-
Optimize machine learning for Metal apps
Discover the latest enhancements to accelerated ML training in Metal. Find out about updates to PyTorch and TensorFlow, and learn about Metal acceleration for JAX. We'll show you how MPS Graph can support faster ML inference when you use both the GPU and Apple Neural Engine, and share how the same API can rapidly integrate your Core ML and ONNX models.
For more information on using Metal for machine learning, check out “Accelerate machine learning with Metal” from WWDC22.Resources
Related Videos
WWDC22
-
Search this video…
♪ ♪ Denis: Hi, my name is Denis Vieriu, and I'm a software engineer in the GPU, Graphics, and Display Software group at Apple. Today I will present to you all the new features and enhancements introduced to machine learning this year in Metal. I'll first recap the existing machine learning backends. The Metal machine learning APIs are exposed through Metal Performance Shaders framework. MPS is a collection of high-performance GPU primitives for various fields, like image processing, linear algebra, and machine learning. MPSGraph is a general purpose compute graph, which sits on top of the MPS framework and extends support to multi-dimensional tensors. machine learning inference frameworks, like CoreML, build on top of the MPSGraph backend. MPSGraph also supports training frameworks, like TensorFlow and PyTorch. To learn more about MPSGraph and ML Frameworks, please refer to the previous Metal WWDC talks listed here.
This session focuses on the updates and enhancements added to PyTorch and TensorFlow Metal backends, the new GPU acceleration for JAX, and the features added this year to MPSGraph for ML Inference.
PyTorch and TensorFlow Metal acceleration enable you to use the highly efficient kernels from MPS to get the best performance on your Mac. PyTorch Metal acceleration has been available since version 1.12 through the MPS backend. This was introduced last year into the PyTorch ecosystem, and since then, multiple improvements have been made for optimizing memory usage and view tensors. This year, PyTorch 2.0 MPS Backend made a great leap forward and has been qualified for the Beta Stage. But these were not all the improvements. Latest PyTorch builds contain lots of new updates, such as MPS operation profiling, custom kernel, and Automatic Mixed precision support. Before covering all the nightly build features, I'll start with what is new in PyTorch 2.0.
There is support for the top 60 most used Torch operators, including ops such as grid sampler, triangular solve, topk, and many more.
The testing coverage has greatly improved. This includes tests for most of the Torch operators, gradient testing, and ModuleInfo based testing.
Since release, the network coverage has expanded as multiple popular models adopted MPS as their official backend on macOS. This includes foundation models, such as WhisperAI, object detection models such as YOLO, stable diffusion models, and many more. Let's check one of these models in action using latest PyTorch 2.0. For this example, I am using YoloV5, an object detection network running on an M2 Max. On the left side, I have the network running and generating live images using the PyTorch MPS backend, while on the right, I have the exact same model, but running on the CPU. The left side, using the MPS backend, is running at noticeably higher framerate.
And furthermore, the developers not only adopted the PyTorch MPS backend in their external networks, but also have contributed code for multiple new operators, including histogram, group_norm, signbit, and more.
Next, I'll cover the new features available in the latest PyTorch builds, starting with profiling support for MPS operations. PyTorch nightly builds have profiling support that uses OS signposts to show the exact running time for operation executions, copies between CPU and GPU, and fallbacks to the CPU caused by unsupported operators. You will be able to visualize the profiling data in a very familiar tool, Metal System Trace, which is part of Instruments. To learn more about profiling ML applications using Metal System Trace, I recommend you watch the session from last year, "Accelerate machine learning with Metal." Using the profiler is a very simple process. Call the start method on the MPS profiler package to enable tracing, and, at the end of your script, use the stop method to end profiling. Now I will walk through the profiler to debug an example.
This sample network uses a Sequential model composed of linear transformations and Softshrink activation functions with a total of seven layers in the model.
The current performance of this model is not satisfying. In this case, the profiler can be used to find the bottleneck.
In the Metal System Trace, first, make sure to enable the os_signpost. This will allow you to capture the PyTorch operator information. Next, check that the device and the right executable are set, in this case, the Python binary. Then click on the record button.
Instruments is now recording the PyTorch execution. I'll let it run for couple of seconds to make sure I capture enough data. Then I click Stop.
In the os_signpost tab, disclose the PyTorch Intervals timeline.
This timeline displays the execution time of an operator, alongside PyTorch Metadata, such as string identifiers, data types, and copy lengths.
Zooming into the timeline reveals PyTorch operators used by this example. The pattern from this trace can be easily identified to the custom Sequential model made of seven layers.
