-
Optimize Metal Performance for Apple silicon Macs
Apple silicon Macs are a transformative new platform for graphics-intensive apps — and we're going to show you how to fire up the GPU to create blazingly fast apps and games.
Discover how to take advantage of Apple's unique Tile-Based Deferred Rendering (TBDR) GPU architecture within Apple silicon Macs and learn how to schedule workloads to provide maximum throughput, structure your rendering pipeline, and increase overall efficiency. And dive deep with our graphics team as we explore shader optimizations for the Apple GPU shader core.
We've designed this session in tandem with “Bring your Metal app to Apple silicon Macs,” and recommend you watch that first.
For more, watch “Harness Apple GPUs with Metal” to learn how TBDR applies to a variety of modern rendering techniques.리소스
관련 비디오
WWDC23
Tech Talks
WWDC21
WWDC20
-
비디오 검색…
Hello and welcome to WWDC.
Hi, my name is Mike Imbrogno from GPU Software and welcome to "Optimize Metal Performance for Apple Silicon Macs." As you know by now, Apple GPUs are coming to the Mac for the first time and we're really excited for you to see what they can do. Apple GPUs are faster and more power efficient. Your apps are going to perform great out of the box. They support all the features of Intel-based Macs and support all the Metal features unique to Apple GPUs. This talk will show you how to optimize for the Apple GPU architecture. If you previously developed for iOS then some of the advice here today may already be familiar to you. But if you're new to Apple GPUs and want your app to stand out on Apple Silicon Macs, then this is the session for you. Before we get started, let's take a look at where this session fits in your transition to Apple Silicon Macs. On Intel-based Macs, your app runs natively. On Apple Silicon Macs, your app will run out of the box under Rosetta's highly optimized translation layer.
Under translation, your app will also be automatically opted into several Metal consistency features to ensure that they look great too. But translation and consistency features will cost you some performance, so your next step will be to re-compile your app with a new macOS SDK. To learn more about Metal consistency and translation behavior differences, please see the earlier session from my colleagues Gokhan and Sam. Once consistency issues are fixed, you're ready to focus on performance optimizations and the focus of this talk. Let's look at today's agenda. In the first section, I'll describe how to fix the top performance issues we've observed in your apps that come from not taking into account Apple's tile-based deferred rendering architecture.
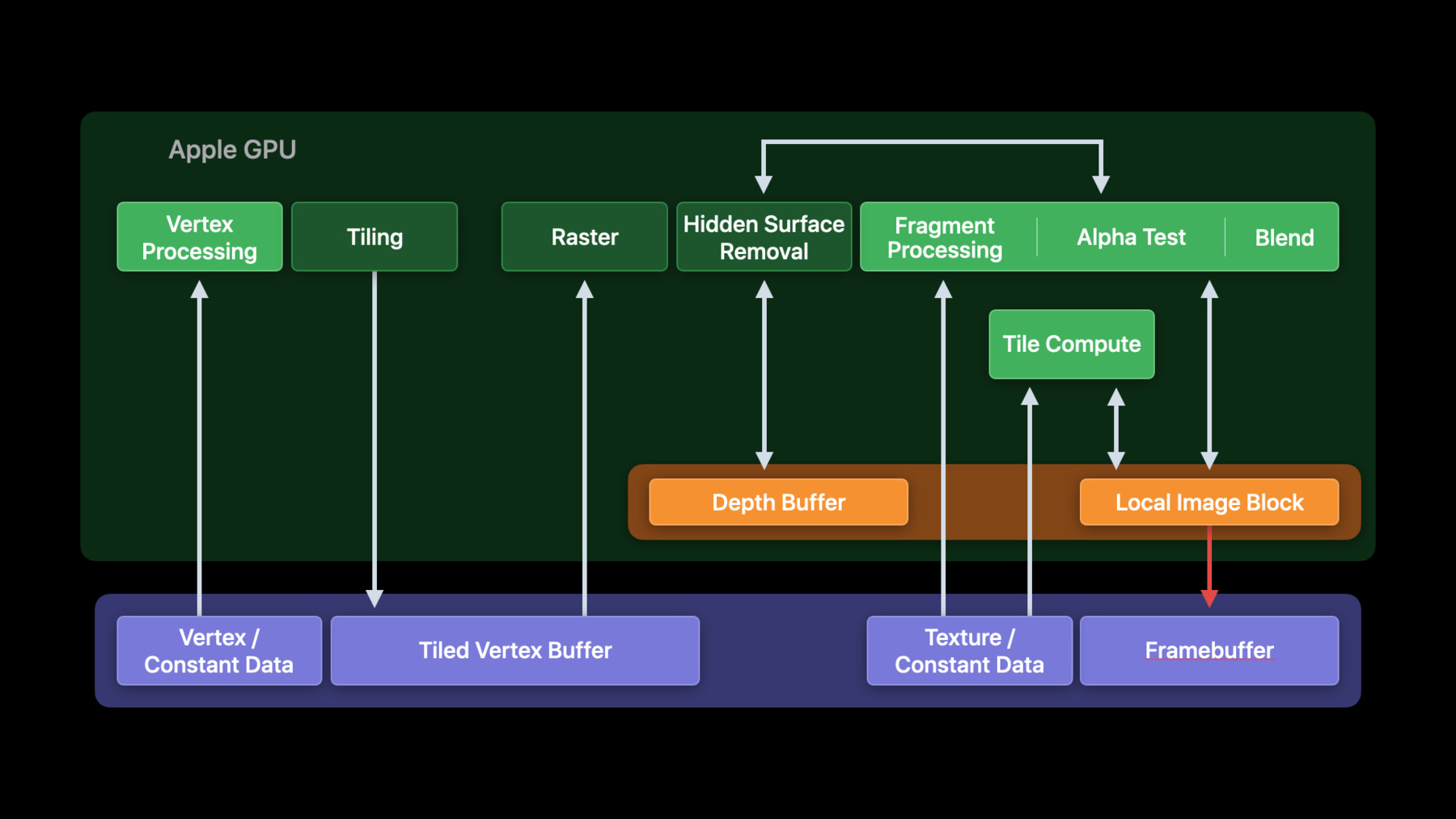
You'll learn how to schedule work efficiently, optimize pass management and minimize overdraw. In the next section, my colleague Dom will explain how to use Metal's explicit TBDR features to take your optimizations to the next level. You'll learn how to manage tile memory and use tile shaders to optimize the rendering techniques that you already use. And finally, in the last section, Dom will also show you how to optimize for the Apple GPU shader core. Let's jump in. Now this section requires a good understanding of the Apple GPU architecture, so let's start with a recap from our earlier talks. Apple-designed GPUs have a tile-based, deferred rendering architecture designed for both high performance and low power. It uses a high bandwidth, low latency tile memory to eliminate overdraw and reduce system memory traffic. The Apple GPU first processes all the geometry of a render pass in the vertex stage. It transforms and bins your geometry into screen-aligned, tiled vertex buffers that are then passed to the fragment stage.
Each tiled vertex buffer is then processed entirely on-chip as part of the fragment stage. The GPU rasterizes all primitives in a tile before shading any pixels using fast, on-chip, tile memory. Metal is designed to directly take advantage of this architecture. For example, load and store actions make explicit how render pass attachments move in and out of this tile memory.
