-
Metalでのバインドレスレンダリングの詳細
Argument Buffersを追加してバインドレスレンダリングを採用することで、シェーダーの可能性を最大限に引き出し、最新のレンダリング技術を実装します。レイトレーシングとラスタライズのパイプラインを最大限に活用するために、シーン全体とリソースをGPUで利用できるようにする方法を確認しましょう。
リソース
- Rendering reflections in real time using ray tracing
- Applying realistic material and lighting effects to entities
- Accelerating ray tracing using Metal
- Managing groups of resources with argument buffers
- Metal Feature Set Tables
- Metal
- Metal Shading Language Specification
関連ビデオ
WWDC22
WWDC21
-
このビデオを検索
♪ (Metalでの バインドレスレンダリングの詳細) WWDCにようこそ! Ale Segovia Azapianです AppleのGPU ソフトウェアエンジニアです このセッションでは Metalのバインドレスレンダリング を探っていきたいと思います バインドレスは GPUが リソースグループを使うのを可能にし 現代のレンダリング技術を 導入できるようにする 最新の リソースバインディングモデルです 最初にバインドレス概念の背後にある ニーズについて見ていきましょう それから バインドレスモデルを紹介し 従来のバインディングモデルの課題 を解決するために必要な 柔軟性をどのように与えてくれるか 示します エンコードのメカニズムと 引数バッファを用いて シーンリソースをMetalで 利用できるようにするメカニズム およびシェーダからGPU構造を ナビゲートする方法をまとめました それでは始めます! バインドレスレンダリングは すべてのシーンリソースを シェーダが活用するのを 可能にするもので グラフィック技術に信じられないほど 柔軟性をもたらしてくれます 例をみてみましょう アクセラレーション構造に対する インターセクションを見つける レイトレーシングカーネルがあると 想像してください レイトレーシングシャドーなど 一部の照明エフェクトについては アルゴリズムが非常に自然です インターセクションと照明間の オブジェクトを 見つけたいと思います シャドーレイのトレースに 必要なのは ポジションと 光に向かう方向だけです インターセクションの ワールドスペース位置を超えると オブジェクト属性やメタルリソースは 必要ありません これは 光線と インターセクションのパラメータ から得ることができます しかし 映り込みなど ほかのエフェクトでは 状況はもっと複雑になります Metalシェーディング言語の レイトレーシンング 映り込みシェーダ を見てみましょう この新事例では インターセクションを 見つけたところで 現在の反射色を使って ピクセルをペイントしようと しました インターセクションを見つけてから ソリッドカラーをペイントするなら グラウンドの映り込みは 正確に見えません 正しい結果に導くなら 発見した各反射ポイントの属性を 判断し そのピクセルのシェーディングを 正しく計算する必要があります この問題は 拡散性の全体照明など レイトレーシングエフェクトや 一部の場合では アンビエントオクルージョンにも 存在します その課題とは レイトレース時に 光線がアクセラレーション構造の いずれのオブジェクトにもヒットする 可能性があることです つまり レイトレーシングシェーダから 交差するメッシュに関連づけられる 頂点データおよび その素材を含む シーン内の あらゆるMetalリソースにアクセス する必要があるかもしれません この大量のリソースを 直接パイプラインに バインドすることは不可能です ここでバインドレス バインディングモデルの出番です バインドレスの背後の考えは リソースを集合させ お互い結びつけることです これでシングルバッファを パイプラインにバインドでき ナビゲーションを通じて 全参照リソースを利用できる ようになります Metalでは それを可能にする 構成要素は 引数バッファです 特にバインドレスでは 引数バッファのティア2が 必要です Apple 6 およびMac2 GPU ファミリーで使用できます 引数バッファはMetalのすべての シェーダタイプから使用できます つまり レイトレーシングと ラスタライズ双方に使用できると