-
Metal 앱용 기계 학습 최적화하기
Metal의 가속 ML(Machine Learning) 훈련에 대한 최신 개선 사항을 확인하세요. 파이토치와 텐서플로의 업데이트 사항을 살펴보고, JAX용 Metal 가속에 대해 알아보세요. GPU와 Apple Neural Engine을 모두 사용할 때 MPS 그래프가 어떻게 더 빠른 ML 추론을 지원하는지 보여드리고, 동일한 API로 어떻게 코어 ML과 ONNX 모델을 빠르게 통합할 수 있는지 공유합니다. 기계 학습에 Metal을 사용하는 방법에 대한 자세한 내용은 WWDC22의 'Metal로 기계 학습 가속하기'를 확인하세요.
리소스
관련 비디오
WWDC22
-
비디오 검색…
♪ ♪
안녕하세요 저는 데니스 비에리우입니다 소프트웨어 엔지니어로서 Apple의 GPU, 그래픽, 디스플레이 소프트웨어 팀 소속이죠 오늘 소개해 드릴 모든 기능과 개선 사항은 올해 Metal의 기계 학습에 도입된 것들입니다 먼저 기존 기계 학습 백엔드를 간략히 설명하겠습니다 Metal 기계 학습 API는 Metal Performance Shaders 프레임워크를 통해 노출됩니다 MPS는 이미지 처리, 선형 대수 및 기계 학습과 같은 다양한 분야를 위한 고성능 GPU 프리미티브 컬렉션이죠 MPSGraph는 범용 컴퓨팅 그래프로 MPS 프레임워크 위에 위치하며 다차원 텐서까지 지원을 확장합니다 CoreML과 같은 기계 학습 추론 프레임워크는 MPSGraph 백엔드 위에 구축됩니다 MPSGraph는 텐서플로 및 파이토치와 같은 훈련 프레임워크도 지원합니다 MPSGraph와 ML 프레임워크에 대한 자세한 내용은 아래에 나오는 Metal 관련 예전 WWDC 세션을 참조하세요
이 세션에서 중점을 둘 것은 파이토치와 텐서플로 Metal 백엔드에 추가된 업데이트 및 개선 사항과 JAX를 위한 새로운 GPU 가속 그리고 ML 추론을 위해 MPSGraph에 올해 추가된 기능입니다
파이토치와 텐서플로 Metal 가속을 사용하면 MPS의 고효율 커널을 써서 Mac에서 최고의 성능을 얻을 수 있습니다 파이토치 Metal 가속은 버전 1.12부터 쓸 수 있습니다 MPS 백엔드를 통해서요 이는 작년에 파이토치 생태계에 도입되었으며 그 이후 여러 가지가 개선되었습니다 메모리 사용과 뷰 텐서를 최적화하기 위해서요 올해 파이토치 2.0 MPS 백엔드는 큰 도약을 이루었으며 베타 스테이지에 도달하였습니다 하지만 이것만 개선된 것은 아닙니다 최신 파이토치 빌드에는 업데이트된 사항이 많은데요 MPS 작업 프로파일링 사용자 맞춤형 커널 자동 혼합 정밀도 지원과 같은 많은 것이 포함돼 있죠 nightly build 기능을 모두 다루기 전에 파이토치 2.0의 새로운 기능부터 시작하겠습니다