Keep this in mind as we dive into our top performance best practices. I have three optimization categories to share with you today. The first category is workload scheduling. Apple GPUs execute different workloads concurrently to maximize utilization and minimize latency. But unnecessary dependencies across render passes can create serialization. So in this section, I'll teach you how to identify and eliminate those dependencies. The next category is minimizing system bandwidth. Apple GPUs achieve maximum performance when system memory bandwidth is minimized. So in this section, I'm also going to show you how to structure your render passes to reduce load and store traffic. And finally, I'll teach you how to minimize overdraw by maximizing the hidden surface removal capabilities of Apple GPUs. Let's start with workload scheduling. Apple GPUs process vertex, fragment and even compute workloads in parallel using independent hardware channels. Overlapping these workloads maximizes GPU utilization and minimizes execution time. So your goal is to overlap wherever possible. Metal automatically overlaps your workloads whenever there are no data dependencies between them. But data dependencies are a natural result of producing and consuming Metal resources between passes. So what we're focusing on here are the unnecessary dependencies that don't need to be there. Let's take a closer look. Apple GPUs process all vertices of a render pass before any fragments, so stages from the same pass must execute serially. But vertex processing of the next pass should overlap with fragment processing of the current pass. This even occurs across frame boundaries so often times the vertex cost is almost entirely hidden by fragment processing. But now let's take a look at what happens when you make vertex work dependent on fragment work of a previous pass.
In this example, the fragment stage of each pass is producing data into a Metal buffer or texture that is read by the next vertex stage. This will reduce your overlap and extend execution time by creating a bubble of inactivity in the vertex stage. If you see this pattern in your app, then you really want to fix it. But sometimes the pattern won't be so simple or obvious. Unnecessary dependencies often involve multiple chains of vertex, fragment and compute. In this example, the vertex stage of Render Pass 1 depends on Compute Pass 1. And Compute Pass 1 in turn depends on the fragment stage of Render Pass 0. All these holes in your GPU activity will again hurt your performance.
So now that you know what to look out for, let's talk about how false dependencies come up in practice. False dependencies are caused by sharing the same Metal resources between adjacent passes but not the data inside those resources. In this example, Render Pass 0 produces data for some later passes into the same resource that Render Pass 1 consumes, but the data is unrelated.
Metal only tracks dependencies at the resource level and not the data itself.
So one way to fix this is to use separate resources. In this example, I've separated the resources into two. So now Metal understands that there is no dependency and will schedule your work optimally. But if separating your data into different resources isn't an option, then you can also ask Metal to not track the resource at all. In this example, we're back to only one resource but it's now marked as untracked so that Metal will schedule it optimally. Untracked resources let you control if and when synchronization is required. You'll be responsible for inserting any necessary synchronization using Metal fences or events. Metal fences and events are powerful synchronization primitives that give you fine control over the scheduling of your work. To learn more about them, please see the previous Metal WWDC talks listed here. Now, the last tip for optimal workload scheduling is pass re-ordering.
