-
Safely manage pointers in Swift
Come with us as we delve into unsafe pointer types in Swift. Discover the requirements for each type and how to use it correctly. We'll discuss typed pointers, drop down to raw pointers, and finally circumvent pointer type safety entirely by binding memory.
This session is a follow-up to "Unsafe Swift" from WWDC20. To get the most out of it, you should be familiar with Swift and the C programming language.Resources
Related Videos
WWDC20
-
Search this video…
Hello and welcome to WWDC.
Hi, my name's Andy. I'll be talking to you about how to "Safely Manage Pointers in Swift." This session builds directly on "Unsafe Swift" also from WWDC 20. In that session, we defined unsafe operations as having undefined behavior on some input.
In this talk, I'll delve deeper into some details of programming Swift outside the usual safety zone.
These aren't the kind of details that application programmers typically need to worry about. Managing pointers safely means knowing all the different ways they can be unsafe.
I'll spend most of our time here on type safety. This is a source of undefined behavior in C that tends to be poorly understood.
I'll explain the APIs that give Swift the same low-level capabilities and explain how to use them to avoid that undefined behavior. Pointer safety can be looked at as a series of levels.
Each level down, you take more responsibility for the correctness of your code.
So it's recommended that you write code at the highest safety level possible.
The first level is safe code.
A major goal of Swift is providing new ways of writing code that don't require any unsafe constructs. Swift has a robust type system that provides a lot of flexibility and performance.
Swift's collection APIs, slices and iterators provide much of the functionality you may have wanted from pointers. And not using pointers at all is a great strategy for code safety.
But another important goal of Swift is performant interoperability with unsafe languages.
To do that, Swift needs to provide low-level expressibility in the form of unsafe APIs.
These are denoted by the prefix "Unsafe" in their type or function name. Swift's UnsafePointer lets you take responsibility for some of the dangers of using pointers without worrying about type safety. If you need to work with raw memory as a sequence of bytes, Swift provides UnsafeRawPointer.
Loading and storing values with raw memory gives you the responsibility for knowing the layout of types.
At the deepest level, Swift provides a few APIs for binding memory to types. It's only by using one of these lowest level APIs that you take full responsibility away from Swift for managing the safety of pointer types.
Let me explain what I mean by levels of safety.
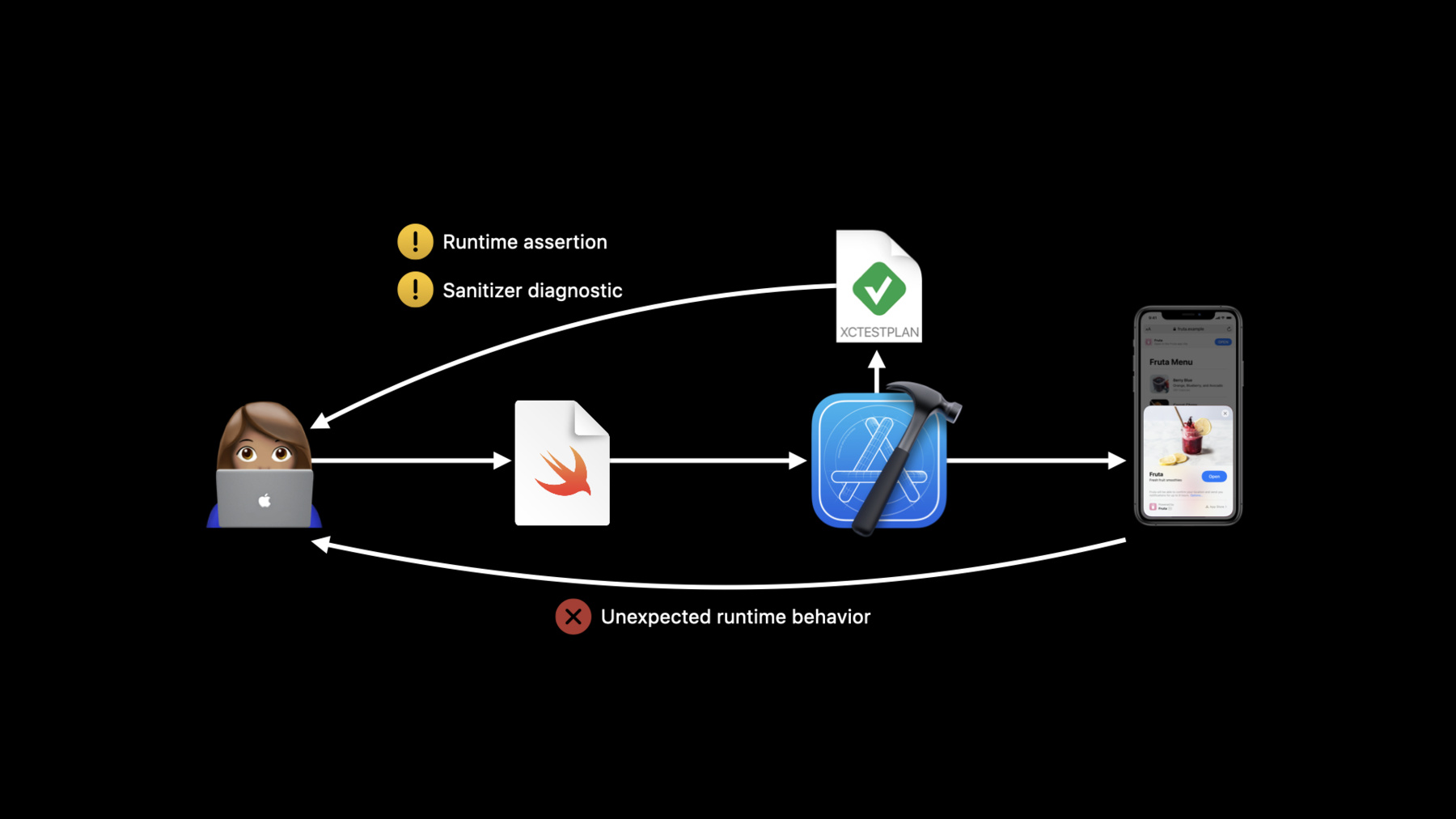
Safe code isn't necessarily correct code, but it does behave predictably. In most cases, if a programming error could lead to unpredictable behavior, then the compiler catches it.
For errors that can't be caught at compile time, runtime checks guarantee that the program crashes immediately with a diagnostic.
It won't continue past an incorrect assumption.
