-
Metalメッシュシェーダでジオメトリを変換する
Metalメッシュシェーダとは - GPU駆動のジオメトリを作成・処理する、Metalの最新かつ柔軟なパイプラインです。このAPIがレンダリングパイプラインを向上させ、柔軟性を高める仕組みをはじめ、GPU駆動の機能がもたらす可能性について解説します。メッシュシェーダを使用するGPUで、ヘアレンダリングなどの手続き型ジオメトリを作成する方法や、追加の計算パスや中間バッファを使用せず、単独のレンダリングパスで構築する方法をご覧ください。また、GPU駆動のメッシュレットカリングで、シーンの処理やレンダリングを改善する方法も紹介します。
リソース
関連ビデオ
Tech Talks
WWDC22
-
このビデオを検索
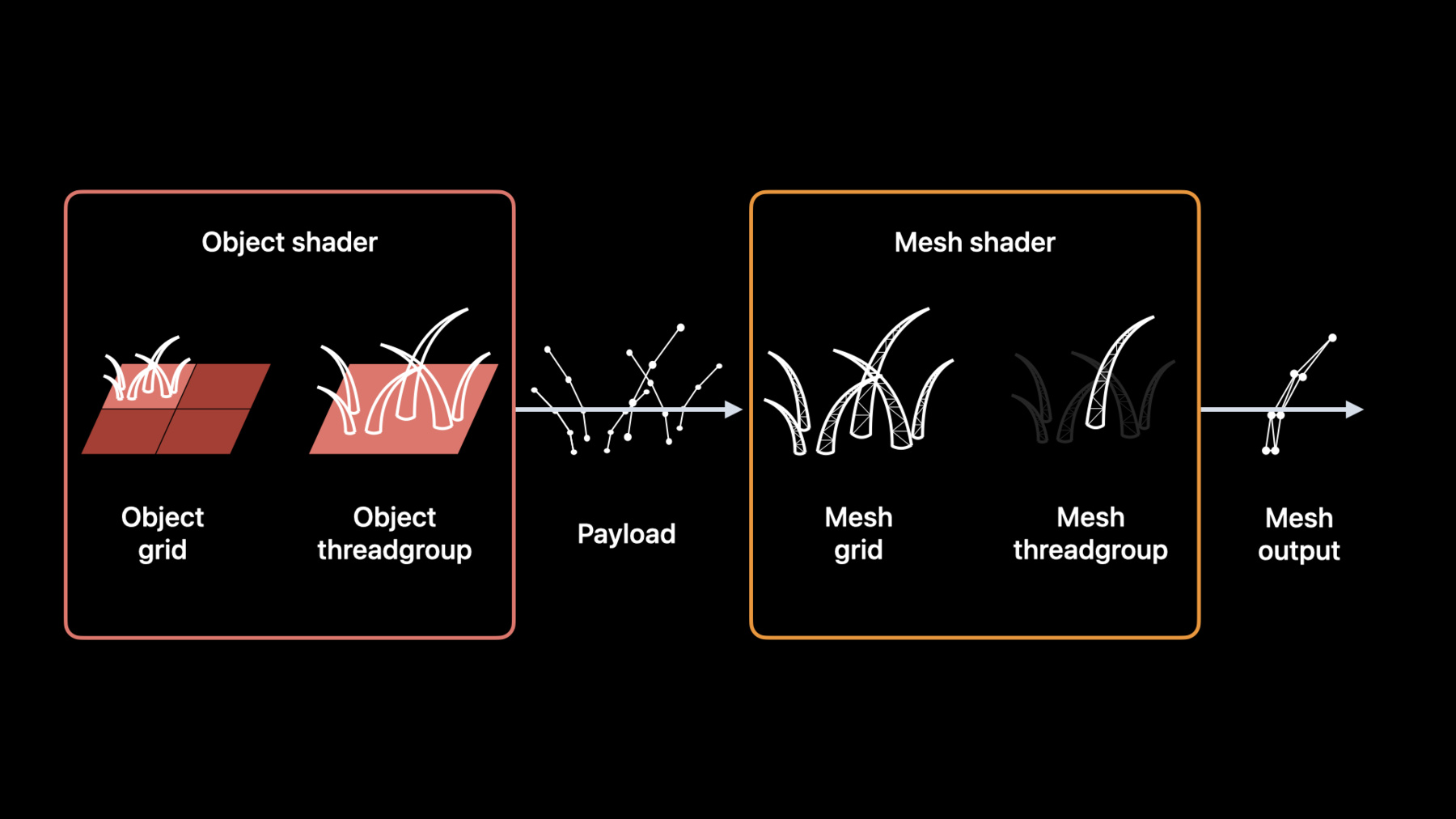
こんにちは Andreiです Metal framework teamの GPUソフトウェア エンジニアです 今日はMetalメッシュシェーダをご紹介します MeshシェーダはGPUによる ジオメトリ作成処理を行える Metalの新しい柔軟なパイプラインです 頂点/フラグメントパイプラインを改良し 多くの柔軟性を追加し 頂点ごとの制限を取り払ったものです 複数の用途がありますがその代表的なものは きめ細かいジオメトリカリング処理 GPU上でのスケーラブルな プロシージャルジオメトリの作成 圧縮頂点ストリーム メッシュレットや複雑なプロシージャル アルゴリズムなどの カスタム ジオメトリ入力などです 今日はこの3つを取り上げます まずMetalメッシュシェーダについて説明します その後 メッシュシェーダの 使用例を2つ紹介します メッシュシェーダはプロシージャルヘアなど プロシージャルジオメトリの作成に最適です シーン処理や レンダリングの 改善にも役立ちます この主な例がメッシュシェーダによる GPUを使ったメッシュレットカリングです まず メッシュシェーダから紹介します これはスタンフォードバニーです GPUでレンダリングできる典型的なメッシュです このメッシュをレンダリングするには まず頂点と インデックスのデータを デバイスメモリに配置する必要があります その後 レンダーコマンドエンコーダを使って ドローコールを実行します 従来のレンダリングパイプラインは 3つの基本ステージからなります プログラマブル頂点シェーダステージ 固定関数ラスタライズステージ プログラマブル フラグメント シェーダステージです 頂点シェーダステージではデバイスメモリから ジオメトリを入力として受け取り 処理します ラスタライザは 画面スペースでフラグメントを生成し フラグメントシェーダで 最終的な画像を生成します このパイプラインはよく機能してきました しかし柔軟性に欠けある種の制限もあります 例を見てみましょう GPUでプロシージャル ジオメトリを作成するとします このウサギにプロシージャルな毛皮を足します 従来のジオメトリパイプラインでは どう処理されるでしょうか 従来 プロシージャルジオメトリの作成には 演算カーネルのディスパッチを実行する 演算コマンドエンコーダが必要でした 演算カーネルは 元のメッシュを入力として受け取り プロシージャルジオメトリを 作成して デバイスメモリに戻します 次に レンダリングコマンドエンコーダを 使用して プロシージャル ジオメトリを入力とする ドローコールを実行し 最終画像を生成します この方法では2つのコマンド エンコーダが必要なだけでなく プロシージャルジオメトリを格納するために 追加のメモリを割り当てる必要があります 間接ドローコールや拡張係数が高い場合 メモリ量はかなり多くなり 予測も困難になります また 2つのエンコーダ間に障壁があり GPU全体で処理を逐次行います Metalメッシュシェーダは これらの問題を解決します メッシュシェーダは 新しいジオメトリパイプラインで 頂点シェーダステージを オブジェクトシェーダステージと メッシュシェーダという 2つのステージで置き換えます この例ではオブジェクトシェーダが ジオメトリを入力として受け取り 処理して ペイロードと呼ばれるデータを メッシュシェーダへ出力します このデータの中身はあなた次第です メッシュシェーダはこのデータを使って プロシージャルジオメトリを作成します このプロシージャルジオメトリは ドローコール内にのみ存在し デバイスメモリを割り当てる必要はありません これはラスタライザに直接パイプラインされ 最終画像を作成する フラグメントシェーダに送られます メッシュドローコールは従来の ドローコールと同タイプの レンダーコマンドエンコーダを使います メッシュドローコールと従来の ドローコールは混在可能です では 2つのプログラマブル ステージを見てみましょう
