-
Swiftのパフォーマンスの詳細
Swiftが抽象化とパフォーマンスをどのようにバランスよく両立しているかを見ていきます。考慮すべきパフォーマンス要素と、それらをSwiftが最適化する仕組みについて学ぶことができます。Swiftのさまざまな機能を紹介するとともに、それらを実装して、パフォーマンスに影響を与える可能性があるトレードオフを把握する方法を解説します。
関連する章
- 0:00 - Introduction
- 1:24 - Agenda
- 1:46 - What is performance?
- 4:31 - Low-level principles
- 4:36 - Function calls
- 8:29 - Memory allocation
- 10:34 - Memory layout
- 13:57 - Value copying
- 20:54 - Putting it together
- 21:08 - Dynamically-sized types
- 24:33 - Async functions
- 28:11 - Closures
- 30:36 - Generics
- 34:00 - Wrap up
リソース
関連ビデオ
WWDC24
WWDC19
WWDC16
-
このビデオを検索
John McCallです 今日は Swiftのパフォーマンスについて説明します プログラミング言語で作業をする際は その言語での様々な操作の パフォーマンスについて 優れた直感を持つことが重要です 多くの場合 C言語のプログラマーは この直感を持っています 良くも悪くも C言語から機械語への 変換はかなり逐語的です このようなローカル変数は スタックに割り当てられます
ヒープ割り当ては 呼び出しを行う場合のみ発生します コンパイラはレジスタへの移動や メモリの最適化など 処理を高速化するための 賢明な方法を見つけるでしょう しかし どのように コンパイルされるかについては 確信が持てる基準があります
Swiftは必ずしも単純ではありません その理由の一部は安全性に関係しています C言語の翻訳は コードが間違っていても喜んで メモリ全体に書き込んでしまいます しかしSwiftは クロージャやジェネリクスなど C言語にはない 抽象化のための多くのツールを提供します これらの抽象化は実装が容易ではなく mallocの明示的な呼び出しほど コストも明確ではありません とはいえ コードの実際の動作について 同様の直感を養えないというわけでは ありません パフォーマンスに関する作業が必要な場合 これは非常に重要です このセッションでは Swiftの低レベル パフォーマンスについて説明します まず パフォーマンスとは何を意味するのか について話します 次に 低レベルのパフォーマンスを 検討するにあたり 考慮すべき原則を紹介します 最後に Swiftの主要機能が どのように実装され それがパフォーマンスに どのように影響するかについて 詳しく見ていきます
パフォーマンスとは何でしょうか?
これはかなり深い質問です プログラムを何らかのツールにかけるだけで パフォーマンスに関する 1つの数値が 得られるのであれば 話は簡単です 例えば Safariのパフォーマンススコアは 「9.2」というように しかし 実際はそうはいきません パフォーマンスは多次元的であり 状況によって変わります 通常 パフォーマンスを気にするのは マクロ的な問題があるからです デーモンが電力を消費しすぎている クリック時のUIの動作が遅い アプリが頻繁に強制終了されるなどです このような問題を調査する場合 一般にトップダウン方式が使用されます Instrumentsなどの ツールを使用して計測し 詳しく調査すべき場所を特定します
多くの場合 コードの低レベル パフォーマンスは考慮せずに アルゴリズムの改善によって これらの問題を解決します
しかし 低レベルパフォーマンスの調査が 必要になることもあります この場合 調査対象を 実行トレースの一部分に絞り込みます アルゴリズムレベルでできることは それほどありません 時間がかかるだけです さらに先に進むには コードの実際の動作を 理解する必要があり そのためにはボトムアップの アプローチが必要となります 低レベルのパフォーマンスは 4つの検討事項に左右される傾向があります 1つ目は 最適化されていない 多数の関数呼び出し 2つ目は データの表現方法に起因する 多くの時間やメモリの浪費 3つ目は メモリの割り当てに 時間をかけ過ぎていること 4つ目は 値のコピーと破棄に 不必要に多くの時間を費やしていることです Swiftのほとんどの機能は これらのコストに影響を与えます このすべてを見ていきますが その前に 考慮事項を もう1つ付け加えさせてください Swiftは強力な最適化機能を備えています パフォーマンスの問題として 認識していない場合でも コンパイラがそれらを適切に排除します 最適化には限界があります コードの書き方は 最適化機能の処理能力に 大きな影響を与える可能性があります 説明を進めていく中で 最適化の可能性についてもお話しします パフォーマンスを考慮した プログラミングの重要な要素だからです 最適化機能に依存することに 抵抗があるのであれば 1つ提案させてください パフォーマンスがプロジェクトの 重要な部分である場合は 定期的に監視する必要があります トップダウンの調査で ホットスポットを特定したら 開発プロセスの一環として それらを測定する方法を見つけ 測定を自動化するよう努めます そうすれば 何らかの理由で 最適化を混乱させてしまった場合でも あるいは 誤って二次アルゴリズムを 追加した場合でも すぐにリグレッションを 特定することができます その後 最適化機能が 期待通りに実行されているかを確認します
以上を踏まえて 低レベルパフォーマンスの 4つの原則を詳しく見ていきましょう 1つ目は関数呼び出しです
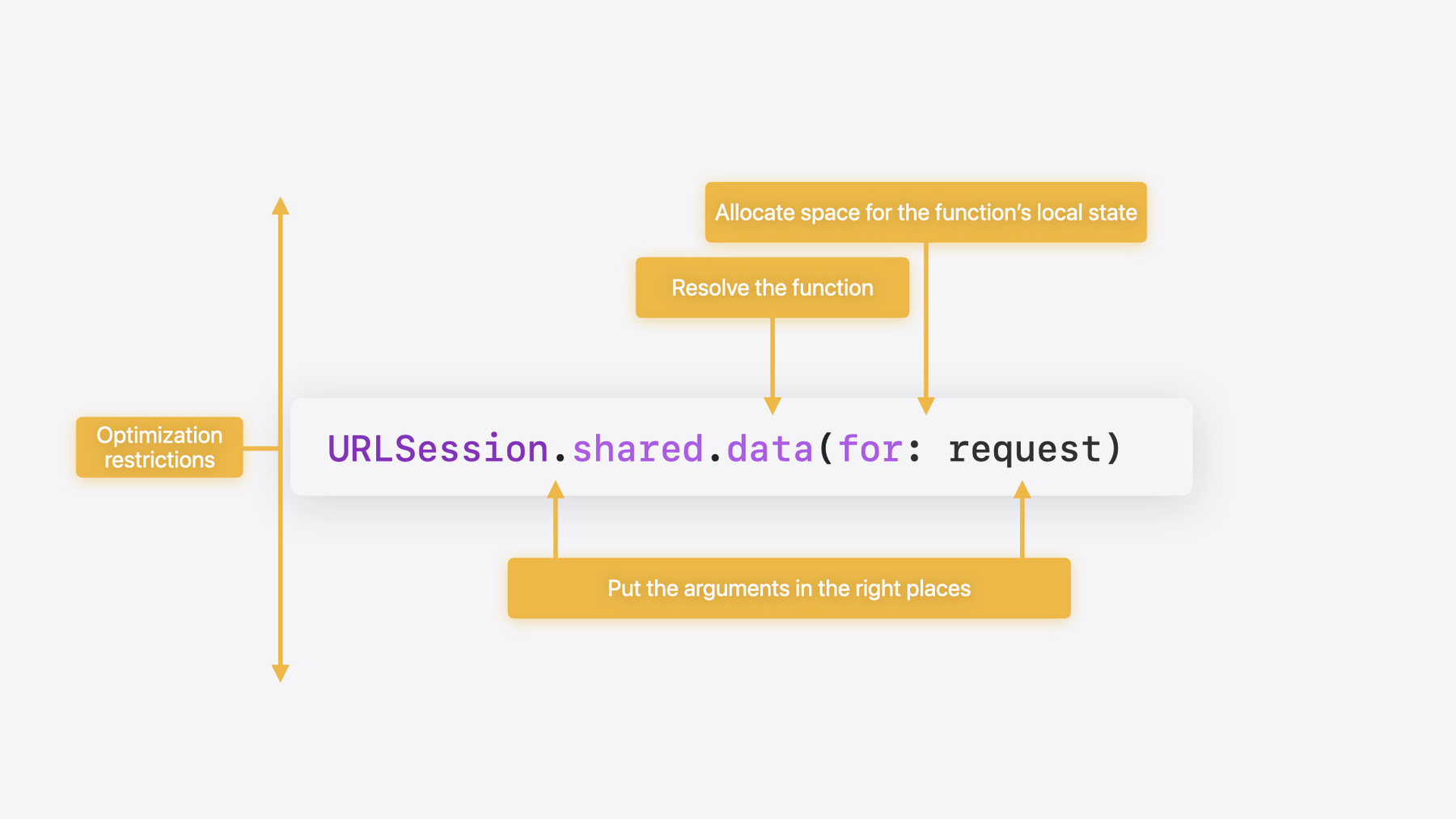
関数呼び出しには 4つのコストがあります そのうちの3つは私たちが行うことです まず 呼び出しの引数を 設定する必要があります
また 呼び出す関数のアドレスを 解決しなければなりません さらに 関数のローカル状態用の領域を 確保する必要があります
4つ目は私たちが行うことではありません 呼び出し元と 呼び出される関数の両方で このすべてが最適化の妨げとなる 可能性があります
これが 4つのコストです
