-
Swift의 성능 살펴보기
Swift가 추상화와 성능 간에 균형을 유지하는 방식을 확인해 보세요. 고려해야 할 성능 요소를 알아보고, Swift 옵티마이저가 이러한 요소에 어떠한 영향을 주는지 살펴보세요. Swift의 다양한 기능을 살펴보고, 이렇게 구현된 기능들을 통해 성능에 영향을 줄 수 있는 여러 트레이드오프를 파악하는 방법을 알아봅니다.
챕터
- 0:00 - Introduction
- 1:24 - Agenda
- 1:46 - What is performance?
- 4:31 - Low-level principles
- 4:36 - Function calls
- 8:29 - Memory allocation
- 10:34 - Memory layout
- 13:57 - Value copying
- 20:54 - Putting it together
- 21:08 - Dynamically-sized types
- 24:33 - Async functions
- 28:11 - Closures
- 30:36 - Generics
- 34:00 - Wrap up
리소스
관련 비디오
WWDC24
WWDC19
WWDC16
-
비디오 검색…
안녕하세요, John McCall입니다 오늘은 Swift의 성능에 대해 살펴보겠습니다 한 프로그래밍 언어로 많은 작업을 할 때는 해당 언어로 작성된 다양한 연산이 어떤 성능을 내는지 직관적으로 알 수 있어야 합니다 C 언어 프로그래머의 경우 그런 경우가 많죠 C 언어는 기계어 코드로 리터럴하게 번역됩니다 이와 같은 로컬 변수는 스택에 할당되며
힙 할당은 호출을 하는 경우에만 이루어집니다 컴파일러가 데이터를 레지스터로 옮기거나 메모리를 최적화하는 등 작업 속도를 높이는 여러 영리한 방법이 있지만 적절한 컴파일 방식에는 기본 원리가 있습니다
Swift는 꼭 그렇게 간단하지는 않습니다 부분적으로는 안정성 때문인데요 C에서는 깔끔한 기계어 코드를 얻을 수 있지만 코드를 잘못 작성하면 메모리가 완전히 난잡해지죠 대신 Swift는 C에서 제공하지 않는 다양한 추상화 기능과 클로저, 제네릭 등을 지원합니다 이러한 추상화 기능은 간단하게 구현되어 있지 않으며 명시적으로 malloc을 호출하듯이 명확한 비용을 알 수 없습니다 그렇다고 해서 코드의 실제 실행 방식에 대한 비슷한 직관을 기를 수 없는 것은 아닙니다 성능과 관련된 작업에서는 이러한 직관이 매우 중요한데요 이번 시간에는 Swift의 로우 레벨 성능에 대해 살펴보겠습니다 먼저 성능이란 무엇을 의미하는지 살펴보고 로우 레벨 성능에 대해 생각할 때 고려해야 하는 여러 기본 원칙을 살펴보겠습니다 끝으로 Swift의 주요 기능이 어떻게 구현되어 있는지 세부적으로 살펴보며 그러한 기능이 성능에는 어떤 영향을 주는지 알아보겠습니다
성능이란 무엇일까요?
상당히 심오한 질문이죠 만약 어떤 도구가 있어서 프로그램을 그 도구에 집어넣으면 하나의 숫자가 출력되고 그 숫자로 프로그램의 성능을 모두 알 수 있다면 얼마나 좋을까요 이를테면 Safari의 성능 점수가 9.2라고 출력되는 거죠 안타깝지만 그렇게 할 수는 없습니다 성능은 다차원적이고 상황에 따라 달라지니까요 우리는 보통 거시적인 차원에서 성능에 대해 다룹니다 데몬이 너무 많은 자원을 사용하고 있거나 UI를 클릭할 때 지나치게 느리게 반응하거나 앱이 계속 중단되는 경우죠 이러한 문제를 조사할 때는 보통 하향식으로 접근합니다 Instruments와 같은 도구로 측정해 보면 어디를 살펴봐야 할지 확인할 수 있습니다
대부분의 경우 이러한 문제는 알고리즘을 개선하여 해결합니다 코드의 로우 레벨 성능까지 굳이 살펴보는 일은 없죠
하지만 가끔은 로우 레벨 성능까지 살펴봐야 합니다 어떤 경우에는 조사의 범위를 실행 추적의 어느 한 부분까지 좁힐 수 있었지만 알고리즘 수준에서 더 이상 개선할 부분이 없을 수도 있을 겁니다 그냥 느리게 실행되는 거죠 더 나아가려면 코드가 실제로 어떻게 실행되는지 이해해야 하고 그렇게 하려면 상향식 접근 방식이 필요합니다 로우 레벨 성능은 대체로 다음 4가지 사항에 크게 영향을 받습니다 첫째, 효율적으로 최적화되지 않은 수많은 호출에 영향을 받습니다 둘째, 데이터를 표현하는 방식에 많은 시간 또는 메모리를 소비합니다 셋째, 메모리를 할당하는 데 너무 많은 시간을 소비하며 넷째, 불필요하게 값을 복사하고 파괴하며 많은 시간을 허비하죠 Swift 기능의 대부분은 이러한 비용 중 하나 이상에 영향을 줍니다 모든 사항을 살펴보려 하는데요 마지막으로 고려할 사항을 하나 추가하겠습니다 Swift에는 강력한 옵티마이저가 있습니다 몇 가지 성능 문제는 발생할 일이 없는데 컴파일러가 효과적으로 제거해 주기 때문입니다 최적화에는 한계가 있습니다 코드를 작성하는 방식은 옵티마이저의 최적화 