頂点シェーダと違い オブジェクトとメッシュシェーダは 演算カーネルに似ています これらはスレッドグループの グリッドで起動します 各スレッドグループは 個々のスレッドのグリッドであり 演算スレッド同様互いに通信が可能です オブジェクトスレッドグループは メッシュグリッドを生成し 起動したメッシュグリッドの サイズをプログラム的に定義できるため 非常に柔軟性があります オブジェクトスレッドグループは ペイロードを生成したメッシュグリッドに渡します オブジェクトステージは その名の通り オブジェクトを処理します オブジェクトは抽象的な概念で 必要に応じ定義可能です シーンモデルやその一部など プロシージャルジオメトリを 作成したい空間に使用できます メッシュステージはメッシュを作成し ジオメトリデータを 直接ラスタライザに送ります 次の2つの例で オブジェクトと メッシュの関係を説明します まずメッシュシェーダで 毛皮をレンダリングします 作業を単純化するため ウサギではなく平面を使います 毛皮を作成するため 入力ジオメトリをタイルに分割し 各タイルが詳細レベルと 必要な毛の量を計算し 個々の毛を1本ずつ作成します メッシュシェーダを使用してこの平面に毛皮を 順番に生成しましょう 平面をタイルに分割して オブジェクトスレッドグループに対応させます 各オブジェクトスレッドグループは 毛の束の数を計算し それぞれの束のカーブ制御点を生成します これペイロードになります オブジェクトスレッドグループは メッシュグリッドを起動し 各メッシュスレッドグループが一束を表します 各メッシュスレッドグループは ラスタライザにメッシュを出力します 新しいジオメトリパイプラインは ジオメトリ処理をハードウェアにマッピングし GPUのすべてのスレッドを最大限活用できます メッシュレンダリングパイプラインでは 入力ジオメトリはオブジェクトシェーダ グリッドのためタイルに分割されます 各オブジェクトシェーダスレッド グループは独立してペイロードを生成し メッシュグリッドを起動できます 各メッシュシェーダスレッドグループは レンダリングパイプラインの残りの部分で さらに処理されるmetal::meshを生成します 各ステージで作成される データを詳しく見てみましょう ペイロードはオブジェクト シェーダで定義されます 各オブジェクトスレッドグループは カスタマイズされたペイロードを 生成するメッシュグリッドに渡します 毛のレンダリングの場合 ペイロードはカーブ制御点で構成されます 一方 メッシュシェーダは新しい metal::meshタイプを通じて 頂点とプリミティブデータを出力します
オブジェクトとメッシュステージは パイプラインの残りの部分で 使用されるメッシュデータを出力します 従来のパイプラインからの頂点出力と同様 メッシュデータはまずラスタライザで使用され その後フラグメントシェーダが実行されます 毛のレンダリングメッシュパイプラインに ついて詳しく見てみましょう まず 毛で覆われる平面がタイルに分割され 各タイルはオブジェクトスレッド グループに対応します オブジェクトスレッドグループは メッシュグリッドのサイズを決定し メッシュグリッドに渡す ペイロードデータを初期化します この場合 タイルには6本の毛があり 3x2のメッシュグリッドが生成され 毛ごとにカーブペイロード データが付与されます 各スレッドグループは 固有の メッシュグリッドサイズを生成できます 次のスレッドグループでは4本の毛を 生成する必要があるため 2x2のメッシュグリッドが設定され 4本分のカーブペイロード データが初期化されます この方法を実装した オブジェクトシェーダはこうなります オブジェクトシェーダのコードを指定するため Metalにオブジェクト属性が追加されました ペイロード属性とオブジェクト データアドレス空間により シェーダ内でペイロード引数が使用可能です
