-
Swift Regexの紹介
Swift Regexを活用することで、より効果的に文字列を処理する方法を学びます。文字列処理への新しい宣言的なアプローチであるRegexビルダーの簡潔なリテラル表記をご覧ください。また、StringのUnicodeモデルを紹介し、Swift Regexによってユニコードの修正処理を容易にする仕組みも解説します。
リソース
関連ビデオ
WWDC22
-
このビデオを検索
こんにちはMichael Ilsemanです Swift standard library teamの エンジニアです SwiftでRengexに触れて理解しましよう Swift Regexにはたくさんの魅力がありますが そのすべてを味わってみましょう ある金融機関の調査官と共同で 取引に不正がないか分析する ツールを開発したとします さて このような重要なタスクでは よく構造化されたデータを 処理すると思うでしょう しかし その代わりに文字列の束があるのです ここで 最初の領域は取引の種類 2番目の領域は取引日 3番目の領域は個人または機関 4番目と最後の領域は米ドルでの金額です 領域は2つ以上のスペースか タブで区切られていますが これは関係者が誰も思い出せないような 非常に重要な技術的理由によるものです そして そうです日付の領域は完全に曖昧です 年/月/日であると願い 様子を見ることにしています これらの取引の処理には文字列処理が含まれ 文字列は収集であるため 一般的な収集アルゴリズムに接続できます このアルゴリズムは基本的に 要素に対して動作するものと 索引に対して動作するものの2種類があります 取引の領域を分割して 要素ベースのアルゴリズムを使おうとしても 領域のセパレータがタブか2つ以上のスペース であるため難しく 空白だけで分割してもうまくいかないのです また 低レベルのインデックス操作のコードに 落とし込む方法もあります
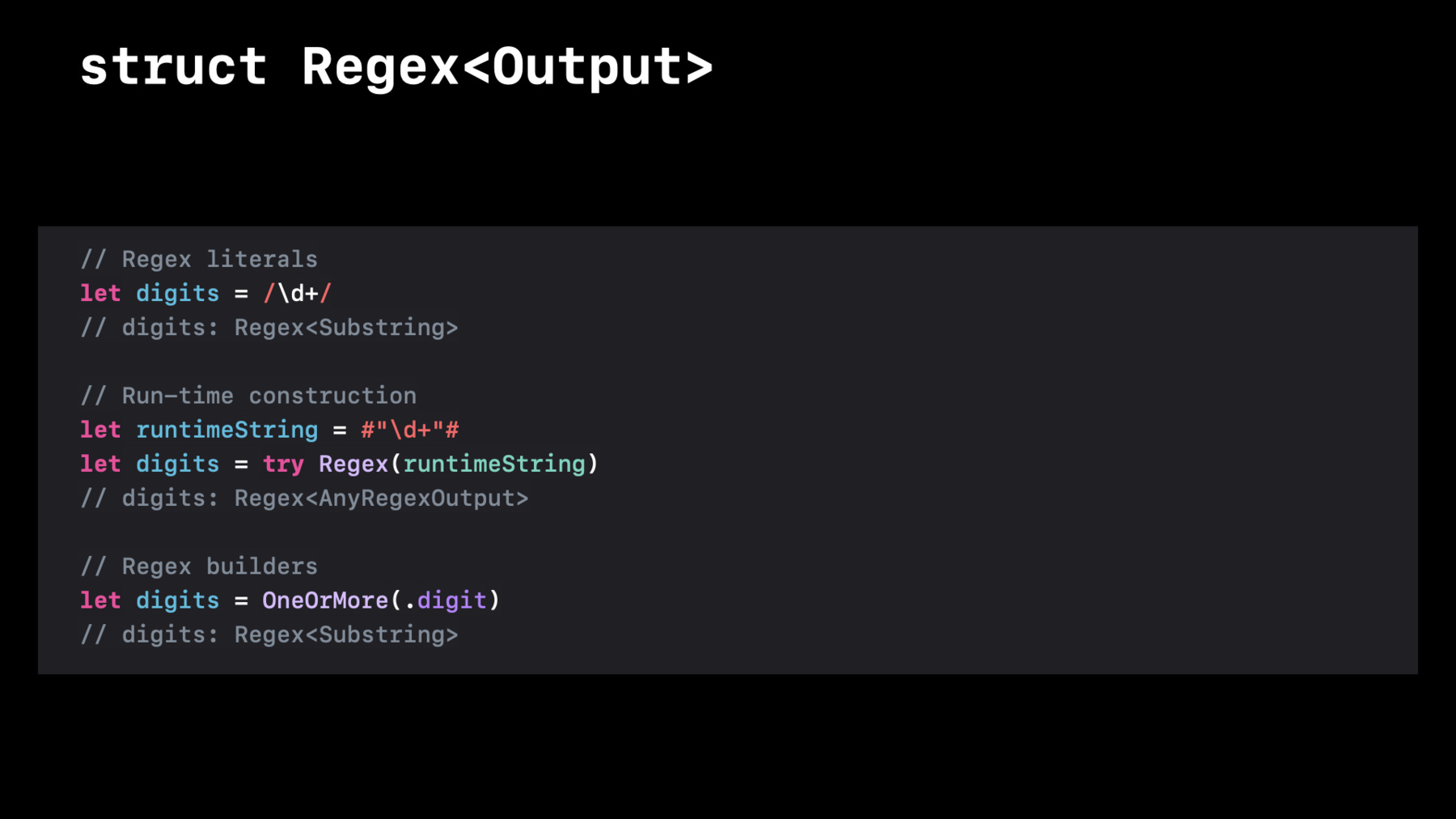
しかし正しく行うのは難しく たとえ何をやっているのか分かっていても 多くのコードが必要です 分割に戻りましょう この方法が機能しないのは領域分離が もっと複雑なパターンなのに 対し 要素ベースなためです 様々な言語で見られる解決策は 正規表現を書くことです 正規表現は形式言語理論から生まれたもので 正規言語を定義するものです エディタやコマンドラインツールでの 検索や コンパイラでの 字句解析に実用化されました このAppでは入力の一部を抽出したり 直接実行を制御したり 表現力を加えたりする必要があるため 正規表現の理論的な ルーツを超えています そして Swiftはそれをさらに 推し進めようとしています この誘導体をRegexと呼びます Regexは キャプチャを含む 適用結果であるOutputを 総称する構造体です スラッシュで区切られた 正規表現を含むリテラルを 使って作成できます Swiftの正規表現構文はPerl Python Ruby Java NSRegularExpression その他 多くと互換性があります この正規表現は 1つ以上の数字にマッチします コンパイラは正規表現の文法を知っているので 構文強調表示やコンパイル時 のエラー さらには後で 紹介する 強く定型化された キャプチャも表示されます 正規表現は同じ正規表現構文を含む 文字列から実行時に作成できます エディタやコマンドライン ツールの検索領域に便利です 入力無効な構文が含まれる時 実行時にエラーを送出します 出力タイプは 実行時までキャプチャの型と数が わからないため 実存の AnyRegexOutputとなります
また同じ正規表現を冗長では あるが宣言的で構造化された 正規表現ビルダーを使って 記述することも可能です
先ほどの分割方法を正規表現 リテラルに合せてみましょう 最初の部分は 2個以上の 任意の空白文字に一致します 2番目の部分は 横長の1枚のタブと一致します パイプ文字は 2つ以上のスペースか1つのタブを 領域分離として選択することを表示します 領域が分割されたので 文明そのものに貢献し その領域分離を1つのタブに 正規化して終わりとします 分割後の結果に対して’join’ を呼び出すこともできますが これにはもっと良いアルゴリズムがあります ‘replacing’を使い 領域分離 を1つのタブに置き換えます
