-
Use Core ML Tools for machine learning model compression
Discover how to reduce the footprint of machine learning models in your app with Core ML Tools. Learn how to use techniques like palettization, pruning, and quantization to dramatically reduce model size while still achieving great accuracy. Explore comparisons between compression during the training stages and on fully trained models, and learn how compressed models can run even faster when your app takes full advantage of the Apple Neural Engine.
For more on optimizing Core ML, check out “Improve Core ML integration with async prediction" from WWDC23.Resources
Related Videos
WWDC23
- Q&A: Core ML
- Q&A: Machine learning open forum
- Q&A: Machine learning open forum
- Q&A: Machine learning open forum
- Q&A: Machine learning open forum
WWDC20
-
Search this video…
♪ ♪ Pulkit: Hi, I am Pulkit, and I am an engineer on the Core ML team. I am excited to share several updates that have been made to Core ML Tools. These updates help you optimize the size and performance of your machine learning models. With the capabilities of models improving significantly, more and more features are being driven by machine learning. As a result, the number of models deployed in a single app is increasing. Along with that, each model in the app is also getting bigger, putting an upward pressure on the size of an app. So, it's critical to keep model size in check. There are several benefits of reducing model size. You can ship more models in the same memory budget if each model is smaller. It can also enable you to ship bigger, more capable models. It can also help make the model run faster. This is because a smaller model means less data to move between the memory and the processor. So, it seems like reducing a model's size is a great idea. What makes a model large? Let me walk through an example to help you understand. ResNet50 is a popular image classification model. Its first layer is a convolution layer with about 9,000 parameters. And it has 53 convolution layers in total with varying sizes. At the end, it has a linear layer with about 2.1 million parameters. This all adds up to 25 million parameters If I save the model using Float16 precision, it uses 2 bytes per weight, and I get a model of size 50 megabytes. A 50-megabyte model is large, but when you get to some newer models like Stable Diffusion, you end up with even larger models. Now, let's talk about some paths to getting a smaller model. One way is to design a more efficient model architecture that can achieve good performance with fewer and smaller weights. Another way is to compress the weights of your existing model. This path of model compression is what I will focus on. I'll start by describing three useful techniques for model compression. Next, I'll demonstrate two workflows that integrate these model compression techniques. I'll then illustrate how the latest Core ML Tools helps you in applying these techniques and workflows to your models. And lastly, Srijan will discuss the impact of model compression on runtime performance. Let's start with the compression techniques. There are a couple of ways to compress model weights. The first way is to pack them more efficiently using a sparse matrix representation. This can be achieved by using a technique called pruning. Another way is to reduce the precision used to store the weights. This can be achieved either by quantization or by palettization. Both of these strategies are lossy, and the compressed models are typically slightly less accurate compared to their uncompressed counterparts.
Let's now take a deeper look at each of these techniques.
Weight pruning helps you efficiently pack your model weights with a sparse representation. Sparsifying or pruning a weight matrix means setting some of the weight values to 0. I start with a weight matrix. To prune it, I can set the smallest magnitude weights to 0.
Now, I only need to store the non-zero values. I end up saving about 2 bytes of storage for every zero introduced. Of course, I will also need to store the locations of zeros, to reconstruct the dense matrix later. Model size goes down linearly with the level of sparsity introduced. A 50% sparse model means 50% of its weights are zero, and for a ResNet50 model, it has a size of about 28 megabytes, which is approximately half the Float16 size.
