-
Create ML Componentsについて学ぶ
Create MLにより、画像識別、オブジェクト検出、音声識別、ハンドポーズ識別、アクション識別、形式データの回帰などのカスタム機械学習モデルが簡単に構築できるようになります。また、Create ML Componentsフレームワークを使用すると、基礎となるタスクをさらにカスタマイズして、モデルを改良できるようになります。これらのタスクを構成する特徴抽出器、トランスフォーマー、エスティメーターについて解説し、これらを他のコンポーネントや前処理行程と組み合わせて、画像回帰などのコンセプトのカスタムタスクを構築する方法を紹介します。 複雑なカスタマイズ可能なタスクの作成に関する詳細については、WWDC22の「Create ML Componentsで高度なモデルを作成する」をご覧ください。
リソース
関連ビデオ
WWDC23
WWDC22
WWDC21
Tech Talks
WWDC20
WWDC19
-
このビデオを検索
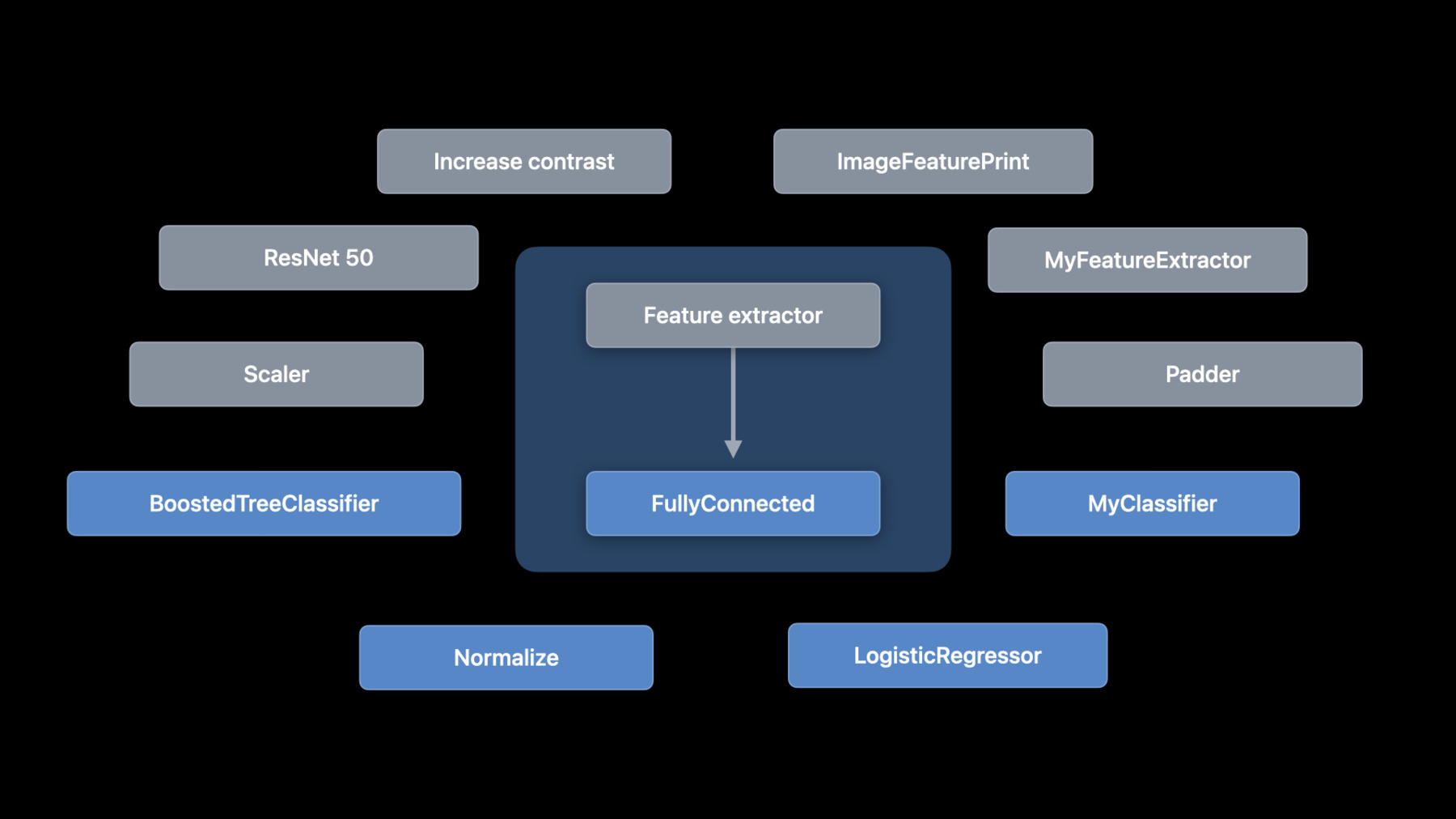
♪音楽♪ ♪ こんにちはAlejandroです CreateML teamのエンジニアです 今日はコンポーネントを使って 機械学習モデルを構築する 新しいAPIを紹介します Create MLはマシン学習モデルを トレーニングのためのAPIを提供します これは画像分類音声分類などの サポートされた一連のタスクに基づきます WWDC 2021では CreateMLフレームワーク関連の講演を 2回行いました 必ずご確認ください 定義されたタスク以上の事について話します Create MLの機能を上回る問題に 対応するタスクをカスタマイズする場合や 別のタイプのタスクを ビルドする場合どうでしょうか コンポーネントを使って新しい創造的な方法で タスク作成ができるようになりました それでは見てみましょう まずMLタスクを分割し 各コンポーネントの機能を説明します そしてコンポーネントの接続方法を説明します カスタムイメージタスクの例を紹介し 表形式のタスクについて説明します そして最後は展開戦略です まず機械学習タスクの内部を調べ そのタスクに何がありどう機能するかを 理解しましょう カスタムタスクの作成をはじめると 意味が分かると思います 例として画像分類器を挙げます 画像分類器はラベル付けされた 画像のリストでモデルをトレーニングします ここにラべル付の 犬と猫があります 各ステップで画像の変換方法見ます そのために画像分類タスクを展開して 中身を確認します 概念的には画像分類器はとてもシンプルです これは 特徴抽出器と分類器でできています ただし重要な部分はMLコンポーネントの作成で コンポーネントに個別に アクセスできることです コンポーネントを追加 削除 切替えてタスクを作成します コンポーネントをボックスとして表します 矢印はデータのフローを表しています 画像分類器の初めのステップである 特徴抽出を見てみましょう 通常 特徴抽出器は 特徴のある部分だけを保持して 入力の次元を減らします 画像の場合 特徴抽出器は画像内のパターンを探します Create MLはVision Frameworkの 画像特徴抽出機能である Vision Feature Printを使います 次に行きましょう 分類器についてです 分類器は一連のサンプルから 分類を学習します 一般的な実装にはロジスティック回帰 ブーストツリーニューラルネットワークがあり 画像分類器のトレーニングは 注釈付きの画像から始まり アノテーションされた特徴を経由して 分類器にたどり着きます なぜこうするのでしょう 理由は 可能性を広げるためです コントラストを上げて 前処理をしたいときもあります または すべての画像を 正規化したいこともあります そのため 特徴を抽出する前に 均一な明るさにします あるいは 別の機能抽出機能を試したり 別の分類器を試したいこともあります 可能性は無限大です これらは選択肢のほんの一部です なのでMLコンポーネントのサポートを macOS iOS iPadOS tvOSで追加しました 当社の希望はコンポーネントの複数を 独自のコンポーネントと一緒に使ったり コミュニティの他の人が構築した コンポーネントを使った新規モデルの作成です そして皆さんは様々なプラットフォームで 活用できます 下記はCreateMLコンポーネントに 組み込まれた物の一部ですが