So safe code is really about error enforcement.
If you don't use any Swift types or APIs that are marked unsafe and you take care to manage thread safety, then you know that predictable behavior is fully enforced.
In unsafe Swift code, predictable behavior is not fully enforced, so you take on extra responsibility.
Testing still provides helpful diagnostics.
But the level of diagnostics depends on the level of safety you've chosen. Unsafe standard library APIs have assertions in debug builds that catch certain kinds of invalid input.
Adding your own preconditions to verify unsafe assumptions is also good practice.
You can test with more runtime checks by enabling sanitizers, like the address sanitizer.
Sanitizer diagnostics are a great time-saver by pinpointing bugs but they don't catch all undefined behavior.
When errors are not uncovered during testing, they can lead to unexpected runtime behavior. That could be a hard to debug crash that occurs far from the source of the problem. Or worse than a crash, your program could do the wrong thing, even corrupting user data. A crash is a bad experience, but corrupting or losing data is worse. The further down you venture into unsafe territory, the harder it is to find those mistakes, and the more confusing the symptoms may be. Symptoms may not even show up until long after the bug was introduced.
Let's look at pointers to understand some of the ways that code can be unsafe. Swift is designed to be programmed without using pointers, and looking at why they're unsafe will make it clear why avoiding them is a good strategy.
But if you do need to directly access memory using low-level APIs, it's also useful to know how to manage different aspects of safety yourself. You may need to point to the storage for a variable, to the elements of an array, or to memory that you allocated directly.
Before you can point to that object, it needs a stable memory location. The stable storage that you point to has a limited lifetime, either because it goes out of scope or because you directly deallocate the memory.
However, your pointer value has its own lifetime. When the pointer's lifetime exceeds the storage lifetime, any attempt to access it is undefined. This is the primary reason that pointers are unsafe, but not the only one.
Objects can be composed of a sequence of elements. Pointers are allowed to move to different memory addresses by adding offsets to the pointer. That's an efficient way to address different elements. But adding or subtracting too large of an offset points to memory that doesn't belong to the same object. Accessing a pointer that has exceeded its object's boundary is undefined. For this talk, we'll focus on another aspect of safety that's easily overlooked.
Pointers have their own types, distinct from the types of values in memory.
How do we ensure those types are consistent, and what happens if they aren't? When we ask for a pointer to storage of type Int16, we get back a pointer to Int16. So far so good.
As we'll see, it's pretty hard to get a pointer to the wrong type in Swift. Now let's say we manage to overwrite the same memory with a different type, now Int32.
