-
Apple Siliconを利用した画像処理Appの作成
画像処理AppをAppleシリコン向けに最適化する方法を紹介します。Metalのレンダリングコマンドエンコーダ、タイルシェーディング、ユニファイド・メモリ・アーキテクチャ、メモリレス・アタッチメントを活用する方法について説明します。Apple独自のタイルベースの遅延レンダラーアーキテクチャを使用して、低メモリフットプリントで電力効率の高いAppを作成する方法や、計算ベースのAppをディスクリートGPUからAppleシリコンに移行する際のベストプラクティスをお伝えします。
リソース
- Debugging the shaders within a draw command or compute dispatch
- Metal Feature Set Tables
- Metal
- Metal Shading Language Specification
関連ビデオ
WWDC20
-
このビデオを検索
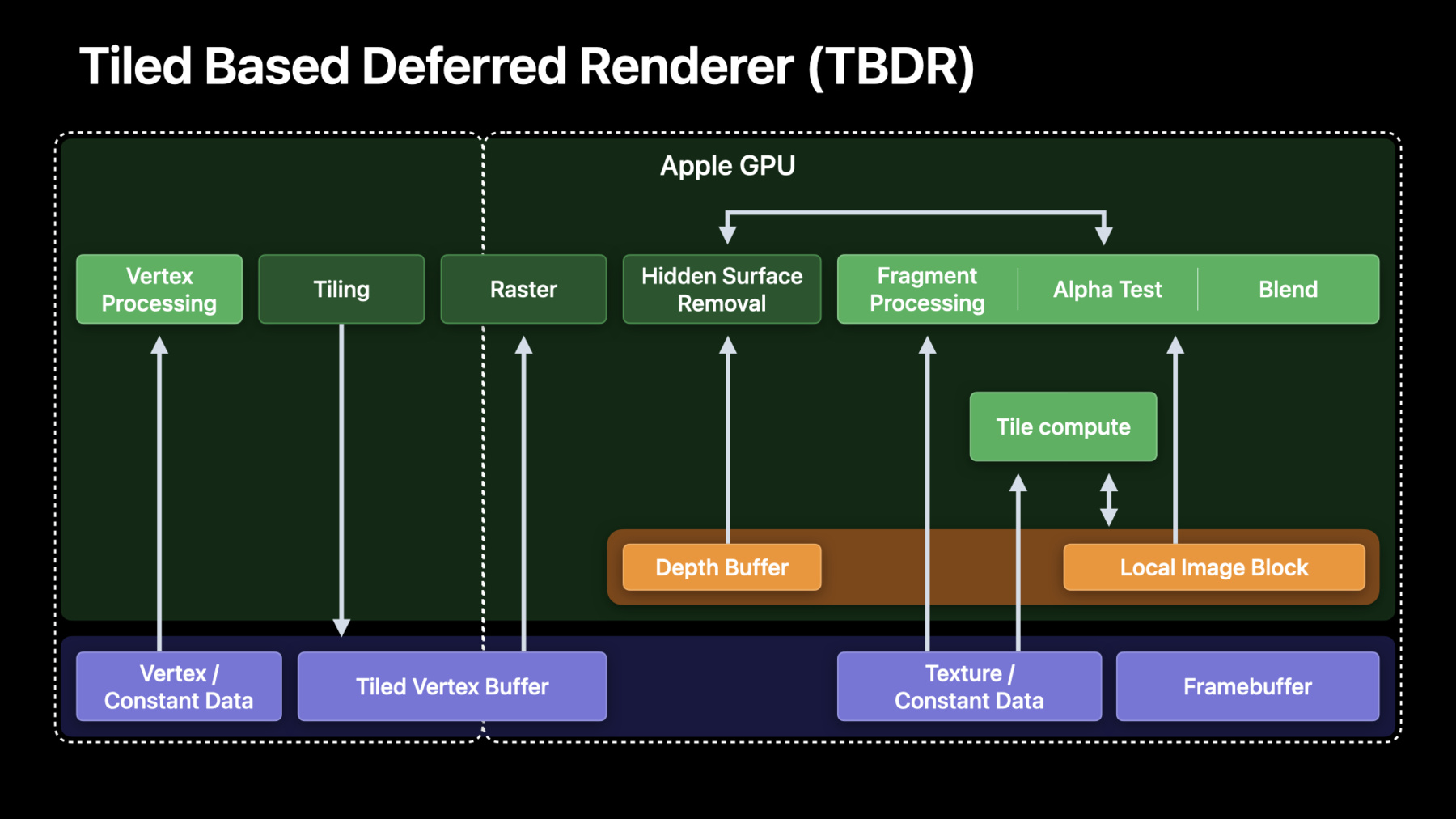
♪ (Apple Siliconを利用した画像処理Appの作成) WWDCへようこそ 私はEugene Zhidkovです GPUソフトウェア部門の者です Macシステムアーキテクチャ部門の Harshも参加します 二人で画像処理Appの作成方法を紹介します Apple siliconのMetalで稼働するものです まず私がフォーカスするのは ベストプラクティスと学習済みのレッスンです M1用の画像処理Appの最適化も 昨年得られた開発者の関与に基づきます そしてHarshが段階ごとのガイドを紹介します Apple silicon上での最適パフォーマンスのために 画像処理パイプラインを設計変更する方法です それでは始めましょう まずAppleシステムを手短に振り返りましょう オン・ザ・チップアーキテクチャとその利点です 多くの画像処理と映像編集Appは 独立したGPUを念頭に設計されています ですからAppleのGPUで何が大きく違うかを 強調することが重要です まず全Appleチップはユニファイド メモリアーキテクチャ使用です すべてのブロック CPU GPU ニューラルエンジン メディアエンジンが ユニファイドメモリ インターフェイスを使用して 同じシステムメモリにアクセスします 次に弊社のGPUはタイルベース デファードレンダラー つまりTBDRです TBDRには2つの主要フェーズがあり まずタイル化です ここでレンダー表面全体がタイルに分割され 形状処理は独立して処理されます そしてレンダリングです ここですべてのピクセルが 各タイルに関して処理され Apple siliconで最も効率的になります 皆さんの画像処理Appは ユニファイドメモリの活用を開始すべきです パイプラインが実施していた コピーを回避しましょう メモリを利用することでTBDR構造や ローカル画像ブロックも 活用しましょう Apple TBDRが低レベルで 機能する方法を知るため 弊社のシェーダーコアを ターゲットにする方法を知るために 昨年のセッションを視聴してください 次に説明するのは まさにApple siliconのために 画像処理キャプチャ負荷を最適化するために 行うことです 昨年 画像パイプライン移行のために 多くの優れた開発者と緊密に作業してきました 弊社には6つの最も役立つヒントがあります まず不必要なメモリコピーを 回避する方法を考えました これが非常に重要なのは 最大8Kの画像で作業しているためです それから レンダーパイプラインと テクスチャを使用する価値を 強調することにしました バッファ上の計算を使用する代わりです そして皆さん自身の画像処理パイプラインで そうする方法もです 我々がレンダーとテクスチャのパスを 稼働させたら 適切な負荷/ストアのアクションと メモリレスアタッチの重要性を 皆さんに紹介したかったのです これでほとんどの タイルメモリ不足が防止できます 次にUberシェーダーの 最適化アプローチを紹介します その動的制御フローを用いて またより小型のデータタイプを 活用する方法も説明します つまりショート型やハーフ型です これは性能と効率性を向上するためです そして最後に重要なアドバイスがあります 最適スループットのための テクスチャ形式についてです いいですね では最も役立つヒントの1つからはじめましょう Apple siliconで不必要な コピーを回避する方法です ほとんどの画像処理Appは 