가장 많이 쓰는 상위 60개 Torch 연산자를 지원하는데요 그리드 샘플러, triangular solve topk 등이 포함되죠
테스트 범위도 크게 개선되었습니다 대부분의 Torch 연산자에 대한 테스트 그레이디언트 테스팅 ModuleInfo 기반 테스팅이 포함되죠
출시 이후 네트워크 범위도 확장되었습니다 여러 인기 모델이 macOS의 공식 백엔드로 MPS를 채택하면서요 여기에는 WhisperAI와 같은 기초 모델 YOLO와 같은 객체 감지 모델 안정적 확산 모델 등이 포함되죠 최신 파이토치 2.0을 사용하여 이런 모델 중 하나를 작동해 보죠 이 예제에서는 YoloV5를 쓸게요 M2 Max에서 실행되는 객체 감지 네트워크죠 왼쪽에서는 네트워크를 실행시켜 파이토치 MPS 백엔드를 사용하여 실시간 이미지를 생성하는 반면 오른쪽은 완전히 동일한 모델이지만 CPU에서 실행되고 있습니다 백엔드를 사용하는 왼쪽이 훨씬 더 높은 프레임률로 실행되죠
또한 개발자들은 외부 네트워크에 파이토치 MPS 백엔드를 채택했으며 여러 새로운 연산자를 위한 코드도 기증했죠 히스토그램과 GroupNorm signbit 같은 것들요
다음으로 소개할 새로운 기능은 최신 파이토치 빌드에서 사용 가능한 것입니다 MPS 연산에 대한 프로파일링 지원부터 시작해 보죠 파이토치 nightly build에는 프로파일링 지원이 있습니다 OS signpost를 써서 연산의 정확한 실행 시간을 알려주고 CPU와 GPU 간의 사본 지원되지 않는 연산자로 인한 CPU로의 폴백 등을 지원하죠 프로파일링 데이터의 시각화는 매우 친숙한 도구인 Insturments의 일부인 Metal System Trace로 할 수 있죠 Metal 시스템 트레이스를 사용한 ML 앱 프로파일링에 대해 자세히 알아보려면 작년 세션인 'Metal로 기계 학습 가속하기'를 시청해 보세요 프로파일러는 매우 간단하게 사용할 수 있습니다 MPS 프로파일러 패키지에서 start 메서드를 호출하여 트레이스를 활성화하고 스크립트 말미에 stop 메서드를 써 프로파일링을 종료하면 되죠 이제 프로파일러를 사용하여 예제를 디버깅해 보겠습니다 이 샘플 네트워크는 순차 모델을 사용합니다 선형 변환과 Softshrink 활성화 기능으로 구성된 이 순차 모델에는 레이어가 총 일곱 개 있습니다 이 모델의 현재 성능은 만족스럽지 않습니다 이 경우 프로파일러를 사용하여 병목 지점을 찾을 수 있죠
Metal 시스템 트레이스에서 먼저 os_signpost를 활성화하면 파이토치 연산자 정보를 캡처할 수 있습니다 다음으로, 기기와 올바른 실행 파일이 시작됐는지 확인하죠 이 경우엔 파이썬 이진 파일입니다 기록 버튼을 클릭합니다 이제 Instrument가 파이토치 실행을 기록합니다 데이터를 충분히 캡처할 수 있도록 몇 초 동안 실행하겠습니다 그런 다음 중지를 클릭하고
