-
Visionによる人物、顔、ポーズの検出
Visionフレームワークの最新のアップデートにより、Appで人、顔、ポーズを検出できるようになりました。画像内の人物を周囲の環境から分離するためのPerson Segmentation APIや、人物の頭部のピッチ、ヨー、ロールを追跡するための最新のコンティグメトリクスを紹介します。また、こうした機能をCore Imageなどの他のAPIと組み合わせることで、シンプルなバーチャル背景から、画像編集Appでのリッチなオフライン合成まで、さまざまな機能を実現することができます。 このセッションを最大限に活かしていただくため、あるいは人物の分析についてさらに詳しく知りたい場合は、WWDC20の「Visionで身体は手のポーズを検出する」とWWDC19の「Visionフレームワークを使って画像を理解する」をご確認いただくことをお勧めします。
リソース
関連ビデオ
WWDC22
WWDC21
WWDC20
WWDC19
-
このビデオを検索
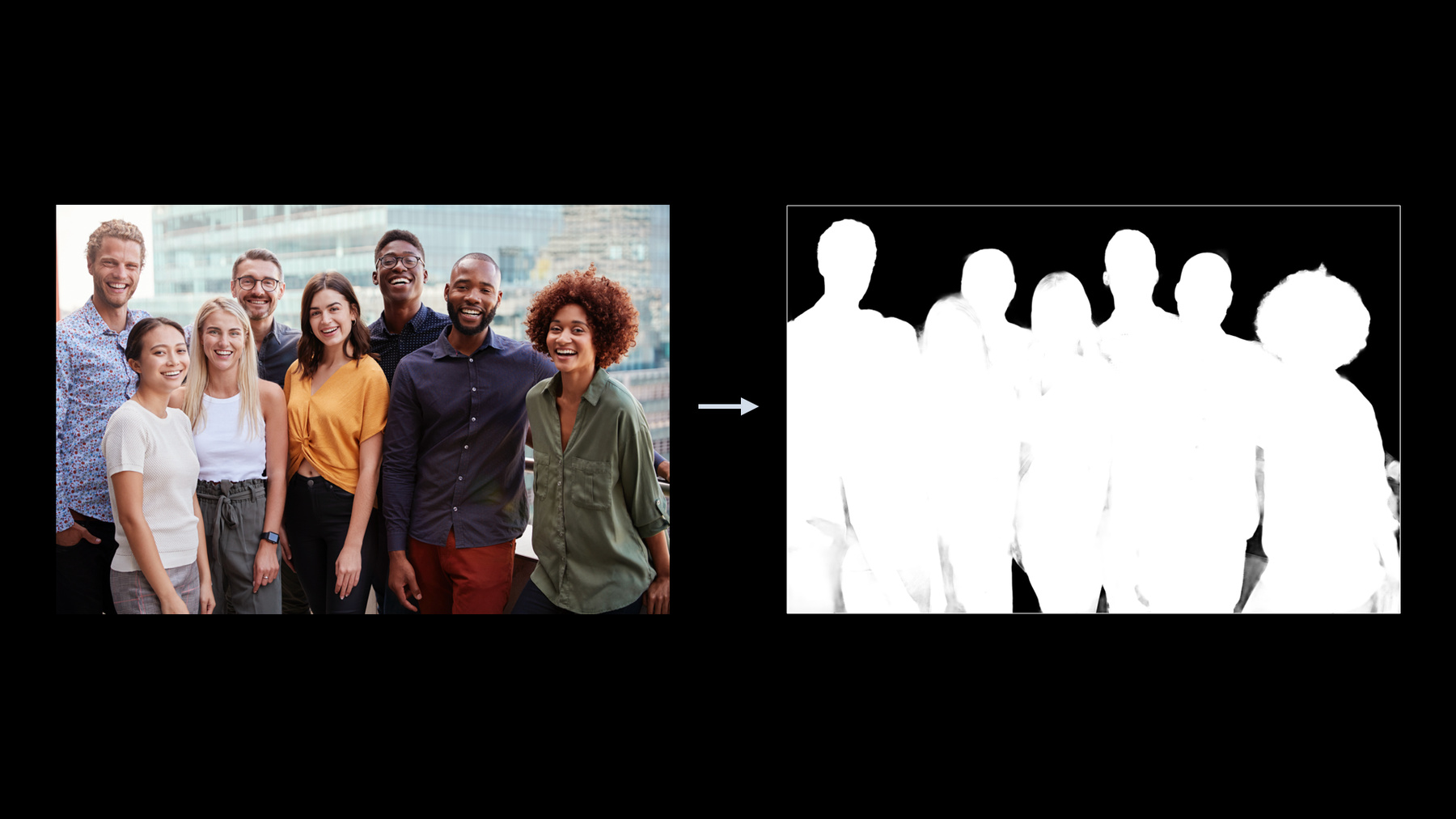
♪ (Visionによる 人物、顔、ポーズの検出) みなさん こんにちは WWDCへようこそ 私はセルゲイ・カメンスキーです Visionフレームワークチームの ソフトウェアエンジニアです 今日のセッションのトピックは Visionフレームワークが どう人物分析に役立つかを 示すことです 今日の議題は2つの主要な項目で 構成されています まず Visionフレームワーク における 人物分析技術の概要を説明します それをしながら 特に新しい追加点に焦点を当てます そして第2に 我々は新しい 人物セグメンテーション機能の 詳細なレビューをしていきます まず 人物分析技術から 始めましょう Visionにおける 人物分析の基礎は 人の顔の分析です Visionフレームワークの 提供開始以来 私たちは人の顔分析機能の 追加と強化を行ってきました 現在 顔検出 顔のランドマークの検出 および顔のキャプチャ品質の検出を 提供しています Visionフレームワーク の顔検出機能は DetectFaceRectanglesRequest で行います 当社の顔検出器は 高い精度と再現率で 様々なサイズの任意の向きの顔や 部分的に遮られたを顔 見つけることができます これまで眼鏡や帽子で 隠れた顔検出を サポートしてきました 現在 顔検出器を リビジョン番号3に アップグレードしており 既存のすべての品質を 向上させることに加えて マスクで覆われた顔も 検出できるようになりました 私たちの顔検出器の主な機能は もちろん顔の矩形領域を 見つけることですが 顔の向きも検出できます 以前はロールとヨーのみを 提供していました 多くの値は ラジアンで表わされ その値は個別のビンで返されます 今回のバージョンアップで ピッチも追加され これで 全体像が完成します しかし それだけにとどまりません 3つの値すべて 連続する空間で得られます すべての顔のポーズの値は FaceObservationオブジェクトの プロパティとして返されます DetectFaceRectanglesRequest を実行した結果です 顔のポーズ検出機能を使った デモAppを見てみましょう AppはVisionの顔検出器で カメラのフィードを処理します 結果をラジアンから度に変換した後 顔の向きを表示します 値の変化を見やすくするために 正の方向への変化を 赤で表します 負の方向への変化は 青で示します どちらの場合も 色が薄いほど 値がゼロに近いです 各値のゼロ位置は 人間の頭の中立位置と 呼ばれるもので ちょうどこのように人が まっすぐ見ているときを指します すでに説明したように ロール ヨー ピッチの3つの 顔のポーズ値があります これらの用語は飛行力学に由来し それらは航空機の重心に対して 航空機の主軸を表現しています 人間の頭のポーズの表現でも 同じ用語が 採用されているのです 頭のポーズ あるいは 顔のポーズでは それらは次のように 人間の頭の動きを表します ロールはこの方向の 頭の動きを表しています ロールが最も負の値から 最も正の値に動くとき 背景色が変わるのがわかります