene mentioned, this is something that's very useful because a lot of Pro Apps need to utilize IOSurfaces, which is really necessary for framework interoperability. And finally, our tools give you visibility into Metal events and shared events. So you can actually see where the signal and wait events occur. It also shows how many milliseconds are spent waiting and draws dependency lines for you to follow.
And finally at the bottom, there's even detailed lists about your events in the activity summary. So Metal system trace is a great tool for all your Pro App needs. So now that we understand how to utilize multiple GPU's, let's look at how to transfer data between them.
Scaling performance across CPU's and GPU's is extremely important, but at the end of the day your Pro App is only as fast as its slowest bottleneck.
When you're transferring massive 8K frames, your data transfers can quickly become that bottleneck. In this section, I'm going to talk about bandwidth considerations and how they relate to the new Mac Pro.
Then I'll review a few Metal peer groups transfer strategies, and some of these are already in use today by Pro App developers. And finally I'll walk you through an example use case to show how Infinity Fabric Link can help unlock challenging workflows. So let's start by looking at the transfer rates for our key connection points. Our baseline here is PCI Express gen 3 with 16 links.
So first we have Thunderbolt 3. In the real world this maxes out around one-quarter of the rate of PCI Express. It's a really great scalable solution for compute heavy workloads but maybe not the best for bandwidth intensive ones. Next we have two GPU's each with their one PCI lanes. This can double your bandwidth.
And this week we introduced the new Infinity Fabric Link with the peer group transfer API which can transfer data between GPU's at speeds up to five times that of PCI Express. So now let's look at some common Mac Pro configurations. This diagram illustrates a great configuration for bandwidth intensive ones.
Here we have a new Apple Afterburner which has its own dedicated PCI lanes.
We also have two internal GPU's with their own dedicated PCI lanes.
And finally, you can connect those GPU's with Infinity Fabric Link to quickly copy data between them.
The Mac Pro also allows you to have up to four internal GPU's that share two sets of PCI lanes.
Because the lanes are shared, it lends itself maybe to a more compute heavy pro application. And in this case, it can also be connected with the Infinity Fabric Link. So there is many, many ways to manage these transfer strategies. I'm going to go over a few proven strategies that some Pro App developers are using today.
The most straightforward approach is to transfer entire frames for display. The premise is to process alternating frames. Any frame processed on the auxiliary device can be transferred quickly to the display attached GPU and then sent to the display. Another transfer strategy is to send tiles to each GPU that are essentially pieces of the entire frame. All the tiles processed on the auxiliary device can be sent to the display GPU and then reconstructed as part of the final output image.
This result has really good load balancing.
So we've looked at two strategies quickly. Now let's see a great example of a Pro App actually leveraging the Infinity Fabric Link.
So over the last six months, I've had the opportunity to collaborate with the Final Cut Pro team. They've done an outstanding job optimizing for the new Mac Pro. They're scaling across 28 CPU cores and all internal GPU's.
They've also fully utilized the Infinity Fabric Link. This is helping them to enable real time editing of multiple 8K ProRes video streams.
Now let's take a closer look at how this works.
So here we have a simple timeline diagram that shows how video streams move from the CPU to the display. In this case we're focusing on playback of three 8k ProRes raw video streams with some effects.
This is how it might look on a single GPU.
So first, we encode frame one commands on the CPU.
Then upload all three streams over PCI to VRAM.
Finally we process those streams with effects on the GPU and display. We continue this process for each of the additional frames.
And as much as we want this to fit within our 30 frames per second, it won't. It's just too much work to pack into that space. A Pro App will drop at least 30% of their frames in this scenario. Now let's see how this might work on a dual GPU system.
So first, we encode frame one as in the previous example.
For frame two, we follow a similar process. Now this is looking really good. We've got things going in parallel here. But do we double our frame rate? Unfortunately, we don't. The problem comes when any frame that we've processed on the auxiliary device has to somehow be copied back to the display attach device, and this is where things get tricky. To get the display GPU, we have to copy a 265-megabyte output buffer over PCI to the host, and then we copy a second time from there to the display attached GPU.
This can take up to 48 milliseconds on a good day. So now, let's continue with frames three and four to give you a better picture.
And you can quickly see that we're using a considerable amount of PCI bandwidth but also we see a lot of gaps and dependencies. We're still doing better than the single GPU case, but it's not going to double our frame rate.
All this PCI traffic will result in dropping some frames. But to improve on this problem, the Mac Pro introduces the new Infinity Fabric Link feature with the peer group API. This completely blows away the GPU copy.