os_signpost 탭에서 파이토치 Intervals 타임라인을 표시합니다 이 타임라인에는 연산자의 실행 시간 파이토치 메타데이터 문자열 식별자 데이터 유형, 길이 복사 등이 표시됩니다
타임라인을 확대하면 이 예제에서 사용된 파이토치 연산자를 확인할 수 있죠 이 트레이스의 패턴은 쉽게 알아볼 수 있습니다 레이어 일곱 개로 구성된 맞춤형 순차 모델이 쉽게 식별되죠
트레이스를 보면 병목 현상이 CPU로 간 Softshrink 폴백에서 나타난다는 것을 알 수 있습니다 이 프로세스는 매우 비효율적입니다 이 모델은 Softshrink 연산자의 CPU 실행과 추가 복사본으로 인해 오버헤드가 발생하고 GPU는 수행할 작업이 없습니다 GPU 타임라인의 대부분의 공백은 Softshrink 활성화 함수가 CPU로 폴백하는 데서 비롯됩니다 이 문제를 해결하기 위해 맞춤형 커널을 작성하여 성능을 개선하겠습니다 맞춤형 연산을 작성하려면 다음과 같은 네 단계를 거칩니다 먼저 Objective-C와 Metal에서 연산을 구현합니다 다음으로 Objective-C 코드에 대한 Python 바인딩을 생성하고 확장 프로그램을 컴파일합니다 마지막으로 확장 프로그램이 빌드되면 연산을 훈련 스크립트로 가져와서 사용을 시작합니다 작업 구현부터 시작하겠습니다
Torch 확장 프로그램 헤더를 가져오는 것으로 시작하죠 C++ 확장 프로그램을 작성하는 데 필요한 모든 파이토치 비트가 포함되어 있습니다
그런 다음 compute 함수를 정의하고 get_command_buffer MPS 백엔드 API를 사용하여 MPSStream 명령 버퍼에 대한 참조를 가져오고 마찬가지로 get_dispatch_queue API를 사용하여 직렬 큐에 대한 참조를 가져옵니다 다음으로 명령 버퍼를 사용하여 인코더를 만들고 맞춤형 GPU 커널을 정의합니다
다중 스레드의 제출이 직렬화되도록 디스패치 대기열 내부에서 커널을 인코딩합니다
모든 작업이 인코딩된 후 동기화 API를 사용하여 현재 명령 버퍼의 실행이 완료될 때까지 기다리면 직렬화된 제출을 관찰할 수 있습니다 아니면 직렬화가 필요하지 않다면 commit API를 사용하십시오 다음으로 맞춤형 함수를 바인딩하죠 PYBIND11을 사용하여 매우 간단한 방식으로 Objective-C 함수를 파이썬에 바인딩할 수 있습니다 이 확장 프로그램의 경우, 필요한 바인딩 코드는 두 줄에 불과합니다
바인딩 후 확장 프로그램을 컴파일합니다 먼저 torch.utils.cpp_extension을 가져옵니다 이것은 확장 프로그램을 컴파일하는 데 사용할 수 있는 load 함수를 제공하죠 그런 다음 빌드할 확장 프로그램 이름을 전달하고 소스 코드 파일에 대한 상대 또는 절대 경로 목록을 전달하세요 선택 사항으로, 빌드에 전달할 추가 컴파일러 플래그를 나열할 수도 있죠 load 함수는 소스 파일을 공유 라이브러리로 컴파일하고 이후 현재 파이썬 프로세스에 모듈로 로드됩니다
