-
Objective-Cランタイムの進化
Objective-CやSwiftクラスの基礎となる、低レベルのビットやバイトのミクロの世界に飛び込んでみましょう。内部のデータ構造、メソッド一覧、タグ付きポインタに対する最近の変更がどのようにパフォーマンスの改善やメモリー使用量の減少につながっているかをお伝えします。内部の個々の要素に依存するコードにおけるクラッシュの認識および解決方法を紹介し、ランタイムに対する変更に影響されないコードの維持方法もお伝えします。
リソース
関連ビデオ
WWDC20
-
このビデオを検索
“ようこそ WWDCへ” こんにちは WWDCへようこそ
“Objective-Cランタイムの進化” ランタイムチームのベンです 本日 紹介するのはiOSとmac OSでの Objective-Cランタイムの変更点です メモリの使用が改善されます 今日の話は他と違い― コードの変更は不要です 新しいAPIや非推奨の警告の話はしません 運がよければ 何もせずに アプリケーションが速くなります これらの改善について話す理由は クールで興味深いからです また ランタイムの改善が可能なのが 我々の内部データ構造が APIの背後に隠されているからです データ構造に直接アクセスすると クラッシュが多くなります あなたのコードベースで作業する人が 不適切なアクセスをした時に 注意すべきことをお伝えします 3つの変化を見ていきます 最初は Objective-Cランタイムが クラスの監視に使うデータ構造の変化です 次が Objective-Cのメソッドのリストの変化 最後がタグ付きポインタの記述の変化です
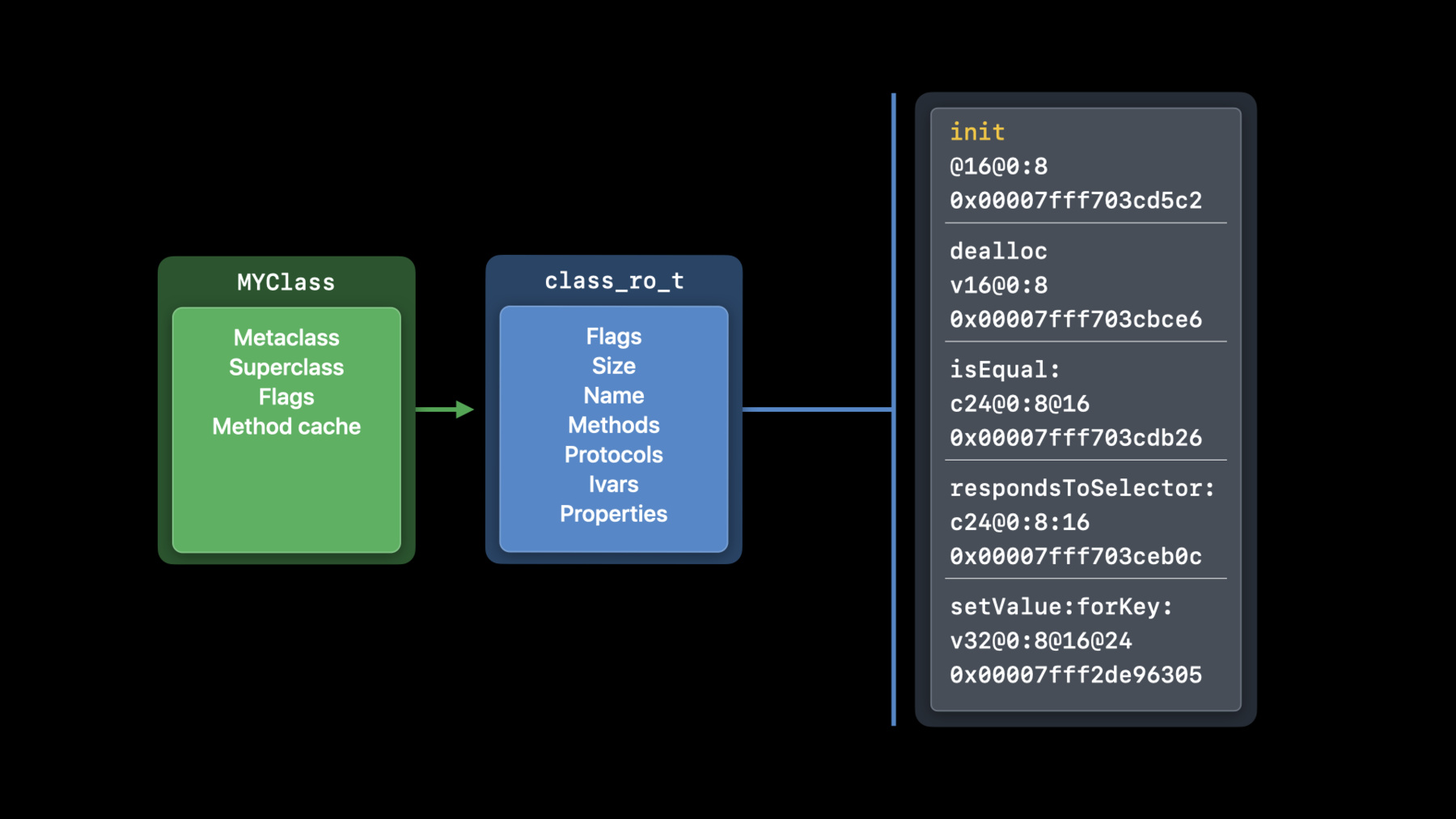
ではクラスのランタイムデータの 変化から始めます アプリケーションのバイナリで クラスは こう見えます まずクラスオブジェクトです 頻繁にアクセスする情報が含まれます メタクラスとスーパークラスと メソッドキャッシュへのポインタです データへのポインタもあります 詳しい情報が格納されたclass_ro_tです “ro”は読み取り専用の意味です ここに含まれるのはクラス名― メソッドやプロトコルや インスタンス変数の情報です
この基礎構造は SwiftとObjective-Cに共通で Swiftの各クラスは同じデータ構造を持ちます クラスはディスクからメモリにロードされ 最初は この形ですが 使い始めると変わります このことを理解するために クリーンなメモリとダーティなメモリの違いを 知るのがいいでしょう クリーンなメモリはロードされても変わりません class_ro_tは読み取り専用なのでクリーンです ダーティメモリはプロセス実行中に変化します
クラス構造がダーティなのは ランタイムが新しいデータを書き込むからです 新しいメソッドキャッシュや ポインタを生成します
ダーティメモリのほうがクリーンより高価です プロセス実行中は必ず使い続けます
一方 空き容量を作るため クリーンメモリは解放できます 必要であれば いつでも再ロードできるからです
macOSはダーティメモリを スワップアウトできますが スワップ機能のないiOSでは ダーティメモリはコストがかかります
ダーティメモリのせいで このクラスデータは2分割されます データはクリーンなほうがいい 変化しないデータを分割すれば クラスデータの大分部は クリーンなメモリのままです
最初のデータで十分でも ランタイムは各クラスの情報がさらに必要です クラスが使われ始めると― ランタイムはさらにストレージを割り当てます
この割り当てられたストレージは データの読み書き用のclass_rw_tです ランタイムで生成された 新しい情報だけを格納します サブクラスと兄弟クラスのポインタを使い― すべてのクラスをツリー構造でつなげます ランタイムは使用中の全クラスをトラバースでき メソッドキャッシュの無効に役立ちます
メソッドとプロパティは読み取り専用ですが このクラスにあります ランタイムで変化するからです ロードされたカテゴリが 新しいメソッドをクラスに加えます ランタイムAPIを動的に使い このメソッドを加えられます class_ro_tは読み取り専用なので class_rw_tで これらの監視が必要です