いうことです 特定のレイトレーシング エフェクトでは 良質な視覚を得るために バインドレスの使用は 必須です ラスタライズでは バインドレスの使用は任意ですが 直接バインディングモデルに 対する利点があります 特にいずれのドローコールの バインドできる リソース数のスロット制限を 実質的に取り除きます また 後ほど説明しますが 最適化の機会も 与えてくれます Metal APIへのシングルコールで 一度に定数データと リソースをバインドすることを 可能にする メカニズムとして Metal 2で 引数バッファを導入しました 引数バッファは柔軟であり 他のバッファでさえも 参照できます このバインドレスモデルの 背後にある考えは シーンリソースをお互いすべて 結びつける機能を 活用するということです これにより それらをGPUが 一度に利用できるように なります それでは引数バッファに シーンリソースを結びつける 方法の事例を見ていきましょう この消防車のようなモデルを レンダリングしたいとします このモデルは テクスチャ 頂点データ インデックスデータ から構成されています これらは従来のバインディング モデルのドローコールに1つずつ バインドする典型的な リソースです しかし 私たちのケースでは すべてのテクスチャ 頂点データ インデックスを一度に 使用できるようにしたいので それらを集合させる 必要があります こちらは それをするために 考えられる方法です まず アセットの編成方法に応じて すべてのメッシュまたは サブメッシュを含む メッシュの引数バッファを 作成することができます この引数バッファは シーンの頂点やインデックス配列の 参照を可能にします 同様に同じことを行い 引数バッファに 素材をエンコードします 各素材はインライン定数データを 含むとともに テクスチャを参照する ことができます GPUがすべてのメッシュと 素材を使用できるようになりましたが どのようにしてそれらを 集合させられるでしょうか 例えばインスタンスオブジェクト を作成して 引数バッファに配置できます インスタンスが1つのメッシュと 関連づけられた素材を参照できます これは インライン定数データとして モデル変換行列を格納するのに 良好な場所でもあります しかし そこでやめる 必要はありません 1つのインスタンスを 格納できるようになったところで すべてのインスタンスを ひとつの配列として この引数バッファに エンコードできるよう にもなりました この図表を単純化して それぞれ独自の素材を持つ トラックインスタンスを いくつか追加してみましょう ご覧のように これで すべてのシーンとそのリソースを エンコードし 結びつける ことが可能になりました その後 シェーダから これらのリソースを 参照したいときは インタンスバッファに対する ポインタだけが必要です 直接それを渡し バッファを1つの配列として 解釈するか 他のシーン引数バッファで ポインタを渡すことができます ここでは間接的にアクセスされた リソースの常駐で 何が起こるのか注意することが 重要です 私たちはただパイプラインへの シーンに ポインタを渡すだけなので Metalはバッファリファレンス を認識するでしょうが 間接的にアクセスしたリソース は認識しないでしょう Appは 間接的にアクセスした すべてのリソースの常駐について 宣言する責任を持ちます リソースを常駐させることは つまり ドライバーに信号を送り GPUがメモリを使用できるように するためです これはシェーダから参照するために 必要です これは コンピュートエンコーダ向けの useResource:usage: APIと レンダリングコマンドエンコーダ向けの useResource:usage:stages: APIを 呼び出すことでできます 非常駐リソースに アクセスすることは GPU再起動とコマンドバッファ エラーのよくある要因です このAPI呼び出しを 忘れた場合 そのメモリページが存在しない 可能性があるためです Metalの間接的にアクセスした 各リソースを宣言することは 非常に重要です さて もう一つの便利な オプションとして MTLHeapsから割り当てられた リソースは useHeap APIの手段により 単一の呼び出しで常駐化 できるようになりました すでにヒープからサブ割り当てを 実行または 計画している場合は 優れたオプションです 今やヒープはMetal APIの すばらしい部分であり 最適なリソース作成の パフォーマンスと メモリ保存の機会に ヒープを使用することを 推奨します しかし ヒープを効率的に 利用するには いくつか検討すべき ことがあります 最初に問うべきは 割り当てたリソースすべてが 