From the trace, it's clear that the bottleneck is in the Softshrink fallback to the CPU. This process is very inefficient. The model incurs the overhead from the CPU execution of the Softshrink operator and the additional copies, while the GPU is starved. Most of the gaps in the GPU timeline are coming from the Softshrink activation function falling back to CPU. In order to fix this, I'll write a custom kernel to improve the performance. There are four steps to write a custom operation. First, implement the operation in Objective-C and Metal. Next, create the Python bindings for your Objective-C code and compile your extension. Finally, once your extension is built, import the operation into your training script and begin using it. I'll start with the operation implementation.
Start by importing the Torch extension header. This includes all the necessary PyTorch bits to write C++ extensions.
Then define the compute function and use the get_command_buffer MPS backend API to get a reference to the MPSStream Command Buffer. Similarly, use the get_dispatch_queue API to get a reference to the serial queue.
Next, create an encoder using the command buffer and define the custom GPU kernel.
You encode the kernel inside the dispatch queue to ensure that submissions from multiple threads are serialized.
After all the work is encoded, use the synchronize API to wait until the current command buffer is done running, so you can observe serialized submissions. Or if you don't need serialization, use the commit API.
Next, bind your custom functions. You can use PYBIND11 to bind the Objective-C functions into Python in a very simple manner. For this extension, the necessary binding code spans only two lines.
After binding, compile your extension. First import torch.utils.cpp_extension.
This provides a load function which you can use to compile your extension. Next, pass the name of your extension to build, then a list of relative or absolute paths to the source code files. Optionally, you can list additional compiler flags to forward to the build. The load function will compile the source files into a shared library, which will be subsequently loaded into the current Python process as a module.
Finally, import the operator into your script to begin using it.
Start by importing the compiled library and change the previous Sequential model to use the custom Softshrink kernel.
Let's run the same model again and check the result.
With the newly added custom operator, the model runs much more efficiently.
All the copies and intermediate tensors created by the fallback to the CPU are gone, and the Sequential model runs much faster. Now let's explore more ways your network can be further improved.
PyTorch MPS backend now supports automatic mixed precision, which allows you to train faster using less memory and without loss in quality. To understand mixed precision, I will first review the supported data types. Mixed precision training is a mode that allows training deep learning models with a mix of single precision floating point and half precision floating point. Starting with macOS Sonoma, MPSGraph adds support for a new data type, bfloat16.
bfloat16 is a 16-bit floating point format for deep learning. It is comprised of 1 sign bit, 8 exponent bits, and 7 mantissa bits. This is different from the standard IEEE 16-bit floating point format, which was not designed with deep learning applications in mind. Automatic Mixed Precision will be enabled for both float16 and bfloat16.
Automatic mixed precision chooses the right precision per layer by measuring the performance of the network in default precision, then it runs again, with mixed precision settings to optimize the performance without impacting the accuracy. Some layers of the neural networks can be executed at lower precision, such as convolutional or linear layers. Other layers such as reductions will often require a higher precision level.
Adding Automatic Mixed Precision support to your network is a very easy process. First, add autocast. Both float16 and bfloat16 are supported. Autocast serves as a context manager that allows a region of the script to run in mixed precision.
In this region, MPS ops run in a data type chosen by autocast to improve performance while maintaining accuracy.
The MPS backend has also been significantly optimized. With PyTorch 2.0 and macOS Sonoma, the MPS backend is up to five times faster compared to our previous release. That's it for PyTorch. Now let's move on to TensorFlow. The TensorFlow Metal backend has matured to a stable 1.0 release version. In this release, a grappler remapping optimizer pass has been added to the plugin. The Metal plugin also gets mixed precision support, and the installation process is now simpler than before.
The performance of the TensorFlow Metal backend has been improved through addition of automatic fusion of recognized computation patterns. These computations include fused convolutions and matrix multiplications, optimizer operations, and RNN cells. This optimization happens automatically through the grappler pass when the computation graph is created.
Here I have an example of a common computation of a two-dimensional convolution operation. The convolution is often followed by an addition function, a common pattern in convolutional neural networks. By identifying this pattern, the grappler pass can remap the computation.
This allows you to use a more optimized kernel to achieve the same output, leading to better performance. Like in PyTorch, TensorFlow also gets mixed precision support. TensorFlow allows setting mixed precision globally. This enables all network layers to be automatically created with the requested data type policy, so enabling this change in your standard workflow requires minimal changes to existing code.
Global policy can be set to use either Float16 or BFloat16.