まず 引数の受け渡しから見ていきましょう 2つのレベルがあります 最も低いレベルでは 呼び出しを行う時に 呼び出し規約に従って適切な場所に 引数を配置する必要があります 現代のプロセッサでは これらのコストは レジスタ名の変更によって隠されるので 実際には大きな違いはありません
しかし より高いレベルでは 場合によっては 関数の所有権規約に合わせて コンパイラが値のコピーを 追加する必要が生じます これは 呼び出し元または呼び出し先で 余分な保持や解放としてプロファイルに 表示されることがよくあります これについては後ほど説明します 次の2つのコストである 関数の解決と最適化への影響は どちらも同じ問題に行き着きます 呼び出す関数が コンパイル時に 正確にわかっているかということです わかっている場合は 呼び出しで 静的ディスパッチを使用します それ以外なら動的ディスパッチを使用します 静的ディスパッチの方が効率的であり プロセッサレベルで少し高速になります さらに重要なのは コンパイラが関数定義を確認できる場合 インライン化や Generic Specializationなど コンパイル時に可能な最適化が 多数あることです 一方 動的ディスパッチでは ポリモーフィズムなど 抽象化のための強力なツールを使用できます
Swiftでは 特定の種類の呼び出しでのみ 動的ディスパッチが使用されます これは 呼び出している 宣言を見ればわかります
この例では プロトコル型の値を 更新する呼び出しがあります これがどのような呼び出しかは メソッドの宣言場所によって決まります
プロトコル本文で宣言されているなら プロトコル要件であり その呼び出しでは 動的ディスパッチが使用されます
プロトコル拡張で宣言されている場合は 呼び出しで静的ディスパッチが使用されます これは意味的にもパフォーマンスの面でも 非常に重要な違いです
関数呼び出しの最後のコストは ローカル状態用のメモリの割り当てです この関数を実行するには ある程度のメモリが必要です これは通常の同期関数なので Cスタックにメモリが割り当てられます Cスタックに領域を確保するには スタックポインタから減算します
これをコンパイルすると 関数の開始と終了時に スタックポインタを操作する アセンブリコードが生成されます
関数に入ると スタックポインタは Cスタックを指します まず アセンブリでスタックポインタから 値を減算します ここでは 208バイトであることがわかります これにより 従来CallFrameと 呼ばれるものが割り当てられ 関数を実行するための領域が確保されます これで 関数の本体を実行できます
制御を戻す直前に スタックポインタに208バイト加算し 以前に割り当てたメモリの 割り当てを解除します
CallFrameは Cの構造体のような レイアウトを持つものと考えてください この関数のローカル状態は いずれもCallFrameの フィールドになるのが理想的です CallFrameに要素を配置するのが 理想的である理由は コンパイラは常に 関数の開始時に その減算を出力するからです 戻りアドレスなどの重要な要素を保存する 領域を作るために これが必要となります より大きな定数を減算しても 時間はかからないので 関数でメモリが必要な場合は CallFrameの一部として割り当てれば 領域がほぼ確保されます
これは 次に説明する低レベルの原則 つまり メモリ割り当てにつながります
従来 メモリは3種類あると 考えられています コンピュータにとっては 最終的にすべて 同じRAMプールから提供されますが プログラム上では 様々なパターンで 割り当てて使用します これはオペレーティングシステムにとって 重要であり ひいてはパフォーマンスの面でも 重要になります
グローバルメモリは プログラムの 読み込み時に割り当てられ 初期化されます このメモリはほぼ空いています グローバルメモリの大きな欠点は プログラムの終了まで解放されない 一定量のメモリを使用する 特定のパターンでしか機能しないことです グローバル変数や静的メンバー変数には うまく適合しますが それ以外には適合しません
スタック割り当ての例として CallFrameについて既に説明しました グローバルメモリと同様に スタックメモリも低コストですが 特定のパターンでしか機能しません この場合 メモリの範囲を 指定する必要があります 現在の関数内で それ以降は そのメモリを使用しないと保証する ポイントを設ける必要があります これは標準的なローカル変数に うまく適合します
最後はヒープメモリです ヒープメモリは非常に柔軟です 任意の時点で割り当てたり 割り当てを解除したりできます
この柔軟性により 他の2種類のメモリに比べて 割り当てと割り当て解除に かなりのコストがかかります
ヒープはクラスインスタンスのような 明確な目的で使用されます また 強力な静的ライフタイム制約がなく 他のメモリを使用する理由がない場合も 一部の機能でヒープが使用されます
多くの場合 ヒープメモリを割り当てると そのメモリは共有所有権を 持つことになります つまり 同じメモリへの複数の独立した 参照が存在するということです Swiftでは これらの割り当ての有効期間を 参照カウントで管理します
Swiftでは 参照カウントの インクリメントを「保持」と呼び 参照カウントのデクリメントを 「解放」と呼びます
さて メモリの割り当てについて 説明しました 次に Swiftでそのメモリを使用して 値を格納する方法を説明します これは「メモリレイアウト」と呼ばれます
Swiftに関するほとんどの会話では 値について話す時に メモリ内のどこに何が 格納されているかを問わず 上位概念について話します
例えば この初期化の後 この変数の値は 2つのdoubleの配列になると 言うことがあります
メモリ内の状態について 話す必要がある時にも 「値」という単語を 使用する場合があります 混乱を招きそうなので 今回は代わりに より専門的な「表現」という単語を 使用することにします 値の表現は その値がメモリ内で どのように配置されるかを示します この変数配列は 現在 2つのdouble値の表現で 初期化されている バッファオブジェクトへの 参照を保持するメモリの名前です
表現の中で どのポインタもたどらずに 取得できる部分だけを表す 「インライン表現」という言葉も 使用します この変数配列のインライン表現は 単一のバッファ参照であり そのバッファの実際の内容は 無視されます 標準ライブラリのMemoryLayout型は インライン表現を測定します 配列の場合 8バイトであり 64ビットポインタ1つ分のサイズです
