-
Metal関数ポインタの紹介
Metalは、低レベル・低オーバーヘッドのハードウェア加速グラフィックスフレームワークであり、Appに素晴らしい視覚効果をもたらすシェーダーAppプログラミングインタフェースです。関数ポインタを使用して、Metal Shading言語で書かれたシェーダーのプログラム制御性と拡張性を改善する方法を紹介します。Metalシェーダーの動的フロー制御にこの新しい機能を利用する方法について学びます。関数ポインタを使用して、レイトレーシングAppのカスタム交差機能を指定する方法について説明します。GPUパイプラインサイズとランタイムパフォーマンスのバランスをとるために、どのように関数ポインタが複数のコンパイルモデルを許可するかについて説明します。
リソース
- Modern rendering with Metal
- Accelerating ray tracing and motion blur using Metal
- Metal for Accelerating Ray Tracing
- Debugging the shaders within a draw command or compute dispatch
- Metal Feature Set Tables
- Metal Performance Shaders
- Metal
- Metal Shading Language Specification
関連ビデオ
WWDC21
-
このビデオを検索
こんにちは WWDCへようこそ “Metal関数ポインタの紹介” 私はリッチ・フォースター AppleのGPUソフトウェアエンジニアです このセッションでは今年Metalに追加した 新しい関数ポインタAPIについてお話しします 基本の関数ポインタから始めましょう 関数ポインタは呼び出すことができるコードを 参照する力を与えます それらはコードを記述できるようにすることで コードを拡張可能にし これまでに見たことのないコードを 呼び出すことができるようになります
典型的な例はコールバックで 実行は関数ポインタで識別されるコードに ジャンプします これによりプラグイン 特殊化または通知の機能を提供できます しかしもっと多くのことができます 今日はMetalで関数ポインタの サポートを公開する方法と visible関数を使用して目標を 達成する方法についてお話します 私たちがサポートする 様々なコンパイルモデルが 何を意味し それらを いつ使用するかについて説明します 次にvisible関数の表について説明し 最後はパフォーマンスについて説明します それではMetalの関数ポインタから始めましょう
Metalに関数ポインタを追加すれば それを使用する様々な機会があることを 知っていました 明らかなケースはレイトレーシングで 関数ポインタを使用して カスタムintersection関数を指定します そしてこのセッションに関連する レイトレーシングのトークを ご覧になることをお勧めします
レイトレーシングは関数ポインタの 他の使用についてお話しする最高の場所であり 今日はここから始めたいと思います 従来のCornell Boxに レイトレーシングを適用すると シーンに光線を発射し そしてそれらが表面にぶつかった時 交差をシェーディングする必要があります 通常交差するサーフェスのマテリアルがあり 次にライトに当たるまで トレーシングを継続します その時点でライトの寄与を評価します レイトレーシングのプロセスフローを もう一度見てみましょう まず カメラから始まり シーンに放出される光線を生成します 次にシーン内のジオメトリとの交差について それらの光線をテストします
次に各交点の色を計算し 画像を更新します このプロセスはシェーディングと呼ばれます シェーディングプロセスでは 追加の光線を生成することもできます シーンとの交差について それらの光線をテストします このプロセスを何度も繰り返し シーンの周囲に光が跳ね返るのを シミュレートします このプレゼンテーションの内容を簡略化し 単一の交差を実行するパストレーサーを 検討することから始め 次にその交差の結果をシェーディングします これはこれらの3つのステージの 各コードを含む計算パイプラインを作成する― 単一のコンピュータカーネルになります しかし 私が注目したいのは シェーディングです これは画像を出力する前の 最後のステップであり 関数ポインタを使用する 様々な機会を提供します
レイトレーシングカーネル内では シェーディングは最後の方で行います 交差ができたら 一致するマテリアルを見つけ そのマテリアルの シェーディングを実行します この例では マテリアルとライティングコードはすべて ファイルの他の場所にある shade関数に含まれています shade関数をさらに詳しく見てみましょう
