-
Create image processing apps powered by Apple silicon
Discover how to optimize your image processing app for Apple silicon. Explore how to take advantage of Metal render command encoders, tile shading, unified memory architecture, and memoryless attachments. We'll show you how to use Apple's unique tile based deferred renderer architecture to create power efficient apps with low memory footprint, and take you through best practices when migrating your compute-based apps from discrete GPUs to Apple silicon.
Resources
- Debugging the shaders within a draw command or compute dispatch
- Metal Feature Set Tables
- Metal
- Metal Shading Language Specification
Related Videos
WWDC20
-
Search this video…
♪ Bass music playing ♪ ♪ Eugene Zhidkov: Hi and welcome to WWDC.
My name is Eugene Zhidkov. I am from GPU software.
And together, with Harsh Patil from Mac system architecture, we'll show you how to create image-processing applications powered by Metal on Apple silicon.
First, I will focus on the best practices and lessons learned, optimizing image-processing applications for M1 based on developer engagements we have had over the last year.
And then Harsh will give you a step-by-step guide to how you can redesign your image-processing pipeline for optimal performance on Apple silicon.
So let’s jump right in! To start, let’s briefly revisit Apple system on-the-chip architecture and its benefits.
Many image-processing and video-editing apps are designed with discrete GPUs in mind.
So it’s important to highlight what’s so different about Apple GPUs.
First, all Apple chips use Unified Memory Architecture.
All blocks -- such as CPU, GPU, Neural and Media engines -- have access to the same system memory using unified memory interface.
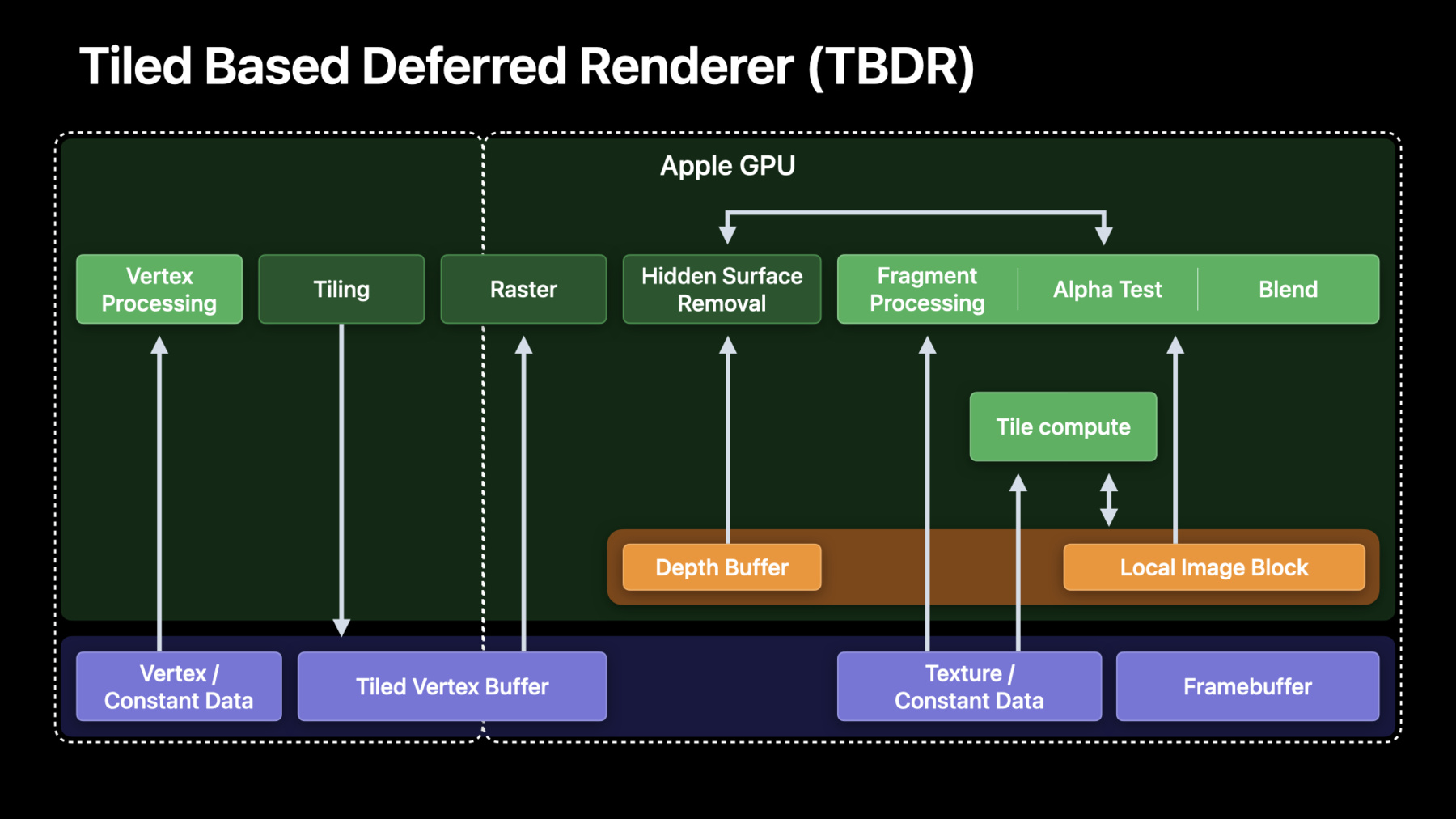
And second, our GPUs are Tile Based Deferred Renderers, or TBDRs.
TBDRs have two main phases: tiling, where whole render surfaces split into tiles and processed geometry is then handled independently; and rendering, where all of the pixels will be processed for each tile.
So in order to be most efficient on Apple silicon, your image-processing app should start leveraging unified memory -- to avoid any copies your pipeline used to have -- and TBDR architecture by exploiting tile memory and local image block.
To learn more about how Apple TBDR works at low level and how to target our shader core, please watch these sessions from the last year.
And now, let’s talk about the exact things we are going to do to optimize image-processing compute workloads for Apple silicon.
Last year, we’ve been working closely with many great developers on their image pipeline transitions.