마지막으로 스크립트로 연산자를 불러와서 사용을 시작하세요
컴파일된 라이브러리를 불러와서 시작하고 이전 순차 모델을 변경하여 맞춤형 Softshrink 커널을 사용합니다
동일한 모델을 다시 실행하고 결과를 확인하겠습니다 새로 추가된 맞춤형 연산자를 사용하면 모델이 훨씬 더 효율적으로 실행됩니다
폴백에 의해 생성된 모든 사본과 중간 텐서가 CPU에 전달되지 않고 순차 모델이 훨씬 빠르게 실행됩니다 이제 네트워크를 더 개선할 수 있는 더 많은 방법을 살펴보겠습니다
파이토치 MPS 백엔드는 이제 자동 혼합 정밀도를 지원하므로 적은 메모리를 사용하여 품질 손실 없이 더 빠르게 학습할 수 있습니다 혼합 정밀도를 이해하기 위해 먼저 지원되는 데이터 유형을 알아보겠습니다 혼합 정밀도 훈련은 단정밀도 부동 소수점과 반정밀도 부동 소수점이 혼합된 딥 러닝 모델을 훈련하는 모드죠 macOS Sonoma부터 MPSGraph는 새로운 데이터 유형인 bfloat16에 대한 지원을 추가했습니다 bfloat16은 딥 러닝용 16비트 부동 소수점 형식입니다 부호 비트 한 개 지수 비트 여덟 개 맨티사 비트 일곱 개로 구성되며 이는 딥 러닝 응용 프로그램을 염두에 두고 설계되지 않은 표준 IEEE 16비트 부동 소수점 형식과는 다르며 자동 혼합 정밀도는 float16과 bfloat16 모두에 대해 활성화되죠 자동 혼합 정밀도는 레이어별로 적절한 정밀도를 선택할 때 기본 정밀도로 네트워크의 성능을 측정하여 정하고 혼합 정밀도 설정으로 다시 실행합니다 정확도에 영향을 주지 않고 성능을 최적화하기 위해서요 신경망의 일부 레이어는 콘볼루션 레이어나 선형 레이어처럼 낮은 정밀도로 실행될 수 있습니다 리덕션과 같은 다른 레이어는 종종 더 높은 정밀도 수준이 필요합니다
네트워크에 자동 혼합 정밀도 지원을 추가하는 것은 매우 쉬운 프로세스입니다 먼저, autocast를 추가합니다 float16과 bfloat16이 모두 지원되며 autocast는 스크립트의 특정 영역이 혼합 정밀도로 실행되게 하는 콘텍스트 관리자 역할을 합니다
여기서 MPS 연산은 autocast가 선택한 데이터 유형으로 실행되어 정확도를 유지하면서 성능을 향상합니다
MPS 백엔드도 크게 최적화되었습니다 파이토치 2.0 및 macOS Sonoma에서 MPS 백엔드는 이전 릴리스에 비해 최대 다섯 배 빠릅니다 파이토치에 대한 설명은 이만 마치고 이제 텐서플로로 넘어가겠습니다 텐서플로 Metal 백엔드는 안정적인 1.0 릴리스 버전으로 발전했으며 이번 릴리스에서는 그래플러 리매핑 옵티마이저 패스가 플러그인에 추가되었습니다 Metal 플러그인은 또한 혼합 정밀도를 지원하며 설치 프로세스가 이전보다 간단해졌습니다
