-
Create MLで音声識別モデルをトレーニングする
このセッションでは、オーディオファイルやライブオーディオストリームの音声を識別できるCore MLモデルをすばやく簡単に作成する方法を紹介します。音声識別モデルのトレーニングおよび評価機能に加えて、Create ML Appでは、Macのマイクロフォンを使用してリアルタイムでモデルのパフォーマンスをテストすることもできます。新しいSound Analysisフレームワークを使用して、Appで音声識別のオンデバイスモデルを活用しましょう。
リソース
関連ビデオ
WWDC22
WWDC21
WWDC19
-
このビデオを検索
(音楽)
(拍手) おはよう ダン・クリングラーです オーディオチームの ソフトウェア・エンジニアです 私が お話しするのは Create MLを使った 音声分類モデルのトレーニング法です
本題に入る前に 音声分類とは何かを説明し それをアプリケーションに 役立てる方法を話します
音声分類とは 音を数あるカテゴリの 1つに収める作業です
考えてみれば 音声を 分類する方法は多くあります
まず 音声を出す物体で 分けられます ご覧の例では ギターとドラムの音です 人間が音を聞き分けられるのは 物体ごとに音響特性が異なるためです
2つ目の分類法は 音が鳴る場所で分ける方法です ハイキングの時と 都市の中にいる時では 周りの音の特質が異なることに 気付くでしょう 際立つ音がなくても 区別できますね
3つ目の音声分類法は 音声の特性に着目する方法です ご覧の例では 赤ちゃんの笑い声と泣き声です 音声の源は同じでも この2つの特性は大きく違うので 区別できるのです
皆さんのアプリケーションごとに 音声分類の活用法は異なります それなら分類モデルを あなたのアプリケーション専用に トレーニングできたら いいですよね
Xcodeに入っているCreate MLなら それができます 簡単に音声の分類器を トレーニングできます
そのためには まずラベルの付いた音声データを 音声ファイルにして Create MLに読ませます
すると Create MLは そのデータで 音声の分類器をトレーニングします
その音声の分類器をあなたの アプリケーションに使うのです これから このプロセスのデモを お見せします
(拍手)
まずCreate MLを起動します Create MLはXcodeに バンドルされています
新しいドキュメントを作ります テンプレートからSoundを選択
Nextをクリック プロジェクト名は MySoundClassifierです
これをドキュメントの ディレクトリに保存します
Create MLが起動すると このホーム画面が出ます 左のInputタブが選択されています
ここからCreate MLに トレーニングデータを与え 皆さん専用のモデルを トレーニングします
上部にはTrainingとValidation Testingというタブがあり ここにトレーニングの精度が 段階別に表示されます
トレーニングが終了すると Outputタブにモデルができます リアルタイムにモデルと インタラクトもできます
今日は楽器の分類器を トレーニングしてみましょう 楽器は用意しています
TrainingDataディレクトリの中には 音声ファイルがあります
その中には 例えばアコースティックギターや カウベルやシェイカーの音が 録音されています
モデルをトレーニングするには そのディレクトリを 直接Create MLにドラッグします