ちょっと戻ってみましょう 2つのコンポーネントの種類があります トランスフォーマーとエスティメーターです トランスフォーマーは単に何かの変換を 実行できるタイプです 入力タイプと出力タイプを定義します 例えば画像特徴抽出器は入力画像を取得し 特徴のある配列を生成します 一方エスティメーターはデータから学習します 入力例を取って数点処理を行い トランスを生成します このプロセスを「フィッティング」と呼びます ではCreate MLコンポーネントを使って コンポジションを使って各コンポーネントから 画像分類器を構築する方法について 説明します これはコンポーネントを使った画像分類器です 特徴抽出器としてImageFeaturePrintがあり 分類器として LogisticRegressionClassifierがあります コンポーネントがトランスフォーマーか エスティメータであるかに関係なく 追加方法を使って結合します そしてコンポーネントには無限の可能性があり 単純な変更でロジスティック回帰ではなく 全結合ニューラルネットワークを 分類器として使うことができます 例えばモデルギャラリーにある ヘッドレスResNet-50モデルです 2つのコンポーネントを構成する場合は 最初のコンポーネントの出力は 2番目のコンポーネントの入力と同じです 画像分類器の場合特徴抽出器の出力は CoreMLフレームワークからの 整形された配列です これはロジスティック回帰分類器の入力です 追加メソッドを使う際にコンパイラエラーが 発生したらはじめに確認します タイプマッチを確認しましょう フィッティングの重要なポイントも見ます そのフィッティングはエスティメーターから トランスフォーマーに移行すると話しました 構成されたエスティメーターの観点から これを見てみましょう 画像分類器のようにエスティメーターに トランスフォーマーとエスティメーターが ある場合はエスティメーターの ピースのみが取り付けられます しかし トランスフォーマーは エスティメーターの 適合方法に正しい機能を 供給するために使われるので プロセスの重要な部分です これがコードです 画像分類器の特徴は画像であり 注釈が文字列である注釈付きフィーチャーの コレクションが必要です デモに入るときに 機能のロードについて説明します データ取得後にfittedメソッドを呼出します トレーニング済みモデルの トランスが返されます フィッティング時のタイプは関連していますが 結果のトランスタイプとは異なるので ご注意ください 特に fittedメソッドの タイプは常にコレクションです また 監視対象の見積もり担当者の場合 機能に注釈が含まれる必要があります MLコンポーネントの作成には上記を使って 機能と注釈を表します モデルを入手したら予測を行うことができます フィットしたばかりのモデルであるか ディスクからパラメーターを ロードするかは関係ないです APIはどちらの場合も同じです 分類器をトレーニングしているため 結果は分類分布になります 分布には各ラベルの確率が含まれます この場合 画像の最も可能性の高いラベルを 印刷しているだけです 適合方法は検証指標を含む トレーニングイベントを 監視するメカニズムも提供します この例では検証データを渡し 検証精度を出力しています 監視対象の推定値のみが検証メトリックを 提供することにご注意ください モデルをトレーニングしたら 学習済パラメーターを保存し 後で再利用したり Appにデプロイしたりすることが可能です これは writeメソッドを使って行います そしてreadメソッドで 読み取ることができます そしてそれが構成です これがこのソリューションの面白いところです Create MLが今までサポート未対応だった 新しいタスクの作成について話します
画像スコアリングの モデルトレーニングについてです 果物の写真を 分類する代わりに 評価したいとします 熟度に基づいてスコアを付けます これを行うには分類ではなく 回帰を行う必要があります では バナナの熟度ごとに画像をスコア付けする 画像リグレッサを作成しましょう 各画像に1から10の間の熟度の値を与えます イメージリグレッサは 画像分類器と類似しています 唯一の違いは 推定値が分類器ではなく リグレッサーになることです ご想像のとおり これは簡単なことです 記憶のリフレッシュのために ここに画像分類器があります そして これはイメージリグレッサです ロジスティック回帰分類器を 線形回帰器に置き換えました このシンプルな変更によって フィットされたメソッドへの 入力も変更されます 以前は 画像とラベルが必要でした 今は 画像とスコアが必要です コンセプトについては十分です 実際のコードでこれをデモしてみましょう
