-
Training Object Detection Models in Create ML
Custom Core ML models for Object Detection offer you an opportunity to add some real magic to your app. Learn how the Create ML app in Xcode makes it easy to train and evaluate these models. See how you can test the model performance directly within the app by taking advantage of Continuity Camera. It's never been easier to build and deploy great Object Detection models for Core ML.
Resources
Related Videos
WWDC20
WWDC19
-
Search this video…
Good morning. I'm Alex Brown, an Engineer in Core ML. And today, we are going to present Create ML for Object Detection. In the What's New in Machine Learning session, you were introduced to the new Create ML app. It provides a really approachable way to build custom machine learning models to add to your applications. In this session, we're going to dig a little deeper into two specific templates. Object detection, which works with images, and sound classification. Let's get started with object detection.
Object detection enables your application to identify real-world objects captured by your device's camera, and respond based on their presence, position, and relationship. You can download object detectors from the web which know the difference between broad categories of objects.
But by training a custom machine learning model on your own data, you can teach your application about the subtle differences between individual animals, hand gestures, street signs, or game tokens. If you've used machine learning with Apple before, you may already be familiar with image classification.
With image classification, you build a model which can provide a single simple description of an image.
This image we might describe as outdoors or park, or for a particular application, dog.
But what if we're interested in more than one object in the scene? In this case, object detection can come to the rescue. It can identify multiple objects within your photograph, and provide the location, size, and label for each one. This can enable your application to do more sophisticated things using your camera, but in order to do that, we need to go into more detail when teaching the model about your images.
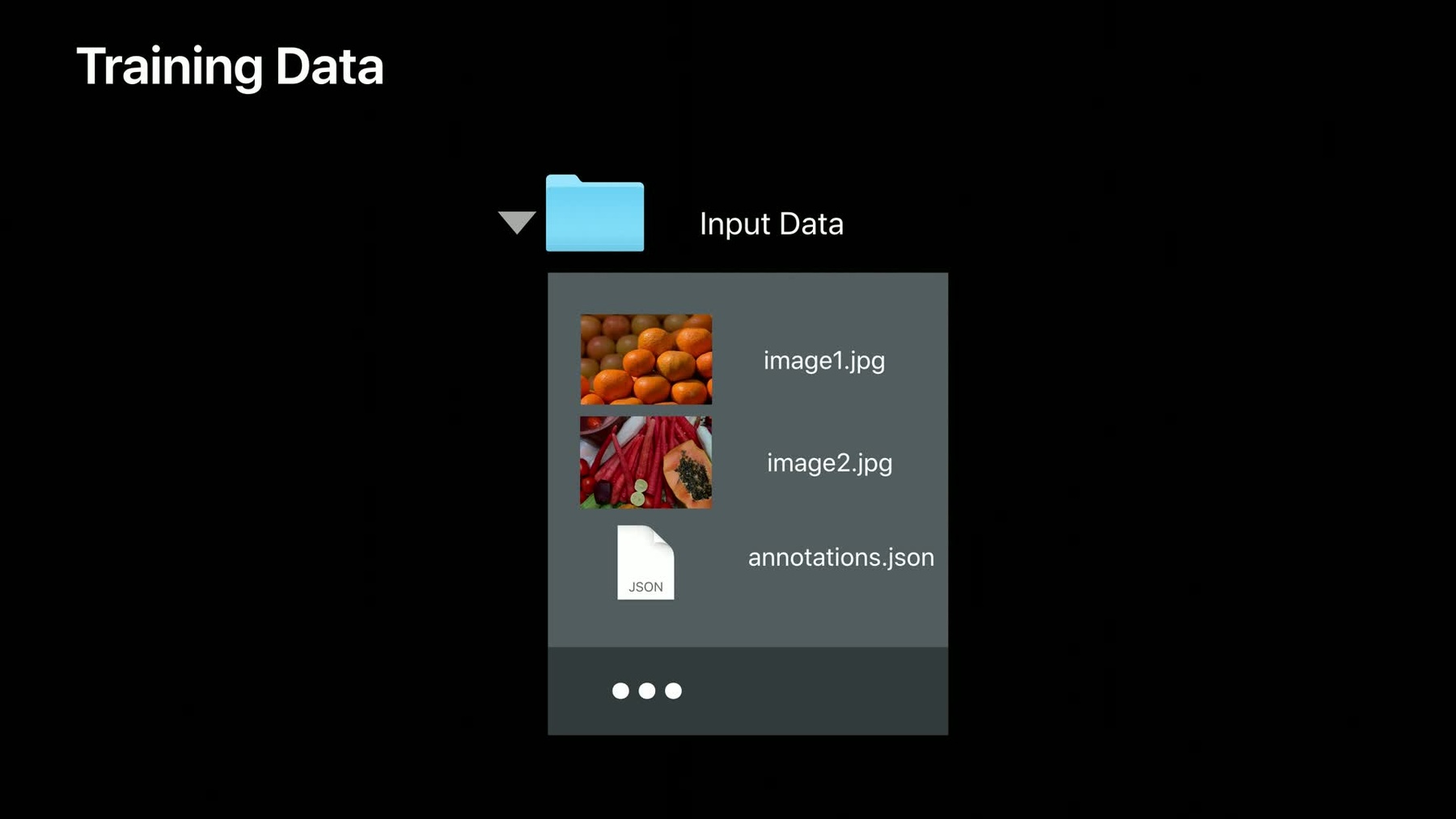
To train an object detector, you need to annotate each image with labeled regions that you would like the model to recognize. The bounding box for your annotated objects starting at the center of each object of interest and having a size, height, and width, this is measured in pixels from the top left-hand corner of your image to the center of each object of interest. You bundle together all of these annotations, label, position, and size, in a JSON file in the following format. You can download tools from the web to help you build these, but make sure they use the same coordinate system the Create ML app expects. Once you've assembled your annotations, simply drop them into the same folder as the images they describe, and that's it. Your training data is ready. So now we know how to create training data for object detection. Let's consider a real case.