We picked the six most rewarding tips to share.
First, we’ll discuss how to avoid unnecessary memory copies or blits.
This is really important given we are now working with images up to 8K.
Then, we wanted to highlight the benefits of using render pipeline and textures instead of using compute on buffers and how you could do that in your own image-processing pipeline.
Once we have the render and textures paths up and running, we wanted to show you the importance of proper load/store actions and memoryless attachments.
This will help you getting the most out of the tile memory.
Then, we’ll talk how to best approach Uber-shaders with its dynamic control flow and also how to leverage smaller data types -- such as short and half -- to improve performance and efficiency.
And we’ll finish with important advice about texture formats to get the best throughput.
All right.
So let’s get started with one of the most rewarding tips: avoiding unneeded blits on Apple silicon.
Most image-processing apps are designed around discrete GPUs.
With discrete GPUs, you have separate system memory and video memory.
To make the frame image visible or resident to the GPU, explicit copy is required.
Moreover, it is usually required twice; to upload the data for the GPU to process it, and to pull it back.
Let’s consider we are decoding an 8K video, processing it, and saving it to disk.
So this is a CPU thread, decoding, in this case.
That’s where we need to copy the decoded frame to GPU VRAM.
And here is GPU timeline, where all the effects and filters are applied.
Let’s take it one step further and let’s recall we need to save the results to disk, right? So we must also consider bringing the processed frame back to system memory and the actual encoding of the frame.
So, these are known as "copy" or "blit gaps", and advanced image-processing applications had to do deep pipelining and other smart things to fill them in.
Well, the good news is that on Apple GPUs, blitting for the sake of residence is no longer needed.
Since memory is shared, both the CPU and GPU can access it directly.
So please add a simple check to detect if you are running on unified memory system and avoid unnecessary copies.
It will save you memory, time, and is an absolute first step to do.
So this is where we land on Unified Memory Architecture with the blits removed.
By removing the blits, we completely avoid copy gaps and can start processing immediately.
This also gives better CPU and GPU pipelining with less hassle.
Let’s make sure you implement unified memory path with no copies involved.
