-
Optimize Metal apps and games with GPU counters
GPU counters can help you precisely measure GPU utilization to pinpoint bottlenecks and optimize workloads for your Metal apps and games. We'll walk you through the tools available in the Metal System Trace instrument and Metal Debugger in Xcode 12 to profile your graphics workload, and show you how to use collected data to discover underused and overworked stages of your GPU pipeline. Discover how you can act on that data to improve your app's capabilities.
To get the most out of the session, you should understand the tile-based deferred rendering architecture of Apple GPUs and familiarize yourself with our recommended best practices for performance optimization. For a primer, check out “Delivering optimized Metal apps and games” and “Harness Apple GPUs with Metal.”
Once you've learned how to act on GPU counter data to optimize your Metal apps, see how you can use those skills to "Bring your Metal app to Apple silicon Macs" and "Optimize Metal Performance for Apple silicon Macs".Resources
Related Videos
WWDC23
WWDC21
- Discover Metal debugging, profiling, and asset creation tools
- Optimize high-end games for Apple GPUs
WWDC20
- Bring your Metal app to Apple silicon Macs
- Gain insights into your Metal app with Xcode 12
- Harness Apple GPUs with Metal
- Optimize Metal Performance for Apple silicon Macs
WWDC19
WWDC18
-
Search this video…
Hello and welcome to WWDC.
Guillem Vinals Gangolells: Hello and welcome to this session. I am Guillem Vinals from the Metal Ecosystem team. Today I will talk about how to optimize your game or app using GPU performance counters. This talk will walk you through the architecture of modern Apple GPUs and explain its performance metrics. We will start with an introduction to both our GPUs and the performance counters. Then we will cover several groups of GPU performance counters.
We'll talk about performance limiters, memory bandwidth, occupancy, and hidden surface removal. All of these GPU performance counters will help us understand the Apple GPUs much better. We will start with an introduction to the GPU and its performance counters. The GPU is a central part of Apple processors such as A13. So let's do a quick recap of Apple GPUs first.
Apple GPUs are part of the Apple processors, which are very power efficient. Apple processors have unified memory architecture where the CPU and the GPU share System Memory. The GPU has on-chip Tile Memory. Notice that the GPU does not have dedicated Video Memory, so bandwidth could be a problem if the content has not been tuned. To be fast and efficient without Video Memory, our GPUs are TBDRs, or Tile Based Deferred Renderers.
This diagram shows the Apple GPU rendering pipeline. We have covered the pipeline in more detail in other talks, so I will just provide a quick overview. The rendering pipeline has two distinct phases: First, Tiling, where all of the geometry will be processed. Second, Rendering, where all of the pixels will be processed. So let's recap both phases, starting with the Tiling Phase.
During the Tiling Phase, the GPU will, for the entire render pass, split the viewport into a list of tiles, shade all of the vertices, and bin the transformed primitives into tiles. Now, the GPU is going to shade all of these tiles separately. Each GPU core will shade at least one tile at a time.
For each tile in the render pass, the GPU will execute the load action, rasterize and compute the visibility for all of the primitives, shade all of the visible pixels, and then execute the store action.
This is how our design can scale so well. The more GPU cores we have, the more tiles we can shade at the same time. Before concluding this overview, let's have a closer look at the GPU configuration.
Apple GPUs have multiple cores. A GPU core contains a Shader Core, a Texture Unit, and a Pixel Backend, as well as a dedicated pool of Tile Memory. Notice that Tile Memory is just part of the hierarchy. Both the ALU and the TPU have dedicated L1s. All of the GPU cores share a last level cache. And then, of course, there's System Memory which is basically DRAM. This talk will assume some familiarity with the Apple TBDR architecture as well as the Metal Best Practices. Check out these two talks to brush up on both topics. I would actually recommend you to start with "Harness Apple GPUs with Metal" and then look at the Best Practices. So, let's build up some context around GPU profiling first. In order to render a frame, the GPU needs to process multiple render passes. Each render pass will be executed across multiple GPU cores. And each GPU core will, in turn, process different tasks, such as shading or texturing.
