-
Metalのコンパイルワークフロー
Metalシェーディング言語は強力なC++ベース言語で、柔軟なシェーダ開発パイプラインを維持しながら、Appで驚くべき効果をレンダリングすることができます。ダイナミックライブラリとファンクションポインタを使用して、レンダリングパイプラインをより簡単に構築・拡張する方法について確認します。また、バイナリ関数アーカイブ、関数リンキング、関数スティッチングを使用して、ランタイムでのシェーダのコンパイルを高速化する方法も紹介します。
リソース
- Shader libraries
- Creating a Metal dynamic library
- Metal Feature Set Tables
- Metal
- Metal Shading Language Specification
関連ビデオ
WWDC23
WWDC22
WWDC21
WWDC20
-
このビデオを検索
こんにちは Rini Patelです GPUソフトウェア エンジニアリング担当です 今回は Metalの新しい シェーダコンパイルの ワークフローを紹介します Metalシェーディング言語は C++ベースの言語であり そのコンパイルモデルは CPUのモデルに似ています GPUのワークロードが複雑化し Metalも最新ユースケースを サポートするため柔軟に パフォーマンスを上げました シェーダをオーサリングする 際によくある既存の課題は パイプライン間での ユーティリティコードの共有 再コンパイルせずに実行時に シェーダの動作の変更 App起動間で コンパイルされた GPUバイナリを再利用する ことなどがあります 簡単なシェーダのコードで シナリオを検討してみます
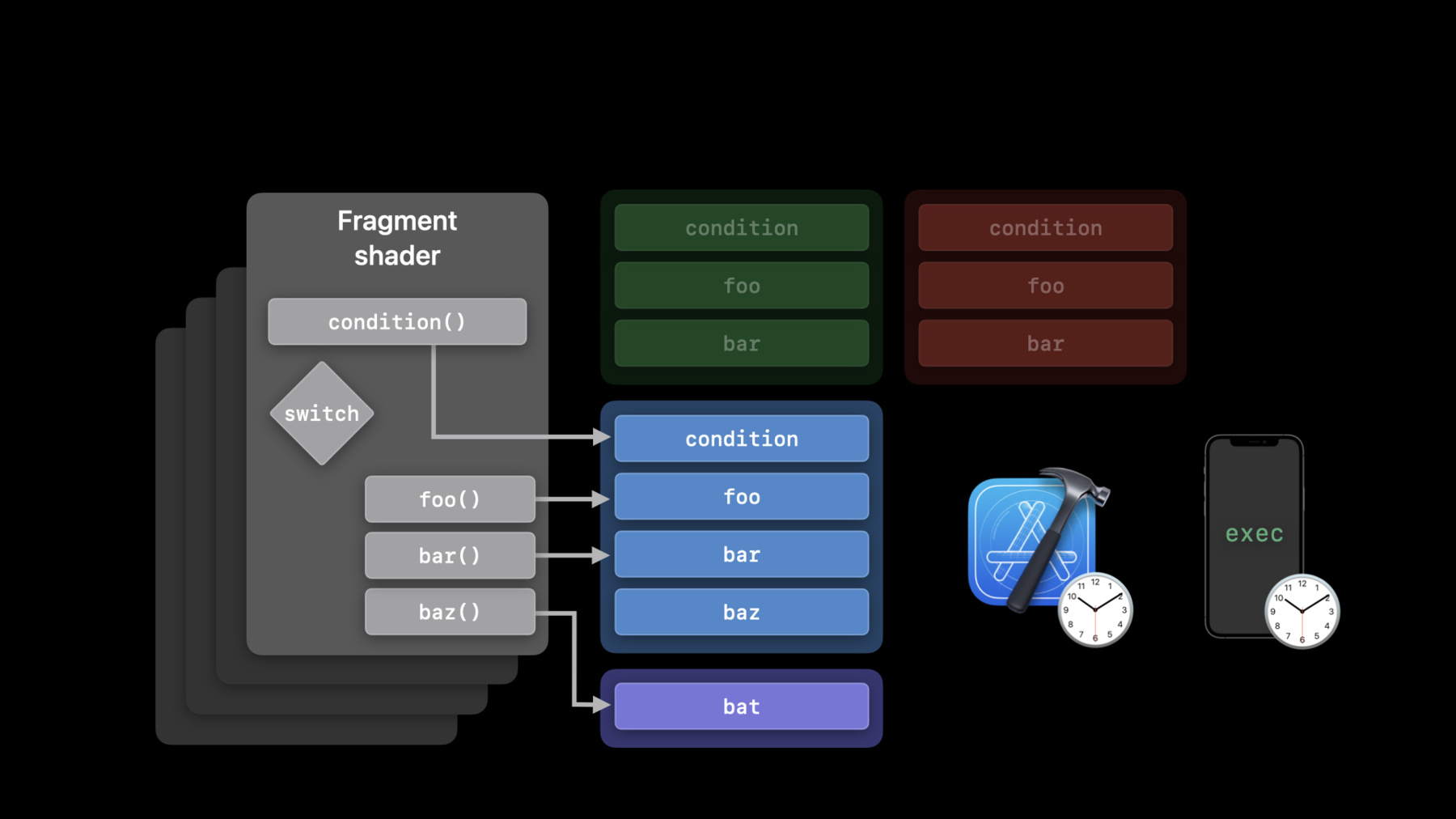
条件の結果に応じてfoo() またはbar()の結果を返す シンプルなフラグメント シェーダを用意しました この関数が複数パイプライン から呼び出される場合 一度にコンパイルして 各パイプライン にリンクする方法が考えられます
これらの関数の別の実装を 実行時にリンクするか baz()の 新しいケースステートメントを 処理するため フラグメントシェーダを 拡張する必要が あるかもしれません また フラグメント関数から baz()ではなくbat()という ユーザー提供の関数を 呼び出したい場合もあります このように シェーダ オーサリングパイプラインは さまざまな要件があり Metalはさまざまな実装を サポートするために さまざまなAPIを提供します それぞれのアプローチは コンパイル時間とシェーダの パフォーマンスの間の トレードオフが異なります パフォーマンスと柔軟性の バランスをとるのに役立つ コンパイルワークフローに ついてお話します レンダーパイプライン用の ダイナミックライブラリと レンダーパイプライン用の 関数ポインタを 新たにサポートする ことから始めます binaryArchive APIへの 追加機能もお話します それからプライベートリンク 機能を見ましょう 最後にMetalで可視化された 機能をスティッチングする 全く新しい機能を紹介します まずMetalのダイナミック ライブラリ対応について ダイナミックライブラリは 一般的なツールです ユーティリティコードを独立した コンパイルユニットに 区分けするための共有 オブジェクトファイルです コンパイルされた シェーダコードを減らし 複数のパイプライン間での 再利用に役立ちます さらに GPUのバイナリコード を動的にリンクしたり 読み込んだり 共有することも可能です
昨年はコンピュートパイプラインの ための動的言語を紹介しましたが Metalの動的ライブラリについて 詳細は昨年のプレゼンテーション 「MetalでGPUバイナリを作成する」 をご覧ください 今年レンダーパイプラインや タイルパイプラインに ダイナミックライブラリを導入し 全ワークロードで ユーティリティライブラリを 共有できるようになりました ダイナミックライブラリとは 何かを理解したところで 次はユースケースを 紹介しましょう ヘルパー関数は一般的な コンピュートやバーテックス フラグメント タイルシェーダで よく使用されます ダイナミックライブラリを 追加することで 大量のユーティリティコードを管理し 全ワークロードで共有できます 実行時に使用されうる