You could see here with Infinity Fabric Link the transfer is much faster. It also frees up a considerable amount of PCI bandwidth and with that bandwidth we can upload our frames earlier.
Infinity Fabric Link also operates on its own parallel GPU channel. This means you could transfer data while using the render and compute channels at the same time.
This helps us to improve concurrency and hide latency. At the end of the day, this can enable your Pro App to unlock challenging workloads and enable new use cases. So this is what it looks like on a boring timeline diagram. But now let's see what it looks in action. This is the Final Cut Pro demo you saw in the keynote. You can see it plays back multiple streams of 8K video with effects and transitions. This is also done in real time using multiple GPU's and the Infinity Fabric Link.
Final Cut Pro is an outstanding example of a Pro App utilizing efficient data transfers. So now before we close this section, let's look at how to use Infinity Fabric Link and the peer grant transfer group API in your code. So the first thing you need to do is detect these connections. To facilitate this, Metal defines a brand-new peer group API, defines properties on the Metal device for peer group ID, index, and count.
With this you can detect if you have linked GPU's and if they have shared PCI lanes or dual PCI lanes. More importantly, you can use this to determine the best configuration for you and scale your performance based on the bandwidth limitations.
And this is how you transfer data between GPU's. The first thing you need to do is create your shared event from the auxiliary device.
We also create a render texture and a remote texture view. The remote view will give our display attached GPU access to the auxiliary texture.
Next we create an encoder and render.
This should immediately be followed by the encoded signal event.
Now on the display device we create a blit command buffer. We immediately encode a wait event. So we wait for the rendering to complete before transferring the data. And finally we do a copy using the textured view, and that's it. Very simple.
Utilizing Metal peer group API to leverage Infinity Fabric Link can unlock challenging workloads by reducing your PCI bandwidth. It also can enhance concurrency by using a parallel channel. So before I conclude this session, let's look at one more really great Pro App in action.
So now I'm excited to share a demo of Affinity Photo from Serif Labs. The engineers at Serif have done an outstanding job of adopting Metal. They're also a really, really good example of how to officially leverage platform resources. On a typical document, their performance can be around 10 times faster on a single GPU when compared to an eight course CPU.
Let's take a look.
So in this example, Affinity is going to be live compositing a massive document called the rabbit trick. As the video demonstrates, it has hundreds of massive layers, and they'll be compositing at 4K resolution.
Some layers have pixel data while others have procedural adjustments.
This will be hierarchically composited in real time, and this will also put a tremendous load on both the CPU and the GPU.
Now let's run this massive document on the CPU. This is using an 18-core system. You could see that we're able to composite in real time; however, the document is so complex it gets a little bit choppy in the user interface.
Now let's switch and run that on a single GPU.
Here, you can see the UI responds really well and everything runs smoothly. The frame rate runs about 18 to 20 frames per second.
And now for the best part. We're going to enable a total of four external GPU's and as you can see it runs incredibly smooth and it maintains greater than 60 frames per second the entire time. This is due in part to Affinity's advanced tile-based load balancing scheme. They can distribute their work efficiently among any number of GPU's, and with this they can achieve linear performance scaling. Here is one last example that I want to share.
This is one of Affinity Photo's most memory bandwidth intensive filters known as depth of field.
Here we're previewing in real time on the CPU. You can visually see the time it takes between applying the effect and it actually rendering.
This is still impressive, and it's fast, but the GPU can make this even better.
So now we're going to run the same effect with four external GPU's. You could see here it runs amazingly smooth and easily maintains a frame rate greater than 60 frames per second.
This particular filter is memory bandwidth intensive. So we get great improvement here because of the massive memory bandwidth available on modern GPU's today. And this is an outstanding example of how to officially scale performance across multiple GPU's. So before we close this session, let's review some of the key takeaways.
Apple provides a wealth of frameworks to solve all your Pro App needs.
You can leverage this ecosystem to achieve real-time editing performance on 8k content with a predictable frame rate.
Apple's AV Foundation and Core Animation Metal Layer provide API's to seamlessly support high dynamic range. You can couple this with HDR TV's and Apple's new Pro Display XDR to generate amazing videos and images. The Mac Pro can have up to 28 CPU cores and four internal GPU's. Metal provides all the API for you to scale your performance across all these devices.
And finally, we introduced a new hardware feature Affinity Fabric Link with a Metal peer group API.
This empowers you to leverage this connection to unlock new and exciting use cases.
For more information, please visit our website and please visit us in tomorrow's lab. Also check out additional Metal labs on Friday. Thank you very much.
[ Applause ]
-