-
Build customized ML models with the Metal Performance Shaders Graph
Discover the Metal Performance Shaders (MPS) Graph, which extends Metal's Compute capabilities to multi-dimensional Tensors. MPS Graph builds on the highly tuned library of data parallel primitives that are vital to machine learning and leverages the tremendous power of the GPU. Explore how MPS Graph can help express sophisticated and dynamic neural network training architectures and optimize across them to get acceleration on the GPU.
For a deeper understanding of the concepts covered in this session, check out "Metal for Machine Learning” from WWDC19.Resources
Related Videos
WWDC21
Tech Talks
WWDC19
-
Search this video…
Hello and welcome to WWDC. Hi, I am Dhruv. I am a GPU software engineer at Apple, and I am here to talk about implementing customized machine learning operations using the new Metal Performance Shaders Graph. Let us begin. MPS is a library of Metal based high performance GPU accelerated primitives for varied fields like image processing, linear algebra, ray tracing and machine learning. MPS team optimizes Metal kernels to give the best performance on each hardware across Apple's various platforms.
We have an exciting set of new features to discuss today. We'll talk about performance improvements made across MPS, discuss how to leverage the full 32-bit floating point support in machine learning... reveal the new MPSNDArray primitive, and finally, we will introduce the new Metal Performance Shaders Graph.
Allow me to go over some of the amazing improvements we added to image processing in MPS. We tuned and improved our distance transform filter. It made for 15 times faster features in Final Cut Pro. MPS also has a new edge detection primitive using the EDLines algorithm. It improved the Measure app and made it ten times faster, which enables it to do even better line segment detection in higher resolution.
We have also expanded support for our CNN primitives.
We now have full FP32 support for convolution and fully connected primitives, so developers do not need to recalculate their hyper-parameters or refactor their code to get the same accuracy. To enable this, implement the kernelWeightsDataType method on your data source provider and set it to float32.
Please refer to our previous years' talks for more details on how to implement a convolution data source provider.
There is a new MPS primitive called MPSNDArray. MPSNDArray and corresponding operations can support up to 16 dimensions, which is more than enough for machine learning and various other scientific domains. Also, there are virtually no restrictions on the dimension sizes in this new primitive as long as you can fit them in memory.
To create an MPSNDArray, first use an MPSNDArrayDescriptor to specify a shape and a data type for the elements. Then pass it to the initializer, along with the Metal device on which you wish to allocate the MPSNDArray.
MPSNDArray provides converters to and from our already existing MTLTexture based MPSImageBatch types. And it can even import and export data using your Metal buffers.
Now let's get to the meat of what we would be talking about: the new Metal Performance Shaders Graph framework.
MPSGraph sits on top of the MPS framework in the stack. We use it to extend Metal's compute functionality to multidimensional tensors.
The new MPSGraph framework will be supported on macOS, iOS, iPadOS and tvOS, same as the MPS framework. You can include the new framework in your project from the "Build Phases" tab in Xcode. It is right next to the Metal Performance Shaders framework.
We have a lot to cover. We will introduce the new MPSGraph, walk through the different APIs available to write custom compute functions, and finally, look at writing and executing machine learning training graphs.
Let's start looking at the basics of the MPSGraph.
MPSGraph represents a DAG of operations and tensors.
The operations are nodes of the graph representing a unit of computation. Here we have an example of three basic math operations: multiply, add, subtract.
Along with operations, tensors are the edges of the graph defining the dataflow in the graph. We can see in our example the tensors are flowing through our basic math operations.
This symbolic representation allows us to abstract away numerous data primitives and provide a unified interface to get the best performance on the GPU.
The MPSGraph object maintains ownership for all the tensors and operations created using methods on the graph.
MPSGraphTensors represent a symbolic abstraction of data. It consists of a shape, data type, and a reference to the operation responsible for creating the tensor.
Here we can see how to create a constantTensor simply by calling the constant method on the graph.
Operations in the graph connect with each other via three kinds of edges...
input tensors, which represent tensors that act as data inputs to the operation...
output tensors, which are created by the operation itself... and finally, a special kind of edge called control dependency.
These are a set of operations the graph would execute before the current operation even if the operation itself does not depend on these set of operations.
Just like the constant operation, operations can be created by calling simple intuitive methods on the graph. Here we see how to add two tensors in the graph.