If you just leave blit copies exactly as it was on the discrete GPU, you’ll pay with system memory bandwidth, less GPU time for actual processing, and potential scheduling overhead.
Not to mention we no longer need separate VRAM image allocated.
GPU frame capture can help you with spotting large blits.
Please inspect your application blits and make sure you only do the copies required.
Now, let’s talk about how exactly we should start leveraging Apple GPU TBDR architecture for image processing.
Most image-processing applications operate on image buffers by dispatching series of compute kernels.
When you dispatch a compute kernel in default serial mode, Metal guarantees that all subsequent dispatches see all the memory writes.
This guarantee implies memory coherency for all shader cores, so every memory write is made visible to all other cores by the time the next dispatch starts.
This also means memory traffic could be really high; the whole image has to be read and written to.
With M1, Apple GPUs enable tile dispatches on MacOS.
In contrast to regular compute, they operate in tile memory with tile-only sync points.
Some filters -- like convolutions -- cannot be mapped to the tile paradigm, but many other filters can! Deferring system memory flush until the encoder end point provides solid efficiency gains.
You can execute more useful GPU work when not limited by system memory bandwidth.
To take it even further, let’s notice that many per-pixel operations don’t require access to neighboring pixels, so tile sync point is not necessary.
This maps really well to fragment functions.
Fragment functions can be executed without implicit tile sync, requiring sync only at the encoder boundary or when tile kernels are dispatched serially after the fragment kernels.
We now learned that Apple GPUs enable fragment functions and tile kernels for more efficient image processing.
Let’s see how we could use that.
We do that by converting regular compute dispatches on buffers to render command encoder on textures.
As we just discussed, rule of thumb is the following.
Per-pixel operations with no interpixel dependency should be implemented using fragment functions.
Any filter with threadgroup scoped operations should be implemented with tile shading, since neighbor pixels access within a tile is required.
Scatter-gather and convolution filters cannot be mapped to tile paradigm since they require random access, so these should still remain compute dispatches.
Render command encoder also enables a unique Apple GPU feature: lossless bandwidth compression for textures and render targets.
This is a really great bandwidth saver, especially for an image-processing pipeline, so let’s see how we should use it.
Well, speaking of enabling lossless compression, it’s actually easier to say what you should not do.
First, already-compressed texture formats cannot benefit from lossless.
Second, there are three particular texture flags which cannot work with this compression, so make sure you don’t set them just by an accident.
And third, linear textures -- or backed by an MTLBuffer -- are not allowed as well.
Some special treatment is also required for nonprivate textures; make sure to call optimizeContentsForGPUAccess to stay on the fastest path.
GPU frame capture Summary pane now shows you lossless compression warnings and highlights the reasons why the texture has opted out.
In this example, PixelFormatView flag was set.
In many cases, developers are setting these flags unintentionally.
Don’t set PixelFormatView if all you need is components swizzle or sRGB conversion.
All right, we have the render and textures path up and running.
Now, let’s make sure we properly use tile memory.
Tile memory TBDR concepts -- such as load/store actions and memoryless attachments -- are totally new to the desktop world.
So let’s make sure we use them properly.
Let’s start with load/store actions! As we already know, the whole render target is split into the tiles.
Load/store are per-tile bulk actions guaranteed to take the most optimal path through memory hierarchy.
They are executed at the beginning of the render pass -- where we tell the GPU how to initialize the tile memory -- and at the end of the pass to inform the GPU what attachments need to be written back.
The key thing here is to avoid loading what we don’t need.
If we are overwriting the whole image, or the resource is temporary, set load action to LoadActionDontCare.
With render encoder, you no longer need to clear your output or temporary data, as you probably did before with dedicated compute pass or fillBuffer call.
By setting LoadActionClear, you can efficiently specify the clear value.
And the same goes for the store action.
Make sure to only store the data you will later need -- like the main attachment -- and don’t store anything temporary.
Besides explicit load and store actions, Apple GPUs saves your memory footprint with memoryless attachments.
We can explicitly define an attachment as having memoryless storage mode.