個別のGPUを念頭に設計されています 独立したGPUでは 個別のシステムメモリと ビデオメモリがあります フレーム画像をGPUに表示して 常駐させるために 明示的なコピーが必要です さらにこれは通常2回必要です データをGPUにアップロードして処理して それを引き戻すためです 8K映像をデコードして処理してから ディスクに保存するで これは この場合 CPUスレッドデコーディングです このためデコードされたフレームを GPUのVRAMにコピーします そしてこれがGPUタイムラインです ここですべての効果とフィルタが適用されます さらに一歩進んで思い出してみましょう 結果をディスクに保存する必要がありますね ですから処理済みフレームを システムメモリに戻す事も 考えないといけません そしてフレームの実際のエンコーディングも これらが「コピー」や 「ブリット ギャップ」であり そして高度な画像処理Appは これらの作業のために 深いパイプラインなどの高度な 作業を実施する必要があります しかし吉報はApple GPUです 常駐のためのコピーは もはや不必要です メモリが共有されるため CPUとGPUの両方が メモリに直接アクセスできます ユニファイドメモリシステムで 実行して不必要なコピーを 回避しているか簡単な チェックを追加してください これでメモリや時間を節約でき これは実施すべき 絶対的な第一歩です これがコピーを排除して統一メモリ構造を 実施したところです コピーを排除することで 完全にコピーギャップを回避でき 処理を即座に開始できます これでCPUとGPUのパイプラインも向上し 楽になります 必ずユニファイドメモリパスを実装して コピーを排除してください ブリット コピーを放置した場合は まさに独立GPUの場合と 同じになります システムメモリの帯域幅を利用し 実際の処理ではGPU時間が短くなり スケジューリングオーバー ヘッドの可能性があります 当然個別のVRAM画像を配置する 必要はありません GPUフレームキャプチャにより 大型ブリットを特定できます Appのブリットを検査して 必要なコピーだけを行うようにしてください では画像処理でAppleGPU TBDR の活用を 実際にどのように開始するかを 説明します ほとんどの画像処理Appは 一連の計算カーネルを利用して 画像バッファ上で動作します 計算カーネルを利用するとき デフォルトのシリアルモードでは Metalがすべてのその後の利用で すべてのメモリ書き込みが 見えることを保証します この保証は全シェーダコアでの メモリ一貫性を含意するので あらゆるメモリ書き込みが 次の利用開始までに 他のすべてのコアに可視になります これはメモリトラフィックがとても 高くなることも意味します 画像全体を読み書きする必要があるためです M1のApple GPUはMacOSでの タイルディスパッチを可能します 通常の計算と対称的に タイルのみの同期ポイントで これらはメモリで動作します 畳み込みなどの一部のフィルタは タイルのパラダイムにはマップできませんが 多くの他のフィルタは可能です エンコーダの端点までシステム メモリフラッシュを遅延して 明確な効率性ゲインが得られます システムメモリ帯域幅で制限されないときは より有用なGPU作業を実行できます これをさらに進めて 多くのピクセルごとの操作が 隣接ピクセルへのアクセスを必要としないので タイル同期点は必要ありません これは断片化機能によくマッピングします 断片化機能は明示的なタイル同期なしで 実行できます 同期が必要なのはエンコーダの境界や タイルカーネルが断片カーネルのあとで シリアルに利用されるときだけです AppleのGPUが断片化機能と タイルカーネルを有効化して より効率的に画像処理することを説明しました これの使い方を説明します 弊社では通常のテクスチャへの コマンドエンコーダをレンダする バッファ上の計算利用を転換してこれを行います すでに説明したように経験則は次のとおりです ピクセル間の依存性のないピクセルごとの操作は 断片化機能を使用して実装するべきです スレッドグループスコープ機能のあるフィルタは シェーディング付きで実装するべきです これはタイル内の隣接ピクセル アクセスが必要なためです スキャッターギャザーと畳み込みフィルタは タイルパラダイムにマップできません これはそこでランダムアクセスが必要なためです このためこれらは計算利用に 依然として留まります レンダーコマンドエンコーダも ユニークなApple GPU機能を有効にします