-
Explore structured concurrency in Swift
When you have code that needs to run at the same time as other code, it's important to choose the right tool for the job. We'll take you through the different kinds of concurrent tasks you can create in Swift, show you how to create groups of tasks, and find out how to cancel tasks in progress. We'll also provide guidance on when you may want to use unstructured tasks.
To get the most out of this session, we first recommend watching “Meet async/await in Swift.”Resources
Related Videos
WWDC23
WWDC22
WWDC21
-
Search this video…
♪ ♪ Hi, I’m Kavon, and I’ll be joined by my colleague, Joe, later on. Swift 5.5 introduces a new way to write concurrent programs, using a concept called structured concurrency. The ideas behind structured concurrency are based on structured programming, which so intuitive that you rarely think about it, but thinking about it will help you understand structured concurrency. So let’s dive in.
In the early days of computing, programs were hard to read because they were written as a sequence of instructions, where control-flow was allowed to jump all over the place. You don’t see that today, because languages use structured programming to make control-flow more uniform. For example, the if-then statement uses structured control-flow. It specifies that a nested block of code is only conditionally executed while moving from top to bottom. In Swift, that block also respects static scoping, meaning that names are only visible if they are defined in an enclosing block. This also means that the lifetime of any variables defined in a block will end when leaving the block. So, structured programming with static scope makes control-flow and variable lifetime easy to understand.
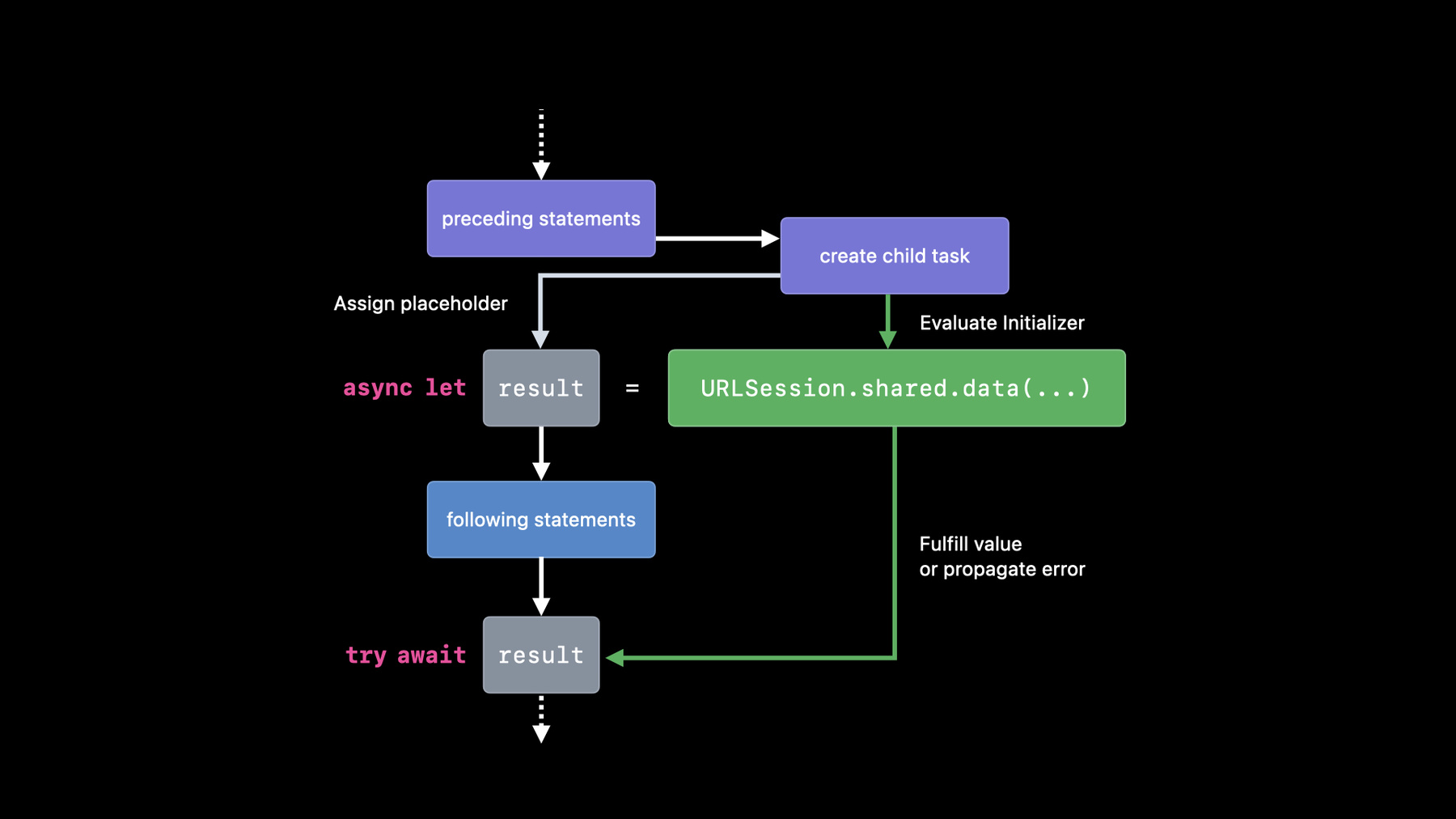
More generally, structured control-flow can be sequenced and nested together naturally. This lets you read your entire program top to bottom. So, those are the fundamentals of structured programming. As you can imagine, it is easy to take for granted, because it is so intuitive for us today. But today’s programs feature asynchronous and concurrent code, and they have not been able to use structured programming to make that code easier to write. First, let’s consider how structured programming makes asynchronous code simpler. Say that you need to fetch a bunch of images from the internet and resize them to be thumbnails sequentially. This code does that work asynchronously, taking in a collection of strings that identify the images. You’ll notice this function does not return a value when called. That’s because the function passes its result, or an error, to a completion handler it was given. This pattern allows the caller to receive an answer at a later time. As a consequence of that pattern, this function cannot use structured control-flow for error handling. That’s because it only makes sense to handle errors thrown out of a function, not into one. Also, this pattern prevents you from using a loop to process each thumbnail. Recursion is required, because the code that runs after the function completes must be nested within the handler. Now, let’s take a look at the previous code but rewritten to use the new async/await syntax, which is based on structured programming. I’ve dropped the completion handler argument from the function. Instead, it is annotated with “async” and “throws” in its type signature. It also returns a value instead of nothing. In the body of the function, I use “await” to say that an asynchronous action happens, and no nesting is required for the code that runs after that action. This means that I can now loop over the thumbnails to process them sequentially. I can also throw and catch errors, and the compiler will check that I didn’t forget. For an in-depth look at async/await, check out the session “Meet async/await in Swift.” So, this code is