You should always encode independent work as early as possible. Let's consider this example again. If Compute Pass 2 is not dependent on Compute Pass 1, then encode it ahead of Compute Pass 1 to fill in the execution gap. Likewise, if Render Pass 2 is independent of Render Pass 1, then it should also be encoded ahead of Render Pass 1. Now you might not always observe a performance improvement after reordering your passes because Metal will also reorder independent passes when it can. But Metal's visibility is limited, so it's always better to reorder explicitly. Okay, so now you know what patterns to look out for and how to fix them. But how do you actually find these bubbles? The answer is to use Metal System Trace. Metal System Trace will clearly highlight missed overlap opportunities in your apps. In this example, you can see that the vertex, fragment and compute stages do not overlap at all. This is because there are unnecessary dependencies inserted between each stage.
Here's the exact same frame at the exact same scale, but with all the unnecessary dependencies removed. Notice that there is now significantly better overlap between stages, particularly between the vertex and compute stages. Be sure to use Metal System Trace while tuning your workloads to verify that you're taking advantage of overlap between stages. So that's it for workflow scheduling.
Now let's explore how to minimize the system memory bandwidth. Apple GPUs process render pass attachments in tile storage and those attachments are moved in and out of tile memory using load and store actions. These actions consume the majority of your app's system bandwidth. Apple GPUs achieve peak performance when they are not system memory bandwidth bound, so it's important to minimize load and store traffic. Load and store actions are executed for each render pass so you can minimize load and store traffic by reducing the number of render passes used. We sometimes see apps with more render passes than necessary. Let me show you some of those common cases and how to fix them. Some apps split updates to the exact same set of attachments into separate yet adjacent passes. In this example, we have three render passes drawing to the same attachments incrementally, so that each attachment is loaded and stored multiple times. That uses a lot of system memory bandwidth. This often happens when you parallelize encoding using multiple command buffers. Metal lets you encode different passes to different command buffers in parallel to minimize CPU latency, so it's not surprising that you might be using it in this way. You might even think it's the only way to achieve encoding parallelism in Metal based on experience with other graphics APIs. In this example, the app is encoding (on the CPU timeline) the three parts of the G-Buffer into three separate command buffers. But the G-Buffer is logically a single render pass, so should be encoded that way to avoid the execution overhead of repeatedly loading and storing the same attachments. To fix this, we should instead use Metal's parallel render command encoder. With parallel render command encoders, you still achieve your goal of multi-threaded encoding but without the execution cost. In this example, I've replaced the separate command buffers with parallel sub encoders. Metal will combine those sub-encoders into a single render pass before execution, saving most of the system memory bandwidth along the way. Let's take a quick look at how the API is used.
You start by creating a parallel render command encoder. The descriptor is setup exactly how you would for a regular render pass encoder. All sub-encoders will share the exact same render pass configuration. You then create your sub-encoders. In this case, I'm creating two sub-encoders. The order in which sub-encoder commands execute is implied by the creation order. So it's important to create those up front to match your intended order. You then hand off the sub-encoders to your worker threads for async encoding. In this case, I'm dispatching asynchronously to the global queue. And once encoding is complete, you'll need to finalize the parallel encoder. In this example, I first wait for completion using my dispatch group before finalizing.
Now let's look at another common case where rendered passes are split unnecessarily.
In this example, we have a forward renderer drawing opaque geometry in the first pass and translucent objects in the second. The set of attachments are the same but the load and store actions are different. In the first pass, color and depth are written. And in the second pass, color is accumulated but depth is only loaded. We often see this pattern in apps that choose to abstract their graphics API usage and that abstraction decides when to start a new pass based on the attachments used and the actions needed. Now you don't have to change your abstraction layer to fix this. You only need to update your app logic to avoid splitting passes when only the actions change.
Here I've merged the two passes by drawing the translucent objects immediately after the opaque objects. I can do this because render passes don't need to be split when only load and store actions change. This eliminates the intermediate loads and stores and the associated system memory bandwidth. Merging also lets you store only the final color just once. We also don't need the depth attachment outside of this pass, so I set its store action to Don't Care. And in this case, the depth buffer isn't used outside the pass either, so I mark it memoryless to save on footprint too. Now let's look at another common pattern we call Attachment Ping-ponging. Apps often need to perform some intermediate rendering that is then composited onto the main scene and often have to do so repeatedly. This looks like a game of ping-pong where the app switches back and forth between two sets of attachments.
In this example, we're lighting a scene with a series of lights. Each light needs its screen space attenuation texture generated before lighting the scene.
Each light therefore creates a separate render pass, forcing the main scene attachments to load and store repeatedly. This, of course, is not great for performance.
To fix this, let's use multiple render targets. Metal lets you reference up to eight color attachments in each pass. So here I just reference both the main scene texture and the light attenuation texture together. Draws for the main scene will target the main scene texture and attenuation draws will target only its texture. This optimization avoids all the intermediate memory traffic. Only the main scene attachment is stored. The attenuation attachment is set to the Don't Care store action. The attenuation attachment isn't referenced outside this pass either so I've marked it memoryless too.