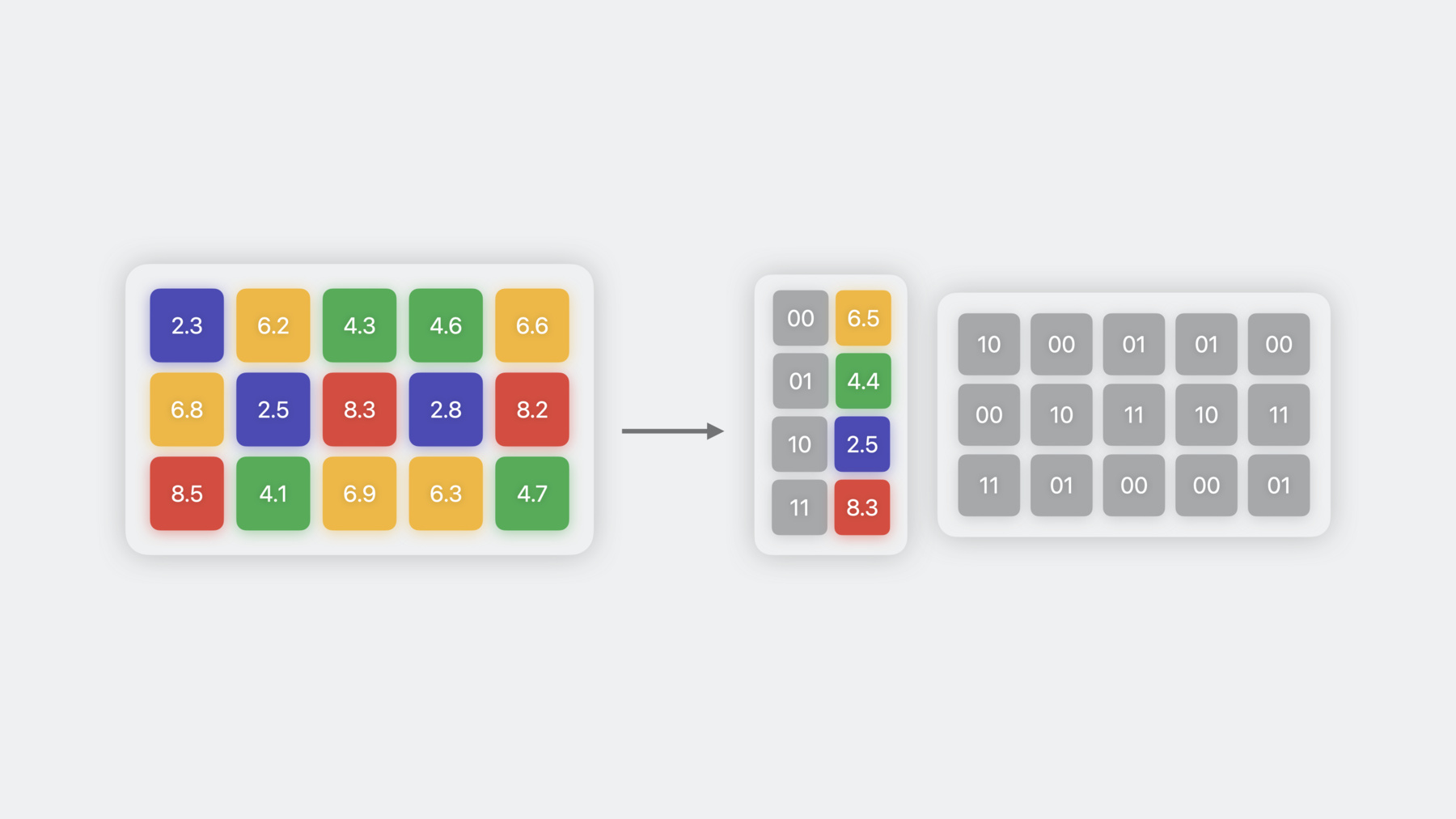
The second weight compression technique is quantization, which uses 8-bit precision to store the weights. To perform quantization, you take the weight values and scale, shift, and round them such that they lie in the INT8 range. In this example, the scale is 2.35, which maps the smallest value to -127, and the bias is 0. Depending on the model, a non-zero bias can also be used, which sometimes helps in reducing quantization error. The scale and bias can later be used to de-quantize the weights to bring them back to their original range. To reduce the weight precision below 8 bits, you can use a technique called weight clustering or palettization. In this technique, weights with similar values are grouped together and represented using the value of the cluster centroid they belong to. These centroids are stored in a look up table. And the original weight matrix is converted to an index table, where each element points to the corresponding cluster center. In this example, since I have four clusters, I am able to represent each weight using 2 bits, achieving 8x compression over Float16. The number of unique cluster centers that can be used to represent the weights is equal to 2 to the power of n, where n is the precision used for palettization. So 4-bit palettization means you can have 16 clusters. While quantization reduces your model size by half, palettization can help you make it up to 8 times smaller.