성능에 큰 영향을 줄 수 있습니다 이번 주제를 이야기하면서 최적화 가능성에 대해서도 이야기할 예정입니다 성능과 관련해 프로그래밍에서 중요한 부분이기 때문이죠 옵티마이저에 의존하는 것이 불편한 분들을 위해 한 가지 제안을 드리겠습니다 프로젝트에서 성능이 중요하다면 정기적인 모니터링이 필요합니다 하향식으로 조사하다가 문제가 될 만한 부분을 발견하면 측정할 수 있는 방법을 찾고 그러한 측정을 자동화하여 개발 프로세스에 포함하세요 그런 식으로 진행하면 퇴행의 원인을 제대로 식별하여 어떤 식으로든 옵티마이저를 혼란스럽게 만든 것이 문제인지 2차 복잡도 알고리즘을 실수로 추가한 것이 원인인지 알 수 있습니다 그러면 이제 옵티마이저가 원하는 대로 잘 작동하는지 파악할 수 있습니다
그러면 이제 로우 레벨 성능의 4가지 기본 원칙을 살펴보겠습니다 먼저 함수 호출입니다
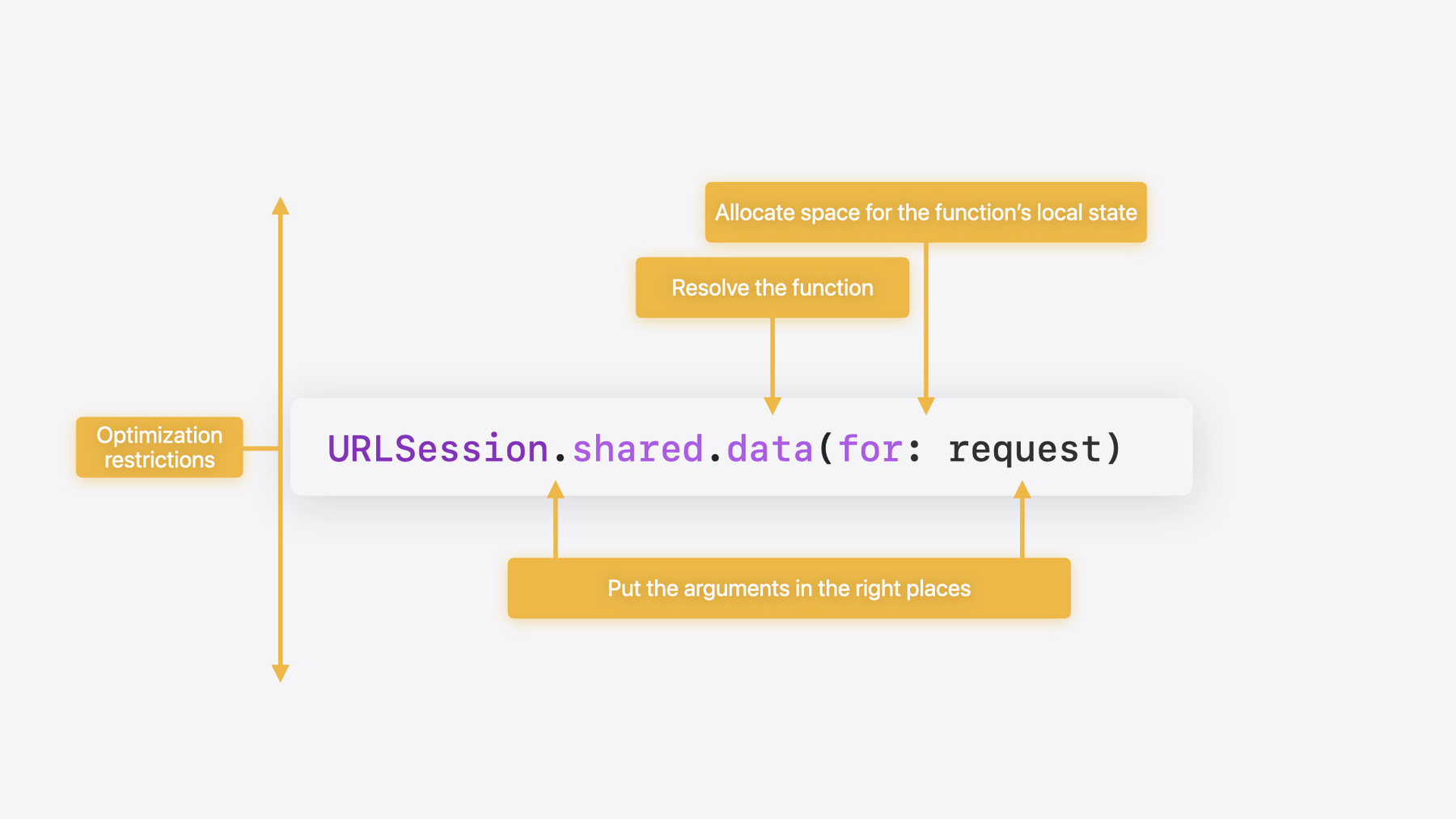
함수 호출에 연관된 비용은 4가지입니다 우리는 그중 3가지 작업을 하죠 먼저 호출할 때 인수를 설정해야 합니다
그리고 호출하는 함수의 주소를 알아내야 합니다 또한 함수의 로컬 상태를 저장할 공간을 할당해야 합니다
4번째 작업은 우리가 하지 않습니다 이 모든 작업이 최적화에 제약을 걸 수 있습니다 호출자에서도, 호출하는 함수에서도 그럴 수 있죠
이렇게 4가지 비용입니다
먼저 인수 전달에 대해 살펴보죠 이 비용은 2개 수준에서 발생합니다 가장 낮은 수준에서는 호출을 할 때 호출 규칙에 따라 인수를 올바른 위치에 배치해야 합니다 최신 프로세서에서는 보통 이 비용을 레지스터 이름을 바꿔 숨길 수 있으므로 실질적으로 큰 영향을 주지는 않습니다
하지만 더 높은 수준에서는 함수의 소유권 규칙을 충족하기 위해 컴파일러가 값을 복사해야 할 수도 있습니다 이는 프로파일의 호출자 또는 호출되는 함수에서 소유권의 추가 획득과 해제로 나타나고는 합니다 이 부분은 나중에 다시 설명하겠습니다 다음 두 비용인 함수 결정과 최적화에 미치는 영향은 모두 같은 이유에서 발생합니다 컴파일 타임에 어떤 함수를 호출하는지 정확히 알고 있나요? 알고 있다면 호출은 정적 디스패치를 사용하는 것이고 아니라면 동적 디스패치를 사용하는 것입니다 정적 디스패치는 더 효율적이고 프로세서 수준에서 더 빠르게 작동하기도 하지만 무엇보다 중요한 것은 컴파일 타임에 다양하게 인라인 처리나 제네릭 구체화처럼 상당한 최적화가 이루어진다는 점입니다 컴파일러가 함수 정의를 알 수 있다면 말이죠 하지만 동적 디스패치는 다형성과 같은 강력한 추상화 기능을 제공합니다
Swift에서는 특정 종류의 호출만 동적 디스패치를 사용하며 호출 대상의 정의에서 이를 확인할 수 있습니다
이 예에서는 프로토콜 유형의 값을 업데이트하는 호출이 있습니다 이 호출의 유형은 메서드가 선언된 장소에 따라 달라집니다
프로토콜의 메인 바디 안에 선언된 경우 프로토콜 요구사항이며 호출은 동적 디스패치를 사용합니다
하지만 프로토콜 확장 안에서 선언되면 호출은 정적 디스패치를 사용합니다 이는 의미론적으로도 성능면에서도 아주 중요한 차이가 있습니다
함수 호출에 관한 마지막 비용은 로컬 상태 저장을 위한 메모리 할당입니다 함수가 실행되려면 메모리가 필요합니다 일반적인 동기 함수이므로 이 메모리를 C 스택에 할당합니다 C 스택에 공간을 할당하려면 스택 포인터에서 할당할 공간만큼 빼면 됩니다
이를 컴파일하면 어셈블리 코드의 함수 시작과 끝 부분에서 스택 포인터를 조작합니다
함수에 진입하면 스택 포인터가 C 스택을 가리키고 있습니다 먼저 스택 포인터에서 값을 빼면서 시작합니다 어셈블리 코드에서 208바이트만큼 빼고 있습니다 이렇게 하면 기존에 CallFrame이라고 부르던 공간이 할당되며 함수가 실행될 공간이 마련됩니다 이제 함수 본문을 실행할 수 있습니다
반환하기 직전에 스택 포인터에 다시 208바이트를 더해 이전에 할당한 메모리를 할당 해제합니다
CallFrame은 C 구조체 같은 레이아웃으로 생각할 수 있습니다 이상적으로는 함수의 모든 로컬 상태가 CallFrame의 필드가 됩니다 CallFrame에 모든 것을 넣는 게 가장 좋은 이유는 컴파일러가 함수 시작 시 항상 스택 포인터에서 값을 빼 공간을 확보하기 때문입니다 반환 주소와 같은 중요한 정보를 저장할 공간이 필요하니까요 더 큰 상수를 빼더라도 더 많은 시간이 걸리지는 않으니 함수에 메모리가 필요한 경우 CallFrame의 일부로 할당하는 게 가장 비용이 적게 듭니다
이는 다음으로 살펴볼 로우 레벨 기본 원칙인 메모리 할당으로 연결됩니다
전통적으로 메모리는 세 종류로 구분됩니다 물론 컴퓨터 입장에서는 결국 동일한 RAM 상의 메모리입니다 하지만 프로그램에서 우리는 서로 다른 패턴으로 할당하고 사용하죠 이러한 점은 운영 체제에 중요한 사항이며 성능 면에서도 중요합니다