Now let's take a quick look at how to set up the pass for this example.
You start by creating the main scene attachment then create the attenuation attachment of the same size. Notice that I've marked it memoryless here. Then you create the render pass by first describing the attachment configuration.
We want to clear both the scene and attenuation textures but only store the scene texture. And finally we create Our render pass from our descriptor. That's it. Now let's look at an example of how not to clear attachments in Metal. Here's another common pattern we see for apps ported from other graphics APIs is that have a standalone clear operation. In this example, the standalone clear is translated into a separate render pass that only exists to clear that attachment. This again generates wasted system memory traffic.
The solution is to fold the clear operation into the render pass that needs it. With Apple GPUs, the clear load action only operates on tile memory and draws will also target tile memory either occluding or overwriting the cleared pixel so you don't waste bandwidth storing cleared pixels that are later over drawn. So that's a simple load action improvement. For our last tip, let's look at a similar store action improvement that you can make to your multi-sampled apps. Multi-sampling anti-aliasing is a great way to improve the image quality of your app, and on Apple GPUs it's really efficient when used correctly. Some apps however are choosing to first store the multi-sampled attachment data, and then reload it just to perform the resolve operation. In this example we store the sample data for both color and depth in the first pass and then resolve both in the second pass. Like the separate clear example, we often observe this pattern in apps ported from other graphics APIs that don't support load actions. But sample data is rarely needed off chip, so the resolve operation should really be performed as part of the previous pass. That way, we only consume system memory bandwidth for the pixels that matter and not the samples.
Also notice in this example, that I've made the MSA textures memoryless.
MSA samples are often only ever needed within a pass, so it's a great opportunity to save a lot of memory. So that's our advice for minimizing system memory bandwidth your apps. Now let's learn how to maximize hidden surface removal efficiency to minimize overdraw. Remember that Apple GPUs support hidden surface removal in hardware. The goal of HSR is to shade only visible pixels and not pixels occluded by later draws. To do this HSR categorizes fragments based on their visibility. First, we have opaque fragments which always occlude or hide everything beneath them. Then we have feedback fragments, which are generated by fragment functions containing a discard statement or that return of depth value. Alpha tested foliage falls into this category.
And finally we have translucent fragments, which blend with their background like a smoke effect would. To maximize HSR efficiency draw, each type of fragment together and then the order shown. First opaque, then feedback, and finally translucent objects. Draw ordering within each category only matters for feedback and translucent fragments. Opaque draws can be in any order but are usually sorted by your app's material system. Let's focus more on opaque fragments. Opaque fragments allow HSR to eliminate the most work because any pixel beneath them can be rejected before shading. For example when rendering the opaque triangles on the right, hidden surface removal reject all fragments belonging to the yellow and green triangles that are covered by the blue triangle. Not all opaque geometry is treated equally though. We already know that some Metal features will make your fragments non-opaque, like alpha blending and alpha testing. But some Metal features will also reduce hidden surface removal efficiency. It's OK to use those features when needed but you should be aware their performance and how to minimize the efficiency impact. Let's review them now. Metal supports writing to buffers and textures from fragment functions. These resources are not your render pass attachments. By default Metal is required to execute all such fragments even if they're occluded by later fragments. Metal does this to ensure that memory rights are deterministic at the expense of hidden surface removal. But you often don't need resource writes to occur for rejected fragments. And when that is true, Metal provides the early fragment test attribute to recover some of that efficiency. That attribute tells Metal that it's ok to not shade the fragment if it fails the depth test. You should add the early fragment test attribute to these fragment functions wherever possible. Another feature that reduces HSR efficiency is write masking. Write masks allow you to restrict which color channels of a render pass attachment are written, even when the shader writes all the channels. In this example color attachment will only have its red and green channels written by the fragment function bound to this pipeline. The blue and alpha channels will not be updated. Metal must preserve the untouched channels for correctness and on Apple GPUs, that means shading underlapping fragments to first generate those values. All the channels of the underlapping fragment are shaded even though only some channel values are actually needed. So some computation is wasted. Now if you need write masking to express your rendering technique, then by all means use it. And you probably intended to use write masking when you set it up through the Metal API. But now let me show you an example we found where write masking was not intentional.
Write masks can be setup in fragment functions too. And fragment functions that don't write any channels of an attachment are also write masking.
Consider this on-chip deferred rendering example. The G-Buffer consists of three render pass attachments: albedo normals and the light accumulation texture.
The fragment function of the G-Buffer generation phase only writes to two of those three attachments because the last attachment isn't used in this phase.
This form of write masking was unintentional. You didn't intend to reduce HSR efficiency here. To fix this, we just need to write all of the attachments.
And in this case we can just initialize the lighting attachment to zeros. So remember that unless you really need to preserve the previous values of an attachment, you should write to all render pass attachments to improve HSR efficiency. To close our discussion on hidden surface removal best practices, let's look at the role of depth pre-passes on Apple GPUs. Depth pre-pass is a commonly-used technique in existing Mac games to minimize overdraw.
You first render the scene into your depth attachment only to determine visibility.
