-
パーソナルボイスとカスタムボイスによる音声合成技術の拡張
最新の音声合成技術の革新をアプリに導入しましょう。iOSやmacOSにカスタム音声合成や音声を統合する方法を紹介します。SSMLを使用して表現力豊かな音声合成を生成する方法や、パーソナルボイスを利用して補助的な役割を果たすコミュニケーションアプリで本人に代わって自然な声で話す方法を解説します。
関連する章
- 0:00 - Welcome
- 1:25 - Explore SSML
- 2:37 - Implement a synthesis provider
- 10:01 - Use Personal Voice
リソース
- Audio Unit
- Creating an audio unit extension
- Speech Synthesis Markup Language (SSML)
- Speech synthesis
関連ビデオ
WWDC20
-
このビデオを検索
♪ ♪
こんにちは Grantです アクセシビリティチームのエンジニアです 多くの方がAppleのプラットフォームで 音声合成を使っており 一部の方は合成音声に頼っています 音声がデバイスの利用に欠かせない 窓口になっています そのため 使用する声は 時にパーソナルなものとなります iOSで音声合成を使っている方は すでに多くの種類の声を選択できます では さらに多くの音声を 提供する方法を見ていきましょう 始めに Speech Synthesis Markup Language (SSML)とは何か カスタムボイスでイマーシブな 音声を出力する方法 そして 音声プロバイダがこれを 採用すべき理由について説明します 次に 音声合成プロバイダを導入して 音声合成と 音声体験を デバイス全体で実現する方法を説明します そして最後に パーソナルボイスについて説明します こちらは新機能となります これにより 自分の声を録音し それを基に 合成音声を生成することが可能です つまり ユーザー自身の声で 音声を合成できます では SSMLから見ていきましょう SSMLは音声テキストを表現するための W3C標準規格です SSML音声は XML形式に従い宣言し 様々なタグや属性を使って表現します これらのタグを使って速度やピッチなどの 音声プロパティを制御できます SSMLはファーストパーティの 音声合成で使用されています これにはWebkitのWebSpeechも含まれ 音声合成ソフトの標準入力となっています ではSSMLの使い方を見ていきましょう ポーズを含む フレーズの例を見てみましょう このポーズもSSMLで表現できます まず“hello”という文字列から始め SSMLのbreakタグを使って1秒間ポーズし 最後に早口の “nice to meet you!”で終わります SSMLの韻律タグを追加し rate属性を200%に設定します このSSMLを使ってAVSpeechUtterance を作成し 発話します 次に 独自の音声合成ボイスを 実装する方法を見てみましょう
そもそも 音声合成とは何でしょうか? 音声合成とは あるテキストと希望する 音声特性に関する情報をSSML形式で受け取り そのテキストの音声表現を提供するものです たとえば 素晴らしい新しい音声を有する シンセサイザーがあり それをiOS macOS iPadOSに 導入したいと仮定します 音声合成プロバイダは 独自の音声合成や 音声を 私たちのプラットフォームへ 導入することを可能にし ユーザーにシステム音声以上の パーソナル化を提供します
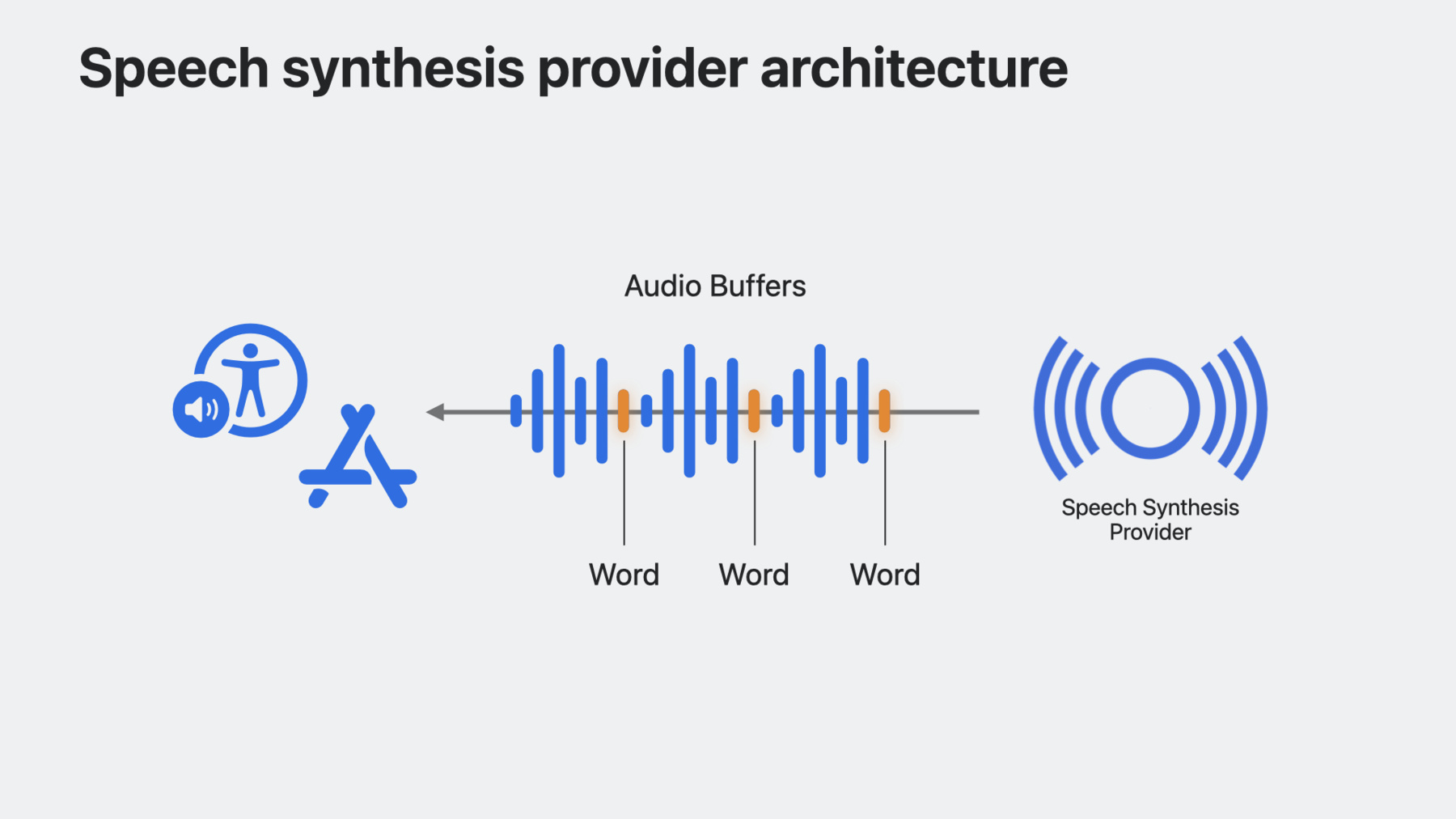
その仕組みを見てみましょう 音声合成プロバイダの音声ユニット 機能拡張はホストアプリに組み込まれ SSMLの形で 音声リクエストを受け取ります この機能拡張は SSML入力の音声をレンダリングし オプションで 音声バッファ内の単語の位置を示す マーカーを返します システムは その音声リクエストの すべての再生を管理します 音声セッションの管理は Speech Synthesis Provider フレームワークにより内部的に管理され 処理を行う必要はありません 音声合成の仕組みが分かったので 音声合成機能拡張を作ってみましょう まず XcodeでAudio Unit Extension アプリプロジェクトを作成し “Speech Synthesizer” Audio Unit Typeを選択して シンセサイザーの4文字の サブタイプ識別子と 制作者を示す 4文字の識別子を指定します Audio Unit Extensionsは 音声合成機能拡張の コアとなるアーキテクチャです これにより シンセサイザーは ホストアプリのプロセスではなく 拡張プロセスで実行可能になります
このアプリは 機能拡張が合成する 音声を選択し 購入するための シンプルなインターフェイスを提供します まず 購入可能な音声を表示する リストビューを作成します 各音声のセルには 音声名と購入ボタンが表示されます
次に リストにいくつか音声を入力します このWWDCVoiceは 音声名と 識別子を有するシンプルな構造体です