글로벌 메모리는 프로그램 로드 시 할당되고 초기화됩니다 비용은 거의 없다시피 하죠 글로벌 메모리의 커다란 단점은 고정된 크기의 메모리를 사용하는 특정 패턴에서만 사용 가능하며 프로그램을 실행하는 동안 메모리가 유지된다는 점입니다 이러한 특성은 글로벌 변수와 정적 멤버 변수에는 적합하지만 그 외의 경우에는 적합하지 않죠
스택 할당의 예시로 CallFrame에 대해 살펴봤습니다 글로벌 메모리처럼 스택 메모리도 비용이 아주 적지만 특정 패턴에만 사용할 수 있습니다 스택 메모리의 경우 메모리의 범위가 한정되어야 합니다 현재 함수의 특정 지점부터는 해당 메모리가 더 이상 사용되지 않도록 해야 합니다 일반적인 로컬 변수에 적합합니다
마지막 종류의 메모리는 힙입니다 힙 메모리는 매우 유연합니다 언제든지 할당할 수 있으며 이후 언제든지 할당을 해제할 수 있습니다
이러한 유연성 때문에 다른 종류의 메모리에 비해 할당 및 할당 해제 시 훨씬 더 많은 비용이 필요합니다
힙은 클래스 인스턴스 같이 특히 자주 사용되는 용례가 있고 정적 수명 제한이 분명하지 않아 다른 메모리를 사용하기 어려울 때도 사용됩니다
종종 힙 메모리를 할당할 때 메모리가 소유권을 공유하게 될 때가 있으며 이는 같은 메모리를 여러 레퍼런스가 개별적으로 참조하는 것을 의미하죠 Swift는 레퍼런스 카운팅으로 할당의 수명을 관리합니다
Swift에서 레퍼런스 카운트를 늘리는 것을 획득이라 하고 레퍼런스 카운트를 줄이는 행위는 해제한다고 합니다
메모리 할당에 대해 살펴봤으니 Swift가 이 메모리를 사용하여 값을 저장하는 방법을 알아보겠습니다 이를 메모리 레이아웃이라고 합니다
Swift 대해 이야기할 때 대체로 하이 레벨 개념에서 값에 대해 논합니다 메모리의 어떤 위치에 무엇이 저장되는지는 관련이 없죠
예를 들어 이렇게 초기화하면 이 변수의 값은 두 개의 double이 담긴 배열이라고 할 수 있습니다
메모리에 저장된 형태에 대해 이야기해야 할 때 값이라는 단어를 그대로 사용하는 경우가 있는데 이번 주제에서는 그렇게 하면 혼란스러울 수 있으므로 더 기술적인 용어인 ‘표현’을 사용하겠습니다 값의 표현은 메모리에 값이 배열되는 방식을 말합니다 변수 array는 메모리의 이름으로 버퍼 객체에 대한 레퍼런스를 가지며 이는 두 double 값의 표현으로 초기화되어 있습니다
또한 인라인 표현이라는 용어를 사용하여 포인터를 따라가지 않고 확인할 수 있는 부분의 표현을 나타내겠습니다 따라서 변수 array의 인라인 표현은 하나의 버퍼 레퍼런스입니다 버퍼에 담긴 내용이 무엇인지는 고려하지 않는 거죠 표준 라이브러리의 MemoryLayout이 인라인 표현을 측정해 줍니다 array의 경우 단지 8바이트로 64비트 포인터 하나의 크기입니다
좋습니다 Swift에서 모든 값은 특정 컨텍스트 안에 담깁니다 로컬 범위에는 그 안에서 사용되는 모든 값이 담깁니다 로컬 변수, 중간 결과 등이죠 구조체와 클래스에는 모든 저장 속성이 담겨 있습니다 배열과 딕셔너리는 버퍼를 통해 그 요소를 모두 담고 있는 등 그런 식이죠
Swift의 모든 값은 유형을 가집니다
값의 유형이 메모리에서 값이 어떻게 표현되는지 결정하며 인라인 표현도 마찬가지입니다 값의 컨텍스트가 인라인 표현을 저장할 메모리 위치를 결정합니다
우리 예를 통해 이를 살펴보겠습니다 array는 로컬 변수입니다 배열 값이 있고 로컬 범위에 속해 있습니다
로컬 범위에서는 가능하면 인라인 표현을 함수의 CallFrame에 배치합니다 여기서도 그렇게 동작하죠 이 CallFrame 어딘가에 Double 배열의 인라인 표현을 위한 공간이 있습니다
Double 배열의 인라인 표현이란 무엇일까요? Array는 구조체이며 구조체의 인라인 표현은 모든 저장 속성의 인라인 표현입니다 표준 라이브러리 소스 코드를 보면 이해하기 어려울 수 있지만 제가 정리해 드리자면 결국 Array의 저장 속성은 하나이며 클래스 레퍼런스입니다 그리고 클래스 레퍼런스는 객체에 대한 단순한 포인터입니다
따라서 실제로 CallFrame에는 이 포인터만 저장됩니다
Swift에서 구조체, 튜플 및 열거형은 모두 인라인 공간을 사용합니다 포함된 모든 것이 컨테이너 안에 인라인 방식으로 정리되며 일반적으로 선언된 순서를 따릅니다
클래스 및 액터는 외부 공간을 사용합니다 포함하고 있는 모든 것을 객체 안에 인라인 방식으로 저장하고 컨테이너는 해당 객체에 대한 포인터만 저장합니다 이 차이는 성능에 큰 영향을 줍니다 이에 대해 설명하려면 마지막 로우 레벨 기본 원칙 값 복사에 대해 살펴봐야 합니다 Swift에는 소유권이라는 기본 개념이 있습니다 값에 대한 소유권이란 값의 표현을 관리할 수 있는 책임입니다