This enables tile-only memory allocation, meaning that your resource will persist for each and every tile only within encoder lifetime.
This can greatly reduce your memory footprint, especially for 6K/8K images, where every frame takes hundreds of megabytes.
Let’s see how this all can be done in code.
We start by creating the textureDescriptor and then create the outputTexture.
We then create a temporary texture.
Notice that I’ve marked it memoryless, as we don’t want any storage here.
Then we create the render pass by first describing what the attachments are and then what are the load/store actions.
We don’t care about loading the output since it is fully overwritten, but we need to store it.
As for the temporary texture, we don’t load but clear it, and we don’t need to store it either.
Finally, we create our renderPass from the descriptor.
That’s it.
So we are using unified memory, moved our image-processing pipeline to render command encoder, and are properly leveraging tile memory.
Now, let’s talk about uber-shaders.
Uber-shaders, or uber-kernels, is a pretty popular way to make developers' life easier.
Host code sets up the control structure, and shader just loops through a series of if/else statements, for example, if tone mapping is enabled or if the input is in HDR or SDR formats.
This approach is also known as "ubers-shader" and is really good at bringing total number of pipeline state objects down.
However, it has drawbacks.
The main one is increased register pressure to keep up with more complex control flow.
Using more registers can easily limit maximum occupancy your shader is running at.
Consider a simple kernel where we pass in the control struct.
We use flags inside the struct to control what we do.
We have two features here: if the input is in HDR and if tonemapping is enabled.
All look good, right? Well, here is what happens on the GPU.
Since we cannot deduce anything at compile time, we have to assume we could take both paths -- HDR and non-HDR -- and then combine based on the flag.
Same goes for tone mapping.
We evaluate it and then mask it in or out, based on the input flag.
The problem here is registers.
Every control flow path needs live registers.
This is where uber-shaders are not so good.
As you recall, registers used by the kernel define maximum occupancy the shader could run.
That happens because registers file is shared by all simdlanes on the shader core.
If we could only run what’s only needed, that would enable higher simdgroup concurrency and GPU utilization.
Let’s talk how to fix this.
Metal API has the right tool for the job, and it's called "function_constants".
We define both control parameters as function_constants, and we modify the code accordingly.
Here, we are showing the modified kernel code.
Host side must be also updated to provide function_constant value at pipeline creation time.
Another great way to reduce register pressure is using 16-bit types in your shaders.
Apple GPUs have native 16-bit type support.
So, when using smaller data types, your shaders will require less registers, increasing occupancy.
Half and short types also require less energy and might achieve higher peak rates.
So, please use half and short types instead of float and int when possible, since type conversions are usually free.
In this example, consider a kernel using the thread_position in threadgroup for some computations.
We are using unsigned int, but the maximum threadgroup size supported by Metal can easily fit in unsigned short.
threadgroup_position_in_grid, however, could potentially require a larger data type.
But for the grid sizes we’re using in image processing -- up to 8K or 16K -- unsigned short is also enough.
If we use 16-bit types instead, the resulting code will use a smaller number of registers, potentially increasing the occupancy.
Now, let me show you where you can have all the details on registers.
GPU frame debugger in Xcode13 now has advanced pipeline state object view for render, tile, and compute PSOs.
You can inspect detailed pipeline statistics -- now with registers usage -- and fine-tune all your shaders.
With register concerns covered, let’s talk about texture formats.
First, we want to note that different pixel formats might have different sampling rates.
Depending on hardware generation and number of channels, wider floating-point types might have reduced point sampling rate.
Especially floating-point formats such as RGBA32F will be slower than FP16 variants when sampling filtered values.
Smaller types reduce memory storage, bandwidth, and cache footprint as well.
So we encourage, again, to use the smallest type possible, but in this case, for the textures storage.
This was actually a common case for 3D LUTs in image processing; most applications we worked with were using float RGBA for a 3D LUT application phase with bilinear filtering enabled.
Please consider if your app can instead use halfs and the precision will be enough.
If that’s the case, switch to FP16 right away to get peak sampling rates.