All of those tasks will be executed on different hardware units, such as the ALU or the TPU. And of course, every single one of these units has a different throughput which uses different metrics. For example, we will use FLOPS to measure the ALU throughput or megabytes per second to measure the TPU throughput. So, there's multiple metrics to look at. What metrics should we look at then? Well, enter GPU performance counters. GPU performance counters will measure how the GPU is being utilized. Will help us find if the GPU doesn't have enough work, or if the GPU has too much work. Will help us identify performance bottlenecks, and also help us optimize the commands that take the longest. Cool, so let's review the GPU performance counters for our Apple GPUs. Well, that's actually quite a list. There's over 150 GPU counters to look at. Maybe at this point, there's just far too much data to parse.
So how can we make sense of all those numbers? The answer is tooling. Our GPU tools will help you navigate all that data, starting with Metal System Trace, which is part of Instruments. You will want to use Metal System Trace for performance overview. You will see both the CPU and the GPU timelines. Your workload will be affected by thermals and dynamic system changes.
Metal System Trace is already part of the Game Performance template in Instruments. You can also enable GPU performance counters which can be used to identify potential GPU or memory bottlenecks at different points during the frame. Of course, there's also the Metal Debugger which is part of Xcode.
You will want to use this tool for a deep performance investigation. You will see both a detailed GPU timeline as well as the Metal API usage of your game. And your workload will be unaffected by thermals or dynamic system changes. Xcode also supports GPU performance counters and exposes every single one of them at encoder granularity.
There's also a large subset of counters available per draw call.
Xcode is where all of the counters are listed, so it's definitely the right tool to correlate metrics. So what exactly do those values mean? By now you know that there are a ton of counters, and that the tools will help you focus on the important ones.
The rest of the talk will walk you through different groups of counters and explain them in more detail.
We will start with performance limiters, arguably the GPU counters you should always look at first. Limiters are very important due to the parallel nature of GPUs.
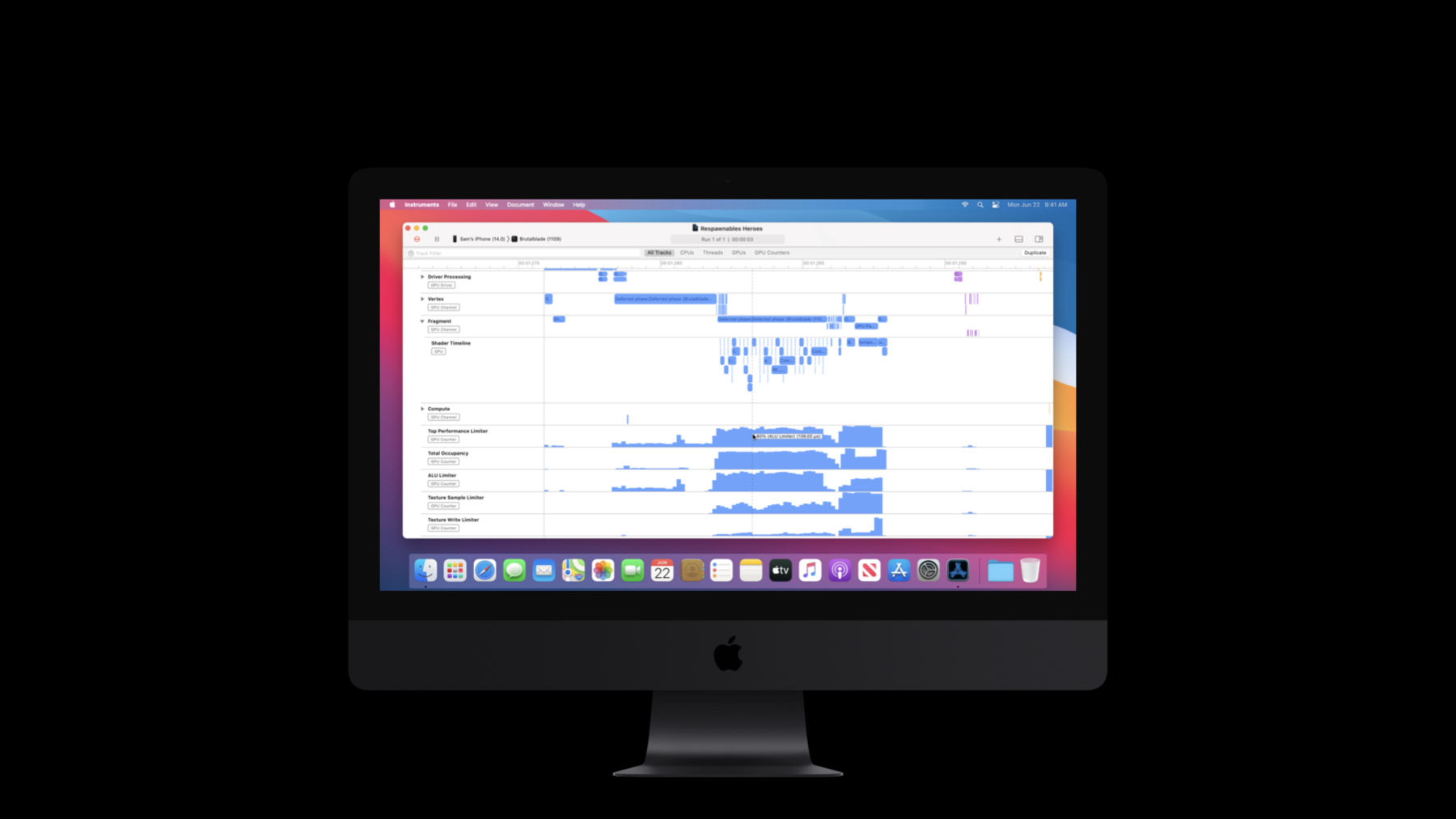
The GPU can execute a ton of work in parallel: arithmetic, memory accesses, as well as rasterization tasks. The limiter counters will measure the activity of multiple GPU subsystems. They will help you find work being executed, as well as find stalls that prevent work from being executed. Remember, the GPU is only as fast as the slowest part. Limiters will point you to that part for you to investigate. Time for a demo. Please welcome Sam for a cool demo of Metal System Trace. Thanks, Guillem. I've got my iPad Pro, and I'm playing Respawnables Heroes, a game by our friends over at Digital Legends. It looks great. It's got reflections, beautiful dynamic lighting with shadows, and many more post-processing effects.