ダークブルーからライトブルー ニュートラル ライトレッドへ そして最後にダークレッドへ 同様の色の変化が ヨーでも起きています 頭が右または左に回る角度を 表している時です そして最後にピッチは 私の頭が上下にうなずいている時の 頭の動きを表しています スペクトルの最も負の値から 最も正の値の端に動くとき ここでも同様の色の変化を 見ることができます 顔のランドマークの検出は 顔分析パッケージの もう1つの重要な機能です 顔のランドマークの検出は DetectFaceLandmarksRequest によって提供され 最新のリビジョンは リビジョン番号3です このリビジョンは主要な顔の領域を より適切に表すため 76箇所を測定し また正確な瞳孔検出も提供します 顔分析パッケージには 顔測定の正確性の度合いである 「品質」の検出も含まれます 品質測定には以下の属性を 考慮に入れます 人間の顔の表情 照明 遮蔽物 ぼけ ピント調節などです API は DetectFaceCaptureQualityRequest で このリクエストの最新リビジョンは リビジョン番号2です 顔のキャプチャ品質の値は 同じ被写体に対してのみ比較が可能です この機能はたとえば フォトライブラリにある 一連のバーストショットから 最高の写真を選ぶ またはその人を表すのに 最適な写真を選ぶ際に うまく機能します この機能はさまざまな人々の 顔を比較するようには 設計されていません 人体分析は Visionフレームワーク によって提供される 人分析技術のもう1つの 大きなセクションです Visionは 人体の検出を含む 人間のポーズの検出 そして最後に重要なことを 言い残していましたが 人間の手のポーズの検出 この領域で複数の機能を提供します まず 人体の検出を見てみましょう この機能は DetectHumanRectanglesRequestを 介して提供され 現在人間の 上半身のみを検出しています このリクエストに 新しい機能を追加し このようにリビジョン番号2に アップグレードします 新しいリビジョンでは 上半身の検出に加えて 全身検出も提供しています 上半身のみの選択か 全身の検出かは DetectHumanRectanglesRequestの 新しいプロパティ upperBodyOnly で 制御されます このプロパティのデフォルト値は 下位互換性を維持するため trueに設定されています 人体のポーズの検出は Visionフレームワークの DetectHumanBodyPoseRequest で 可能になります このリクエストでは 人体の関節の位置の収集が 提供されます リビジョン番号1が最新で このリクエストの 唯一の利用可能なリビジョンです Visionフレームワークは DetectHumanHandPoseRequest で 人間の手のポーズ検出も提供します 人体のポーズ検出と同様に 手のポーズリクエストの処理では 人間の手の関節位置を収集し返します このリクエストの リザルトのオブザベーションに 重要なプロパティを追加することにより アップグレードしました 右手と左手の判別です HumanHandPoseObservation の 新しい chirality プロパティには 検出された手が左か右かの 情報が含まれます 詳細を知りたい場合 手のポーズ検出については以下を ご覧になることをお勧めします 「CreateMLで手のポーズと アクションを分類」 これで人の分析技術パッケージの 新しいアップグレード 概要は終わりです 今度はセッションの2番目の トピックに移ります 人物セグメンテーションです 人物セグメンテーションとは 何でしょう? 非常に簡単に言えば それはシーンから人々を 分離する機能です 今日 人物セグメンテーション技術には 多くのアプリケーションがあります たとえば ビデオ会議アプリの 仮想バックグラウンド機能は 皆さんおなじみですね ライブスポーツ分析や 自動運転 その他多くの場面で 使用されます 人物のセグメンテーションは有名な ポートレートモードにも役立ちます Visionフレームワークでの 人物セグメンテーションは 単一のフレームで動作するように 設計された機能です ストリーミングパイプラインで 使用できますが オフライン処理にも適しています この機能は複数プラットフォームで サポートされています MacOS iOS iPadOS tvOS Visionフレームワークはセマンティック 人物セグメンテーションを実装し これはフレーム内の すべての人物に対する 単一のマスクを返すことを意味します