Create MLは 中の49個の音声ファイルが 7つのクラスに分かれると 認識しました
後は 開始のボタンを押せば トレーニングが始まります Create MLはモデルを トレーニングする際に まず各音声ファイルを調べます そしてファイル全体の 音声の特徴を抽出します 全ての特徴を抽出した後 ご覧のプロセスが始まり モデルの重みが 何度も更新されています
更新されるに従って モデルの性能が向上します またAccuracyも 100%に近づきます それがモデルの収束を 示しています 今日 用意した音声は カウベルとギターのように 大きく異なります なので この音声分類モデルは ご覧のように TrainingでもValidationでも 好成績を収めます
Testingタブは ベンチマークのために 大きなデータセットを読ませる場所です Create MLでは複数のモデルを 同時にトレーニングでき 異なるデータセットも入力できます よってTestingタブでは 異なる設定のモデルに対して 共通のベンチマークが得られます
右端のOutputタブに進みましょう UIを見ればモデルと インタラクトする方法が分かります さて トレーニングセットに 加えなかったファイルを TestingDataの ディレクトリに入れました そのディレクトリを UIにドラッグすると classification testという名の ファイルが認識されます
このファイルをスクロールすると Create MLが冒頭の音声を 背景雑音と分類したようです さらに 次の数秒を人の声 最後をシェイカーと分類しています
この分類が合っているか 調べましょう UI上でファイルを再生できます
テスト 1 2 3 (シェイカー) (拍手) 少なくとも このファイルでは モデルは十分な性能を発揮するようです でも 欲を言えば モデルと リアルタイムでインタラクトしたいです そこで このボタンを付けました Record Microphoneです 録音を開始すると マイクのデータが モデルにフィードされます (拍手) 私が話すと モデルは高い精度で 声と認識しています 私が黙ると モデルも背景雑音を認識します
持ってきた楽器を演奏し 認識するか確かめましょう まず シェイカーです (シェイカー) (拍手) カウベルもあります (カウベル)
もっとカウベルを ご要望にお応えしてカウベルです (カウベル) (拍手) アコースティックギターもあるので 試してみましょう
まず短音の旋律です (ギター) コードも試しましょう (ギター)
(拍手) うまく機能しているので 使えそうです では 録音を止めましょう Create MLでは録音を スクロールして戻し 解析した各セグメントを見られます それで異常や誤りがないか 調べられます また ファイルの一部を トレーニングセットに加え モデルの性能を 高めることもできるでしょう モデルが理想的に 機能してることを確認できれば モデルをデスクトップに移し アプリケーションに統合できます 以上がCreate MLでの 音声の分類器のトレーニングです コードを書かずに 1分以内にできました (拍手)
デモで見たとおり データを収集する際には 注意点があります まず データはディレクトリに 分けられています
ギターの音は全て Guitarディレクトリにあります ドラムや背景雑音も同様です 背景雑音のクラスを 考えてみましょう
