-
Swift concurrency: Behind the scenes
Dive into the details of Swift concurrency and discover how Swift provides greater safety from data races and thread explosion while simultaneously improving performance. We'll explore how Swift tasks differ from Grand Central Dispatch, how the new cooperative threading model works, and how to ensure the best performance for your apps.
To get the most out of this session, we recommend first watching “Meet async/await in Swift,” “Explore structured concurrency in Swift,” and “Protect mutable state with Swift actors.”Resources
Related Videos
WWDC23
WWDC22
WWDC21
- Explore structured concurrency in Swift
- Meet async/await in Swift
- Protect mutable state with Swift actors
- Swift concurrency: Update a sample app
- What‘s new in Swift
WWDC17
WWDC16
-
Search this video…
♪ Bass music playing ♪ ♪ Rokhini Prabhu: Hello, and welcome to "Swift Concurrency Behind the Scenes." My name is Rokhini, and I work on the Darwin Runtime team. Today, my colleague Varun and I are very excited to talk to you about some of the underlying nuances around Swift concurrency.
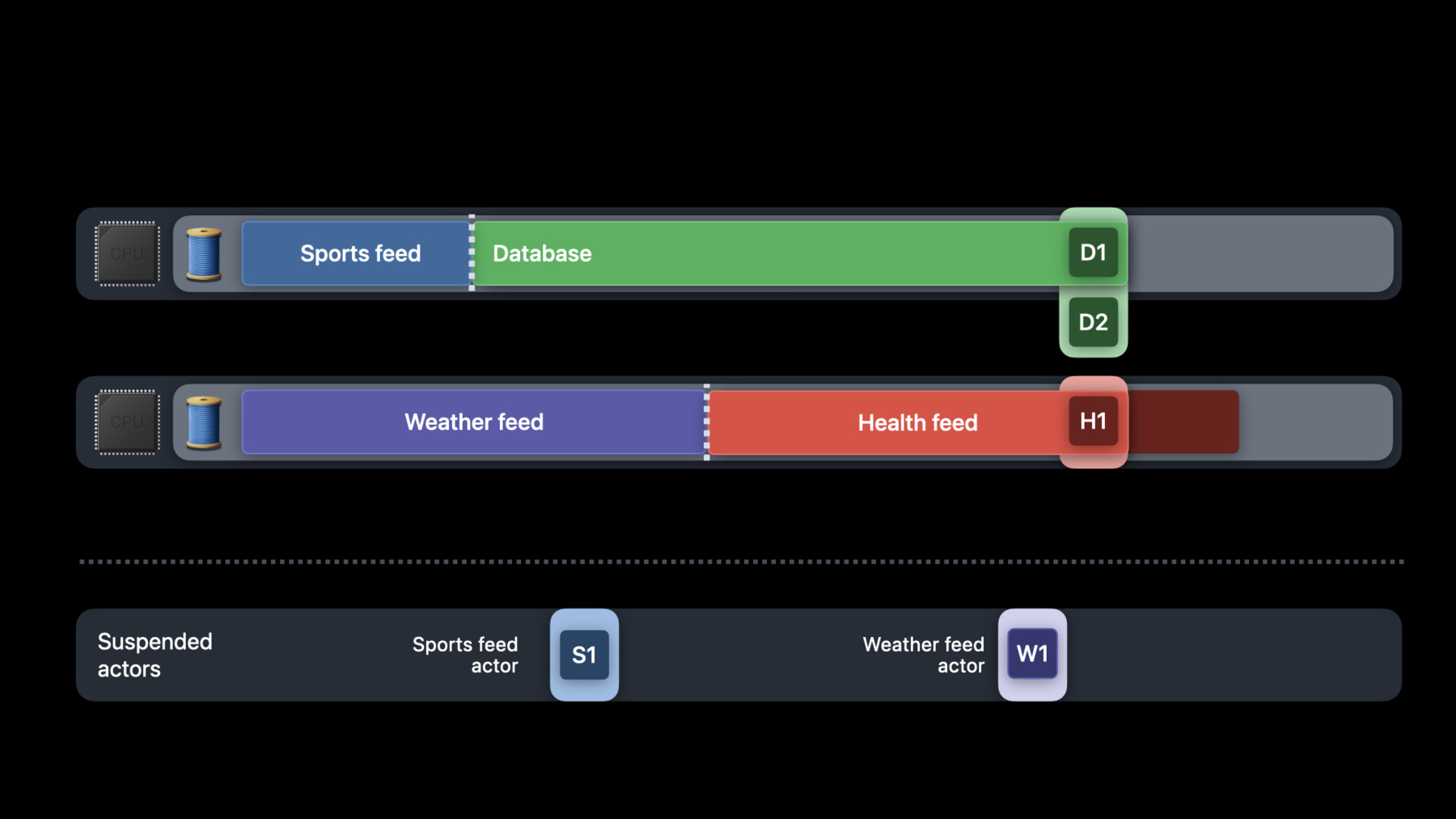
This is an advanced talk which builds upon some of the earlier talks on Swift concurrency. If you are unfamiliar with the concepts of async/await, structured concurrency, and actors I encourage you to watch these others talks first. In the previous talks on Swift concurrency you've learned about the various language features available this year native to Swift and about how to use them. In this talk, we will be diving deeper to understand why these primitives are designed the way they are, not only for language safety but also for performance and efficiency. As you experiment and adopt Swift concurrency in your own apps, we hope this talk will give you a better mental model of how to reason about Swift concurrency as well how it interfaces with existing threading libraries like Grand Central Dispatch. We're going to discuss a few things today. First, we'll talk about the threading model behind Swift concurrency and contrast it with Grand Central Dispatch. We'll talk about how we've taken advantage of concurrency language features to build a new thread pool for Swift, thereby achieving better performance and efficiency. Lastly, in this section, we'll touch on considerations you need to keep in mind when porting your code to using Swift concurrency. Varun will then talk about synchronization in Swift concurrency via actors. We'll talk how actors work under the hood, how they compare to existing synchronization primitives you already may be familiar with -- like serial dispatch queues -- and finally, some things to keep in mind when writing code with actors. We have a lot of ground to cover today so let's dive right in. In our discussion today about threading models, we'll start by taking a look at an example app written with the technologies available today like Grand Central Dispatch. We will then see how the same application fares when rewritten with Swift concurrency. Suppose I wanted to write my own news feed reader app. Let's talk about what the high-level components of my application might be. My app will have a main thread that will be driving the user interface. I will have a database keeping track of the news feeds that the user is subscribed to, and finally, a subsystem to handle the networking logic to fetch the latest contents from the feeds. Let's consider how one might structure this app with Grand Central Dispatch queues. Let's suppose that the user has asked to see the latest news. On the main thread, we will handle the user event gesture. From here, we will dispatch async the request onto a serial queue that handles the database operations. The reason for this is twofold. Firstly, by dispatching the work onto a different queue, we ensure that the main thread can remain responsive to user input even while waiting for a potentially large amount of work to happen. Secondly, access to the database is protected, since a serial queue guarantees mutual exclusion. While on the database queue, we'll iterate through the news feeds the user has subscribed to and for each of them, schedule a networking request to our URLSession to download the contents of that feed. As the results of the networking requests come in, the URLSession callback will be called on our delegate queue which is a concurrent queue. In the completion handler for each of the results, we will synchronously update the database with the latest requests from each of these feeds, so as to cache it for future use. And finally, we'll wake up the main thread to refresh the UI. This seems like a perfectly reasonable way to structure such an application. We've made sure not to block the main thread while working on requests. And by handling the network requests concurrently, we've taken advantage of the inherent parallelism in our program. Let's take a closer look at a code snippet that shows how we process the results of our networking