You then render the scene again into your color attachments; testing against that visibility but without updating it. This ensures that only fragments matching the depth test are shaded in the second pass. Now if you need visibility information before your main scene renders for a particular technique, then you don't have to change your app. But if you only perform a depth pre-pass for performance, then hidden surface removal serves the same purpose on Apple GPUs. When HSR is maximized, it can reject hidden fragments as well as depth pre-passes can, but without any additional costs.
With HSR, geometry is only processed once. An HSR doesn't require the depth attachment to be stored or even have memory backing at all. It also avoids a correctness artifact called z-fighting where the depth calculation of both passes slightly mismatch. For more information on z-fighting, please see this year's Apple Silicon Mac porting session. So that concludes our discussion on how to minimize overdraw with hidden surface removal. Now my colleague Don will introduce you to even more advanced optimization techniques.
Hey, thanks Mike. In the first part of this video we've seen some performance optimization techniques for Apple GPUs that require some relatively small changes in your use of the Metal API. In this section, instead, we're going to discuss further optimization opportunities based on Metal features that are specific to Apple GPUs, such as tile shaders and programmable blending.
Let's start talking about how to optimize deferred shading on Apple GPUs.
Deferred shading is a lighting solution commonly used in several game engines. As a quick recap, in deferred shading, rendering is split in two passes.
First, we draw all the scene geometry to compute some per-pixel material properties. In this case, albedo, normals,and surface roughness are stored in three different attachments. That's what we call G-Buffer. Then in the second pass, the G-Buffer data is used to compute the final per-pixel lighting output.
The main idea is that de-coupling geometry from lighting can keep the shading costs under control. A common issue of deferred shading is that G-buffers can have a large memory footprint and bandwidth costs, especially in cases where multiple G-buffers are used to shade unique materials such as hair or skin. However, Apple GPUs support features designed to reduce the number of render passes for deferred shading. Programmable blending can reduce the bandwidth cost and when combined with memoryless render targets the memory footprint can be reduced to a small fraction. Here you have a basic example of a deferred renderer ported from Intel-based Macs. The G-buffer attachments are rendered and stored to system memory by the first command encoder. The attachments are read back immediately afterwards in the lighting pass, consuming a significant amount of memory bandwidth. Metal on macOS supports the concept of memory barrier and some developers use this construct in their deferred renderers. A memory barrier is a synchronization object that ensures that all writes to a given set of resources have completed before further commands can be processed. So in this case, a memory barrier on the fragment stage could be used to combine the G-buffer and lighting passes together. However, memory barriers within the fragment stage are a very expensive operation on Apple GPUs. That's because they're required to flush the tile memory to system memory, which is what we want to avoid in the first place.
Fortunately, you can use programmable blending to optimize this deferred rendered into a single pass. Programmable blending allows your shader to access the current pixel's value for all color attachments. The results are accessible in the on-chip tile memory without needing to go through system memory.
One important detail to highlight is that the tile memory stores color and depth attachments separately, so the depth is not directly accessible to a fragment shader. To work around this limitation, you can maintain the current fragment's depth in a dedicated color attachment to keep it available to all your fragment shaders. Now that we know the basics of on-chip deferred shading, let's see some more complex examples. Game engines can have multiple lighting pipelines with unique G-buffer layouts. For instance, hair or skin shading often add additional material properties and need custom lighting. Such configuration would consume a lot of memory bandwidth on Apple GPUs. Fortunately, Metal offers a number of techniques to optimize these kind of pipelines. Remember that Metal supports up to 8 core attachments per render pass. If your G-buffer layout is similar among all logical passes of your deferred renderer and you use only a few unique attachments to store all the intermediate lighting results, then you can keep everything in one pass using programmable blending. In this example, besides the G-buffer attachments, you have one attachment for regular lighting and one attachment for the specialized hair lighting before compositing them together.
And of course, if you don't need to reference G-buffer data outside the render pass, then you can even make those attachments memoryless, reducing the memory footprint of your workload. To summarize, we now know that programmable blending is a simple yet powerful feature to maximize the use of tile memory. However, there are cases where you need to repurpose more drastically the structure of your tile memory. Later in this video, we'll focus again on this topic but before, we need to talk about how to mix render and compute together. Modern renderers often implement more sophisticated lighting pipelines than what we've seen so far. In many cases, those pipelines use both render- based techniques as well as compute dispatches. A typical example is tile-based light culling which is a rendering technique where the rendered target is split into small tiles and a compute shader builds a list of all lights that affect each tile. The final lighting pass uses the per-tile light list to shade only the lights affecting a given tile, reducing the shading costs dramatically. Now that we are throwing compute into the mix, keeping data on-chip might require some additional work. Metal supports render command encoders for drawing and compute command encoders for dispatches.
But starting with A11 Bionic, Apple GPUs also support tile-based compute dispatches.