テクスチャとレンダーターゲットの ロスレス帯域幅圧縮です これは優秀な帯域幅節約機能であり 画像処理パイプラインではなおさらです これを行う方法を説明します ロスレス圧縮を有効にする方法を説明します すべきでないことを説明するのは 実際にはより簡単です まず圧縮済みのテクスチャ形式は ロスレスの利益が得られません 次にこの圧縮で機能しない3つの特定の テクスチャフラッグがあるので 誤ってこれらを設定しないでください そして3番目に線形テクスチャや MTLBufferへのバックも 許可されません 非プライベートテクスチャでは ある種の特殊な処理も 必要です optimizeContentsForGPUAccessを 必ず呼び出します これは最速パスにとどまるためです GPUフレームキャプチャサマリーペインに ロスレス圧縮警告が表示され テクスチャがオプトアウト された理由がハイライトされます PixelFormatViewフラグが この例で設定されました 多くの場合に 開発者はこれらのフラグを 意図せず設定しています PixelFormatViewを設定すべきでないのは コンポーネントスウィズルや SRGB変換のみが必要な場合です これで レンダーパスおよびテクスチャパスを 稼働できました それではタイルメモリを正しく 使用していることを確認します メモリTBDRの概念は ロード/保管動作とメモリレス添付などですが デスクトップの世界ではまったく 新しいものです このためこれらを正しく使用しましょう ロード/保管アクションから始めましょう すでに説明したように レンダーターゲット全体がタイルに分割されます ロード/保管はタイルごとのバルク動作であり メモリ階層の中で最適パスを取ることが 保証されます これらはレンダーパスの最初に実行されます つまりタイルメモリを初期化する 方法をGPUに伝えるときであり パスの最後にGPUに伝えるのは どの添付を書き戻す必要があるかです ここで重要なのは 不必要な ものをロードしないことです 画像全体を上書きする場合 またはリソースが一次的な場合は LoadActionDontCareにロード動作を設定します レンダーエンコーダーで 出力や一時データをクリアする 必要はもはやありません これは以前は専用計算パスや fillBufferコールでやっていたことでしょう LoadActionClearを設定して クリア値を効率的に指定できます そして保管動作も同じようにします 後で必要になるデータだけを保管します それは主要な添付などであり 一時的なものは保管しません 明示的なロード動作や保管動作に加えて Apple GPUはメモリフット プリントを節約します これはメモリレス 添付によります 我々は添付をメモリレス 保管モードを持つものとして 明示的に定義できます これでタイルのみのメモリ 割り当てが可能になり エンコーダ寿命内だけであらゆる各タイルで リソースが永続します これでメモリフットプレリントを 大幅に削減でき 6K/8K画像ではなおさらです そこでは各フレームが 数百メガバイトになるためです これをコードで実施する方法を説明します textureDescriptorをまず作成し 次にoutputTextureを作成します 次に一時テクスチャを作成します 私はこれをメモリレスとマークしました ここでストレージは必要ないためです それからレンダーパスを作成します 最初に添付が何かを記述し 次にロード/保管動作を記述します 出力のロードは気にしません 完全に上書きされるためですが これを保管する必要があります 一時テクスチャとしてはロードせずクリアし これを保管する必要もありません 最後に記述子からレンダーパスを作成します これだけです こうしてユニファイドメモリを使用し 画像処理パイプラインを移動して コマンドエンコーダをレンダリングし タイルメモリを適切に利用しています ここでウーバーシェーダーについて説明します ウーバーシェーダーやウーバーカーネルは 開発者を楽にする人気の手法です ホストコードで制御構造が設定され シェーダーは一連のif/else文を 単にループするだけです たとえばトーンマッピングが有効な場合や 入力がHDR形式やSDR形式の場合は このアプローチは 「ウーバーシェーダー」とも呼ばれ パイプライン状態オブジェクトの 合計数を削減するとても良い方法です しかし欠点もあります 主な欠点はレジスタ圧を増加させることですが これはより複雑な制御フローを扱うためです 使用するレジスタが増えると シェーダーが実行される 