Array의 인라인 표현이 버퍼 객체에 대한 레퍼런스라고 설명했습니다 이러한 레퍼런스는 레퍼런스 카운팅을 통해 관리됩니다 컨테이너가 Array 값의 소유권을 가지고 있다는 것은 다시 말해서 컨테이너에 값을 저장하는 과정에서 안에 담긴 배열 버퍼의 소유권을 획득한 것입니다 이제 컨테이너는 그러한 획득과 해제의 균형을 책임지고 유지해야 합니다
적어도 컨테이너가 사라질 때는 그러한 작업이 발생해야 합니다 이 예에서는 컨테이너가 로컬 범위이고 변수가 범위 바깥으로 사라지면 객체는 해제됩니다
Swift에서 값이나 변수를 사용할 때는 언제나 이 소유권 시스템과 상호작용하며 이는 메모리 안전의 핵심입니다 소유권 상호작용은 세 가지 유형이 있습니다 값이 소모될 수 있고 변경되거나 대여될 수 있습니다
값을 소모하는 것은 표현의 소유권을 한 곳에서 다른 곳으로 넘긴다는 의미입니다 자연스럽게 값을 소모하는 가장 중요한 작업은 메모리에 값을 할당할 때입니다
이 예시에서도 그 작업을 볼 수 있죠 변수를 초기화하려면 초기 값의 소유권을 변수에 넘겨줘야 합니다
어떤 경우, 값을 복사하지 않아도 이전할 수 있습니다 이 예에서 변수의 초기 값은 배열 리터럴이고 이는 기본적으로 새롭고 독립적인 값을 생성합니다 Swift는 이 값의 소유권을 직접 변수에 이전할 수 있습니다
첫 번째 변수의 값으로 두 번째 변수를 초기화하려면 값의 소유권을 다시 새로운 변수로 이전해야 합니다 하지만 이제 초기 값의 표현식이 기본적으로 새 값을 생성하지 않습니다 단순히 기존 변수를 참조하죠 이 변수의 값을 그냥 훔칠 수는 없습니다 앞으로 더 사용할 수도 있으니까요
독립된 값을 얻으려면 기존 변수의 현재 값을 복사해야 합니다 값이 배열이므로 복사하려면 값의 버퍼 소유권을 획득해야 합니다
이러한 작업은 자주 최적화됩니다 기존 변수가 앞으로 사용되지 않음을 컴파일러가 확인할 수 있다면 값을 복사하지 않고 이전할 수 있습니다
consume 연산자를 사용해 이를 명시적으로 요청할 수도 있습니다 이 값이 명시적으로 소모된 이후 시점에 변수를 사용하려 하면 Swift는 오류를 표시하며 값이 더 이상 존재하지 않는다고 말해줍니다
값을 사용하는 두 번째 방법은 값을 변경하는 겁니다 값을 변경한다는 것은 변경 가능한 변수에 저장된 현재 값의 소유권을 일시적으로 가져오는 겁니다 소유권 소모와의 가장 큰 차이는 값이 변경된 후에도 변수가 소유권을 가져야 한다는 겁니다
이처럼 값을 변경하는 메서드를 호출하면 변수가 현재 가지고 있는 값의 소유권을 메서드에 넘겨주게 됩니다 Swift는 호출 도중에 변수를 어떤 방법으로든 동시에 사용하지 못하도록 방지합니다
메서드가 완료되면 새 값의 소유권을 변수에 다시 넘겨줍니다 이렇게 함으로써 변수가 값의 소유권을 보유한다는 사실을 유지할 수 있습니다
값을 사용하는 마지막 방법은 값을 대여하는 것입니다 값을 대여하는 것은 다른 누구도 소모하거나 변경하지 못하게 하는 것입니다 기본적으로 값을 그저 읽고 싶을 때 적합한 작업입니다 이때 중요한 것은 다른 곳에서 값을 변경하거나 파괴하지 않는 것이니까요
인수를 전달하는 사례가 값을 대여하는 가장 일반적인 경우 중 하나입니다 array를 print에 전달하면 이상적으로는 정보만 전달하고 다른 작업을 수행하지 않아야 합니다 하지만 몇 가지 경우에는 Swift가 값을 대여하는 대신 방어적으로 인수를 복사해야 할 때도 있습니다 값을 대여하려면 동시에 값을 변경하거나 소모하려는 작업이 없다는 것을 Swift가 검증할 수 있어야 합니다 이 간단한 예시에서는 안정적으로 이를 검증할 수 있습니다 더 복잡한 예시에서는 어려울 때도 있습니다 예를 들어 클래스 속성에 있는 공간의 경우 이 속성이 대여 중에 변경되지 않는다는 것을 Swift가 검증하기 어려우므로 방어적으로 복사해야 할 수 있습니다 Swift는 이 영역에서 활발하게 개선이 이루어지고 있습니다 옵티마이저도 개선되고 있으며 복사하지 않고 명시적으로 값을 빌릴 수 있는 기능도 새로 추가되고 있습니다
값을 복사한다는 것의 실질적인 의미는 무엇일까요? 값의 인라인 표현에 따라 다릅니다 값을 복사한다는 것은 인라인 표현을 복사한다는 말이므로 독립적인 소유권이 있는 새로운 인라인 표현을 얻는 것입니다
따라서 클래스 값을 복사하면 레퍼런스의 소유권을 복사한다는 의미로 단순히 참조하는 객체의 소유권을 획득하는 것입니다 구조체 값을 복사하면 구조체의 모든 저장 속성을 재귀적으로 복사합니다
따라서 인라인 공간과 외부 공간을 선택할 때 실질적인 절충이 필요합니다 인라인 공간은 힙에 메모리를 할당하지 않으며 작은 유형에 적합합니다 더 큰 유형의 경우 복사에 드는 비용 때문에 성능이 크게 저하될 수 있습니다 복사를 자주 해야 한다면 말입니다 성능의 최적화를 위한 정해진 규칙은 없습니다