MPSGraph provides a numerous set of operations to manipulate tensors in the graph. For example, you could reshape a one-dimension tensor into a two-dimension tensor.
You can slice apart that tensor and take a small piece of it.
You can concatenate that piece back into the original tensor to create an even bigger one.
You can transpose tensors in any dimension.
And finally, you can even create a zero-length slice. Zero-sized tensors are supported in MPSGraph. This enables some dynamic use cases like recurrent neural network operations on variable length sequences.
We support a plethora of operations on the MPSGraph, from multiple variants of convolutions and reductions to all the basic math operations you may need in your compute graphs.
Let's start putting some of these operations together to create and execute a custom compute function with our very first MPSGraph. In recent years, machine learning research has found novel ways to handle natural language processing. One such innovation was a new kind of activation function used in BERT. This activation is called Gaussian Error Linear Unit, commonly known as GeLU. For our example, we will try to implement a custom GeLU function on the GPU using MPSGraph.
This is a simple three-step process. We define the inputs to the graph, write a set of operations to perform, and finally, execute the graph on provided data.
Let's start by defining the inputs to the graph.
Our GeLU activation function consists of a single input.
Input tensors are created using placeholder operations in the graph, which, as the name suggests, act as placeholders during run time. They are replaced by caller provided input data.
We show here the API call to create an example placeholder of the type float32 with three columns and two rows.
Users might have varying sizes of inputs going into the graph known only at run time. For example, in the machine learning domain, users frequently pass in variable length sequences or differing batch sizes of input images.
For these scenarios, MPSGraph supports dynamic sizes in placeholders. Simply specify the size of the dimension as -1, and the graph will evaluate shapes from the corresponding fed inputs at run time.
If even the number of dimensions of the incoming input is unknown, simply pass a nil to the placeholder shape. MPSGraph fully supports type inference and will propagate the shapes at run time all through the graph.
Now that we have defined the inputs to the graph, we can go to step two and write out our custom compute function in the graph.
Usually, we expect to use the GeLU activation at various points in our neural network. So, for modularity, we will define a helper function on our graph which takes a tensor as an input. Let's add the necessary operations to apply the activation on the given input tensor.
First, let's define some of the constants used in our GeLU neuron.
We simply call the constant method on the graph with a scalar passed in and set it to float32 dataType.
Next up, we have a unary math operation: namely squareRoot.
MPSGraph provides basic unary math operations. We just call the squareRoot method on the graph with the half constant tensor as the input.
Now that we have our constants and inputs prepped, we start doing some compute with a couple of multiplies.
These operations implicitly support broadcasting, so the result tensor shape would be automatically inferred to be the same shape as the input to the neuron.
We pass the two input tensors into the multiplication method on the graph to do just that.
This little unary method forms the heart of the GeLU neuron, known as error function.
Once more, we simply pass in the input to the unary operation and get back the output tensor on the left-hand side, ready for further computation.
Finally, we finish off the activation with an add and a multiply.
Just as before, we create the binary math operations, and the output of the multiplication is returned from our GeLU function.
We have successfully and quite easily constructed a graph of operations representing our GeLU neuron.
We can finish off with the third and final step, which is seeing how we execute this graph.
Running the graph is very easy. Firstly, we pass the dictionary of feeds which map to the placeholders in the graph.
Next, we specify the list of target tensors we want the graph to evaluate and return the results for. These results are returned in a dictionary on the left-hand side.
Finally, the users can optionally pass a list of target operations which the graph guarantees to execute.
As we saw, at execution time, developers can feed placeholders by passing MPSGraphTensorData objects, which in turn returns a set of outputs using the same MPSGraphTensorData object.
MPSGraphTensorData helps abstract over the numerous data primitives available in the Metal ecosystem. You can initialize it with a Metal buffer.
You can create a four-dimensional tensor data using an MPSImageBatch.
We abstract over MPSVectors and MPSMatrices as well. And finally, the new MPSNDArray primitive can also be used to initialize the MPSGraphTensorData.
So, we put it all together.
We start by creating an MPSGraph. We define the inputs to the graph with placeholders. We call our GeLU helper function to write out the necessary operations in the graph.
Finally, we execute the graph by passing the input data as feeds requesting the GeLU tensor as a target. And that's all that is needed to execute a custom compute function on any multidimensional tensor on the GPU.