To summarize, there are three different techniques for weight compression. Each of them uses a different way to represent the weights. They offer varying levels of compression, which can be controlled by their respective parameters, like the amount of sparsity for pruning and the number of bits for palettization. Now, I will illustrate how you can integrate these techniques in your model development workflow. Let's first start with the workflow for Core ML model conversion. You may start by training a model with your favorite python training framework and then use Core ML Tools to convert that model to Core ML. This workflow can be extended one step further to become a post-training compression workflow. To do that, you add a compression step which operates on the already trained and converted model weights in order to reduce the overall size. Note that this workflow can start at any point. For example, you may start with a pre-trained model with no need for training data or an already converted Core ML model.
When applying this workflow, you will have an option to choose the amount of compression applied. The more compression you apply, the smaller your resulting model will be, but as one may expect, there are some tradeoffs. Specifically, you will be starting with an uncompressed model that achieves a certain accuracy. As you apply some compression, your model size will reduce, but it may also impact your accuracy. As you apply more compression, this impact may become more prominent and the accuracy loss may become unacceptable.
This trend and the acceptable tradeoff will be different for each use case and it is model- and dataset-dependent. To see this tradeoff in practice, let's look at a model that segments objects in an image. For my image, the model returns probability of each pixel belonging to the sofa. The baseline Float16 model segments the object very well. For a 10% pruned model, the output is very similar to the base model. Artifacts start appearing at 30% sparsity and increase with higher levels. Once I get to 40% pruning, the model completely breaks down, and the probability map becomes unrecognizable. Similarly, 8-bit quantization and 6-bit palettization preserve the base model's output. At 4-bit palettization, you start seeing some artifacts, and at 2-bit palettization, the model fails to segment the object altogether. To overcome this degradation in model performance at higher compression rates, you can use a different workflow. This workflow is called training time compression. Here, you fine-tune your model on some data while compressing the weights. Compression is introduced gradually and in a differentiable manner to allow the weights to readjust to the new constraints imposed on them. Once your model achieves a satisfactory accuracy, you can convert it and get a compressed Core ML model. Note that you may either incorporate training time compression in your existing model training workflow or start with a pre-trained model. Training time compression improves the tradeoff between model accuracy and the amount of compression, allowing you to maintain the same model performance at higher compression rates. Let's look at the same image segmentation model again. For training time pruning, the model output is unaltered up to 40% sparsity. This is where the post-training accuracy broke down. In fact, now even at 50% and 75% sparsity, the model achieves a similar probability map as the base model. It's at 90% sparsity that you start observing a significant degradation in model accuracy. Similarly, training time quantization and palettization also preserve the baseline model's output, even up to 2 bits of compression in this case. To recap, you can apply weight compression either during model conversion or during model training. The latter provides better accuracy tradeoff at the cost of longer training time. Because the second workflow applies compression during training, we also need to use differentiable operations to implement the compression algorithms. Let's now explore how these compression workflows can be executed with Core ML Tools. Post-training model compression APIs have been available in Core ML Tools 6 for pruning, palettization, and quantization under the compression utils submodule. However, there were no APIs for training time compression. With Core ML Tools 7, new APIs have been added to provide capabilities for training time compression as well. And we have consolidated the older APIs and the new ones under a single module called coremltools.optimize. The post-training compression APIs have been migrated under coremltools.optimize.coreml, and the new training time APIs are available under coremltools.optimize.torch. The latter work with PyTorch models. Let's first take a closer look at the post-training APIs. In the post-training compression workflow, the input is a Core ML model. It can be updated by the three methods available in the optimize.coreml module, which apply each of the three compression techniques that I have described. To use these methods, you start by creating an OptimizationConfig object, describing how you want to compress the model. Here, I am doing magnitude pruning