shade関数には いくつかのステップがあります これは単純なパストレーサーであるため サーフェス上の交差ポイントでライトから 即座にライティング計算されます 次にマテリアルを使用して 交差ポイントにライティングを適用します
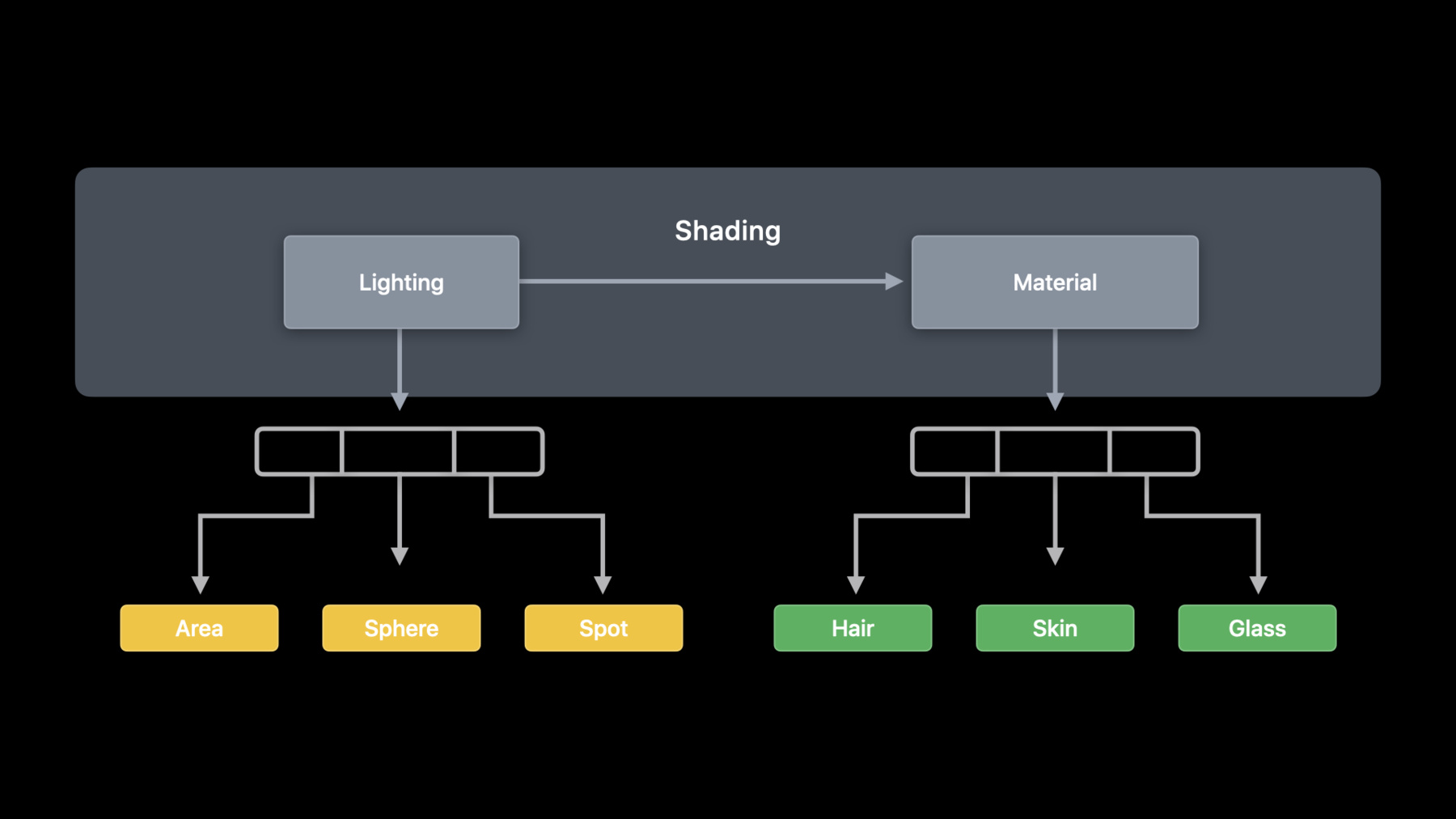
フローに関してはライティングとマテリアルを 別々のステージと見なすことができます しかし複数のタイプのライトと 複数のタイプのマテリアルがあります
ライティングを別々のタイプのライトに 分割することができます これにはライトタイプごとに異なる コードが必要になります
マテリアルのコードはライトのコードよりも さらに多様である可能性があります Metalの新しいvisible関数タイプを使用して ライティングおよびmaterial関数の操作します
Visibleは頂点フラグメント カーネルなどの新しい関数修飾属性です 関数定義でvisible属性を使用できます visible属性を使用する時は Metal APIから関数を操作することを 宣言しています APIを使用してデバイスクエリで この操作を実行できるかどうかを確認します visible関数を使用すると コードを参照可能なフレキシブルオブジェクトと 見なすことができます この場合 エリアライトの コードを考えてみましょう そのコードはパイプラインを表す カーネル外に存在できるオブジェクトです コードは別のMetalファイル または別のMetalライブラリに含まれます
lighting関数をvisibleとして宣言するには 関数の定義の前にvisible属性を追加します こうすることで関数内のコードを表す Metal関数オブジェクトを作成できます
次のステップはMetalシェーダーコードを パイプラインに接続して 呼び出すことができるようにすることです まずエリアライトコードを Metal関数オブジェクトでラップします 次に新しいMetal関数オブジェクトを パイプラインに追加できます
area light関数のvisible属性を使用して それをCPUのMetal関数オブジェクトに ラップできます 標準のメソッドを使用し visible関数の名前で Metal関数オブジェクトを作成します
次にlinkedFunctionsの一部として 関数オブジェクトを 計算パイプライン記述子に追加して パイプライン作成プロセスで パイプラインに追加できるようにします すると後で関数ポインタで 参照できるようなります パイプラインのvisible関数の 追加について話しているので 利用可能なコンパイルモデルの選択について 説明する必要があります
各ライティングおよびmaterial関数の Metal関数オブジェクトを一旦取得すれば それらをパイプラインに追加できます
パイプラインを構築する時 これらの visible関数の各コピーを取得できます これを“単一コンパイル”と呼びます パイプラインとそれが使用する すべてのvisible関数を表す― 単一オブジェクトがあるためです
先ほど見たlinkedFunctionsオブジェクトを 使用して パイプラインから呼び出すことができる関数を リストします 次に標準のパイプライン作成APIを使用して ComputePipelineStateを作成します
パイプラインを作成するとカーネルコードの 特殊化されたバージョンと すべての関数の特殊化されたコピーの 両方を含むオブジェクトが生成されます この特殊化はリンク時最適化に似ており カーネルコードとvisible関数を その使用方法に基づいて最適化できます
しなしながらこの最適化により パイプラインの作成にかかる時間が長くなり パイプラインに追加する 関数オブジェクトのコピーにより パイプラインオブジェクトが大きくなります しかし パイプラインが呼び出すことができ コピーの必要がない個別のオブジェクトとして パイプライン外の関数オブジェクトを 持つことができます これは個別にコンパイルされた パイプラインの基礎です
各Metal関数オブジェクトを作成する時 各関数をスタンドアロンのGPUバイナリー形式に コンパイルできるため 関数コードを個別に保ち 複数のパイプラインで再利用できます
関数をバイナリにコンパイルするには 関数記述子を使用します これによりMetal関数オブジェクトの作成に オプションを追加できます 関数を作成する場合 このコードスニペットは nameパラメーターを持つ同じメソッドと 同じ結果のMetal関数を作成します ただしfunctionDescriptorでは さらに多くの構成オプションを指定できます