カスタムイメージリグレッサ の作成方法を紹介します コードカプセル化のため画像リグレッサ構造を 定義してみましょう
さまざまな熟度のバナナの画像が 入ったフォルダがあります そのURLを定義することから始めます
次はトレーニングメソッドの追加です ここで トレーニングデータを 使ってモデルの作成を行います 構成されたエスティメータで ステップを追加変更する際 リターンタイプが変更されないよう リターンタイプを「some」にします それではエスティメーターを定義します これは 線形回帰が追加された シンプルな特徴抽出器です そして今 このスコアでトレーニング画像を ロードする必要があります URLと文字列ラベルを含む注釈付き機能の 注釈付きファイルを使えます ニーズに合った便利な初期化子を提供します ファイルは 名前 ダッシュ 熟度の値で構成されています そのため区切り文字がダッシュで 注釈がファイル名コンポーネントの インデックス:1にあることを指定します またtype引数を使って画像 ファイルのみをリクエストします URLができたので画像をロードしましょう mapFeaturesメソッドと ImageReaderが使えます また スコアを文字列から浮動小数点値に 変換する必要があります これにはmapAnnotationsメソッドが使えます
これでトレーニングデータができました しかし いくつかは検証の ためにとっておきましょう ここではラrandomSplitメソッドを使います トレーニング用に80%を使い 残りを検証に使用します 準備ができました
トレーニング用のパラメータを保存し Appをデプロイします 保存先を選びます
そしてwriteメソッドを呼び出します
最後にトランスフォーマーを返します
この定義方法とトレーニングモデルは コンポーネントを使います エスティメーターを定義し トレーニングデータを ロードして近似メソッドを呼び出し 書き込んでパラメータを保存します しかし まだ改善できる点があります 手始めに 検証データセットを行いますが 検証エラーを観察しないため やってみましょう fitedメソッドはメトリックの 収集に使えるイベントハンドラーを取ります
今はトレーニングと検証の両方の 最大エラー値を出力します 最終モデルの平均絶対誤差も必要です
検証機能に近似を適用し 実際のスコアと共に meanAbsoluteError関数で 計算します 実行してみましたがエラーが多く 良いモデルになりませんでした これは バナナの画像が少なかったからです 実行前にもっと画像を集めるべきでした データセットを拡張してみましょう 画像を回転・拡大縮小して より多くの例を得られます このために注釈つきの画像を用意して それを拡張するための新しい メソッドを作ります 注釈付き画像の配列を返します
まずは回転してみます
-piとpiの間の角度をランダムに選び 画像を回転させます またランダムにスケールして
3つの画像を返します 元の画像 回転 スケールの3つです
拡張機能を使ってflatMapを使用し トレーニング画像を拡張します
データセットの各要素は配列に変換されます FlatMapは配列を平坦化します これは近似メソッドに必要です 拡張は予測を行う時ではなく フィッティング時にのみ 適用されることにご注意ください これで正確性が向上します ここでモデル改善のさらなるポイントについて お話しします Visionフレームワークで画像の 目立つ部分にトリミングします 画像はトレーニングデータの一部です 他の果物が映っている所で 誰かがバナナを持っています この場合 他のものが画像に 映るのでモデルが混乱します Vision framework APIは 最も顕著なオブジェクトに 自動でクロップします 詳細はWWDC2019をご確認ください フィッティング時も予測取得時も カスタムトランスフォーマーを書くだけで 簡単に適用できます 実際にやってみましょう 適用されたメソッドの実装だけで トランスフォーマープロトコルに 準拠できます 画像を受け取って 返してみます 顕著なオブジェクトを取得しない場合 元の画像を返すだけであるということを除き このコードについては説明を省略します カスタムトランスフォーマーができたので 画像リグレッサに追加します