requests. First, we have created a URLSession for performing downloads from our news feeds. As you can see here, we've set the delegate queue of this URLSession to be a concurrent queue. We then iterate over all the news feeds that need to be updated and for each of them, schedule a data task in the URLSession. In the completion handler of the data task -- which will be invoked on the delegate queue -- we deserialize the results of our download and format them into articles. We then dispatch sync against our database queue before updating the results for the feed. So here you can see that we've written some straight-line code to do something fairly straightforward but this code has some hidden performance pitfalls. To understand more about these performance problems, we need to first dig into how threads are brought up to handle work on GCD queues. In Grand Central Dispatch, when work is enqueued onto a queue, the system will bring up a thread to service that work item. Since a concurrent queue can handle multiple work items at once, the system will bring up several threads until we have saturated all the CPU cores. However, if a thread blocks -- as seen on the first CPU core here -- and there is more work to be done on the concurrent queue, GCD will bring up more threads to drain the remaining work items. The reason for this is twofold. Firstly, by giving your process another thread, we are able to ensure that each core continues to have a thread that executes work at any given time. This gives your applications a good, continuing level of concurrency. Secondly the blocked thread may be waiting on a resource like a semaphore, before it can make further progress. The new thread that is brought up to continue working on the queue may be able to help unblock the resource that is being waited on by the first thread. So now that we understand a bit more about thread bringups in GCD, let's go back and look at the CPU execution of the code from our news app. On a two-core device like the Apple Watch, GCD will first bring up two threads to process the feed update results. As the threads block on accessing the database queue, more threads are created to continue working on the networking queue. The CPU then has to context switch between different threads processing the networking results as indicated by the white vertical lines between the various threads. This means that in our news application, we could easily end up with a very large number of threads. If the user has a hundred feeds that need to be updated, then each of those URL data tasks will have a completion block on the concurrent queue when the network requests complete. GCD will bring up more threads when each of the callbacks block on the database queue, resulting in the application having lots of threads. Now you might ask, what's so bad about having a lot of threads in our application? Having a lot of threads in our applications means that the system is overcommitted with more threads than we have CPU cores. Consider an iPhone with six CPU cores. If our news application has a hundred feed updates that need to be processed, this means that we have overcommitted the iPhone with 16 times more threads than cores. This is the phenomenon we call thread explosion. Some of our previous WWDC talks have gone into further detail on the risks associated with this, including the possibility of deadlocks in your application. Thread explosion also comes with memory and scheduling overhead that may not be immediately obvious, so let's look into this further. Looking back at our news application, each of the blocked threads is holding onto valuable memory and resources while waiting to run again. Each blocked thread has a stack and associated kernel data structures to track the thread. Some of these threads may be holding onto locks which other threads that are running might need. This is a large number of resources and memory to be holding onto for threads which are not making progress. There is also greater scheduling overhead as a result of thread explosion. As new threads are brought up, the CPU need to perform a full thread context switch in order to switch away from the old thread to start executing the new thread. As the blocked threads become runnable again, the scheduler will have to timeshare the threads on the CPU so that they are all able to make forward progress. Now, timesharing of threads is fine if that happens a few times -- that is the power of concurrency. But when there is thread explosion, having to timeshare hundreds of threads on a device with limited cores can lead to excessive context switching. The scheduling latencies of these threads outweigh the amount of useful work they would do, therefore, resulting in the CPU running less efficiently as well. As we've seen so far, it is easy to miss some of these nuances about the threading hygiene when writing applications with GCD queues thereby resulting in poor performance and greater overhead. Building on this