At that point, we'll have a pointer to the correct Int32 type, but our Int16 pointer could still be hanging around.
Accessing the old pointer of type Int16 is undefined behavior because the pointer type and the in-memory type are now inconsistent. You might be wondering, "How can undefined behavior be worse than a program crash, and why would pointer types cause that?" To understand, let's look at some very unsafe code.
I don't expect anyone to write code like this, but you may be surprised at what Swift code can look like when it's ported from C, and still calls parts of the old C code. Code that does scary things is supposed to look scary, but we don't need to understand all these low-level types yet to see the problem.
Imagine we have a collage struct that holds a stand-alone pointer to some image data in memory and another property for the image count.
Maybe this type was imported from C.
We also have a function, addImages, that writes image data into memory and increases an image count.
When we call addImages, we want it to update the image count in our collage struct, but there's a mismatch between our struct's imageCount type, Int, and the function argument's pointer to UInt32.
The safe thing to do would be to create a new count variable of the correct type and use Swift's integer conversions.
Instead, this complex line of code creates a pointer directly into our struct.
Later, the code needs to read the image count again to pass it to saveImages.
The problem is, at runtime, this count could be zero, meaning that the program has silently lost all the images.
By giving the count property an Int type and the pointer a UInt32 type, we've signaled to the compiler that those values reside in different memory objects. The compiler does not see any updates to an Int object, so it could just reuse the initialization value of zero. In practice, the compiler is forgiving, so such a small example probably won't go wrong.
But we can't predict what will happen.
To the compiler, type information is a fact that assumptions are based on. Once the compiler makes a bad assumption, that can percolate through the compiler's pipeline and show up in surprising ways.
So, two versions of the compiler can cause different program behavior.
Pointer type bugs can cause your program to misbehave in ways that are worse than crashing. But what makes them more insidious is that it's rare for them to be observed. So, a program may appear to work fine while a bug lingers in the code for years without anyone noticing. Someone might later make a safe and seemingly innocuous change to the source that exposes the problem. Or it may show up after a regular compiler update, so your program starts behaving differently without anyone changing the code.
The challenge of pointer type safety predates Swift.
Knowing how to use pointer types correctly in C requires deep knowledge of the language spec.
You can find those discussions under the terms "strict aliasing" and "type punning." Fortunately, you're not expected to understand those rules to be able to use Swift pointers safely.
It is common to pass pointers from Swift into C though, so Swift pointers need to be at least as strict as C to safely interoperate.
Swift's UnsafePointer gives you most of the low-level capabilities of C pointers. In exchange, you need to manage object lifetime and object boundaries. The "Unsafe Swift" talk explains how to do this.
But you do not need to take responsibility for type safety.
UnsafePointer's generic type parameter is enforced at compile time, making it a type-safe API.
Let's look at Swift's rules for pointer type safety to see why this works.
UnsafePointer's type parameter indicates the type of value expected to be held in memory. We call this a typed pointer. In Swift, the rule for typed pointers is strict and simple. Conceptually, the memory state includes the type that a memory location is bound to. That memory location can only hold values of that type. As a type-safe API, UnsafePointer only reads values of that type from memory, and UnsafeMutablePointer only reads or writes values of that type.
It may be natural to think that pointer types won't matter, as long as the bytes are laid out in memory correctly. And in C, it's not uncommon to cast pointers to different types, with both pointers continuing to refer to the same memory.
Whether that's actually legal in C depends on various special cases.
In Swift, accessing a pointer whose type parameter does not match its memory location's bound type is always undefined behavior.
To guard against this, Swift does not allow casting pointers in the familiar C style. This way, pointer types are enforced at compile time by Swift's type system. There's no need to store extra runtime information, extra type information in memory or perform extra runtime checks. Let's look at how memory is bound to a type and where typed pointers come from. If you declare a variable of type Int and ask for a pointer to the variable's storage, you'll get back a pointer-to-Int consistent with the variable declaration. Array storage is bound to the array element type. And of course, asking for a pointer into array storage gives you a pointer to the array's element type.
You can also allocate memory directly by calling the static allocate method on UnsafeMutablePointer.
Allocation binds memory to its type parameter and returns a typed pointer to the new memory.
This is different from pointers to variables and arrays because, as the state diagram shows, memory is already bound to a type even though it doesn't hold any initialized values yet. You can use the typed pointer that allocation gives you to initialize memory only to the correct type. In the initialized state, memory can be reassigned.