If half precision is not enough, we found out that fixed-point unsigned short provides great uniform range of values, so encoding your LUTs in unit scale and providing LUT range to the shader was a great way to get both peak sampling rate and sufficient numerical accuracy.
All right, so we just went over how we should leverage Apple GPU architecture to make your image-processing pipeline run as efficient as possible.
To apply it all right away, please meet Harsh! Harsh Patil: Thanks, Eugene.
Now let’s walk through redesigning an image-processing pipeline for Apple silicon based on all the best practices we have learned so far.
To be specific, we are going to tailor the image-processing phase of the video-processing pipeline for Apple GPUs.
Real-time image processing is very GPU compute and memory bandwidth intensive.
We will first understand how it is usually designed and then how we can optimize it for Apple silicon.
We are not going to go into the details of video-editing workflow in this section, so please refer to our talk from two years ago.
We will solely focus on transitioning the compute part of image processing to render path.
Before we start, let's begin quickly take a look at where image-processing phase stands in a typical video-processing pipeline.
We'll take ProRes-encoded input file as an example.
We first read the ProRes-encoded frame from the disk or external storage.
We then decode the frame on CPU, and now the image-processing phase executes on this decoded frame on the GPU and renders the final output frame.
Finally, we display this output frame.
We could additionally also encode the final rendered frame for delivery.
Next, let’s take a look at what comprises an image-processing pipeline.
Image processing starts with unpacking different channels of the source image RGB in alpha into separate buffers in the beginning.
We will process each of these channels in our image-processing pipeline, either together or separately.
Next, there might be color space conversions to operate in the desired color-managed environment.
We then apply a 3D LUT; perform color corrections; and then apply spatial-temporal noise reduction, convolutions, blurs, and other effects.
And finally, we pack the individually processed channels together for final output.
What do these selected steps have in common? They are all point filters, operating only on a single pixel with no interpixel dependency.
These map well to fragment shader implementation.
Spatial and convolution-style operations require access to large radius of pixels, and we have scattered read-write access patterns as well.
These are well-suited for compute kernels.
We’ll use this knowledge later.
For now, let’s see how these operations are executed.
Applications represent chain of effects applied to an image as a filter graph.
Every filter is its own kernel, processing the inputs from the previous stage and producing outputs for the next stage.
Every arrow here means a buffer being written to/from output of one stage and read as the input in the next stage.
Since memory is limited, applications usually linearize the graph by doing a topological sort.
This is done to keep the total number of intermediate resources as low as possible while also avoiding race conditions.
This simple filter graph in that example would need two intermediate buffers to be able to operate without race conditions and produce the final output.
The linearized graph here roughly represents the GPU command buffer encoding as well.
Let’s look deeper on why this filter graph is very device memory bandwidth intensive.
Every filter operation has to load whole image from device memory into the registers and write the result back to the device memory.
And that’s quite a bit of memory traffic.
Let’s estimate the memory footprint for a 4K-frame image processing based on our example image-processing graph.
A 4K decoded frame itself takes 67 megabytes of memory for floating-point 16 precision or 135 megabytes of memory for floating-point 32 precision, and professional workflows absolutely need floating-point 32 precision.
For processing one 4K frame in floating-point 32 precision through this image-processing graph, we are talking more than two gigabytes of read-write traffic to device memory.
Also, writes to buffers holding the intermediate output thrashes the cache hierarchy and impacts other blocks on the chip as well.
Regular compute kernels don’t benefit from the on-chip tile memory implicitly.
Kernels can explicitly allocate threadgroup-scoped memory, which will be backed by the on-chip tile memory.
However, that tile memory is not persistent across dispatches within a compute encoder.
In contrast, the tile memory is actually persistent across draw passes within one render command encoder.
Let’s see how we can redesign this representative image-processing pipeline to leverage the tile memory.
We are going to address this by following three steps.
We first change the compute pass to render pass and all the intermediate output buffers to textures.
We then encode per-pixel operations with no interpixel dependency as fragment shader invocations within one render command encoder, making sure to account for all the intermediate results and setting appropriate load/store actions.
And finally, we discuss what do we do in more complex situation than just point filters.
Our first step is to use separate MTLRenderCommandEncoder to encode eligible shaders.