だから 私たちは外に出て 明らかに優れたアプローチを 耳を傾けてくれる人に伝道するのです 採用はゆっくりですが期待できます 正規表現をご存知の方は その複雑な評判もご存じかもしれません 昔から言われているように「問題があったので 正規表現を書いた」今は2つの問題がある しかし Swift regexは違います
Swiftは 4つの重要な分野で 技術を進歩させています 正規表現の構文は簡潔で表現力が豊かですが 素っ気なく読みにくいものに なることがあります 新機能は一段と暗号化された 構文の使用が必要です
Swiftの正規表現はRegexビルダーによって 原始コードを構造化し整理 するのと同じようにできます 文字は簡潔で ビルダーは構造を与え 文字は ビルダーでの使用で 完璧な バランスを見つけられます データのテキスト表現は 非常に複雑になっており 正しく扱うには標準適合パーサが必要です Swift regexでは 正規表現の 個々の構成要素として 業務用パーサを織り交ぜて使用できます ライブラリ拡張可能方法で行われるため どんなパーサでも参加できます
正規表現の応用の歴史の多くは コンピュータシステム全体が 単一の言語と符号化 特に ASCIIしかサポートしてない 世界で行われていた しかし 現代はUnicodeです Swift regexは表現性を妥協 せず Unicodeを処理します 最後に 正規表現の力は網羅的に探索すべき 広範な探索空間を開くことができます そのため その実行を推論することは困難です 言語によっては制御に対応していますが 暗号のような構文が背後にあるため 不明瞭になりがちです 予測可能な実行を提供し 制御を顕著に表面化します これまで扱ってきた財務諸表に戻り Swiftで 文字列処理の叙述手法である Regex ビルダーを使用して 各取引を完全に解析してみましょう RengexBuilderモジュールの インポートから始めます 先ほど定義した領域分離 正規表現を再利用できます 最初の領域は簡単ですCREDITかDEBITかです すでに見てきた正規表現の 文字構文を使って書くのです その後に領域分離そして日付が来ます 手作業で日付を解析するのは良くないです Foundationには 日付 数字URLなどの型に対し 優秀なパーサがあり Regex- Builderで直接使用できます
作者の意図を最も推測できる 明確なロケールを提供します 現在のロケールを暗黙的に 使用せず このようにします 後でいつでも変更できますし コードの中で仮定を 明示的にしているので変更も簡単です
3つ目の領域は"何でも"なので "あれやこれや"と書きたくなりますね そして 正しい答えが得られますが 最初に不要な作業をたくさんしてしまうのです これは 後に来るものとの 照合から始めるからです 正規表現は1文字ずつ控えて 残りのパターンを試します 正規表現が終端領域分離を 見た時に停止したいとします これを遂行する方法はいくつかあります 良い方法の一つは 入力の 次の部分を実際に消費せず 覗き見る NegativeLookaheadの使用です ここでは文字に照合する前に 領域分離の表示がないことを 確認するために入力を覗き込んでいます NegativeLookaheadは正規表現とその構成要素の マッチングを正確に制御するツール群の1つです
最後に Foundationのパーサの1つを使って 今度は通貨の金額を照合します これまでカンマは千の区切り ピリオドは小数の区切りと 仮定してきましたがこの仮定を明示します 取引元帳から行を解析する 正規表現を作成しました 行を認識するだけではなく データの一部を抜き出します そのために 入力の一部を 抽出して後で処理する キャプチャを使用しています 慣例により'0番目'の キャプチャは正規表現全体が 一致した入力部分であり 各明示キャプチャが続きます 取引の種類は 入力の薄片の 部分列として捕捉されます 日付については テキストを後処理することなく 解析された強く型付け された値を実際に取得します 個人または機関は 再び 入力の一部として取得され 小数の取得は 別の強く型付けされた値です 使い方は 照合結果から日付と小数点以下の値を 抽出し 捜査員がここから取り出します この時点で構造化照会などの 明白な利点のため データを 実際のデータベースにダンプ することをお勧めします 彼らは違う意見を持っています 何でもかんでも文字列にしようとします この講演でSwift Regexを より理解できるのは朗報です すべてが順調です突然そうでなくなるまでは