読み取られるかです リソースに書き込む必要がある かもしれない場所として 例えばコンピューターシェーダからの メッシュスキニングや ダイナミックテクスチャなどがあります こうしたケースではGPUが リソースを書き込む必要があるなら それらは 使用フラグを書いて個別に 常駐を宣言する必要があります さらに修正された可能性がある リソースを読み込みたい場合 それぞれにuseResourceの 呼び出しが必要です これは Metalフレームワークが リソース移行の処理や GPUキャッシュのフラッシュ そして内部メモリレイアウトの 調整をできるようにするものです 次に考慮すべきは ヒープがサブ割り当てのリソース 依存関係を追跡するかについて これは同じヒープから生じる リソースを読み込んだり 書き込んだりする場合に 特に重要です Metalは依存関係を追跡することで 同期の問題を回避するのに 優れています またMetal 2.3以降では ヒープはリソースへのアクセスの 問題を追跡するように 構成できます しかし ヒープはMetalに対する 単一リソースであるため 同期については サブ割り当てレベルではなく ヒープレベルで処理されます これにより サブ割り当てされたリソースが 誤って共有されるという リスクがあります 例を見てみましょう 同じヒープから リソースにアクセスする ふたつのレンダリングパス AとBがあると想像しましょう レンダリングパスAは 追跡されたヒープから 割り当てられたレンダリング テクスチャにレンダリングします レンダリングパスBは 同じヒープからサブ割り当てされた 無関係のバッファから 読み込んでいます 異なる条件に応じて レンダリングパスAとBは GPUによって 並行して実行される条件を 満たすかもしれません しかし 同じリソース - ヒープ からの書き込みと読み込みの 潜在的リスクのため Metalは競合状態がないことを 確認する目的で アクセスをシリアル化する 必要があります それは GPUによる作業負荷の 実行経過時間を 潜在的に増やします ただし 個々のリソースが 独立しているとわかっている場合は この障害は回避できます それを行うには ふたつの方法があります 1つ目のオプションは アップデートできるリソースを ヒープから静的リソースとは別に サブ割り当てすることです 2つ目のオプションは すべて1つにまとめたい場合 ヒープがサブ割り当てされた リソースを 追跡しないように 構成することです これはMetalの デフォルト動作であり 私たちプログラマーは同期の 危険性に対して責任を担うことを 意味しています この図では 誤った共有の 問題を説明するため 多少単純化しています 実際には 重複は レンダリングパスレベルではなく シェーディングステージレベルで 生じます 結果として Metalはステージレベルで 障害を特定することを 可能にします すばらしいことです なぜなら 頂点ステージ ラスタライザーなど パイプラインの一部を 同時に実行するのを 可能にしてくれるからです そして前のパスの フラグメントステージの アウトプットへの依存が 生じる場合のみ 後でブロックしてくれます パフォーマンスを最大化するため できる限り これを行うことをお勧めします 覚えるべきことが たくさんありますね このリストからあえて 焦点を当てるなら 静的テクスチャや メッシュなど 読み込み専用のデータの扱いが 最も簡単であるということを 覚えておいてください トータルの割り当てサイズおよび 事前のアライメント要件を決定し App起動または ゲームのローディング中 これらのリソースを ヒープに配置してください そうすれば 後ほどクリティカルパス にて最小のオーバーヘッドで それをシングルコールで 常駐させることができます バインドレスバインディングモデルが 理解できたところで リソースのエンコードを実践して 引数バッファで GPUが完全なシーンを 利用できるようにする方法を 見てみましょう 例えば インスタンスバッファを エンコードしたいとします このバッファはインスタンスの 配列から成ります ご覧のように インスタンンスは メッシュ 素材を参照し ローカルからワールド空間への 移行を説明する インライン定数4x4行列を 含んでいます エンコーディングは 引数バッファ エンコーダを通じて実行されます Metalではこのエンコーダ作成に ふたつの方法があります 映り込みによるエンコーディングは よく知られているかもしれません 引数バッファが ダイレクトパラメータとして シェーダ関数に渡される場合 MTLFunctionオブジェクトに エンコーダを作成するように 求めることができます このメカニズムは非常に良く 