これは かなりのメモリを使用します どのデバイスでも 多くのクラスを使います iPhoneのシステムで class_rw_t構造は 30MBになります どう削減できるでしょう? これらはランタイムで変化するので 読み書き部分に格納します
でも使用量を調べると― クラスの10%ほどしか メソッドは変化していません
デマングルされた名前は Swiftのクラスだけが使います Objective-Cの名前が不要なら Swiftのクラスでも使いません
だから 使われない部分を分割します これでclass_rw_tが半分になります さらに情報が必要なクラスに 拡張されたレコードの1つを割り当て― クラス全体に加えて使用します
クラスの約90%は この拡張されたデータは不要で システムの14MBを節約しています アプリケーションのデータ保存などに 有効に使えるメモリです ターミナルで簡単なコマンドを実行すれば この変化の影響が分かります 実際にやってみます MacBookのターミナルで― どのMacでも使える ヒープというコマンドを実行します 実行中のプロセスで 使用中のヒープメモリを調べます ではメールのアプリケーションで実行しましょう このままだと メールのヒープの割り当てを表す― 大量の行が出力されます 今日 話題にしているタイプで― grep検索を行います class_rw_tです ヘッダも検索します
検索結果によると 9000のclass_rw_tを メールで使っていることが分かります しかし拡張された情報が必要なのは 10分の1の約900だけです この変化で節約したサイズを計算できます このタイプは2分割されました この数字から差し引くのが 拡張されたタイプに割り当てたメモリです メールだけで データの約250キロバイトを節約しました これをシステム全体で行えば ダーティメモリに関して かなりの節約です クラスからデータをフェッチするコードは 拡張されたデータを持つクラスと 持たないクラスに対処します ランタイムがすべて処理します 表面的には すべて前と同じ働きをし メモリの使用が減ります これらの構造を読み込むコードが ランタイム内にあり アップデートされているからです これらのAPIが重要になります データ構造に直接アクセスしようとするコードは 今年リリースのOSで使えません 新しいレイアウトに対応していないからです これらの変化で壊れたコードもあります 自分のコードだけでなく アプリケーションの 外部依存関係にも注意しましょう 知らぬ間に データ構造を使うかもしれません
これらの構造の情報はすべて 公式のAPIで有効です class_getNameやclass_getSuperclassの 関数があります これらのAPIで この情報にアクセスする時― シーンの背景で何を変えても APIは機能し続けます これらのAPIの説明は developer.apple.comのドキュメントにあります 次にクラスのデータ構造を詳しく見て Relative Method Listsを説明します クラスごとにメソッドのリストがあり 新しいメソッドを書き込むと追加されます ランタイムはこのリストを使い情報を送ります 各メソッドには情報が3つずつあります まずメソッド名またはセレクタです セレクタは独特な文字列で pointer equalityとも比較されます
次にメソッドのtype encodingです これはパラメータや戻り値の型を表す文字列で 情報は送りませんが― ランタイム・イントロスペクションや フォワーディングに必要です
最後はメソッドをインプリメントするポインタで 実際のコードです メソッドを書き込むとC関数に コンパイルされます そして関数ごとにメソッドのリストに加わります 一例を見せましょう 初期化のメソッドです メソッド名とデータ型 インプリメントが見えますね
リストのデータそれぞれがポインタです 64ビットなら それぞれのテーブル項目を 24バイトが占めています クリーンメモリですが フリーなままとはいかず― 使用時にはディスクからロードして メモリを使います