But to get a sense of how well it's running, I'm going to show you how to record the performance limiters in Instruments. Let's switch back to my computer where I've already got Instruments open.
First, I'll select the Game Performance template. Then, I'll make sure that my device is selected and the game. I'm gonna long-press on the Record button and click on Recording Options.
Then, I'll switch to the Metal Application recording options and make sure that Performance Limiters is selected under the GPU Counter Set.
I'm also going to enable the new Shader Timeline, and you'll see why in a sec. But for now, let's click on the Record button.
Instruments is now recording the game, and when we're done, we can click Stop.
The Game Performance template gathers a lot of information about the state of the system, but for now, we're interested in the GPU.
So I'm going to disclose the A12Z track to see what was running.
I'm going to hold Option and left-click and drag to zoom into a frame.
We can now see a timeline of all of the command buffers and encoders that were running, color-coded by frame.
We can see that Respawnables Heroes first renders a shadow map. This is then followed by a Deferred Phase Encoder where it looks roughly 50-50 split between the vertex and fragment shader, but the fragment shader is a little bit longer. In this case, 1.29 milliseconds. After this is a bunch of post-processing effects.
Now, I'm going to take a close look at the Deferred Phase Encoder because it's taking the longest time. So I can disclose the fragment track to see the new Shader Timeline...
which shows me which shaders are running at certain sample times during the execution of my command encoder.
This fine-grained detail makes it really easy to see and identify longer-running shaders, and helps to explain why a given encoder is taking a certain amount of time. If I select the track and a region, I can actually see which shaders were running in the table below, along with how many samples they were running for and an approximate GPU time.
We can also see the performance limiters in Instruments.
So, the first track is the top performance limiter track. Now, if I scrub my mouse over this track, we can see that during the deferred phase, the ALU Limiter is the highest. And during the post-processing, it's the Texture Sampler.
Now, this makes a lot of sense. But don't worry if you don't know what they mean. Guillem will later explain each limiter and what to do if you see a high value.
Below the Top Performance Limiter tracks are the individual limiters themselves, such as ALU, Texture Sampler, and many, many more.
Now, back to Guillem.
Excellent. Thank you, Sam. Now we know where to find the GPU performance limiters. So, let's focus on some of them.