ライブラリを コンパイル時の減速なしで プリコンパイルできます さらにパイプライン作成時に読み込む ライブラリを変更するだけで実行時に 関数を切り替えることもできます ソースを提供しなくても ユーザーがシェーダコードを作成し パイプラインの一部として ロードすることも可能です ダイナミックライブラリをいつ 使うかについて話しました では どのように構築し 扱うかを見ていきましょう フラグメントシェーダの例では 関数foo()とbar()を呼び出しますが コンパイル時には どちらも実装しません これらの関数の実装は Metalのライブラリにあり レンダリングパイプラインを 作成する際にリンクします 使用する可能性のある 機能ごとに 別々のライブラリを 用意することも可能です では Metalでダイナミック ライブラリを構築する際の ツールと柔軟性について 説明します まず Metalシェーダのソース をAIRにコンパイルします Metalツールチェーンを使うか newLibraryWithSource APIを 使用したソースからのコンパイルかの いずれかで行います AIRにMetalシェーダを コンパイルしたら newDynamicLibrary APIで ダイナミックライブラリを作成でき GPUのバイナリ形式で使用できます 後から再利用したい場合は どうでしょう? serializeToURL APIで ダイナミックライブラリを ディスクにシリアル化し newDynamicLibraryWithURL API を呼び出せば再利用できます ダイナミックライブラリと フラグメントシェーダから 関数を呼び出す例を 見てみましょう 関数foo()とbar()をextern キーワードで宣言しますが 定義はしていません フラグメントシェーダから この関数を呼び出すだけです Metalライブラリを 構築する際に extern関数の実装を 提供することができます これらの実装を実行時に 別のものに置き換えることも 可能だと覚えておいてください そのためには ダイナミックライブラリを 適切なプリロードライブラリ 配列に追加するだけです 例ではフラグメントですが 同様のプロパティが ステージやパイプライン ごとに用意されています この配列にライブラリが 追加されたのと同じ順番で シンボルが 解決されていきます このワークフローは 新しい実装を試すのに 適しています ダイナミックライブラリ については以上です Metalのダイナミックライブラリは macOS Monterey の Apple GPUファミリー7 以上に対応しています 他のGPUやほとんどのMacファミリー2 デバイスにも対応していますが Metalのデバイスダイナミックライブラリ サポートを呼び出す必要があります iOS 15ではこの機能は Apple6以上の全デバイスで使えます レンダーやタイルパイプラインは Apple6をサポートする 全デバイスで利用可能です
次に今年加わった関数ポインタの 改良について説明します
関数ポインタは これまで見たことのない 関数を呼び出すことができる コードを参照する構成で コードの拡張性が 高まります コンピュートパイプラインの 関数ポインタについては 昨年のプレゼンテーション 「Metal関数ポインタの紹介」を 確認してください 今年 Apple Siliconのタイルと レンダリングパイプラインに 関数ポインタのサポートを 拡大します ダイナミックライブラリ同様 カスタマイズ可能な パイプラインを 作ることができます 関数ポインタを使えば パイプライン コンパイル時にはなかった コードをGPUパイプラインで 呼び出すことができます 関数ポインタテーブルでは 異なる関数テーブルを バインドしたときや GPUパイプラインが インデックスを付けると コードの動作が動的に変化します また 関数ポインタを使って コンパイル時と実行時の パフォーマンスのバランスを 取ることもできます 最速でコンパイルするために 関数ポインタをGPUバイナリに プリコンパイルして パイプラインで素早く対処できます 一方 実行時のパフォーマンスを 向上させるためには パイプラインがAIR表現の 関数を参照するようにして コンパイラが最大限の 最適化を行えるようにします コードで関数ポインタを設定 する方法を見てみましょう 3つに大きく分かれています まず関数を インスタンス化し