機能しますが 全体シーンを引数バッファに エンコードしていると すべてのエンコーダを反映できる わけではありません 特にMTLFunctionシグネチャは 間接的に参照されたバッファを 認識しません 他にもMTLFunctionから エンコーダを作成することが 不便な場合があります 例えばエンジンアーキテクチャが 引数バッファの作成とリソースの ローディングを パイプラインステートの作成から 切り離して扱う場合です また 配列が渡されることを 関数が予想している場合 エンコーダを反映できません こうしたケースでは どうすればいいでしょうか これらのケースでは MetalにはMTLArgumentDescriptor を通じて エンコーダを作成する 便利な2番目のメカニズムがあります MTLArgumentDescriptorsにより Metalに構造体メンバーを説明し その次にMTLFunctionなしで エンコーダを作成することを 可能にします まず各メンバーに記述子を作成し データタイプとバインディング インデックスを特定します 次に記述子を 直接MTLDeviceに渡し エンコーダを作成します 結果的にエンコーダ オブジェクトを再取得します コードでこれを探ってみましょう 各メンバーについて MTLArgumentDescriptor を作成する必要があります バインディングインデックスを 特定し 構造体のメンバーの ID属性と一致させます MTLDataTypeと 場合によってアクセスを特定し 最後にすべてのメンバーを 宣言した後 デバイスから直接 エンコーダを作成でき すべての記述子を用いて 配列を渡します エンコーダが一旦できれば データをバッファに記録するのは 容易になります 引数バッファをエンコーダに 設定して バッファの始まりを指します それから格納したいデータを 設定します 配列のエンコードも簡単です エンコーダから簡単に 取得できるEncodedLengthで エンコーダの引数バッファの レコーディングポイントを オフセットするだけです 次のインスタンスでは encodedLengthを 二度目となるオフセットに 加えます 実際 記録しなければならない 各ポジションのオフセットは インデックス x encodedLengthとなります このメカニズムは 構造体の配列のエンコードを 簡単にしてくれます ひとつ重要な点をお伝えします 配列にインデックスを加えるのに シェーダ側から特別な処置を することはないということです シェーダはバッファの長さを 知る必要はなく 配列のいずれかの場所に インデックスを自由に 加えることができます これがうまく機能します バインドレスシーンを エンコードできたところで ナビゲーションを見てみましょう レイトレーシングの場合 ナビゲーションは非常に自然です まず レイトレーシング パイプラインに対する バインドレスシーンのルートを含む バッファをバインディングします ここから 他のすべてに アクセスできる 引数バッファの場所です 次にカーネルから いつも通り レイトレーシング インターセクションを進めます インターセクションを発見した後 その結果オブジェクトは ナビゲーションを説明します このオブジェクトを instance_idとgeometry_id およびprimitive_idに対し クエリできます これらのメンバーは特に アクセラレーション構造を ナビゲートする目的で 設計されました そのため 先に示したように アクセラレーション構造を 反映した構造で バインドレスシーンを 構築することが重要です それをもう一度見てみましょう 覚えておいてください これはシーンの編成方法の 一例ですので 私の編成方法に応じて ナビゲートしていきます シーンの詳細は あなたの引数バッファの 編成方法に応じて 異なる可能性があります まずインターセクションを 見つける必要があります 一度それを取得すると バインドレスシーンを戦略的に 編成したので instance_idを考慮して インスタンスバッファへの ポインタをたどり どちらにヒットするかを判断します 次に ご覧のとおりインスタンスは メッシュと素材を認識しています 私たちは単純に geometry_idを使用して 参照バッファ内で どちらのジオメトリにヒット するかを判断できます 最後にインデックスバッファを 認識するため 各メッシュを準備した場合は primitive_idを使用して ヒットする正確な プリミティブを判断できます 例えば三角形の場合は 配列から3つのインデックスを 引いて その頂点データを検索するのに それらを使用できます こちらは Metalの シェーディング言語での ナビゲーションの様子です