We will talk about Arithmetic, Texture Read and Write, Tile Memory Load and Store, Buffer Read and Write, GPU Last Level Cache, and Fragment Input Interpolation limiters. As we go through the list, we will also be putting them in the context of the Apple GPU. Also, I will show you how to find them in Xcode, starting with the ALU limiter. Before looking at the limiter, we will build some context first. The ALU is part of the shader core. It processes arithmetic operations, both bit-wise and relational operations. It is optimized for both floating-point arithmetic and coherent execution. So, let's review that. Let's review the relative throughput of the different operations first. At the top, we can see 16-bit floating point operations, which are run at double rate. Then, we also have 32-bit floating point operations, which are run at full rate.
Finally, we also have 32-bit integer and complex operations, which are run at half rate or less.
For example, we should prefer F16 over F32 when possible.
Also, watch out for complex operations. The best case is shown here. Some complex operations such as a square root will have an actually lower rate. Great. So let's talk about the execution model of our shader core.
Each shader core has multiple SIMD units, as well as dedicated Tile Memory and a pool of Register Memory. Each SIMD unit has 32 threads, and each thread in the SIMD executes the same instruction. This is very important when it comes to authoring shaders.
Each SIMD lane has 32 threads but a single program counter. This is ideal when all of the threads execute the same instruction.
In this case, the condition "a" is equal for all of the threads. That's what we call coherent execution. All of the threads will execute the same instruction. And the total time to execute this program will be 40 cycles. There is no penalty for the "if" branch other than the extra temporary registers required and not utilized.
In this case, we have divergent execution. Some of the threads will evaluate "a" to "true." All of the SIMD lane has to execute all of the instructions. The threads that don't take the branch will mask out the execution, but still spend the cycles. In this case, the total cost will be 70 cycles. Notice that we have the extra 30 cycles from the "if" condition. One last note on execution model. There are some cases where only a few threads of a SIMD will actually need to run. This will, of course, have an impact on performance, since most of the threads are wasting cycles. Okay, so with that in mind, we can now look at the limiter. So what can we do if we are actually limited by the ALU? Well, in most cases, we may want to celebrate. That's exactly what we want: the GPU is crunching numbers, and that's exactly what the GPU is for. But what if we actually want to reduce the ALU load? In which case, we will want to replace complex calculations with either approximations or lookup tables. Also, try to replace floats, full-precision by half-precision. Try to avoid implicit conversions. Avoid FP32 inputs such as textures or buffers. And also make sure that all of the shaders are compiled using the Metal "-ffast-math" flag.
Notice, though, that a high limiter value does not mean that the workload is efficient. It's a great step though. For example, we can be 100% ALU limited but only stay at 50% utilization if all we are doing are FP32 operations. Xcode is the ideal tool to find out about what is causing a limiter to be high or low. For example, we can filter by ALU in order to see all of the arithmetic-related counters. Great. So let's move on to Texture Read and Write. Before we talk about the limiter, we should understand Metal textures first. Metal textures are backed by Device Memory. They are always read by the Texture Unit, which does have a dedicated L1, as well as support for multiple filtering and compression modes. Textures, on the other hand, are written by the Pixel Backend. Notice that the Texture Unit and Pixel Backend are different hardware blocks, so we should review them separately, starting with the Texture Processing Unit, or TPU. The TPU reads texture data. When the render pass executes the LoadActionLoad for an attachment, or when we are explicitly reading or sampling from a shader. It is optimized for gather operations as well as regular pixel formats.
The pixel format has a direct impact on the sampling rate. Particularly, watch out for 128-bit formats such as RGBA32Float, since those are sampled at quarter rate. Oftentimes, these high precision pixel formats are used for noise textures or lookup tables for post-process effects.
The pixel filtering rate is also important and should be kept in mind. It could be a problem when we have very high levels of anisotropy.
