-
Explore low-latency video encoding with VideoToolbox
Supporting low latency encoders has become an important aspect of video application development process. Discover how VideoToolbox supports low-delay H.264 hardware encoding to minimize end-to-end latency and achieve new levels of performance for optimal real-time communication and high-quality video playback.
Resources
Related Videos
WWDC21
WWDC20
-
Search this video…
♪ ♪ Hi. My name is Peikang, and I’m from Video Coding and the Processing team. Welcome to “Exploring low-latency video encoding with Video Toolbox.” The low-latency encoding is very important for many video applications, especially real-time video communication apps. In this talk, I’m going to introduce a new encoding mode in Video Toolbox to achieve low-latency encoding. The goal of this new mode is to optimize the existing encoder pipeline for real-time applications. So what does a real-time video application require? We need to minimize the end-to-end latency in the communication so that people won’t be talking over each other.
We need to enhance the interoperability by letting the video apps capable of communicating with more devices. The encoder pipeline should be efficient when there are more than one recipients in the call.
The app needs to present the video in its best visual quality.
We need a reliable mechanism to recover the communication from errors introduced by network loss.
The low-latency video encoding that I’m going to talk about today will optimize in all these aspects. With this mode, your real-time application can achieve new levels of performance.
In this talk, first I’m going to give an overview of low-latency video encoding. We can have the basic idea about how we achieve low latency in the pipeline. Then I’m going to show how to use VTCompressionSession APIs to build the pipeline and encode with low-latency mode. Finally, I will talk about multiple features we are introducing in low-latency mode. Let me first give an overview on low-latency video encoding. Here is a brief diagram of a video encoder pipeline on Apple’s platform. The Video Toolbox takes the CVImagebuffer as the input image. It asks the video encoder to perform compression algorithms such as H.264 to reduce the size of raw data.
The output compressed data is wrapped in CMSampleBuffer, and it can be transmitted through network for video communication. As we may notice from the previous diagram, the end-to-end latency can be affected by two factors: the processing time and the network transmission time.
To minimize the processing time, the low-latency mode eliminates frame reordering. A one in, one out encoding pattern is followed. Also, the rate controller in this mode has a faster adaptation in response to the network change, so the delay caused by network congestion is minimized as well. With these two optimizations, we can already see obvious performance improvements compared with the default mode. The low-latency encoding can reduce the delay of up to 100 milliseconds for a 720p 30fps video. Such saving can be critical for video conferencing.
As we reduce the latency, we can achieve a more efficient encoding pipeline for real-time communications like video conferencing and live broadcasting.
Also, the low-latency mode always uses a hardware-accelerated video encoder in order to save powers. Note, the supported video codec type in this mode is H.264, and we’re bringing this feature on both iOS and macOS.
Next, I want to talk about how to use low-latency mode with Video Toolbox. I’m going to first recap the use of VTCompressionSession and then show you the step we need to enable low-latency encoding. When we use VTCompressionSession, the first thing is to create the session with VTCompressionSessionCreate API.
We can optionally config the session, such as target bit rate, through VTSessionSetProperty API. If the configuration is not provided, the encoder will operate with the default behavior.
After the session is created and properly configured, we can pass the CVImageBuffer to the session with VTCompressionSessionEncodeFrame call. The encoded result can be retrieved from the output handler provided during the session creation.
Enabling low-latency encoding in the compression session is easy. The only change we need is in the session creation.
Here is a code snippet showing how to do that. First we need a CFMutableDictionary for the encoderSpecification. The encoderSpecification is used to specify a particular video encoder that the session must use. And then we need to set EnableLowLatencyRateControl flag in the encoderSpecification.
Finally, we need to give this encoderSpecification to VTCompressionSessionCreate, and the compression session will be operating in low-latency mode.
The configuration step is the same as usual. For example, we can set the target bit rate with AverageBitRate property.
OK, we’ve covered the basics of the low-latency mode with Video Toolbox. I’d like to move on to the new features in this mode that can further help you develop a real-time video application. So far, we’ve talked about the latency benefit by using the low-latency mode. The rest of the benefits can be achieved by the features I’m going introduce.
The first feature is the new profiles. We enhanced the interoperability by adding two new profiles to the pipeline.
And we are also excited to talk about temporal scalability. This feature can be very helpful in video conferencing.