最大占有率が簡単に制限されます 制御構造で通過する単純なカーネルを考えます 構造の中のフラグを使用して すべきことを制御します ここに2つの機能があります 入力がHDRの場合とトーン マッピングが有効な場合です すべて良好に見えますね これがGPUで起こっていることです コンパイル時には何も推論できないため HDRとHDR以外の両方のパスを取ると 想定する必要があり フラグに基づいて結合します トーンマッピングでも同じです 我々はこれを評価してから 入力フラグに基づいて 内外にマスクします ここでの問題はレジスタです あらゆる制御フローパスで ライブレジスタが必要です これはウーバーシェーダーが 苦手な分野です ご存知のように カーネルで使用するレジスタで シェーダーが実行される 最大占有率が定義されます これはレジスタファイルがシェーダーコアの 全simdlaneで共有されるためです 必要なものだけを実行できるなら simdgroup占有率とGPU利用率が 向上します これを修正する方法です Metal APIにはこの作業に適したツールがあり "function_constants"と呼ばれています 両方の制御パラメータを function_constantとして 定義し ふさわしくコードを修正します ここに修正済みカーネルコードがあります ホスト側も更新してパイプライン作成時に function_constant 値を提供する必要があります レジスタ圧を減少する別の優れた方法は シェーダーで16ビット型を使用することです Apple GPUにはネイティブの 16ビットサポートがあります このためより小型の データタイプを使用するときは シェーダーが必要なレジスタが少なくなり 占有率が増加します ハーフ型やショート型もエネルギー要求が少なく より高いピークレートを 達成する可能性があります このため ハーフ型やショート型を使用して 可能ならfloatやIntを避けてください これは型変換が通常自由なためです この例では 一部の計算でスレッドグループで thread_positionの使用を考慮します 符号なしintを使用しますが Metalがサポートする 最大スレッドグループサイズは 符号なしショート型に簡単に適合できます しかしthreadgroup_position_in_gridで より大きなデータ型が 必要となることもあります しかし画像処理で使用するグリッドサイズは 最大8Kや16Kであり 符号なしショート型で十分です 代わりに16ビット型を 使用するなら結果のコードでは 使用するレジスタの数がさらに減り 占有率が増加する可能性があります ここでレジスタのすべての詳細が わかるところを説明します Xcode13のGPUフレームデバッガーに レンダー タイル P50計算用の 先進のパイプライン状態 オブジェクトビューが搭載されました レジスタ使用率とともに 詳細パイプライン統計を検査して すべてのシェーダーを微調整できます 関係するレジスタをカバーして テクスチャ形式を説明します 最初に多様なピクセル形式が 多様なサンプリングレートに なりうることを指摘します ハードウェア生成やチャネル数により より幅広い浮動小数点型で ポイントサンプリングレートが 減少することがあります 特にRGBA32Fなどの浮動小数点形式は サンプリングが値をフィルタしたときに 浮動小数点16ビット型よりも遅くなります より小型の型を使用するとメモリストレージ 帯域幅 キャッシュフットプリントも 削減されます このため可能な最小の型を 使用することを推奨します しかしテクスチャストレージのこのケースでは これは実際には画像処理の 3D LUTの一般的なケースで 我々が作業するほとんどのAppは バイリニアフィルタを有効にした 3D LUT AppフェーズでRGBAを使用します Appで代わりにハーフ型を使用できないか 精度が十分かを考察してください その場合は FP16にすぐに切り替えてピーク サンプルレートを達成します ハーフ型の精度が十分でないなら 固定少数点符号なしショートで すばらしい均一レンジの値が 可能なことが分かります このためユニットスケールで LUTをエンコードし LUTレンジをシェーダーに 与えることは ピークサンプルレートと十分な 数値精度の両方を得るための すばらしい方法でした これでApple GPU構造を利用して 画像処理パイプラインを 可能な限り効率的に実行する 方法を説明しました これをすぐに適用する方法は Harshが説明します Eugene ありがとう