Now, let's talk about compressed formats. Apple GPUs support both block-compressed pixel formats, such as PVRTC or ASTC, as well as lossless compression of conventional pixel formats. In this diagram, we see an example of a block-compressed HDR environment map. The small Cube Map would require three megabytes if left uncompressed. Using ASTC HDR, which is supported by A13 GPUs, allows us to massively reduce the memory footprint and bandwidth, of course, for these assets. So what can we do if we see a high Texture Sample limiter? Well, you will want to use mipmaps if minification is likely occurring. Also, consider changing the filtering options. Try to use lower anisotropic sample count, for example. Consider using smaller pixel sizes. And of course, make sure you are leveraging texture compression. Use block-compression such as ASTC for assets, and lossless texture compression for textures generated at run-time. Same as we did before, we can use Xcode to find more about texture reads. In this case, we can select the "Texture" group to see all of the texture-related counters. Great. Now let's move on to texture write. Textures are written into Device Memory by the Pixel Backend. The Pixel Backend will write texture data when a render pass executes the StoreActionStore for an attachment. Or when we explicitly write into a texture from a shader. It is also optimized for coherent writes, so you should avoid all kinds of divergent writes, such as writing to different array indices or different tiles. There really is not much to say on the write rates themselves. Try to keep a small pixel size and potentially watch out for MSAA. The most important thing to bear in mind is that the Pixel Backend and Texture Processing Units are different hardware blocks, so they have different throughput altogether. You may want to make sure that the lower texture write rate is not actually the main limiter for your shaders. So what can we do if we see a high texture write limiter value? Based on the rate, you should watch out for the pixel sizes, as well as the number of unique MSAA samples per pixel. Also, try to optimize for coherent writes. Xcode is a great tool to narrow down the search. We can also use more complex filters such as "Texture" and "Write" to get all of the texture-write counters found across different groups. Great. So, moving on to the next limiter: Tile Memory Load and Store. To understand this limiter, first, we need to understand Tile Memory. Tile Memory is a set of high-performance memory that stores Threadgroup and Imageblock data. Tile Memory is accessed when reading or writing pixel data from the Imageblock, such as when using tile shaders. It's also accessed when reading or writing data from Threadgroup Memory, for example, when you're using compute dispatches, and it is also accessed when reading or writing to render pass color attachments, such as when using programmable blending, or even when enabling blending on a rendering pipeline. So what can we do if we see a high value? This may be the case when writing complex compute shaders that explicitly leverage threadgroup memory. If such is the case, you will want to reduce the number of threadgroup atomics, consider using threadgroup parallel reductions, or SIMD lane operations instead. Also, make sure to align threadgroup memory allocations and accesses to 16 bytes.
Finally, consider reordering your memory access patterns for higher efficiency. Tile Memory is referred to in the tools as Imageblock and Threadgroup Memory. This is the case for both our tools and documentation. So in this case, typing "Imageblock" in Xcode will reveal all of the Tile Memory counters. On to the next limiter, which is Buffer Read and Write. Same as we did with Textures, we should first understand Metal buffers. Metal buffers are also backed by Device Memory. But Metal buffers are accessed only by the Shader Core, which does have a dedicated L1 as well as support for different address spaces. Address spaces for buffer data are device for read-write data or constant for read-only data. For example, you will want to use the device address space for data which is indexed per fragment or per vertex, and use constant address space for data that is utilized by many vertices or fragments. So what can we do if we are limited by Buffer Read or Write? You may actually want to pack data more tightly. Try to use smaller types. Also, try to vectorize load and store, and, if possible, avoid device atomics and register spills altogether. Another interesting optimization could be to use textures to balance the workload since both the ALU and the TPU have different caches. Xcode can also help us find whether Buffer Read or Write is a problem. By typing "Buffer" in the filter, you will see all of the Buffer Read and Write counters, as well as the limiter, of course. Great. So let's talk about GPU Last Level Cache or GPU LLC. The GPU Last Level Cache is shared across all GPU Cores. It caches both texture and buffer data, as well as storing device atomics. It is optimized for spatial and temporal locality. This is a great opportunity to review the relative peak rates of the memory hierarchy of a GPU core. Based on these rates, we should actually favor Tile Memory over the GPU LLC and also watch out for atomic operations. So what can we do if we are being limited by the GPU Last Level Cache? Well, if texture or buffer limiters also show a high value, try to optimize this first. Potentially consider reducing the size of working sets. If your shaders are using device atomics, try to refactor code to use threadgroup atomics instead. Also, make sure to access memory with better spatial and temporal locality. Typing "Last Level Cache" will, very unsurprisingly, reveal all of the GPU LLC counters, including the limiter, of course. Great! On to the last limiter, Fragment Input Interpolation. Same as we did before, we should first understand Fragment Input Interpolation.