みんなが全く曖昧だと 言っていた取引文の日付順が 実際に曖昧であることが判明したのです 必ずしも同じではなく 取引に使われる通貨によって 異なるという説が有力です もちろんそうだからです つまり 米ドルは月/日/年 英ポンドは日/月/年ということです 曖昧さをなくすsedのような スクリプトを書きましょう 正規表現では 拡張デリミタを使用します スラッシュを避けることなく 内部に持つことができます また 空白を無視する拡張構文モードも 利用できるため標準コードと同様に 可読性を高めるために空白の使用も可能です タプルラベルの表示には 指定キャプチャを使いました 通貨記号を認識するために Unicode Propertyを使います これにより 正規表現がより順応可能になり 応用論理で特定のシンボルを 扱うことになります
手動でテキストを切り貼りするのではなく 今回もFoundationの日付パーサを使用します pickStrategyは通貨記号を受け取り それに基づいて解析戦略を決定します すべての前提条件がコードで 明示されているため 適応や展開が容易であり 最終的には必ず必要になるものです
キャプチャを含む照合結果を 使用し置換文字列を作成する クロージャを提供して 正規表現とヘルパー関数を 検索置換アルゴリズムで使ってみましょう 取り込んだ通貨を元に 戦略を選び日付を解析します 位置だけでなく 名前で キャプチャに接続できます 出力には 曖昧さのない 業界標準のISO-8601を使用し 新しい日付をフォーマットします この台帳を曖昧でない台帳に 変換するのがこのツールです 本物の日付パーサと フォーマッタを使用している ため 要求の変化への 適応性がはるかに高いのです また 通貨記号の認識にUnicode Propertyを 使用することで より早く 進化させることができます 正規表現は文字列モデルの アルゴリズムを示します SwiftのStringは Unicodeで 作業する複数の型を示します これは時代を超えた恋物語を 表現し 3文字が含まれます これらの文字は 正式にはUnicode extended- grapheme clustersと呼ばれる複雑な実体です 文字は1つ以上のUnicode スカラー値で構成されます 文字列は内容の下位レベルの 表現に接続するために UnicodeScalarViewを提供します これにより 高度な利用や 他系統との互換性が可能です
物語の主人公である最初のキャラクターは 4つのUnicodeスカラーで構成されています ゾンビ ゼロ幅ジョイナ女性の表示 そして VARIATION SELECTOR-16は この文脈では 絵文字での 表現を好むことを示します もちろんです! スカラーは 視覚的に見る 1枚の絵文字を生成します 文字列をメモリに格納する時 UTF-8バイトで暗号化します これらはUTF-8表示を使って見ることができます UTF-8は可変幅符号化なので 1つのスカラーに複数の バイトが必要なことがあり これまで見てきたように 1つの文字に複数のスカラー が必要になることがあります 4つのユニコードスカラーで 表される物語の主人公は 13のUTF-8バイトで符号化されます 複数のスカラーで構成される だけでなく 全く同じ役柄が 異なるスカラーセットで 表現されることもあります これは 英語以外の言語を 扱うときによく出てきます この例では 鋭アクセントの ついた'e'は 単一のスカラー 鋭アクセントの合成済みe または ASCIIの'e'に続く 結合鋭アクセントとして表現可能です これらは同じ文字なので Stringの対照は真を返します これは Stringが正式にはUnicode Canonical Equivalenceと呼ばれるものに従うからです
UnicodeScalarViewやUTF-8表示から見ると 内容が異なっておりこれらの下位レベルの 表示内で比較するとこの違いがよくわかります Swiftの正規表現は初期値で 執拗にUnicodeに正確です しかし 表現力を損なう ことなく実現されています 一組の文字列を入れ替えてみましょう 最初の文字列は ドット(.)で 示される文字で囲まれた 名前付きUnicodeスカラー 「SPARKLING HEART」に一致
any character分野はSwiftの任意の文字 つまり Unicode拡張書記素クラスタに一致します