My colleague, Scott, has got a great idea for building a math game that is really engaging for kids, and uses real-world dice to provide the questions.
You can hear more about this application in session 228, Creating Great Apps Using Core ML and AR Kit. So, Scott asked me to help build a model for his game, and I suggested using Apple's Create ML application to train an object detector. Scott has already sent me the training data.
He took a bunch of images of dice from different angles and with different values on the top, and he's annotated them, drawing bounding boxes around the top face and adding a label, counting the number of pips on each dice. So, now we've got our data ready. Let's take a look at how we can use the Create ML application to build our model.
So first of all, let's just check the data.
You can see we've put all of our images in a folder, and each one contains multiple dice, and we've gathered together the annotations in a single JSON file.
So now, I'll open the Create ML application. I can do this from inside X code's menu, or I can just use Spotlight.
When the Create ML application opens, it gives us the option to access documents we already created. Here, we want a new project. First, you'll see the template picker, which give you a collection of machine learning model types to select from. In this case, we want an image object detector.
I give it a name, so we can identify it later on, and fill in a few details.
Here, you can see the main window with the training view on the right-hand side. It has already selected the input tab, ready for our training data. I can drag that straight into the training data well. Even before training the model, the application takes a look at the data, and checks it's in the right format, contains images rather than sound, for instance, and has a JSON file, which correctly describes them. It also provides some initial statistics. Here, we can see we have around 1,000 images, and there are six classes, six, for the six sides of a six-sided dice. That's perfect.
We can do some other things on this screen. For instance, we can supply testing data, to allow us to compare the performance of two different models. Also, we can set some advanced parameters, tuning the way the model trains. But we don't need to worry about any of that right now, we're actually ready to train. Let's hit the play button, and see what happens.
Training has begun. It takes us instantly to the Training tab, where we can see the progress of the model training. This is a graph of loss. Loss decreases as the model gets better and better. So we should see this converge down to the bottom of the graph. Object detection takes a lot longer to train than image classification. I estimate this is probably going to take an hour or more. We don't want to wait for that, so I've already trained a model using this data.