In this filter graph, unpack, color space conversion, LUT, and color-correction filters are all point per-pixel filters that we can convert to fragment shader and encode them using one render command encoder.
Similarly, mixer and pack shaders -- which are towards the end of this image-processing pipeline -- can also be converted to fragment shaders and encoded using another MTLRenderCommandEncoder.
Then we can invoke these shaders within their respective render passes.
When you create the render pass, all the resources attached to the color attachments in that render pass are implicitly tiled for you.
A fragment shader can only update the image block data associated with fragment’s position in the tile.
Next shader in the same render pass can pick up the output of the previous shader directly from the tile memory.
In the next section, we will take a look at how we can structure the fragment shaders which map to these filters.
We will also take a look at what constructs we need to define and use to enable access to the underlying tile memory from within these fragment shaders.
And finally, we will take a look at how the output generated in the tile memory by one fragment shader can be consumed directly from the tile memory by the next fragment shader within the same render command encoder.
This is what you have to do in your code.
Here I have attached output image as a texture attached to color attachment 0 of the render pass descriptor.
I have attached texture holding intermediate result to color attachment 1 of the render pass descriptor.
Both of these will be implicitly tiled for you.
Please set the appropriate load/store properties as discussed earlier in the talk.
Now, set up a structure to access these textures in your fragment shader.
In the coming examples, we will show how to use this structure within your fragment shaders.
You simply access the output and the intermediate textures within your fragment shader as highlighted by using the structure we defined earlier.
Writes to these textures are done to appropriate tile memory location corresponding to the fragment.
Output produced by the unpack shader is consumed as input by color space conversion shader using the same structure that we defined earlier.
This fragment shader can do its own processing and update the output and intermediate textures which will, once again, update the corresponding tile memory location.
You are to continue the same steps for all the other fragment shaders within the same render encoder pass.
Next, let's visualize how this sequence of operations looks now with these changes.
As you can see, now you have unpack, color space conversion, application of 3D LUT, and color-correction steps, all executed on the tile memory using one render pass with no device memory passes in between.
At the end of the render pass, render targets that are not memoryless are flushed to the device memory.
You can then execute the next class of filters.
Let’s talk a bit about filters that have scatter-gather access patterns.
Kernels representing such filters can directly operate on the data in the device memory.
Convolution filters are very well-suited for tile-based operations in compute kernels.
Here, you can express intent to use tile memory by declaring a threadgroup-scoped memory.
Now, you bring in the block of pixels into the tile memory along with all the necessary halo pixels, depending upon the filter radius, and perform the convolution operation directly on the tile memory.
Remember, tile memory is not persistent across compute dispatches within a compute encoder.
So after executing Filter1, you have to explicitly flush the tile memory contents to device memory.
That way, Filter2 can consume the output of Filter1.
So where do we land once we make all of these changes? For processing one 4K frame in floating-point 32 precision through our example restructured image-processing graph, here’s what we have now.
Bandwidth goes down from 2.16 gigabytes to just load and store worth 810 megabytes, and that’s 62 percent reduction in memory traffic to the device memory.
We don't need two intermediate device buffers saving 270 megabytes of memory per frame.
And finally, we have reduced cache thrashing, and that's because all the fragment shaders within that render pass are operating directly on the tile memory.
One of the key features of Apple silicon is its Unified Memory Architecture.
Let’s see an example of how to leverage this Unified Memory Architecture for interaction between different blocks on the Apple silicon.
We will take HEVC encoding of the final video frame rendered by GPU as a case study.
This encoding is done using dedicated hardware media engines on Apple silicon.
The final output frame rendered by the GPU can be consumed directly by our media engines with no extra memory copies.
In the coming section, we will walk through an example on how to set up a pipeline for HEVC encoding of the final output frame produced by the GPU in the most efficient way.
For that, first we will leverage CoreVideo API to create a pool of pixel buffers backed by IOSurfaces.
Then, using the Metal API, we render the final frames into Metal textures backed by IOSurfaces from the pool we just created.
And finally, we dispatch these pixel buffers directly to the media engine for encode without any additional copies of the output frames produced by the GPU, thus leveraging the Unified Memory Architecture.