2つ目の文字列は 等しい 文字は等しいものとして 比較し 大文字小文字を無視できます そして今 単純な恋物語は もっと複雑になっています 人生には またこの場合人生でないものには 処理が必要な複雑な要素があることがあります
Stringと同様に 互換性や 下位書記素クラスタの精度に Unicodeスカラー値を自分で 処理する必要がある場合は 'unicodeScalar'意味論で 一致させることが可能です Unicode Scalarレベルで一致する場合 ドットは完全なSwift Characterではなく 単一のUnicode Scalar値に一致します VARIATION-SELECTOR 16 つまり また友人に会えます この扱いやすい小セレクタは ドットで一致され 単独では 空の余白として表現され見ることができません とても参考になります
さて 精度と正しさを追求したところで 少し変わったことをやって金融に戻りましょう 調査員たちが戻ってきて 今回は興味深い依頼がありました また取引照合ツールを改良し 事後的に台帳の処理でなく 電信による取引をそのまま 傍受するようにしました コードを見ると 実は結構 良い仕事をしていますが 拡大縮小問題に直面しており 我々の助けが必要です 処理する取引はよく似て いますが 細かな相違があり 日付の代わりに 正確な時刻印が表示されます これは 明確で曖昧さのない 衝撃的な独自の書式で表現されています 前世紀に書かれた正規表現があり これにうまく一致するそうです それで結構です 次に 個人と識別コードを 含む詳細領域があります この領域に対して 入力から 得られた実行時に収集された 正規表現を使用して 取引を フィルタリングします ライブで しかもこの後まだまだ領域あるので 面白くない取引は早めに手を引きたいです その後 金額やチェックサム などの領域がきますが これらは単独で問題なく処理できます 当然 領域は2つ以上の余白 またはタブで区切られます
彼らの取引マッチャーは 私たちのとよく似ています 時刻印には独自の正規表現を持ち 詳細な正規表現は入力から蓄積され 残りの領域を処理します 彼らは結構良い仕事をし 技術的にはすべて正常です うまく拡大縮小できていないだけです 時刻印と詳細の正規表現が 領域よりもさらに多くの 入力に一致することが頻繁だと気づきました 理想的には この正規表現は 1つの領域に対してのみ 実行されるように制約されます 私たちの事業では 同様の 問題を 負の先読みを使って 処理したので その正規表現を引き出しましょう
‘field’は領域分離に遭遇するまでは どんな文字にも効率よく一致するので 正規表現を格納するために使用します 後処理段階でも行えますが ライブで実行するので 正規表現が領域に一致しない 場合は早期に立ち去ります TryCaptureを使用して行うことができます TryCaptureは一致した領域を クロージャに渡し そこで 調査員の時刻印と詳細の 正規表現に対して検査します 一致した時は 照合が成功し その領域がキャプチャされた ことを意味するその領域の値を返します それ以外の場合はゼロを返し 照合の失敗を知らせます TryCaptureのクロージャは 照合に積極的に参加します つまり まさに私たちが必要としているものです これにより 拡大縮小の 大きな問題を解決できました しかし まだもう一つ問題があります 取引マッチャーの後のほうで 何かが失敗したとき 終了するのに長い時間がかかります
冒頭で定義したfieldSepa- rator正規表現は2つ以上の 空白やタブに一致するもので 私たちが望むものです 8個の空白文字がある場合 残りの正規表現を試す前に それら全てに一致します しかし 後に正規表現が失敗 した場合 バックアップして 7つの空白文字にのみ照合 させてから再試行します もし失敗した時は 6文字の 空白文字のみ照合 のように
あらゆる選択肢を試した末に 初めて照合に失敗します 代替案を試すための逆流を グローバルバックトラック 形式論理学では クリーネクロージャといいます それが正規表現の特徴的な力になっています しかし それは調査のための 広い探索空間を開くもので ここではより直線的な探索空間を求めています すべての空白を一致させ決してあきらめません 使えそうなツールがいくつかあります 一般的な方法は fieldSepa- ratorをグローバルではなく ローカルのバックトラック スコープに置くことです