with 75% target sparsity. Once the config is defined, you can use the prune_weights method to prune the model. It's a simple, one-step process to get a compressed model. You can use similar APIs for palettizing and quantizing the weights using configs specific to those techniques. Let's consider the training time compression workflow now. In this case, as I described earlier, you need a trainable model and data. More specifically, to compress the model with Core ML Tools, you start with a PyTorch model, likely with pre-trained weights. Then use one of the available APIs in the optimize.torch module to update it and get a new PyTorch model with compression layers inserted in it. And then fine-tune it, using the data and the original PyTorch training code. This is the step where weights will get adjusted to allow for compression. And you can do this step on your MacBook locally, using the MPS PyTorch backend. Once the model gets trained to regain accuracy, convert it to get a Core ML model. Let's explore this further through a code example. I am starting with the PyTorch code required to fine-tune the model I want to compress. You can easily leverage Core ML Tools to add training time pruning by adding just a few lines of code. You first create a MagnitudePrunerConfig object describing how you want to prune the model. Here, I am setting the target sparsity to 75%. You can also write the config in a yaml file and load it using the from_yaml method. Then, you create a pruner object with the model you want to compress and the config you just created. Next, you call prepare to insert pruning layers in the model. While fine-tuning the model, you call step API to update the pruner's internal state. At the end of the training, you call finalize to fold the pruning masks into the weights. This model can then be converted to Core ML using the conversion APIs. The same workflow can be used for quantization and palettization as well. Now, Srijan will walk you through a demo showing how you can use Core ML Tools APIs to palettize an object detection model. Srijan: Thank you, Pulkit. My name is Srijan, and I will be walking you through a demo of the Core ML Tools optimize API. I will be using an SSD model with a ResNet18 backbone to detect people in images. Let's first import some basic model and training utilities. I am going to start with getting an instance of the SSD ResNet18 model I just talked about. To simplify things, I will just call the pre-written get_ssd_model utility for that. Now that the model is loaded, let's train it for a few epochs. Since it's an object detection model, the goal of training would be to reduce the SSD loss of the detection task. For conciseness, the train_epoch utility encapsulates the code required to train the model for an epoch, like calling the forward through different batches, calculating the loss, and performing gradient descent. During training, the SSD loss seems to be coming down. I will now convert the model into a Core ML model. To do that, I will first trace the model and then call the coremltools.convert API. Let's call an imported utility to check out the size of the model.
The size of the model is 23.6 megabytes. Now, I will run predictions on the Core ML model. I have chosen an image of myself from my London trip as well as another image to test the detections. The confidence threshold for the model to detect an object is set to 30% so it would only plot boxes for which it is at least 30% confident of the object being present.
That detection seems spot on. I am now curious to see if I can reduce the size of this model. I am going to try out post-training palettization first. For that, I'll import some config classes and methods from coremltools.optimize.coreml.
I am now going to palettize the weights of the model with 6 bits. For that, I'll create an OpPalettizerConfig object, specifying mode as kmeans and nbits as 6. This will specify parameters at an op level, and I can palettize each op differently. However, right now, I'm gonna apply the same 6-bit mode to all the ops. I'll do that by defining OptimizationConfig and pass this op_config as a global parameter to it.
The optimization config is then passed to the palettize_weights method along with the converted model to get a palettized model. Let's see what the size got reduced to now.
The size of the model has gone down to around 9 megabytes, but did it affect the performance on test images? Let's find out. Wow, the detection still works well. I am really excited to push my luck to trying out 2-bit post-training palettization now. Doing that is as simple as just changing nbits from 6 to 2 in the OpPalettizerConfig and running the palettize_weights API again.
Let's use the utilities to see the size and performance of this Core ML model.
As expected, the model's size has reduced and has come down to around 3 megabytes. The performance, however, is suboptimal as the model isn't able to detect people in both the images. No boxes show up in the prediction, as none of the boxes predicted by the model have confidence probability above the 30% threshold. Let's try out 2-bit training time palettization to see if that performs better.