great, but what if you’re producing thumbnails for thousands of images? Processing each thumbnail one at a time is no longer ideal. Plus, what if each thumbnail’s dimensions must be downloaded from another URL, instead of being a fixed size? Now there is an opportunity to add some concurrency, so multiple downloads can happen in parallel. You can create additional tasks to add concurrency to a program. Tasks are a new feature in Swift that work hand-in-hand with async functions. A task provides a fresh execution context to run asynchronous code. Each task runs concurrently with respect to other execution contexts. They will be automatically scheduled to run in parallel when it is safe and efficient to do so. Because tasks are deeply integrated into Swift, the compiler can help prevent some concurrency bugs. Also, keep in mind that calling an async function does not create a new task for the call. You create tasks explicitly. There are a few different flavors of tasks in Swift, because structured concurrency is about the balance between flexibility and simplicity. So, for the remainder of this session, Joe and I will introduce and discuss each kind of task to help you understand their trade-offs. Let’s start with the simplest of these tasks, which is created with a new syntactic form called an async-let binding. To help you understand this new syntactic form, I want to first break down the evaluation of an ordinary let binding. There are two parts: the initializer expression on the right side of the equals and the variable’s name on the left. There may be other statements before or after the let, so I’ll include those here too. Once Swift reaches a let binding, its initializer will be evaluated to produce a value. In this example, that means downloading data from a URL, which could take a while. After the data has been downloaded, Swift will bind that value to the variable name before proceeding to the statements that follow. Notice that there is only one flow of execution here, as traced by the arrows through each step. Since the download could take a while, you want the program to start downloading the data and keep doing other work until the data is actually needed. To achieve this, you can just add the word async in front of an existing let binding. This turns it into a concurrent binding called an async-let. The evaluation of a concurrent binding is quite different from a sequential one, so let’s learn how it works. I will start just at the point before encountering the binding. To evaluate a concurrent binding, Swift will first create a new child task, which is a subtask of the one that created it. Because every task represents an execution context for your program, two arrows will simultaneously come out of this step. This first arrow is for the child task, which will immediately begin downloading the data. The second arrow is for the parent task, which will immediately bind the variable result to a placeholder value. This parent task is the same one that was executing the preceding statements. While the data is being downloaded concurrently by the child, the parent task continues to execute the statements that follow the concurrent binding. But upon reaching an expression that needs the actual value of the result, the parent will await the completion of the child task, which will fulfill the placeholder for result. In this example, our call to URLSession could also throw an error. This means that awaiting the result might give us an error. So I need to write “try” to take care of it. And don’t worry. Reading the value of result again will not recompute its value. Now that you’ve seen how async-let works, you can use it to add concurrency to the thumbnail fetching code. I have factored a piece of the previous code that fetches a single image into its own function. This new function here is also downloading data from two