Local builderは 含まれる 正規表現がうまく一致した 時に 未試行の代替表現が すべて捨てられるような スコープを作成します
たとえ取引マッチャーが後で失敗したとしても スペースを少なくするために 後戻りすることはないのです 正規表現の初期値である グローバルバックトラックは 検索やファジーマッチングに最適です ローカルは正確に指定された トークンの照合に便利です 領域分離は 厄介かもしれませんが 正確です
ローカルは原子非取り込み グループとして他の所で 知られていますが恐ろしい名前かもしれません 正規表現が爆発しそうな感じになります しかし 実際にはその逆で探索空間を含んでいて
これにより 拡大縮小問題を解決できたのです 今日はSwift Regexを紹介しましたが 紹介しきれなかったことがたくさんあります 同僚のRichardによる 「Swift Regex: 上級編」もご覧ください 退出前に いくつかの点を強調しておきます Regexビルダーは構造を与え Regexリテラルは簡潔です どのタイミングでどちらを使うかは 最終的には主観的な判断になります 可能な限り本物のパーサを使用してください 膨大な時間を節約し 頭痛を避けることができます Swiftの初期値を使うだけで 他のどこよりはるかに多くの Unicodeの対応と良さを 手に入れることができます 通貨記号を合わせたときの ように 文字の特性など 効果的に使う方法を探してみてください ルックアヘッドやローカル バックトラックスコープなど 制御の使用で 検索や処理の アルゴリズムを簡素化します ご視聴ありがとうございました
-
-
1:35 - Processing collections
let transaction = "DEBIT 03/05/2022 Doug's Dugout Dogs $33.27" let fragments = transaction.split(whereSeparator: \.isWhitespace) // ["DEBIT", "03/05/2022", "Doug\'s", "Dugout", "Dogs", "$33.27"] -
1:49 - Low-level index manipulation
var slice = transaction[...] // Extract a field, advancing `slice` to the start of the next field func extractField() -> Substring { let endIdx = { var start = slice.startIndex while true { // Position of next whitespace (including tabs) guard let spaceIdx = slice[start...].firstIndex(where: \.isWhitespace) else { return slice.endIndex } // Tab suffices if slice[spaceIdx] == "\t" { return spaceIdx } // Otherwise check for a second whitespace character let afterSpaceIdx = slice.index(after: spaceIdx) if afterSpaceIdx == slice.endIndex || slice[afterSpaceIdx].isWhitespace { return spaceIdx } // Skip over the single space and try again start = afterSpaceIdx } }() defer { slice = slice[endIdx...].drop(while: \.isWhitespace) } return slice[..<endIdx] } let kind = extractField() let date = try Date(String(extractField()), strategy: Date.FormatStyle(date: .numeric)) let account = extractField() let amount = try Decimal(String(extractField()), format: .currency(code: "USD")) -