Fragment Input is interpolated during the rendering stage by the Shader Core. The Shader Core has a dedicated Fragment Input Interpolator, which is both fixed function and full precision. Due to the fixed function nature of the Fragment Input Interpolation, there's not much we can do if we see a high limiter value. We can only remove vertex attributes passed to the Fragment Shader. You can find the Fragment Shader Interpolation Limiter in Xcode, of course. Now it's a great time to point out to some of our documentation on the topic of both limiters and developer tools. Notice that I have also included here some articles about memory bandwidth and occupancy, which we will cover next. This next section is about understanding memory bandwidth. This is a very important GPU counter since many of the TBDR optimizations have something to do with saving bandwidth. Remember that Device Memory is backed by System Memory on Unified Memory Systems such as the A13. It will store both Metal resources as well as the output from the tiling phase. Also, it will be cached by the GPU Last Level Cache.
The Memory Bandwidth GPU counter measures transfer from System Memory to the actual GPU itself. For example, when we read buffer or texture data. Notice, though, that there's also System Level Cache, or SLC. This means that oftentimes you may see bursts of data transfer at a higher rate than the actual DRAM throughput. So what can we do if we see a high Memory Bandwidth GPU counter? Well, if texture or buffer limiters show a high value, you should try to optimize those instead. Also, make sure that the load and store instructions are efficient, so only load data needed by the current render pass, and only store data needed by future render passes. Of course, this is a great moment to remind you that you should always leverage texture compression. Use block-compression, ASTC, for assets and lossless compression for textures generated at run-time. Texture compression really has a big impact on the memory bandwidth.
Great. Moving on. Another good set of counters to look at is occupancy.
Occupancy measures how many threads are executed out of the total thread pool. Latency, in this context, is the time it takes for a task to be completed. For example, the left diagram shows a GPU where only half of the thread pool is executing. The diagram to the right shows a case of 100% occupancy where the GPU runs as many tasks as it can. So, why is occupancy important? Well, GPUs do hide latency by switching between available threads. GPUs will, of course, create new threads when there are enough internal resources to do so or when there are commands scheduled to run. So, if a task has high latency, for example, due to memory transfers, the GPU will switch between available threads to avoid stalling. Of course, all of that while creating new threads when possible. Occupancy will depend, in large part, on some static properties of the compute or rendering pipeline. So you may want to query those. You may want to query the maximum number of threads per threadgroup, the execution width of a SIMD lane, and also, the length of the threadgroup memory that needs to be statically allocated. So let's talk about the occupancy GPU counter. This GPU counter will measure the percentage of the total thread capacity being used by the GPU. This counter is actually the sum of other counters. It's the sum of Compute, Vertex, and Fragment Occupancy. Notice also that neither high or low occupancy are indicative of a problem. For example, low Vertex Occupancy is fine if there is enough Fragment Occupancy. Low occupancy is also fine if the GPU resources are being fully utilized. Overlapping work in different subsystems may increase occupancy. For example, the diagram below shows high overlap between tiling, rendering, and compute. So what can we do if we see a high occupancy GPU counter? Well, we will want to correlate occupancy measurements with data from other counters or tools. And if overall occupancy is low, this means that shaders may have exhausted some internal resources, such as tile or threadgroup memory. It could also be that threads finish executing faster than the GPU can create new ones. Also, it may be that your app is rendering to a small area or dispatching very small compute grids. Great. So now let's talk about Hidden Surface Removal, or HSR. Hidden Surface Removal, or HSR, is an early visibility pass. It is important to use the GPU counters to measure its efficiency for your game. Let's recap HSR first.