experience, Swift has taken a different approach when designing concurrency into the language. We've built Swift concurrency with performance and efficiency in mind as well so that your apps can enjoy controlled, structured, and safe concurrency. With Swift, we want to change the execution model of apps from the following model, which has lots of threads and context switches, to this. Here you see that we have just two threads executing on our two-core system and there are no thread context switches. All of our blocked threads go away and instead we have a lightweight object known as a continuation to track resumption of work. When threads execute work under Swift concurrency they switch between continuations instead of performing a full thread context switch. This means that we now only pay the cost of a function call instead. So the runtime behavior that we want for Swift concurrency is to create only as many threads as there are CPU cores, and for threads to be able to cheaply and efficiently switch between work items when they are blocked. We want you to be able to write straight-line code that is easy to reason about and also gives you safe, controlled concurrency. In order to achieve this behavior that we are after, the operating system needs a runtime contract that threads will not block, and that is only possible if the language is able to provide us with that. Swift's concurrency model and the semantics around it have therefore been designed with this goal in mind. To that end, I'd like to dive into two of Swift's language-level features that enable us to maintain a contract with the runtime. The first comes from the semantics of await and the second, from the tracking of task dependencies in the Swift runtime. Let's consider these language features in the context of our example news application. This is the code snippet we walked through earlier that handles the results of our news feed updates. Let's see what this logic looks like when written with Swift concurrency primitives instead. We'd first start with creating an async implementation of our helper function. Then, instead of handling the results of our networking requests on a concurrent dispatch queue, here we are using a task group instead to manage our concurrency. In the task group, we will create child tasks for each feed that needs to be updated. Each child task will perform a download from the feed's URL using the shared URLSession. It will then deserialize the results of the download, format them into articles and finally, we will call an async function to update our database. Here, when calling any async functions, we annotate it with an await keyword. From the "Meet async/await in Swift" talk, we learned that an await is an asynchronous wait. That is, it does not block the current thread while waiting for results from the async function. Instead, the function may be suspended and the thread will be freed up to execute other tasks. How does this happen? How does one give up a thread? My colleague Varun will now shed light on what is done under the hood in the Swift runtime to make this possible. Varun Gandhi: Thanks, Rokhini. Before jumping into how async functions are implemented, let's do a quick refresher on how nonasync functions work. Every thread in a running program has one stack, which it uses to store state for function calls. Let's focus on one thread for now. When the thread executes a function call, a new frame is pushed onto its stack. This newly created stack frame can be used by the function to store local variables, the return address, and any other information that is needed. Once the function finishes executing and returns, its stack frame is popped. Now let's consider async functions. Suppose that a thread called an add(_:) method on the Feed type from the updateDatabase function. At this stage, the most recent stack frame will be for add(_:). The stack frame stores local variables that do not need to be available across a suspension point. The body of add(_:) has one suspension point, marked by await. The local variables, id and article, are immediately used in the body of the for loop after being defined, without any suspension points in-between. So they will be stored in the stack frame. Additionally, there will be two async frames on the heap, one for updateDatabase and one for add. Async frames store information that does need to be available across suspension points. Notice that the newArticles argument is defined before await but needs to be available after the await. This means that the async frame for add will keep track of newArticles. Suppose the thread continues executing. When the save function starts executing, the stack frame for add is replaced by a stack frame for save. Instead of adding new stack frames, the top most stack frame is replaced since any variables that will be needed in the future will already have been stored in the list of async frames. The save function also gains an async frame for its use. While the