You can now have a fine-grained control over the image quality with max frame quantization parameter. Last, we want to improve the error resilience by adding the support of long-term reference.
Let’s talk about the new profile support. Profile defines a group of coding algorithms that the decoder is capable to support. In order to communicate with the receiver side, the encoded bitstream should comply with the specific profile that the decoder supports.
Here in Video Toolbox, we support a bunch of profiles, such as baseline profile, main profile, and high profile.
Today we added two new profiles to the family: constrained baseline profile, CBP, and constrained high profile, CHP.
CBP is primarily used for low-cost applications and CHP, on the other hand, has more advanced algorithms for better compression ratio. You should check the decoder capabilities in order to know which profile should be used.
To request CBP, simply set ProfileLevel session property to ContrainedBaseLine_AutoLevel.
Similarly, we can set the profile level to ContrainedHigh_AutoLevel to use CHP.
Now let’s talk about temporal scalability. We can use temporal scalability to enhance the efficiency for multi-party video calls.
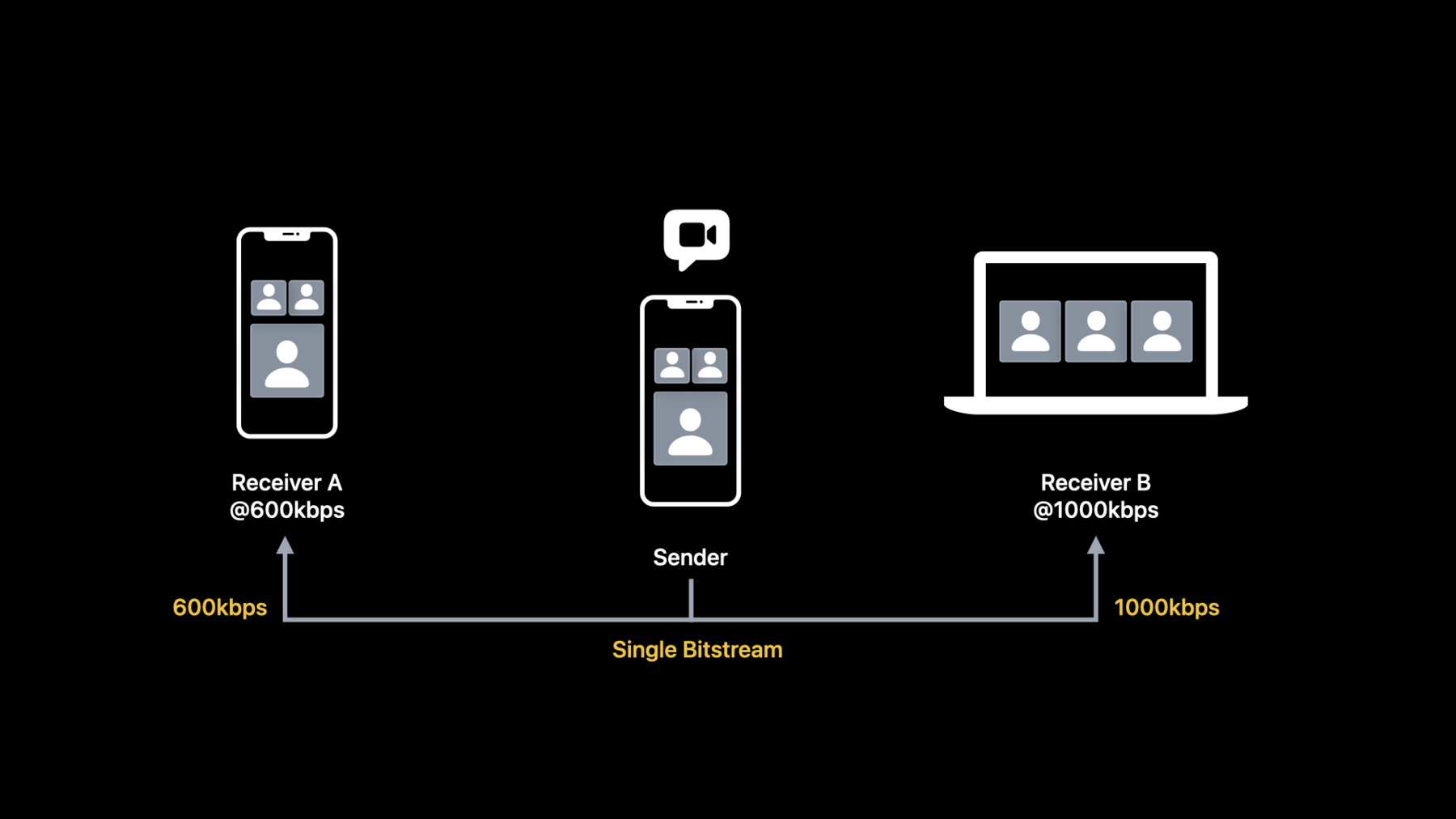
Let us consider a simple, three-party video conferencing scenario. In this model, receiver "A" has a lower bandwidth of 600kbps, and receiver B has a higher bandwidth of 1,000kbps.