I will start by importing DKMPalettizerConfig and DKMPalettizer from coremltools.optimize.torch to do that. DKM is an algorithm to learn weight clusters by performing an attention-based differentiable kmeans operation on them. Now it's time to define the palettization config. Just need to simply specify n_bits as 2 in the global_config, and all supported modules would be 2-bit palettized. And here, I'll create a palettizer object from the model and the config. Calling the prepare API now would insert palettization-friendly modules into the model. Time to fine-tune the model for a few epochs. Now that the model has been fine-tuned, I will call the finalize API which would restore the palettized weights as weights of the model, thus completing the process. The next step is to check out the size of the model. For that, I will convert the torch model into a Core ML model. Let's start by tracing the model using torch.jit.trace. I will now call the convert API, and this time, I will use an additional flag called PassPipeline and set its value to DEFAULT_PALETTIZATION. This will indicate to the converter to use a palettized representation for the converted weights.
Let's see the size of the model and its performance on test images. I can see that the model I training-time palettized is around 3 megabytes as well, which comes down to 8x compression, but unlike the post-training palettized model, this model is performing the detection on test images correctly. Since this was a demo, I just tested model performance on two sample images. In a real-world scenario, I would use a metric like mean average precision and evaluate on a validation data set.
Let's recap. I started with a trained model and converted it to get a 23.6-megabyte model with Float16 weights. Then, I used the palettize_weights API to quickly get a smaller model with 6-bit weights, which did perform well on my data. However, when I pushed it further to 2 bits, it showed a clear drop in performance. Post this, I updated the torch model with the optimize.torch APIs and used the differentiable kmeans algorithm to fine-tune for a few epochs. With that, I was able to get good accuracy with the 2-bit compression option. While the demo employed a specific model and optimization algorithm combination, this workflow will generalize to your use case and will help you in figuring out the tradeoff between the amount of compression you desire and the time and data required to retrain the model. This brings us to our last topic, performance. I would like to briefly touch upon the improvements that have been made to the Core ML runtime to execute such models more efficiently when deployed in your app. Let's look at a few key differences between the runtime in iOS 16 and iOS 17. While in iOS 16, there was support for weight-only compressed models, in iOS 17, 8-bit activation quantized models can also be executed. In iOS 16, a weight compressed model runs at the same speed as the corresponding model with float weights, while in iOS 17, the Core ML runtime has been updated, and now compressed models run faster in certain scenarios. Similar runtime improvements are available in newer versions of macOS, tvOS, and watchOS as well. But how are these improvements achieved? In models, where only the weights are compressed, since the activations are in floating point precision, before an operation such as a convolution or a matrix multiplication can happen, the weight values need to be decompressed to match the precision of the other input. This step of decompression takes place ahead of time in the iOS 16 runtime. Hence, in this case, the model is converted to a fully float precision model in memory prior to execution. Hence, no change is observed in inference latency. However, in iOS 17, in certain scenarios, the weights are decompressed just in time, just before the operation is executed. This has the advantage of loading smaller bit weights from the memory at the cost of doing decompression in every inference call. For certain compute units, such as the Neural Engine, and certain types of models that are memory bound, this could lead to inference gains. To illustrate these runtime benefits, I selected and profiled a few models and plotted the relative amount by which their inference is sped up compared to their Float16 variant.
As expected, the amount of speedup is model- and hardware-dependent. These are the range of speedups for 4-bit palettized models on iPhone 14 Pro Max. The improvements vary between 5% to 30%. For sparse models too, there are varying improvements based on model type, with some models running 75% faster than their Float16 variants. The question now arises: what is the strategy to get the best latency performance? That would be to start with a float model and use the optimize.coreml APIs to explore various representations of the model. This would be quick, as it doesn't require retraining the model. Then, profile it on the device of your interest. For this, Core ML performance reports in Xcode will give you a lot of visibility into inference, including where operations run. Then, shortlist based on which configurations give you the best gains. After this, you can focus on evaluating accuracy and trying to improve, which may require applying some training time compression with torch and Core ML Tools before finalizing your model.
To summarize, it is important to reduce the size of the models, and now you can do that more easily than ever with the new Core ML Tools APIs and achieve lower memory footprint and inference speedups. To check out more options and benchmarking data, do visit our documentation. I would also highly recommend tuning in to the "Improve Core ML integration with async prediction" video which talks about improvements made to the Core ML framework that I did not cover in the slides today. Thank you, and happy compressing.
-