ではApple siliconで 画像処理パイプラインを 設計変更する方法を説明します これは学習してきた全ベスト プラクティスに基づきます とりわけ Apple GPU用に映像処理パイプラインの 画像処理フェーズを改良します リアルタイム画像処理はまさにGPU計算であり メモリ帯域幅を必要とします 最初に通常の設計方法を説明してから Apple silicon用に最適化する方法を説明します この節では映像編集ワークフローの 詳細には触れないので 2年前の我々のセッションを参照してください 我々はパスをレンダーするための 画像処理の計算部分への 移行だけにフォーカスします 開始する前に 一般的な映像処理パイプラインで 画像処理フェーズが ある場所を手短に調べましょう ProResエンコード済みの 入力ファイルを例に取ります ProResエンコード済み フレームをまずディスクや 外部ストレージから読み出します それからCPUでフレームをデコードし 画像処理フェーズを このデコード済みフレームにGPUで実行し 最終出力フレームをレンダーします 最後に この出力フレームを表示します またさらにこの最終レンダー フレームをデリバリ用に エンコードします 次に画像処理パイプラインを 構成するものを説明します 画像処理はソース画像のRGBとアルファの 多様なチャネルをアンパックし別個のバッファに 入れることで開始します これらのチャネルのそれぞれを 画像処理パイプラインで 一緒または個別に処理します 次に色空間変換を実施して 必要な色管理環境で動作させます 次に3D LUTを適用し色補正を実行し 空間一時ノイズ除去 畳込み にじみなどの効果を適用します そして最後に 個別に処理されたチャネルを一緒にパックして 最終出力します これらの選択した手順に 共通なものは何でしょうか すべてポイントフィルターです ピクセル間の依存性がなく 単一ピクセルのみで機能します これらは断片シェーダー実装に よくマップします 空間スタイルと畳込み スタイルの動作では 大半径のピクセルへの アクセスが必要で 拡散読み書きアクセス パターンも必要です これらが計算カーネルに 適しています この知識は後ほど使います 今のところは これらの操作を 実行する方法を説明します Appはフィルタグラフとして 画像に適用される一連の効果を表します あらゆるフィルタはそれ自体のカーネルであり 前の段階からの入力を処理し 次の段階への出力を作ります ここでのあらゆる矢印が 1つの段階出力に書き込まれ 次の段階で入力として読み取られる バッファを意味します メモリが制限されているので Appは通常位相ソートを行って グラフを線形化します これは中間リソースの合計数を できるだけ少なく保つため また競合状態を回避するために行います この例の単純なフィルタグラフは 競合状態なしに動作して 最終出力を作成するために 2つの中間バッファが必要です この線形化グラフはおおむね GPUコマンドバッファ エンコーディングも示しています このフィルタグラフが非常に多くの デバイスメモリ帯域幅を必要とする 理由を説明します あらゆるフィルタ動作は デバイスメモリから レジスタに画像全体を ロードして 結果をメモリデバイスに 書き戻す必要があります そしてこれはかなりの メモリトラフィックです 4Kフレーム画像処理のメモリ フットプリントを 画像処理グラフの例に 基づいて考えましょう 4Kデコード済みフレーム自体は 浮動小数点16ビット精度で 68Mバイトのメモリを 消費します 浮動小数点32ビット精度では 135Mバイトのメモリです またプロフェッショナル ワークフローは 絶対に浮動小数点32ビット 精度が必要です この画像処理グラフで浮動小数点 32ビット精度で1つの 4Kフレームを処理するには 2ギガバイトを超える デバイスメモリへの読み書き トラフィックが必要です また中間出力を持つバッファへの 書き込みは キャッシュ階層を進み チップの他のブロックにも 影響します 通常の計算カーネルは オンチップタイルメモリから 暗黙的に利益を得ません カーネルはスレッドグループ スコープメモリを明示的に割り当て これはオンチップタイル メモリに支えられます しかしそのタイルメモリは 計算エンコーダ内の ディスパッチ間で 永続的ではありません 対称的にタイルメモリは 実際に1つのレンダー コマンドエンコーダ内の ドローパス間で永続します 我々がこの代表的な画像処理 パイプラインを設計変更して タイルメモリを利用する 方法を説明します 