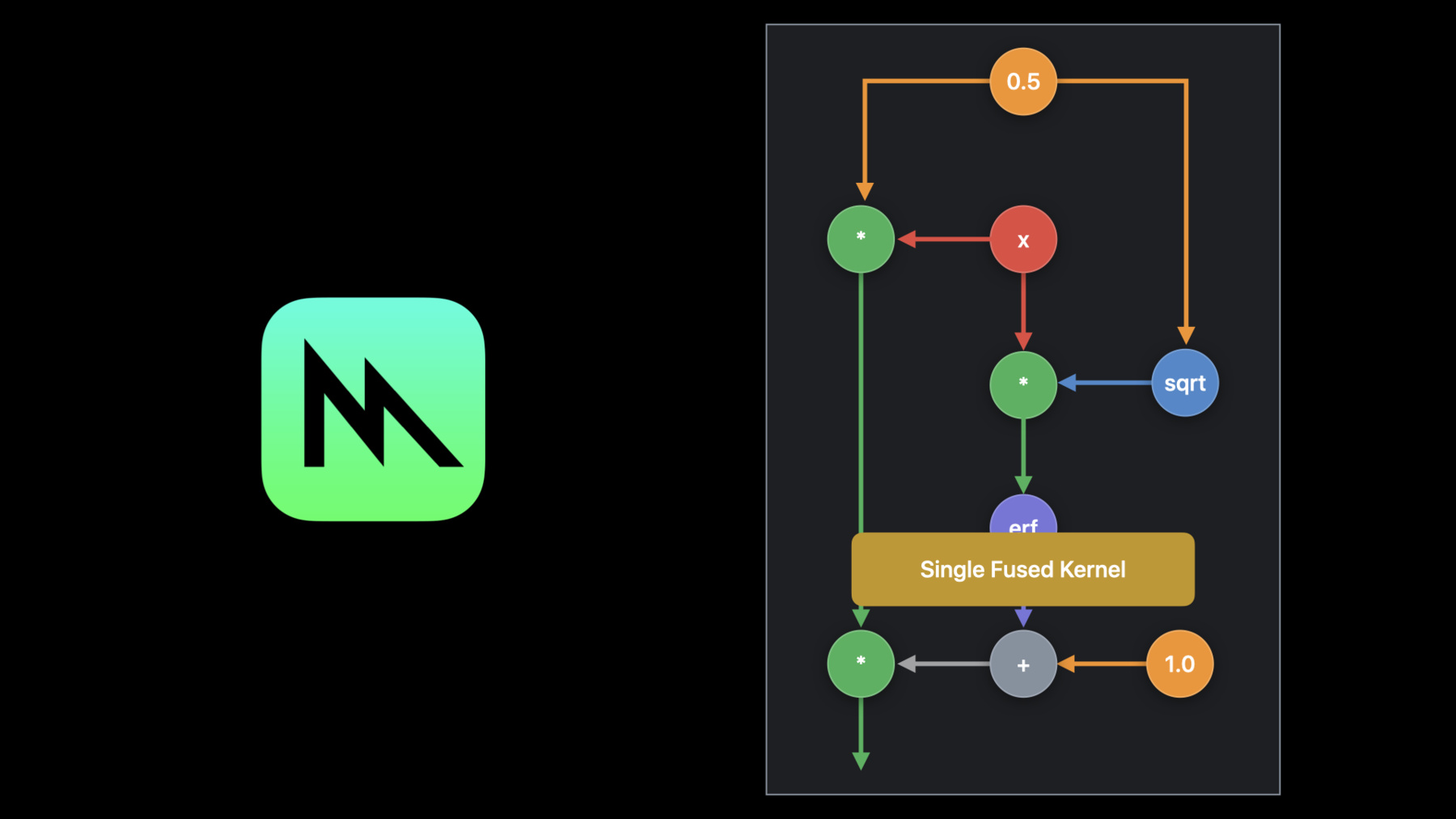
We just witnessed how you can use basic math operations in the MPSGraph to create a custom compute function. Usually, for every operation, output would be written out to memory.
The next operation would read from this same global memory, and this would end up causing unneeded memory traffic and performance issues, especially on the GPU.
However, MPSGraph compiler applies a special optimization to automatically fuse such operations for the users. We call this stitching.
