-
Compose advanced models with Create ML Components
Take your custom machine learning models to the next level with Create ML Components. We'll show you how to work with temporal data like video or audio and compose models that can count repetitive human actions or provide advanced sound classification. We'll also share best practices on using incremental fitting to speed up model training with new data.
For an introduction to custom machine learning models, watch "Get to know Create ML Components" from WWDC22.Resources
Related Videos
WWDC23
WWDC22
- Get to know Create ML Components
- Meet the Presenter: Compose advanced models with Create ML Components
- Meet the Presenter: Get to know Create ML Components
- Q&A: Create ML
- What's new in Create ML
WWDC21
- Discover built-in sound classification in SoundAnalysis
- Meet AsyncSequence
- Meet the Swift Algorithms and Collections packages
WWDC20
WWDC19
-
Search this video…
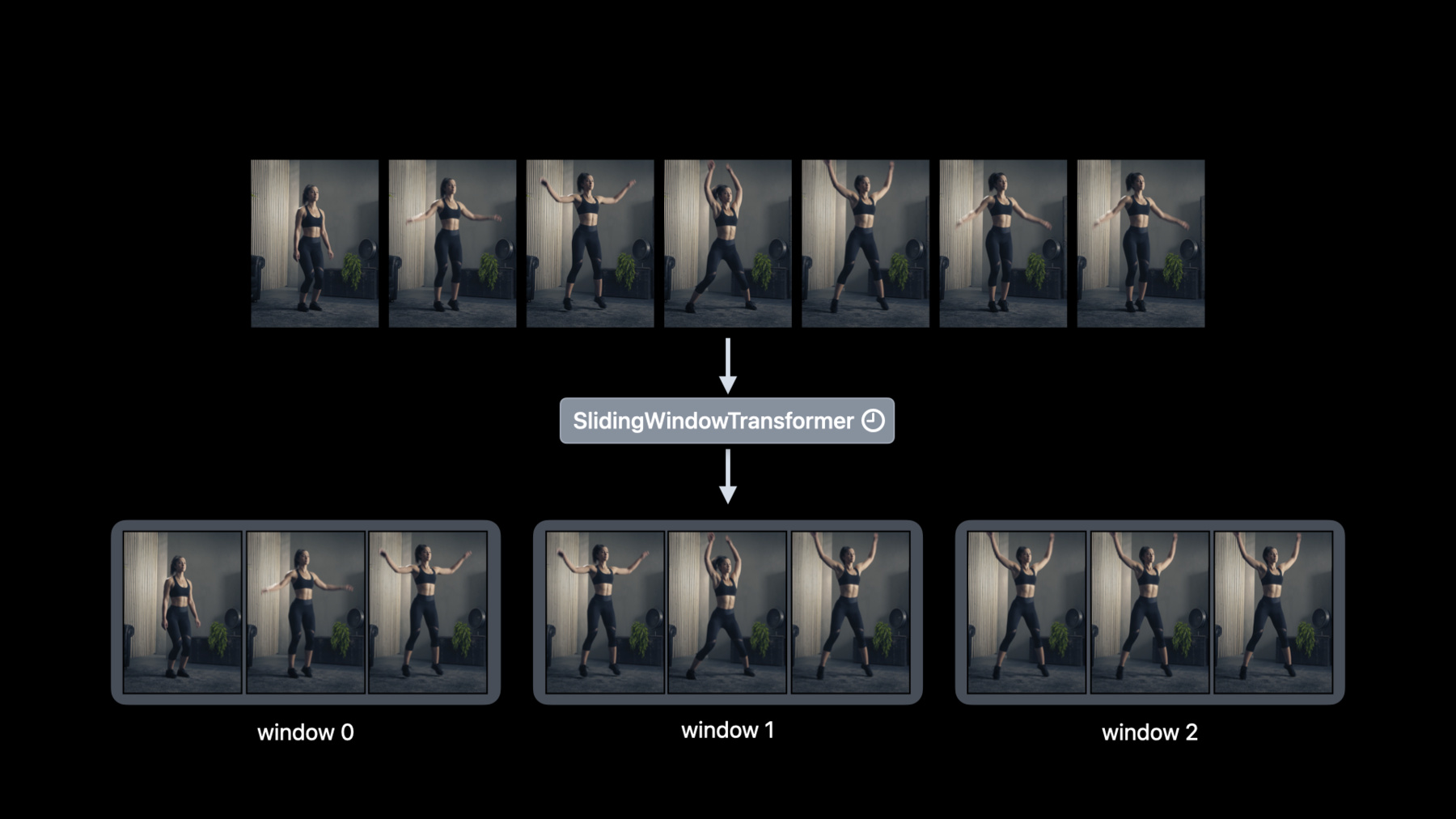
♪ instrumental hip hop music ♪ ♪ Hi, my name is David Findlay, and I'm an engineer on the Create ML team. This session is all about Create ML Components, a powerful new way to build your own machine learning tasks. My colleague Alejandro gave an introduction in the session "Get to know Create ML Components." He explores deconstructing Create ML tasks into components and revealed how easy it is to build custom models. Transformers and estimators are the main building blocks that you can compose together to build custom models like image regression. In this session, I want to go way beyond the basics and demonstrate what's possible with Create ML Components. Let's go over the agenda; there's lots to cover. I'll start by talking about video data and go into detail about new components designed to handle values over time. Then I'll put those concepts to work and build a human action repetition counter using only transformers. Finally, I'll move on to training a custom sound classifier model. I'll discuss incremental fitting which allows you to update your model with batches, stop training early, and checkpoint your model. There's so much opportunity with this level of flexibility. I can't wait to dive in. Let's get started. At WWDC 2020, we introduced Action Classification in Create ML, which allows you to classify actions from videos. And we demonstrated how you can create a fitness classifier to recognize a person's workout routines, such as jumping jacks, lunges, and squats. For example, you can use the action classifier to recognize the action in this video as a jumping jack. But what if you wanted to count your jumping jacks? The first thing you need to consider is that a jumping jack spans consecutive frames, and you'll need a way to handle values over time. Thankfully, Swift's AsyncSequence makes this really easy. If you're unfamiliar with async sequences, you should check out the session "Meet AsyncSequence”. With Create ML Components, you can read your video as an async sequence of frames, using the video reader. And AsyncSequence provides a way of iterating over the frames as they are received from the video. For example, I can easily transform each video frame asynchronously using the map method. This is useful when you want to process frames one at a time. But what if you wanted to process multiple frames at a time? That's where temporal transformers come in. For example, you may want to downsample frames to speed-up an action in a video. You can use a downsampler for that which takes an async sequence and returns a downsampled async sequence. Or you may want to group frames into windows, which is important for counting action repetitions. That's where you can use a sliding window transformer. You can specify a window length, which is how many frames you want to group in a window, and a stride, which is how you control the sliding interval. The input is, again, an async sequence, and the output in this case is a windowed async sequence. Generally speaking, a temporal transformer provides a way to process an async sequence into a new async sequence. So let's put these concepts to work. I don't know about you, but when I'm working out, I always lose count of my reps. So I decided to shake things up a bit and build an action repetition counter with Create ML Components. In this example, I'll go over how to compose transformers and temporal transformers together. Let's start