Here we are, and I can jump to the same training tab that we just looked at. You can see that the loss has neatly declined, showing the performance of the model has really increased over the time it took to train. There's a couple of other things that you should really have a look at on this screen. First of all, the overall performance. Ninety-two percent, which is a really great number for an object detector.
We also want to have a look and check that we have consistent performance across all of the classes. The classes, 1 to 6, each here has 90% or more, and they're about the same value. This is important because it shows that it is performing equally well on the six sides of the dice. For a game of dice, where fairness is important, that's pretty important. So, the model has told us mathematically that it's pretty good, but how do we get confidence that it's going to work for our cases? Well, we can use the output tab.
Scott sent me a test image to try out before I send the model back to him, so let's drag that in now.
That's looking pretty great. You can see that it is identified, the five dice in the scene. It has correctly drawn the box around their top faces, and by clicking through, 6, 1, 5, we can see each label, and the confidence is assigned.
That's performing really well. So, if I was building my own app, I could go ahead and drag the model that has been produced and use it within Xcode. I think Scott is probably waiting for this model to build his application.
But before we go there, there's something I want to try.
While I was preparing for this demo, playing with dice, and a camera, and my computer, my son, who is 9, came over and asked what I was doing. Once I'd explained it, he got pretty excited, and already started coming up with an idea for a game which had animals, bears, and bats, and they cooperate to collect bolts to build a space ship. And they use dice, colored dice, to level up for each different kind of monster.
So we got his dice, and I decided to try them with Scott's model. So the dice he's using are a little bit different. They're role-playing dice, so let's see how the model performs. Using the Max Continuity Camera feature, I can import an image directly from my phone. This is really great because it means it's using the same glass, the same camera that your application will use.
I take the photo and click Use Photo. And it's instantly analyzed it. So let's take a moment to have a look at what is going on here. It has correctly spotted the two six-sided dice with pips, and it has given them the right labels. It has ignored most of the other dice in the picture, except for a couple over here.
It has given those the wrong numbers. So why is this? The problem here is a difference in expectation. Scott knows the dice that are going to be used are six-sided white dice with pips. My son's idea of dice is quite different. They're colored. They don't just have six sides. So how might we address this in our application? Well, either we can insist on using the dice that maybe are supplied with the game in the classroom, or we can train the model with these dice. There are two ways we can approach this. Either we can decide that only the six-sided dice with pips are valid, but we want to exclude the other dice, in which case, we just need to take photographs containing both kinds of dice, and just label the six-sided ones. Or if we were building a bear and bat game, we might like to add the other kinds of dice into our model, and label those too, either just using their numbers or adding extra labels to distinguish the colors. Red 6, black 4, etc.
So let's send this model on to Scott, so he can build his demo. I can use the Share button to simply mail the model.
And there we have it.
So, we've seen how you can use the Create ML application to train your object detector on training data that you've collected. There are some things I'd like you to consider when building that training data. Firstly, you should have a balanced number of images with annotations for each class. This tells the algorithm that you consider each of these to be equally important, and we can build a model which performs equally well on all of the classes.
Secondly, you are going to need a bunch of images. I recommend you start with 30 images with annotations for each class you want the model to recognize, and increase that number if you find performance isn't good enough, or if your subjects are particularly complicated. For instance, they look different on different sides.
What about the issue we encountered with the different colored dice? Well, that's not the only way pictures might differ. We recommend you consider how the application will be used in the real world. Your users may not have studio lighting, standard dice, and a beautiful wooden desk to work with. Perhaps ask your friends to collect additional data in different scenarios, such as indoor lighting, outdoors in the sun, different backgrounds, and add in different objects that you aren't using for your model. This helps the model generalize really well.
Something that may be surprising to you, if you've used an image classifier before, is that one label is enough. This is because by explaining a part of your image that is a dog, you're also saying that the rest of it isn't, and the model trains accordingly. So, for example, if you were building an application to count the number of pickle jars in your fridge, you don't need to label all of the other condiments. It automatically infers that they're not pickle jars.
Once you've built your model, and you want to add the functionality into your application, we recommend you use the vision framework. The vision framework can seamlessly integrate live camera as well as video into your model flow.
And that's all there is to training object detectors. [ Applause ]
-