Normally, the sender needs to encode two sets of bitstreams in order to meet the downlink bandwidth of each receiver side. This may not be optimal.
The model can be more efficient with temporal scalability, where the sender only needs to encode one single bitstream but can be later divided into two layers.
Let me show you how this process works.
Here is a sequence of encoded video frames where each of the frames uses the previous frame as predictive reference.
We can pull half of the frames into another layer, and we can change the reference so that only the frames in the original layer are used for prediction.
The original layer is called base layer, and the new constructed layer is called enhancement layer.
The enhancement layer can be used as a supplement of the base layer in order to improve the frame rate.
For receiver "A," we can send base layer frames because the base layer itself is decodable already. And more importantly, since the base layer contains only half of the frames, the transmitted data rate will be low.
On the other hand, receiver B can enjoy a smoother video since it has a sufficient bandwidth to receive base layer frames and enhancement layer frames.
Let me show you the videos encoded using temporal scalability. I’m going to play two videos, one from the base layer, and the other from the base layer together with the enhancement layer.
The base layer itself can be played normally, but at the same time, we may notice the video is not quite smooth.
We can immediately see the difference if we play the second video. The right video has a higher frame rate compared with the left one because it contains both base layer and enhancement layer.
The left video has 50% of the input frame rate, and it uses 60% of the target bit rate. These two videos only require the encoder to encode one single bitstream at one time. This will be much more power efficient when we are doing multi-party video conferencing.
Another benefit of temporal scalability is error resilience. As we can see, the frames in the enhancement layer are not used for prediction, so there is no dependency on these frames.
This would mean if one or more enhancement layer frames are dropped during network transmission, other frames won’t be affected. This makes the whole session more robust.
The way to enable temporal scalability is pretty straightforward. We created a new session property in low-latency mode called BaseLayerFrameRateFraction. Simply set this property to 0.5, meaning half of the input frames are assigned to base layer and the rest are assigned to enhancement layer.
You can check the layer information from the sample buffer attachment. For base layer frames, the CMSampleAttachmentKey_ IsDependedOnByOthers will be true, and otherwise it will be false.
We also have the option to set the target bit rate for each layer. Remember that we use the session property AverageBitRate to config the target bit rate.
After the target bit rate is configured, we can set the new BaseLayerBitRateFraction property to control the percentage of the target bit rate needed for the base layer.
If this property is not set, a default value of 0.6 will be used. And we recommend the base layer bit rate fraction should range from 0.6 to 0.8.
Now, let’s move to max frame quantization parameter, or max frame QP.
Frame QP is used to regulate image quality and data rate.
We can use low-frame QP to generate a high-quality image. The image size will be large in this case.
On the other hand, we can use a high-frame QP to generate an image in low quality but with smaller size.
In low-latency mode, the encoder adjusts frame QP using factors such as image complexity, input frame rate, video motion in order to produce the best visual quality under current target bit rate constraint. So we encourage to rely on the encoder’s default behavior for adjusting frame QP.
But in some cases where the client has a specific requirement for the video quality, we now let you control the max frame QP that the encoder is allowed to use.
With the max frame QP, the encoder will always choose the frame QP that is smaller than this limit, so the client can have a fine-grained control over the image quality.
It’s worth mentioning that the regular rate control still works even with the max frame QP specified. If the encoder hits the max frame QP cap but is running out of bit rate budget, it will start dropping frames in order to maintain the target bit rate.
One example of using this feature is to transmit screen content video over a poor network.
You can make a trade-off by sacrificing the frame rate in order to send sharp screen content images. Setting max frame QP can meet this requirement.
Let’s look at the interface. You can pass the max frame QP with the new session property MaxAllowedFrameQP.