その関数で パイプラインを構成し 最後に関数テーブルを 作成します 新しいレンダリングループの使用 に多くのコードは不要です ではワンステップずつ 見ていきましょう まず関数ディスクリプタを宣言し GPUバイナリバージョンを コンパイルするために インスタンスを作成します パイプライン作成を短縮でき ディスクリプタを宣言し バイナリにコンパイルする オプションの設定だけです これでライブラリから Metal関数fooを作成すると GPUバックエンドコンパイラ によってコンパイルされます 次にレンダーパイプライン ディスクリプタを設定します まず パイプライン ディスクリプタを介し 頂点 フラグメント タイルなど 関数を使用する ステージに追加します 関数の追加は AIRか バイナリ形式で選択できます AIR関数を追加する際 コンパイラが可視化された 関数を静的にリンクするため バックエンドのコンパイラが コードを最適化できます 一方バイナリ関数を追加すると 外部でコンパイルされた関数が パイプラインから呼び出せる形で ドライバに通知します バイナリ関数を使用し パイプラインを作成する際 呼び出しているコードが 例示されているように 複雑な呼び出しチェーンを 持つ場合 コンパイラが 深さを決定する静的解析を 行えないため 必要な最大呼び出し時間を 指定することが重要です 実行される最大の深さを デフォルトとします 正確でないと スタック オーバーフローが発生します 逆に言えば 深さを正しく 指定すれば より良い リソースコンセプションと パフォーマンスになります ディスクリプタの 設定が完了したら 関数ポインタを使える パイプラインを作成できます 次に 可視化された 関数テーブルを作成し APIの関数ハンドルを 入力します ディスクリプタを使い可視化 された関数テーブルを作成し レンダリングステージを 指定します そして その関数を参照する 関数ハンドルを作成します 関数ハンドルとテーブルは 特定のパイプラインと 選択されたステージに 固有のものです そして setFunction APIで ハンドルを挿入できます では この関数テーブルを どう使うか見てみましょう コマンドとコーディングの 一環として可視化された 関数テーブルを BufferIndexにバインドし シェーダ自体ではバッファ バインディングとして visible_function_tableが 渡され関数を呼び出せます 関数ポインタを使うという 単純なケースです 関数ポインタを使用する場合 後で追加関数にアクセスが 必要か確認でパイプラインを 作成することもあります 同じディスクリプタから 2つ目のパイプラインを 作成して関数を追加し 実現できたとしても パイプラインのコンパイルが 必要になります この処理を促進するために Metalで元のパイプラインを 拡張する予定か 指定することができます これで既存のパイプライン から新しいパイプラインを より速く作成でき 最初に作成されたすべての 関数ポインタテーブルを 使用することができます コードから行うには元の パイプライン作成の際に supportAddingBinary Functionsオプションを 拡張したいステージに対し YESに設定します その後 拡張パイプラインを 作成する必要があるときは RenderPipelineFunction Descriptorを作成し フラグメント長関数リストに バイナリ関数batを含めます 最後にRenderPipeline1で 追加のバイナリ関数を持つ 新しいRenderPipelineState を呼び出し 同一となるが 追加の関数ポインタbatを 含むRenderPipeline2を作成 大体こんなところです ここからは関数ポインタの 使い方を紹介します Apple GPUファミリー6以上 macOS Big Sur iOS 14で サポートされています Macファミリーの2つの デバイスもサポートします Apple GPUファミリー6以上 Mac OS Monterey iOS 15のレンダーとタイル パイプラインの 関数ポインタのサポートも 拡張します