articles are being saved to the database, it would be better if the thread could do some useful work instead of being blocked. Suppose the execution of the save function is suspended. And the thread is reused to do some other useful work instead of being blocked. Since all information that is maintained across a suspension point is stored on the heap, it can be used to continue execution at a later stage. This list of async frames is the runtime representation of a continuation. Say after a little while, the database request is complete, and suppose some thread is freed up. This could be the same thread as before, or it could be a different thread. Suppose the save function resumes executing on this thread. Once it finishes executing and returns some IDs, then the stack frame for save will again be replaced by a stack frame for add. After that, the thread can start executing zip. Zipping two arrays is a nonasync operation, so it will create a new stack frame. Since Swift continues to use the operating system stack, both async and nonasync Swift code can efficiently call into C and Objective-C. Moreover, C and Objective-C code can continue efficiently calling nonasync Swift code. Once the zip function finishes, its stack frame will be popped and execution will continue. So far, I've described how await is designed to ensure efficient suspension and resumption, while freeing up a thread's resources to do other work. Next, Rokhini will describe the second language feature, which is the runtime's tracking of dependencies between tasks. Rokhini: Thanks, Varun. As described earlier, a function can be broken up into continuations at an await, also known as a potential suspension point. In this case, the URLSession data task is the async function and the remaining work after it is the continuation. The continuation can only be executed after the async function is completed. This is a dependency tracked by the Swift concurrency runtime. Similarly, within the task group, a parent task may create several child tasks and each of those child tasks needs to complete before a parent task can proceed. This is a dependency that is expressed in your code by the scope of the task group and therefore explicitly known to the Swift compiler and runtime. In Swift, tasks can only await other tasks that are known to the Swift runtime -- be it continuations or child tasks. Therefore, code when structured with Swift's concurrency primitives provide the runtime with a clear understanding of the dependency chain between the tasks. So far, you've learned how Swift's language features allow a task to be suspended during an await. Instead, the executing thread is able to reason about task dependencies and pick up a different task instead. This means that code written with Swift concurrency can maintain a runtime contract that threads are always able to make forward progress. We have taken advantage of this runtime contract to build integrated OS support for Swift concurrency. This is in the form of a new cooperative thread pool to back Swift concurrency as the default executor. The new thread pool will only spawn as many threads as there are CPU cores, thereby making sure not to overcommit the system. Unlike GCD's concurrent queues, which will spawn more threads when work items block, with Swift threads can always make forward progress. Therefore, the default runtime can be judicious about controlling how many threads are spawned. This lets us give your applications the concurrency you need while making sure to avoid the known pitfalls of excessive concurrency. In previous WWDC talks about concurrency with Grand Central Dispatch, we've recommended that you structure your applications into distinct subsystems and maintain one serial dispatch queue per subsystem to control the concurrency of your application. This meant that it was difficult for you to get concurrency greater than one within a subsystem without running the risk of thread explosion. With Swift, the language gives us strong invariants which the runtime has leveraged, thereby being able to transparently provide you with better-controlled concurrency in the default runtime. Now that you understand a bit more about the threading model for Swift concurrency, let's go through some considerations to keep in mind while adopting these exciting new features in your code. The first consideration that you need to keep in mind has to do with performance when converting synchronous code into asynchronous code. Earlier, we talked through some of the costs associated with concurrency such as additional memory allocations and logic in the Swift runtime. As such, you need to be careful to only write new code with Swift concurrency when the cost of introducing concurrency into your code outweighs the cost of managing it. The code snippet here might not actually benefit from the additional concurrency of spawning a child task simply to read a value from the user's defaults. This is because the useful work done