With tile shaders, you can dispatch threadgroups that operate on a per-tile basis within a render command encoder. Tile dispatches introduce implicit barriers against the fragment shading stage of the earlier and later draws. For this reason, a tile dispatch can use the fragment shading results of all earlier draws in the tile and finish executing before any subsequent draws start their fragment shading. Tile shaders are deeply integrated in the architecture of modern Apple GPUs, so they can access imageblocks. threadgroup memory and device memory as well. With this in mind let's go back to our tile deferred renderer. Here is a pipeline that has a G-buffer pass followed by a light culling compute pass. To determine whether a light affects a given tile, the light culling pass uses the depth attachment produced by the G-buffer pass. Finally the culled light list is used in the last compute pass to accumulate the lighting contribution of all lights in a given tile. Without tile shading dispatching thread groups without a compute command encoder would break rendering into three passes, forcing several flashes of the tile memory to system memory.
Using tile shaders instead, you can access the whole image block data in a tile dispatch, so you can generate per-tile light lists in the middle of a render command encoder. In this configuration, the light list is stored in a threadgroup memory buffer which can be read by the fragment shaders that calculate lighting later on. And once again, because most of the intermediate data stays in the on-chip tile memory you could use memoryless attachments to reduce the memory footprint. Let's look at how to setup the render pass descriptor for this configuration. Let's define the dimension of the on-chip tiles, so that they match with the light culling scheme. In this case, I'm using 32 by 32 pixels for each tile. One detail to keep in mind is that Apple GPUs only support a few different tile dimensions. Then, I allocate the threadgroup memory buffer used to store the per-tile light list. I'm assuming that each tile will contain up to eight unique lights. Now it's time to set up the G-buffer attachments. Notice that I'm using the .dontCare storeAction as I don't want to store the G-buffers back to system memory. And as discussed, we can use memory- less textures for those attachments. The last three lines configure the lighting attachment to be cleared at the beginning of the render pass and stored out to system memory at the end of the render pass and that's it: our render pass descriptor is now ready to be used. Tiles shaders are a powerful and flexible tool. And over the last few years, we at Apple prepared a lot of material about it. If you're looking for a deep dive into tile shading, please see our Metal 2 on A11 Tech Talk on tile shading. And if you want to know more about tile- based light culling, please check out our Modern Rendering with Metal talk at WWDC 19. Now that we know about tile shaders, let's go back to our discussion about how to repurpose tile memory. One more reason to have tile shaders in your tool box is when you need to change the layout of your image block or threadgroup memory. When you're looking for opportunities to merge passes, sometimes you have data, stored in color attachments or image block fields that are no longer needed. A good example would be transitioning an image block from a G-buffer layout to a layout suitable to sort and accumulate multiple layers of translucent geometry. To implement this transition, you need a fragment-based tile pipeline, which is a tile shader dispatch with a fragment function bound. Let's look at the source code. Here is the image block layout used for deferred shading. I want to transition to a layout that is useful for storing multiple layers of translucent fragments per pixel.
This struct will serve as the fragment shader output. It has a single field marked with the imageblock_data attribute. The fragment function will read a DeferredShadingFragment input and return a FragmentOutput structure, which will initialize the image block for multilayer alpha blending. The fragment shader will read any values that need to be processed or preserved from the input image block and return the correct value to repurpose the image block itself. So this concludes our discussion about repurposing tile memory. For further details. Please see our Metal 2 on A11 Tech Talk on Image Blocks. In the final section of this video, we'll have a brief architectural overview of the Apple Shader Core which is a key component of our GPUs. Then we'll focus on some optimization techniques for your shaders. The Apple shader core uses a modern scalar architecture that is closely aligned to the Metal shading language programming model. And even if its math units are scalar, the Apple Shader core prefers to load and store vector types directly. The shader core can hoist execution of a constant code ahead of time and prefetch constant data, once per draw or dispatch. This allows each parallel thread to focus on its own unique work. The operator core contains both a 16-bit and a 32-bit ALU so it can perform math at different precisions to reduce power usage and increase performance. You get most of these benefits for free but optimal performance may require some tweaking of your shaders. The next sections will focus on three important topics. Let's start talking about memory address spaces and how to use them effectively. GPUs have multiple paths to memory that are designed for different access patterns. For this reason the Metal Shading language implements the concept of address space. Every time you declare a buffer binding in your shaders, the Metal shading language requires you to tag your data with a specific address space. Choosing the right address space is an important decision that will directly impact the performance of your shaders. We're going to focus our attention on the device and constant address bases. The device adress space is a read-write memory space with virtually no size restrictions.
On the other hand the constant address space is read-only and can fit only a limited amount of data. Keep in mind that this address space is optimized for the use of data that is constant across all threads in the same draw or dispatch. Picking the correct address space is usually a matter of asking yourself two simple questions: first, how much data are we dealing with? If the amount of data is not known at compile time and each thread in your draws or dispatches reads a different number of items, then the data should be placed in the device address space. Second if the size is fixed, how many times is each item read? If it's a few, then use the device address space. Otherwise, if the same item is reused several times by different threads, use the constant address space. For instance if your indexing some data of your vertex ID or fragment coordinates, then each thread will likely access a different item. In such case, use the device address space. Choosing the right address space can be critical for achieving the best performance. Next let's discuss about one particular optimization related to the constant address space. In some cases, the shader compiler can preload your buffers into special registers dedicated to constant data. Let's call those registers "uniforms." The preloading happens before your shaders run. So it's a helpful mechanism to reduce latency. Buffers tagged with the constant address space can likely be pre-loaded into uniforms. Preloading is more likely to happen if the offset of the data within your buffer can be determined at compile time.