さて Swiftのすべての値は 何らかのコンテキストに含まれています ローカルスコープには ローカル変数 中間結果など そのスコープ内で使用される すべての値が含まれます 構造体とクラスには すべての ストアドプロパティが含まれます 配列と辞書には バッファなどを介して そのすべての要素が 含まれます
また Swiftのすべての値が型を持ちます
値の型は メモリ内での 値の表現を示します これにはインライン表現も含まれます 値のコンテキストは インライン表現を保持する メモリの提供元を示します
どのようになるのか この例で見てみましょう この配列はローカル変数です 配列の値が ローカルスコープに含まれています
ローカルスコープでは 可能であれば関数の CallFrameにインライン表現を配置します ここではそれが可能なので このCallFrameのどこかに DoubleのArrayのインライン表現用の 領域が確保されます
DoubleのArrayのインライン表現は どのようなものでしょうか Arrayは構造体であり 構造体のインライン表現は すべてのストアドプロパティの インライン表現です 標準ライブラリのソースコードを見ても わかりづらいかもしれないので 種明かしをしておきます 結局のところ Arrayには ストアドプロパティが1つしかなく それはクラス参照です クラス参照はオブジェクトへの ポインタに過ぎません
実際には このCallFrameには そのポインタが格納されているだけです
Swiftでは 構造体 タプル 列挙型は いずれもインラインストレージを使用します これらに含まれるものはすべて 通常は宣言された順序で コンテナのインラインにレイアウトされます
クラスとアクターはアウトオブライン ストレージを使用します これに含まれるものは全部 オブジェクトのインラインにレイアウトされ コンテナにはオブジェクトへの ポインタだけが格納されます この違いはパフォーマンスに 大きな影響を与えます それを説明するために 最後の低レベルの原則である 値のコピーについて説明します Swiftには「所有権」と呼ばれる 基本概念があります 値の所有権は その値の表現を管理する 責任を意味します
Arrayのインライン表現は バッファオブジェクトへの 参照だと確認しました このような参照は 参照カウントを使用して管理されます コンテナがArrayの値の 所有権を持つということは コンテナに値を格納する一環として 基礎となる配列バッファが 保持されているという 不変性があることを意味します コンテナは最終的に 保持と解放のバランスをとる 役割を担います
少なくとも コンテナがなくなる時 この処理が行われる必要があります この例では コンテナは ローカルスコープであり 変数がスコープ外になると オブジェクトが解放されます
Swiftでの値や変数の使用は 何らかの形でこの所有権システムと 相互作用します これはメモリ安全性の重要な部分です 所有権の相互作用は 主に3つあります 値の消費 値の書き換え 値の借用です
値の消費は その表現の所有権を 別の場所に移転することを意味します 値を消費するために当然必要となる 最も重要な操作は メモリに値を代入することです
この例で見てみましょう 変数を初期化するには 初期値の所有権をその変数に 移転する必要があります
場合によっては コピーなしで実行できます この例では 変数の初期値は 配列リテラルであり 新しい独立した値が生成されます Swiftでは その値の所有権を 直接変数に移転できます
2つ目の変数を1つ目の変数の値で 初期化する場合も 値の所有権をその新しい変数に 移転する必要があります しかし 初期値式は当然ながら 新しい値を生成するわけではありません 既存の変数を参照するだけです その変数から値を 窃取することはできません 他にも用途がある可能性があるからです
独立した値を取得するためには 古い変数の現在の値を コピーする必要があります この値は配列であるため 値のコピーはバッファの保持を意味します
これは頻繁に最適化されるものです 元の変数がもう使用されていないことを コンパイラが確認できる場合は コピーなしで ここに値を移すことができます
consume演算子を使用して これを明示的に要求することもできます 変数が明示的に消費されるこの時点を 過ぎてから変数を使おうとすると Swiftでエラーが発生し そこにはもう値がないことが通知されます
値を使用する 2つ目の方法は書き換えです 値の書き換えは 可変変数に格納されている 現在の値の所有権を一時的に 取得することを意味します 消費との重要な違いは 変数がその後も値の所有権を持つことが 求められる点です
このように値を書き換える メソッドを呼び出すと 現在変数にある値の所有権を そのメソッドに 移転することになります Swiftでは 呼び出しの間は 他の方法で変数を同時に 使用することができません
メソッドが完了すると 新しい値の所有権が 変数に戻されます これにより 変数が値の所有権を持つという 不変性が維持されます
値を使用する最後の方法は 値の借用です 値の借用とは 他の誰も値の消費や 書き換えを行えないと表明することです 値の読み取りだけを行う場合は この方法を使用します 気にするべきは 他の人がその値を変更したり 破棄したりしないかだけです
引数の受け渡しは 通常は借用するだけでよい 最も一般的な状況の1つです 配列をprintに渡す場合 余分な作業を行わずに 情報を渡すだけでよいのが 理想的です しかし Swiftで 引数を借用する代わりに 引数を防御的にコピーすることが 必要な状況もあります 値を借用するために Swiftでは値の書き換えや消費の試みが 同時に行われていないことを 証明する必要があります この単純な例では それを確実に行うことができます より複雑な例では 難しい場合もあります 例えば ストレージがクラスプロパティに 含まれている場合 同時にプロパティが 変更されていないことを証明するのは 簡単ではありません 防御的コピーの追加が必要な場合もあります これは Swiftが積極的に 改善を進めている領域です 最適化機能を強化すると共に コピーすることなく 値を明示的に 借用できる新しい機能を取り入れています
値のコピーとは 実際にはどういうことでしょうか 値のコピーは 値のインライン表現に依存します 値のコピーとは インライン表現をコピーし 独立した所有権を持つ新しい インライン表現を取得することです