mesh grid propertiesの引数は メッシュの グリッドサイズのエンコードに使用されます 次に パイプラインを初期化します まずMesh Render Pipeline Descriptorを割り当て オブジェクト関数を初期化し スレッドグループごとのスレッドの最大数と ペイロードの長さを指定します オブジェクトシェーダには一定の制約があります ペイロードフォーマットとコンテンツは 完全にカスタマイズ可能です ただしペイロードサイズは 最大16キロバイトです また 各オブジェクトスレッド グループが生成する メッシュスレッドグループの最大値は1,024です オブジェクトシェーダステージの 準備が終わったので メッシュシェーダステージを初期化します メッシュシェーダはユーザー定義の ペイロードが入力になります この場合 ペイロードは一連のカーブ制御点です 各メッシュスレッドグループが1本の毛となる metal::meshを生成します メッシュシェーダの出力メッシュは metal::meshである必要があります metal::meshはMetalの組み込み 構造体で ラスタライザおよび フラグメントシェーダに 頂点およびプリミティブ データを出力するインターフェースを提供します metal::meshは 頂点データの出力タイプに似た 頂点データ型 プリミティブデータ型最大頂点数 最大プリミティブ数 点 線 三角形のメッシュトポロジーを定義します どのコードがメッシュ シェーダかを指定するため Metalシェーダ言語にmesh属性が追加されました metal::meshはメッシュシェーダ内の 出力構造として使われます
メッシュシェーダは GPUのジオメトリ処理に最適で ラスタライザが使用するmetal::meshを オンザフライで生成できます メッシュシェーダはmetal::meshを活用しており 計算パスを追加することなく レンダーコマンドに 多くの処理を割り当て可能です メッシュのエンコードは同じスレッド グループのスレッド間で行われます この例ではスレッドグループの 最初の9スレッドが この髪の頂点 インデックス プリミティブ データをエンコードします スレッド0~4がそれぞれメッシュの 頂点をエンコードします 残りのスレッドはメッシュの 頂点をエンコードしません 次に 9つのスレッドすべてが 1つのインデックスをエンコードします
次に最初の3つのスレッドが三角形の プリミティブデータをエンコードします 残りはプリミティブデータを エンコードしません 最後に1つのスレッドがMetalメッシュの プリミティブ数をエンコードします このメッシュシェーダの ソースコードをお見せします メッシュシェーダは 頂点インデックス プリミティブデータをエンコードし 最後にプリミティブ数をエンコードするという 同じステップを踏むことでスレッドの分岐を 可能な限り避けるよう構成されています
メッシュパイプライン記述子の 初期化に戻りましょう メッシュパイプライン 記述子には メッシュスレッド グループあたりの最大 スレッド数が設定されています metal::mesh構造には守るべき制限があります metal::meshシェーダの制限は以下の通りです metal::meshは最大256個の頂点と 512個のプリミティブをサポートします metal::meshの最大サイズは16キロバイトです メッシュグリッドで Metalメッシュが生成されると ラスタライザに渡され フラグメントシェーダが実行されます 従来のレンダリングパイプラインのように メッシュパイプライン記述子に フラグメント関数を設定します 記述子が初期化されたので Metalデバイスの「make render pipeline state with mesh descriptor」メソッドで パイプラインの 状態が生成されます メッシュパイプラインの エンコードは 従来のドローコールに似ています パイプラインの状態が エンコーダに設定されます パイプラインの各ステージは リソースをバインドできます この例ではオブジェクトバッファを オブジェクトステージにテクスチャを メッシュステージに