Assignment implicitly deinitializes the previous in-memory value and reinitializes memory to a new value of the same type.
You can deinitialize memory using the same typed pointer.
At that point, memory is still bound to the same type, but it's now safe to deallocate.
With variable and array storage, these steps are automatically handled by Swift. With direct allocation, you take responsibility for managing memory's initialized state, but Swift still ensures type safety. Since typed pointers follow simple, strict rules, you generally won't have two active pointers to the same memory location that disagree on the type.
But let's see what happens with composite types.
In this example, we have a block of memory that contains values of type MyStruct.
We can either get a pointer to the outer struct or a pointer to its property, and those pointers are both valid at the same time. We can access either one without changing the type that memory is bound to. This still obeys the same basic rule for pointer safety because when memory is bound to a composite type, it's also effectively bound to the members of that type, as they're laid out in memory.
Swift's typed pointers give you direct access to memory, but only within the confines of type safety. You can't have two typed pointers to the same memory that disagree on the type. So, if your goal is to reinterpret bytes of memory as different types, then you need use a lower-level API.
UnsafeRawPointer lets you refer to a sequence of bytes without specifying the type of values they may represent.
You take control over memory layout.
With a raw pointer, you interpret bytes as typed values when you load them from memory.
Consider a block of memory that's initialized to Int64 using a typed pointer.
It's always possible to cast from a typed pointer down to a raw pointer.
Operations on that raw pointer only see the sequence of bytes in memory. The memory's bound type is irrelevant. You can ask that raw pointer to load any type. It does that by reading the required number of bytes and assembling them into the requested type. For example, when we call load as UInt32, four bytes are loaded from the current address generating a UInt32 value.
It's even okay to load a smaller type, as long as you account for the target platform's endianness. You can also use a raw pointer to write a value's bytes into memory. Storing bytes is asymmetric with loading because it modifies the in-memory value. Unlike assignment using a typed pointer, storing raw bytes does not deinitialize the previous value in memory. So it's now your responsibility to make sure the memory doesn't contain any object references. In this example, calling storeBytes on a raw pointer extracts four bytes from a UInt32 value, writing them into the upper four bytes of an in-memory Int64 value.
When the bytes are written to memory, they're reinterpreted as the memory's bound type. So the typed pointer that already points to the in-memory value can still be used to access it.
We cannot cast a raw pointer back into a typed pointer because doing that would conflict with the memory's bound type. In this case, we would end up with both a pointer to Int64 and a pointer to UInt32 to overlapping memory.
Casting from a typed pointer is not the only way to get a raw pointer. The withUnsafeBytes API exposes a variable storage as a raw buffer for the duration of its closure.
UnsafeRawBufferPointer is a collection of bytes, just like UnsafeBufferPointer is a collection of typed values. Here, the buffer count is the size in bytes of the variable's type. The collection index is a byte offset, and reading the indexed element gives you a UInt8 value for that byte.
You can also modify a variable's raw storage.
withUnsafeMutableBytes gives you a collection of mutable bytes so you can store UInt8 values at specific byte offsets.
And just like array has a withUnsafeBufferPointer method, it also has a withUnsafeBytes method that exposes the raw storage for the array elements. The buffer size will be the array's count multiplied by the element stride. Some of those bytes could be padding for element alignment.
Foundation's data type is often used to pass around a collection of bytes. Data also has a withUnsafeBytes method that exposes the underlying raw pointer for the duration of a closure. Here, we use that to read a specific element type, UInt32, at a chosen byte offset.
You can allocate raw memory directly by calling the static allocate method on UnsafeMutableRawPointer.
Here you take on the responsibility to compute the memory size and alignment in bytes.
After raw allocation, the memory state is neither initialized nor bound to a type.
To initialize memory with a raw pointer, you need to specify the type of values that memory will hold. Initialization binds memory to that type and returns a typed pointer.
The transition to initialized memory only goes in one direction. To deinitialize memory, you need to know the type of in-memory values. So there's no way to deinitialize with a raw pointer. You can deinitialize using the typed pointer returned by initialization. We already saw the memory state diagram for typed pointers. You can use the raw pointer to deallocate the memory as long as it's in an uninitialized state. Deallocation doesn't care if a memory is bound to a type or not. Memory allocation with typed pointers is safer and more convenient, so that should be preferred.
But here's an example of why you might want to allocate raw storage instead. Let's say we want to store unrelated types in the same contiguous block of memory with variable length. After computing the total size in bytes and the alignment, we call the raw version of allocate.