つまりクラスの値のコピーは 参照の所有権を コピーするということであり 参照先のオブジェクトを 保持することになります 構造体の値のコピーは 構造体のすべてのストアドプロパティの 再帰的コピーを意味します
インラインとアウトオブラインの どちらのストレージを選ぶかには トレードオフが伴います インラインストレージは ヒープにメモリを確保しなくて済むため 小さな型に最適です 大きな型では コピー回数が多い場合に コストがパフォーマンスを 下げる場合があります 最適なパフォーマンスを得るための 厳格なルールはありません
大きな構造体のコピーのコストは 2つの部分に分かれています まず 値型のコピーでは 多くの場合 ビットをコピーするだけではありません この3つのストアドプロパティは オブジェクト参照を使用して表現されており 構造体をコピーする時に これらの参照を保持する必要があります これをクラスにした場合は コピーする時にクラスオブジェクトを 保持しなければなりません しかし 構造体としてコピーしても 実際にはこの3つのフィールドを 保持することになります
また この値の各コピーには 全ストアドプロパティ用の 独自のストレージが必要になります そのため この値を何度もコピーすることが 予想される場合 使用するメモリの量が増えることがあります 代わりに この型で アウトオブラインストレージを使用すると どのコピーも 同じオブジェクトを参照するので メモリが再利用されます ここでも厳格なルールはありませんが ルールについて考える必要があります
Swiftでは 値セマンティクスを持つ型を 記述することが推奨されます 値セマンティクスとは 値のコピーがコピー元と無関係なように 動作することです 構造体はこのように動作しますが 常にインラインストレージを使用します クラス型はアウトオブラインストレージを 使用しますが 参照セマンティクスを持ちます アウトオブラインストレージと 値セマンティクスの両方を使用する 1つの方法として クラスを構造体で ラップし コピーオンライトを使用します 標準ライブラリでは Array、Dictionary、Stringなど Swiftの基本的なすべてのデータ構造で この手法を使用しています
ここまで 4つの基本原則の説明に 多くの時間を費やしてきました そして これらの原則が 構造体 クラス 関数などのSwiftの基本機能に どのようにつながるのかを確認しました 次に これらをまとめて Swiftの高レベルの機能について説明します まず 動的サイズの型から見ていきます Cの構造体は常に一定サイズですが Swiftの型は実行時にサイズが 決定する場合があります これは2つのケースで発生します
第1に FoundationのURLなど SDKの多くの値型は 将来のOSアップデートで ストアドプロパティを 追加および変更する権利を有します これは レイアウトに関する物事を コンパイル時に 不明として扱う必要があることを意味します
第2に 通常 ジェネリック型の 型パラメータは 可能な表現のどの型にでも 置き換えることができるため やはりそのレイアウトを 不明として扱う必要があります
型パラメータにクラスの制約がある場合 この2番目のルールには例外があります この例ではクラス型の表現が必要です つまり 常にポインタが必要になります この制約を受け入れることができる場合は ジェネリック置換が有効ではなくても より効率的なコードになる可能性があります
次にSwiftで コンパイラが型の表現を 静的に認識していない場合は メモリのレイアウトと割り当てを どのように処理するのでしょうか それは値を格納するコンテナの 種類によって異なります ほとんどのコンテナでは 実行時にレイアウトを行うことができます 例えば このConnection構造体には URLが含まれています URLのレイアウトは 静的に認識されていないため Connectionのレイアウトも 静的に認識することはできません しかし それは構いません これはConnectionを含む側の 問題になります コンパイラは最初の 動的サイズのプロパティへの 到達までConnectionの 静的なレイアウトを認識しています 残りの部分はこのプログラムが 型のレイアウトを初めて必要とする時に Swiftランタイムによって 動的に設定されます
URLが最終的に24バイトになる場合 コンパイラが静的に認識している状態で レイアウトするのとまったく同様に Connectionは実行時にレイアウトされます コンパイラは定数を使用できるのではなく サイズとオフセットを 動的に読み込む必要があります
ただし コンテナによってはサイズが 一定でなければならないものもあります このような場合 コンパイラは コンテナ用のメイン割り当てとは別に 値用のメモリを割り当てる必要があります
例えば コンパイラは一定量の グローバルメモリしか要求できません URLのような型の グローバル変数を作成すると コンパイラはポインタ型の グローバル変数を作成します そのグローバル変数に 初めてアクセスした時に イニシャライザの遅延実行の一環として ヒープ上にその変数用の領域の 遅延割り当ても行われます
CallFrameもサイズが 一定である必要があるため ローカル変数でも同様のことが行われます
CallFrameにはURLへの ポインタが格納されます 変数がスコープに入ると 関数はそれを動的に割り当て スコープ外になったら 解放する必要があります
ただし ローカル変数には スコープが設定されているため この割り当ては引き続き Cスタック上で実行できます 関数に入る時に 通常どおりCallFrameを割り当てます
変数がスコープに入った時点で 変数のサイズ分 スタックポインタから また減算するだけです
変数がスコープ外になったら スタックポインタを以前の状態に リセットできます
ここまで 同期関数について 説明してきました 非同期関数はどうでしょうか
非同期関数の中心的な考え方は Cのスレッドは貴重なリソースであり ブロックだけを目的にスレッドを 保持すると そのリソースを有効に 活用できないというものです そのため 非同期関数は 2つの特別な方法で実装されます 1つ目は Cスタックとは別のスタックに ローカル状態を保持することです 2つ目は 非同期関数を実行時に 複数の関数に分割することです
非同期関数の例を見てみましょう