The MPSGraph compiler recognizes all adjacent operations and passes it to the Metal compiler.
The Metal compiler fuses the operations together to create a single optimized Metal shader. This leads to no memory overhead and improves performance.
MPSGraph compiler goes even one step further. For any math operations around hand tuned MPS kernels, like convolution, matrix multiplication, or reduction, MPSGraph recognizes adjacent stitchable operations to create a region...
and once more passes the region of operations to the Metal compiler for them to be fused directly into the hand tuned MPS kernel, giving the best of hand tuned MPS optimizations for each hardware and the memory savings from automatic fusion of operations by the Metal compiler.
Using the stitching optimization makes GeLU go almost ten to 50 times faster.
We even gain significant memory savings.
All this is done always and automatically for you without a single line of code needed.
One such custom compute function is machine learning inference. Inference is the process of applying a network on an input and producing an output.
The network is made up of a collection of operations, such as convolution and neuron activation layers, which, as we showed, can be expressed with operations in MPSGraph. These layers, in turn, depend upon a set of trained parameters.
During inference, these parameters are fixed. Their values are determined during the training phase. Therefore, for inference, we can use constants to represent these parameters in our MPSGraph.
With support for these wide variety of operations in MPSGraph, we now support recurrent neural networks in the graph as well. I'd like to introduce my colleague, Chris. He will show us an exciting demo of a text generation inference network in action.
Thanks, Dhruv. I'm Chris. I'm a GPU software engineer, and I am here to make your iPad Pro write a Shakespearean play. We do this using the Long Short Term Memory based Text Generator model.
The generator loop works on a single character input, in this case the letter O, which is the last letter in our initialization string "Romeo." We feed the character index into the embedding layer, which is a gather operation in MPSGraph.
This produces a single vector, and we feed this rank-one tensor to the LSTM layer, which has a constant set of trained parameters.
The result of the LSTM layer is fed to the un-embedding layer, which can be implemented with a matrix multiplication operation in MPSGraph...
and the state of the LSTM layer is updated for the next iteration.
Then the results are multiplied by the inverse temperature.
MPSGraph automatically broadcasts this scalar value to the vector length. The result is then fed into the softmax layer, which gives us a probability distribution for the next possible character.
We sample the distribution of predicted characters from the softmax layer. This gives us the index of the next character, which we can look up in our index-to-character table.
Finally, we move the newly generated result as the input to the next iteration to produce the next character.
Now let's see this network created with MPSGraph in action. We have implemented an LSTM-based text generator network with the new MPSGraph that is running here in an app on the iPad Pro. MPSGraph allows our users to implement these models, and thanks to the flexibility of the new graph interface, it's easy to make tweaks to the models to run experiments and still enjoy the benefits of optimized kernels. The network has been trained on a large text file containing writings of Shakespeare that we can see by clicking the "Show Training DataSet" link at the top. Here we can see a short excerpt of the text.
Now let's see if we can use the network to generate Shakespearean-looking text. We have set by default the initial text to be "Romeo." So let's see what happens when we hit "Generate." As we can see, the model is producing text that looks like Shakespeare's texts, at least to my untrained eye.
We can choose another initial word, so let's type here "Juliet." And hit "Generate" again. Now the produced text starts with the word "Juliet." The length of the generated text can be controlled by the slider at the bottom.
This will generate a longer piece of text.
We can also change the temperature variable with a slider. The reciprocal of this value is used to multiply the input values going into the softmax layer, which creates a more smooth and flat distribution for high-temperature values and a more sharp distribution for low-temperature values. This has the effect of making the sampling process become more random with high temperatures and less random with low temperatures. Let's move the temperature slider to about two to see if it generates more surprising text.
It does look more random to me. I'm unsure if this is even proper English anymore. Let's try setting it to three and hit "Generate" again.
Okay, yeah. Now it's starting to look like pure random letter soup. I want to get back to more conventional Shakespeare, so let's move the temperature slider back to 0.1 and see what happens.
Okay, that's better. Now the model seems to be generating text that resembles the training data set more closely.
The MPSGraph not only enables us to run these models in the graph, it also enables the user to make a wide variety of customizations to the models while still enjoying the benefits of tuned kernels thanks to the stitching capabilities. This allows support for a wide array of models, enables rapid prototyping, and reduces the amount of workarounds and hacks needed to support a model. That's all I have. Back to you, Dhruv. Thanks, Chris. We saw how easy and intuitive it was to write custom compute functions with MPSGraph. Now let's look at features in MPSGraph you can leverage to easily and optimally train your neural networks.