また 購入した音声を管理するための ステート変数と それらを表示するための 新しいセクションも必要です 次に 音声を購入するための 関数を作りましょう ここで 新しく購入した 音声をリストに追加し それに応じてUIを更新します AVSpeechSynthesisProviderVoice メソッドの updateSpeechVoicesに注意してください これにより シンセサイザーで 利用可能なボイスセットが変更され システムボイスセットを 再構築する必要があると アプリに知らせることができます この例では 音声のアプリ内購入を 完了した後に この呼び出しを行うことができます また 音声合成機能拡張で どの音声が利用可能か 把握する方法も必要です これは アプリグループを通して 共有されるUserDefaultsの インスタンスを作成すると可能になります アプリグループによって この音声リストを ホストアプリと 機能拡張の間で共有できます アプリグループの作成時に指定した スイート名を明示的に指定しています これにより ホストアプリと機能拡張が 同じドメインから読み込まれます 購入機能を見てみると 新しい音声の購入時に ユーザーのデフォルトを 更新する方法を実装してあります また AVSpeechSynthesizerには 利用可能な システムボイスの変更を検知する 新しいAPIがあります システムボイスのセットは ユーザーが音声を削除したり 新たにダウンロードすると更新されます availableVoicesDidChangeNotification にサブスクライブすることで これらの変更に基づいて 音声のリストを変更できます ホストアプリが完成したので 4つの主要なコンポーネントからなる オーディオユニットを入力します
最初に追加するのは シンセサイザーが どのような音声を提供するかを システムに知らせる方法です これはspeechVoicesゲッターを オーバーライドして 音声のリストを提供し 先程指定した アプリグループUserDefaultsから 読み取り 実現します 音声リストの各項目について AVSpeechSynthesisProviderVoice を米国英語に設定します 次に 合成するテキストを システムがシンセサイザーに 伝える方法が必要です synthesizeSpeechRequestメソッドは システムがテキストの合成を開始したことを 機能拡張に通知したいときに呼び出されます このメソッドの引数は SSMLと 使用する音声を保有する AVSpeechSynthesisProviderRequest のインスタンスになります 次に 音声エンジンの実装で作成した ヘルパーメソッドを呼び出します この例では getAudioBufferメソッドが リクエストで指定された音声と SSML入力に基づいて音声データを生成します また framePositionと呼ばれる インスタンス変数を0に設定し レンダーブロックが呼び出され バッファから フレームをコピーする時に レンダリングされたフレームを追跡します システムは 音声合成を停止し 現在の音声リクエストを破棄するよう シンセサイザーに信号を送る方法も必要です cancelSpeechRequestを使い 現在のバッファを破棄することで これを実現します 最後に レンダーブロックの実装が必要です レンダーブロックは 希望のframeCountで システムから呼び出されます オーディオユニットが 要求されたフレーム数を outputAudioBufferに入力します 次に ターゲットバッファへの参照と synthesizeSpeechRequest 呼び出しの際に 生成して保存したバッファへの 参照を設定します 次に フレームを ターゲットバッファにコピーします そして最後に オーディオユニットが 現在のスピーチリクエストの バッファをすべて使いきった後 actionFlags引数を offlineUnitRenderAction_Completeに 設定して レンダリングが完了して レンダリングする オーディオバッファが無いことを システムに知らせます 実際に動かしてみましょう これが私の音声合成アプリです 音声を購入し 新しい音声と 音声合成エンジンを使って 音声を合成するビューに移動します まず シンセサイザーに “hello”と入力します
合成音声:Hello Grant:次に“goodbye”と入力します
合成音声:Goodbye Grant:これで 音声合成プロバイダを導入し VoiceOverから独自のアプリまで システム全体で使用できる音声を 提供するアプリが完成しました これらのAPIを使って どんな新しい音声や text-to-speech体験ができるか楽しみです 次に パーソナルボイスと呼ばれる 新機能について説明します iOSとmacOSで デバイスの力を使って自分の声を録音し 再現できるようになりました あなたのパーソナルボイスは サーバーではなくデバイス上で生成されます この音声は 他のシステム音声と共に表示され ライブスピーチという新機能で使用できます ライブスピーチはiOS iPadOS macOS watchOSに搭載されている 音声合成機能で その場で自分の声を合成できます パーソナルボイス用の 新しいリクエスト承認APIを使用して これらの音声を使った 音声合成へのアクセスをリクエストできます パーソナルボイスの使用には 注意が必要であり 主に拡張または代替コミュニケーション アプリで使用される必要があります パーソナルボイスを使用するために 私が 作ったAACアプリをチェックしましょう このアプリには WWDCで 私が良く口にするフレーズを話すボタンと パーソナルボイスの使用を リクエストするボタンがあります AVSpeechSynthesizerの requestPersonalVoiceAuthorization APIで承認をリクエストできます 承認されると パーソナルボイスは AVSpeechSynthesisVoice APIの speechVoicesで システムボイスと一緒に表示され isPersonalVoiceという 新しいvoiceTraitで示されます