And if you're indexing into an array, its size needs to be known at compile time as well. Let's see an example. The fragment shader on the left reads an array of light structures from system memory. In this example, constant preloading will not happen. That's because even if we specify the const qualifier, we're actually reading the light array from the device address space. But also, the size of the light array is not determined at compile time.
To help the shader compiler to preload your constant buffers, make sure to provide your constants as a single struct, passed by reference. And for your constant arrays, provide a size known at compile time. The resulting code would look like this. The light array is now encapsulated in a struct loaded by reference from constant address space. And the maximum number of lights is known at compile time with the MAX_LIGHTS constant. The shader compiler is now able to preload the lights array into a uniform registers. Let's now talk about ALU data types and how they can significantly affect the performance of your shaders. First, some definitions. By data types, we mean whatever types you use throughout your shader code. Apple GPUs are optimized for 16-bit data types. So when you use a type bigger than 16-bits, you will allocate more registers accordingly and if you use a smaller type you will still consume a full 16-bit register. Using 16-bit data types instead of 32-bit data types, your shaders will require less registers leading to an increase in shader core occupancy. Higher occupancy means that more GPU threads can be in flight at the same time which is great to improve the latency hiding capabilities of the shader core. But also in most cases, 16-bit data types use faster arithmetic instructions than the equivalent 32-bit data types, leading to a significantly better ALU utilization. For all those reasons use half and short instead of float and int when possible. Don't worry about type conversions. Those are typically free, even between single precision and half precision floating point values. Let's see some examples. In this example, consider a kernel using the thread position within a thread group for some computation. I'm using 32-bits but the maximum threadgroup size supported by Metal can easily fit in a 16-bit value. The threadgroup position within the dispatch grid, however, could potentially require a larger datatype depending on the grid size. In this case, for the grid size I'm going to use, a 16-bit value is enough. The resulting code would use a smaller number of registers to compute local and global positions within the dispatch, potentially increasing the shader core occupancy. Next let's talk about another case where it is possible to use more registers than expected, this time through floating point literals. The Metal shading language specifies that operations have to happen at the highest precision among all operands. So even if the A and B arguments are using half precision, the compiler has to promote the whole expression to single precision. that's because of the -2 and 5 literals. So when you're writing half precision code make sure to use half procedure literals using the H letter suffix.
Finally let's talk about how to avoid some common pitfalls in the memory accesses of your shaders. In general, try to avoid stack-allocated arrays as sometimes the force the compiler to generate suboptimal code. For instance, the compiler cannot easily optimize away dynamically indexed arrays initialized at runtime. In this case, if the value of the index argument is not known at compile time, the compiler would likely spill to memory A B and C and read back the correct value based on the index argument. In this other example, the loop will likely get unrolled so the compiler will be able to know the value of the index variable at compile time optimizing away any spilling. The best way to know if you have stack accesses getting spilled to memory is to use the GPU frame debugger in Xcode. If you see a warning sign next to one of your draws, click on the Pipeline Statistics section. This will open a remarks panel containing a message similar to this if you hit any spilling due to stack accesses. Another thing to look out for is the type of the indices used in memory accesses. The best practice is to use signed types wherever you can. Let's consider the following example.
Here you have a simple loop accessing a buffer. The loop index variable uses an unsigned type. Unsigned types have a well-defined wrapping semantic in the Metal Shading language. So if the index overflows, the compiler needs to make sure that it wraps around correctly and such behavior comes at a cost. Let's take a look at the memory access pattern involving wrapping.
In this case, "start" has a value larger than "end." In the Metal Shading language, this is perfectly valid. And what will happen is that the index will wrap around when reaching UINT_MAX. To implement its behavior, the shader compiler cannot vectorize the loads together, potentially affecting the performance of this shader. If you need the wrapping behavior, of course use an unsigned type. However most of the times this is not necessary.
Replacing the index with a signed type will tell the compiler you don't need the wrapping semantic, as overflow of signed values is undefined behavior in the Metal Shading language. With this change, the shader compiler is now able to vectorize the four loads together, likely leading to a performance improvement.
And once again batching your memory accesses together is generally a good thing for performance. The compiler will try to do it for you, but sometimes it needs your help. Let's consider the following example. The main loop is accessing fields A and C of the foo struct at the same time. The problem here is that those fields are not adjacent as B is sitting between them, therefore the compiler will not be able to load them together. To fix that, you can merge the fields manually like this using a vector datatype directly, forces the compiler to emit a vectorized load in this case. You can achieve the same behavior by simply modifying your structure so that the fields are next to each other. And this concludes our discussion about the Apple Shader core. OK, let's review what we learned today in this video. Mike and I showed you many different optimization techniques for the Apple GPU architecture.
We discussed about eliminating unnecessary dependencies to maximize vertex, fragment, and compute overlap. Next, we discussed avoiding unnecessary pass changes through pass re-ordering and merging. We also talked about how to minimize memory bandwidth through proper use of load and store actions.