The training process involves repeatedly attempting to execute the network on known data. Each attempt updates the set of parameters, improving the ability of the network to work correctly.
When the network works well, the training process is stopped.
Now we can look at how to use the new MPSGraph to implement some of these ideas.
For the purposes of our talk, we will implement a simple digit classification network.
As we saw before, for doing computations with the MPSGraph, there are three major steps. Here is our road map to training our neural network. The first and the last step remain the same. We will dive deeper into step two and take a look at what operations we must create to train the parameters of our neural network.
As before, first we define our set of inputs.
We define placeholders for our inputs and target labels. We use -1 to specify a variable length batchSize for our network.
Next, we must specify the trainable parameters we spoke of before. With MPSGraph, these parameters are part of the graph itself.
As a simple example, we will be looking at training a single layered convolution neural network. This network has a set of weights corresponding to the convolution and biases to be added to the result of the convolution. These are the parameters we would be updating as part of the training process.
To specify these parameters, we will utilize variable support in the MPSGraph. Variables retain values across graph runs, so you do not need to pass these as inputs to the graph for each iteration. To create a variable, we call the variable method on the graph, providing initial values, shape, and an element dataType.
Now that we have our parameters to train, let's specify our forward pass, which also happens to be the inference network for our model.
First up, we look at how to create a convolution layer.
Convolution layer is the workhorse of the neural network, where most of the computation occurs, and the MPSGraphConvolution layer supports numerous variants.
To create a convolution layer, we first create a convolution descriptor.
Next, we pass this descriptor to the convolution method on the graph. We support numerous padding styles on our convolution. Developers can explicitly set padding in height and width or use convenience padding modes SAME and VALID, which apply padding exactly like TensorFlow.
Sometimes tensor dimensions have a semantic meaning attached to them for convenience. This is where MPSGraph TensorNamedDataLayout helps. It conveys which dimension corresponds to what name, like batch, channel, height or width.
MPSGraph supports NCHW and NHWC formats, which are commonly used for image data in TensorFlow and PyTorch.
Weights can also be specified in multiple formats like the OIHW format, which has been used in MPS, or the HWIO format used by third-party frameworks like TensorFlow.
When it comes to passing the values of our weight variables to the convolution, we would utilize the readVariable operation. It returns a tensor representing the value of the variable at this point during the execution of the graph.
In our training network, we read the weights variable and pass the returned tensor to the convolution.
The convolution layer will use the shape of the weights tensor passed in to infer kernel sizes and number of output feature channels.
MPSGraph provides the convenience of not needing to explicitly call the readVariable operation. If the variable tensor is directly passed to any operation, the graph will implicitly add readVariable operations for your convenience.
For the bias after the convolution, we will call the add node, which implicitly supports broadcasting.
For nonlinearity, we apply the rectified Linear Unit function, which is a commonly used activation.
We reshape the four-dimensional reLU output to a two-dimensional tensor, which happens to be the same shape as our labels. Its dimensions represent an unknown batch size and the number of classes to classify to, which, in our case, are the ten digits.
Finally, we add a softMax layer to estimate probabilities of each class. We set the axis to be -1, which helps us indicate the fastest moving axis.
We have successfully defined the forward pass for our neural network. Now we define the loss function, which we will try to minimize to train our neural network.
We will use the commonly used Softmax Cross Entropy loss function.
We define the loss by passing in the labels and the evaluated reshapeTensor. We utilize reductionSum to accumulate the losses across the batch into a single scalar loss value.
Now that we have defined our loss value to minimize, we need to calculate the gradients for the computed loss with respect to the trainable parameters. To do that, we must backpropagate the gradients using the chain rule.
To begin our chain rule, the first step is to calculate the gradient of the loss with itself, which happens to be 1.
After that, we need to utilize gradient operations and the other operations available in the graph. We use them to apply chain rule by multiplying partial derivatives of each layer all the way till we get the gradients of the loss with respect to each trainable parameter.
However, MPSGraph provides a convenience method which gives the gradients of a tensor with respect to a list of tensors. We call this automatic differentiation.