特徴を抽出する前にカスタム トランスフォーマーを 使います
顕著性はタスク定義の一部になっているため あらゆるトレーニング画像を トリミングするのに使われ 推論する時にも使われます これは トレーニングと推論の間でタスク定義を 共有することの利点のひとつです 次のタスクの前にいくつか 重要なポイントを強調します コンポーネントを使って カスタムタスクが作れます 私は追加メソッドで作成しました 注釈付きファイルを使って 注釈付きファイル名で ファイルをロードしましたが ディレクトリで注釈付きの ファイルをロードすることも可能です 画像リーダーを使ってURLを 画像にマッピングしました randomSplitで検証データセットを確保して 後で使うためにトレーニング済の パラメータを保存します 拡張機能を追加してモデル改善のための カスタムトランスフォーマーを定義しました しかしこれは単なる画像以上のものです ここでタビュラータスクについて 説明しましょう これは表形式のデータを使用するタスクです 表形式のデータには様々なタイプの機能が あることが特徴です 数値データとカテゴリデータの 両方を含めることができます 一般的な例としては住宅価格の データが当てはまります エリアや築年数だけでなく ご近所や 建物の種類などもあります 例えば 売却価格など 価値の予測を学びたいとします 2021年リリースの TabularDataフレームワークを Create MLコンポーネントと一緒に使って 表形式の分類器とリグレッサーを構築します TabularDataのセッションもお勧めです タスク構築の時に必要なデータ拡張についても 学ぶことができます それでは見てみましょう 表形式のデータを処理する場合 表の各列には違うタイプの機能があり また 情報の種類に基づき 各列をそれぞれの方法で 分布 値の範囲等にあわせ 処理することも可能です Create MLコンポーネントの作成では ColumnSelectorを使います 次の方法で処理することができます 住宅価格はご覧の通りなので アボカドの価格を例に出しましょう ここに価格表があります ここで価格予測のための表形式リグレッサーを 作成してみましょう 単位数 年度 数量などの数値データと タイプや地域などの カテゴリ列があります 一部のリグレッサーはこれらの値を より適切に表現することで意味があります 例えば これはデータセット内の数量分布です 通常の分布に近いですが15000を中心に 大きな値があります これは正規化の恩恵を受ける可能性のある データセットの良い例だと思います そのため最初行うのは値の正規化です 正規化する列名を ColumnSelectorに入れて 標準スケーラーを使います これがコードです まず 列セクターを作ります 次に スケーリングする列名を入れます すべての列に同じタイプの 要素がある必要があります この場合 Doubleです 次に オプションをアンラップします 欠落値がないことがわかっているので 実行できます 次にStandardScalerを アンラッパーに追加します そこで 袋の数が数万 数量が数十万の この表から始めました そして 列をスケーリングした後で 1に近い値になり モデルパフォーマンスを向上させます 具体的には値の平均が ゼロになりました これは同様の例ですがこの例では タイプ文字列のタイプ列と地域列を選択し ワンホットエンコーディングを実行します ワンホットエンコーディング とはアレイを使って カテゴリデータをエンコードし 各カテゴリの存在を示します ここにはブロンズ シルバー ゴールドの 3つのカテゴリがあります それぞれがアレイ内で一意の位置を取得し その位置に1つ示されます 別の方法は 各カテゴリに連続した番号を与える 通常のエンコーダを使うことです カテゴリが少ない場合は ワンホットエンコーダを使い それ以外の場合は通常のエンコーダを使います すべてをまとめて表形式の リグレッサーを作ります
前と同じように 構造の作成とデータURLと パラメーターURLの定義をはじめます
また 予測したい列(価格)の 列IDを定義します
トレーニングメソッドと 予測メソッドの両方で使えるように タスクを個別に定義します
前に話したように音量を正規化します