We then discussed how to maximize the efficiency of the hidden surface removal hardware by ordering draws properly and paying attention to the uses of Metal that can affect the opaqueness of your fragments. We also showed you how to use Metal's TBDR-specific features to optimize your apps for Apple GPUs even further. We showed you how to optimize for the Apple shader core by using 16-bit data types where possible and using the right address space to enable constant data prefetch. And then we discussed about how to avoid common pitfalls in the memory accesses of your shaders. We are now at the end of this road that started with porting your native x86 apps to the new Apple silicon Macs. So what are the next steps? If you want to profile your apps, the Metal System Trace instrument is the best tool at your disposal. And remember that we at Apple prepared a lot of material to help you squeeze every bit of performance out of your apps. In particular, check out our new talk about Metal App Profiling in Xcode 12 from my colleague Sam. And don't forget to check last year's WWDC talks about Delivering Optimized Metal Apps and Games as well as the Modern Rendering with Metal talk. Thank you.
-
-
11:16 - Encoding with parallel render commands
// Encoding with parallel render commands let parallelDescriptor = MTLRenderPassDescriptor() // … setup render pass as usual … let parallelEncoder = commandBuffer.makeParallelRenderCommandEncoder(descriptor:parallelDescriptor) let subEncoder0 = parallelEncoder.makeRenderCommandEncoder() let subEncoder1 = parallelEncoder.makeRenderCommandEncoder() let syncPoint = DispatchGroup() DispatchQueue.global(qos: .userInteractive).async(group: syncPoint) { /* … encode with subEncoder0 … */ } DispatchQueue.global(qos: .userInteractive).async(group: syncPoint) { /* … encode with subEncoder1 … */ } syncPoint.wait() parallelEncoder.end() -
14:51 - Multiple render target setup
// Multiple render target setup let textureDescriptor = MTLTextureDescriptor.texture2DDescriptor(…) let lightingTexture = device.makeTexture(descriptor: textureDescriptor) textureDescriptor.storageMode = .memoryless let attenuationTexture = device.makeTexture(descriptor: textureDescriptor) let renderPassDesc = MTLRenderPassDescriptor() renderPassDesc.colorAttachments[0].texture = lightingTexture renderPassDesc.colorAttachments[0].loadAction = .clear renderPassDesc.colorAttachments[0].storeAction = .store renderPassDesc.colorAttachments[1].texture = attenuationTexture renderPassDesc.colorAttachments[1].loadAction = .clear renderPassDesc.colorAttachments[1].storeAction = .dontCare let renderPass = commandBuffer.makeRenderCommandEncoder(descriptor: renderPassDesc); -
19:47 - Write masking
let descriptor = MTLRenderPipelineDescriptor(); // ... descriptor.colorAttachments[0].writeMask = .red | .green; -
21:15 - Write to all render pass attachments
struct FragInput { ... }; struct FragOutput { float3 albedo; float3 normals; float3 lighting; }; fragment FragOutput GenerateGbuffer( FragInput in [[stage_in]]) { FragOutput out; out.albedo = sampleAlbedo(in); out.normals = interpolateNormals(in); out.lighting = float3(0, 0, 0); return out; } -
30:19 - Optimized tiled deferred render pass setup
let renderPassDesc = MTLRenderPassDescriptor() renderPassDesc.tileWidth = 32 renderPassDesc.tileHeight = 32 renderPassDesc.threadgroupMemoryLength = MemoryLayout<LightInfo>.size * 8 renderPassDesc.colorAttachments[0].texture = albedoMemorylessTexture renderPassDesc.colorAttachments[0].loadAction = .clear renderPassDesc.colorAttachments[0].storeAction = .dontCare renderPassDesc.colorAttachments[1].texture = normalsMemorylessTexture renderPassDesc.colorAttachments[1].loadAction = .clear renderPassDesc.colorAttachments[1].storeAction = .dontCare renderPassDesc.colorAttachments[2].texture = roughnessMemorylessTexture renderPassDesc.colorAttachments[2].loadAction = .clear renderPassDesc.colorAttachments[2].storeAction = .dontCare renderPassDesc.colorAttachments[3].texture = lightingTexture renderPassDesc.colorAttachments[3].loadAction = .clear renderPassDesc.colorAttachments[3].storeAction = .store -
32:20 - Transitioning from deferred rendering to multi-layer alpha blending layout
// Transitioning from deferred rendering to multi-layer alpha blending layout struct DeferredShadingFragment { rgba8unorm<half4> albedo; rg11b10f<half3> normal; float depth; rgb9e5<half3> lighting; }; struct MultiLayerAlphaBlendFragments { half4 color_and_transmittence[3]; float depth[3]; }; struct FragmentOutput { MultiLayerAlphaBlendFragments v [[imageblock_data]]; }; fragment FragmentOutput my_tile_shader(DeferredShadingFragment input [[imageblock_data]]) { FragmentOutput output; output.v.color_and_transmittence[0] = half4(input.lighting, 0.0h); output.v.depth[0] = input.depth; return output; }
-