It automatically writes out the backward pass of the graph and returns a dictionary of tensors and the corresponding gradients.
You can use the gradient method to write out the gradient function for even any basic math function. We take a simple logarithm operation here for our example. The gradient method correctly creates a reciprocal operation as a partial derivative and multiplies it with the starting gradient which, as we discussed, is always 1.
However, we end up with a set of unused operations. Once more, the graph compiler helps us out here. The graph is pruned to eliminate any dead code whose results are unused, and any constants like 1 are folded and eliminated.
So in the case of our neural network, we would take the gradient of the loss tensor with respect to the weights and the biases.
Once we have a gradient of loss with respect to trainable parameters, we can update the variables.
To calculate updates to the tensors, we use the stochastic gradient descent optimizer. It takes in a learningRate, the original weight value, and the gradient for the weights which we get by using the gradients dictionary.
Finally, we use the assign variable operation in the graph to assign the new update tensor value to the variable.
Final step is the same as before. We wrote out our training graph, and now we need to execute it.
Our training loop is quite straightforward. For each iteration, we get a sample of training input images and corresponding labels. We pass these into the graph as feeds.
Then we request the lossTensor be targeted and returned. Every iteration, the weights and bias variables would get updated, since we also target the assignment operations in the graph.
The graph compiles once for each unique type of inputs and outputs on the very first invocation, and the executables are automatically cached for any further iterations to get the best performance.
MPSGraph also offers asynchronous run methods. This execution call is non-blocking and will immediately return without waiting for the GPU to finish computing. The optional executionDescriptor can be utilized to synchronize between the CPU and the GPU.
We use one such synchronization method on the descriptor. Users can register their completion handlers, which will be called once the GPU is finished executing the graph.
In the past years, we have showcased the virtue of overlapping CPU encoding and the GPU execution. The training iterations we execute can use the same principles.
We create a semaphore with a value of 2.
We signal the semaphore from the completion handler of our execution descriptor.
Inside the loop, we wait on the semaphore, and once through, we asynchronously execute our graph so it immediately returns.
For users who wish to integrate MPSGraph into their existing Metal work flow, MPSGraph offers low-level execution methods in which you can pass your own existing MTLCommandQueues.
MPSGraph even provides MPS style ability to encode the graph on your MPSCommandBuffers.
Users can specify their own results dictionary, giving them fine-grained control over their output allocations.
Now we go back to Chris. He will show our digit classifier training network in action. Now that Dhruv has shown us the new MPSGraph for training, let's see how we can use it to implement digit classification on an iPhone 11. We have implemented a simple convolutional neural network using the new MPSGraph framework, and we can use this to classify digits drawn by a user.
Upon opening the app, we start off with a completely untrained graph. On the inference tab, we can see that currently the network is doing a lousy job trying to label these numbers. It can't predict this 1. Nor can it predict this zero.
But if I go back to the training tab, I can press the "play" button to kick off a small batch of training. We use the auto differentiation feature of MPSGraph to get weight gradients and target operations to update our weight variables to easily implement training. The loss for each iteration is plotted at the top, and we can see it going down as the network is trained.
We train for only a few hundred iterations with a small batch size, and we already have almost 95% accuracy on the test set.
Going back to the inference tab... we can test our newly trained graph.
We can see it has already learned to classify our inputs with good accuracy. The new MPSGraph makes it easy to build custom machine learning models, and use them for both training and inference. This example of how you can use MPSGraph to build, train, and execute a digit classifier will be available as sample code online. Now back to Dhruv for more on training. Thanks, Chris, for showing us the power of the MPSGraph training on an iPhone. MPSGraph adds the capability to support even more sophisticated neural network architectures.
Let's look at one such example. This time, we want to create new sets of real looking handwritten digits. However, there is an issue. There is no way for the machine to determine what constitutes a real-looking handwritten digit.
The answer to our problem is competition. Humans have for many years used competition to better each other and achieve heights of excellence which they can't by themselves. We do the same here, training two neural networks by making them compete against each other. One tries to create handwritten digits and the other tries to evaluate its quality.
The first of our networks is the generator, the artist. Its purpose is to take a random set of values as seed and generate a real-looking handwritten digit.
The generator network is quite simple. We take our random set of values and pass them through three stages to progressively increase the image size to create our handwritten digit. Let's quickly go through some of the new layers here.