この関数には一時停止の可能性がある ポイント(await)が1つあります
これらのローカル関数は 一時停止ポイントを越えて使用されるため Cスタックに保存できません
先ほど説明したように 同期関数では スタックポインタから減算することで Cスタック上にローカルメモリを確保します
非同期関数も 概念的には同様に動作しますが 連続する大きなスタックから 割り当てるわけではありません
代わりに 非同期タスクが 1つ以上のメモリスラブを保持します
非同期関数は 非同期スタックに メモリを割り当てる必要がある時に タスクにメモリを要求します スタックは現在のスラブから その要求を満たそうとします 可能であれば問題ありません
タスクはスラブのその部分を 使用済みとしてマークして関数に渡します
しかしスラブの大部分が占有されている場合 割り当てられない可能性があります その場合 タスクはmallocで 新しいスラブを割り当てる必要があり
割り当てはそこから行われます
いずれの場合も 割り当て解除によって メモリをタスクに戻すと そのメモリは未使用としてマークされます
このアロケータは単一のタスクでのみ 使用され スタックの規律を使用するため 一般に mallocよりもかなり高速です 呼び出しのオーバーヘッドが少し 大きくなるだけで 全体的な パフォーマンスプロファイルは 同期関数とほぼ同じです
非同期関数を実際に実行するには 一時停止の可能性がある ポイント間のギャップを埋める 部分関数に 分割する必要があります この例では 関数にawaitが1つあるため 2つの部分関数に分割することになります
最初の部分関数は 元の関数に入ることから始まります 配列が空の場合 非同期呼び出し元に制御を戻します それ以外の場合は 最初のタスクを取り出し それを待機します もう1つの部分関数は awaitの後の処理を行います まず 待機していたタスクの結果を 出力配列に追加し ループの続行を試みます タスクがなくなると 非同期呼び出し元に戻ります それ以外の場合は ループバックして 次のタスクを待機します
ここで重要なのは Cスタック上には最大で 1つの部分関数しか存在しないことです
1つの部分関数に入り 一時停止の可能性がある次のポイントまで 通常のC関数と同様に実行します 部分関数が 一時停止ポイントを 越える必要のない ローカル状態を要する場合は CのCallFrameに 割り当てることができます
その時点で 部分関数は 次の部分関数を末尾呼び出しします CallFrameがCスタックから消え 次のフレームが割り当てられます
その部分関数は 一時停止の可能性がある ポイントに到達するまで実行されます
タスクが一時停止する必要がある場合は Cスタック上で通常どおり制御を戻し スレッドを他の処理に すぐに再利用できるように 通常は同時実行ランタイムに 直接送信されます
これまでの例では 常にfunc宣言を示してきました クロージャはどのように機能し ローカル 割り当てにどう影響するのでしょうか
クロージャは常に 関数型の値として渡されます この関数は 非エスケープ関数を 引数として受け取ります Swiftの関数値は 常に関数ポインタと コンテキストポインタのペアになります Cの用語では この関数シグネチャは このようになります
Swiftの関数値の呼び出しでは 関数ポインタを呼び出し 暗黙の追加引数として コンテキストポインタを渡します
1つ外側のスコープから値を取り込む クロージャ式では それらの値をコンテキストに パッケージ化する必要があります その機能は 生成する必要がある 関数値の種類によって異なります この例では 関数は非エスケープ関数です そのため 呼び出しの完了後に 関数値が使用されることはありません つまり 関数値は メモリ管理されている必要はなく スコープが設定された割り当てで コンテキストを割り当てられます
したがって コンテキストは 取り込まれた値を含む 単純な構造体になります
コンテキストをスタックに 割り当てることができ そのアドレスがsumTwiceに渡されます
クロージャ関数では ペアのコンテキストの 型がわかっているので そこから必要なデータを 取り出すことができます エスケープクロージャの場合は異なります クロージャが 呼び出し中だけ使用されるのかどうか わからなくなっています そのため コンテキストオブジェクトを ヒープに割り当て 保持と解放で管理する必要があります
コンテキストは 基本的にはSwiftの匿名 クラスのインスタンスと同様に動作します
Swiftでは クロージャ内の ローカル変数を参照する時に その変数を参照で取得します これにより 変数に変更を加え 元のスコープで確認できるようになります その逆も同様です
変数が非エスケープクロージャでのみ 取得される場合 変数の有効期間は変わりません そのため クロージャは 変数の割り当てへの ポインタを取得するだけで これを処理できます
しかし 変数がエスケープクロージャで 取得される場合は クロージャが存続している限り 変数の 有効期間が延長される可能性があります
そのため 変数をヒープに割り当てる 必要があり クロージャコンテキストは そのオブジェクトへの参照を 保持する必要があります
最後にジェネリクスについて説明します
この関数はデータモデルに対して ジェネリックです この型のレイアウトが 静的に不明であることと 様々なコンテナでの処理については 既に説明しました プロトコル制約の機能については まだ説明していません Swiftでは プロトコル要件を使用する この呼び出しを 実際にはどのように実行するのでしょうか
Swiftのプロトコルは プロトコルの 各要件に対応する関数ポインタのテーブルで 実行時に表現されます このテーブルは Cではこのようになります
プロトコル制約がある時は常に 適切なテーブルへのポインタを渡します
このようなジェネリック関数では 型テーブルとwitnessテーブルが 追加の隠しパラメータになります 実行時のこのシグネチャのすべての要素は Swiftの元のシグネチャの要素に 直接対応します
プロトコル型の値を扱う時は異なります この例では この関数の柔軟性を高めることで 配列の各要素に異なる型の データモデルを指定できるようにしました ただし これは実行効率と トレードオフの関係にあります
AnyDataModelのようなプロトコルの インライン表現は Cではこのようになります 値のストレージと 値の型とその適合性を記録する フィールドがあります