次にバイナリ関数の コンパイル時の オーバーヘッドの管理 について紹介します シェーダのコンパイルは 時間がかかるため アプリへのオーバーヘッドを 制御したい場合があります そこでバイナリアーカイブを 昨年Metalに追加しました バイナリアーカイブはパイプ ラインのコンパイルされた バイナリバージョンを ディスクに集め保存 コンパイル時間と実行を節約 メモリコストを削減できます 可視化して保存する機能や インターセクション機能を 追加しオーバーヘッドを 削減できるようにしています バイナリアーカイブへの格納 と読み込み方法を見てみます addFunctionWithDescriptor を呼び 引数に関数ディスクリプタと ソースライブラリを渡します バイナリ関数ポインタを読み 込むにはbinaryArchivesの 配列にBinaryArchiveを配置 Metalライブラリメソッド newFunctionWithDescriptor を呼び出します アーカイブがコンパイルした 関数ポインタを持っていれば 再コンパイルすることなく すぐにそれが返されます newFunctionWithDescriptor がbinaryArchivesに対して どのように動作するかを示す ルールを紹介します まずリストから その関数の バイナリバージョンを探し 見つかれば返され 見つからなければ CompileToBinary オプションをチェックし バイナリコンパイルの要求が ない場合 AIR関数を返します 要求された場合 パイプ ラインオプションに応じ FailOnBinaryArchiveMissは 関数のバイナリを 実行時にコンパイルするか nilを返します MTLBinaryArchiveをアプリに 組み込むとGPUで コンパイルされたコードを 同アーカイブに格納できます レンダリング タイル パイプ ライン 関数ポインタなど アーカイブにパイプライン ステートオブジェクトと バイナリ関数を登録後 シリアル化できます GPUバイナリを収集 保存して 次のアプリ実行時に シェーダのコンパイルを 高速化できます 関数ポインタを使うパイプ ラインの使用では状態を表す オブジェクトをキャッシュ したい場合があります ですが様々な関数ポインタの 組み合わせが可能な パイプラインがあるのに なぜキャッシュを? 例えばここでは ユーザ関数ポインタを除き 同一の3つのパイプライン ディスクリプタがあります そのためAIRの関数ポインタ を使用している場合は パイプラインのすべての 順列をキャッシュしますが バイナリ関数ポインタを使用 する場合 関数ポインタが 追加されてもパイプラインの バイナリコードは変更なく 単一のバリアントを キャッシュするだけです そのアーカイブを使って パイプラインディスクリプタに どのバイナリ関数ポインタが 使われているかに関係なく 他のすべてのバリエーション を見つけることができます MetalではbinaryArchives の使用をお勧めします パイプラインのコンパイル コストを抑えられます binaryArchivesのサポートは 全てのデバイスで可能ですが BinaryArchiveに関数 ポインタを追加するには 関数ポインタの 能力に依存します さて 今年の次の 追加機能である プライベートリンク機能に ついて簡単に説明します ダイナミックライブラリと 関数ポインタが シェーダ開発パイプラインに 柔軟性をもたらすことを 説明してきましたが パフォーマンス上の理由から 外部関数を静的に リンクする場合もあります 昨年 AIRの関数を静的に リンクする機能を持つ linkedFunctions APIを 追加しました しかし これには関数 ポインタのサポートが必要で これらは関数テーブルで 使用できるからです 今年はprivateFunctionsを 導入します functionsも privateFunctionsも AIRレベルで静的に リンクされていますが privateなので 関数ポインタ に対し関数処理できず コンパイラはシェーダ コードを最適化できます では どこで入手 できるのでしょうか? この機能はAIRレベルの コードで動作するため macOS MontereyとiOS 15の 全デバイスで利用できます さて最後に 関数の スティッチングについて お話しましょう ダイナミックコンテンツが 必要なアプリもあります 例えばユーザーの要望で グラフィック効果を カスタマイズする ことなどです または入力データに基づき カーネルを複雑に計算など これを処理するには関数の スティッチングが有効です 関数のスティッチング以前は