インターセクションオブジェクトから instance_idを取得して インスタンス配列への動的な インデックスに使用でき ヒットするインスタンスを 取得できます 次に インスタンスがあるので geometry_idを使用して どのジオメトリまたはサブメッシュが ヒットしたかを判断します ジオメトリを決定したら インデックスバッファから インデックスを直接引き出せます 三角形の場合は 次々と 3つのインデックスを 引き出すことができます これらのインデックスで 頂点データ配列にアクセスし 必要な属性を取得します 例えば 各頂点に一致する 法線を取得できます 最後にポイントの重心座標 を使用して インターセクションの正しい法線に 到達するため 頂点法線を手動で補間します インプレースのこうした変更を ティーポットの事例に戻すと インターセクションポイントで 法線を計算する方法が確立し 映り込みを正しくシェーディング できるようになります インターセクションポイントで 正しい属性を見つけるために コードをアップデートしました そしてその結果は 視覚的に正確です このフレームワークの構築を続行し テクスチャの適用に使う テクスチャ座標や 通常のマッピングの実行に応用する 接ベクトルなど 取得したいその他の属性も 計算できるようになりました バインドレスシーンを ナビゲートして 頂点データを取得する方法 手動でそれを補間する方法 そして最後には発見した インターセクションポイントを 正確にシェードするための 適用方法を見てきました こうしたコンセプトをあなたの エンジンに導入してもらうため これらすべての具体的導入を示す コードサンプルを公開する予定です こちらはハイブリッド レンダリングサンプルで Model I/Oフレームワークを使って ロードされたシーンの レイトレーシングの映り込み を計算するものです このサンプルはレイトレーシングの アクセラレーション構造と マッチするバインドレスシーンを エンコードする方法のほか インターセクションを見つける方法と レイトレーシングシェーダから 直接関連ピクセルを 正しくシェーディングする方法を 紹介するものです こちらでわかるように サンプルは光線がトラックと交わる ポイントで 映り込みレイトレーシングシェーダの アウトプットを直接 視覚化することを可能にします これは映り込みアルゴリズムを 反復検証するうえで最適です 本日は盛り沢山の内容を確認しました 特にレイトレーシングに ついて話してきましたが 先ほど述べたように ラスタライズについても 同じ原理を応用してピクセルを 正しくシェーディングできます 物理ベースのレンダリングは この最適な候補です PBRでは フラグメントシェーダは いくつかのテクスチャから生じる 情報が必要です 例えばアルベド 表面の粗さ メタリック アンビエントオクルージョンなどです 直接的なバインディングモデルでは 各ドローコールを出す前に 個別に各スロットをバインディング する必要があります バインドレスモデルは これを大幅に単純化します 引数バッファをエンコードすると 直接シーンをバインド できるようになり ドローコールに一致する素材まで ナビゲートし すべてのテクスチャに間接的に アクセスできるようになります 実際 単一バッファを一度だけ バインドすれば済むようになったので このアーキテクチャは ドローコール数を減らすことで エンジンを最適化し インスタンスレンダリングを 代わりに使用する 最適な機会を与えてくれます アクセスを計画しているすべての テクスチャを常駐させてください こちらは典型的なPBRシェーダの 事例です 従来のモデルにおいて 参照テクスチャはそれぞれ ドローコール前に個々に バインディングする必要があります 次のドローコールが 異なるテクスチャのセットを 要求する場合 それらの全リソースについても同様に それぞれバインディングが必要です バインドレスモデルを 使用する場合 前述のように ルート引数バッファを渡し 参照ストラクチャから 直接 素材を取得することができます まず インスタンスを取得します これは頂点シェーディングステージで 判断されることがあります それからその素材を取得し その参照テクスチャと 定数データを使って 正確なシェーディングを 計算します 最後にカラーを返します いいですね! 以上が Metalでバインドレス レンダリングを効果的に 実施する方法の案内でした 振り返ってみましょう Metalのバインドレスモデルについて その優れた柔軟性と いかに自在にシーンを表現できるか を学びました アドバイスとしてレンダラーの ナビゲーションを容易にする 構造をデザインし構築することを お勧めします そうすれば ナビゲーションは 非常に自然なものになり レイトレーシングと ラスタライズの双方に 同一のバッファを 使うこともできます バインドレスは非常に 革新的なものであり 現代のレンダリング技術を 駆使するのに必要な すべてのデータをGPUに提供できます さらに応用して このアーキテクチャを使って GPUを中心に据え 間接的なコマンドバッファと GPUカリングを通じて 間接的なパイプラインを 採用することもできます 皆さんがこれをどのように実践し 次世代のグラフィックAppとゲームを 実現されるのか 今からとても楽しみです 引き続きWWDC2021を お楽しみください ♪