Firstly, we see some convolution transposes.
Convolution transpose is a unique layer which derives from the gradient of a convolution operation. So for a stride two, the output size would be twice as big rather than half the size of the input. To describe a convolution transpose, we pass the descriptor for the corresponding convolution and the output shape we expect.
Another new-looking layer here is batch normalization. Normalization layers are a very important part of neural networks. They help us ensure our trained values and their corresponding gradients don't vanish or explode.
To normalize a tensor, we need to use the statistics for the tensor.
MPSGraph has methods to get mean and variance of the tensor on selected axes. The axes we choose give us an opportunity to select if we want batch normalization, instance normalization, or any other variant.
For batch normalization, we would choose batch, height, and width dimensions.
Then we call the normalization layer with trainable gamma and beta parameters.
The second layer is the discriminator, our detective. Its purpose is to take a handwritten digit and classify it as real or fake.
We already saw how to write classifier networks. This network is very similar. Only difference is that instead of ten digits, now we have one class to predict. That is the realness of the incoming image.
The discriminator has another new layer: namely, dropout.
The dropout layer randomly drops values of the input by making them zero at a given rate. At the same time, it boosts the rest of the values by the inverse of the rate to retain the energy of the propagated features.
Now that we have looked at the forward pass for both networks, we'll look into training for the two networks.
Let's start with our discriminator network.
We control if we pass real or fake images into the discriminator. The discriminator's objective is to predict the realness of the incoming image, so for real images, it should predict 1 for the probability of being real, and for fake images, it should predict a probability of zero.
For the generated images, we subtract the discriminator result from 1 to instead get the fakeness of the input images.
We use the commonly used cross entropy loss to quantify how far our discriminator was from the correct real or fake prediction.
Finally, we want to provide the discriminator equal opportunity to learn to classify real and fake images without introducing bias. So for each iteration, we pass the same number of real and fake images and add their losses together.
With the loss in hand, we use the automatic differentiation feature of the MPSGraph. Notice how we ask for the gradients for the list of discriminator variables only. This is because we only wish to train the discriminator in this pass.
We have the makings of a good detective. Now let's look at training our artist to generate realistic digits.
As we described before, we use the discriminator to quantify how realistic our generated image is. The generator will try to learn to fool the discriminator into predicting that the generated image is real.
And once more, we use the cross entropy loss to quantify how far the probability of being real was.
We use this generator loss to get the gradients.
Notice again, we only get the gradients for the generator variables. This is because we don't want the discriminator to learn to predict fake images as real. MPSGraph will automatically differentiate through both networks and return gradients for the generator variables only.
With the gradients for both networks, we can update the variables just as before by applying optimizers. And now we see how to execute the training for the two networks.
MPSGraph makes it really easy to execute. We simply pass both losses as targets and request both the generator and discriminator update operations in a single run call. The MPSGraph will compile and optimize across both networks and execute them together.
We just saw how easy it was to write out two networks within a single MPSGraph and execute them together with a single execution call. Let's ask Chris to generate some digits for us. Hello again. Now that we know how these networks work, let's see them in action on our iPad Pro. I'll hit the "play" button on the "train" tab to begin training.
On the top, we see the loss for the generator network and the bottom shows the loss for the discriminator network. In the center, we can see images generated by the generator network, and as the networks train, we will see these generated numbers start to resemble digits.
Just like we saw in the digit classifier demo, we use the auto differentiation feature of MPSGraph to update the trainable layers in both the generator and discriminator networks. Both networks are trained using a single MPSGraph.
We can see these networks are already battling each other, but it'll take time before the generator is able to produce believable digits. We can pause this training...
and jump to the "inference" tab to test the networks after they have trained for a few hundred epochs.
Here we see a 5, 9. I don't know what that is. 7, 9. They look like digits to me. All of this is running on an iPad Pro using MPSGraph. Okay, back to Dhruv. Thanks again, Chris. In summary, we introduced the new MPSGraph framework. We learned how to write and execute custom compute functions using MPSGraph. We saw how the MPSGraph compiler stitches and optimizes operations across your entire graph to give the best performance.
And finally, we saw how easy it is to train neural networks using MPSGraph with support for features like variables and automatic differentiation. Thank you for listening. Please check out our sample code and documentation, and have a great WWDC.
-