これでパーソナルボイスにアクセス可能になり 話すことができます
実際にパーソナルボイスを使ってみましょう まず “Use Personal Voice” ボタンをタップして承認を求めます 承認されると シンボルをタップして 自分の声を聞くことができます パーソナルボイス:こんにちは Grantです WWDC23へようこそ Grant:すごいですね これらの音声を皆さんのアプリでも使えます
SSMLについて説明しました 音声入力を標準化し アプリでリッチな 音声体験を構築するために SSMLを使いましょう また Appleのプラットフォームに 音声合成ソフトを実装する方法についても 話しました これにより システム全体で使える音声を提供できます 最後に パーソナルボイスを使えば 特に自分の声を失う恐れのある人々のために アプリの合成音声にパーソナルな タッチを加えることができます 皆さんがこれらのAPIを使って生み出す 体験を楽しみにしています ご視聴ありがとうございました
-
-
2:10 - SSML phrase
<speak> Hello <break time="1s"/> <prosody rate="200%">nice to meet you!</prosody> </speak> -
2:29 - SSML utterance
let ssml = """ <speak> Hello <break time="1s" /> <prosody rate="200%">nice to meet you!</prosody> </speak> """ guard let ssmlUtterance = AVSpeechUtterance(ssmlRepresentation: ssml) else { return } self.synthesizer.speak(ssmlUtterance) -
4:33 - Create a host app
struct ContentView: View { var body: some View { List { Section("My Awesome Voices") { ForEach(availableVoices) { voice in HStack { Text(voice.name) Spacer() Button("Buy") { // Buy this voice... } } } } } } var availableVoices: [WWDCVoice] { return [ WWDCVoice(name: "Screen Reader Voice", id: "com.example.screen-reader-voice"), WWDCVoice(name: "Reading Voice", id: "com.example.reading-voice") ] } } -
5:04 - Keep track of purchased voices
struct ContentView: View { @State var purchasedVoices: [WWDCVoice] = [] var body: some View { NavigationStack { List { MyAwesomeVoicesSection Section("Purchased Voices") { ForEach(purchasedVoices) { voice in NavigationLink { // Destination View } label: { Text(voice.name) } } } } } } } -
5:13 - Inform the system when available voices change
struct ContentView: View { @State var purchasedVoices: [WWDCVoice] = [] var body: some View { List { MyAwesomeVoicesSection PurchasedVoicesSection } } func purchase(voice: WWDCVoice) { // Append voice to list of purchased voices purchasedVoices.append(voice) // Inform system of change in voices AVSpeechSynthesisProviderVoice.updateSpeechVoices() } } -
5:39 - Update UI with purchased voices