人物セグメンテーション のための Vision の API は GeneratePersonSegmentationRequest で 実装されます Visionフレームワークの 一般的なリクエストとは異なり これは状態を保持する ステートフルオブジェクトです ステートフルリクエスト オブジェクトはフレームの シーケンス全体で再利用されます 特定のケースで このリクエストオブジェクトは 高速品質レベルのモデルで フレーム間の時間的変化を 滑らかにするのに役立ちます Visionフレームワークが提供する 人物セグメンテーションAPIを 見てみましょう このAPIは すでにおなじみの 使い方で 確立されたパターンです リクエストを作成し リクエストハンドラを作成し リクエストハンドラで リクエストを処理し 最後に 結果を確認します GeneratePersonSegmentationRequest の デフォルトの初期化は revision, qualityLevel, outputPixelFormat プロパティを デフォルト値に戻します すべてのプロパティを 1つずつ確認してみましょう 1つ目は revision プロパティです ここではリビジョンを リビジョン番号1に設定します このリクエストタイプは新規なため 1がデフォルトであり 利用可能な唯一のリビジョンです 今日ここでは 技術的に 選択の余地はありませんが 常に明示的に設定することを お勧めします 将来の確実な動作を 保証するためです これは新しいリビジョンが 導入された場合 最新のリビジョンでは デフォルトの値も 変更される可能性があるからです 2番目は qualityLevel プロパティです Vision API は次の3つの 異なるレベルを提供します accurate これは デフォルトでもあります balanced と fast です 画像処理での ユースケースに関しては accurate レベルを 使用することをお勧めします これは可能な限り最高の品質を 達成したいユースケースです そして 通常時間に 制限はありません 同様のロジックで ビデオのフレームごとの セグメンテーションには balanced レベルを ストリーミング処理には fast レベルお勧めします 3番目のプロパティは 出力マスク形式です 結果のマスクを詳細に確認します しかしここで 私はクライアントとして リザルトのマスクの フォーマットが 指定できることに 触れたいと思います ここには3つの選択肢があります: 典型的な0〜255ポイントの 符号なし8ビット整数マスク および2つの 浮動小数点マスク形式: 32ビットの全精度のもの もう1つは16ビットの半精度です 16ビットの半精度は 省メモリの浮動小数点形式で Metalを使用した GPUベースの処理で そのまま使えます 人物セグメンテーションリクエストの 作成 設定 実行を どのように行うかを 学びました 今度はリザルトを見てみましょう 人物セグメンテーションリクエスト の処理結果は PixelBufferObservation オブジェクトの形式で提供されます PixelBufferObservation は Observation を継承し 重要な pixelBuffer プロパティが 追加されています このプロパティに格納されている CVPixelBuffer オブジェクトは 人物セグメンテーションリクエストで 設定したピクセルフォーマットと 同じフォーマットです 人物セグメンテーションリクエスト の処理は セグメンテーションマスクを 生成します 元の画像と 人物セグメンテーションリクエスト の実行で生成された 3つの異なる品質レベルの マスク見てみましょう Fast Balanced そして Accurate です ズームインして 各マスクの詳細を見てみましょう 