-
-
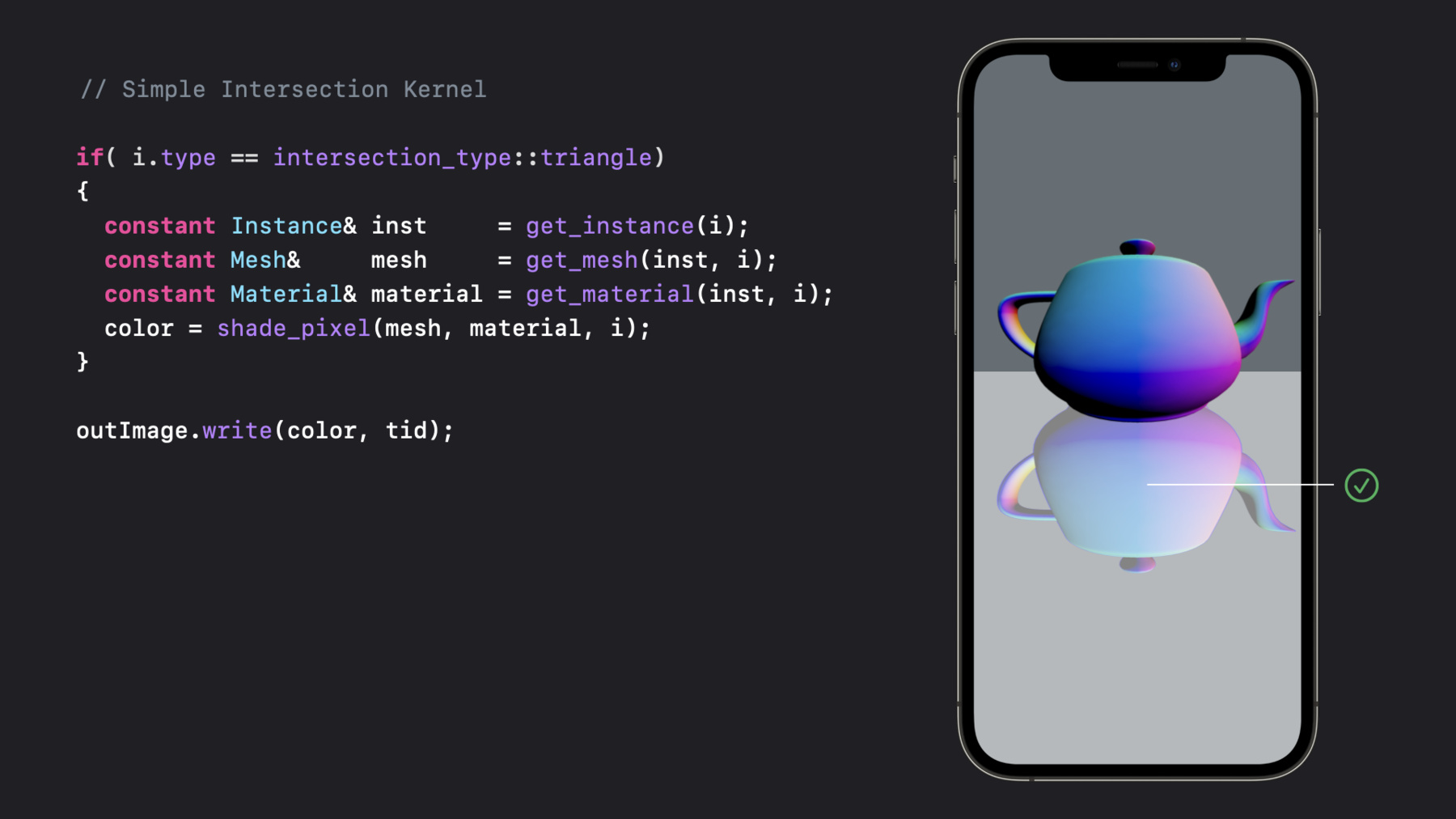
0:07 - Simple Intersection Kernel 2
if(i.type == intersection_type::triangle) { constant Instance& inst = get_instance(i); constant Mesh& mesh = get_mesh(inst, i); constant Material& material = get_material(inst, i); color = shade_pixel(mesh, material, i); } outImage.write(color, tid); -
0:08 - PBR fragment shading requires several textures
fragment half4 pbrFragment(ColorInOut in [[stage_in]], texture2d< float > albedo [[texture(0)]], texture2d< float > roughness [[texture(1)]], texture2d< float > metallic [[texture(2)]], texture2d< float > occlusion [[texture(3)]]) { half4 color = calculateShading(in, albedo, roughness, metallic, occlusion); return color; } -
0:09 - Bindless makes all textures available via AB navigation
fragment half4 pbrFragmentBindless(ColorInOut in [[stage_in]], device const Scene* pScene [[buffer(0)]]) { device const Instance& instance = pScene->instances[in.instance_id]; device const Material& material = pScene->materials[instance.material_id]; half4 color = calculateShading(in, material); return color; } -
1:48 - Simple Intersection Kernel 1
if (intersection.type == intersection_type::triangle) { // solid blue triangle color = float4(0.0f, 0.0f, 1.0f, 1.0f); } outImage.write(color, tid); -
11:33 - Encoder creation
struct Instance { constant Mesh* pMesh [[id(0)]]; constant Material* pMaterial [[id(1)]]; constant float4x4 modelTransform [[id(2)]]; }; -
11:50 - Encoder via reflection
// Shader code references scene kernel void RTReflections( constant Scene* pScene [[buffer(0)]] ); -
13:08 - Argument Buffers referenced indirectly