That gives us a raw pointer to a contiguous block of bytes. Now we can initialize part of that memory as the header, giving us a pointer to the header type.
After adding the header's byte offset, we can initialize the remaining bytes to integers. That gives us a separate typed pointer to the region of memory holding only integers.
This storage allocation technique is great for implementing standard library types like Set and Dictionary, but not usually something you want to reach for. In general, raw pointers are a kind of power tool that are good for implementing high performance data structures, but we don't want to expose them too much.
Fiddling with byte offsets and data alignment is very tricky.
The more likely case where you'll want to use a raw pointer is when you have a buffer of bytes that's externally generated, and you want to decode those bytes into Swift types. Using UnsafeRawBufferPointer's load API, we first read a descriptor to determine the sizes and types of subsequent data. We follow up with more calls to the load API at increasing byte offsets, each time specifying whatever type we want to decode from the stream.
Raw pointers retain an important level of type safety. You take responsibility for memory layout at the point that they're used, but they don't affect when its legal to use typed pointers, so using raw pointers does not make it more dangerous to use the same memory and typed pointers. At the deepest level, Swift provides APIs that expose memory's bound type. When you use these APIs, you're taking all the responsibility for pointer type safety. Before jumping into these, see if you can use one of the higher-level APIs instead.
You'll know when you're circumventing the enforcement of pointer types because you'll need to explicitly call an API that refers to memory's bound type.
The danger of circumventing type safety is that you can easily introduce undefined behavior somewhere else in the code where typed pointers are used.
There's still just one rule to follow: access to a typed pointer needs to agree with the memory's bound type.
It is a simple rule, but it's not easy to follow because different parts of the code all need to agree on memory type, and the compiler won't be able to guide you. Let's look at some of the reasons you might use such a dangerous API, and pay attention to why each of these uses is safe.
In rare cases, code may not preserve a typed pointer.
What if we just have the raw pointer, but we know with certainty what type the memory is bound to? We should be able to tell Swift we know what we're doing and get back our typed pointer.
In this example, we have a container that holds raw memory, but we also have a variable, pointsToInt, telling us whether the memory can only hold integer values. Calling assumingMemoryBound-to on our raw pointer and giving it the Int type as an argument gives us back a typed pointer to integers.
We know this is safe because when we allocated the memory, it was bound to type Int.
Only call assumingMemoryBound-to when you can guarantee the memory will already be bound to the type you want. It's not checked at runtime. It's just a way to ask the compiler to make an assumption, so you're on the hook for the correctness of that assumption.
Here's another example where we need assumingMemoryBound-to. This time we're calling the C API pthread_create. First we initialize a context pointer with our custom ThreadContext type. When we call pthread_create, we pass it our context pointer. But when pthread_create calls back to our start routine in a new thread, it only gives us a raw pointer.
The C function declares a void star argument to the callback, which gets imported as UnsafeMutableRawPointer. That sort of thing happens in C sometimes, and there's no way to make it generally type-safe. In this case, we do know it's safe to recover a typed context pointer by calling assumingMemoryBound-to because that's the type we just bound memory to when we allocated it a few lines above. In the last couple examples, the original pointer type was erased.
Sometimes we have a typed pointer, but it's at the wrong level in a composition of types.
Here we have a function that takes a pointer to integers. If we have a tuple of Ints, we should be able to pass a pointer to the tuple's elements into that function. To get a pointer into the tuple's storage, we need to call withUnsafePointer. But that gives us back a pointer to the tuple type, which is incompatible with our function type. Memory can only be bound to one type at a time, but since the tuple type is a composite type, binding memory to a tuple type also binds it to the element types. So, we know using a pointer to integers for the tuple's storage is type-safe, but we need to use a type-unsafe API to get that pointer type. First we construct a raw pointer, deliberately erasing the type of our tuple pointer.
Then we can use assumingMemoryBound-to, just like we did before, to create a pointer to integers.
Lowering a pointer down to a member type like this requires knowing the layout of the composite type. Swift's implementation does guarantee that tuples whose elements are all the same type are laid out in a standard pattern, one value after another, according to the stride of the element type. Let's look at how this applies to struct properties.
Once again, we have a function that takes a pointer to integers. This time, instead of a tuple, we have a struct with an integer property. withUnsafePointer gives us a typed pointer to our outer struct. Using the MemoryLayout API, we compute the byte offset of the value property. By casting the struct pointer down to a raw pointer and adding that byte offset, we get a raw pointer to the value property.