인식된 계산 패턴의 자동 융합을 추가하여 텐서플로 Metal 백엔드의 성능이 향상되었습니다 이러한 계산에는 융합 콘볼루션을 비롯하여 행렬 곱셈과 옵티마이저 연산 RNN 셀이 포함되며 이 최적화는 계산 그래프가 생성될 때 그래플러 패스를 통해 자동으로 이뤄집니다
이것이 2차원 콘볼루션 연산에 대한 일반적인 계산 예입니다 콘볼루션에는 종종 콘볼루션 신경망의 일반적인 패턴인 덧셈 함수가 뒤따르며 이 패턴을 식별함으로써 그래플러 패스는 계산을 리매핑할 수 있습니다
이를 통해 더욱 최적화된 커널을 사용하여 동일한 출력을 얻을 수 있으므로 성능이 향상됩니다 파이토치와 마찬가지로 텐서플로 역시 혼합 정밀도를 지원합니다 텐서플로는 전체적으로 혼합 정밀도를 설정할 수 있습니다 이를 통해 모든 네트워크 레이어가 자동으로 생성됩니다 요청된 데이터 유형 정책에 맞게요 변경 사항을 표준 워크플로에서 활성화하려면 기존 코드를 약간 수정하면 됩니다
전체 정책은 Float16 또는 BFloat16로 설정할 수 있습니다
성능 향상과 더불어 Metal 가속을 활성화하는 사용자 경험도 간소화되었습니다 이제부터는 패키지 관리자를 통해 텐서플로 휠과 텐서플로-Metal 플러그인을 설치하는 일반적인 경로를 따르기만 하면 Metal 가속을 사용할 수 있습니다 이제 텐서플로 개발을 최신으로 유지하려는 분들을 위해 Metal 가속 지원을 텐서플로의 nightly release에서도 사용할 수 있게 했습니다 이제 JAX용 새 GPU 가속에 대해 이야기해 보겠습니다 올해에는 파이토치 및 텐서플로와 유사하게 Metal 백엔드를 통해 JAX GPU 가속이 지원됩니다 JAX는 고성능 수치 연산 및 기계 학습 연구를 위한 파이썬 라이브러리입니다 대규모 배열 작업에 널리 사용되는 NumPy 프레임워크에 기반하고 있으며 기계 학습 연구를 위한 세 가지 주요 확장을 지원합니다
먼저, grad 함수를 사용하여 자동 미분을 지원하는데요 이 함수는 파이썬 기능의 큰 하위 집합을 통해 미분할 수 있으며 고차 도함수를 취할 수도 있습니다 JAX는 또한 빠르고 효율적인 벡터화를 지원합니다 함수 apply_matrix가 주어지면 파이썬에서 배치 차원을 반복할 수 있지만 최적 성능 이하로 실행될 수 있습니다 이런 경우 vmap을 사용하여 일괄 처리 지원을 자동으로 추가할 수 있죠 또한 JAX를 사용하면 jit라는 API를 사용하여 함수를 최적화된 커널로 적시에 컴파일할 수 있습니다 같은 경우, jit는 vmap 위에서 함수를 변환하여 더 빠르게 실행되도록 하는 데 사용됩니다
M2 Max가 탑재된 MacBook Pro에서 JAX Metal 가속은 이러한 네트워크에서 CPU보다 평균 열 배 빠른 놀라운 속도 향상을 제공합니다 JAX의 환경 설정과 설치에 대한 자세한 내용은 Metal 개발자 리소스 웹 페이지를 참조하세요