これがプロセス中のメモリを拡大した様子です 原寸ではありません 64ビットのアドレスのため 大きなアドレス空間があります アドレス空間には スタックやヒープの他に― 実行ファイルやライブラリ 2値画像がプロセスにロードされます 青色の部分です
2値画像の1つを拡大して見てみましょう ここではメソッドの3つのエントリーが 2値画像を指しています ここでコストがかかります 2値画像は動的なリンカが決定した場所で メモリにロードされます リンカはポインタをイメージに解像し 修復しなければなりません これはロード時に メモリ内の実際のロケーションを示すためです バイナリからのクラスメソッドのエントリーは そのバイナリだけでインプリメントされます あるバイナリのメタデータやコードを持つ メソッドを― 他にインプリメントはできません リストに載せるものは 64ビットのアドレス空間 全体に― 関連する必要はないということです リストは関連したバイナリの関数に 準ずればいいので常に近くにあります
つまり64ビットの絶対アドレスではなく― 32ビットの相対アドレスを オフセットで使うこともできます これが今年 変更した部分です いくつか利点があります ロードした場所に関係なく オフセットはいつも同じなので― ディスクからロードした後 修復の必要はありません 修復しないので 読み取り専用メモリとして さらに安全性が高くなります 32ビットのオフセットを使うことで 64ビットの半分のメモリしか必要としません 調べたところ 普通のiPhoneのシステム全体は 80MBなので― このメソッドなら 半分の40MBを節約できます アプリケーションのユーザーに余裕ができます
では swizzleは? バイナリ内のメソッドは アドレス空間 全体を使えませんが― swizzleすれば どこでもインプリメントできます それにメソッドのリストを 読み取り専用にしておきたいので― global table mappingのメソッドを swizzleのインプリメントに使います メソッドの大半は swizzleされないので― このテーブルは さほど大きくなりません 小さい分 メモリがダーティになるのは 1ページごとで済みます 以前のメソッドなら swizzleでページ全体がダーティになります 単独のswizzleが 大量のダーティメモリを生むのです 1つのテーブルのせいで余計なコストを払います 今回の改良点も皆さんの目には触れず 使い心地は変わりません Relative Method Listsは 今年 登場するOSでサポートされます 最小デプロイ・ターゲットで ビルドするなら― ツールはバイナリのリストに 自動的に生成されます 古いOSが対象の時でも心配は要りません Xcodeが古いリストのフォーマットで生成して フルにサポートします Relative Method Listsの入ったOSの 恩恵を受けられ― 新旧のフォーマットで アプリケーションを同時に使っても大丈夫です 今年のOSを手に入れれば バイナリが小さくなりメモリを節約できます Objective-CやSwiftには朗報です 最小デプロイ・ターゲットは SDKやAPIだけの話ではありません Xcodeが古いOSのサポートは不要と 認識すると― 最適化したコードやデータを放出します 古いバージョンが必要なのは承知ですが― できるタイミングでバージョンアップすることを お勧めします
注意が必要なのは― ビルドの際のデプロイ・ターゲットが 対象とするバージョンよりも新しい場合です Xcodeが防ぐはずですが― よそでビルドしたライブラリやフレームワークを 取り込むと すり抜けます 古いOSで実行すると ランタイムがメソッドを認識する時― それが理解できず 昔ながらの ポインタベースのメソッドで解釈しようとします
つまり32ビットのフィールド2つを 64ビットで読み込もうとするのです その結果 2つの整数型で 1つのポインタになり― 値として意味を持たないのでクラッシュします ランタイムがクラッシュした時 メソッドの情報を読むと― ここに見られるように 32ビットの値が 合わさっているので分かります