Metalのソース文字列を 生成するしか方法が ありませんでした また Metalから AIRへの変換は 実行時に行われ これはコストの かかる作業です では関数のスティッチングの 仕組みを見てみましょう 計算グラフや プリコンパイルされた関数から 実行時に関数を生成する 仕組みを提供します 計算グラフは 有向非巡回グラフです またグラフには 生成された関数の引数を表す 入力ノードと関数の 呼び出しを表す関数ノードの 2種類のノードがあります エッジも2種類あり あるノードから別のノードへ データの流れを表す データエッジと 関数呼び出しの実行順序を 表すコントロールエッジです ここでは関数ステッチが 計算グラフを使って 関数を生成する様子を 見てみましょう まずスティッチングできる 関数について説明します グラフの関数は スティッチング属性が必要で このような関数は 可視化された関数であり functionStitching APIで 使用することができ アプリのバンドルに同梱の Metalライブラリの 一部にしてAIRへの 変換コストを回避できます
スティッチング処理では Metalのフロントエンドを 完全に飛ばしてAIRで 直接機能を生成します 生成された関数は通常の スティッチングできる関数で パイプラインにリンクしたり 関数ポインタにしたり 他の関数生成に使用したり することができます そこで先ほどのグラフで ライブラリから 二重関数AとCが 出てきたとします これらをグラフにバインド するとどうなるか見てみます スティッチャーは 各関数ノードに対応する 関数タイプを関連付けます N0とN1は FunctionAから型を取得し N2はFunctionCから 型を取得します その後 スティッチングは 入力ノードを使う関数の パラメータの型を見て 入力ノードの型を推定します 例えば Input0は N0とN1の第1引数なので pointerで考案された型 であると推測されます
そしてスティッチングは Metalで説明した 以下のものと 同等の関数を生成します functionStitching APIを 使えばこのような関数を含む ライブラリをAIRから 直接生成することができます ステッチの仕組みが わかったところで APIでの使い方を紹介します まずスティッチング関数の 入力を定義します 全ての引数を考慮し 十分な入力ノードを作ります グラフ内で呼び出す関数ごと に関数ノードを作成します 明示的な順序付けが必要な場合 各関数の呼び出しに対し 名前 引数 および制御の 依存関係を定義します 最後に 関数名 グラフ内で 使用される関数ノード 適用したい関数属性を持つ グラフを作成します また OutputNodeを 割り当てます OutputNodeは スティッチング関数の 結果の出力値を返します グラフができました 次は関数です 最初にStitchedLibrary Descriptorを作成します stitchableFunctionsと functionGraphを追加します そしてディスクリプタを 使ってライブラリを作成し スティッチング関数を 作ることができ 他のスティッチングの グラフの関数としてなど スティッチング関数が必要な 場所どこでも使用できます スティッチング関数に ついては以上です このAPIはmacOS Montereyや iOS 15でも利用可能です 今日はお話したのは レンダーパイプラインの ダイナミックライブラリと 関数ポインタについてと プライベートリンク関数で 表示関数を静的にリンクでき 動的にシェーダを作成する際 スティッチング関数が どうコンパイル時間を短縮 できるのかについてでした
どのような場合にどちらを 選ぶのでしょうか? ヘルパーやユーティリティ 関数をリンクするのに ダイナミックライブラリは 優れた選択肢で セットが固定で頻繁な 変更がない場合に最適です 関数ポインタはシェーダが シグネチャ以外知らない関数を 呼び出す機能を 追加するものです 関数の数や名前はもちろん 開発者がAIRやバイナリで どんな速度と柔軟性の トレードオフを 行ったかまで 知る必要はありません 関数ポインタもキャッシュ できるようになりました プライベート関数は 関数を名前で静的に パイプラインステート オブジェクトにリンクします これらはパイプラインの 内部にあるため 可視化された関数テーブルに エンコードはできませんが コンパイラが最適化し すべてのGPUファミリーで サポートされています スティッチング関数では コードスニペットをAIRに 直接プリコンパイルし実行時 関数のコンパイルを行えます Metalシェーダストリングを 合成していて実行時に ソースからコンパイルする コストがかかっているなら スティッチング関数は ワークフローを高速化します これらのコンパイラ機能を 活用してMetalを使った 新しい体験を開発して いただきたいと思います ご視聴ありがとうございました WWDC 2021をお楽しみ下さい [音楽]