different URLs: one for the full-sized image itself and the other for metadata, which contains the optimal thumbnail size. Notice that with a sequential binding, you write “try await” on the right side of the let, because that’s where an error or suspension would be observed. To make both downloads happen concurrently, you write “async” in front of both of these lets. Since the downloads are now happening in child tasks, you no longer write “try await” on the right side of the concurrent binding. Those effects are only observed by the parent task when using the variables that are concurrently bound. So you write “try await” before the expression’s reading the metadata and the image data. Also, notice that using these concurrently bound variables does not require a method call or any other changes. Those variables have the same type that they did in a sequential binding. Now, these child tasks I’ve been talking about are actually part of a hierarchy called a task tree. This tree is not just an implementation detail. It’s an important part of structured concurrency. It influences the attributes of your tasks like cancellation, priority, and task-local variables. Whenever you make a call from one async function to another, the same task is used to execute the call. So, the function fetchOneThumbnail inherits all attributes of that task. When creating a new structured task like with async-let, it becomes the child of the task that the current function is running on. Tasks are not the child of a specific function, but their lifetime may be scoped to it. The tree is made up of links between each parent and its child tasks. A link enforces a rule that says a parent task can only finish its work if all of its child tasks have finished. This rule holds even in the face of abnormal control-flow which would prevent a child task from being awaited. For example, in this code, I first await the metadata task before the image data task. If the first awaited task finishes by throwing an error, the fetchOneThumbnail function must immediately exit by throwing that error. But what will happen to the task performing the second download? During the abnormal exit, Swift will automatically mark the unawaited task as canceled and then await for it to finish before exiting the function. Marking a task as canceled does not stop the task. It simply informs the task that its results are no longer needed. In fact, when a task is canceled, all subtasks that are decedents of that task will be automatically canceled too. So if the implementation of URLSession created its own structured tasks to download the image, those tasks will be marked for cancellation. The function fetchOneThumbnail finally exits by throwing the error once all of the structured tasks it created directly or indirectly have finished. This guarantee is fundamental to structured concurrency. It prevents you from accidentally leaking tasks by helping you manage their lifetimes, much like how ARC automatically manages the lifetime of memory. So far, I have given you an overview of how cancellation propagates. But when does the task finally stop? If the task is in the middle of an important transaction or has open network connections, it would be incorrect to just halt the task. That’s why task cancellation in Swift is cooperative. Your code must check for cancellation explicitly and wind down execution in whatever way is appropriate. You can check the cancellation status of the current task from any function, whether it is async or not. This means that you should implement your APIs with cancellation in mind, especially if they involve long-running computations. Your users may call into your code from a task that can be canceled, and they will expect the computation to stop as soon as possible. To see how simple it is to use cooperative cancellation, let’s go back to the thumbnail fetching example.