次にboosted tree regressorを使って 価格を予測します これは 結果の予測の列でもある 注釈列の名前を取り3つの特徴列 すべての名前を取ります これらの3つの列から始めます 次に 注釈メソッドで ピースを結合してタスクを返します
タスク定義ができたので前と同じように トレーニングメソッドを追加します
そして前と同じように リターンタイプがモデルの 詳細に依存しないことを確認します まずCSVファイルをデータ フレームにロードします この作業に表形式データ フレームワークを使います 以前と同じように検証用にデータを 分割します
トレーニングと検証のデータセットを 適合メソッドに適用します
以前と同様に検証エラーも報告し トレーニング済のパラメーターを保存します
最後にトランスフォーマーを返します
用意されたトランスフォーマーを入手したら データフレームの価格予測を行えます そのために予測メソッドを作成します
まず タスク定義とパラメーターURLから モデルをロードします
データフレームにタイプ 地域 数量などの 機能として使用した列が あることを確認しましょう 予測値は価格の列に表示されます 上部で定義した列IDを使用します
表形式のリグレッサーは終わりです トレーニングされたパラメータを生成するため 一度だけ呼び出す必要があるメソッドと アボカドの価格 タイプ地域 数量に 基づく予測を返す 予測メソッドがあります Appで使うために必要なのはこれだけです 表形式のタスクで作業する際に 注意すべき点がいくつかあります ColumnSelector操作を使って 特定の列を処理できます ツリー分類器とリグレッサは すべて表形式であることにご注意ください 表形式のタスクは注釈つき機能 プロバイダーで線形回帰等の 非表形式を使うこともできます 詳しくはドキュメントをご確認ください 予測を行うときは必要な列を使って データフレームを作成し 正しいタイプを使っている ことをご確認ください カスタムタスクの作成方法を理解したので デプロイについて説明しましょう 今までトレーニングと推論に 同じAPIを使いました Create MLコンポーネントを使う場合 モデルはコードであることを指摘しておきます トレーニングされたパラメータをファイルから ロードする場合でもタスク定義が必要です これは状況によっては便利になりますが デプロイにCoreMLを使いたいこともあります Core MLを使う場合はコードを残します モデルはモデルファイルによって表されます Core MLを使う準備ができているなら 優れたワークフローになる可能性があります また 最適化されたテンソル操作の 利点があります 覚えておくと良いです CoreMLですべての操作が サポートされているとは限りません ここにはカスタムトランスフォーマーと エスティメータなどが含まれます また Core MLは 画像や成形アレイなどの タイプだけをサポートします Core MLモデルを使う際にAppで 変換するだけです これがCore MLモデルとして トランスフォーマーを エクスポートする方法です トランスにサポートされていない操作が 含まれている場合エラーをスローします トレーニングされたパラメータとともに タスク定義をデプロイすることにこだわるなら Swiftパッケージへのバンドルをご検討ください これでパラメータをロードし 簡単に予測できます Swiftパッケージリソースの詳細は WWDC2020の講演をご確認ください これで以上です 覚えておいていただきたいのは コンポジションを使って カスタムタスクを作成できる ということであり可能性は無限大です どんなものができるか楽しみにしています 音声ビデオタスクを含む上級編については 「Create ML Componentsで 高度なモデルを作成する」 のセッションをご確認ください 私の同僚Davidが解説します 残りのWWDC 2022もお楽しみください
-
-
8:59 - Image regressor