Keep in mind that the value of max frame QP must range from 1 to 51 according to the standard.
Let’s talk about the last feature we’ve developed in low-latency mode, long-term reference.
Long-term reference or LTR can be used for error resilience. Let’s look at this diagram showing the encoder, sender client, and the receiver client in the pipeline.
Suppose the video communication goes through a network with poor connection. Frame loss can happen because of the transmission error.
When the receiver client detects a frame loss, it can request a refresh frame in order to reset the session.
If the encoder gets the request, normally it will encode a key frame for the refresh purpose. But the key frame is usually quite large.
A large key frame takes a longer time to get to the receiver. Since the network condition is already poor, a large frame could compound the network congestion issue.
So, can we use a predictive frame instead of a key frame for refresh? The answer is yes, if we have frame acknowledgement. Let me show you how it works.
First, we need to decide frames that require acknowledgement. We call these frames long-term reference, or LTR. This is the decision from the encoder. When the sender client transmits an LTR frame, it also needs to request acknowledgement from the receiver client.
If the LTR frame is successfully received, an acknowledgement needs to be sent back.
Once the sender client gets the acknowledgement and passes that information to the encoder, the encoder knows which LTR frames have been received by the other side.
Let’s look at the bad network situation again.
When the encoder gets the refresh request, since this time, the encoder has a bunch of acknowledged LTRs, it is able to encode a frame that is predicted from one of these acknowledged LTRs.
A frame that is encoded in this way is called LTR-P.
Usually an LTR-P is much smaller in terms of encoded frame size compared to a key frame, so it is easier to transmit. Now, let’s talk about the APIs for LTR. Note that the frame acknowledgement needs to be handled by application layer. It can be done with mechanisms such as RPSI message in RTP Control Protocol.
Here we’re only going to focus on how the encoder and the sender client communicate in this process.
Once you have enabled low-latency encoding, you can enable this feature by setting EnableLTR session property.
When an LTR frame is encoded, the encoder will signal a unique frame token in the sample attachment RequireLTRAcknowledgementToken.
The sender client is responsible for reporting the acknowledged LTR frames to the encoder through AcknowledgedLTRTokens frame property. Since more than one acknowledgement can come at a time, we need to use an array to store these frame tokens.
You can request a refresh frame at any time through ForceLTRRefresh frame property. Once the encoder receives this request, an LTR-P will be encoded. If there is no acknowledged LTR available, the encoder will generate a key frame in this case.
All right. Now we’ve covered the new features in low-latency mode. We can talk about using these features together.
For example, we can use temporal scalability and max frame quantization parameter for a group screen sharing application. The temporal scalability can efficiently generate output videos for each recipient, and we can lower the max frame QP for a sharper UI and text in the screen content.
If the communication goes through a poor network and a refresh frame is needed to recover from the error, long-term reference can be used. And if the receiver can only decode constrained profiles, we can encode with constrained baseline profile or constrained high profile.
OK. We’ve covered a few topics here. We’ve introduced a low-latency encoding mode in Video Toolbox.
We’ve talked about how to use VTCompressionSession APIs to encode videos in low-latency mode.
Besides the latency benefit, we also developed a bunch of new features to address the requirements for real-time video application. With all these improvements, I hope the low-latency mode can make your video app more amazing. Thanks for watching and have a great WWDC 2021. [upbeat music]
-
-
5:03 - VTCompressionSession creation
CFMutableDictionaryRef encoderSpecification = CFDictionaryCreateMutable(kCFAllocatorDefault, 0, NULL, NULL); CFDictionarySetValue(encoderSpecification, kVTVideoEncoderSpecification_EnableLowLatencyRateControl, kCFBooleanTrue) VTCompressionSessionRef compressionSession; OSStatus err = VTCompressionSessionCreate(kCFAllocatorDefault, width, height, kCMVideoCodecType_H264, encoderSpecification, NULL, NULL, outputHandler, NULL, &compressionSession); -
7:35 - New profiles
// Request CBP VTSessionSetProperty(compressionSession, kVTCompressionPropertyKey_ProfileLevel, kVTProfileLevel_H264_ConstrainedBaseline_AutoLevel); // Request CHP VTSessionSetProperty(compressionSession, kVTCompressionPropertyKey_ProfileLevel, kVTProfileLevel_H264_ConstrainedHigh_AutoLevel);
-