2:47 - Regex literals
// Regex literals let digits = /\d+/ // digits: Regex<Substring> -
3:20 - Regex created at run-time
// Run-time construction let runtimeString = #"\d+"# let digits = try Regex(runtimeString) // digits: Regex<AnyRegexOutput> -
3:44 - Regex builder
// Regex builders let digits = OneOrMore(.digit) // digits: Regex<Substring> -
3:56 - Split approach with a regex literal
let transaction = "DEBIT 03/05/2022 Doug's Dugout Dogs $33.27" let fragments = transaction.split(separator: /\s{2,}|\t/) // ["DEBIT", "03/05/2022", "Doug's Dugout Dogs", "$33.27"] -
4:36 - Normalize field separators
let transaction = "DEBIT 03/05/2022 Doug's Dugout Dogs $33.27" let normalized = transaction.replacing(/\s{2,}|\t/, with: "\t") // DEBIT»03/05/2022»Doug's Dugout Dogs»$33.27 -
6:55 - Create a Regex builder
// CREDIT 03/02/2022 Payroll from employer $200.23 // CREDIT 03/03/2022 Suspect A $2,000,000.00 // DEBIT 03/03/2022 Ted's Pet Rock Sanctuary $2,000,000.00 // DEBIT 03/05/2022 Doug's Dugout Dogs $33.27 import RegexBuilder let fieldSeparator = /\s{2,}|\t/ let transactionMatcher = Regex { /CREDIT|DEBIT/ fieldSeparator One(.date(.numeric, locale: Locale(identifier: "en_US"), timeZone: .gmt)) fieldSeparator OneOrMore { NegativeLookahead { fieldSeparator } CharacterClass.any } fieldSeparator One(.localizedCurrency(code: "USD").locale(Locale(identifier: "en_US"))) } -
9:04 - Use Captures to extract portions of input
let fieldSeparator = /\s{2,}|\t/ let transactionMatcher = Regex { Capture { /CREDIT|DEBIT/ } fieldSeparator Capture { One(.date(.numeric, locale: Locale(identifier: "en_US"), timeZone: .gmt)) } fieldSeparator Capture { OneOrMore { NegativeLookahead { fieldSeparator } CharacterClass.any } } fieldSeparator Capture { One(.localizedCurrency(code: "USD").locale(Locale(identifier: "en_US"))) } } // transactionMatcher: Regex<(Substring, Substring, Date, Substring, Decimal)> -
10:31 - Plot twist!