記述子の“オプション”プロパティを使用して バイナリのプリコンパイルを要求します 関数を作成すると関数がバイナリに プリコンパイルされます
次にlinkedFunctionsオブジェクトの バイナリ関数の配列に 新しい関数を提供します これは計算パイプラインの関数の コピーと特殊化を要求するのではなく 関数のバイナリバージョンを 参照していることを示しています ご覧のようにプリコンパイルされた関数を 特殊化したい関数と組み合わせることができます そして以前のように標準の呼び出しを使用して パイプラインを作成します
単一コンパイルと個別コンパイルの 両方をご説明したので それぞれの利点を比較しましょう 単一コンパイルでは 標準のメソッドを使用して visible関数を作成します 個別コンパイルでは バイナリにプリコンパイルして コンパイルバイナリを共有し パイプラインの作成中に関数の バイナリコンパイルを回避できるようにします
パイプライン記述子を構成する時は 関数配列を使用し それらを特殊化することを示し binaryFunctions配列を使用して バイナリバージョンを使用することを示します
特殊化の結果 単一コンパイルの場合の パイプラインが大きくなります 個別コンパイルがバイナリ関数への呼び出しを 追加するパイプラインになり バイナリ関数が共有されます
関数の特殊化には バイナリ関数の呼び出しを追加するよりも 長いパイプライン作成時間が必要です 先ほどお伝えしたように これはリンク時最適化に似ています コンパイラはパイプライン全体を 知ることができますが 特殊化を適用するには 追加のビルド時間が必要です
そのすべての関数の特殊化は 単一コンパイルが実行時に 高いパフォーマンスを発揮することを意味します 個別にコンパイルされたパイプラインの フレキシビリティは バイナリ関数の呼び出しに 実行時オーバーヘッドがあることを意味します 先ほども触れましたが プリコンパイルされた関数と特殊化のための 関数のセットを混在させることができますが 完全に特殊化された 単一コンパイルパイプラインが 最高のパフォーマンスを提供します 既存のパイプラインで 個別にコンパイルされた関数を置き換えるために バックグラウンドで 新しい単一コンパイルパイプラインを いつでも作成することができます 別のコンパイルパイプラインに戻ると パイプラインから呼び出すことができる 関数の配列があります しかしながら関数の固定集合がある場合 常に別の関数が常に表示されます
この場合 パイプラインに追加する 新しいウッドマテリアルがあります インクリメンタルコンパイルは 既存のパイプラインに 新しい関数を追加するためのものです 新しい関数の使用は通常 動的環境 特にストリーミングが 新しいアセットを新しいシェーダーで ロードするゲームで非常に一般的です
これをコードに組み込むと まず 最初の計算パイプラインを 作成する時に 最初にインクリメンタルコンパイルを サポートするように選択する必要があります デフォルトではインクリメンタルコンパイルは サポートされません バイナリ関数を 後で追加できるようにすることは たとえパイプラインの作成時に 何も指定されていなくても バイナリ関数の呼び出しが可能になることが 期待されるからです
次に関数記述子を使用して プリコンパイルされたバイナリ関数として ウッドシェーダーの Metal関数オブジェクトを作成します
最後にComputePipelineStateに 新しく追加されたメソッドを使用し 追加のバイナリ関数を含む 計算パイプラインを作成します
次にvisible関数テーブルについてお話します visible関数テーブルは visible関数への関数ポインタを GPUに渡す方法です
シェーディングのために検討した 一連のライティング関数とmaterial関数に戻ると GPUで実行されているカーネルに これらを提供する必要があります
関連する関数をグループ化してGPUに渡すため Metal APIを使用して visible関数テーブルを作成します visible関数テーブルはMetalシェーダーコードに 渡すことができるオブジェクトです
始める前に 使用する宣言をいくつか追加して 関数ポインタの型を定義し コード例が長くなり過ぎないようにしましょう vsible関数テーブルは カーネルパラメータとして指定でき バッファーバインディングポイントを使用します それらを引数バッファーに渡すこともできます