楽器の分類器を トレーニングする際にも 楽器が鳴っていない時のことも 考える必要があります 楽器の音声だけで モデルをトレーニングし 次に背景雑音をフィードすると 新しいデータとして認識されます 音声の分類器を トレーニングする際に 背景雑音のある状況で モデルを機能させるには 背景雑音も クラスに加えてください
soundsという名前の ファイルがあるとします 最初にドラムの音が入っており 次に背景雑音に変わり ギターの音で終わるファイルです そのファイルは そのままでは Create MLにドラッグしても 使えません 複数のクラスの音声を含むからです
トレーニングにはラベルの付いた ディレクトリを使わねばなりません ですから この場合には このファイルを3つに分割し それぞれにdrums guitar backgroundと 名づけましょう
ファイルを分ければ モデルをよりよくトレーニングできます
音声データを収集する際は 他にも注意点があります まず データが現実の音響環境に 対応している必要があります
アプリケーションを多様な音響環境で 機能させるには 多様な音響環境で データを集めるか “畳み込み”という技術で 環境を再現してもいいでしょう
もう1つの注意点は マイクのオンデバイス処理です
AVAudioSessionのモードから あなたのアプリケーションでの 処理モードを探してください そしてアプリケーションに 最適なモードか あなたのトレーニングデータに 対応するモードを選ぶのです
最後の注意点はモデルの アーキテクチャを意識することです これは音声の分類器なので 音声はうまく分類できても 純粋な音声認識器などは トレーニングできません よって その目的に適した 道具を使ってください
さて 機械学習のモデルは できました 次はアプリケーションへの 統合方法を話します
アプリケーション内で音声分類モデルを 最も簡単に動かすために SoundAnalysisというフレームワークを リリースしています
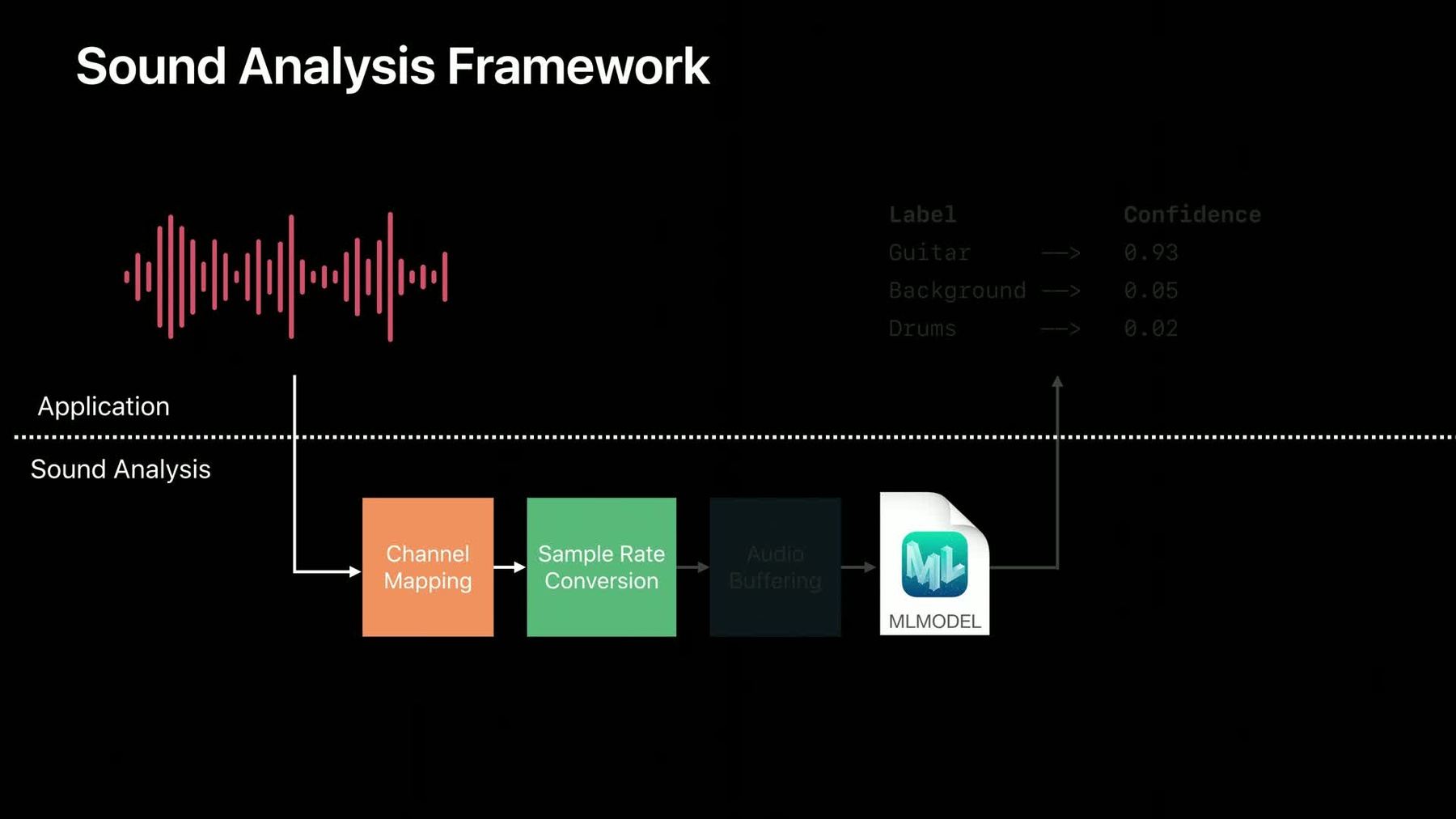
音声を解析する 高度なフレームワークです SoundAnalysisは Core MLモデルを使い 内部で通常の音声操作を行います 例えばチャンネルマッピングや サンプルレートの変更 再ブロック化です
アプリケーション内での SoundAnalysisの動作を見ましょう 上のセクションは アプリケーションを示しています 一方 下のセクションは SoundAnalysisの様子です
まず Create MLでトレーニングした モデルを SoundAnalysisの フレームワークに入れてください
次にアプリケーションが 音声をSoundAnalysisに与えます
その音声は まず チャンネルマッピングの段階に入ります もしモデルが 1チャンネルの音声を 受け付けるのなら それがモデルに供給されます たとえ あなたが ステレオの音声を与えてもです
次の段階はサンプルレートの変更です モデルは元々16khzの音声データで 機能しますから 音声をモデルの要求するレートに 変更するのです