큰 구조체를 복사할 때 비용은 두 부분에서 발생합니다 첫째, 값 유형을 복사할 때 단순히 비트만 복사하지는 않습니다 이 저장 속성 3개는 모두 객체 레퍼런스로 표현되며 둘러싸고 있는 구조체를 복사할 때 소유권을 획득해야 합니다 이것을 클래스로 만들면 복사할 때 클래스 객체의 소유권을 획득해야 하겠지만 이를 구조체로 복사하면 여전히 이 3개 필드의 소유권을 각각 획득하게 됩니다
또한 이 값의 각 사본에 모든 저장 속성을 위한 공간이 필요하게 됩니다 따라서 이 값을 많이 복사해야 하는 경우 많은 메모리를 사용하게 되죠 이 유형이 대신 외부 공간을 사용한다면 모든 사본이 같은 객체를 참조하므로 메모리가 재사용될 것입니다 마찬가지로 고정된 규칙은 없지만 생각해 볼 만한 방법입니다
Swift에서는 값 의미를 채택해 유형을 작성할 것을 권장합니다 그러면 값의 사본이 원본과 전혀 관련이 없는 것처럼 동작합니다 구조체는 이렇게 동작하지만 항상 인라인 공간을 사용합니다 클래스 유형은 외부 공간을 사용하며 기본적으로 레퍼런스 의미를 기반으로 합니다 외부 공간을 사용하면서 값 의미를 활용하려면 클래스를 구조체로 둘러싸고 Copy-on-Write를 사용합니다 표준 라이브러리에서는 Swift의 모든 기본적인 데이터 구조인 배열이나 딕셔너리, 문자열 등에 이 기법을 사용합니다
네 가지 기본 원칙에 대해 긴 이야기를 드렸습니다 그와 동시에 이러한 원칙이 Swift의 기본적인 기능인 구조체와 클래스 함수 등에 어떻게 적용되는지 살펴봤습니다 이제 그러한 내용을 모아서 Swift의 고수준 기능에 대해 이야기하겠습니다 동적 크기 유형부터 이야기할까요 C 구조체의 크기는 항상 고정적이지만 Swift 유형의 크기는 런타임에 결정될 수 있습니다 두 가지 경우가 있습니다
첫째, SDK의 많은 유형은 미래의 OS 업데이트에서 저장된 속성이 추가되거나 변경될 수 있으며 Foundation의 URL 같은 유형도 여기에 포함되죠 따라서 이러한 유형의 레이아웃은 컴파일 타임에 알려지지 않는 것으로 취급해야 합니다
두 번째로 제네릭 유형의 유형 매개변수는 어떤 가능한 표현의 어떤 유형으로든 대체될 수 있어야 하므로 마찬가지로 레이아웃을 모르는 것으로 취급해야 합니다
두 번째 규칙에는 예외가 있는데 유형 매개변수가 특정 클래스로 제한되면 클래스 유형의 표현을 가져야 한다는 것을 알 수 있습니다 즉, 항상 포인터여야 하죠 이렇게 하면 제네릭으로 대체되지 않더라도 훨씬 효율적인 코드가 됩니다 제한 사항을 수용할 수 있다면 말이죠
그렇다면 Swift는 컴파일러가 유형의 표현을 정적으로 알 수 없으면 메모리 레이아웃과 할당을 어떻게 처리할까요? 어떤 유형의 컨테이너가 값을 저장하고 있는지에 따라 다릅니다 대부분의 컨테이너에 대해 Swift는 런타임에 레이아웃을 처리할 수 있습니다 예를 들어 이 Connection 구조체에는 URL이 있습니다 URL의 레이아웃을 정적으로 알 수 없으므로 Connection의 레이아웃도 정적으로 알 수 없습니다 하지만 괜찮습니다 Connection을 담고 있는 컨테이너에 문제가 될 뿐이니까요 컴파일러는 Connection의 첫 번째 동적 크기 속성에 도달할 때까지의 정적 레이아웃을 파악할 수 있습니다 나머지 레이아웃은 Swift가 런타임에 프로그램에서 처음으로 이 유형의 레이아웃이 필요할 때 동적으로 채웁니다
URL이 24바이트가 되는 경우 런타임에 Connection의 레이아웃은 컴파일러가 정적으로 레이아웃을 알 수 있었을 때와 동일하게 구성됩니다 상수를 사용할 수 있는 대신 컴파일러는 크기와 오프셋을 동적으로 불러와야 할 뿐입니다
하지만 일부 컨테이너는 크기가 상수여야 합니다 이러한 경우에는 컴파일러가 값에 대한 메모리를 컨테이너의 할당과 별개로 할당해야 합니다
예를 들어 컴파일러는 고정된 크기의 글로벌 메모리만 요청할 수 있으며, URL 같은 유형의 글로벌 변수를 선언하면 컴파일러가 포인터 유형의 글로벌 변수를 생성합니다 글로벌 변수에 처음으로 액세스하면 이니셜라이저를 지연 실행하는 작업의 일환으로 Swift가 힙 공간도 지연 할당합니다
로컬 변수의 경우에도 비슷한 동작이 이루어집니다 CallFrame도 크기가 상수여야 하니까요
CallFrame은 URL에 대한 포인터만 저장합니다 변수가 범위 내에 들어오면 함수가 변수를 동적으로 할당해야 하고 범위를 벗어나면 해제해야 합니다
그런데 로컬 변수는 범위를 가지므로 C 스택에서 할당할 수도 있습니다 함수에 진입할 때 평소처럼 CallFrame을 할당합니다
변수가 범위 내에 들어오면 단순히 스택 포인터에서 변수의 크기만큼 더 빼면 됩니다
변수가 범위를 벗어나면 스택 포인터를 다시 복원하면 됩니다
지금까지는 동기 함수에 대해서만 이야기했습니다 비동기 함수는 어떨까요?