이제 주제를 바꿔서 ML 추론으로 넘어가 보겠습니다 먼저 새로운 직렬화 형식인 MPSGraph를 소개합니다 로드 시간을 최적화하는 데 사용되죠 이 새로운 직렬화 형식은 다른 프레임워크의 직렬화된 기존 네트워크에서 생성할 수 있습니다 마지막은 네트워크 메모리 설치 공간을 최적화하는 방법인데 8비트 정수 양자화를 활용하죠 시작하겠습니다 MPSGraph는 계층별로 완전한 유연성을 갖춘 고수준 API를 사용하여 만들 수 있습니다 자세한 내용은 'Metal Performance Shaders Graph로' '맞춤형 ML 모델 구축하기' 영상을 참고하세요 맞춤형 그래프를 정의하고 컴파일한 후 MPSGraphExecutable로 실행하여 결과를 얻습니다 일반적으로 이 프로세스는 훌륭하게 작동하지만 많은 레이어가 있는 복잡한 그래프에서는 이 초기 컴파일로 인해 앱 시작 시간이 길어질 수 있죠
MPSGraph에는 이 문제를 정확히 해결하기 위해 MPSGraphPackage이라는 새로운 직렬화 형식이 있습니다 이 새로운 직렬화 형식을 사용하면 MPSGraphExecutable을 미리 생성할 수 있습니다 일단 생성되면 최적화된 MPSGraphExecutable을 MPSGraphPackage 파일에서 직접 로드할 수 있습니다 MPSGraphPackage 생성은 매우 간단합니다
직렬화 디스크립터를 생성하고 이를 직렬화하고자 하는 MPSGraphExecutable의 직렬화 함수에 전달하기만 하면 됩니다 또한 저장할 경로를 전달해야 하며 패키지를 만든 후 앱에 그래프를 로드하는 방법은 다음과 같습니다 컴파일 디스크립터와 저장된 패키지의 경로가 필요하며 이를 써서 MPSGraphExecutable을 초기화할 수 있습니다 이미 MPSGraph를 사용하고 있다면 우리가 제시한 API를 사용하여 새로운 직렬화 형식을 쉽게 채택할 수 있지만 다른 프레임워크에서 온 경우 이제 새로운 MPSGraphTool을 사용하여 MPSGraphPackage로 쉽게 마이그레이션할 수 있습니다 CoreML 사용자의 경우 ML 프로그램에 MPSGraphTool을 전달하면 MPSGraphPackage가 생성되며 ONNX의 경우에도 ONNX 파일을 입력으로 사용할 수 있습니다 이 새로운 도구를 사용하면 추론 모델을 수동으로 인코딩할 필요 없이 MPSGraph 응용 프로그램에 기존 모델을 빠르게 넣을 수 있죠 명령행 도구를 사용하는 방법은 다음과 같습니다 MPSGraphTool에 입력 모델 유형 여기서는 CoreML 패키지를 선언하는 플래그를 주고 출력 대상 경로와 출력 모델의 이름을 제공하며 대상 플랫폼과 최소 OS 버전을 정의하고 변환 후 생성된 MPSGraphPackage를 앱에 로드하여 직접 실행할 수 있습니다 다음으로 8비트 정수 양자화로 