フラグメントバッファを フラグメントステージにバインドしています 次にメッシュパイプラインの開始に 必要な定数を定義します オブジェクトグリッドのサイズ オブジェクトスレッド グループごとのスレッド数 メッシュスレッドグループごとのスレッド数 これらの定数を使用して新しい 「draw mesh threadgroups」 メソッドによる描画をエンコードします 毛の平面をレンダリングするのと同じ方法を ウサギ全体に適用して メッシュパイプラインを通じて 毛皮をプロシージャルに生成できます 次に メッシュシェーダの 別の使用方法を見てみましょう メッシュシェーダは メッシュレットカリングを使用して 大量のジオメトリを効率よく処理し レンダリングできます この手法の基本はシーンメッシュを小さな メッシュレットという断片に分割することです
メッシュレットに分割することで シーンの粒度が向上し より効率的できめ細かい カリングが可能になります これによりジオメトリの オーバーヘッドを大幅に削減できます メッシュレット粒度処理を活用することで 画面空間のオクルージョンカリングや 法線フィルタリングなどのカリング アルゴリズムを効率的に行えます メッシュシェーダを使用すると GPUによるカリングやレンダリング パイプラインを実装できます ここでは 1つの演算パスと 1つのレンダーパスを使用して シーン処理とレンダリングを実行する 従来のGPU型パイプラインを示しています シーンデータはメッシュレットに分割され 演算パスに送られます 演算パスはフラストラムカリング LODの選択 デバイスメモリへの 描画エンコードを担当します レンダーパスがシーンのドロー命令を実行し 最終的な画像を作成します メッシュシェーダを使用すると 2つのパスを1つのメッシュシェーダ ディスパッチに統合することで 同期ポイントを削除し 中間ドローコマンドを回避できます やり方をお見せします ここに メッシュシェーダ ディスパッチを実行する レンダーパスがあります オブジェクトシェーダが フラストラムカリングを行い 見えるメッシュレットごとにLODを演算します メッシュシェーダのペイロードは エンコードする メッシュリストIDの一覧です メッシュシェーダは ラスタライズとシェーディングを行う メタルメッシュオブジェクトを エンコードします 最終的な画像は従来のパイプラインと同様 フラグメントシェーダで シェーディングされます ジオメトリ処理はすべて メッシュスレッドグループコマンド内と 単一のエンコーダで行われます 三角形のデータはメッシュシェーダで エンコードされるため ドローコマンドを保存する 中間バッファは不要です
ではカリングの話ですが 特にメッシュレットカリングの 実装を取り上げます シーンはここにある図形の モデルで構成されています ここでは各モデルがオブジェクト グリッドの一部になります オブジェクトシェーダスレッドグループが 生成したメッシュグリッドは モデルの表面を覆う 三角形の集まりである メッシュレットで構成されます 新しいジオメトリパイプラインは 非常に柔軟性があります シーンをどうオブジェクトグリッドに マッピングするかは自由です ここではオブジェクトスレッド グループにマッピングしていますが タスクに適したマッピングを使用してください オブジェクトシェーダは ビューイングフラストラムを使い メッシュレットの可視性を決定します 最終的な画像に表示されるものにだけ 作業をディスパッチします シーンの2つのモデルに注目しましょう オブジェクトシェーダが可視性に 基づきメッシュグリッドを開始します メッシュシェーダがメッシュレットを 処理し metal::meshを構築します プログラム可能なメッシュグリッドサイズは 見える範囲のメッシュレットのみを 処理するため柔軟にディスパッチを行います パイプラインの後半で見えないジオメトリの 処理に費やす時間を短縮できます 固定関数ラスタライザは 見える表面だけを受け取るので 見えないジオメトリの処理や クリップ処理の時間を短縮します 最後にフラグメントシェーダが呼び出され 最終的な画像が生成されます このように 新しい ジオメトリパイプラインにより プロシージャルメッシュの作成や メッシュレットカリングの例で示した ドローコールの効率化など 様々な問題に対処できます Metalには モダンで柔軟な新しい ジオメトリパイプラインが実装されました 毛のレンダリングの例のように プロシージャルなジオメトリを これまで以上に簡単に作成可能です さらに メッシュレットカリングの デモで見たように 追加の演算パスや 中間バッファを必要とせず1回のレンダーパスで GPUによる作業の可能性が広がりました 新しいジオメトリパイプラインは Family7とMac2デバイスで利用可能です