In addition to improvements in performance, the user experience in enabling the Metal acceleration has been streamlined. From now on, simply following the usual path of installing the TensorFlow wheel and the TensorFlow-Metal plugin through a package manager will enable the Metal acceleration. For those who want to stay on the bleeding edge of TensorFlow development, the Metal acceleration support is now also available on the nightly releases of TensorFlow. Now let's talk about the new GPU acceleration for JAX. This year, JAX GPU acceleration will be supported through the Metal backend, similar to PyTorch and TensorFlow.
JAX is a Python library for high-performance numerical computing and machine learning research. It is based on the popular NumPy framework for working with large arrays, with three key extensions for machine learning research.
First, it supports automatic differentiation using the grad function. It can differentiate through a large subset of Python's features, and it can even take high order derivatives. JAX also supports fast and efficient vectorization. Given a function apply_matrix, you could loop over a batch dimension in Python, but it may run at sub-optimal performance. In this case, vmap can be used to add batching support automatically.
And further, JAX lets you just-in-time compile your function into optimized kernels using an API called jit. In the same case, jit is used to transform the function on top of vmap to make it run faster.
On a MacBook Pro with M2 Max, JAX Metal acceleration provides amazing speedups, with an average of ten times faster than the CPU across these networks. For more details on environment setup and installation of JAX, please refer to the Metal Developer Resources web page.
Let's switch gears and move to ML inference. I will start by introducing a new serialization format for MPSGraph that you use to optimize your load times. This new serialization format can be generated from your existing serialized networks from other frameworks. Finally, I will show you how to optimize the memory footprint of your network by leveraging 8-bit integer quantization. Let's begin. An MPSGraph can be created using the high level APIs with full flexibility, layer by layer. Please refer to the video on building customized ML models with Metal Performance Shaders Graph for details. After defining and compiling your custom graph, it will then execute through the MPSGraphExecutable to get results. Normally, this process works great. However, in complex graphs with many layers, this initial compilation can lead to high application launch times.
MPSGraph has a new serialization format called MPSGraphPackage, to address exactly this problem. This new serialization format allows you to create the MPSGraphExecutable ahead of time. Once created, the optimized MPSGraphExecutable can be loaded directly from a MPSGraphPackage file. Creating a MPSGraphPackage is very simple.
All you need to do is to create a serialization descriptor and pass it to the serialize function of the MPSGraphExecutable you want to serialize. You'll also need to pass a path to store it. After creating the package, this is how you load the graph into your app. You need a compilation descriptor and the path to your stored package. Then use them to initialize the MPSGraphExecutable. If you've been already using MPSGraph, you can easily adopt the new serialization format using the APIs we have presented. But if you're coming from other frameworks, you can now easily migrate to MPSGraphPackage using the new MPSGraphTool. For users of CoreML, you can pass your ML Programs tp the MPSGraphTool, which will create a MPSGraphPackage for you. The same goes for ONNX, where you can use your ONNX file as the input. This new tool lets you quickly include your existing models to your MPSGraph application without the need to encode the inference model manually.
Here's how you use the command line tool. You give the MPSGraphTool a flag to declare the input model type, in this case, CoreML Package. You also provide it with the path to your output destination and the name of your output model. Additionally, you define the target platform and minimum OS version. After conversion, the produced MPSGraphPackages can be loaded to your app and executed directly.
Next, lets discuss how you can improve the efficiency of your computations using the 8-bit integer quantizations. It's common to use floating point formats to do training and inference, such as 16-bit floating point format. However, at inference, these models may take a longer time to predict results. Instead, it's better in many cases to use reduced precision or 8-bit integer numbers. This will help you in saving memory bandwith and reduce the memory footprint of your model.
For 8-bit integer formats, there are two types of quantization: symmetric and asymmetric. MPSGraph now supports APIs for both of them. Compared to the symmetric quantization, the asymmetric one lets you specify a quantization bias, denoted by zeroPoint here.