import CoreImage import CreateMLComponents struct ImageRegressor { static let trainingDataURL = URL(fileURLWithPath: "~/Desktop/bananas") static let parametersURL = URL(fileURLWithPath: "~/Desktop/parameters") static func train() async throws -> some Transformer<CIImage, Float> { let estimator = ImageFeaturePrint() .appending(LinearRegressor()) // File name example: banana-5.jpg let data = try AnnotatedFiles(labeledByNamesAt: trainingDataURL, separator: "-", index: 1, type: .image) .mapFeatures(ImageReader.read) .mapAnnotations({ Float($0)! }) let (training, validation) = data.randomSplit(by: 0.8) let transformer = try await estimator.fitted(to: training, validateOn: validation) try estimator.write(transformer, to: parametersURL) return transformer } } -
12:18 - Image regressor with metrics and augmentations
import CoreImage import CreateMLComponents struct ImageRegressor { static let trainingDataURL = URL(fileURLWithPath: "~/Desktop/bananas") static let parametersURL = URL(fileURLWithPath: "~/Desktop/parameters") static func train() async throws -> some Transformer<CIImage, Float> { let estimator = SaliencyCropper() .appending(ImageFeaturePrint()) .appending(LinearRegressor()) // File name example: banana-5.jpg let data = try AnnotatedFiles(labeledByNamesAt: trainingDataURL, separator: "-", index: 1, type: .image) .mapFeatures(ImageReader.read) .mapAnnotations({ Float($0)! }) .flatMap(augment) let (training, validation) = data.randomSplit(by: 0.8) let transformer = try await estimator.fitted(to: training, validateOn: validation) { event in guard let trainingMaxError = event.metrics[.trainingMaximumError] else { return } guard let validationMaxError = event.metrics[.validationMaximumError] else { return } print("Training max error: \(trainingMaxError), Validation max error: \(validationMaxError)") } let validationError = try await meanAbsoluteError( transformer.applied(to: validation.map(\.feature)), validation.map(\.annotation) ) print("Mean absolute error: \(validationError)") try estimator.write(transformer, to: parametersURL) return transformer } static func augment(_ original: AnnotatedFeature<CIImage, Float>) -> [AnnotatedFeature<CIImage, Float>] { let angle = CGFloat.random(in: -.pi ... .pi) let rotated = original.feature.transformed(by: .init(rotationAngle: angle)) let scale = CGFloat.random(in: 0.8 ... 