A property's memory is always bound to the property's declared type, so it's safe to call assumingMemoryBound-to to get a pointer to an integer. In general, the layout of struct properties is not guaranteed, so when you get a pointer to a struct property, you can only use it to point to a single value for that property. Pointing to struct properties is common, so, fortunately, there's an easy alternative that avoids unsafe APIs. When you pass the property as an inout argument, the compiler implicitly converts it to the unsafe pointer type declared for that function argument. assumingMemoryBound-to tells the compiler to make an unchecked assumption about the memory's bound type. The bindMemory API actually lets you change memory's bound type. If the memory location was not already bound to a type, it just binds the type for the first time. If the memory is already bound to a type, then it rebinds the type, and whatever values were in memory take on the new type.
Say we allocate a block of memory to hold two UInt16 values. Then we ask for a raw pointer to that block of memory. By calling bindMemory on that raw pointer, we change the type in place to a single Int32 value. This is just a bitwise conversion, so you don't get any of the safety checks that happen with normal type conversion. In fact, nothing needs to happen at runtime.
bindMemory is really a declaration to the compiler that the type has changed at that memory location.
bindMemory returns an Int32 pointer that should be used to access the memory now. Accessing the old UInt16 pointer is undefined.
At any single point in the program, a memory location is only bound to a single type. Changing the memory's bound type doesn't physically modify memory, but you should still think of it as changing a global property of the memory state.
This isn't type-safe for two reasons. First, it reinterprets the raw bytes in place. So, just like when you're using a raw pointer, you're taking responsibility away from Swift for the layout of types in memory.
But rebinding memory is more dangerous than using raw pointers because it also invalidates existing typed pointers. Their pointer address is still valid, but accessing them is undefined while memory is bound to the wrong type. When you have a pointer into storage for an object with a declared type, like variables, arrays, and other collection types, using that pointer to rebind memory can invalidate the object itself.
The bindMemory API is really a low-level language primitive in Swift.
It's not intended for regular code.
In reality, though, there are situations where you want to rebind the memory type.
This happens when you have multiple external APIs that disagree on the type of some data, and you want to avoid copying the data back and forth. It's something that tends to come up with C APIs where pointer type safety was not carefully considered. Here we have a function that takes a UInt8 pointer, and we have pointer into memory of type Int8.
Swift enforces pointer types, so it won't let us pass that pointer into that function. We could allocate a new block of memory with the correct type and copy the data.
That's safe with regard to pointer types but slower. Since we only need to reinterpret memory for the duration of a call, we can use Swift's withMemoryRebound to API.
Just like with UnsafePointer, withMemoryRebound to gives you a pointer that's guaranteed to be valid for the scope of its closure. We know it's safe to rebind memory within the closure because our Int8 pointer isn't used anywhere inside the closure. When the closure returns, withMemoryRebound to rebinds memory back to the original Int8 type. This makes it independent of typed pointer access in surrounding code. We can prove it's safe to use just by reasoning about the code within the closure. The withMemoryRebound to API makes binding memory safe with respect to surrounding code, but it has some strict limitations. Because of these, you still may need to call bindMemory directly. When you do that, use the same technique to reason about safety. Only use bindMemory to get a pointer within a controlled scope where you know the code isn't accessing the same memory with an old pointer. When the scope ends, make sure to rebind memory back to the original type before other code can access the same memory using a previously obtained pointer. Let's recap the memory-binding APIs.
assumingMemoryBound-to is the intended way to recover a typed pointer from a raw pointer. It's dangerous because you need to know the memory is already bound to that type. bindMemory is a low-level primitive that changes the memory's bound type state.
It's especially dangerous because it can cause undefined behavior when typed pointers are accessed elsewhere in the code. withMemoryRebound to is a much safer way to temporarily bind memory when it's necessary. It's useful for calling C APIs that disagree on types without copying the underlying memory.
The most common misuse of the bindMemory API is simply to read a different type from memory. This code calls bindMemory to get a pointer of the type it wants to read. That typed pointer is only needed to read a value.