by the child task is diminished by the cost of creating and managing the task. We therefore recommend profiling your code with Instruments system trace to understand it's performance characteristics as you adopt Swift concurrency. The second thing to be careful about is the notion of atomicity around an await. Swift makes no guarantee that the thread which executed the code before the await is the same thread which will pick up the continuation as well. In fact, await is an explicit point in your code which indicates that atomicity is broken since the task may be voluntarily descheduled. As such, you should be careful not to hold locks across an await. Similarly, thread-specific data will not be preserved across an await either. Any assumptions in your code which expect thread locality should be revisited to account for the suspending behavior of await. And lastly, the final consideration has to do with the runtime contract that is foundational to the efficient threading model in Swift. Recall that with Swift, the language allows us to uphold a runtime contract that threads will always be able to make forward progress. It is based on this contract that we have built a cooperative thread pool to be the default executor for Swift. As you adopt Swift concurrency, it is important to ensure that you continue to maintain this contract in your code as well so that the cooperative thread pool can function optimally. It is possible to maintain this contract within the cooperative thread pool by using safe primitives that make the dependencies in your code explicit and known. With Swift concurrency primitives like await, actors, and task groups, these dependencies are made known at compile time. Therefore, the Swift compiler enforces this and helps you preserve the runtime contract. Primitives like os_unfair_locks and NSLocks are also safe but caution is required when using them. Using a lock in synchronous code is safe when used for data synchronization around a tight, well-known critical section. This is because the thread holding the lock is always able to make forward progress towards releasing the lock. As such, while the primitive may block a thread for a short period of time under contention, it does not violate the runtime contract of forward progress. It is worth noting that unlike Swift concurrency primitives, there is no compiler support to aid in correct usage of locks, so it is your responsibility to use this primitive correctly. On the other hand, primitives like semaphores and condition variables are unsafe to use with Swift concurrency. This is because they hide dependency information from the Swift runtime, but introduce a dependency in execution in your code. Since the runtime is unaware of this dependency, it cannot make the right scheduling decisions and resolve them. In particular, do not use primitives that create unstructured tasks and then retroactively introduce a dependency across task boundaries by using a semaphore or an unsafe primitive. Such a code pattern means that a thread can block indefinitely against the semaphore until another thread is able to unblock it. This violates the runtime contract of forward progress for threads. To help you identify uses of such unsafe primitives in your codebase, we recommend testing your apps with the following environment variable. This runs your app under a modified debug runtime, which enforces the invariant of forward progress. This environment variable can be set in Xcode on the Run Arguments pane of your project scheme as shown here. When running your apps with this environment variable, if you see a thread from the cooperative thread pool that appears to be hung it indicates the use of an unsafe blocking primitive. Now, having learned about how the threading model has been designed for Swift concurrency, let's discover a little bit more about the primitives that are available to us to synchronize state in this new world. Varun: In the Swift concurrency talk on actors you've seen how actors can be used to protect mutable state from concurrent access. Put differently, actors provide a powerful new synchronization primitive that you can use. Recall that actors guarantee mutual exclusion: an actor may be executing at most one method call at a time. Mutual exclusion means that the actor's state is not accessed concurrently, preventing data races. Let's see how actors compare to other forms of mutual exclusion. Consider the earlier example of updating the database with some articles by syncing to a serial queue. If the queue is not already running we say that there is no contention. In this case, the calling thread is reused to execute the new work item on the queue without any context switch. Instead, if the serial queue is already running the queue is said to be under contention. In this situation, the calling thread is blocked. This blocking behavior is what triggered thread explosion as Rokhini described earlier in the talk. Locks have this same behavior. Because