private let ledger = """ KIND DATE INSTITUTION AMOUNT ---------------------------------------------------------------- CREDIT 03/01/2022 Payroll from employer $200.23 CREDIT 03/03/2022 Suspect A $2,000,000.00 DEBIT 03/03/2022 Ted's Pet Rock Sanctuary $2,000,000.00 DEBIT 03/05/2022 Doug's Dugout Dogs $33.27 DEBIT 06/03/2022 Oxford Comma Supply Ltd. £57.33 """ // 😱 -
10:53 - Use named captures
let regex = #/ (?<date> \d{2} / \d{2} / \d{4}) (?<middle> \P{currencySymbol}+) (?<currency> \p{currencySymbol}) /# // Regex<(Substring, date: Substring, middle: Substring, currency: Substring)> -
11:33 - Use Foundation's date parser
let regex = #/ (?<date> \d{2} / \d{2} / \d{4}) (?<middle> \P{currencySymbol}+) (?<currency> \p{currencySymbol}) /# // Regex<(Substring, date: Substring, middle: Substring, currency: Substring)> func pickStrategy(_ currency: Substring) -> Date.ParseStrategy { switch currency { case "$": return .date(.numeric, locale: Locale(identifier: "en_US"), timeZone: .gmt) case "£": return .date(.numeric, locale: Locale(identifier: "en_GB"), timeZone: .gmt) default: fatalError("We found another one!") } } -
11:48 - Find and replace
let regex = #/ (?<date> \d{2} / \d{2} / \d{4}) (?<middle> \P{currencySymbol}+) (?<currency> \p{currencySymbol}) /# // Regex<(Substring, date: Substring, middle: Substring, currency: Substring)> func pickStrategy(_ currency: Substring) -> Date.ParseStrategy { … } ledger.replace(regex) { match -> String in let date = try! Date(String(match.date), strategy: pickStrategy(match.currency)) // ISO 8601, it's the only way to be sure let newDate = date.formatted(.iso8601.year().month().day()) return newDate + match.middle + match.currency } -
12:45 - A zombie love story
let aZombieLoveStory = "🧟♀️💖🧠" // Characters: 🧟♀️, 💖, 🧠 -
13:01 - A zombie love story in unicode scalars
aZombieLoveStory.unicodeScalars // Unicode scalar values: U+1F9DF, U+200D, U+2640, U+FE0F, U+1F496, U+1F9E0 -
13:44 - A zombie love story in UTF8
aZombieLoveStory.utf8 // UTF-8 code units: F0 9F A7 9F E2 80 8D E2 99 80 EF B8 8F F0 9F 92 96 F0 9F A7 A0 -
14:12 - Unicode canonical equivalence
"café".elementsEqual("cafe\u{301}") // true -
14:49 - String's views are compared at binary level
"café".elementsEqual("cafe\u{301}") // true "café".unicodeScalars.elementsEqual("cafe\u{301}".unicodeScalars) // false "café".utf8.elementsEqual("cafe\u{301}".utf8) // false -
15:14 - Unicode processing
switch ("🧟♀️💖🧠", "The Brain Cafe\u{301}") { case (/.\N{SPARKLING HEART}./, /.*café/.ignoresCase()): print("Oh no! 🧟♀️💖🧠, but 🧠💖☕️!") default: print("No conflicts found") } -
15:54 - Complex scalar processing
let input = "Oh no! 🧟♀️💖🧠, but 🧠💖☕️!" input.firstMatch(of: /.\N{SPARKLING HEART}./) // 🧟♀️💖🧠 input.firstMatch(of: /.\N{SPARKLING HEART}./.matchingSemantics(.unicodeScalar)) // ️💖🧠 -
17:56 - Live transaction matcher
let timestamp = Regex { ... } // proprietary let details = try Regex(inputString) let amountMatcher = /[\d.]+/ // CREDIT <proprietary> <redacted> 200.23 A1B34EFF ... let fieldSeparator = /\s{2,}|\t/ let transactionMatcher = Regex { Capture { /CREDIT|DEBIT/ } fieldSeparator Capture { timestamp } fieldSeparator Capture { details } fieldSeparator // ... } -
18:26 - Replace field separator
let field = OneOrMore { NegativeLookahead { fieldSeparator } CharacterClass.any } -
18:55 - Use TryCapture
// CREDIT <proprietary> <redacted> 200.23 A1B34EFF ... let fieldSeparator = /\s{2,}|\t/ let field = OneOrMore { NegativeLookahead { fieldSeparator } CharacterClass.any } let transactionMatcher = Regex { Capture { /CREDIT|DEBIT/ } fieldSeparator TryCapture(field) { timestamp ~= $0 ? $0 : nil } fieldSeparator TryCapture(field) { details ~= $0 ? $0 : nil } fieldSeparator // ... } -
21:45 - Fixing the scaling issues
// CREDIT <proprietary> <redacted> 200.23 A1B34EFF ... let fieldSeparator = Local { /\s{2,}|\t/ } let field = OneOrMore { NegativeLookahead { fieldSeparator } CharacterClass.any } let transactionMatcher = Regex { Capture { /CREDIT|DEBIT/ } fieldSeparator TryCapture(field) { timestamp ~= $0 ? $0 : nil } fieldSeparator TryCapture(field) { details ~= $0 ? $0 : nil } fieldSeparator // ... }
-