-
Metal 2 on A11 - Raster Order Groups
Raster order groups allow Metal 2 apps to precisely control the order of parallel fragment shader threads accessing the same pixel coordinates. Learn how A11 extends raster order groups with support for multiple groups and adds new capabilities for accessing threadgroup memory. See how you can improve the performance of single pass deferred shading and order independent transparency.
Resources
- Tailor Your Apps for Apple GPUs and Tile-Based Deferred Rendering
- Rendering a scene with deferred lighting in Objective-C
- Order Independent Transparency with Imageblocks
Related Videos
Tech Talks
-
Search this video…
Raster Order Groups is a new feature in Metal 2 and we're further extended it specifically for the new A11 GPU. This video is one of five that describe the new GPU capabilities of A11. To get the most out of it, you'll want to have previously watched videos on Imageblocks and Tile Shaders.
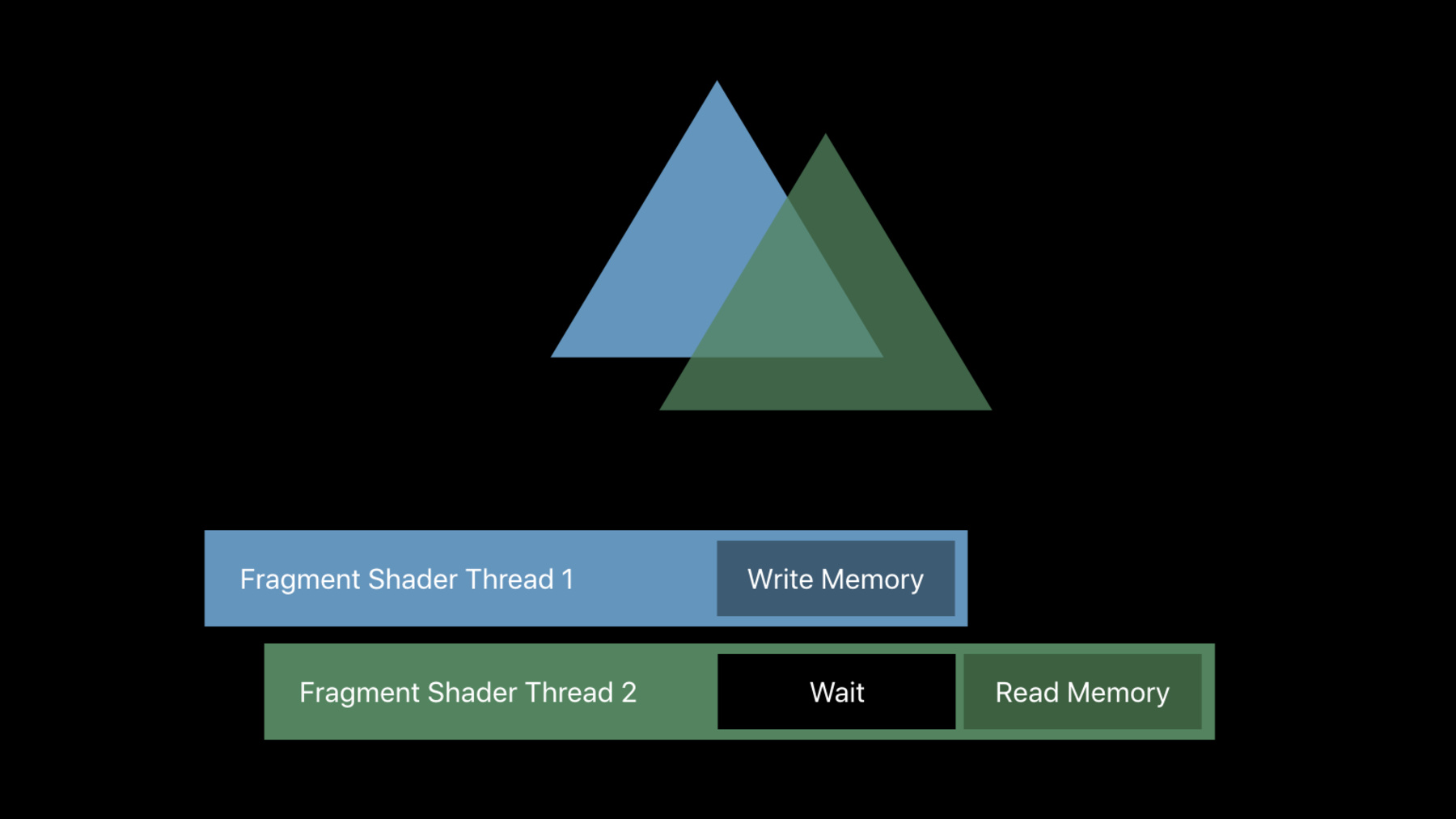
I'll start with a brief review of Raster Order Groups as already available in Metal 2, before moving on to new A11's new capabilities. Raster Order Groups is a feature that requires that the GPU execute part of your fragment shader threads in order with other threads that overlap it. This ordering comes from the submission order of your draw calls within a renderpass, and the order of each triangle within that draw call. The overlap is determined by the Rasterizer. Two fragment threads are determined to overlap if they target the same framebuffer X and Y location, the same sample, and the same layer. For example, two fragments would be considered to overlap if they would both depth test against the same depth buffer sample. This is a typical case of two triangles, with the blue triangle first and the green triangle second. For access to classic graphics framebuffers, blending is always something the GPU executes in order. GPUs are not going to suddenly blend the green triangle in back, because of scheduling variations from frame to frame. But fragment shaders are going to execute concurrently and out of order. Without raster order groups, work is only serialized after fragment shading completes, but before blending. But what if you're not blending into the framebuffer? Many recent developments in graphics algorithms attempt to build more interesting data structures from your fragment shaders. There are multi-layer encodings for better post-processing or order independent transparency. There's voxelization, and special purpose blend functions. All of these are built on the fragment shaders that are storing data into custom data structures in memory, rather than merely blending a color into an output texture. But if direct access to memory from the body of your fragment shader can happen in any order, at any time, and concurrently, that's severely limiting. Dealing with those data races has caused existing implementations of those algorithms to be far more expensive than they otherwise would have been.
What we really want is to get that blending-like ordered behavior, but not after the end of our fragment shader, but within it. We effectively want the illusion that our memory accesses are happening serially in order. That's what Raster Order Groups does. It lets you annotate your pointers to memory with a Raster Order Group. Accesses through those pointers are then done in a per-pixel submission order. The hardware will wait for any older Fragment Shader Threads that overlap with the current thread to finish before the current