of the problems associated with blocking, we have generally advised that you prefer using dispatch async. The primary benefit of dispatch async is that it is nonblocking. So even under contention, it will not lead to thread explosion. The downside of using dispatch async with a serial queue is that when there is no contention Dispatch needs to request a new thread to do the async work while the calling thread continues to do something else. Hence, frequent use of dispatch async can lead to excess thread wakeups and context switches. This brings us to actors. Swift's actors combine the best of both worlds by taking advantage of the cooperative thread pool for efficient scheduling. When you call a method on an actor that is not running, the calling thread can be reused to execute the method call. In the case where the called actor is already running, the calling thread can suspend the function it is executing and pick up other work. Let's look at how these two properties work in the context of the example news app. Let's focus on the database and networking subsystems. When updating the application to use Swift concurrency, the serial queue for the database would be replaced by a database actor. The concurrent queue for networking could be replaced by one actor for each news feed. For simplicity, I've only shown three feed actors here -- for the sports feed, the weather feed and the health feed -- but in practice, there will be many more. These actors would run on the cooperative thread pool. The feed actors interact with the database to save articles and perform other actions. This interaction involves execution switching from one actor to another. We call this process actor hopping. Let's discuss how actor hopping works. Suppose that the actor for the sports feed is running on a thread from the cooperative pool, and it decides to save some articles into the database. For now, let's consider that the database is not being used. This is the uncontended case. The thread can directly hop from the sports feed actor to the database actor. There are two things to notice here. First, the thread did not block while hopping actors. Second, hopping did not require a different thread; the runtime can directly suspend the work item for the sports feed actor and create a new work item for the database actor. Say the database actor runs for a while but it has not completed the first work item. At this moment, suppose that the weather feed actor tries to save some articles in the database. This creates a new work item for the database actor. An actor ensures safety by guaranteeing mutual exclusion; at most, one work item may be active at a given time. Since there is already one active work item, D1, the new work item, D2, will be kept pending. Actors are also nonblocking. In this situation, the weather feed actor will be suspended and the thread it was executing on is now freed up to do other work. After a little while, the initial database request is completed, so the active work item for the database actor is removed. At this point, the runtime may choose to start executing the pending work item for the database actor. Or it may choose to resume one of the feed actors. Or it could do some other work on the freed-up thread. When there is a lot of asynchronous work, and especially a lot of contention, the system needs to make trade-offs based on what work is more important. Ideally, high-priority work such as that involving user interaction, would take precedence over background work, such as saving backups. Actors are designed to allow the system to prioritize work well due to the notion of reentrancy. But to understand why reentrancy is important here, let's first take a look at how GCD handles priorities. Consider the original news application with the serial database queue. Suppose the database receives some high-priority work, such as for fetching the latest data to update the UI. It also receives low-priority work, such as for backing up the database to iCloud. This needs to be done at some point, but not necessarily immediately. As the code runs, new work items are created and added to the database queue in some interleaved order. Dispatch queues execute the items received in a strict first-in, first-out order. Unfortunately, this means that after item A has executed five low-priority items need to execute before getting to the next high-priority item. This is called a priority inversion. Serial queues work around priority inversion by boosting the priority of all of the work in the queue that's ahead of the high-priority work. In practice, this means that the work in the queue will be done sooner. However, it does not resolve the main issue, which is that items 1 through 5 still needed to complete before item B could start executing. Solving this issue requires changing the semantic model away from strict first-in, first-out. This brings us to actor reentrancy. Let's explore how reentrancy is connected to ordering with an example.