予想通り fast から balanced に 最終的には accurate に 変更すると マスクの品質が向上します 詳細を見てみましょう 品質とパフォーマンスの 関係について それぞれのマスクレベルを 調べてみましょう fastか ら balanced に そして最終的には accurate に 変更すると マスクの品質が上がります ただ リソースの使用量も同様です マスクの品質を上げると ダイナミックレンジ マスク解像度 メモリ消費 処理時間が すべて増加します セグメンテーションマスクの品質と マスクの計算に必要な リソース消費量の間の トレードオフを表しています あなたはすでにマスク生成と それらのプロパティについての すべてを知っています マスクを使うと何ができるのでしょう 3つの画像から始めましょう 入力画像 入力画像を処理して得られた セグメンテーションマスク そして背景画像です 私たちがやりたいのは マスク領域の外側の元画像の背景を 別の背景画像に 置き換えることです このような合成操作を 実行すると 元の画像の若い男が ビーチの遊歩道から 森へと移動します このブレンドシーケンスの コードはどのようになるのでしょうか? まず関連するすべての処理が 完了したと仮定しましょう すでに3つの画像があります: 入力画像 マスク および背景です 次にマスクと背景の両方を 元の画像のサイズに 拡大縮小する必要があります 次にCoreImageの ブレンドフィルターを 作成して初期化します ブレンドフィルターは 赤のマスクで作成しました これはCIImageを 単一コンポーネントの PixelBuffer で 初期化すると (すべてのマスクがそうであるように) デフォルトでは赤のチャネルで オブジェクトが作成されるためです 最後にブレンド操作を実行して 結果を取得します Visionフレームワークで 人物セグメンテーション機能の 使用方法を見てみましょう 2番目のデモAppは すでにダウンロード可能です 顔のポーズメトリック検出を 新しい人物セグメンテーション機能と 組み合わせた物です Appは顔検出と 人物セグメンテーションを実行して カメラフィードを処理します 得られたセグメンテーションマスクの 外側の背景を 異なる色のマスクピクセルに 置き換えます 使用する背景色は その時点での ロール ヨー ピッチの 値の組み合わで決めます 私は現在テーブルと椅子のある 部屋にいます デモAppは私のセグメント化 されたシルエットを 私の頭の位置に応じた カラーミックスである 新しい背景の上に表示します 私の頭の位置に一致させます ロール ヨー ピッチの変化を 追跡するかどうかを見てみましょう このように頭を傾けると ロールが変化して 背景色の混合の決定の大きな要員です 頭を左右に回すと ヨーが主要な要員 そして最後に 上下にうなずきます ピッチが主要な要員です Visionフレームワークだけが 人物セグメンテーションAPIを 提供する場ではありません 同じテクノロジーを搭載した 同様の機能を提供する 他のいくつかの フレームワークがあります それぞれについて 簡単に見てみましょう 最初は AVFoundationです AVFoundationは 人物セグメンテーションマスクを 一部の新世代デバイスで 写真撮影セッション中に 返すことができます AVCapturePhoto の portraitEffectsMatte プロパティを 介してセグメンテーションマスクが 返されます それを取得するには 最初に確認する必要があります サポートされている場合は 配信を有効にします 人物セグメンテーションAPIを 提供する2番目のフレームワークは ARKitです この機能は A12 Bionic 以降の デバイスでサポートされて カメラフィードの処理時に 生成されます ARFrame の segmentationBuffer プロパティを 介してセグメンテーションマスクが 返されます それを取得しようとする前に ARWorldTrackingConfiguration クラスの supportFrameSemantics プロパティで サポートされているかを チェックする必要があります 3番目のフレームワークは