コードを実行しても この構造体で値を読み込むので― ランタイムと同じような問題が起きます ユーザーがアップグレードすると クラッシュします それを避けるには 画面のAPIを使ってください これなら背面で何が変わろうとも大丈夫です 例えばメソッドのポインタを得て フィールドに値を返す関数もあります
今年の もう1つの変化を見てみましょう ARM64でのタグ付きポインタ形式の変更です まずタグ付きポインタが何であるか 低レベルになりますが ご心配なく 他の話同様 知る必要はありません でも面白いです メモリ使用率の理解にも役立つかもしれません まず通常のオブジェクトポインタの 構造を見てみましょう 通常 これらは大きな16進数として出力されます いくつかは先ほど見ました
バイナリ表現に分解してみましょう 64ビットですが すべてのビットを使うわけではありません 中間のこれらのビットだけが 実際のオブジェクトポインタに設定されます アライメント要件のため 下位ビットは常に0です オブジェクトは常にポインタサイズの倍数の アドレスに配置します
アドレス空間が限られているため 上位ビットは常に0です 2から64まで わたることはありません 上位ビットと下位ビットは常に0です 常に0のビットのどれかを1にしてみましょう これで即座に実際の オブジェクトポインタではないと分かり― 次に他のすべてのビットに 他の意味を割り当てられます これをタグ付きポインタと呼びます
例えば数値を他のビットに 詰め込むことができます NSNumberにビットの読み方を教え ランタイムに タグ付きポインタの適切な処理を教えれば― 残りのシステムはオブジェクトポインタのように これらを扱い 違いに気づきません 同様のすべてのケースに 小さな数のオブジェクトを割り当て― オーバーヘッドを節約でき 大きな得になります
話が逸れますが― これらの値はプロセスの起動時に初期化される ランダムな値の組み合わせで難読化されています タグ付きポインタの偽造を 困難にするセキュリティ対策です 残りの議論では無視します トップのレイヤーにすぎません 値を見ても スクランブルされているだけと 覚えておきましょう これがIntelのタグ付きポインタの 完全な形式です 下位ビットは1に設定され タグ付きポインタであることを示しています このビットは 実際のポインタでは 判別のため 常に0でなければなりません
次の3ビットはタグ番号で タグ付きポインタの型を示します 例えば3はNSNumberであること 6はNSDateであることを意味します 3つのタグビットでは 8種のタグ型が可能です
残りのビットはペイロード 特定の型が好きなように使えるデータです
タグ付けされたNSNumberの場合 これは実際の番号です
特別なケースはタグ7です これは拡張タグを示します 拡張タグは次の8ビットを使って 型をエンコードし― さらに256種のタグ型を 小さなペイロードで可能にします データをより小さなスペースに収められる限り より多くのタグ付きポインタを使用できます これはタグ付けされたUI色や NSIndexSetに使われます
これが便利だと思った方は ガッカリするかもしれませんが― ランタイムメンテナーのAppleしか タグ付きポインタ型を追加できません しかしSwiftプログラマーなら 独自の種類のタグ付きポインタを作成できます 関連値がクラスの列挙型を使ったことがあれば それがタグ付きポインタのようなものです Swiftランタイムは列挙型識別子を 関連値ペイロードのスペアビットに格納します さらにSwiftの値型の使用は タグ付きポインタを重要でなくします 値を正確にポインタサイズにする 必要がなくなるためです 例えばSwift UUID型は 2語で1列に収められるので― ポインタ内に収まらず 別のオブジェクトを 割り当てることになりません これがIntelのタグ付きポインタです ARMを見てみましょう ARM64では順序が逆になります 最下位ビットでなく最上位ビットが1に設定され タグ付きポインタを示します 次の3ビットにはタグ番号が入り ペイロードが残りのビットを使います ARMのタグ付きポインタを示すのにIntelのように 最下位でなく最上位ビットを使う理由は? objc_msgSendのための小さな最適化です msgSendの最も一般的なパスを できるだけ高速にしたいわけです 最も一般的なパスは通常のポインタ用で― 一般的でないケースが タグ付きポインタとnilです