MTLArgumentDescriptor* meshArg = [MTLArgumentDescriptor argumentDescriptor]; meshArg.index = 0; meshArg.dataType = MTLDataTypePointer; meshArg.access = MTLArgumentAccessReadOnly; // Declare all other arguments (material and transform) id<MTLArgumentEncoder> instanceEncoder = [device newArgumentEncoderWithArguments:@[meshArg, materialArg, transformArg]]; -
16:10 - Navigation 1
// Instance and Mesh constant Instance& instance = pScene->instances[intersection.instance_id]; constant Mesh& mesh = instance.mesh[intersection.geometry_id]; // Primitive indices ushort3 indices; // assuming 16-bit indices, use uint3 for 32-bit indices.x = mesh.indices[ intersection.primitive_id * 3 + 0 ]; indices.y = mesh.indices[ intersection.primitive_id * 3 + 1 ]; indices.z = mesh.indices[ intersection.primitive_id * 3 + 2 ]; -
16:43 - Navigation 2
// Vertex data packed_float3 n0 = mesh.normals[ indices.x ]; packed_float3 n1 = mesh.normals[ indices.y ]; packed_float3 n2 = mesh.normals[ indices.z ]; // Interpolate attributes float3 barycentrics = calculateBarycentrics(intersection); float3 normal = weightedSum(n0, n1, n2, barycentrics); -
17:15 - Simple Intersection Kernel
if(i.type == intersection_type::triangle) { constant Instance& inst = get_instance(i); constant Mesh& mesh = get_mesh(inst, i); constant Material& material = get_material(inst, i); color = shade_pixel(mesh, material, i); } outImage.write(color, tid); -
19:30 - PBR fragment shading requires several textures
fragment half4 pbrFragment(ColorInOut in [[stage_in]], texture2d< float > albedo [[texture(0)]], texture2d< float > roughness [[texture(1)]], texture2d< float > metallic [[texture(2)]], texture2d< float > occlusion [[texture(3)]]) { half4 color = calculateShading(in, albedo, roughness, metallic, occlusion); return color; } -
19:48 - Bindless makes all textures available via AB navigation
fragment half4 pbrFragmentBindless(ColorInOut in [[stage_in]], device const Scene* pScene [[buffer(0)]]) { device const Instance& instance = pScene->instances[in.instance_id]; device const Material& material = pScene->materials[instance.material_id]; half4 color = calculateShading(in, material); return color; }
-