Core Imageです Core Imageは Core Image ドメイン内で 全てのユースケースを実行できるよう Visionの人物セグメンテーションAPI上に 薄いラッパーを提供します ここで人物セグメンテーションが どのようにCore Image APIを 使用して実装できるかを 見てみましょう セグメンテーションを実行のため 画像の記録から始めます 次に人物セグメンテーションの CIFilterを作成します inputImageを割り当て フィルタ実行してセグメンテーション マスクを取得します 複数のバージョンの 人物セグメンテーションAPIを AppleのSDKで 見てきました それぞれどこで使用できるかを まとめます AVFoundation では 一部の iOS デバイスで AVCaptureSession で使えます キャプチャセッションを 使っている場合は これを選択すると良いでしょう ARKit Appを 開発している場合は セグメンテーションマスクを 取得できる AR セッションをすでに使っているはずです この場合は ARKit APIを 使用することをお勧めします Vision API はオンラインと オフラインの単一フレームの処理用に 複数のプラットフォームで 利用できます そして最後に Core Image は Vision API に薄いラッパーを提供します Core Image ドメイン内に とどまりたい場合に 便利なオプションです 他のアルゴリズムと同様に 人物セグメンテーションには ベストプラクティスが あります つまり それが最もよく機能する 条件のセットです 人物セグメンテーション機能の 使用を計画している場合は これらのルールに従うと Appのパフォーマンスが 向上します 第一に セグメントを行う場合 画面に最大4名まで 多少重なっていても すべての人が ほぼ見える状態にしてください 第二に 一人一人の身長が 画像の高さの半分以上と なる様にし 理想的には背景と比較して 十分なコントラストが欲しいです そして第三に 彫像や人の写真 遠くにいる人のような あいまいさを避けることも 重要です これでセッションは終了です 今日学んだことを 簡単に見てみましょう まず 概要を説明しました Vision フレームワーク における人体分析技術 マスクをした顔の検出 顔のピッチの識別の追加 顔のポーズ指標の 連続空間での取得 また 人の手のポーズ検出に新しく 右手左手の識別を導入しました 第2部では Vision フレームワーク に追加された 新しい人物セグメンテーション API を深く掘り下げました 同様の機能を提供する 他の API も調べました そしてそれぞれを使用できる ガイダンスを提供しました このセッションを見て App を開発するための 新しいツールを学び すぐに試してみたいとあなたが 思うことを本当に願っています 今日を終える前に ご覧いただきありがとうございます 幸運を願っています WWDCの残りの部分はまだ たくさんあります ♪
-
-
8:13 - Get segmentation mask from an image
// Create request let request = VNGeneratePersonSegmentationRequest() // Create request handler let requestHandler = VNImageRequestHandler(url: imageURL, options: options) // Process request try requestHandler.perform([request]) // Review results let mask = request.results!.first! let maskBuffer = mask.pixelBuffer -
8:33 - Configuring the segmentation request