-
-
5:38 - Shading language
// Declare external functions extern float4 foo(FragmentInput input); extern float4 bar(FragmentInput input); // Use functions in shader fragment float4 main(FragmentInput input [[stage_in]]) { switch(condition(input)) { case 0: return foo(input); case 1: return bar(input); } } -
9:01 - Declare and instantiate visible functions
// Declare a descriptor and set CompileToBinary options MTLFunctionDescriptor* functionDescriptor = [MTLFunctionDescriptor new]; functionDescriptor.options = MTLFunctionOptionCompileToBinary; // Backend compile the function functionDescriptor.name = @"foo"; id<MTLFunction> foo = [library newFunctionWithDescriptor:functionDescriptor -
9:30 - Configure pipeline descriptor
// Provide a list of functions that the pipeline stage may call // AIR functions renderPipeDesc.fragmentLinkedFunctions.functions = @[foo, bar, baz]; // Binary functions renderPipeDesc.fragmentLinkedFunctions.binaryFunctions = @[foo, bar, baz]; -
10:47 - Create and populate visible function table
// Create visible function table [renderPipeline newVisibleFunctionTableWithDescriptor:stage:]; // Create function handles [renderPipeline functionHandleWithFunction:stage:]; // Insert handles into table [visibleFunctionTable setFunction:atIndex:]; -
11:21 - Encoding and calling function pointers
// Bind visible function table objects to each stage [renderCommandEncoder setFragmentVisibleFunctionTable:atBufferIndex:]; // Usage in shader fragment float4 shaderFunc(FragmentData vo[[stage_in]], visible_function_table<float4(float3)>materials[[buffer(0)]]) { //... return materials[materialSelector](coord); } -