次にシェーダーにて インデックスで関数にアクセスします 関数へのポインタを取得するか テーブルから直接呼び出すことができます
CPUでテーブルに必要な 関数エントリの数に基づいて ComputePipelineStateから visible関数テーブルを割り当てます
次にパイプラインステートを作成する時に 指定した関数への ハンドルをテーブルに入力します
最後にテーブルを使用する時は 必要に応じてcomputeCommandEncoder またはargumentEncoderに設定します argumentEncoderを使用する場合は useResourceを呼び出しを忘れないでください インクリメンタルコンパイルされた パイプラインを できるだけ低コストで 使用できるようにするために 祖先パイプラインからvisible関数テーブルを 再利用できるようにしています テーブルに既に存在するハンドルは 引き続き有効であり 新しい関数ハンドルを テーブルに追加するだけです まったく新しいテーブルを作成して 構築する必要はありません 最後に古いパイプラインから 新しく追加された関数ハンドルに アクセスしないように気をつけてください 今日の最後になりましたが アプリケーションで 関数ポインタを使用する際の パフォーマンスに関する 考慮事項について説明します パフォーマンスでは 3つの主要な領域を取り上げます 最適化のための関数グループから始めましょう 前の図に戻ると 特定の目的のための関数の グループがあることを確認しましたね ただしパイプライン作成では これらの関係は認識されません
シェーダーでの使用に基づいて 関数をグループ化できます ライティングに使用する関数と マテリアルに使用する関数を どれにするかは分かっています
シェーディング関数で 関数のグループを表すために それを更新して実行する 呼び出しの関数グループを含めました Metalでは関数グループによって 関数が使用される場所を コンパイラに指示できます シェーダーコードでは関数を呼び出す行に 関数グループ属性を適用し その場所から呼び出し可能な 関数グループに名前を付けます
次に計算パイプライン記述子を構成する時に グループごとに呼び出すことができる セッター関数を使用して ディクショナリにグループを指定します これによりコンパイラは可能な限り 多くの情報を入手でき パイプラインを生成する際の 最適化に役立ちます 関数配列の関数に対して コンパイラが実行する特殊化に加えて コンパイラは各グループの セッター関数間の共通点を利用して それを関数グループ属性でマークされた 呼び出しサイトに適用できます このすべての新しいフレキシビリティにより 再帰関数を実装できるようになります
レイトレーシングプロセスフローを 開始したところに戻ると マルチバウンスを考慮する このレイトレーシングのモデルは 反復的または再帰的な方法で実装できます
交差とシェーディングの関係に注目すると このコールグラフをたどることができます
再帰パストレーサーを使用して 交差後に交差ポイントを シェーディングします この場合 新しいwood material関数を使用します このウッドマテリアルには 反射コンポーネントが含まれているため 別のレイとシーンと交差させ 交差をシェーディングします
この場合もウッドマテリアルにおいて 覆われた表面と交差します 次に これがシーンを反射して 再び交差します もう一度ウッドマテリアルをヒットします 続行することもできますが 通常パフォーマンスとスタックの オーバーフローを避けるために 再帰的レイトレーサーの深度を制限するため ここでストップします visible関数のチェーンを 呼び出す計算カーネルの 様々なスタックの使用を サポートするために 計算パイプライン記述子で maxCallStackDepthプロパティを公開し カーネルから関数を呼び出す深さを 指定できるようにします デフォルトは1なので visible関数とintersection関数の 一般的な使用例はそのまますぐ使用できます この値はvisible関数呼び出しのチェーンに 使用されることが予想されますが レイトレーシングの場合このコードは スタックの消費量を減らすために 反復的に記述されていたかもしれません 今日お話ししたい最後の パフォーマンスの考慮事項は 関数ポインタを使用した場合の ダイバージェンスのインパクトでした ただし関数ポインタについて説明する前に 昨年の“Ray Tracing with Metal” プレゼンテーションでは 後続のバウンスの一貫性が低下した時に レイトレーシングに固有の ダイバージェンスを処理する 高レベルメソッドについて説明しました これにはブロック Linear Layoutによる レイのコヒーレンス アクティブなレイのレイコンパクション GPU間でのロードバランシングのための インターリーブタイリングが含まれます レイトレーシング最適化のアイデアの 優れたレビューについては プレゼンテーションを 確認されることをお勧めします ただし関数ポインタの場合は スレッドレベルでのダイバージェンスを 考慮する必要があります スレッドグループをディスパッチする時 SIMDグループとして定義された より小さな スレッドグループで実行されることがわかります この例では8つのSIMDグループがあります