struct ContentView: View { @State var purchasedVoices: [WWDCVoice] = [] var body: some View { List { Section("My Awesome Voices") { ForEach(availableVoices.filter { !purchasedVoices.contains($0) }) { voice in HStack { Text(voice.name) Spacer() Button("Buy") { purchase(voice: voice) } } } } PurchasedVoicesSection } } } -
5:46 - Save available voices into UserDefaults
struct ContentView: View { let groupDefaults = UserDefaults(suiteName: "group.com.example.SpeechSynthesizerApp")! @State var purchasedVoices: [WWDCVoice] = [] var body: some View { List { MyAwesomeVoicesSection PurchasedVoicesSection } } func purchase(voice: WWDCVoice) { // Append voice to list of purchased voices purchasedVoices.append(voice) // Write purchasedVoices to defaults updatePurchasedVoices() // Inform system of change in voices AVSpeechSynthesisProviderVoice.updateSpeechVoices() } } -
6:25 - Monitor for system voice changes
struct ContentView: View { @State var systemVoices: [AVSpeechSynthesisVoice] = AVSpeechSynthesisVoice.speechVoices() var body: some View { List { MyAwesomeVoicesSection PurchasedVoicesSection Section("System Voices") { ForEach(systemVoices.filter { $0.language == "en-US" }) { voice in Text(voice.name) } } } .onReceive(NotificationCenter.default .publisher(for: AVSpeechSynthesizer.availableVoicesDidChangeNotification)) { _ in systemVoices = AVSpeechSynthesisVoice.speechVoices() } } } -
6:53 - Override speechVoices getter
// Implement a synthesis provider public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override var speechVoices: [AVSpeechSynthesisProviderVoice] { get { } } } -
7:02 - Use UserDefaults to provide set of available voices
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override var speechVoices: [AVSpeechSynthesisProviderVoice] { get { let voices: [String : String] = groupDefaults.value(forKey: "voices") as? [String : String] ?? [:] return voices.map { key, value in return AVSpeechSynthesisProviderVoice(name: value, identifier: key, primaryLanguages: ["en-US"], supportedLanguages: ["en-US"] ) } } } } -
7:22 - Use your synthesis engine on each synthesis request
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override func synthesizeSpeechRequest(speechRequest: AVSpeechSynthesisProviderRequest) { currentBuffer = getAudioBuffer(for: speechRequest.voice, with: speechRequest.ssmlRepresentation) framePosition = 0 } } -