これは固定サイズの型にする必要があります 様々な型のデータモデルをサポートするため この表現はサイズを変更できません 値のストレージをどれだけ大きくしても そこに収まらないデータモデルになる 可能性があります 対処法を説明します
Swiftでは 3ポインタの 任意のバッファサイズを使用します プロトコル型に格納された値が そのバッファに収まる場合は インラインでそこに配置されます それ以外の場合は ヒープ上に値用の領域が確保され そのポインタがバッファに格納されます
これらの関数シグネチャはよく似ていますが 実際には 大きく異なる特性があります 最初の関数は データモデルの 同種配列を受け取ります これらのデータモデルは 効率的に配列に収められます 型情報は 個々の最上位の引数として 関数に一度だけ渡されます
関数がどの型で呼び出されるかを 呼び出し元が認識していれば 関数を特殊化できます ここでは 既知の型の配列に対して 関数を呼び出しています 最適化機能によって 呼び出しを 簡単にインライン展開することも この引数の型で動作する 関数の特別なバージョンを 生成することもできます これにより updateの呼び出しが MyDataModelの適合性で 実装に直接送信されるようになり ジェネリクスに関連する 抽象化のコストが排除されます
2番目の関数は データモデルの 異種混合配列を受け取ります こちらの方が柔軟です 様々な型のデータモデルがある場合は これが必要になると思います ただし 配列の各要素が 独自の動的な型を持つようになり 配列内に値が密集しなくなります
実際にこれを最適化するのも さらに難しくなります コンパイラは データが配列に流れ込み 関数で使用される方法について 完全に推論しなければなりません パフォーマンスが完全に 損なわれるわけではありませんが この場所でのコンパイラの支援が かなり減ることになります このセッションの締め括りとして お伝えしたいことがあります 私が伝えたいのは 「プロトコル型を使用するな」 ということではありません このセッションでは 様々なコストを取り上げました 確かにコストは伴いますが それに見合う価値があります 抽象化はパワフルで便利なツールです ぜひ活用してください Swiftコードのパフォーマンスに対する 直感を養う上で このセッションの情報が お役に立てば幸いです ご視聴ありがとうございました
-
-
0:24 - An example C function, with self-evident allocation
int main(int argc, char **argv) { int count = argc - 1; int *arr = malloc(count * sizeof(int)); int i; for (i = 0; i < count; ++i) { arr[i] = atoi(argv[i + 1]); } free(arr); } -
0:50 - An example Swift function, with a lot of implicit abstraction
func main(args: [String]) { let arr = args.map { Int($0) ?? 0 } } -
4:39 - An example of a function call
URLSession.shared.data(for: request) -
6:30 - A Swift function that calls a method on a value of protocol type
func updateAll(models: [any DataModel], from source: DataSource) { for model in models { model.update(from: source) } } -
6:40 - A declaration of the method where it's a protocol requirement using dynamic dispatch
protocol DataModel { func update(from source: DataSource) } -
6:50 - A declaration of the method where it's a protocol extension method using static dispatch
protocol DataModel { func update(from source: DataSource, quickly: Bool) } extension DataModel { func update(from source: DataSource) { self.update(from: source, quickly: true) } } -
7:00 - The same function as before, which we're now talking about the local state within
func updateAll(models: [any DataModel], from source: DataSource) { for model in models { model.update(from: source) } } -
7:18 - Partial assembly code for that function, showing instructions to adjust the stack pointer
_$s4main9updateAll6models4fromySayAA9DataModel_pG_AA0F6SourceCtF: sub sp, sp, #208 stp x29, x30, [sp, #192] … ldp x29, x30, [sp, #192] add sp, sp, #208 ret -
7:59 - A C struct showing one possible layout of the function's call frame
// sizeof(CallFrame) == 208 struct CallFrame { Array<AnyDataModel> models; DataSource source; AnyDataModel model; ArrayIterator iterator; ... void *savedX29; void *savedX30; }; -