계산의 효율성을 향상하는 방법에 대해 얘기해 보죠 16비트 부동 소수점 형식과 같은 부동 소수점 형식을 사용하여 학습 및 추론을 수행하는 것이 일반적이지만 추론 시 이러한 모델은 결과를 예측하는 데 더 오랜 시간이 걸릴 수 있으므로 그 대신 정밀도를 줄이거나 8비트 정수를 사용하는 것이 많은 경우에 더 좋습니다 이렇게 하면 메모리 대역폭을 절약하고 모델의 메모리 사용량을 줄일 수 있죠
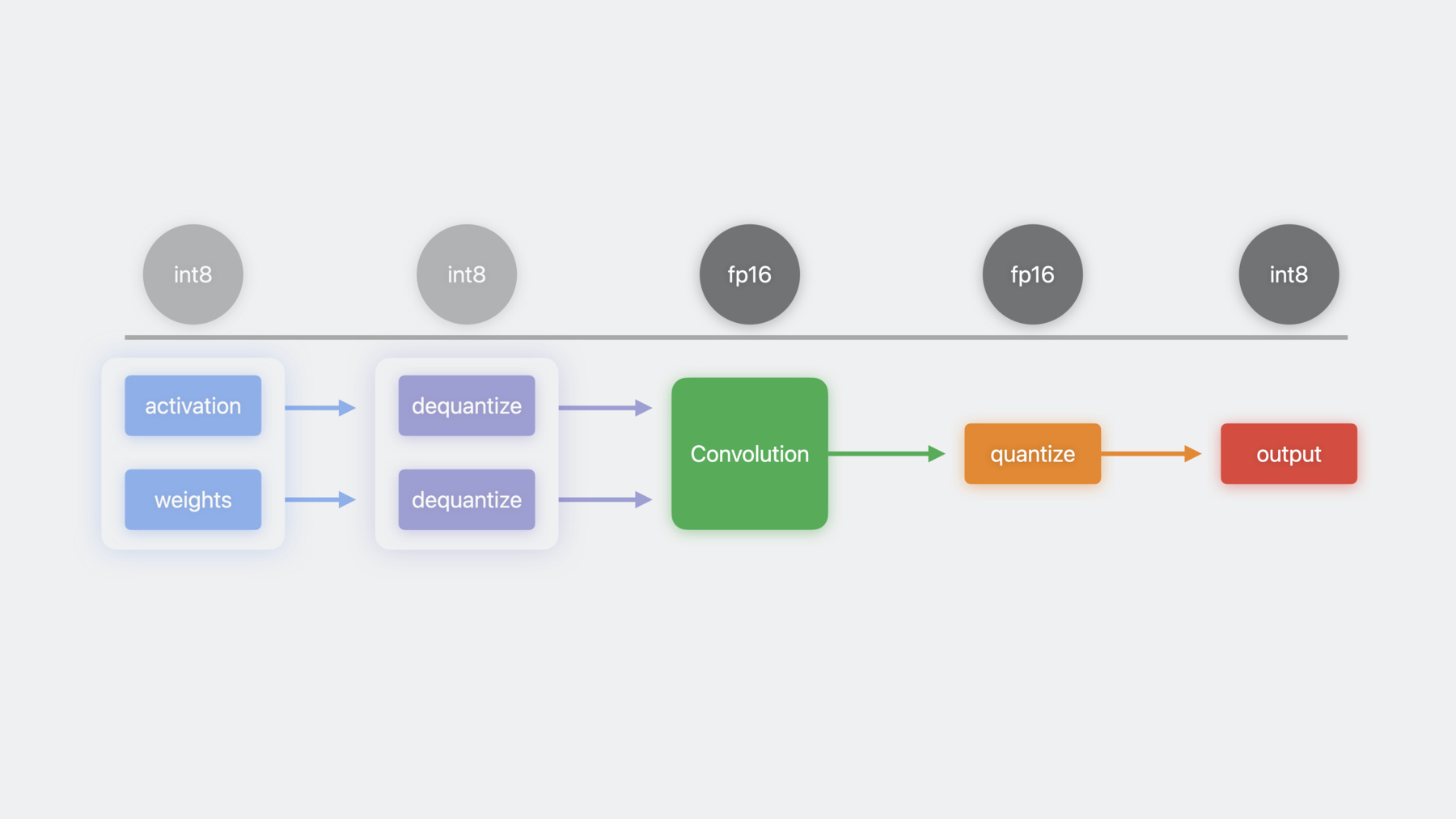
8비트 정수 형식의 경우 양자화에는 대칭과 비대칭의 두 가지 유형이 있으며 MPSGraph는 이제 두 가지 유형 모두에 대한 API를 지원합니다 대칭 양자화에 비해 비대칭 양자화를 사용하면 여기서 zeroPoint로 표시되는 양자화 편향을 지정할 수 있습니다
이제 예제를 통해 양자화된 계산을 사용하는 방법을 살펴보겠습니다 활성화와 가중치를 Int8 형식으로 입력하는 것부터 시작해 보죠 이 입력은 MPSGraph의 dequantizeTensor 연산자를 써서 부동 소수점 형식으로 역양자화됩니다 이제 부동 소수점 입력은 콘볼루션 연산에 입력될 수 있으며 그 결과로 나온 부동 소수점 텐서는 quantizeTensor 연산자를 사용하여 Int8로 다시 양자화될 수 있습니다 MPSGraph는 이러한 모든 커널을 단일 연산으로 자동 융합하여 메모리 대역폭을 절약하고 잠재적 성능 향상이 가능하죠 이것이 MPSGraph에서 양자화 지원을 쓰는 방법입니다
이전의 새로운 기능 외에도 MPSGraph는 더 많은 기계 학습 연산자를 지원하며 올해부터 대부분의 그래프 연산에 대해 복소수 유형이 지원됩니다 복소수는 단정밀도 또는 반정밀도 부동 소수점 형식으로 사용할 수 있으며 복소수 데이터 유형을 기반으로 고속 푸리에 변환을 계산하기 위한 연산자를 추가하여 복소수에서 복소수 복소수에서 실수 실수에서 복소수 변환을 최대 4차원까지 적용합니다 이는 오디오, 비디오, 이미지 처리 응용 프로그램에서 일반적이죠 또한, 이제 MPSGraph를 사용하여 3차원 콘볼루션, 그리드 샘플링 정렬 및 ArgSort, 합계, 곱 최솟값 및 최댓값을 포함한 누적 연산을 수행할 수 있습니다 MPSGraph의 새로운 기능에 대한 설명을 마칩니다 오늘 이 세션에서 발표한 내용을 복습해 보겠습니다 저는 Metal을 통해 파이토치, 텐서플로처럼 인기 있는 ML 프레임워크 가속의 개선 사항을 살펴봤습니다 이제 새로운 Metal 가속 JAX 프레임워크도 활용할 수 있죠 새로운 직렬화 도구를 사용하여 다른 프레임워크의 기존 모델을 MPSGraph에 매끄럽게 통합하는 방법에 대해서도 논의했습니다 이것으로 세션을 마치겠습니다 이 모든 기능을 사용하여 여러분이 만들어 낼 놀라운 콘텐츠가 기대되네요 시청해 주셔서 감사합니다 ♪ ♪
-