最上位ビットを使うと 1回の比較で両方を確認できるので― 別々に確認するより msgSendの一般的ケースの 条件付きブランチを節約できます Intelと同様 タグ7には特別なケースがあり― 次の8ビットは拡張タグに使われ 残りのビットはペイロードに使われます
以上は実はiOS 13で使われていた古い形式で 今年のリリースでは少し動かしています タグビットは最上位のままです msgSend最適化は依然 とても役立つからです しかしタグ番号が下位3ビットに移動 拡張タグは使用中の場合 タグビットに続く上位8ビットを占めます こうした理由? 通常のポインタから考えてみましょう
動的リンカなどの既存のツールは― ARMのTop Byte Ignore機能で ポインタの上位8ビットを無視します そして拡張タグを Top Byte Ignoreビットに配置します アラインされたポインタでは 下位3ビットは常に0です しかしポインタに小さな数を加えるだけで それをいじることができます 下位ビットを1に設定するために7を加えます 7は これが拡張タグであることを示します つまり この上のポインタを拡張タグポインタ ペイロードに収められるのです 結果はペイロードに通常のポインタを持つ タグ付きポインタです それが役立つ理由? タグ付きポインタで文字列や他のデータ構造など バイナリの定数データの参照が可能になり― ダーティメモリの占有を避けられます この変更によって― これらのビットに直接アクセスするコードは 今年のiOS 14のリリース後 機能しなくなります こういうビット単位のチェックは 以前は機能していました しかし将来のOSでは誤答を出すようになり アプリケーションがユーザーデータを破損します そこで 今 話したようなコードは使用しないで― 代わりに… お分かりですね APIを使用してください isKindOfClassのような型判定は 古いタグ付きポインタ形式で機能し― 新しいタグ付きポインタ形式でも機能し続けます NSStringやNSNumberメソッドは すべて機能し続けます これらのタグ付きポインタ内の情報は すべて標準APIを通じて取得できます CF型にも当てはまる点も注目に値します 我々は何も隠したくないし 誰のアプリケーションも壊したくありません 詳細を伏せるのは このような変更を行うための 柔軟性を維持するためだけです これらの内部詳細に依存しない限り アプリケーションは問題なく機能し続けます では まとめましょう 今回は舞台裏の改善を いくつか お見せしました それでランタイムのオーバーヘッドが減り あなたとユーザーが使えるメモリが増えました 何もしなくても改善は得られますが デプロイ・ターゲットを 上げることは検討しましょう 我々が毎年 改善を行うために 単純なルールに従ってください 内部ビットを直接読み取らず APIを使用すること ご視聴ありがとう 高速デバイスを お楽しみください
-
-
5:37 - Use the heap command to calculate memory savings
heap Mail | egrep 'class_rw|COUNT' -
7:35 - Use the APIs
class_getName class_getSuperclass class_copyMethodList -
14:38 - Use the APIs
method_getName method_getTypeEncoding method_getImplementation -
21:52 - Use the APIs
if ([obj isKindOfClass:[NSString class]]) { // a string } NSUInteger length = [obj length]; if (CFGetTypeID(obj) == CFStringGetTypeID()) { // a string } CFIndex length = CFStringGetLength(obj);
-