1.2) let scaled = original.feature.transformed(by: .init(scaleX: scale, y: scale)) return [ original, AnnotatedFeature(feature: rotated, annotation: original.annotation), AnnotatedFeature(feature: scaled, annotation: original.annotation), ] } } -
20:23 - Tabular regressor
import CreateMLComponents import Foundation import TabularData struct TabularRegressor { static let dataURL = URL(fileURLWithPath: "~/Downloads/avocado.csv") static let parametersURL = URL(fileURLWithPath: "~/Downloads/parameters.pkg") static let priceColumnID = ColumnID("price", Double.self) static var task: some SupervisedTabularEstimator { let numeric = ColumnSelector( columns: ["volume"], estimator: OptionalUnwrapper() .appending(StandardScaler<Double>()) ) let regression = BoostedTreeRegressor<String>( annotationColumnName: priceColumnID.name, featureColumnNames: ["type", "region", "volume"] ) return numeric.appending(regression) } static func train() async throws -> some TabularTransformer { let dataFrame = try DataFrame(contentsOfCSVFile: dataURL) let (training, validation) = dataFrame.randomSplit(by: 0.8) let transformer = try await task.fitted(to: DataFrame(training), validateOn: DataFrame(validation)) { event in guard let validationError = event.metrics[.validationError] as? Double else { return } print("Validation error: \(validationError)") } try task.write(transformer, to: parametersURL) return transformer } static func predict( type: String, region: String, volume: Double ) async throws -> Double { let model = try task.read(from: parametersURL) let dataFrame: DataFrame = [ "type": [type], "region": [region], "volume": [volume] ] let result = try await model(dataFrame) return result[priceColumnID][0]! } }
-