メッシュシェーダの学習と体験用に 新しいAPIの使用方法を示した サンプルコードが Appleデベロッパウェブサイトで 公開されています これらの機能とApple GPUの超並列性を活用し みなさんのニーズにあったジオメトリ処理を 実現させてください ご視聴ありがとうございました
-
-
8:13 - Object shader (MSL)
[[object]] void objectShader(object_data CurvePayload *payloadOutput [[payload]], const device void *inputData [[buffer(0)]], uint hairID [[thread_index_in_threadgroup]], uint triangleID [[threadgroup_position_in_grid]], mesh_grid_properties mgp) { if (hairID < kHairsPerBlock) payloadOutput[hairID] = generateCurveData(inputData, hairID, triangleID); if (hairID == 0) mgp.set_threadgroups_per_grid(uint3(kHairPerBlockX, kHairPerBlockY, 1)); } -
8:35 - Initializing object stage
let meshPipelineDescriptor = MTLMeshRenderPipelineDescriptor() meshPipelineDescriptor.objectFunction = objectFunction meshPipelineDescriptor.payloadMemoryLength = payloadLength meshPipelineDescriptor.maxTotalThreadsPerObjectThreadgroup = hairsPerBlock -
9:26 - Defining a Metal Mesh
struct VertexData { float4 position [[position]]; }; struct PrimitiveData { float4 color; }; using triangle_mesh_t = metal::mesh< VertexData, // Vertex type PrimitiveData, // Primitive type 10, // Maximum vertices 6, // Maximum primitives metal::topology::triangle // Topology >; [[mesh]] void myMeshShader(triangle_mesh_t outputMesh, ...); -
11:16 - Mesh Shader (MSL)
[[mesh]] void myMeshShader(triangle_mesh_t outputMesh, uint tid [[thread_index_in_threadgroup]]) { if (tid < kVertexCount) outputMesh.set_vertex(tid, calculateVertex(tid)); if (tid < kIndexCount) outputMesh.set_index(tid, calculateIndex(tid)); if (tid < kPrimitiveCount) outputMesh.set_primitive(tid, calculatePrimitive(tid)); if (tid == 0) outputMesh.set_primitive_count(kPrimitiveCount); } -