Consider the database actor executing on a thread. Suppose that it is suspended, awaiting some work, and the sports feed actor starts executing on that thread. Suppose after a while, the sports feed actor calls the database actor to save some articles. Since the database actor is uncontended, the thread can hop to the database actor even though it has one pending work item. To perform the save operation, a new work item will be created for the database actor. This is what actor reentrancy means; new work items on an actor can make progress while one or more older work items on it are suspended. The actor still maintains mutual exclusion: at most one work item can be executing at a given time. After some time, item D2 will finish executing. Notice that D2 finished executing before D1, even though it was created after D1. Hence, support for actor reentrancy means that actors can execute items in an order that is not strictly first-in, first-out. Let's revisit the example from before but with a database actor instead of a serial queue. First, work item A will execute, as it has high priority. Once that's done, there is the same priority inversion as before. Since actors are designed for reentrancy, the runtime may choose to move the higher-priority item to the front of the queue, ahead of the lower-priority items. This way, higher-priority work could be executed first, with lower-priority work following later. This directly addresses the problem of priority inversion, allowing for more effective scheduling and resource utilization. I've talked a bit about how actors using the cooperative pool are designed to maintain mutual exclusion and support effective prioritization of work. There is another kind of actor, the main actor, and its characteristics are somewhat different since it abstracts over an existing notion in the system: the main thread. Consider the example news app using actors. When updating the user interface, you will need to make calls to and from MainActor. Since the main thread is disjoint from the threads in the cooperative pool, this requires a context switch. Let's look at the performance implications of this with a code example. Consider the following code where we have a function updateArticles on MainActor, which loads articles out of the database and updates the UI for each article. Each iteration of the loop requires at least two context switches: one to hop from the main actor to the database actor and one to hop back. Let's see how the CPU usage for such a loop would look like. Since each loop iteration requires two context switches, there is a repeating pattern where two threads run one after another for a short span of time. If the number of loop iterations is low, and substantial work is being done in each iteration, that is probably all right. However, if execution hops on and off the main actor frequently, the overhead of switching threads can start to add up. If your application spends a large fraction of time in context switching, you should restructure your code so that work for the main actor is batched up. You can batch work by pushing the loop into the loadArticles and updateUI method calls, making sure they process arrays instead of one value at a time. Batching up work reduces the number of context switches. While hopping between actors on the cooperative pool is fast, you still need to be mindful of hops to and from the main actor when writing your app. Looking back, in this talk you've learned how we've worked on making the system the most efficient it can be, from the design of the cooperative thread pool -- the mechanism for nonblocking suspension -- to how actors are implemented. At each step, we're using some aspect of the runtime contract to improve the performance of your applications. We are excited to see how you use these incredible new language features to write clear, efficient, and delightful Swift code. Thank you for watching and have a great WWDC. ♪
-
-
4:57 - GCD code with hidden performance pitfalls
func deserializeArticles(from data: Data) throws -> [Article] { /* ... */ } func updateDatabase(with articles: [Article], for feed: Feed) { /* ... */ } let urlSession = URLSession(configuration: .default, delegate: self, delegateQueue: concurrentQueue) for feed in feedsToUpdate { let dataTask = urlSession.dataTask(with: feed.url) { data, response, error in // ... guard let data = data else { return } do { let articles = try deserializeArticles(from: data) databaseQueue.sync { updateDatabase(with: articles, for: feed) } } catch { /* ... */ } } dataTask.resume() } -
13:18 - Swift concurrency equivalent using a task group
func deserializeArticles(from data: Data) throws -> [Article] { /* ... */ } func updateDatabase(with articles: [Article], for feed: Feed) async { /* ... */ } await withThrowingTaskGroup(of: [Article].self) { group in for feed in feedsToUpdate { group.async { let (data, response) = try await URLSession.shared.data(from: feed.url) // ... let articles = try deserializeArticles(from: data) await updateDatabase(with: articles, for: feed) return articles } } } -
15:16 - Async functions: stack frames and async frames
// on Database func save(_ newArticles: [Article], for feed: Feed) async throws -> [ID] { /* ... */ } // on Feed func add(_ newArticles: [Article]) async throws { let ids = try await database.save(newArticles, for: self) for (id, article) in zip(ids, newArticles) { articles[id] = article } } func updateDatabase(with articles: [Article], for feed: Feed) async throws { // skip old articles ... try await feed.add(articles) } -
37:13 - Excessive context switching due to Main actor hoppping
// on database actor func loadArticle(with id: ID) async throws -> Article { /* ... */ } @MainActor func updateUI(for article: Article) async { /* ... */ } @MainActor func updateArticles(for ids: [ID]) async throws { for id in ids { let article = try await database.loadArticle(with: id) await updateUI(for: article) } } -
38:18 - Batch UI work to reduce the number of context switches
// on database actor func loadArticles(with ids: [ID]) async throws -> [Article] @MainActor func updateUI(for articles: [Article]) async @MainActor func updateArticles(for ids: [ID]) async throws { let articles = try await database.loadArticles(with: ids) await updateUI(for: articles) }
-