비동기 함수의 핵심 아이디어는 C 스레드는 귀중한 리소스이며 실행을 차단하기 위해 C 스레드를 지연하면 리소스가 낭비된다는 것입니다 그 결과 비동기 함수는 두 가지 특수한 방식으로 구현됩니다 먼저 로컬 상태를 C 스택과 다른 별개의 스택에 유지합니다 두 번째로 런타임에 실제로 여러 함수로 나뉘어 실행됩니다
그럼 비동기 함수의 예를 살펴보겠습니다
이 함수에는 잠재적인 중단점인 await가 있습니다
모든 로컬 함수는 중단점 이후에도 사용되므로 C 스택에 저장할 수 없습니다
동기 함수는 스택 포인터에서 값을 빼서 로컬 메모리를 C 스택에 저장한다고 설명했습니다
비동기 함수도 개념적으로 동일하게 작동하지만 크고 연속적인 스택 공간을 할당하지는 않습니다
대신 비동기 작업이 하나 이상의 메모리 슬랩을 관리합니다
비동기 함수가 비동기 스택에 메모리를 할당하려 할 때 작업에 메모리를 요청합니다 스택이 현재 슬랩에서 메모리를 제공하려고 하며 가능하다면
작업이 슬랩의 해당 부분을 사용 중으로 표시하고 함수에 제공합니다
하지만 슬랩 대부분이 점유된 상태라면 할당할 공간이 없을 수 있습니다 이 경우 작업이 malloc으로 새 슬랩을 할당하며
여기에서 메모리를 할당합니다
두 경우 모두 할당 해제 시에는 메모리를 작업에 다시 돌려주며 비어 있는 것으로 표시됩니다
이 할당자는 한 작업에서만 사용되고 스택 원칙을 사용하므로 일반적으로 malloc보다 속도가 훨씬 빠릅니다 전반적인 성능 프로파일은 동기 함수와 비슷하나 호출에 대한 오버헤드가 약간 더 많습니다
실제로 실행되려면 비동기 함수는 부분 함수로 나뉘어 함수가 중단될 수 있는 중단점 사이를 채워야 합니다 여기에서는 함수 내에 await이 하나 있으므로 두 개의 부분 함수로 나뉩니다
첫 번째 부분 함수는 기존 함수 진입 시 시작됩니다 배열이 비어 있다면 단순히 비동기 함수 호출자에게 반환됩니다 비어 있지 않으면 첫 번째 작업을 가져와 대기합니다 나머지 부분 함수가 await 이후에 실행됩니다 먼저 기다렸던 작업의 결과를 출력 배열에 추가하고 루프를 계속 실행하려고 합니다 더 이상 작업이 없으면 비동기 함수 호출자에게 반환됩니다 작업이 더 있다면 루프를 반복하고 다음 작업을 기다립니다
여기에서 핵심은 C 스택에 최대 1개의 부분 함수만 존재한다는 겁니다
한 부분 함수에 진입하여 다음 잠재적 중단점까지 일반적인 C 함수처럼 실행할 수 있습니다 부분 함수가 중단점을 넘지 않는 로컬 상태를 저장하고 싶다면 C CallFrame에 할당할 수 있습니다
그 시점에서 부분 함수가 다음 부분 함수를 꼬리 호출하고 C 스택에서 이전 부분 함수의 CallFrame은 사라지며 다음 함수의 프레임이 할당됩니다
그런 다음 이 부분 함수가 잠재적 중단점에 도달할 때까지 실행됩니다
작업이 실제로 중단되어야 하면 C 스택에서 정상적으로 반환되고 일반적으로 바로 동시성 런타임으로 넘어가 스레드를 즉시 다른 작업에 사용할 수 있습니다
지금까지의 예시에서는 func로 선언한 함수만 봤는데 클로저는 어떻게 작동하며 로컬 할당에 어떤 영향을 줄까요?