11:35 - Initializing the mesh stage
meshPipelineDescriptor.meshFunction = meshFunction meshPipelineDescriptor.maxTotalThreadsPerMeshThreadgroup = vertexCountPerHair -
12:08 - Initializing the fragment stage
meshPipelineDescriptor.maxTotalThreadsPerMeshThreadgroup = vertexCountPerHair -
12:14 - Creating a mesh render pipeline
/// A mesh pipeline state the device creates from a mesh render pipeline descriptor. let meshPipeline: MTLRenderPipelineState do { /// A tuple of the mesh pipeline and its reflection information, if applicable. let (pipeline, reflection) = try device.makeRenderPipelineState(descriptor: meshRenderPipelineDescriptor, options: []) meshPipeline = pipeline } catch { print("The device can't create a mesh pipeline state: \(error)") return } -
12:25 - Encoding a mesh pipeline
// Create a encoder for a render pass from the command buffer. let encoder: MTLRenderCommandEncoder! encoder = commandBuffer.makeRenderCommandEncoder(descriptor: descriptor) // Apply the mesh pipeline to the render pass. encoder.setRenderPipelineState(meshPipeline) // Bind the resources for the render pass. encoder.setObjectBuffer(objectBuffer, offset: 0, index: 0) encoder.setMeshTexture(meshTexture, index: 2) encoder.setFragmentBuffer(fragmentBuffer, offset: 0, index: 0) // Create the size instances for the mesh threadgroups. let objectGridDimensions = MTLSize(width: trianglesPerModel, height: 1, depth: 1) let threadsPerObject = MTLSize(width: hairsPerBlock, height: 1, depth: 1) let threadsPerMesh = MTLSize(width: threadsPerHair, height: 1, depth: 1) // Encode the draw command for the render pass. encoder.drawMeshThreadgroups(objectGridDimensions, threadsPerObjectThreadgroup: threadsPerObject, threadsPerMeshThreadgroup: threadsPerMesh) // Finish encoding the render pass. encoder.endEncoding()
-