thread is allowed to proceed. This effectively gives you mutual exclusion, but better. It provides ordered mutual exclusion, where you know which thread is going to enter the critical section first, and which will do so second. This feature was presented in greater detail at WWDC 2017 in the session Introducing Metal 2, so if you'd like a deeper dive, you can watch that video. So with the basics covered, let's move on to what's new in the A11 GPU. Raster Order Groups are more useful, more powerful, and higher performing on A11. First, A11 exposes the GPU's internal tile memory. Just like device and texture access, tile memory is a lot more useful if you can access it in a predictable order, and so Raster Order Groups can now apply to tile memory too. Second, where Raster Order Groups on other GPUs are limited to only one mutex per pixel, A11 can go finer-grained than that, allowing an even lighter touch, and minimizing how often your threads are waiting for access. I'd like to show you a pair of examples demonstrating how to use these capabilities to unlock new performance in some common graphics algorithms.
The first example is classic deferred shading. On traditional GPUs, deferred shading is done in two passes. First filling a G-Buffer and outputting multiple textures, and then a second renderpass that reads from those textures, rendering light volumes, and calculating the shading results. But deferred shading tends to burns a lot of memory bandwidth. One great ability of our A-series GPUs is keeping as much bandwidth as possible on chip, eliminating these intermediate textures by coalescing both passes into one, keeping the G-Buffer in tile-sized chunks entirely with an imageblock within the GPU. Both of these tasks become phases of one renderpass. You can see a much deeper dive of how to build these coalesced RenderRasses in the A11 Imageblock and Tile Shading videos, while this video is going to focus on just the synchronization aspects. The performance of single pass deferred shading gets even better by leveraging multiple Raster Order Groups. To take look at that, lets dig into some of the details of Phase number two: Lighting. Our basic lighting process starts by drawing a volume that encompasses a light's influence, spawning fragment shader threads. Each thread is effectively applying one light to one pixel. Our Lighting thread starts by reading the G-Buffer fields. On A-series GPUs, you'll want to read this directly from an imageblock, which is the fastest memory available. Then you'll execute your chosen shading model, which is typically quite a bit of math, and can take some time to execute. Finally, you'll sum the contribution of this light back into the imageblock. A very quick step. Then we have a second light being applied by a second thread. For a single-pass deferred shading implementation before A11, it would look something like this. You can see the ordering is imposed on the very first read from the imageblock, forcing the entire execution of these two lights to run serially. This is because a GPU that supports only a single Raster Order Group must wait on all accesses from prior threads to complete before any accesses from later threads can begin. This applies even if both accesses are reads that do not actually conflict with each other. A11's support for multiple Raster Order Groups eliminates this over-synchronization. Multiple groups allow you to run these non-conflicting reads concurrently, and synchronizing only on the very brief end of the shader that accumulates the result.