클로저는 함수 유형의 값을 전달하는 데 사용됩니다 이 함수는 탈출 불가 함수를 인수로 받습니다 Swift에서 함수 값은 항상 함수 포인터와 컨텍스트 포인트의 쌍으로 구성됩니다 C에서는 이 함수의 시그니처가 다음과 같이 표현됩니다
Swift에서 함수 값을 호출하면 단순히 함수 포인터를 호출하여 묵시적으로 컨텍스트 포인터를 추가 인수로 함께 전달합니다
둘러싸인 범위의 값을 사용하는 클로저 표현식에서는 해당 값을 컨텍스트에 전달해야 합니다 이 작동 방식은 출력해야 하는 함수 값의 유형에 따라 달라집니다 여기에서는 함수가 탈출 불가 함수이므로 호출이 완료된 후에 함수 값이 사용되지 않는다는 것을 알 수 있습니다 따라서 값의 메모리를 관리할 필요가 없고 컨텍스트를 범위 내에서 할당할 수 있습니다
따라서 컨텍스트는 포착한 값이 담긴 간단한 구조체가 됩니다
컨텍스트를 스택에 할당할 수 있고 그 주소를 sumTwice에 전달하면 됩니다
클로저 함수에서는 짝을 이루는 컨텍스트의 유형을 알고 있으므로 필요한 데이터를 가져오기만 하면 됩니다 탈출 클로저에서는 다르게 작동합니다 이제는 클로저가 호출 안에서만 사용될지 알 수 없으므로 컨텍스트 객체를 힙에 할당하고 소유권을 획득하고 해제하여 관리해야 합니다
컨텍스트가 기본적으로 익명 Swift 클래스의 인스턴스처럼 작동합니다
Swift의 클로저에서 로컬 변수를 참조할 때는 변수의 레퍼런스를 사용합니다 따라서 변수를 수정할 수 있으며 기존 범위와 현재 범위에 변경사항이 모두 반영됩니다
탈출 불가 클로저에서만 변수를 가져오면 변수의 수명이 변하지 않습니다 따라서 클로저가 변수의 할당 공간에 대한 포인터만 가져와 이를 처리할 수 있습니다
하지만 탈출 불가 클로저에서 변수를 가져오면 클로저의 수명만큼 변수의 수명이 늘어날 수 있습니다
따라서 이 변수도 힙에 할당되어야 하고 클로저 컨텍스트가 해당 객체에 대한 레퍼런스의 소유권을 획득해야 합니다
제네릭에 대해 살펴보며 마무리하겠습니다
이 함수는 데이터 모델에 대해 제네릭한 함수입니다 이러한 유형의 레이아웃은 정적으로 알 수 없고 컨테이너에 따라 다르게 처리된다고 이미 설명해 드렸습니다 프로토콜 제약이 어떻게 작동하는지는 아직 살펴보지 않았습니다 구체적으로 Swift가 프로토콜 요구사항이 있는 호출을 실제로 어떻게 실행할까요?
Swift 프로토콜은 런타임에 함수 포인터 테이블로 표현됩니다 프로토콜의 각 요구사항당 하나죠 C에서는 테이블이 대략 이렇게 표현됩니다
프로토콜 제약이 있을 때마다 적절한 테이블에 포인터를 전달합니다
이와 같은 제네릭 함수에서는 유형 및 감시 테이블이 숨겨진 추가 매개변수가 됩니다 이 런타임 시그니처의 모든 항목이 기존 Swift 시그니처의 항목에 각각 직접 대응됩니다
프로토콜 유형의 값을 사용할 때는 다르게 작동합니다 이번에는 더 유연한 함수입니다 배열의 각 요소가 서로 다른 유형의 데이터가 될 수 있습니다 하지만 이렇게 하면 실행 효율성이 떨어집니다
AnyDataModel 같은 프로토콜의 인라인 표현을 C로 나타내면 이렇습니다 값을 저장할 공간이 있고 값의 유형과 준수할 사항을 저장할 필드가 있습니다
하지만 이는 고정 크기를 가져야 합니다 표현에서 크기를 변경하며 다양한 유형의 데이터 모델을 지원할 수 없습니다 값을 저장할 공간을 얼마나 크게 만들건 맞지 않는 데이터 모델이 있을 수 있습니다 어떻게 해야 할까요?
Swift는 임의 버퍼 크기의 포인터 3개를 사용해 프로토콜 유형에 저장된 값을 해당 버퍼에 넣을 수 있다면 인라인 방식으로 집어 넣습니다 그렇지 않으면 힙에 값을 위한 공간을 할당하고 그 포인터를 버퍼에 저장합니다
따라서 이 함수 시그니처들은 매우 비슷해 보이지만 실제로는 매우 다른 특성을 가지고 있습니다 첫 번째 함수는 같은 유형의 데이터 모델로 구성된 배열을 받습니다 데이터 모델은 배열에 효율적으로 채워지며 별도의 최상위 수준 인수로 함수에 유형 정보가 함수에 한 번 전달됩니다
호출자가 호출되는 유형을 알 수 있다면 함수를 특수화할 수도 있습니다 여기에서는 알려진 유형의 배열로 호출하고 있습니다 이러한 호출은 옵티마이저가 손쉽게 인라인 처리하거나 정확히 이 인수 유형에 특수화된 버전의 함수를 생성할 수도 있습니다 이렇게 하면 제네릭과 관련된 추상화 비용이 제거되며 MyDataModel이 준수하는 구현에서 직접 update를 호출할 수 있습니다
두 번째 함수는 다양한 데이터 모델로 구성된 배열을 받습니다 더 유연하죠 다양한 유형의 데이터 모델을 사용한다면 이렇게 해야 할 겁니다 그러나 배열의 요소들이 각자 다른 동적 유형을 가져 배열에 값이 조밀하게 채워지지 않습니다
실제로 이를 최적화하는 게 훨씬 더 어렵습니다 데이터가 배열에 어떻게 흘러 들어가고 함수에서 사용되는지 컴파일러가 완벽하게 추론해야 합니다 그렇다고 성능이 완전히 저하되는 건 아니지만 이 한 부분에서는 컴파일러의 도움을 별로 받지 못한다는 겁니다 이야기를 마무리하며 여러분에게 강조하고 싶은 내용이 있습니다 제 이야기를 듣고 난 후에 이렇게 생각하시면 안 됩니다 “John이 프로토콜 유형을 사용하지 말라고 했어” 제가 비용에 관해 오늘 설명한 모든 것은 다음 원칙을 따릅니다 비용은 발생하며 때때로 비용을 지불할 가치가 있다는 겁니다 추상화는 강력하고 유용한 도구이며 잘 활용하는 게 좋으니까요 오늘 제 설명이 Swift 코드 성능에 대한 직관을 기르는 데 도움이 되셨기를 바랍니다 시청해 주셔서 감사합니다
-
-
0:24 - An example C function, with self-evident allocation
int main(int argc, char **argv) { int count = argc - 1; int *arr = malloc(count * sizeof(int)); int i; for (i = 0; i < count; ++i) { arr[i] = atoi(argv[i + 1]); } free(arr); } -
0:50 - An example Swift function, with a lot of implicit abstraction
func main(args: [String]) { let arr = args.map { Int($0) ?? 0 } } -
4:39 - An example of a function call
URLSession.shared.data(for: request) -
6:30 - A Swift function that calls a method on a value of protocol type
func updateAll(models: [any DataModel], from source: DataSource) { for model in models { model.update(from: source) } } -
6:40 - A declaration of the method where it's a protocol requirement using dynamic dispatch
protocol DataModel { func update(from source: DataSource) } -
6:50 - A declaration of the method where it's a protocol extension method using static dispatch
protocol DataModel { func update(from source: DataSource, quickly: Bool) } extension DataModel { func update(from source: DataSource) { self.update(from: source, quickly: true) } } -
7:00 - The same function as before, which we're now talking about the local state within
func updateAll(models: [any DataModel], from source: DataSource) { for model in models { model.update(from: source) } } -
7:18 - Partial assembly code for that function, showing instructions to adjust the stack pointer
_$s4main9updateAll6models4fromySayAA9DataModel_pG_AA0F6SourceCtF: sub sp, sp, #208 stp x29, x30, [sp, #192] … ldp x29, x30, [sp, #192] add sp, sp, #208 ret -
7:59 - A C struct showing one possible layout of the function's call frame
// sizeof(CallFrame) == 208 struct CallFrame { Array<AnyDataModel> models; DataSource source; AnyDataModel model; ArrayIterator iterator; ... void *savedX29; void *savedX30; }; -
10:50 - A line of code containing a single variable initialization
var array = [ 1.0, 2.0 ] -
11:44 - Using the MemoryLayout type to examine a type's inline representation
MemoryLayout.size(ofValue: array) == 8 -
12:48 - The variable initialization from before, now placed within a function
func makeArray() { var array = [ 1.0, 2.0 ] } -
15:42 - Initializing a second variable with the contents of the first
func makeArray() { var array = [ 1.0, 2.0 ] var array2 = array } -
16:27 - Taking the value of an existing variable with the consume operator