SIMDグループ内のスレッドは 同じ命令を同時に実行した時に 最高のパフォーマンスを発揮します
ダイバージェンスは次に実行する命令が SIMDグループのスレッドで 異なる場合に起こります 通常シェーダーコードの分岐に 到達した場合に発生します これは通常スレッドの サブセットに命令を実行させ 他のスレッドは未使用のままにすることで 処理されます すべてのスレッドが 有用な命令をアクティブに実行している時に 最高のパフォーマンスが得られます
関数ポインタはダイバージェンスにつながる 可能性があるもう1つのケースです 関数ポインタを介して関数を呼び出す時は セッター関数ポインタがどの程度分岐するかを 考慮する必要があります 最悪の場合SIMDグループ内では 各スレッドが異なる関数を 呼び出している可能性があり 実行時間は必要な各関数を 順番に実行する時間になります
ただしスレッドグループ全体を検討すると 完全なSIMDグループを作成する為の 十分な作業が必要になる場合があります
ダイバージェンスを処理するために 関数呼び出しを並べ替えて SIMDグループにcoherenceを導入します つまりあるスレッドの関数呼び出しは スレッドグループ内の別のスレッドによって 実行される可能性があります
コードに関してはすべての関数パラメータ スレッドのインデックス スレッドグループメモリを呼び出す関数を 書くことから始めます 次にお気に入りのソートを使用して 関数のインデックスを並べ替えます
次に並べ替えられた順序で 関数を呼び出します 関数の結果は スレッドグループのメモリに戻り 各スレッドは そこから結果を読み取ることができます パラメータと結果のデバイスメモリを使用して 同様のバージョンを実装することもできます 複雑な関数を呼び出す場合 これはダイバージェンスの オーバーヘッドを減らすはずです Metalの関数ポインタで できることはたくさんあります 今日はvisible関数の作成と使用 およびそれらをvisible関数テーブルに追加して 計算カーネルから呼び出すことができる関数を 提供する方法について説明しました 関数を動的に追加できるように パイプラインのサイズと作成時間と 実行時のパフォーマンスと必要性の バランスを選択できる― 様々なコンパイルモデルについて説明しました またアプリケーションで 関数ポインタを使用する場合の パフォーマンスに関する考慮事項についても 説明しました 私は関数ポインタの作成をとても楽しんでおり 皆さんと共有できて本当に嬉しいです WWDCをお楽しみください
-
-
3:09 - Our simple Path Tracer in Metal Shading Language:
float3 shade(...); [[kernel]] void rtKernel(... device Material *materials, constant Light &light) { // ... device Material &material = materials[intersection.geometry_id]; float3 result = shade(ray, triangleIntersectionData, material, light); // ... } -
3:30 - Our shading function
float3 shade(...) { Lighting lighting = LightingFromLight(light, triangleIntersectionData); return CalculateLightingForMaterial(material, lighting, triangleIntersectionData); } -
4:59 - Declare a function as visible
[[visible]] Lighting Area(Light light, TriangleIntersectionData triangleIntersectionData) { Lighting result; // Clever math code ... return result; } -