我々は以下の3段階で これに対処しています まずレンダーパスへの 計算パスおよび テクスチャへのすべての中間出力 バッファを変更しています それから1つのレンダーコマンド エンコーダー内の 断片シェーダー 呼び出しとして ピクセル間依存性のないピクセル 操作をエンコードします すべての中間結果を配慮し 適切なロード/保管動作の 設定を確認します そして最後に単なるポイント フィルタよりもより複雑な状況で 作業することを説明します 最初の段階は別個の TLRenderCommandEncoderで 対象のシェーダーを エンコードすることです このフィルタグラフでアンパック 色空間変換 LUT および 色補正フィルタはすべてポイントの ピクセルごとのフィルタです これを断片シェーダーに 変換して 1つのレンダコマンドエンコーダを 使用してエンコードします 同様に ミキサーおよび パックシェーダーも この画像処理パイプ ラインの 終了に向かって 断片シェーダーに変換でき 他のMTLRenderCommandEncoderを 使用してエンコードできます それからそれぞれの レンダーパスの中で これらのシェーダを 呼び出すことができます レンダーパスを作成するときは そのレンダーパス内の色添付に 添付された すべてのリソースは明示的に タイルされます 断片シェーダーはそのタイルの 断片の位置に 関連付けられた画像ブロック データのみを更新できます 同じレンダーパスの次のシェーダーは メモリから直接以前のシェーダーの出力を 取ることができます 次の節では これらのフィルタにマップする 断片シェーダーを構築する方法を 説明します またこれらの断片シェーダーの中から規定の タイルメモリにアクセスできるように 定義して使用する必要がある 構造も説明します そして最後に 同じレンダー コマンドエンコーダーの中の 次の断片シェーダーにより タイルメモリから 直接消費できる 1つの断片シェーダーにより タイルメモリ内に出力が 生成される方法も説明します これがコードですべきことです ここで私はレンダーパス記述子の 色添付0に添付される テクスチャとして出力画像を添付しました 私はレンダーパス記述子の色添付1への 中間結果を保持するテクスチャを添付しました これらの両方が暗黙的にタイルされます セッションで説明したように適切なロード/保管 プロパティを設定してください そして断片シェーダーの中のこれらの テクスチャにアクセスする構造を設定します 次の例では 断片シェーダー内でこの構造を 使用する方法を説明します すでに定義した構造を使用して 強調されているように 断片シェーダー内の出力および 中間テクスチャに アクセスするだけです これらのテクスチャへの書き込みは 断片に対応する適切な メモリ位置に行われます アンパックシェーダーにより生産される出力は すでに定義した同じ構造を使用する 色空間変換シェーダーにより 入力として消費されます この断片シェーダーは それ自体の処理を実施でき 出力と中間テクスチャを更新します これは今一度 対応するタイルメモリ位置を更新します あなたはすべての他の断片シェーダーのために 同じレンダーエンコーダーパスの中で 同じ手順を続行します 次にこの動作シーケンスがこれらの変更で どのように見えるかを示します お分かりの通りアンパックし 色空間変換 3D LUTの適用 および色補正手順を行い すべて1つのレンダーパスを使用しますが 間にデバイスメモリパスはありません レンダーパスの終わりに メモリレスでないレンダーターゲットは デバイスメモリにフラッシュされます それからフィルタの次のクラスを実行できます 散乱収束アクセスパターンのある フィルタについて少し説明します こうしたフィルタを表すカーネルは デバイスメモリで直接データに作用できます 畳み込みフィルタは計算カーネルの タイルベースの動作に非常に適しています ここでスレッドグループスコープ メモリを宣言することで タイルメモリを使用する意図を 表明できます 今ピクセルのブロックを 必要な全ハロピクセルとともに タイルメモリに移動します フィルタ半径に従い タイルメモリで 直接畳み込み 動作を実行します ただしメモリは計算エンコーダ内の 計算ディスパッチを通して永続しません このためFilter1 を実行したあとは タイルメモリの内容をデバイスメモリに明示的に フラッシュする必要があります この方法でFilter2はFilter1の出力を消費します ではこれらの変更をすべて実施 したらどこに行くべきでしょうか 