8:14 - Handle request cancellation
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override func synthesizeSpeechRequest(speechRequest: AVSpeechSynthesisProviderRequest) { currentBuffer = getAudioBuffer(for: speechRequest.voice, with: speechRequest.ssmlRepresentation) framePosition = 0 } public override func cancelSpeechRequest() { currentBuffer = nil } } -
8:28 - Override internalRenderBlock
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override var internalRenderBlock: AUInternalRenderBlock { return { [weak self] actionFlags, timestamp, frameCount, outputBusNumber, outputAudioBufferList, _, _ in guard let self else { return kAudio_ParamError } return noErr } } } -
8:42 - Implement the render block
public class WWDCSynthAudioUnit: AVSpeechSynthesisProviderAudioUnit { public override var internalRenderBlock: AUInternalRenderBlock { return { [weak self] actionFlags, timestamp, frameCount, outputBusNumber, outputAudioBufferList, _, _ in guard let self else { return kAudio_ParamError } // This is the audio buffer we are going to fill up var unsafeBuffer = UnsafeMutableAudioBufferListPointer(outputAudioBufferList)[0] let frames = unsafeBuffer.mData!.assumingMemoryBound(to: Float32.self) var sourceBuffer = UnsafeMutableAudioBufferListPointer(self.currentBuffer!.mutableAudioBufferList)[0] let sourceFrames = sourceBuffer.mData!.assumingMemoryBound(to: Float32.self) for frame in 0..<frameCount { if frames.count > frame && sourceFrames.count > self.framePosition { frames[Int(frame)] = sourceFrames[Int(self.framePosition)] self.framePosition += 1 if self.framePosition >= self.currentBuffer!.frameLength { break } } } return noErr } } } -
11:10 - Request authorization for Personal Voice
struct ContentView: View { @State private var personalVoices: [AVSpeechSynthesisVoice] = [] func fetchPersonalVoices() async { AVSpeechSynthesizer.requestPersonalVoiceAuthorization() { status in if status == .authorized { personalVoices = AVSpeechSynthesisVoice.speechVoices().filter { $0.voiceTraits.contains(.isPersonalVoice) } } } } } -
11:34 - Use Personal Voice
func speakUtterance(string: String) { let utterance = AVSpeechUtterance(string: string) if let voice = personalVoices.first { utterance.voice = voice syntheizer.speak(utterance) } }
-