Here, I have rewritten the original function that was given all of the thumbnails to fetch so that it uses the fetchOneThumbnail function instead. If this function was called within a task that was canceled, we don’t want to hold up our application by creating useless thumbnails. So I can just add a call to checkCancellation at the start of each loop iteration. This call only throws an error if the current task has been canceled. You can also obtain the cancellation status of the current task as a Boolean value if that is more appropriate for your code. Notice that in this version of the function, I’m returning a partial result, a dictionary with only some of the thumbnails requested. When doing this, you must ensure that your API clearly states that a partial result may be returned. Otherwise, task cancellation could trigger a fatal error for your users because their code requires a complete result even during cancellation. So far, you’ve seen that async-let provides a lightweight syntax for adding concurrency to your program while capturing the essence of structured programming. The next kind of task I want to tell you about is called a group task. They offer more flexibility than async-let without giving up all of the nice properties of structured concurrency. As we saw earlier, async-let works well when there’s a fixed amount of concurrency available. Let’s consider both functions that I discussed earlier. For each thumbnail ID in the loop, we call fetchOneThumbnail to process it, which creates exactly two child tasks. Even if we in-lined the body of that function into this loop, the amount of concurrency will not change. Async-let is scoped like a variable binding. That means the two child tasks must complete before the next loop iteration begins. But what if we want this loop to kick off tasks to fetch all of the thumbnails concurrently? Then, the amount of concurrency is not known statically because it depends on the number of IDs in the array. The right tool for this situation is a task group. A task group is a form of structured concurrency that is designed to provide a dynamic amount of concurrency. You can introduce a task group by calling the withThrowingTaskGroup function. This function gives you a scoped group object to create child tasks that are allowed to throw errors. Tasks added to a group cannot outlive the scope of the block in which the group is defined. Since I have placed the entire for-loop inside of the block, I can now create a dynamic number of tasks using the group. You create child tasks in a group by invoking its async method. Once added to a group, child tasks begin executing immediately and in any order. When the group object goes out of scope, the completion of all tasks within it will be implicitly awaited. This is a consequence of the task tree rule I described earlier, because group tasks are structured too. At this point, we’ve already achieved the concurrency that we wanted: one task for each call to fetchOneThumbnail, which itself will create two more tasks using async-let. That’s another nice property of structured concurrency. You can use async-let within group tasks or create task groups within async-let tasks, and the levels of concurrency in the tree compose naturally. Now, this code is not quite ready to run. If we tried to run it, the compiler would helpfully alert us to a data race issue. The problem is that we’re trying to insert a thumbnail into a single dictionary from each child task. This is a common mistake when increasing the amount of concurrency in your program. Data races are accidentally created. This dictionary cannot handle more than one access at a time, and if two child tasks tried to insert thumbnails simultaneously, that could cause a crash or data corruption. In the past, you had to investigate those bugs yourself, but Swift provides static checking to prevent those bugs from happening in the first place. Whenever you create a new task, the work that the task performs is within a new closure type called a @Sendable closure. The body of a @Sendable closure is restricted from capturing mutable variables in its lexical context, because those variables could be modified after the task is launched. This means that the values you capture in a task must be safe to share. For example, because they are value types, like Int and String, or because they are objects designed to be accessed from multiple threads, like actors, and classes that implement their own synchronization. We have a whole session dedicated to this topic, called “Protect mutable state with Swift actors,” so I encourage you to check it out. To avoid the data race in our example, you can have each child task return a value. This design gives the parent task the sole responsibility of processing the results. In this case, I specified that each child task must return a tuple containing the String ID and UIImage for the thumbnail. Then, inside each child task, instead of writing to the dictionary directly, I have them return the key value tuple for the parent to process. The parent task can iterate through the results from each child task using the new for-await loop. The for-await loop obtains the results from the child tasks in order of completion. Because this loop runs sequentially, the parent task can safely add each key value pair to the dictionary. This is just one example of using the for-await loop to access an asynchronous sequence of values. If your own type conforms to the AsyncSequence protocol, then you can use for-await to iterate through them too. You can find out more in the “Meet AsyncSequence” session.
While task groups are a form of structured concurrency, there is a small difference in how the task tree rule is implemented for group tasks versus async-let tasks. Suppose when iterating through the results of this group, I encounter a child task that completed with an error. Because that error is thrown out of the group’s block, all tasks in the group will then be implicitly canceled and then awaited. This works just like async-let. The difference comes when your group goes out of scope through a normal exit from the block. Then, cancellation is not implicit. This behavior makes it easier for you to express the fork-join pattern using a task group, because the jobs will only be awaited, not canceled. You can also manually cancel all tasks before exiting the block using the group’s cancelAll method. Keep in mind that no matter how you cancel a task, cancellation automatically propagates down the tree. Async-let and group tasks are the two kind of tasks that provide scoped structured tasks in Swift. Now, I’ll hand things off to Joe, who will tell you about unstructured tasks. Thanks, Kavon. Hi. I’m Joe. Kavon showed you how structured concurrency simplifies error propagation, cancellation, and other bookkeeping when you add concurrency to a program with a clear hierarchy to the tasks. But we know that you don’t always have a hierarchy when you’re adding tasks to your program. Swift also provides unstructured task APIs, which give you a lot more flexibility at the expense of needing a lot more manual management. There are a lot of situations where a task might not fall into a clear hierarchy. Most obviously, you might not have a parent task at all if you’re trying to launch a task to do async computation from non-async code. Alternatively, the lifetime you want for a task might not fit the confines of a single scope or even a single function. You may, for instance, want to start a task in response to a method call that puts an object into an active state and then cancel its execution in response to a different method call that deactivates the object.