But in the process of creating that pointer, we've changed memory state and probably invalidated other pointers. When you just want to reinterpret a type, UnsafeRawPointer's load API is a solution that avoids the pitfalls of pointer type. You only need to take responsibility for memory layout. The solution works wherever you need it, so if you have a typed pointer to the memory, you can cast it to a raw pointer. And if you have a variable, an array, or a Data object, the withUnsafeBytes method directly gives you access to a raw buffer. Let's say you want to view a region of memory as sequence of elements with a specific element type, but the underlying storage is exposed as a raw pointer and may be viewed as different types by different parts of the code. You could easily create a wrapper around that raw pointer to preserve your element type. Let's call it a BufferView. We'll add the Unsafe prefix to the name, so we don't need to automatically manage memory and we'll limit boundary checks to the debug build. To create a BufferView over a raw buffer, we compute the number of elements that fit in the buffer based on the element stride.
And of course, we add preconditions to verify the buffer has the correct number of bytes and alignment. Now, to read an indexed element, we just compute its byte offset and ask the raw buffer to load our element type. Since loading from raw memory is safe with respect to pointer types, we don't need to worry about how other code views the same memory. Our BufferView lets us reinterpret the sequence of bytes safely, while retaining the element type, so there's no need to use a typed pointer. To end, let's review our strategies for handling pointer types. The best strategy is to avoid using pointers whenever you can.
In the rare case you need to reinterpret the same memory location as a different type, you should choose carefully.
Since typed pointers always need to match the memory's bound type, it's best not to use them to reinterpret types.
This can be hard to remember though because C code often handles this by casting pointer types.
Instead, Swift provides APIs based on raw pointers for that purpose.
These are useful APIs even in pure Swift code.
For example, you may need to decode values from a byte stream.
Or you might implement a container like Set or Dictionary that holds different types in contiguous memory. I hope you enjoyed hearing about pointer type safety in Swift and can see it's not as mysterious as it may look. Thanks for watching.
-
-
5:44 - Images: undefined behavior can lead to data loss
struct Image { // elided... } // Undefined behavior can lead to data loss… struct Collage { var imageData: UnsafeMutablePointer<Image>? var imageCount: Int = 0 } // C-style API expects a pointer-to-Int func addImages(_ countPtr: UnsafeMutablePointer<UInt32>) -> UnsafeMutablePointer<Image> { // ... let imageData = UnsafeMutablePointer<Image>.allocate(capacity: 1) imageData[0] = Image() countPtr.pointee += 1 return imageData } func saveImages(_ imageData: UnsafeMutablePointer<Image>, _ count: Int) { // Arbitrary function body... print(count) } var collage = Collage() collage.imageData = withUnsafeMutablePointer(to: &collage.imageCount) { addImages(UnsafeMutableRawPointer($0).assumingMemoryBound(to: UInt32.self)) } saveImages(collage.imageData!, collage.imageCount) // May see imageCount == 0 -
10:06 - Direct memory allocation
func directAllocation<T>(t: T, count: Int) { let tPtr = UnsafeMutablePointer<T>.allocate(capacity: count) tPtr.initialize(repeating: t, count: count) tPtr.assign(repeating: t, count: count) tPtr.deinitialize(count: count) tPtr.deallocate() } -
14:24 - Using a raw pointer to read from Foundation Data
import Foundation func readUInt32(data: Data) -> UInt32 { data.withUnsafeBytes { (buffer: UnsafeRawBufferPointer) in buffer.load(fromByteOffset: 4, as: UInt32.self) } } let data = Data(Array<UInt8>([0, 0, 0, 0, 1, 0, 0, 0])) print(readUInt32(data: data)) -
14:37 - Raw allocation
func rawAllocate<T>(t: T, numValues: Int) -> UnsafeMutablePointer<T> { let rawPtr = UnsafeMutableRawPointer.allocate( byteCount: MemoryLayout<T>.stride * numValues, alignment: MemoryLayout<T>.alignment) let tPtr = rawPtr.initializeMemory(as: T.self, repeating: t, count: numValues) // Must use the typed pointer ‘tPtr’ to deinitialize. return tPtr } -