Let’s walk through on how to do this step by step and covering all the constructs we need to enable this flow.
First, we create a CVPixelBufferPool backed by IOSurface in the desired pixel format.
Here, we will use the biplanar chroma-subsampled pixel format for HEVC encode.
Now, you get a CVPixelBuffer from this CVPixelBufferPool.
Pass this CVPixelBuffer to the MetalTextureCache with the right plane index to get the CVMetalTextureReference.
Since we are using biplanar pixel format, you need to perform this step for both planes of the biplanar pixel buffer.
Next, get the underlying Metal texture from the CVMetalTextureReference object.
Perform this step for both luma and chroma planes.
Remember that these Metal textures are backed by the same IOSurfaces which are also backing the CVPixelBuffer planes.
Using Metal API, render into the textures corresponding to luma and chroma planes.
This will update the IOSurface which backs these Metal textures as well.
We highly recommend doing the chroma subsampling step on the chroma planes on the GPU itself as a shader pass within your image-processing pipeline.
An important thing to note is that both CVPixelBuffer and the Metal textures -- which we just rendered into -- are backed by the same underlying IOSurface copy in the system memory.
You can now send this CVPixelBuffer directly to the media engine for encode.
As you can see, due to the Unified Memory Architecture, we can seamlessly move data between GPU and media engine block with no memory copies.
And finally, remember to release the CVPixelBuffer and CVMetalTexture reference after every frame.
Releasing the CVPixelBuffer enables recycling of this buffer for future frames.
To wrap up, we encourage you again to do the following: leverage Unified Memory Architecture, use MTLRenderCommandEncoder instead of compute when applicable, merge all your eligible render passes within single render command encoder, set appropriate load/store actions, use memoryless for transient resources, leverage tile shading when applicable, and use buffer pools with other APIs for zero-copy.
We want to thank you for joining this session today.
Enjoy the rest of WWDC 2021! ♪
-
-
10:53 - Memoryless attachments
let textureDescriptor = MTLTextureDescriptor.texture2DDescriptor(…) let outputTexture = device.makeTexture(descriptor: textureDescriptor) textureDescriptor.storageMode = .memoryless let tempTexture = device.makeTexture(descriptor: textureDescriptor) let renderPassDesc = MTLRenderPassDescriptor() renderPassDesc.colorAttachments[0].texture = outputTexture renderPassDesc.colorAttachments[0].loadAction = .dontCare renderPassDesc.colorAttachments[0].storeAction = .store renderPassDesc.colorAttachments[1].texture = tempTexture renderPassDesc.colorAttachments[1].loadAction = .clear renderPassDesc.colorAttachments[1].storeAction = .dontCare let renderPass = commandBuffer.makeRenderCommandEncoder(descriptor: renderPassDesc) -
12:25 - Uber-shaders impact on registers
fragment float4 processPixel(const constant ParamsStr* cs [[ buffer(0) ]]) { if (cs->inputIsHDR) { // do HDR stuff } else { // do non-HDR stuff } if (cs->tonemapEnabled) { // tone map } } -
13:32 - Function constants for Uber-shaders
constant bool featureAEnabled[[function_constant(0)]]; constant bool featureBEnabled[[function_constant(1)]]; fragment float4 processPixel(...) { if (featureAEnabled) { // do A stuff } else { // do not-A stuff } if (featureBEnabled) { // do B stuff } } -
23:02 - Image processing filter graph
typedef struct { float4 OPTexture [[ color(0) ]]; float4 IntermediateTex [[ color(1) ]]; } FragmentIO; fragment FragmentIO Unpack(RasterizerData in [[ stage_in ]], texture2d<float, access::sample> srcImageTexture [[texture(0)]]) { FragmentIO out; //... // Run necessary per-pixel operations out.OPTexture = // assign computed value; out.IntermediateTex = // assign computed value; return out; } fragment FragmentIO CSC(RasterizerData in [[ stage_in ]], FragmentIO Input) { FragmentIO out; //... out.IntermediateTex = // assign computed value; return out; }
-