12:20 - Incremental pipeline creation
// Enable incrementally adding binary functions per stage renderPipeDesc.supportAddingFragmentBinaryFunctions = YES; // Create render pipeline functions descriptor MTLRenderPipelineFunctionsDescriptor extraDesc; extraDesc.fragmentAdditionalBinaryFunctions = @[bat]; // Instantiate render pipeline state id<MTLRenderPipelineState> renderPipeline2 = [renderPipeline1 newRenderPipelineStateWithAdditionalBinaryFunctions:extraDesc -
20:30 - Stitching process
[[stitchable]] int FunctionA(device int*, int) {…} [[stitchable]] int FunctionC(int, int) {…} [[stitchable]] int ResultFunction(device int* Input0, int Input1, int Input2) { int N0 = FunctionA(Input0, Input1); int N1 = FunctionA(Input0, Input2); int N2 = FunctionC(N0, N1); return N2; } -
21:32 - Creating the graph
// Create input nodes inputs[0] = [[MTLFunctionStitchingInputNode alloc] initWithArgumentIndex:0]; // Create function nodes n0 = [[MTLFunctionStitchingFunctionNode alloc] initWithName:@"FunctionA" arguments:@[inputs[0], inputs[1]] controlDependencies:@[]]; n1 = [[MTLFunctionStitchingFunctionNode alloc] initWithName:@"FunctionA" arguments:@[inputs[0], inputs[2]] controlDependencies:@[]]; n2 = [[MTLFunctionStitchingFunctionNode alloc] initWithName:@"FunctionC" arguments:@[n0, n1] controlDependencies:@[]]; // Create graph graph = [[MTLFunctionStitchingGraph alloc] initWithFunctionName:@"ResultFunction" nodes:@[n0, n1] outputNode:n2 attributes:@[]]; -
22:18 - Configure stitched library descriptor
// Configure stitched library descriptor MTLStitchedLibraryDescriptor* descriptor = [MTLStitchedLibraryDescriptor new]; descriptor.functions = @[stitchableFunctions]; descriptor.functionGraphs = @[graph]; // Create stitched function id<MTLLibrary> lib = [device newLibraryWithDescriptor:descriptor error:&error]; id<MTLFunction> stitchedFunction = [lib newFunctionWithName:@"ResultFunction"];
-