HSR allows the GPU to minimize overdraw by keeping track of the front-most visible layer for each pixel. HSR is both pixel perfect and submission order independent for opaque meshes. Notice the pixels are processed into two stages. First, Hidden Surface Removal, and then, Fragment Processing. For example, even if you draw two triangles back to front, HSR will ensure that there is no overdraw. So how can we measure Hidden Surface Removal efficiency? We will actually want to use GPU counters for that. We can use GPU counters to measure the number of pixels rasterized, the number of Fragment Shader invocations, the number of pixels stored, as well as the number of Pre-Z test fails. Overdraw, in this context, is the ratio between Fragment Shader invocations and Pixels Stored. Of course, we can minimize overdraw by reducing the number of full-screen passes, as well as reducing blending. But what else can we do? We should use HSR efficiently. You will want to draw meshes sorted by visibility state. First opaque meshes, then alpha test, discard, and depth feedback, and finally, translucent meshes. You should avoid interleaving opaque and non-opaque meshes, as well as avoid interleaving opaque meshes with different color attachment write masks. Awesome. So please welcome Sam again for another demo. Guillem's just walked us through all the limiters, what they mean, and what to do if you see a high value. So let's look at Respawnables Heroes again, specifically an older build running on my iPhone, but this time in the Metal Debugger with all of the GPU performance counters. I've already captured the frame in Xcode, and I'm looking at the summary. We can see the GPU time in the performance overview is about 12.82 milliseconds. But I want more detail, so I'm going to click on the Show Counters button to jump right into the GPU performance counters. We can now see a detailed view of the counters for each command encoder or draw call. As Guillem showed you earlier, there are a ton of counters for Apple GPUs. So we've made a bunch of improvements to the tool to help you find and organize them.
To begin with, we've reorganized the counters into groups. For instance, if you want to see all of the counters related to memory, simply click on the Memory group.
You can also filter for things. So, if I want to see every counter related to the ALU, I can filter for it.
One of the cool things about groups is that you can also create your own. So after filtering, a Save button will appear on the top right, which you can click to create your very own group.
There's also a new detail table at the bottom, which is strongly linked with the graph. So, I can select something here, and it also selects it in the table, and vice versa.
It also selects it in the navigator.
You can also sort the table by different counters. For example, to quickly find the most expensive encoder, those most bottlenecked by ALU. In this case, it's the deferred phase. The performance limiters group shows us all of the limiters. We can see that the deferred phase is mostly limited by the ALU.
If we look at the floating-point 32 utilization, we can see that it's higher than the floating-point 16 utilization. As Guillem mentioned earlier, floating-point 16 is twice as fast. So we really want to reduce that usage of floating-point 32 as much as possible to make the game run faster. What else can we look for? Guillem mentioned that memory bandwidth is pretty important. So let's focus on that and see if we can reduce it. I want to show you how easy it is to pick a limiter and use the counters to really drill down into the fine details.
So let's switch back to the memory group, and this time I'm going to sort the table by Bytes Read From Main Memory.
Once again, it's our Deferred Phase encoder. But we really want to find out why we are reading so much memory. Since an encoder is just a container, what we really want is to find out which draw is using the most memory. So let's click on the Draw button to switch the graph to Per-Draw Counters mode.
There are thousands of draw calls in this frame. But since we already knew that we're interested in the Deferred Phase encoder, we can filter the table to only show draw calls in this encoder.
Let's sort by texture, L1, by thread, which gives us the draw call that has the most L1 bytes transferred. Since clicking in the table also highlights it in the navigator, it's really easy to find the draw call. Since it's right here, disclosing the draw call, we can click on Bound Resources.
This view shows us which resources the draw call has bound, and in this case, it looks like the draw binds and reads from an RGBA16 floating-point cube map texture.
Let's check the flags.
Storage mode is shared. Ah. In this case, since we're sampling, we could change the texture storage mode to private, which would automatically enable lossless texture compression to reduce the memory bandwidth. We could even consider block compression to further reduce the bandwidth, not to mention the footprint. If private storage mode isn't an option, we can still explicitly optimize it for the GPU with a Blit Command Encoder. I encourage you to check out the "Delivering Optimized Metal Apps and Games" talk from last year's WWDC to learn more. So just like that, we've been able to use the performance counters in the Metal Debugger to drill down and discover some optimizations that can be made. If you pick a limiter and focus on optimizing it, you can use the tools to really increase your game's performance.
In this case, Digital Legends were able to make these changes amongst others, significantly increased their floating-point 16 utilization, and reduced their memory bandwidth by block-compressing texture assets. The game now runs at a steady 120 FPS on iPad Pro. It's been a pleasure. Now back to Guillem.
Thank you, Sam, for this great demo. Okay, so it's time to wrap up. Today, we have reviewed a bunch of really important GPU performance counters and put them into the context of modern Apple GPUs.
So the next step, of course, are for you to profile your game. Use what we have learned. Use the GPU performance counters to understand how the GPU is being utilized and also find the bottleneck.
You should also learn more about GPU tools. Please check the talks below, and thank you for watching.
-