func makeArray() { var array = [ 1.0, 2.0 ] var array2 = consume array } -
16:58 - A call to a mutating method
func makeArray() { var array = [ 1.0, 2.0 ] array.append(3.0) } -
17:40 - Passing an argument that should be borrowable
func makeArray() { var array = [ 1.0, 2.0 ] print(array) } -
18:10 - Passing an argument that will likely have to be defensively copied
func makeArray(object: MyClass) { object.array = [ 1.0, 2.0 ] print(object.array) } -
19:27 - Part of a large struct type
struct Person { var name: String var birthday: Date var address: String var relationships: [Relationship] ... } -
21:22 - A Connection struct that contains a property of the dynamically-sized URL type
struct Connection { var username: String var address: URL var options: [String: String] } -
21:40 - A GenericConnection struct that contains a property of an unknown type parameter type
struct GenericConnection<T> { var username: String var address: T var options: [String: String] } -
21:51 - The same GenericConnection struct, except with a class constraint on the type parameter
struct GenericConnection<T> where T: AnyObject { var username: String var address: T var options: [String: String] } -
22:27 - The same Connection struct as before
struct Connection { var username: String var address: URL var options: [String: String] } -
23:23 - A global variable of URL type
var address = URL(string: "...") -
23:42 - A local variable of URL type
func workWithAddress() { var address = URL(string: "...") } -
25:02 - An async function
func awaitAll(tasks: [Task<Int, Never>]) async -> [Int] { var results = [Int]() for task in tasks { results.append(await task.value) } return results } -
28:21 - A function that takes an argument of function type
func sumTwice(f: () -> Int) -> Int { return f() + f() } -
28:30 - A C function roughly corresponding to the Swift function
Int sumTwice(Int (*fFunction)(void *), void *fContext) { return fFunction(fContext) + fFunction(fContext); } -
28:47 - A function call that passes a closure expression as a function argument
func sumTwice(f: () -> Int) -> Int { return f() + f() } func puzzle(n: Int) -> Int { return sumTwice { n + 1 } } -
29:15 - C code roughly corresponding to the emission of the non-escaping closure
struct puzzle_context { Int n; }; Int puzzle(Int n) { struct puzzle_context context = { n }; return sumTwice(&puzzle_closure, &context); } Int puzzle_closure(void *_context) { struct puzzle_context *context = (struct puzzle_context *) _context; return _context->n + 1; } -
29:34 - The function and its caller again, now taking an escaping function as its parameter
func sumTwice(f: @escaping () -> Int) -> Int { return f() + f() } func puzzle(n: Int) -> Int { return sumTwice { n + 1 } } -
29:53 - A closure that captures a local variable by reference
func sumTwice(f: () -> Int) -> Int { return f() + f() } func puzzle(n: Int) -> Int { var addend = 0 return sumTwice { addend += 1 return n + addend } } -
30:30 - Swift types roughly approximating how escaping variables and closures are handled
class Box<T> { let value: T } class puzzle_context { let n: Int let addend: Box<Int> } -
30:40 - A generic function that calls a protocol requirement
protocol DataModel { func update(from source: DataSource) } func updateAll<Model: DataModel>(models: [Model], from source: DataSource) { for model in models { model.update(from: source) } } -
31:03 - A C struct roughly approximating a protocol witness table
struct DataModelWitnessTable { ConformanceDescriptor *identity; void (*update)(DataSource source, TypeMetadata *Self); }; -
31:20 - A C function signature roughly approximating how generic functions receive generic parameters
void updateAll(Array<Model> models, DataSource source, TypeMetadata *Model, DataModelWitnessTable *Model_is_DataModel); -
31:36 - A function that receives an array of values of protocol type
protocol DataModel { func update(from source: DataSource) } func updateAll(models: [any DataModel], from source: DataSource) -
31:49 - A C struct roughly approximating the layout of the Swift type `any DataModel`
struct AnyDataModel { OpaqueValueStorage value; TypeMetadata *valueType; DataModelWitnessTable *value_is_DataModel; }; struct OpaqueValueStorage { void *storage[3]; }; -
31:50 - A contrast of the two Swift function signatures from before
protocol DataModel { func update(from source: DataSource) } func updateAll<Model: DataModel>(models: [Model], from source: DataSource) { for model in models { model.update(from: source) } } func updateAll(models: [any DataModel], from source: DataSource) { for model in models { model.update(from: source) } } -
32:57 - Specialization of a generic function for known type parameters
func updateAll<Model: DataModel>(models: [Model], from source: DataSource) { for model in models { model.update(from: source) } } var myModels: [MyDataModel] updateAll(models: myModels, from: source) // Implicitly generated by the optimizer func updateAll_specialized(models: [MyDataModel], from source: DataSource) { for model in models { model.update(from: source) } }
-