10:50 - A line of code containing a single variable initialization
var array = [ 1.0, 2.0 ] -
11:44 - Using the MemoryLayout type to examine a type's inline representation
MemoryLayout.size(ofValue: array) == 8 -
12:48 - The variable initialization from before, now placed within a function
func makeArray() { var array = [ 1.0, 2.0 ] } -
15:42 - Initializing a second variable with the contents of the first
func makeArray() { var array = [ 1.0, 2.0 ] var array2 = array } -
16:27 - Taking the value of an existing variable with the consume operator
func makeArray() { var array = [ 1.0, 2.0 ] var array2 = consume array } -
16:58 - A call to a mutating method
func makeArray() { var array = [ 1.0, 2.0 ] array.append(3.0) } -
17:40 - Passing an argument that should be borrowable
func makeArray() { var array = [ 1.0, 2.0 ] print(array) } -
18:10 - Passing an argument that will likely have to be defensively copied
func makeArray(object: MyClass) { object.array = [ 1.0, 2.0 ] print(object.array) } -
19:27 - Part of a large struct type
struct Person { var name: String var birthday: Date var address: String var relationships: [Relationship] ... } -
21:22 - A Connection struct that contains a property of the dynamically-sized URL type
struct Connection { var username: String var address: URL var options: [String: String] } -
21:40 - A GenericConnection struct that contains a property of an unknown type parameter type
struct GenericConnection<T> { var username: String var address: T var options: [String: String] } -
21:51 - The same GenericConnection struct, except with a class constraint on the type parameter
struct GenericConnection<T> where T: AnyObject { var username: String var address: T var options: [String: String] } -
22:27 - The same Connection struct as before
struct Connection { var username: String var address: URL var options: [String: String] } -
23:23 - A global variable of URL type
var address = URL(string: "...") -
23:42 - A local variable of URL type
func workWithAddress() { var address = URL(string: "...") } -
25:02 - An async function
func awaitAll(tasks: [Task<Int, Never>]) async -> [Int] { var results = [Int]() for task in tasks { results.append(await task.value) } return results } -
28:21 - A function that takes an argument of function type
func sumTwice(f: () -> Int) -> Int { return f() + f() } -
28:30 - A C function roughly corresponding to the Swift function
Int sumTwice(Int (*fFunction)(void *), void *fContext) { return fFunction(fContext) + fFunction(fContext); } -
28:47 - A function call that passes a closure expression as a function argument
func sumTwice(f: () -> Int) -> Int { return f() + f() } func puzzle(n: Int) -> Int { return sumTwice { n + 1 } } -
29:15 - C code roughly corresponding to the emission of the non-escaping closure