5:30 - Single compilation pipeline on CPU
// Single compilation configuration let linkedFunctions = MTLLinkedFunctions() linkedFunctions.functions = [area, spot, sphere, hair, glass, skin] computeDescriptor.linkedFunctions = linkedFunctions // Pipeline creation let pipeline = try device.makeComputePipelineState(descriptor: computeDescriptor, options: [], reflection: nil) -
7:43 - Introducing MTLFunctionDescriptor
// Create by function descriptor: let functionDescriptor = MTLFunctionDescriptor() functionDescriptor.name = "Area" // More configuration goes here let areaBinaryFunction = try library.makeFunction(descriptor: functionDescriptor) -
8:08 - Binary pre–compilation
// Create and compile by function descriptor: let functionDescriptor = MTLFunctionDescriptor() functionDescriptor.name = "Area" functionDescriptor.options = MTLFunctionOptions.compileToBinary let areaBinaryFunction = try library.makeFunction(descriptor: functionDescriptor) -
8:20 - Binary functions
// Specify binary functions on compute pipeline descriptor let linkedFunctions = MTLLinkedFunctions() linkedFunctions.functions = [spot, sphere, hair, glass, skin] linkedFunctions.binaryFunctions = [areaBinaryFunction] computeDescriptor.linkedFunctions = linkedFunctions // Pipeline creation let pipeline = try device.makeComputePipelineState(descriptor: computeDescriptor, options: [], reflection: nil) -
11:04 - Incremental compilation pipeline
// Create initial pipeline with option computeDescriptor.supportAddingBinaryFunctions = true // Create and compile by function descriptor let functionDescriptor = MTLFunctionDescriptor() functionDescriptor.name = "Wood" functionDescriptor.options = MTLFunctionOptions.compileToBinary let wood = try library.makeFunction(descriptor: functionDescriptor) // Create new pipeline from existing pipeline let newPipeline = try pipeline.makeComputePipelineStateWithAdditionalBinaryFunctions(functions: [wood]) -