This comes up a lot when implementing delegate objects in AppKit and UIKit. UI work has to happen on the main thread, and as the Swift actors session discusses, Swift ensures this by declaring UI classes that belong to the main actor.
Let’s say we have a collection view, and we can’t yet use the collection view data source APIs. Instead, we want to use our fetchThumbnails function we just wrote to grab thumbnails from the network as the items in the collection view are displayed. However, the delegate method is not async, so we can’t just await a call to an async function. We need to start a task for that, but that task is really an extension of the work we started in response to the delegate action. We want this new task to still run on the main actor with UI priority. We just don’t want to bound the lifetime of the task to the scope of this single delegate method. For situations like this, Swift allows us to construct an unstructured task. Let’s move that asynchronous part of the code into a closure and pass that closure to construct an async task. Now here’s what happens at runtime. When we reach the point of creating the task, Swift will schedule it to run on the same actor as the originating scope, which is the main actor in this case. Meanwhile, control returns immediately to the caller. The thumbnail task will run on the main thread when there’s an opening to do so without immediately blocking the main thread on the delegate method. Constructing tasks this way gives us a halfway point between structured and unstructured code. A directly constructed task still inherits the actor, if any, of its launched context, and it also inherits the priority and other traits of the origin task, just like a group task or an async-let would. However, the new task is unscoped. Its lifetime is not bound by the scope of where it was launched. The origin doesn’t even need to be async. We can create an unscoped task anywhere. In trade for all of this flexibility, we must also manually manage the things that structured concurrency would have handled automatically. Cancellation and errors won’t automatically propagate, and the task’s result will not be implicitly awaited unless we take explicit action to do so.
So we kicked off a task to fetch thumbnails when a collection view item is displayed, and we should also cancel that task if the item is scrolled out of view before the thumbnails are ready. Since we’re working with an unscoped task, that cancellation isn’t automatic. Let’s implement it now. After we construct the task, let’s save the value we get. We can put this value into a dictionary keyed by the row index when we create the task so that we can use it later to cancel that task. We should also remove it from the dictionary once the task finishes so we don’t try to cancel a task if it’s already finished. Note here that we can access the same dictionary inside and outside of that async task without getting a data race flagged by the compiler. Our delegate class is bound to the main actor, and the new task inherits that, so they’ll never run together in parallel. We can safely access the stored properties of main actor-bound classes inside this task without worrying about data races. Meanwhile, if our delegate is later told that the same table row has been removed from the display, then we can call the cancel method on the value to cancel the task. So now we’ve seen how we can create unstructured tasks that run independent of a scope while still inheriting traits from that task’s originating context. But sometimes you don’t want to inherit anything from your originating context. For maximum flexibility, Swift provides detached tasks. Like the name suggests, detached tasks are independent from their context. They're still unstructured tasks. Their lifetimes are not bound to their originating scope. But detached tasks don’t pick anything else up from their originating scope either. By default, they aren’t constrained to the same actor and don’t have to run at the same priority as where they were launched. Detached tasks run independently with generic defaults for things like priority, but they can also be launched with optional parameters to control how and where the new task gets executed.