1つの4Kフレームを浮動 小数点32ビット精度で この例の再構成された画像処理 グラフで処理するために これが今得られているものです 帯域幅は2.16ギガバイトから 810メガバイトをロードして 保管できる規模に下がり デバイスメモリへの メモリトラフィックは 62%の削減です 2つの中間デバイスバッファーは不要になり フレームごとに270Mバイトの節約です そして最後にキャッシュスラッシュを 削減していますが これはそのレンダーパス内のすべての 断片シェーダーが直接メモリ上で 動作しているためです Apple siliconの主要機能の1つは ユニファイドメモリアーキテクチャです Apple silicon上の別々の ブロック間でのやり取りのために このユニファイドメモリアーキテクチャを 使用する例を説明します ケーススタディとしてGPUでレンダーされた 最終映像フレームのHEVCエンコードを使います このエンコードは Apple siliconの専用ハードウェア メディアエンジンを使用して実施されました GPUによりレンダーされた 最終出力フレームは 追加のメモリコピーなしで メディアエンジンにより 直接消費できます 次の節では 最も効率的な方法でGPUに より生産された 最終出力フレームのHEVC エンコードのためにパイプラインを セットアップする例を説明します そのために まず IOSurfacesで支援された ピクセルバッファのプールを作成するために CoreVideo APIを利用します それからMetal APIを使用して 作成したばかりのプールから IOSurfaceで支援される Metalテクスチャへと 最終フレームをレンダーします そして最後に GPUが生産した 出力フレームの 追加コピーなしにエンコード用に メディアエンジンに直接 これらのピクセルバッファを ディスパッチし ユニファイドメモリ アーキテクチャを活用します これを実行する方法をステップ ごとに説明し このフローを 有効化するために必要なすべての 構成をカバーします 最初に必要なピクセル形式で IOSurfaceに支援される CVPixelBufferPoolを作成します ここでHEVCエンコード用の バイプレーナークロマ サブサンプル済みのピクセル 形式を使用します ここでCVPixelBufferPoolから CVPixelBufferを得ます このCVPixelBufferを正しいライト プレーンインデックスとともに MetalTextureCacheに渡し CVMetalTextureReferenceを得ます バイプレーナーピクセル形式を 使用しているので バイプレーナー ピクセルバッファーの両面で この手順を実行する必要があります 次にCVMetalTextureReference オブジェクトから 基底のMetalテクスチャを取得します この手順をルマ面と クロマ面の両方で実施します これらのMetalテクスチャは CVPixelBuffer 面も支援する 同じIOSurfacesにより支援されます Metal APIを使用し ルマ面およびクロマ面に対応する テクスチャにレンダーします これでこれらのMetalテクスチャも 支援するIOSurfaceが更新されます 画像処理パイプライン内の シェーダーパスとして GPU自体のクロマ サブサンプリング手順を 実施することを強く推奨します 注意すべき点は レンダー直後のCVPixelBufferと Metalテクスチャの両方が システムメモリの 同じ基底 IOSurfaceコピーで 支援されることです これでCVPixelBufferをエンコードのために 直接メディアエンジンに送信できます ご覧のように ユニファイドメモリ アーキテクチャのために メモリコピーなしにシームレスに データをGPUと メディアエンジンブロックの 間で移動できます そして最後にあらゆるフレームの あとCVPixelBufferと CVMetalTexture 参照を解放します CVPixelBufferを解放すると 次のフレームのためにこの バッファをリサイクルできます つまり 再び以下のことをお勧めします 該当する場合は 計算の代わりに MTLRenderCommandEncoderを 使用すること 1つのレンダーコマンドエンコーダー内に すべての該当するレンダー パスをマージすること 適切なロード/保管アクションを 設定すること 一時リソースのために メモリレスを使用すること 該当する場合はタイル シェーディングを利用すること またゼロコピーで他のAPIで バッファプールを使用すること 今日はセッションに来ていただき ありがとうございました WWDC 2021の他の セッションもお楽しみください