struct puzzle_context { Int n; }; Int puzzle(Int n) { struct puzzle_context context = { n }; return sumTwice(&puzzle_closure, &context); } Int puzzle_closure(void *_context) { struct puzzle_context *context = (struct puzzle_context *) _context; return _context->n + 1; } -
29:34 - The function and its caller again, now taking an escaping function as its parameter
func sumTwice(f: @escaping () -> Int) -> Int { return f() + f() } func puzzle(n: Int) -> Int { return sumTwice { n + 1 } } -
29:53 - A closure that captures a local variable by reference
func sumTwice(f: () -> Int) -> Int { return f() + f() } func puzzle(n: Int) -> Int { var addend = 0 return sumTwice { addend += 1 return n + addend } } -
30:30 - Swift types roughly approximating how escaping variables and closures are handled
class Box<T> { let value: T } class puzzle_context { let n: Int let addend: Box<Int> } -
30:40 - A generic function that calls a protocol requirement
protocol DataModel { func update(from source: DataSource) } func updateAll<Model: DataModel>(models: [Model], from source: DataSource) { for model in models { model.update(from: source) } } -
31:03 - A C struct roughly approximating a protocol witness table
struct DataModelWitnessTable { ConformanceDescriptor *identity; void (*update)(DataSource source, TypeMetadata *Self); }; -
31:20 - A C function signature roughly approximating how generic functions receive generic parameters
void updateAll(Array<Model> models, DataSource source, TypeMetadata *Model, DataModelWitnessTable *Model_is_DataModel); -
31:36 - A function that receives an array of values of protocol type
protocol DataModel { func update(from source: DataSource) } func updateAll(models: [any DataModel], from source: DataSource) -
31:49 - A C struct roughly approximating the layout of the Swift type `any DataModel`
struct AnyDataModel { OpaqueValueStorage value; TypeMetadata *valueType; DataModelWitnessTable *value_is_DataModel; }; struct OpaqueValueStorage { void *storage[3]; }; -
31:50 - A contrast of the two Swift function signatures from before
protocol DataModel { func update(from source: DataSource) } func updateAll<Model: DataModel>(models: [Model], from source: DataSource) { for model in models { model.update(from: source) } } func updateAll(models: [any DataModel], from source: DataSource) { for model in models { model.update(from: source) } } -
32:57 - Specialization of a generic function for known type parameters
func updateAll<Model: DataModel>(models: [Model], from source: DataSource) { for model in models { model.update(from: source) } } var myModels: [MyDataModel] updateAll(models: myModels, from: source) // Implicitly generated by the optimizer func updateAll_specialized(models: [MyDataModel], from source: DataSource) { for model in models { model.update(from: source) } }
-