Let’s say that after we fetch thumbnails from the server, we want to write them to a local disk cache so we don’t hit the network again if we try to fetch them later. The caching doesn’t need to happen on the main actor, and even if we cancel fetching all of the thumbnails, it’s still helpful to cache any thumbnails we did fetch. So let’s kick off caching by using a detached task. When we detach a task, we also get a lot more flexibility in setting up how that new task executes. Caching should happen at a lower priority that doesn’t interfere with the main UI, and we can specify background priority when we detach this new task. Let’s plan ahead for a moment now. What should we do in the future if we have multiple background tasks we want to perform on our thumbnails? We could detach more background tasks, but we could also utilize structured concurrency inside of our detached task. We can combine all of the different kinds of tasks together to exploit each of their strengths. Instead of detaching an independent task for every background job, we can set up a task group and spawn each background job as a child task into that group. There are a number of benefits of doing so. If we do need to cancel the background task in the future, using a task group means we can cancel all of the child tasks just by canceling that top level detached task. That cancellation will then propagate to the child tasks automatically, and we don’t need to keep track of an array of handles. Furthermore, child tasks automatically inherit the priority of their parent. To keep all of this work in the background, we only need to background the detached task, and that will automatically propagate to all of its child tasks, so we don’t need to worry about forgetting to transitively set background priority and accidentally starving UI work. At this point, we’ve seen all of the primary forms of tasks there are in Swift. Async-let allows for a fixed number of child tasks to be spawned as variable bindings, with automatic management of cancellation and error propagation if the binding goes out of scope. When we need a dynamic number of child tasks that are still bounded to a scope, we can move up to task groups. If we need to break off some work that isn’t well scoped but which is still related to its originating task, we can construct unstructured tasks, but we need to manually manage those. And for maximum flexibility, we also have detached tasks, which are manually managed tasks that don’t inherit anything from their origin. Tasks and structured concurrency are just one part of the suite of concurrency features Swift supports. Be sure to check out all these other great talks to see how it fits in with the rest of the language. “Meet async/await in Swift” gives you more details about async functions, which gives us the structured basis for writing concurrent code. Actors provide data isolation to create concurrent systems that are safe from data races. See the “Protect mutable state with Swift actors” session to learn more about how. We saw “for await” loops on task groups, and those are just one example of AsyncSequence, which provides a standard interface for working with asynchronous streams of data. The “Meet AsyncSequence” session goes deeper into the available APIs for working with sequences. Tasks integrate with the core OS to achieve low overhead and high scalability, and the “Swift concurrency: Behind the scenes” session gives more technical details about how that’s accomplished. All these features come together to make writing concurrent code in Swift easy and safe, letting you write code that gets the most out of your devices while still focusing on the interesting parts of your app, thinking less about the mechanics of managing concurrent tasks or the worries of potential bugs caused by multithreading. Thank you for watching. I hope you enjoy the rest of the conference. [upbeat music]
-
-
1:57 - Asynchronous code with completion handlers is unstructured
func fetchThumbnails( for ids: [String], completion handler: @escaping ([String: UIImage]?, Error?) -> Void ) { guard let id = ids.first else { return handler([:], nil) } let request = thumbnailURLRequest(for: id) let dataTask = URLSession.shared.dataTask(with: request) { data, response, error in guard let response = response, let data = data else { return handler(nil, error) } // ... check response ... UIImage(data: data)?.prepareThumbnail(of: thumbSize) { image in guard let image = image else { return handler(nil, ThumbnailFailedError()) } fetchThumbnails(for: Array(ids.dropFirst())) { thumbnails, error in // ... add image to thumbnails ... } } } dataTask.resume() } -
2:56 - Asynchronous code with async/await is structured