SoundAnalysisの最終段階は 音声のバッファです 今日 使っているモデルのほとんどは 解析のため 決まった量の 音声データを必要とします クライアントである あなたが持つ音声データは 任意のバッファサイズであるかも しれません その際 効率的なリングバッファを 実行し 正しいサイズの音声を モデルに供給するのは大変です そこで モデルの要求するのが 約1秒の音声データなら それをモデルに与えるのが この段階の役割です データがモデルに届けられると アプリケーションは コールバックを受け取ります それには音声を分類した結果の 上位が含まれます これが すばらしいのは 全て自動で行われることです ただ音声をSoundAnalysisに与え 結果をアプリケーションで 使えばいいのです
では SoundAnalysisで得られる 結果に関して少し詳しく話します 音声はストリームであり 画像のように始まりや終わりが あるとは限りません そのため 結果は 少し変に見えるかもしれません
結果には時間の幅があり その幅は解析した音声ブロックに 対応します この例でも 各ブロックはモデルの アーキテクチャに固有のサイズで ご覧のように約1秒です
モデルに音声を与えれば 解析したブロック内での 分類の上位を含む結果が得られます
2番目の結果は1番目の結果と 約50%重なっていますね これは仕様によるものです 注意点は 音声が解析範囲の ほぼ中央になるように与えることです 2つの解析範囲の間に入ると モデルが よい性能を発揮しないのです よってデフォルトでは 50%重なります ただ必要な場合はAPIで 設定を変えられます
音声データを与え続ければ 結果も出続けます
音声ストリームが続く限り 結果はどんどん得られます
ではSound AnalysisのAPIを 見てみましょう
仮に ある音声ファイルを トレーニングした分類器で 解析してみましょう まず SNAudioFileAnalyzerを作成し 解析するファイルのURLを入力します
次に SNClassifySoundRequestを作成し トレーニングしたモデルである MySoundClassifierを インスタンス化します
さらに このリクエストを SNClassifySoundRequestに送り モデルが出す結果を扱う オブザーバを与えます
そうすれば ファイルのスキャンが始まり 結果が出てきます
一方 アプリケーションの側では クラスの1つでSNResultsObserving プロトコルを実行してください それでフレームワークから 結果が得られます
最初に実行するメソッドは didProduce Resultのリクエストです
このメソッドは 何度もコールされる可能性があります 新たなオブザベーションが ある度にです
分類上位の結果と それに関連する タイムレンジを採用するといいでしょう 以上がアプリケーション内における 音声分類イベントでのロジックです
もう1つの興味深いメソッドは didFailWithErrorのリクエストです 何かの理由で解析が失敗すれば このメソッドがコールされます それ以上の結果は Analyzerから得られません 一方 ファイルが終わり ストリームが無事に終了すれば didCompleteのリクエストを 受け取ります
今日のまとめをしましょう
Create MLで音声の分類器を トレーニングする方法を学びましたね
次に SoundAnalysisを使い そのモデルを オンデバイスで動かしました
詳しくはdeveloper.apple.comの 音声分類の記事を見てください デバイスの内臓マイクと AVAudioEngineを使い 音声分類を行う方法が 見つかるでしょう それは楽器を使ったデモに 似ています
聞いてくれてありがとう あなたのアプリケーションでの 音声分類の活用法を早く見たいです (拍手)
-