You can achieve this by declaring our three G-Buffer fields to be in one group and our accumulated lighting result to be in a second group. The hardware may now order them separately. Outstanding writes into one group do not require that reads in another group have to wait. Multiple readers within a single group do not have to wait on each other. This means that more threads can be eligible to run at any given time, allowing for more parallelism and improved performance, above and beyond what you get by keeping your G-Buffers on-chip in the first place. The code is just as simple. My three G-Buffer fields are read and written together at the same time, and so I will annotate them all to put them into group zero. The accumulator is read and written at a different time, and so I'll annotate it into group one. As far as adoption goes, that's really about it. Raster Order Groups is an extremely easy capability to start using. On to the second example. I'm going to make our deferred shading example more complex by adding another phase. After I have a lit version of my opaque content, I'm going to add a transparency phase to the mix, forward shaded, and approximating back-to-front blending order. One way to do that, which A11 is really good at, is to declare our imageblock to store an array of color and depth pairs. Each forward-shading fragment adds an entry to this array with some handling of overflow. And at the end of my tile, I'll sort and blend back to front, using the saved depths, enabling back-to-front blending. So this is a timeline showing off the life of one tile and its imageblock from left to right. I start with A11's imageblock laid out for deferred shading, and I end up with my shade opaque color. At the end, I have my transparency phase, where I'm building and then sorting my arrays of colors and depths. Within each of these passes, Raster Order Groups will control how much parallelism is possible between fragment threads. For performance reasons, I really want these two operations to be one renderpass. I do not want to save anything out to device memory just to reload it at a later pass. But the imageblock declaration is wildly different between the first and second parts of my scene, both in data type and Raster Order Group assignments. A11 can do this transition with one step on your part. To bridge the gap between these phases, you need to put a tile shader in between. A tile shader is a compute threadgroup that can access the entire tile memory and imageblock. Tile shaders have the behavior that they do not launch until all fragment shader threads prior have completed, regardless of Raster Order Group declarations. This lets you be assured that this tile shading threadgroup has exclusive access to this memory. With the tile shader, you can read and write the entire tile, reformatting it as you wish, and in particular, reading from the imageblock via its old outgoing type, and reinitializing the contents of imageblocks using its new type. Just like tile shaders have a full barrier before they execute, they also have a full barrier after they execute. No subsequent fragment shader threads will access memory until after the tile shader has fully completed, regardless of how you've set up Raster Order Groups in the later phase. This means that you can rely on this initialization being completed before the transparency work begins.
The requirement here is pretty simple. If you want to rearrange your imageblock contents or change which fields a Raster Order Group protects, you need to put a tile shader in the middle to make that transition well-ordered and safe. Several of the pieces of sample code we're publishing for A11 shows this sequence in practice.
So that's really all there is to making use of Raster Order Groups' expanded capabilities on A11. You've seen how Raster Order Groups are even more flexible on A11 than on any other GPU. The hardware supports multiple groups, which can eliminate over-synchronization and improve performance. They work hand-in-hand with A11's fragment shader's access to tile memory and you can use tile shaders to entirely change the character of your imageblocks, including Raster Order Group configuration, right in the middle of your render pass. Putting it all together, this lets you build workloads on A11 that are incredibly light on bandwidth, and very well-performing.
For more information about Metal 2 and A11, and links to the sample code, please visit the Metal developer website. Thank you for watching.
-