func fetchThumbnails(for ids: [String]) async throws -> [String: UIImage] { var thumbnails: [String: UIImage] = [:] for id in ids { let request = thumbnailURLRequest(for: id) let (data, response) = try await URLSession.shared.data(for: request) try validateResponse(response) guard let image = await UIImage(data: data)?.byPreparingThumbnail(ofSize: thumbSize) else { throw ThumbnailFailedError() } thumbnails[id] = image } return thumbnails } -
7:59 - Structured concurrency with async-let
func fetchOneThumbnail(withID id: String) async throws -> UIImage { let imageReq = imageRequest(for: id), metadataReq = metadataRequest(for: id) async let (data, _) = URLSession.shared.data(for: imageReq) async let (metadata, _) = URLSession.shared.data(for: metadataReq) guard let size = parseSize(from: try await metadata), let image = try await UIImage(data: data)?.byPreparingThumbnail(ofSize: size) else { throw ThumbnailFailedError() } return image } -
11:46 - Checking for cancellation by calling a method that throws
func fetchThumbnails(for ids: [String]) async throws -> [String: UIImage] { var thumbnails: [String: UIImage] = [:] for id in ids { try Task.checkCancellation() thumbnails[id] = try await fetchOneThumbnail(withID: id) } return thumbnails } -
12:16 - Obtaining the cancellation status of the current task
func fetchThumbnails(for ids: [String]) async throws -> [String: UIImage] { var thumbnails: [String: UIImage] = [:] for id in ids { if Task.isCancelled { break } thumbnails[id] = try await fetchOneThumbnail(withID: id) } return thumbnails } -
13:13 - Async-let is for concurrency with static width
func fetchThumbnails(for ids: [String]) async throws -> [String: UIImage] { var thumbnails: [String: UIImage] = [:] for id in ids { thumbnails[id] = try await fetchOneThumbnail(withID: id) } return thumbnails } func fetchOneThumbnail(withID id: String) async throws -> UIImage { // ... async let (data, _) = URLSession.shared.data(for: imageReq) async let (metadata, _) = URLSession.shared.data(for: metadataReq) // ... } -
13:58 - A task group is for concurrency with dynamic width
func fetchThumbnails(for ids: [String]) async throws -> [String: UIImage] { var thumbnails: [String: UIImage] = [:] try await withThrowingTaskGroup(of: Void.self) { group in for id in ids { group.async { // Error: Mutation of captured var 'thumbnails' in concurrently executing code thumbnails[id] = try await fetchOneThumbnail(withID: id) } } } return thumbnails } -
16:32 - Accessing the results of tasks within a group
func fetchThumbnails(for ids: [String]) async throws -> [String: UIImage] { var thumbnails: [String: UIImage] = [:] try await withThrowingTaskGroup(of: (String, UIImage).self) { group in for id in ids { group.async { return (id, try await fetchOneThumbnail(withID: id)) } } // Obtain results from the child tasks, sequentially, in order of completion. for try await (id, thumbnail) in group { thumbnails[id] = thumbnail } } return thumbnails } -
20:39 - Creating an unstructured task
@MainActor class MyDelegate: UICollectionViewDelegate { func collectionView(_ view: UICollectionView, willDisplay cell: UICollectionViewCell, forItemAt item: IndexPath) { let ids = getThumbnailIDs(for: item) Task { let thumbnails = await fetchThumbnails(for: ids) display(thumbnails, in: cell) } } } -
22:11 - Cancelling unstructured tasks
@MainActor class MyDelegate: UICollectionViewDelegate { var thumbnailTasks: [IndexPath: Task<Void, Never>] = [:] func collectionView(_ view: UICollectionView, willDisplay cell: UICollectionViewCell, forItemAt item: IndexPath) { let ids = getThumbnailIDs(for: item) thumbnailTasks[item] = Task { defer { thumbnailTasks[item] = nil } let thumbnails = await fetchThumbnails(for: ids) display(thumbnails, in: cell) } } func collectionView(_ view: UICollectionView, didEndDisplay cell: UICollectionViewCell, forItemAt item: IndexPath) { thumbnailTasks[item]?.cancel() } } -
24:09 - Detaching a task
@MainActor class MyDelegate: UICollectionViewDelegate { var thumbnailTasks: [IndexPath: Task<Void, Never>] = [:] func collectionView(_ view: UICollectionView, willDisplay cell: UICollectionViewCell, forItemAt item: IndexPath) { let ids = getThumbnailIDs(for: item) thumbnailTasks[item] = Task { defer { thumbnailTasks[item] = nil } let thumbnails = await fetchThumbnails(for: ids) Task.detached(priority: .background) { writeToLocalCache(thumbnails) } display(thumbnails, in: cell) } } } -
24:57 - Creating a task group inside a detached task
@MainActor class MyDelegate: UICollectionViewDelegate { var thumbnailTasks: [IndexPath: Task<Void, Never>] = [:] func collectionView(_ view: UICollectionView, willDisplay cell: UICollectionViewCell, forItemAt item: IndexPath) { let ids = getThumbnailIDs(for: item) thumbnailTasks[item] = Task { defer { thumbnailTasks[item] = nil } let thumbnails = await fetchThumbnails(for: ids) Task.detached(priority: .background) { withTaskGroup(of: Void.self) { g in g.async { writeToLocalCache(thumbnails) } g.async { log(thumbnails) } g.async { ... } } } display(thumbnails, in: cell) } } }
-