with pose extraction. I can extract poses using the human body pose extractor. The input is an image and the output is an array of human body poses. Behind the scenes, we leverage the Vision framework to extract the poses. Note that images can contain multiple people, which is common for group workouts. That's why the output is an array of poses. But I'm only interested in counting action repetitions for one person at a time. So I'll compose the human body pose extractor with a pose selector. A pose selector takes an array of poses as well as a selection strategy and returns a single pose. There's a few selection strategies to choose from, but for this example, I'll use the rightMostJointLocation strategy. The next step is to group the poses into windows. I'll append a sliding window transformer for that. And I'll use a window length and stride of 90, which will generate nonoverlapping windows of 90 poses. Recall that a sliding window transformer is temporal, which makes the whole task temporal, and the expected input is now an async sequence of frames. Finally, I'll append a human body action counter. This temporal transformer consumes a windowed async sequence of poses and returns a cumulative count of the action repetitions so far. By now, you may have noticed that the count is a floating-point number. And that's because the task counts partial actions too. It's that easy. Now I can count my reps in my workout videos and make sure I'm not cheating. But it would be even better to count repetitions live in an app, so that I can keep track of my current workouts. Let me show you how you can do that. First, I'll use the readCamera method which takes a camera configuration and returns an async sequence of camera frames. Next, I'll adjust the stride parameter to 15 frames so that I get an updated count more often. If my camera captures frames at a rate of 30 frames per second, then I get counts every half second. Now I can workout and not worry about missing a rep. So far, I've explored temporal components for transforming async sequences. Next, I want to focus on training custom models that rely on temporal data. In 2019, we demonstrated how you can train a sound classifier in Create ML. Then in 2021, we introduced enhancements to sound classification. I want to go even further and train a custom sound classifier incrementally. The MLSoundClassifier in the Create ML framework is still the easiest way to train a custom sound classifier model. But when you need more customizability and control, you can use the components under the hood. In its simplest form, the sound classifier has two components: an Audio Feature Print feature extractor and a classifier of your choice. AudioFeaturePrint is a temporal transformer that extracts audio features from an async sequence of audio buffers. Similar to a sliding window transformer, AudioFeaturePrint windows the async sequence then extracts features. There are a few classifiers to choose from, but for this example, I'll use a logistic regression classifier and then compose it together with the feature extractor to build a custom sound classifier. The next step is to fit the custom sound classifier to labeled training data. For more information about collecting training data, the "Get to know Create ML Components" session is a good place to start. So far, I've covered the happy path. But building machine learning models can be an iterative process. For example, you may discover and collect new training data over time and want to refresh your model. It's possible that you can improve the model quality. But retraining your model from scratch is time-consuming. That's because you need to redo feature extraction for all of your previous data. Let me give you an example of how you can save time when training your models with newly discovered data. The key is to preprocess your training data separately from fitting your model. In this example, I can extract audio features separately from the classifier fitting. And this works in general too. Whenever you have a series of transformers followed by an estimator, you can preprocess the input through the transformers leading up to the estimator. All you need to do is call the preprocess method and then fit the model on the preprocessed features. I find this convenient because I didn't need to change the sound classifier composition. Now that I have the features