let request = VNGeneratePersonSegmentationRequest() request.revision = VNGeneratePersonSegmentationRequestRevision1 request.qualityLevel = VNGeneratePersonSegmentationRequest.QualityLevel.accurate request.outputPixelFormat = kCVPixelFormatType_OneComponent8 -
12:24 - Applying a segmentation mask
let input = CIImage?(contentsOf: imageUrl)! let mask = CIImage(cvPixelBuffer: maskBuffer) let background = CIImage?(contentsOf: backgroundImageUrl)! let maskScaleX = input.extent.width / mask.extent.width let maskScaleY = input.extent.height / mask.extent.height let maskScaled = mask.transformed(by: __CGAffineTransformMake( maskScaleX, 0, 0, maskScaleY, 0, 0)) let backgroundScaleX = input.extent.width / background.extent.width let backgroundScaleY = input.extent.height / background.extent.height let backgroundScaled = background.transformed(by: __CGAffineTransformMake( backgroundScaleX, 0, 0, backgroundScaleY, 0, 0)) let blendFilter = CIFilter.blendWithRedMask() blendFilter.inputImage = input blendFilter.backgroundImage = backgroundScaled blendFilter.maskImage = maskScaled let blendedImage = blendFilter.outputImage -
14:37 - Segmentation from AVCapture
private let photoOutput = AVCapturePhotoOutput() … if self.photoOutput.isPortraitEffectsMatteDeliverySupported { self.photoOutput.isPortraitEffectsMatteDeliveryEnabled = true } open class AVCapturePhoto { … var portraitEffectsMatte: AVPortraitEffectsMatte? { get } // nil if no people in the scene … } -
14:58 - Segmentation in ARKit
if ARWorldTrackingConfiguration.supportsFrameSemantics(.personSegmentationWithDepth) { // Proceed with getting Person Segmentation Mask … } open class ARFrame { … var segmentationBuffer: CVPixelBuffer? { get } … } -
15:31 - Segmentation in CoreImage
let input = CIImage?(contentsOf: imageUrl)! let segmentationFilter = CIFilter.personSegmentation() segmentationFilter.inputImage = input let mask = segmentationFilter.outputImage
-