♪
-
-
10:53 - Memoryless attachments
let textureDescriptor = MTLTextureDescriptor.texture2DDescriptor(…) let outputTexture = device.makeTexture(descriptor: textureDescriptor) textureDescriptor.storageMode = .memoryless let tempTexture = device.makeTexture(descriptor: textureDescriptor) let renderPassDesc = MTLRenderPassDescriptor() renderPassDesc.colorAttachments[0].texture = outputTexture renderPassDesc.colorAttachments[0].loadAction = .dontCare renderPassDesc.colorAttachments[0].storeAction = .store renderPassDesc.colorAttachments[1].texture = tempTexture renderPassDesc.colorAttachments[1].loadAction = .clear renderPassDesc.colorAttachments[1].storeAction = .dontCare let renderPass = commandBuffer.makeRenderCommandEncoder(descriptor: renderPassDesc) -
12:25 - Uber-shaders impact on registers
fragment float4 processPixel(const constant ParamsStr* cs [[ buffer(0) ]]) { if (cs->inputIsHDR) { // do HDR stuff } else { // do non-HDR stuff } if (cs->tonemapEnabled) { // tone map } } -
13:32 - Function constants for Uber-shaders
constant bool featureAEnabled[[function_constant(0)]]; constant bool featureBEnabled[[function_constant(1)]]; fragment float4 processPixel(...) { if (featureAEnabled) { // do A stuff } else { // do not-A stuff } if (featureBEnabled) { // do B stuff } } -
23:02 - Image processing filter graph
typedef struct { float4 OPTexture [[ color(0) ]]; float4 IntermediateTex [[ color(1) ]]; } FragmentIO; fragment FragmentIO Unpack(RasterizerData in [[ stage_in ]], texture2d<float, access::sample> srcImageTexture [[texture(0)]]) { FragmentIO out; //... // Run necessary per-pixel operations out.OPTexture = // assign computed value; out.IntermediateTex = // assign computed value; return out; } fragment FragmentIO CSC(RasterizerData in [[ stage_in ]], FragmentIO Input) { FragmentIO out; //... out.IntermediateTex = // assign computed value; return out; }
-