12:22 - Visible function tables on the GPU
// Helper using declaration in Metal using LightingFunction = Lighting(Light, TriangleIntersectionData); using MaterialFunction = float3(Material, Lighting, TriangleIntersectionData); // Specify tables as kernel parameters visible_function_table<LightingFunction> lightingFunctions [[buffer(1)]], visible_function_table<MaterialFunction> materialFunctions [[buffer(2)]], // Access via index LightingFunction *lightingFunction = lightingFunctions[light.index]; Lighting lighting = lightingFunction(light, triangleIntersection); return materialFunctions[material.index](material, lighting, triangleIntersection); -
12:49 - Visible function tables on the CPU
// Initialize descriptor let vftDescriptor = MTLVisibleFunctionTableDescriptor() vftDescriptor.functionCount = 3 let lightingFunctionTable = pipeline.makeVisibleFunctionTable(descriptor: vftDescriptor)! // Find and set functions by handle let functionHandle = pipeline.functionHandle(function: spot)! lightingFunctionTable.setFunction(functionHandle, index:0) // Find and set functions by handle computeCommandEncoder.setVisibleFunctionTable(lightingFunctionTable, bufferIndex:1) argumentEncoder.setVisibleFunctionTable(lightingFunctionTable, index:1) -
14:23 - Function groups on GPU
// Add function groups to our shading function float3 shade(...) { LightingFunction *lightingFunction = lightingFunctions[light.index]; [[function_groups("lighting")]] Lighting lighting = lightingFunction(light, triangleIntersection); MaterialFunction *materialFunction = materialFunctions[material.index]; [[function_groups("material")]] float3 result = materialFunction(material, lighting, triangleIntersection); return result; } -
14:49 - Function groups on CPU
// Function Group configuration let linkedFunctions = MTLLinkedFunctions() linkedFunctions.functions = [area, spot, sphere, hair, glass, skin] linkedFunctions.groups = ["lighting" : [area, spot, sphere ], "material" : [hair, glass, skin ] ] computeDescriptor.linkedFunctions = linkedFunctions
-