15:43 - Contiguous allocation
func contiguousAllocate<Header>(header: Header, numValues: Int) -> (UnsafeMutablePointer<Header>, UnsafeMutablePointer<Int32>) { let offset = MemoryLayout<Header>.stride let byteCount = offset + MemoryLayout<Int32>.stride * numValues assert(MemoryLayout<Header>.alignment >= MemoryLayout<Int32>.alignment) let bufferPtr = UnsafeMutableRawPointer.allocate( byteCount: byteCount, alignment: MemoryLayout<Header>.alignment) let headerPtr = bufferPtr.initializeMemory(as: Header.self, repeating: header, count: 1) let elementPtr = (bufferPtr + offset).initializeMemory(as: Int32.self, repeating: 0, count: numValues) return (headerPtr, elementPtr) } -
18:03 - Using assumingMemoryBound(to:) to recover a typed pointer
func takesIntPointer(_: UnsafePointer<Int>) { /* elided */ } struct RawContainer { var rawPtr: UnsafeRawPointer var pointsToInt: Bool } func testContainer(numValues: Int) { let intPtr = UnsafeMutablePointer<Int>.allocate(capacity: numValues) let rc = RawContainer(rawPtr: intPtr, pointsToInt: true) // ... if rc.pointsToInt { takesIntPointer(rc.rawPtr.assumingMemoryBound(to: Int.self)) } } -
18:40 - Calling pthread_create
// Use assumingMemoryBound to recover a pointer type from a (void *) C callback. /* func pthread_create(_ thread: UnsafeMutablePointer<pthread_t?>!, _ attr: UnsafePointer<pthread_attr_t>?, _ start_routine: (UnsafeMutableRawPointer) -> UnsafeMutableRawPointer?, _ arg: UnsafeMutableRawPointer?) -> Int32 */ import Darwin struct ThreadContext { /* elided */ } func testPthreadCreate() { let contextPtr = UnsafeMutablePointer<ThreadContext>.allocate(capacity: 1) contextPtr.initialize(to: ThreadContext()) var pthread: pthread_t? let result = pthread_create( &pthread, nil, { (ptr: UnsafeMutableRawPointer) in let contextPtr = ptr.assumingMemoryBound(to: ThreadContext.self) // ... The rest of the thread start routine return nil }, contextPtr) } -
19:26 - Pointing to tuple elements
func takesIntPointer(_: UnsafePointer<Int>) { /* elided */ } func testPointingToTuple() { let tuple = (0, 1, 2) withUnsafePointer(to: tuple) { (tuplePtr: UnsafePointer<(Int, Int, Int)>) in takesIntPointer(UnsafeRawPointer(tuplePtr).assumingMemoryBound(to: Int.self)) } } -
20:26 - Pointing to struct properties
func takesIntPointer(_: UnsafePointer<Int>) { /* elided */ } struct MyStruct { var status: Bool var value: Int } func testPointingToStructProperty() { let myStruct = MyStruct(status: true, value: 0) withUnsafePointer(to: myStruct) { (ptr: UnsafePointer<MyStruct>) in let rawValuePtr = (UnsafeRawPointer(ptr) + MemoryLayout<MyStruct>.offset(of: \MyStruct.value)!) takesIntPointer(rawValuePtr.assumingMemoryBound(to: Int.self)) } } -
21:17 - bindMemory(to:capacity:) invalidates pointers
func testBindMemory() { let uint16Ptr = UnsafeMutablePointer<UInt16>.allocate(capacity: 2) uint16Ptr.initialize(repeating: 0, count: 2) let int32Ptr = UnsafeMutableRawPointer(uint16Ptr).bindMemory(to: Int32.self, capacity: 1) // Accessing uint16Ptr is now undefined int32Ptr.deallocate() } -
23:13 - withMemoryRebound(to:capacity:) API
func takesUInt8Pointer(_: UnsafePointer<UInt8>) { /* elided */ } func testWithMemoryRebound(int8Ptr: UnsafePointer<Int8>, count: Int) { int8Ptr.withMemoryRebound(to: UInt8.self, capacity: count) { (uint8Ptr: UnsafePointer<UInt8>) in // int8Ptr cannot be used within this closure takesUInt8Pointer(uint8Ptr) } // uint8Ptr cannot be used outside this closure } -
25:49 - BufferView: Layering types on top of raw memory
struct UnsafeBufferView<Element>: RandomAccessCollection { let rawBytes: UnsafeRawBufferPointer let count: Int init(reinterpret rawBytes: UnsafeRawBufferPointer, as: Element.Type) { self.rawBytes = rawBytes self.count = rawBytes.count / MemoryLayout<Element>.stride precondition(self.count * MemoryLayout<Element>.stride == rawBytes.count) precondition(Int(bitPattern: rawBytes.baseAddress).isMultiple(of: MemoryLayout<Element>.alignment)) } var startIndex: Int { 0 } var endIndex: Int { count } subscript(index: Int) -> Element { rawBytes.load(fromByteOffset: index * MemoryLayout<Element>.stride, as: Element.self) } } func testBufferView() { let array = [0,1,2,3] array.withUnsafeBytes { let view = UnsafeBufferView(reinterpret: $0, as: UInt.self) for val in view { print(val) } } }
-