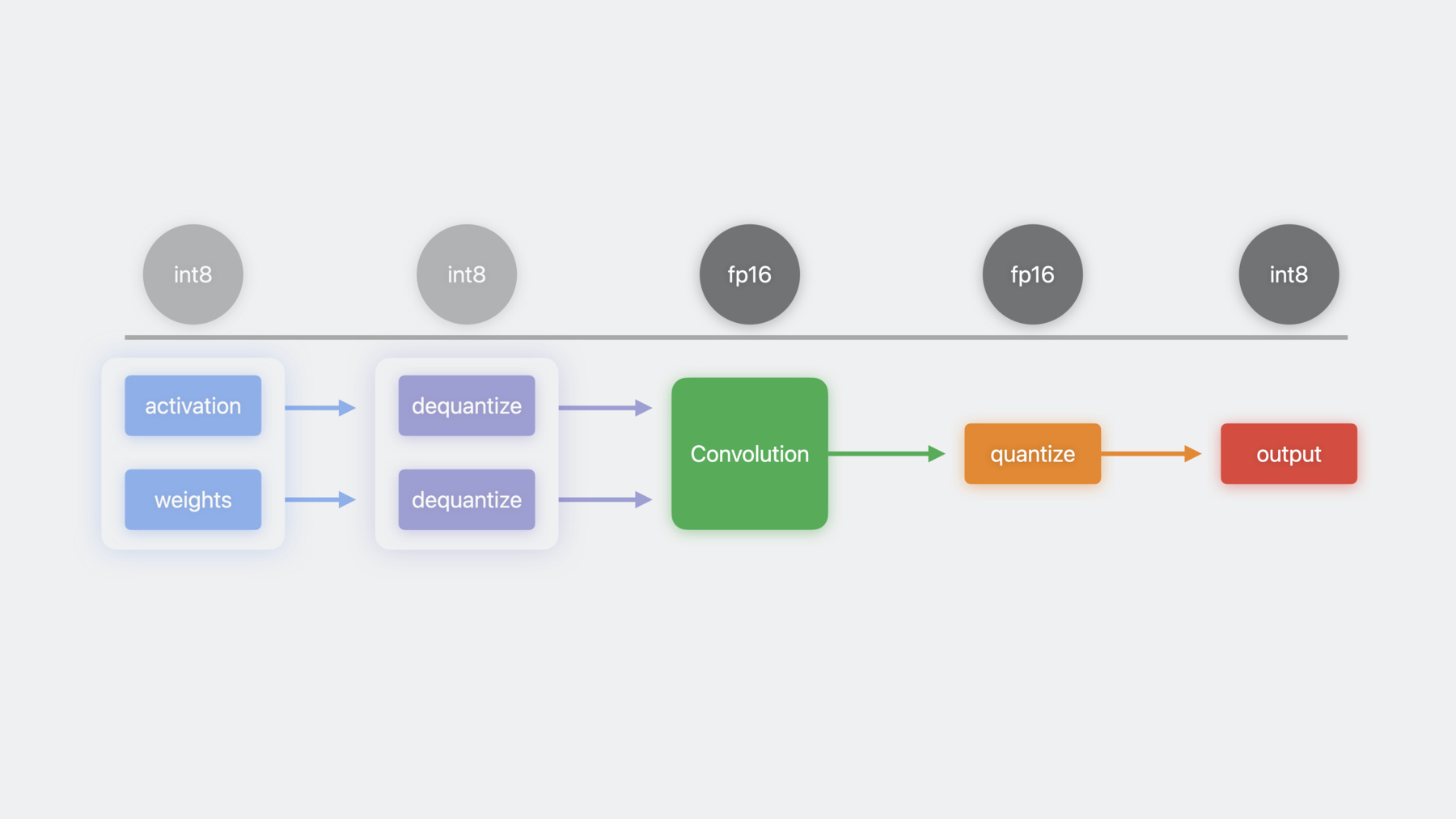
Now let's delve into using quantized computations through an example, starting with activation and weights in an Int8 format as the inputs. These inputs are dequantized to floating point format using the dequantizeTensor op in MPSGraph. Now the floating point inputs can be fed into a convolution operation. The resulting floating point tensor can then be quantized back to Int8 using the quantizeTensor op. MPSGraph will automatically fuse all of these kernels into a single operation, therefore saving memory bandwidth and potentially improving performance.
And this is how you can use the quantization support in MPSGraph.
In addition to the previous new features, MPSGraph supports even more machine learning operators. Starting this year, complex types are supported for most graph operations. You can use complex numbers either with single precision or half precision floating point formats.
Building on the complex data type, MPSGraph adds operators for computing Fast Fourier Transformations. You can apply complex to complex, complex to real, and real to complex transformations up to four dimensions. These are very common in audio, video, and image processing applications. Furthermore, using MPSGraph, you can now perform three-dimensional convolutions, grid sampling, Sort and ArgSort, and cumulative operations, including sums, products, minima, and maxima. And this concludes the discussion about the new features in MPSGraph. Let's review what was presented today in this session.
I went over the improvements in accelerating popular ML frameworks like PyTorch and TensorFlow through Metal. Now you can also take advantage of the new Metal accelerated JAX framework. We also discussed how to seamlessly integrate your existing models from other frameworks to MPSGraph using the new serialization tools. And this concludes our talk. We can't wait to see the amazing content that you will create using all of these features. Thanks for watching. ♪ ♪
-