extracted separately, I have the flexibility to only extract audio features for the new data. As you discover new training data for your model, you can easily preprocess this data separately. And then append the supplemental features to the previously extracted ones. This is just the first example of where preprocessing can save you time. Let's go back to the model-building lifecycle. You may need to tune your estimator parameters until you're satisfied with your model's quality. By separating the feature extraction from the fitting, you can extract your features only once and then fit your model with different estimator parameters. Let's go over an example of changing the classifier parameters without redoing feature extraction. Assuming that I've already extracted features, I'll modify the classifier's L2 penalty parameter. And then I'll need to append the new classifier to the old feature extractor. It's important not to change the feature extractor when tuning your estimator, because that would invalidate the previously extracted features. Let's move on to incrementally fitting your model with batches. Machine learning models in general benefit from large amounts of training data. However, your app may have limited memory constraints. So what do you do? You can use Create ML Components to train a model by loading only a batch of data into memory at a time. The first thing I need to do is replace the classifier with an updatable classifier. In order to train a custom model with batches, your classifier needs to be updatable. For example, the fully connected neural network classifier, which I can easily use instead of the logistic regression classifier which is not updatable.
All right, now I'll write a training loop. I'll start by creating a default initialized model. You won't be able to make predictions yet; that's because this is just the starting point for training. Then I'll extract the audio features before the training starts. This is an important step because I don't want to extract features every iteration. The next step is to define the training loop and specify the number of iterations you'd like to train for. Before I continue, I'll import the algorithm's Swift package. I'll need it for creating batches of training data. Make sure to check out the session "Meet the Swift Algorithms and Collections packages" from WWDC 2021 to learn more.
Within the training loop is where the batching happens. I'll use the chunks method to group the features into batches for training. The chunk size is the number of features that are loaded into memory at once. Then, I can update the model by iterating over the batches and calling the update method.
When you train your model incrementally, you can unlock a few more training techniques. For example, in this training graph, after about 10 iterations, the model accuracy plateaus at 95 percent. At this point, the model has converged and you can stop early. Let's implement early stopping in the training loop. The first thing I need to do is make predictions for my validation set. I'm using the mapFeatures method here because I need to pair the validation predictions with its annotations. The next step is to measure the quality of the model. I'll use the built-in metrics for now, but there's nothing stopping you from implementing your own custom metrics. And finally, I'll stop training when my model has reached an accuracy of 95 percent. Outside of the training loop, I'll write the model out to disk so that I can use it later to make predictions. In addition to stopping early, I'd like to talk about model checkpointing.
You can save your model's progress during training rather than waiting until the end. And you can even use checkpointing in order to resume training, which is convenient especially when your model takes a long time to train. All you need to do is write out your model in the training loop. We recommend doing this every few iterations by defining a checkpoint interval. It's that easy. In this session, I introduced temporal components, a new way to build machine learning tasks with temporal data like audio and video. I composed temporal components together to make a human action repetition counter. And finally, I talked about incremental fitting. This will unlock new possibilities for you to build machine learning into your apps. Thanks for joining me and enjoy the rest of WWDC. ♪
-